
綜述 | 2022 深度學(xué)習(xí)計(jì)算機(jī)視覺進(jìn)展
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
重磅干貨,第一時(shí)間送達(dá)

摘要
近年來,深度學(xué)習(xí)在計(jì)算機(jī)視覺各個(gè)領(lǐng)域中的應(yīng)用成效顯著,新的深度學(xué)習(xí)方法和深度神經(jīng)網(wǎng)絡(luò)模型不斷涌現(xiàn),算法性能被不斷刷新。本文著眼于2016年以來的一些典型網(wǎng)絡(luò)和模型,對(duì)基于深度學(xué)習(xí)的計(jì)算機(jī)視覺研究新進(jìn)展進(jìn)行綜述。首先總結(jié)了針對(duì)圖像分類的主流深度神經(jīng)網(wǎng)絡(luò)模型,包括標(biāo)準(zhǔn)模型及輕量化模型等;然后總結(jié)了針對(duì)不同計(jì)算機(jī)視覺領(lǐng)域的主流方法和模型,包括目標(biāo)檢測(cè)、圖像分割和圖像超分辨率等;最后總結(jié)了深度神經(jīng)網(wǎng)絡(luò)搜索方法。
關(guān)鍵詞
深度學(xué)習(xí);?目標(biāo)檢測(cè);?圖像分割;?超分辨率;?計(jì)算機(jī)視覺
引 言
近20年來,隨著深度學(xué)習(xí)技術(shù)的迅猛發(fā)展和圖形處理器(Graphics processing unit, GPU)等硬件計(jì)算設(shè)備的廣泛普及,深度學(xué)習(xí)技術(shù)幾乎已經(jīng)應(yīng)用到計(jì)算機(jī)視覺的各個(gè)領(lǐng)域,如目標(biāo)檢測(cè)、圖像分割、超分辨率重建及人臉識(shí)別等,并在圖像搜索、自動(dòng)駕駛、用戶行為分析、文字識(shí)別、虛擬現(xiàn)實(shí)和激光雷達(dá)等產(chǎn)品中具有不可估量的商業(yè)價(jià)值和廣闊的應(yīng)用前景[1]。基于深度學(xué)習(xí)技術(shù)的計(jì)算機(jī)視覺同時(shí)可以對(duì)其他學(xué)科領(lǐng)域產(chǎn)生深遠(yuǎn)的影響,如在計(jì)算機(jī)圖形學(xué)中的動(dòng)畫仿真和實(shí)時(shí)渲染技術(shù)、材料領(lǐng)域的顯微圖像分析技術(shù)、醫(yī)學(xué)圖像分析處理技術(shù)、實(shí)時(shí)評(píng)估師生課堂表現(xiàn)和考場(chǎng)行為的智慧教育、分析運(yùn)動(dòng)員比賽表現(xiàn)和技術(shù)統(tǒng)計(jì)的智能系統(tǒng)等。
深度學(xué)習(xí)早在1986年就被Dechter[2]引入機(jī)器學(xué)習(xí)領(lǐng)域,2000年Aizenberg等[3]又在機(jī)器學(xué)習(xí)領(lǐng)域引入了人工神經(jīng)網(wǎng)絡(luò)(Artificial neural network,ANN)[4]。深度學(xué)習(xí)方法由多層組成,用于學(xué)習(xí)多層次抽象的數(shù)據(jù)特征[5]。在人工神經(jīng)網(wǎng)絡(luò)領(lǐng)域中,深度學(xué)習(xí)又被稱為分層學(xué)習(xí)[6],是一種通過在不同計(jì)算階段精確地分配分?jǐn)?shù)來調(diào)節(jié)網(wǎng)絡(luò)激活的技術(shù)[4]。深度學(xué)習(xí)常常用多種抽象結(jié)構(gòu)來學(xué)習(xí)復(fù)雜的映射關(guān)系,如2009年蒙特利爾大學(xué)的Bengio教授提出的帶隱藏層的ANN[7]等。深度學(xué)習(xí)技術(shù)可以被視作一種表征學(xué)習(xí),是機(jī)器學(xué)習(xí)的一個(gè)分支。
2005年多倫多大學(xué)的Hinton教授團(tuán)隊(duì)試圖用圖模型模擬人類的大腦[8],在文獻(xiàn)[9]中提出了一種逐層貪婪算法來預(yù)訓(xùn)練深度信念網(wǎng),克服了深度網(wǎng)絡(luò)難以訓(xùn)練的弊端,并用自編碼器降低數(shù)據(jù)維度[10],開啟了深度學(xué)習(xí)的熱潮,使其被廣泛應(yīng)用在語(yǔ)音識(shí)別、計(jì)算機(jī)視覺和自然語(yǔ)言處理等領(lǐng)域。2011—2012年,深度學(xué)習(xí)技術(shù)在語(yǔ)音識(shí)別領(lǐng)域中最先取得重大突破,Dahl團(tuán)隊(duì)[11]和Hinton團(tuán)隊(duì)[12]先后將識(shí)別錯(cuò)誤率降至20%~30%。在2012年的ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn)競(jìng)賽(ImageNet large scale visual recognition challenge,ILSVRC)中,Hinton的學(xué)生提出的AlexNet[13]以超過第二名準(zhǔn)確率10%的巨大優(yōu)勢(shì)奪得冠軍,深度學(xué)習(xí)正式進(jìn)入了爆發(fā)期。近年來各大互聯(lián)網(wǎng)科技公司,如Google、Microsoft、Facebook、百度、阿里巴巴和騰訊等也爭(zhēng)相投入大規(guī)模深度學(xué)習(xí)系統(tǒng)的研發(fā)中。
筆者在2016年發(fā)表“深度卷積神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺中的應(yīng)用研究綜述”[1],總結(jié)了2016年之前深度卷積神經(jīng)網(wǎng)絡(luò)在計(jì)算機(jī)視覺中的研究成果。本文在文獻(xiàn)[1]的基礎(chǔ)上,重點(diǎn)綜述2016年以后基于深度學(xué)習(xí)的計(jì)算機(jī)視覺研究新進(jìn)展。但為了表述的完整和邏輯的嚴(yán)謹(jǐn),本文與文獻(xiàn)[1]內(nèi)容有少量重合。
1 通用深度神經(jīng)網(wǎng)絡(luò)模型
本文將解決圖像分類任務(wù)的神經(jīng)網(wǎng)絡(luò)模型稱為通用網(wǎng)絡(luò),這類模型通常是解決其他視覺任務(wù)的基礎(chǔ)模型。1989年AT&T貝爾實(shí)驗(yàn)室的研究員LeCun通過反向傳播算法成功地訓(xùn)練了卷積神經(jīng)網(wǎng)絡(luò)[14],這項(xiàng)工作代表了20世紀(jì)80年代神經(jīng)網(wǎng)絡(luò)的研究成果。1998年LeCun等基于前人的工作提出了LeNet[15],由2個(gè)卷積層和3個(gè)全連接層組成,因此也被稱為L(zhǎng)eNet?5,其結(jié)構(gòu)如圖1所示。但LeNet?5的復(fù)雜度遠(yuǎn)遠(yuǎn)無法和今天的深度網(wǎng)絡(luò)模型相比,性能也相差懸殊,但在當(dāng)時(shí)取得了和支持向量機(jī)相媲美的效果,并被廣泛應(yīng)用于識(shí)別手寫數(shù)字,受到了廣泛的關(guān)注。
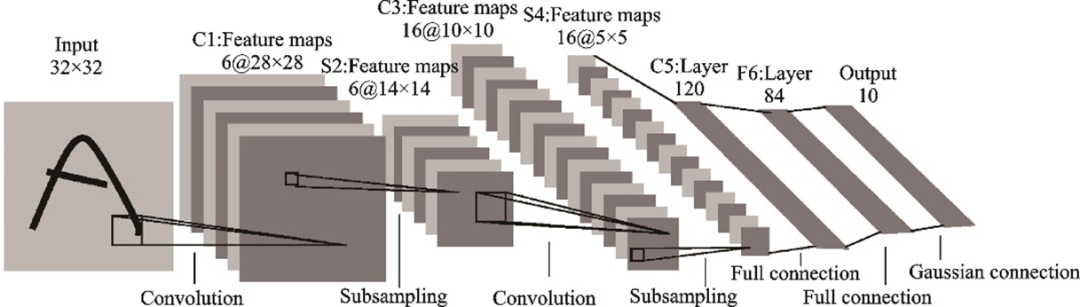
圖1??LeNet-5結(jié)構(gòu)示意圖[15]
Fig.1??Structure of LeNet-5[15]
在LeNet提出后,很長(zhǎng)一段時(shí)間卷積神經(jīng)網(wǎng)絡(luò)并不是計(jì)算機(jī)視覺領(lǐng)域的主流方法,因?yàn)長(zhǎng)eNet只在小數(shù)據(jù)集上表現(xiàn)良好,在規(guī)模更大、更真實(shí)的數(shù)據(jù)集上表現(xiàn)一般。由于當(dāng)時(shí)未普及高性能的神經(jīng)網(wǎng)絡(luò)加速硬件設(shè)備,卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練的時(shí)間成本和空間開銷太大。因此在2012年AlexNet[13]提出之前,大多數(shù)研究者都采用SIFT[16]、HOG[17]和SURF[18]等手工方法提取特征,并花費(fèi)大量的精力進(jìn)行數(shù)據(jù)整理。
2007年,普林斯頓大學(xué)李飛飛團(tuán)隊(duì)基于WordNet的層級(jí)結(jié)構(gòu)開始搭建ImageNet數(shù)據(jù)集[19],通過網(wǎng)絡(luò)抓取、人力標(biāo)注和眾包平臺(tái)等各種方式,最終在2009年公開。如今ImageNet數(shù)據(jù)集包含超過14 000 000張帶標(biāo)簽的高清圖像、超過22 000個(gè)類別。從2010年開始舉辦的ILSVRC圖像分類比賽成為計(jì)算機(jī)視覺領(lǐng)域的重要賽事,用于評(píng)估圖像分類算法的準(zhǔn)確率。ILSVRC比賽數(shù)據(jù)集是ImageNet的一個(gè)子集,包含1 000類、數(shù)百萬(wàn)張圖片。來自NEC實(shí)驗(yàn)室的林元慶帶領(lǐng)NEC?UIUC團(tuán)隊(duì)以28.2%的top?5錯(cuò)誤率贏得了2010年ILSVRC冠軍。2010和2011這兩年的冠軍方案主要采用HOG[17]、LBP[20?21]等算法手動(dòng)提取特征再輸入到特征向量機(jī)進(jìn)行分類。
2012年的冠軍AlexNet[13]首次將深度學(xué)習(xí)技術(shù)應(yīng)用到大規(guī)模圖像分類領(lǐng)域,證明了深度學(xué)習(xí)技術(shù)學(xué)習(xí)到的特征可以超越手工設(shè)計(jì)的特征,開啟了計(jì)算機(jī)視覺領(lǐng)域中的深度學(xué)習(xí)熱潮。AlexNet和LeNet結(jié)構(gòu)理念相似,采用5層卷積層和3層全連接層,激活函數(shù)用ReLU取代了sigmoid,用dropout方法取代了權(quán)重衰減緩解過擬合,結(jié)構(gòu)如圖2所示。AlexNet取得了17.0%的top?5錯(cuò)誤率。
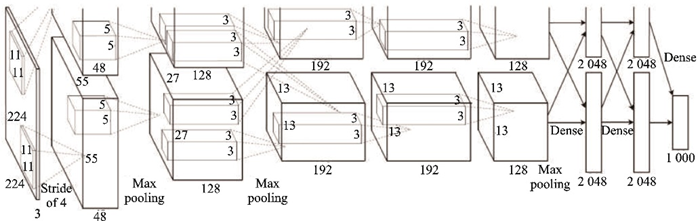
?圖2??AlexNet結(jié)構(gòu)示意圖[13]
Fig.2??Structure of AlexNet[13]
2014年的冠軍團(tuán)隊(duì)提出的ZFNet[22]通過反卷積可視化CNN學(xué)習(xí)到的特征,取得了11.7%的錯(cuò)誤率。2015年的冠軍團(tuán)隊(duì)Szegedy等提出的GoogLeNet[23]將錯(cuò)誤率降到了6.7%。GoogLeNet提出了一種Inception模塊,如圖3所示。這種結(jié)構(gòu)基于網(wǎng)絡(luò)中的網(wǎng)絡(luò)(Network in network,NiN)的思想[24],有4條分支,通過不同尺寸的卷積層和最大池化層并行提取信息,1×11×1卷積層可以顯著減少參數(shù)量,降低模型復(fù)雜度。GoogLeNet一共使用9個(gè)Inception模塊,和全局平均池化層、卷積層及全連接層串聯(lián)。Szegedy提出很多改進(jìn)的Inception版本,陸續(xù)使用了Batch Normalization[25]、Label Smoothing[26]和殘差連接[27]等方法。
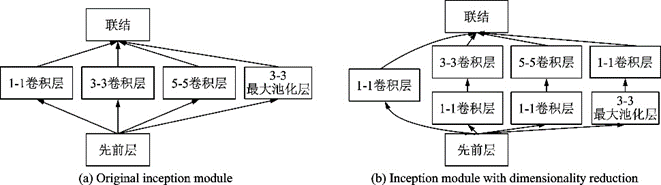
圖3??Inception模塊示意圖[23]
Fig.3??Inception block[23]
2015年的ILSVRC亞軍是由牛津大學(xué)視覺幾何團(tuán)隊(duì)提出的VGGNet[28]。VGGNet重復(fù)使用了3××3的卷積核和2××2的池化層,將深度網(wǎng)絡(luò)加深到16~19層,如圖4所示。
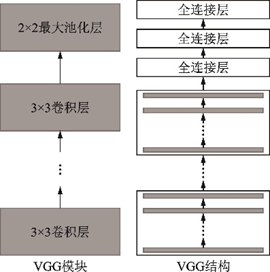
圖4??VGG模塊和VGG結(jié)構(gòu)示意圖
Fig.4??Block and structure of VGG
2016年,微軟亞洲研究院He等提出的ResNet[29]奪得了ILSVRC冠軍,將top?5錯(cuò)誤率降至3.6%。ResNet最深可達(dá)152層,以絕對(duì)優(yōu)勢(shì)獲得了目標(biāo)檢測(cè)、分類和定位3個(gè)賽道的冠軍。該研究提出了殘差模塊的跳接結(jié)構(gòu),網(wǎng)絡(luò)學(xué)習(xí)殘差映射f(x)?xfx-x,每1個(gè)殘差模塊里有2個(gè)相同輸出通道的3××3卷積層,每個(gè)卷積層后接1個(gè)BN(Batch normalization)層和ReLU激活函數(shù)。跳接結(jié)構(gòu)可以使數(shù)據(jù)更快地向前傳播,保證網(wǎng)絡(luò)沿著正確的方向深化,準(zhǔn)確率可以不斷提高。ResNet的思想產(chǎn)生了深遠(yuǎn)的影響,是深度學(xué)習(xí)領(lǐng)域的一個(gè)重要進(jìn)步,奠定了訓(xùn)練更深的深度網(wǎng)絡(luò)的基礎(chǔ),其結(jié)構(gòu)如圖5所示。
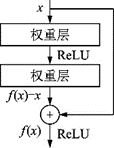
圖5??殘差模塊
Fig.5??Residual block
2017年提出的DenseNet[30]和ResNeXt[31]都是受ResNet[29]的啟發(fā)。DenseNet的目標(biāo)不僅僅是學(xué)習(xí)殘差映射,而且是學(xué)習(xí)類似泰勒展開的更高階的項(xiàng)。因此DenseNet的跳接結(jié)構(gòu)沒有用加法,而是用了聯(lián)結(jié),如圖6所示。

圖6??ResNet和DenseNet結(jié)構(gòu)比較
Fig.6??Structures of ResNet and DenseNet
ResNeXt[31]則是結(jié)合了ResNet[29]和Inception v4[27],采用GoogLeNet分組卷積的思想,在簡(jiǎn)化的Inception結(jié)構(gòu)中加入殘差連接,并通過一個(gè)超參數(shù)“基數(shù)”調(diào)整ResNeXt模塊中分支的數(shù)量。這種簡(jiǎn)化的Inception結(jié)構(gòu)不需要人工設(shè)計(jì)每個(gè)分支,而是全部采用相同的拓?fù)浣Y(jié)構(gòu),結(jié)構(gòu)如圖7所示。ResNeXt在2016年ILSVRC的分類任務(wù)上獲得了亞軍。
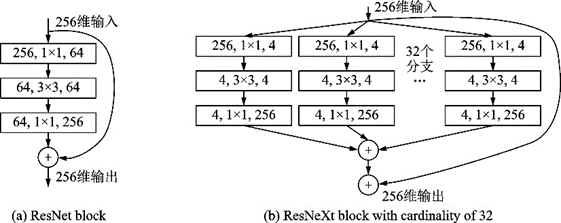
圖7??ResNet殘差模塊和基數(shù)為32的ResNeXt模塊[31]
Fig.7??ResNet block and ResNeXt block with cardinality of 32[31]
和ResNeXt同年提出的Xception[32]也是一種基于Inception分組卷積思想的模型。分組卷積的核心思想是將通道拆分成不同大小感受野的子通道,不僅可以提取多尺寸的特征,還可以減少參數(shù)量,降低模型復(fù)雜度。Xception模塊可以視為一種極端情況的Inception模塊,它的輸入先經(jīng)過一個(gè)1××1的卷積層后進(jìn)入多個(gè)完全相同的3××3卷積層分支,如圖8所示。
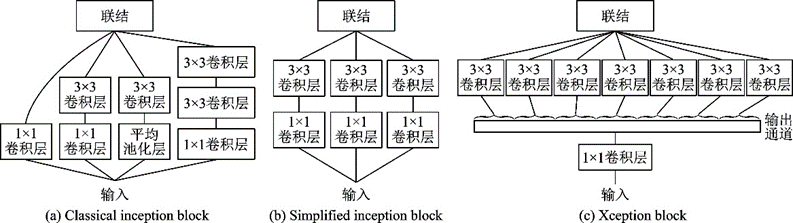
圖8??經(jīng)典及簡(jiǎn)化的Inception模塊和Xception模塊[32]
Fig.8??Classical and simplified Inception blocks and Xception block[32]
ImageNet數(shù)據(jù)規(guī)模大,圖像類別多,因此在ImageNet上訓(xùn)練的模型泛化能力較好。如今很多模型都是在ImageNet上預(yù)訓(xùn)練后進(jìn)行微調(diào),有些模型微調(diào)后準(zhǔn)確率可以超過只在目標(biāo)訓(xùn)練集上訓(xùn)練模型的20%。受ImageNet自由開放思想的影響,很多科技巨頭也陸續(xù)開放了自己的大規(guī)模數(shù)據(jù)集:2018年谷歌發(fā)布了Open Image數(shù)據(jù)集[33],包含了被分為6 000多類的900萬(wàn)張帶有目標(biāo)位置信息的圖片;JFT?300M數(shù)據(jù)集[34]包含300萬(wàn)張非精確標(biāo)注的圖像;DeepMind也公開了Kinetics數(shù)據(jù)集[35?36],包含650 000張人體動(dòng)作的視頻截圖。這些大規(guī)模數(shù)據(jù)集增強(qiáng)了深度學(xué)習(xí)模型的泛化能力,為全世界深度學(xué)習(xí)工作者和數(shù)據(jù)科學(xué)家提供了數(shù)據(jù)支持,保障了深度學(xué)習(xí)領(lǐng)域的蓬勃發(fā)展。
生成模型可以學(xué)習(xí)數(shù)據(jù)中隱含的特征并對(duì)數(shù)據(jù)分布進(jìn)行建模,它的應(yīng)用非常廣泛,可以對(duì)圖像、文本、語(yǔ)音等不同數(shù)據(jù)建模真實(shí)的分布,然后基于這一分布通過采樣生成新的數(shù)據(jù)。在深度學(xué)習(xí)之前就已經(jīng)有許多生成模型被提出,但由于生成模型往往難以建模,因此科研人員遇到了許多挑戰(zhàn)。變分自編碼器(Variational autoencoder, VAE)[37]是一種當(dāng)前主流的基于深度學(xué)習(xí)技術(shù)的生成模型,它是對(duì)標(biāo)準(zhǔn)自編碼器的一種變形。自編碼器將真實(shí)樣本的高級(jí)特征通過編碼器映射到低級(jí)特征,被稱為隱向量(或潛向量),然后又通過解碼器生成相同樣本的高級(jí)特征。標(biāo)準(zhǔn)自編碼器和變分自編碼器的區(qū)別在于對(duì)隱向量的約束不同。標(biāo)準(zhǔn)自編碼器關(guān)注重構(gòu)損失,即
L(X,X')=∥X?X'∥22?X,X'=X-X'22 | (1) |
式中:XX和X'X'分別為輸入圖像和重構(gòu)圖像。
變分自編碼器則強(qiáng)迫隱變量服從單位高斯分布,優(yōu)化如下?lián)p失函數(shù)
L(X)=Ez~q[lg?P(X|z)]?KL(q(z|X)||p(z))?X=Ez~q[lg?P(X|z)]-KL(q(z|X)||p(z)) | (2) |
式中:EE表示期望;z為隱變量;q(z|X)q(z|X)表示隱變量的建議分布,即編碼器輸出的隱變量的分布;p(z)p(z)表示標(biāo)準(zhǔn)高斯分布;P(X|z)P(X|z)表示解碼器分布;KLKL表示KL散度。式(2)等號(hào)右邊第1項(xiàng)表示重構(gòu)圖片的精確度,用均方誤差度量;第2項(xiàng)表示圖片的潛變量分布和單位高斯分布之間的差異,用KL散度來度量。為了優(yōu)化KL散度,變分自編碼器生成1個(gè)均值向量和1個(gè)標(biāo)準(zhǔn)差向量用于參數(shù)重構(gòu)。此時(shí)在隱向量分布中采樣就可以生成新的圖片。自編碼器和變分自編碼器示意圖如圖9、10所示。
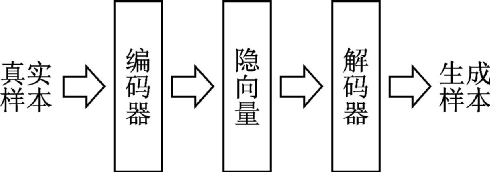
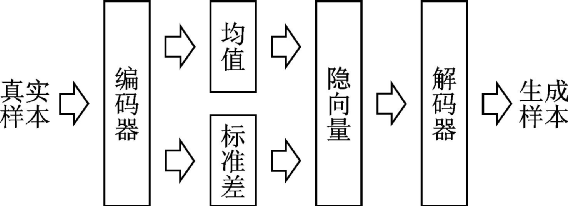
圖10??變分自編碼器示意圖
Fig.10??Variational autoencoder
生成對(duì)抗網(wǎng)絡(luò)(Generative adversarial net, GAN)[38]是另一種十分常見的基于深度學(xué)習(xí)技術(shù)的生成模型,它包括2個(gè)同時(shí)進(jìn)行的組件:生成器和判別器,其結(jié)構(gòu)如圖11所示。生成器從隱向量生成圖像,判別器對(duì)真?zhèn)螆D像進(jìn)行分類,二者相互對(duì)抗,互相促進(jìn)。
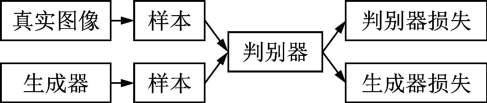
圖11??生成對(duì)抗網(wǎng)絡(luò)示意圖
Fig.11??Generative adversarial net
變分自編碼器和生成對(duì)抗網(wǎng)絡(luò)近年來有了顯著的發(fā)展[39]。在計(jì)算機(jī)視覺領(lǐng)域中,變分自編碼器和生成對(duì)抗網(wǎng)絡(luò)已經(jīng)被廣泛應(yīng)用于圖像翻譯、超分辨率、目標(biāo)檢測(cè)、視頻生成和圖像分割等領(lǐng)域,具有廣闊的研究?jī)r(jià)值和應(yīng)用前景。
2 輕量化網(wǎng)絡(luò)
隨著網(wǎng)絡(luò)層數(shù)的加深,各種深度網(wǎng)絡(luò)模型的性能變得越來越好,隨之而來的問題是模型巨大的參數(shù)量和緩慢的推理速度,因此輕量化網(wǎng)絡(luò)的需求變得愈加強(qiáng)烈。輕量化網(wǎng)絡(luò)的設(shè)計(jì)核心是在盡可能保證模型精度的前提下,降低模型的計(jì)算復(fù)雜度和空間復(fù)雜度,從而使得深度神經(jīng)網(wǎng)絡(luò)可以被部署在計(jì)算性能和存儲(chǔ)空間有限的嵌入式邊緣設(shè)備上,實(shí)現(xiàn)從學(xué)術(shù)界到工業(yè)界的躍遷。在分布式訓(xùn)練中,小模型使得服務(wù)器之間通信產(chǎn)生的帶寬負(fù)擔(dān)也相對(duì)較小。目前學(xué)術(shù)界和工業(yè)界設(shè)計(jì)輕量化的深度網(wǎng)絡(luò)模型主要有4種方法:人工設(shè)計(jì)的輕量化神經(jīng)網(wǎng)絡(luò)、基于神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索(Neural architecture search,NAS)的自動(dòng)設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)技術(shù)、卷積神經(jīng)網(wǎng)絡(luò)壓縮和基于AutoML的自動(dòng)模型壓縮。
2016年由伯克利和斯坦福的研究者提出的SqueezeNet[40]是最早進(jìn)行深度模型輕量化的工作之一,其結(jié)構(gòu)如圖12所示。SqueezeNet提出了一種Fire模塊用來減少參數(shù)量,其結(jié)構(gòu)如圖13所示。它分成Squeeze和Expand兩部分:Squeeze層只由數(shù)個(gè)1××1卷積層構(gòu)成;Expand層則包含數(shù)個(gè)1××1和3××3卷積層。Fire模塊和Inception模塊的結(jié)構(gòu)很相近,二者都使用了1××1和3××3組合的拓?fù)浣Y(jié)構(gòu),在使用了不同尺寸的卷積層后進(jìn)行連結(jié)。在網(wǎng)絡(luò)結(jié)構(gòu)上,SqueezeNet借鑒了VGG堆疊的形式,在2層卷積層和池化層中間堆疊了8個(gè)Fire模塊。最終SqueezeNet在ImageNet上實(shí)現(xiàn)了AlexNet級(jí)別的精確度,參數(shù)減少到原來的1/501/50。通過使用Deep Compression模型壓縮技術(shù),SqueezeNet的參數(shù)量?jī)H有50萬(wàn)個(gè),約為AlexNet的1/5001/500。

圖12??SqueezeNet網(wǎng)絡(luò)結(jié)構(gòu)示意圖[40]
Fig.12??Structure of SqueezeNet[40]
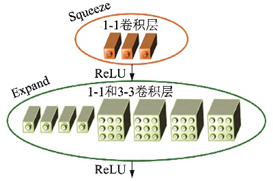
圖13??SqueezeNet的Fire 模塊[40]
Fig.13??Fire block in SqueezeNet[40]
MobileNet[41]是谷歌于2017年提出的輕量化網(wǎng)絡(luò),核心是通過用深度可分離卷積代替標(biāo)準(zhǔn)的卷積。深度可分離卷積將標(biāo)準(zhǔn)卷積拆成1個(gè)深度卷積和1個(gè)逐點(diǎn)卷積(也就是1××1卷積),可以將計(jì)算量降低至原來的1/8~1/91/8~1/9。標(biāo)準(zhǔn)卷積和深度可分離卷積+BN+ReLU結(jié)構(gòu)如圖14所示。
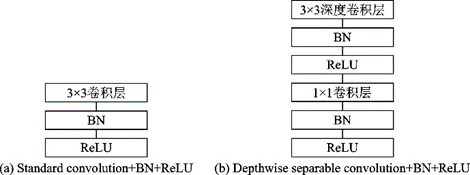
圖14??標(biāo)準(zhǔn)卷積+BN+ReLU網(wǎng)絡(luò)和深度可分離卷積+BN+ReLU網(wǎng)絡(luò)[41]
Fig.14??Standard convolution+BN+ReLU network and depthwise separable convolution+BN+ReLU network[41]
深度可分離卷積的結(jié)構(gòu)成為了很多輕量化網(wǎng)絡(luò)設(shè)計(jì)的參照,這種結(jié)構(gòu)的有效性自從被Xception[32]證明后成為輕量化網(wǎng)絡(luò)設(shè)計(jì)的主流思想。比MobileNet晚2個(gè)月由Face++團(tuán)隊(duì)提出的ShuffleNet[42]基于這一思想,使用了Channel Shuffle和分組卷積。分組卷積的思想最早由AlexNet[13]提出,初衷是為了降低單張GPU的占用,將輸入通道分成相同的幾條分支然后連結(jié),從而減少訓(xùn)練參數(shù)量。之后的Inception模塊將這一思想發(fā)揚(yáng)光大,ResNeXt[31]的成功也證明了分組卷積的有效性。由于分組卷積會(huì)讓信息的流通不當(dāng),ShuffleNet設(shè)計(jì)了Channel Shuffle,將各組通道均分并進(jìn)行混洗,然后依次重新構(gòu)成特征圖,示意圖如圖15所示。
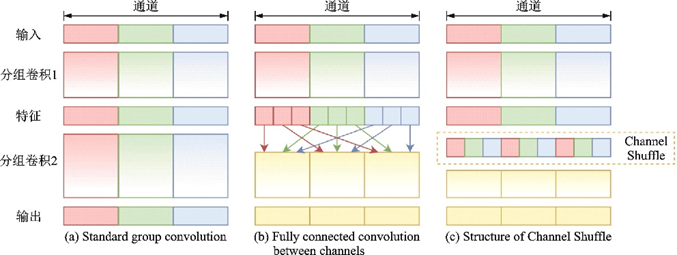
圖15??Channel Shuffle示意圖[42]
Fig.15??Diagrammatic sketch of Channel Shuffle[42]
圖15中,Channel Shuffle后第2個(gè)組卷積GConv2的輸入信息來自各個(gè)通道,圖15(c,b)達(dá)到了一樣的效果。ShuffleNet模塊的設(shè)計(jì)借鑒了ResNet bottleneck的結(jié)構(gòu),如圖16所示。
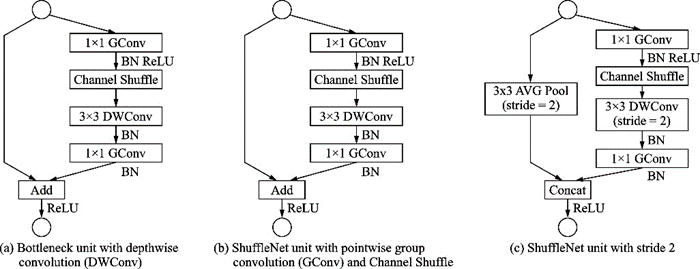
ShuffleNet模塊摒棄了Pointwise卷積,因?yàn)閷?duì)于輸入維度較高的小型網(wǎng)絡(luò),1××1卷積的開銷巨大。例如在ResNeXt模塊中,1××1卷積占據(jù)了93.4%的計(jì)算量。在網(wǎng)絡(luò)拓?fù)渖希琒queezeNet和MobileNet都采用了VGG(Visual geometry group)的堆疊結(jié)構(gòu),而ShuffleNet采用了ResNet的跳接結(jié)構(gòu)。
2018年,MobileNet和ShuffleNet又相繼提出了改進(jìn)版本。MobileNet v2[43]結(jié)構(gòu)如圖17所示,采用了效率更高的殘差結(jié)構(gòu),提出了一種逆殘差模塊,并將MobileNet v1模塊的最后一個(gè)ReLU6層改成線性層。ShuffleNet v2[44]用更直接的運(yùn)算速度評(píng)估模型,摒棄了之前如每秒浮點(diǎn)運(yùn)算次數(shù)(FLOPS)等間接的指標(biāo)。結(jié)構(gòu)上ShuffleNet v2采用了一種Channel Split操作,將輸入的特征圖分到2個(gè)分支里,最后通過連結(jié)和Channel Shuffle合并分支并輸出。ShuffleNet v1和ShuffleNet v2結(jié)構(gòu)如圖18所示。
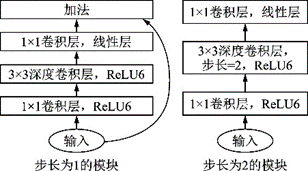
圖17??MobileNet v2模塊[43]
Fig.17??MobileNet v2 block[43]
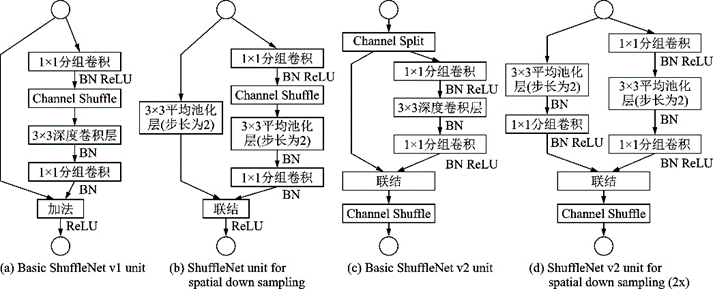
圖18??ShuffleNet v1和ShuffleNet v2結(jié)構(gòu)[44]
Fig.18??Structures of ShuffleNet v1 and ShuffleNet v2[44]
2020年華為諾亞方舟實(shí)驗(yàn)室的團(tuán)隊(duì)提出了GhostNet[45],如圖19所示,可以用更少的參數(shù)量提取更多的特征圖。首先對(duì)輸入特征圖進(jìn)行卷積操作,然后進(jìn)行一系列簡(jiǎn)單的線性操作生成特征圖,從而在實(shí)現(xiàn)了傳統(tǒng)卷積層效果的同時(shí)降低了參數(shù)量和計(jì)算量。該團(tuán)隊(duì)認(rèn)為性能較好的主流卷積神經(jīng)網(wǎng)絡(luò)如ResNet?50通常存在大量冗余的特征圖,正是這些特征圖保證了網(wǎng)絡(luò)對(duì)數(shù)據(jù)深刻的理解。Ghost模塊用更小的代價(jià)模擬了傳統(tǒng)卷積層的效果。
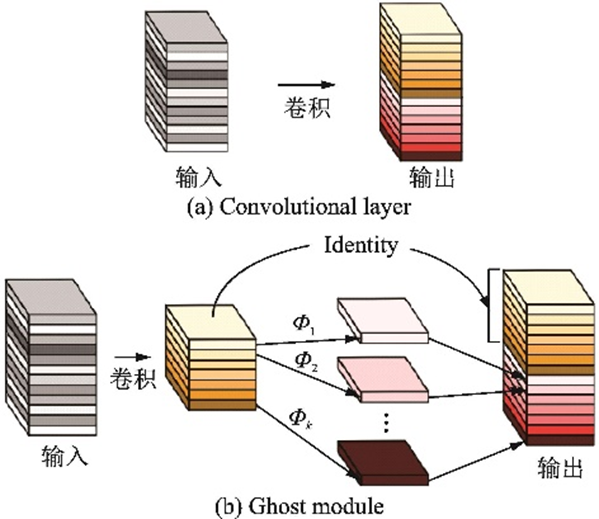
圖19??卷積層和Ghost模塊[45]
Fig.19??Convolutional layer and Ghost module[45]
人工設(shè)計(jì)的輕量化網(wǎng)絡(luò)MobileNet系列[41,43]和ShuffleNet系列[42,44]的基本思想主要是通過分離卷積操作減少運(yùn)算量,再采用殘差跳接結(jié)構(gòu)和Channel Shuffle等混合通道的操作促進(jìn)分支間的交流,提高信息利用率。隨著模型規(guī)模的擴(kuò)大,硬件資源變得更加稀缺,在保證精度的前提下壓縮并加速模型將會(huì)是經(jīng)久不衰的熱門研究方向,也是信息化時(shí)代發(fā)展的必經(jīng)之路。近年來大量的關(guān)于模型壓縮和結(jié)構(gòu)優(yōu)化的工作不斷涌現(xiàn),如網(wǎng)絡(luò)剪枝[46]、張量分解[47?48]和知識(shí)遷移[49]等。輕量化模型的發(fā)展有助于深度學(xué)習(xí)技術(shù)的推廣和應(yīng)用,推動(dòng)深度學(xué)習(xí)技術(shù)的產(chǎn)業(yè)化發(fā)展。
3 面向特定任務(wù)的深度網(wǎng)絡(luò)模型
計(jì)算機(jī)視覺任務(wù)眾多,深度學(xué)習(xí)最開始在圖像分類實(shí)現(xiàn)突破,當(dāng)前深度學(xué)習(xí)幾乎深入到了計(jì)算機(jī)視覺的各個(gè)領(lǐng)域。本節(jié)將針對(duì)目標(biāo)檢測(cè)、圖像分割、圖像超分辨率和神經(jīng)架構(gòu)搜索等其他計(jì)算機(jī)視覺任務(wù)簡(jiǎn)要總結(jié)深度學(xué)習(xí)方法。
3.1 目標(biāo)檢測(cè)
目標(biāo)檢測(cè)任務(wù)作為計(jì)算機(jī)視覺的基本任務(wù)之一,包含物體的分類、定位和檢測(cè)。近年來隨著深度學(xué)習(xí)技術(shù)的發(fā)展,目標(biāo)檢測(cè)算法已經(jīng)從基于手工特征的HOG[17]、SIFT[16]及LBP[20?21]等傳統(tǒng)算法轉(zhuǎn)向了基于深度神經(jīng)網(wǎng)絡(luò)的機(jī)器學(xué)習(xí)技術(shù)。自2014年Girshick等提出了R?CNN[50]模型以來,目標(biāo)檢測(cè)就成為了計(jì)算機(jī)視覺最受人關(guān)注的領(lǐng)域之一。在R?CNN之后,Girshick團(tuán)隊(duì)相繼提出了Fast R?CNN[51]、Faster R?CNN[52]等一系列模型,這些模型均將目標(biāo)檢測(cè)問題歸結(jié)為如何提出可能包含目標(biāo)的候選區(qū)域和如何對(duì)這些區(qū)域分類兩個(gè)階段,因此這類模型也被稱作兩階段模型。
受當(dāng)時(shí)性能最好的圖像分類網(wǎng)絡(luò),如AlexNet[13]和VGG[28]等的影響,R?CNN系列模型的網(wǎng)絡(luò)結(jié)構(gòu)由2個(gè)子網(wǎng)組成:第1個(gè)子網(wǎng)用普通分類網(wǎng)絡(luò)的卷積層提取共享特征;第2個(gè)子網(wǎng)的全連接層進(jìn)行感興趣區(qū)域(Region of interest,RoI)的預(yù)測(cè)和回歸,中間用一個(gè)RoI池化層連接。這些網(wǎng)絡(luò)的結(jié)構(gòu)在文獻(xiàn)[1]中已做介紹,這里不再贅述。在ResNet[29]、GoogLeNet[23]等性能更強(qiáng)的分類網(wǎng)絡(luò)出現(xiàn)后,這種全卷積網(wǎng)絡(luò)結(jié)構(gòu)也被應(yīng)用到了目標(biāo)檢測(cè)任務(wù)上。然而,由于卷積層并不能有針對(duì)性地保留位置信息,這種全卷積結(jié)構(gòu)的檢測(cè)精度遠(yuǎn)低于它的分類精度。R?FCN[53]提出了一種位置敏感分?jǐn)?shù)圖來增強(qiáng)網(wǎng)絡(luò)對(duì)于位置信息的表達(dá)能力,提高網(wǎng)絡(luò)的檢測(cè)精度,其結(jié)構(gòu)如圖20所示。R?FCN[53]在PASCAL VOC 2007數(shù)據(jù)集上平均精度均值(mean Average precision, mAP)達(dá)到了83.6%,單張圖片的推理速度達(dá)到170 ms。
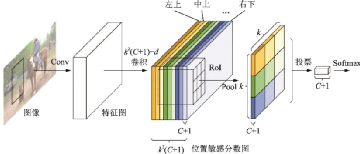
圖20??R-FCN結(jié)構(gòu)示意圖[53]
Fig.20??Structure of R-FCN[53]
如何準(zhǔn)確識(shí)別不同尺寸的物體是目標(biāo)檢測(cè)任務(wù)的難點(diǎn)之一。圖21(a)中的方法通過對(duì)不同尺寸的圖片提取不同尺度特征來增強(qiáng)不同尺度特征的語(yǔ)義信息,但時(shí)間和計(jì)算成本太高。圖21(b)中的單一特征圖方法即為SPPnet[54]、Fast R?CNN[51]和Faster R?CNN[52]使用的方法,即在最后一層的特征圖上進(jìn)行預(yù)測(cè)。盡管速度較快,但包含的語(yǔ)義信息很少,不能準(zhǔn)確地預(yù)測(cè)目標(biāo)的位置。圖21(c)是SSD[55]采用的多尺度融合方法,從網(wǎng)絡(luò)的不同層抽取不同尺度的特征分別進(jìn)行預(yù)測(cè),這種方法不需要額外的計(jì)算,但不能很好地提取小目標(biāo)敏感的淺層高分辨率特征。

圖21??多尺度檢測(cè)的常見結(jié)構(gòu)[56]
Fig.21??Common structures of multiscale detection[56]
特征金字塔網(wǎng)絡(luò)(Feature Pyramid network, FPN)[56]借鑒了ResNet跳接的思想,結(jié)合了層間特征融合與多分辨率預(yù)測(cè),其結(jié)構(gòu)如圖22所示。文獻(xiàn)[56]將FPN用于Faster R?CNN的區(qū)域候選網(wǎng)絡(luò)(Region proposal network, RPN),在每層金字塔后面接一個(gè)RPN頭。由于輸入了多尺度的特征,因此不需要生成多尺度的錨框,只需要在每個(gè)尺度上設(shè)置不同的寬高比,并共享參數(shù)。以ResNet?101為骨干網(wǎng)絡(luò)的Faster R?CNN+FPN在COCO test?dev上[email protected]達(dá)到了59.1%,超過不用FPN的Faster R?CNN 3.4%。實(shí)驗(yàn)證明對(duì)于基于區(qū)域的目標(biāo)檢測(cè)器,該特征金字塔結(jié)構(gòu)的特征提取效果優(yōu)于單尺度的特征提取效果。
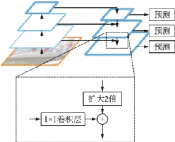
圖22??FPN結(jié)構(gòu)示意圖[56]
Fig.22??Structure of FPN[56]
YOLO[57]是單階段模型的代表,它沒有提出候選區(qū)域的過程,而是直接將提出候選區(qū)域和分類統(tǒng)一為一個(gè)邊界框回歸的問題,將整張圖片作為網(wǎng)絡(luò)的輸入,在輸出層對(duì)邊界框位置信息和類別進(jìn)行回歸,實(shí)現(xiàn)了端到端的學(xué)習(xí)過程,其示意圖如圖23所示。它首先將圖片縮放并劃分為等分的網(wǎng)格,然后在每張圖片上運(yùn)行單獨(dú)的卷積網(wǎng)絡(luò),最后用非極大值抑制得到最后的預(yù)測(cè)框。損失函數(shù)被分為3部分:坐標(biāo)誤差、物體誤差和類別誤差。為了平衡類別不均衡和大小物體等帶來的影響,損失函數(shù)中添加了權(quán)重并將長(zhǎng)寬取根號(hào)。
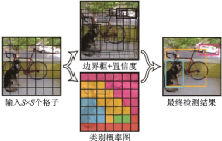
圖23??YOLO示意圖[57]
Fig.23??Pipeline of YOLO[57]
YOLO的網(wǎng)絡(luò)結(jié)構(gòu)借鑒了GoogLeNet的結(jié)構(gòu),用24層卷積層后接2層全連接層,將Inception模塊替換為類似網(wǎng)中網(wǎng)[24]中的1××1卷積層后接3××3卷積層,并在ImageNet上預(yù)訓(xùn)練,其結(jié)構(gòu)如圖24所示。在PASCAL VOC 07+12數(shù)據(jù)集上,YOLO在達(dá)到最高幀率155 幀/s時(shí)mAP可以達(dá)到52.7%,在mAP最高達(dá)到63.4%時(shí)幀率可達(dá)45幀/s。YOLO在保證了準(zhǔn)確率的同時(shí)擁有極高的推理速度,遠(yuǎn)超當(dāng)時(shí)的兩階段模型。
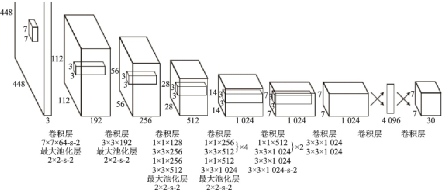
圖24??YOLO網(wǎng)絡(luò)結(jié)構(gòu)圖[57]
Fig.24??Structure of YOLO[57]
YOLOv1的訓(xùn)練流程簡(jiǎn)單,背景誤檢率低,但由于只選擇交并比最高的邊界框作為輸出,每個(gè)格子最多只能預(yù)測(cè)出一個(gè)物體。當(dāng)每個(gè)格子包含多個(gè)物體時(shí),YOLOv1只能檢測(cè)出1個(gè)目標(biāo)。YOLOv2[58]在YOLOv1的基礎(chǔ)上,骨干網(wǎng)絡(luò)采用了以VGG16為基礎(chǔ)的Darknet19,使用了批量歸一化緩解了梯度爆炸和消失的問題。YOLOv2借鑒了Faster R?CNN錨框的設(shè)計(jì),將YOLOv1的全連接層替換為錨框預(yù)測(cè)邊界框的位置,解耦了位置和類別的回歸計(jì)算。YOLOv2[58]同時(shí)采用了多尺度訓(xùn)練,提升了模型的健壯性。后續(xù)的YOLOv3[59]骨干網(wǎng)絡(luò)采用了Darknet53,使用了ResNet的跳接結(jié)構(gòu),并引入了FPN,一定程度上解決了YOLOv2小目標(biāo)檢測(cè)精度較差的問題。YOLOv3在分辨率320?像素×像素×320 像素的輸入上以22 ms的推理時(shí)間使得mAP達(dá)到28.2%,和當(dāng)時(shí)最好的單階段檢測(cè)器SSD達(dá)到相同精度,但擁有3倍的推理速度。YOLOv3以51 ms的推理時(shí)間使得[email protected]達(dá)到57.9%,相較于以198 ms的推理時(shí)間[email protected]達(dá)到57.5%的RetinaNet[60],精度相近但YOLOv3的速度是RetinaNet[60]的近4倍。
SSD[55]是最早達(dá)到兩階段模型精度的單階段模型之一,對(duì)后期的單階段工作影響很深,其結(jié)構(gòu)如圖25所示。為解決YOLOv1小目標(biāo)檢測(cè)精度低的問題,基于VGG不同的卷積段采用了多尺度的特征圖,并在每個(gè)網(wǎng)格點(diǎn)生成更多的不同大小和長(zhǎng)寬比的預(yù)測(cè)框。SSD在PASCAL VOC 2007數(shù)據(jù)集上,對(duì)于300 像素××300 像素的輸入mAP達(dá)到了74.3%,512 像素××512 像素的輸入mAP達(dá)到了76.9%。在COCO trainval35k數(shù)據(jù)集上預(yù)訓(xùn)練再在PASCAL VOC 07+12上微調(diào)后,SSD最終mAP達(dá)到了81.6%。

圖25??SSD網(wǎng)絡(luò)結(jié)構(gòu)圖[55]
Fig.25??Structure of SSD[55]
和兩階段模型相比,單階段模型只需要進(jìn)行一次類別預(yù)測(cè)和位置回歸,因此卷積運(yùn)算的共享程度更高,擁有更快的速度和更小的內(nèi)存占用。最新的單階段模型如FCOS[61]、VFNet[62]等工作已經(jīng)可以達(dá)到接近兩階段模型精度,同時(shí)擁有更好的實(shí)時(shí)性,更適合在移動(dòng)端部署。
目標(biāo)檢測(cè)技術(shù)從傳統(tǒng)的手工特征算法到如今的深度學(xué)習(xí)算法,精度越來越高的同時(shí)速度也越來越快。在過去幾年中,工業(yè)界已經(jīng)出現(xiàn)了成熟的基于目標(biāo)檢測(cè)技術(shù)的應(yīng)用,如人臉檢測(cè)識(shí)別、行人檢測(cè)、交通信號(hào)檢測(cè)、文本檢測(cè)和遙感目標(biāo)檢測(cè)等。這些應(yīng)用不僅便利了人們的生活,也為學(xué)術(shù)界提供了啟發(fā)和指導(dǎo)。
在未來的研究工作中,小目標(biāo)檢測(cè)和視頻目標(biāo)檢測(cè)依舊是研究的熱點(diǎn)問題。同時(shí),為了加快推理速度并在移動(dòng)端嵌入式設(shè)備部署模型,目標(biāo)檢測(cè)的輕量化一直備受工業(yè)界的關(guān)注。在采集到多模態(tài)的信息(如文字、圖像、點(diǎn)云等)后,如何通過更好的信息融合來提高檢測(cè)性能也是未來的一個(gè)重點(diǎn)研究方向。
3.2 圖像分割
本文的圖像分割指圖像語(yǔ)義分割任務(wù),其要求將整張圖片的所有像素分類為預(yù)先定義的多個(gè)類別之一。由于是像素級(jí)的稠密分類任務(wù),相比圖像分類和目標(biāo)檢測(cè)更加困難,是圖像處理和計(jì)算機(jī)視覺中的一個(gè)重要課題,在場(chǎng)景理解、醫(yī)學(xué)圖像分析、機(jī)器人感知及視頻監(jiān)控等領(lǐng)域有著廣泛的應(yīng)用。近年來,由于深度學(xué)習(xí)技術(shù)在計(jì)算機(jī)視覺領(lǐng)域應(yīng)用中取得的成功,人們也進(jìn)行了大量的工作研究基于深度學(xué)習(xí)模型的圖像分割方法。
U?Net[63]和全卷積網(wǎng)絡(luò)(Fully convolutional network, FCN)[64]都是在2015年提出的網(wǎng)絡(luò),啟發(fā)了后來的很多圖像分割和目標(biāo)檢測(cè)的工作。FCN已在文獻(xiàn)[1]中進(jìn)行介紹,此處不再贅述。U?Net最初是一個(gè)用于醫(yī)學(xué)圖像分割的卷積神經(jīng)網(wǎng)絡(luò),分別贏得了ISBI 2015細(xì)胞追蹤挑戰(zhàn)賽和齲齒檢測(cè)挑戰(zhàn)賽的冠軍。U?Net可視為一個(gè)編碼器?解碼器結(jié)構(gòu),編碼器有4個(gè)子模塊,每個(gè)子模塊通過一個(gè)最大池化層下采樣,解碼器再通過上采樣的4個(gè)子模塊增大分辨率直到與輸入圖像的分辨率保持一致,其結(jié)構(gòu)如圖26所示。由于卷積采用的是Valid模式,實(shí)際輸出圖像的分辨率低于輸入圖像的分辨率。U?Net網(wǎng)絡(luò)同時(shí)還采取了跳接結(jié)構(gòu)(即圖26中的灰色箭頭),將上采樣結(jié)果與編碼器中具有相同分辨率的子模塊的輸出進(jìn)行連接,作為解碼器中下一個(gè)子模塊的輸入。
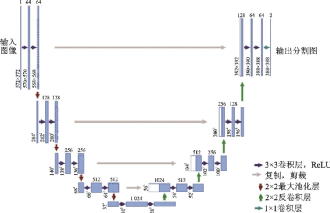
圖26??U-Net結(jié)構(gòu)示意圖[63]
Fig.26??Structure of U-Net[63]
由于人體結(jié)構(gòu)相對(duì)固定,分割目標(biāo)在圖像內(nèi)的分布很有規(guī)律,醫(yī)學(xué)圖像大多語(yǔ)義明確,需要低分辨率的信息用于目標(biāo)物體的識(shí)別。同時(shí)醫(yī)學(xué)圖像形態(tài)復(fù)雜,往往要求高精度的分割,需要高分辨率的信息用于精準(zhǔn)分割。U?Net融合了高低分辨率的信息,因此對(duì)醫(yī)學(xué)圖像分割的效果很好。
深度卷積神經(jīng)網(wǎng)絡(luò)中池化層和上采樣層的設(shè)計(jì)對(duì)于圖像分割的設(shè)計(jì)有致命缺陷。因?yàn)閰?shù)不可學(xué)習(xí),而且池化會(huì)導(dǎo)致像素的空間信息和內(nèi)部的數(shù)據(jù)結(jié)構(gòu)丟失,上采樣也無法重建小物體信息,因此圖像分割的精度一直處于瓶頸。針對(duì)這一問題,2016年的DeepLab[66]又提出了一種空洞卷積,避免了池化層帶來的信息損失,并使用全連接的條件隨機(jī)場(chǎng)(Conditional random field, CRF)優(yōu)化分割精度,其結(jié)構(gòu)如圖29所示。
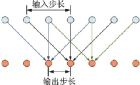
圖29??空洞卷積示意圖(卷積核尺寸為3,輸入步長(zhǎng)為2,輸出步長(zhǎng)為1)[66]
Fig.29??Dilated convolution (kernel size=3, input stride=2, output stride=1)[66]
空洞卷積可以在避免使用池化層損失信息的情況下增大感受野,同時(shí)不增加參數(shù)數(shù)量。作為后處理,DeepLabv1將每個(gè)像素點(diǎn)作為節(jié)點(diǎn),像素之間的關(guān)系作為節(jié)點(diǎn)間的連線,構(gòu)成一個(gè)條件隨機(jī)場(chǎng),再用一個(gè)二元?jiǎng)莺瘮?shù)描述像素點(diǎn)之間的關(guān)系,將相似像素分配相同的標(biāo)簽,從而在分割邊界取得良好的效果。DeepLabv1速度很快,幀率達(dá)到8 幀/s,在PASCAL VOC 2012數(shù)據(jù)集上平均交并比(Mean intersection over union,mIoU)達(dá)到了71.6%,它的“深度卷積神經(jīng)網(wǎng)絡(luò)+條件隨機(jī)場(chǎng)”結(jié)構(gòu)對(duì)之后很多工作產(chǎn)生了深遠(yuǎn)的影響。
2017年劍橋大學(xué)提出的SegNet[67]的主要?jiǎng)訖C(jī)是針對(duì)道路和室內(nèi)場(chǎng)景理解,設(shè)計(jì)一個(gè)像素級(jí)別的圖像分割網(wǎng)絡(luò),同時(shí)保證內(nèi)存和計(jì)算時(shí)間方面上的高效。SegNet采用“編碼器?解碼器”的全卷積結(jié)構(gòu),編碼網(wǎng)絡(luò)采用VGG16[28]的卷積層,解碼器從相應(yīng)的編碼器獲取最大池化索引后上采樣,產(chǎn)生稀疏特征映射。復(fù)用池化索引減少了端到端訓(xùn)練的參數(shù)量,并改善了邊界的劃分。SegNet在道路場(chǎng)景分割數(shù)據(jù)集CamVid 11 Road Class Segmentation[68]上mIoU達(dá)到60.1%, 邊界F1得分(Boundary F1 score,BF) 達(dá)到46.84%;在室內(nèi)場(chǎng)景分割數(shù)據(jù)集SUN RGB?D Indoor Scenes[69]上幾乎所有當(dāng)時(shí)的深層網(wǎng)絡(luò)結(jié)構(gòu)都表現(xiàn)不佳,但SegNet依然在絕大多數(shù)的指標(biāo)上超過了其他網(wǎng)絡(luò)。SegNet結(jié)構(gòu)如圖30所示。

圖30??SegNet結(jié)構(gòu)示意圖[67]
Fig.30??Structure of SegNet[67]
2017年香港中文大學(xué)提出了PSPNet[70],該網(wǎng)絡(luò)采用金字塔池化模塊,用大小為1××1、2××2、3××3和6××6的4層金字塔分別提取不同尺度的信息,然后通過雙線性插值恢復(fù)長(zhǎng)寬,把不同層的特征連結(jié)起來得到全局信息,這種結(jié)構(gòu)比全局池化更具有代表性,融合了多尺度的信息。PSPNet在PASCAL VOC 2012數(shù)據(jù)集上mIoU達(dá)到了82.6%,在MS COCO數(shù)據(jù)集上預(yù)訓(xùn)練后達(dá)到85.4%。PSPNet結(jié)構(gòu)如圖31所示。

圖31??PSPNet結(jié)構(gòu)示意圖[70]
Fig.31??Structure of PSPNet[70]
DeepLabv2[71]在DeepLabv1[66]和PSPNet[70]的基礎(chǔ)上用ResNet101代替VGG16,并提出了一種帶有空洞卷積的空間金字塔池化模塊(Atrous spatial Pyramid pooling, ASPP),用多尺度的方法以不同的速率并行地提取特征圖信息,極大地增加了感受野,其結(jié)構(gòu)如圖32所示。DeepLabv2使用不同的學(xué)習(xí)率,相比DeepLabv1, mIoU達(dá)到了79.7%,提升了8.1%,但二者都使用了全連接條件隨機(jī)場(chǎng)模塊。
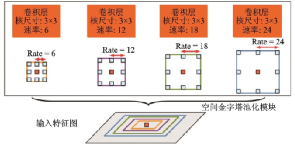
圖32??空洞空間金字塔池化示意圖[71]
Fig.32??Structure of ASPP[71]
DeepLabv3[72]重新審視了空洞卷積的作用,將其級(jí)聯(lián)模塊應(yīng)用在ResNet最后一個(gè)模塊之后。不使用空洞卷積和使用空洞卷積的級(jí)聯(lián)模塊示意圖如圖33所示。
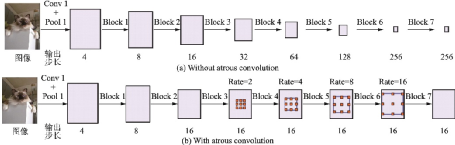
圖33??不使用和使用空洞卷積的級(jí)聯(lián)模塊示意圖[72]
Fig.33??Structures of cascade modules without and with atrous convolution[72]
DeepLabv3改進(jìn)了ASPP模塊,應(yīng)用BN層,并將DeepLabv2中Rate=24的3××3卷積模塊替換為1××1卷積模塊和全局池化模塊,克服了像素點(diǎn)相對(duì)距離增大時(shí)有效權(quán)重減少的問題。DeepLabv3去掉了后處理的DenseCRF模塊,并最終在PASCAL VOC 2012數(shù)據(jù)集上mIoU達(dá)到了86.9%,相較DeepLabv2進(jìn)一步提升了7.2%。改進(jìn)的ASPP模塊示意圖如圖34所示。
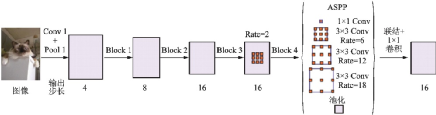
圖34??改進(jìn)的ASPP模塊示意圖[72]
Fig.34??Improved ASPP module[72]
DeepLabv3+[73]相對(duì)于DeepLabv3,采用了“編碼器?解碼器”的結(jié)構(gòu),編碼器中包含豐富的語(yǔ)義信息,解碼器則輸出圖像的邊緣細(xì)節(jié)信息。空間金字塔池化模塊,“編碼器?解碼器”結(jié)構(gòu)和帶有空洞卷積的“編碼器?解碼器”結(jié)構(gòu)如圖35所示,DeepLabv3+結(jié)構(gòu)如圖36所示。
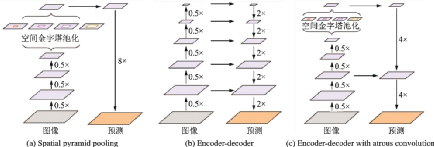
圖35??DeepLabv3+使用了空間金字塔池化模塊,“編碼器-解碼器”結(jié)構(gòu)和空洞卷積[73]
Fig.35??DeepLabv3+ employing spatial Pyramid pooling, encoder-decoder and atrous convolution[73]
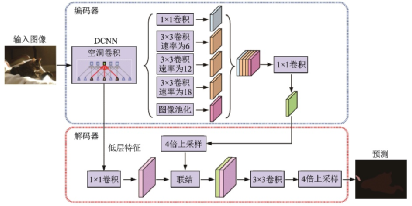
圖36??DeepLabv3+示意圖[73]
Fig.36??Structure of DeepLabv3+[73]
DeepLabv3+將之前的骨干網(wǎng)絡(luò)ResNet101替換為Xception,并結(jié)合深度可分離卷積的思想提出了空洞深度可分離卷積,在減少參數(shù)量的同時(shí)進(jìn)一步增大感受野。和DeepLabv3一樣,DeepLabv3+也沒有使用DenseCRF后處理模塊。最終DeepLabv3+在PASCAL VOC 2012數(shù)據(jù)集上mIoU達(dá)到了89.0%,相較DeepLabv3提升了2.1%。深度卷積、逐點(diǎn)卷積和空洞深度可分離卷積示意圖如圖37所示。
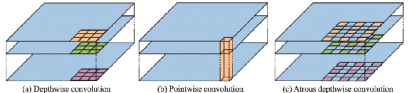
圖37??空洞深度可分離卷積示意圖[73]
Fig.37??Structure of atrous depthwise separable convolution[73]
2019年曠視科技提出了一種名為DFANet[74]的高效CNN架構(gòu),通過子網(wǎng)和子級(jí)聯(lián)的方式聚合多尺度特征,極大地減少了參數(shù)量,其結(jié)構(gòu)如圖38所示。DFANet采用“編碼器?解碼器”結(jié)構(gòu),解碼器的骨干網(wǎng)絡(luò)采用3個(gè)改良的輕量級(jí)Xception融合結(jié)構(gòu),編碼器則是一個(gè)高效的上采樣模塊,用于融合高層和底層的語(yǔ)義信息。在CityScapes[75]測(cè)試數(shù)據(jù)集上,對(duì)于1 024像素××1 024像素的輸入圖片,DFANet在一塊NVIDIA Titan X上mIoU達(dá)到71.3%,F(xiàn)LOPS僅為3.4××109,幀率達(dá)到100 幀/s;在CamVid[68]測(cè)試數(shù)據(jù)集上,對(duì)于960像素××720像素的輸入圖片,DFANet在8 ms的計(jì)算時(shí)間內(nèi)mIoU達(dá)到64.7%,幀率達(dá)到120 幀/s。
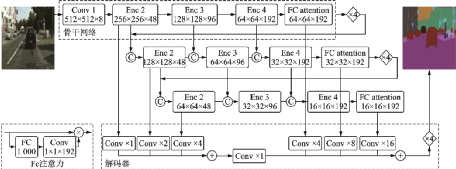
圖38??DFANet結(jié)構(gòu)示意圖[74]
Fig.38??Structure of DFANet[74]
2020年筆者提出一種輕量級(jí)網(wǎng)絡(luò)LRNNet[76]。其中分解卷積塊FCB(圖39(a))利用1××3和3××1的空間分解卷積處理短距離特征,并利用空洞深度分離卷積處理遠(yuǎn)距離特征,實(shí)現(xiàn)了參數(shù)量和計(jì)算量更少、深度更快、準(zhǔn)確率更高的特征提取;高效的簡(jiǎn)化Non?Local模塊LRN(圖39(b))利用區(qū)域主奇異向量作為Non?Local模塊的Key和Value,在降低Non?Local模塊的計(jì)算量和內(nèi)存占用的同時(shí),保持其處理遠(yuǎn)距離關(guān)聯(lián)的效果。在Cityscapes[75]測(cè)試集上,LRNNet的mIoU達(dá)到了72.2%,而網(wǎng)絡(luò)僅有68萬(wàn)個(gè)參數(shù),并在1張GTX 1080Ti卡上達(dá)到71 幀/s的推理速度;在CamVid[68]測(cè)試集上,對(duì)于360像素××480像素的輸入,LRNNet的mIoU達(dá)到了69.2%,參數(shù)量也為68萬(wàn)個(gè),在1張GTX 1080Ti卡上幀率達(dá)到76.5 幀/s。
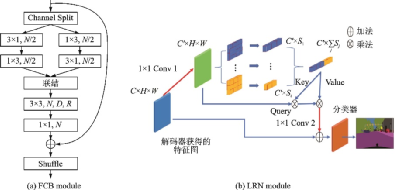
圖39??LRNNet中的FCB和LRN模塊[76]
Fig.39??FCB and LRN modules in LRNNet[76]
圖像分割是像素級(jí)的稠密分類任務(wù),在搜集數(shù)據(jù)集時(shí)需要真值標(biāo)注每個(gè)像素,但由于這個(gè)要求極其耗時(shí)且非常昂貴,許多研究人員開始用弱監(jiān)督學(xué)習(xí)和半監(jiān)督學(xué)習(xí)的方法訓(xùn)練網(wǎng)絡(luò)。常見的弱標(biāo)注有圖像類別標(biāo)簽、邊界框、顯著圖和類激活圖(Class activation map,CAM)等。
2015年谷歌和UCLA團(tuán)隊(duì)的工作[77]是最早開始研究基于弱監(jiān)督學(xué)習(xí)技術(shù)的圖像分割算法之一。該工作基于DeepLab模型[66],研究了弱標(biāo)注(類別標(biāo)簽、邊界框等)與少量強(qiáng)標(biāo)注(像素級(jí)標(biāo)簽)和大量弱標(biāo)注混合對(duì)DCNN圖像分割模型的影響,并在半監(jiān)督和弱監(jiān)督的設(shè)定下提出了一種期望最大化方法(Expectation?maximization,EM)。這項(xiàng)工作證實(shí)了僅使用圖像級(jí)標(biāo)簽的弱標(biāo)注存在性能差距,而在半監(jiān)督設(shè)定下使用少量強(qiáng)標(biāo)注和大量弱標(biāo)注混合可以獲得優(yōu)越的性能,在MS COCO數(shù)據(jù)集上使用5 000張強(qiáng)標(biāo)注圖片和118 287張弱標(biāo)注圖片mIoU超過70%。
盡管類別標(biāo)簽的獲取成本很低,但這類標(biāo)注信息僅僅標(biāo)明某類目標(biāo)存在,不能表示出目標(biāo)的位置和形狀,這往往會(huì)導(dǎo)致分割效果不夠理想,存在邊界模糊等問題。當(dāng)出現(xiàn)目標(biāo)遮擋的情況時(shí),僅使用圖像級(jí)標(biāo)簽獲取完整的目標(biāo)邊界會(huì)更加困難。為了補(bǔ)充監(jiān)督信息中缺少的位置和形狀信息,使用圖像的顯著性信息是一種常見的手段。文獻(xiàn)[78]提出了一個(gè)僅使用類別標(biāo)簽和顯著圖信息的圖像分割模型,其結(jié)構(gòu)如圖40所示。該模型將圖像的顯著圖定義為一個(gè)人最有可能先看到的目標(biāo)的二進(jìn)制掩膜,用預(yù)訓(xùn)練的目標(biāo)檢測(cè)網(wǎng)絡(luò)提取出顯著性區(qū)域,通過種子信息確定目標(biāo)的類別和位置。該工作同樣基于DeepLab[66]的網(wǎng)絡(luò)結(jié)構(gòu),提出的模型測(cè)試精度mIoU達(dá)到56.7%,實(shí)現(xiàn)了全監(jiān)督模型80%的性能。
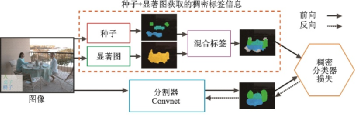
圖40??高層信息指導(dǎo)的圖像分割網(wǎng)絡(luò)結(jié)構(gòu)圖[78]
Fig.40??High-level guided segmentation architecture[78]
定位線索的另一個(gè)流行的選擇是使用CAM。主流的弱監(jiān)督方法通過將CAM作為分割種子,突出局部的顯著部分,然后逐漸生長(zhǎng)直到覆蓋整個(gè)目標(biāo)區(qū)域,從而補(bǔ)充了缺失的目標(biāo)形狀信息。2018年提出的AffinityNet[79]結(jié)合了類別標(biāo)簽和CAM信息,首先計(jì)算圖像的CAM作為監(jiān)督源訓(xùn)練AffinityNet,通過構(gòu)建圖像的語(yǔ)義相似度矩陣,結(jié)合隨機(jī)游走進(jìn)行擴(kuò)散,不斷獎(jiǎng)勵(lì)或懲罰從而修改CAM,最終恢復(fù)出目標(biāo)的形狀。AffinityNet流程如圖41所示。
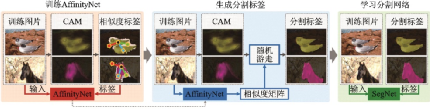
圖41??AffinityNet流程示意圖[79]
Fig.41??Pipeline of AffinityNet[79]
深度學(xué)習(xí)技術(shù)在圖像分割領(lǐng)域取得了顯著成就,但仍然面臨不小的挑戰(zhàn)。當(dāng)前的大規(guī)模數(shù)據(jù)集如MS COCO[80]和PASCAL VOC[81]并不能滿足工業(yè)界的需求,而具有多目標(biāo)和重疊目標(biāo)的數(shù)據(jù)集對(duì)于圖像分割而言更具有應(yīng)用價(jià)值,這可以使得圖像分割技術(shù)更好地處理密集目標(biāo)場(chǎng)景和現(xiàn)實(shí)生活中常見的重疊目標(biāo)場(chǎng)景。基于小樣本學(xué)習(xí)技術(shù)的圖像分割算法同樣具有廣闊的前景,因?yàn)樵谠S多應(yīng)用領(lǐng)域,例如醫(yī)學(xué)圖像分析領(lǐng)域,獲取學(xué)習(xí)樣本的成本較高,難度也較大。圖像分割技術(shù)的實(shí)時(shí)性也是一個(gè)難題,目前大多數(shù)模型并不能達(dá)到實(shí)時(shí)性的要求,但在很多應(yīng)用場(chǎng)景下,速度的重要性遠(yuǎn)高于精度。
3.3 超分辨率
超分辨率技術(shù)是計(jì)算機(jī)視覺領(lǐng)域提高圖像和視頻分辨率的重要處理技術(shù)之一,研究如何將低分辨率的圖像或圖像序列恢復(fù)出具有更多細(xì)節(jié)信息的高分辨率圖像或圖像序列,在高清電視、監(jiān)控視頻、醫(yī)學(xué)成像、遙感衛(wèi)星成像、顯微成像及老舊圖像視頻修復(fù)等領(lǐng)域有著重要的應(yīng)用價(jià)值。傳統(tǒng)上超分辨率屬于底層視覺領(lǐng)域,但本文敘述順序從圖像分類、目標(biāo)檢測(cè)、圖像分割到超分辨率,輸出逐級(jí)復(fù)雜,依次為圖像標(biāo)簽、目標(biāo)位置和類別標(biāo)簽、與輸入同大小的分割圖、比輸入圖像大的高分辨率圖像等。與前幾個(gè)任務(wù)不同,超分辨率需要生成和恢復(fù)輸入中不存在的信息。
超分辨率的概念最早出現(xiàn)在光學(xué)領(lǐng)域,1952年Francia第一次提出了用于提高光學(xué)分辨率的超分辨率的概念[82]。1964年前后,Harris[83]和Goodman[84]分別提出了后來稱為Harris?Goodman頻譜外推的方法,這被認(rèn)為是最早的圖像復(fù)原方法,但這種技術(shù)只能在一些理想情況下進(jìn)行仿真,實(shí)際效果不太理想,因此并未得到推廣。1984年Tsai等[85]首次利用單幅低分辨率圖像的頻域信息重建出高分辨率圖像后,超分辨率重建技術(shù)才得到廣泛的認(rèn)可和應(yīng)用,如今它已經(jīng)成為圖像增強(qiáng)和計(jì)算機(jī)視覺領(lǐng)域中最重要的研究方向之一。
傳統(tǒng)的超分辨率方法包括基于預(yù)測(cè)、基于邊緣、基于統(tǒng)計(jì)、基于塊和基于稀疏表示等方法。根據(jù)輸入輸出的不同,超分辨率問題可以分為基于重建的超分辨率問題、視頻超分辨率問題和單幅圖像超分辨率問題。根據(jù)是否依賴訓(xùn)練樣本,超分辨率問題則又可以分為增強(qiáng)邊緣的超分辨率問題(無訓(xùn)練樣本) 和基于學(xué)習(xí)的超分辨率問題 (有訓(xùn)練樣本)。
最簡(jiǎn)單、應(yīng)用最廣泛的經(jīng)典單幅圖像超分辨率方法是插值法,包括Lanczos、Bicubic、Bilinear和Nearest等,這種方法操作簡(jiǎn)單、實(shí)施性好,但并不能恢復(fù)出清晰的邊緣和細(xì)節(jié)信息,因此很多其他用于增強(qiáng)細(xì)節(jié)的傳統(tǒng)算法相繼被提出。文獻(xiàn)[86]提出了基于塊的方法,也被稱為基于鄰域嵌入的方法。這種方法使用流形學(xué)習(xí)中的局部線性嵌入,假設(shè)高、低維度中圖像塊的線性關(guān)系可以保持,用低分辨率圖像的特征(梯度等)重構(gòu)高分辨率圖像。文獻(xiàn)[87?88]提出了基于稀疏表示的方法,也被成為字典學(xué)習(xí)。這種方法將低分辨率圖像和高分辨率圖像表示為字典DD與原子αα,高分辨率圖像可表示為x=Dhighx=Dhigh,低分辨率圖像為y=Dlowy=Dlow,假設(shè)不同分辨率的同一幅圖像的原子αα,在訓(xùn)練完字典DhighDhigh和DlowDlow后,用低分辨率的圖像得到αα,隨后得到重構(gòu)的高清圖像。基于學(xué)習(xí)的超分辨率技術(shù)[89]如圖42所示,上、下采樣方法示意圖[90]如圖43所示。

圖42??基于學(xué)習(xí)的超分辨率技術(shù)[89]
Fig.42??Learning-based super-resolution[89]

圖43??超分辨率問題中的上采樣和下采樣方法[90]
Fig.43??Upsampling and downsampling in super-resolution[90]
經(jīng)典的超分辨率方法要求研究者具備深厚的相關(guān)領(lǐng)域先驗(yàn)知識(shí)。隨著深度學(xué)習(xí)技術(shù)的興起,用神經(jīng)網(wǎng)絡(luò)方法重建的圖像質(zhì)量超過了傳統(tǒng)方法,速度也更快,這使得大批學(xué)者轉(zhuǎn)向?qū)ι疃葘W(xué)習(xí)技術(shù)在超分辨率領(lǐng)域的應(yīng)用研究。香港中文大學(xué)Dong等于2015年首次將卷積神經(jīng)網(wǎng)絡(luò)用于單幅圖像超分辨率重建,提出了SRCNN[91],該網(wǎng)絡(luò)僅僅用了3個(gè)卷積層,利用傳統(tǒng)稀疏編碼,依次進(jìn)行圖像塊提取、非線性映射和圖像重建,實(shí)現(xiàn)了從低分辨率圖像到高分辨率圖像的端到端映射,流程圖如圖44所示。SRCNN激活函數(shù)采用ReLU,損失函數(shù)采用均方誤差。
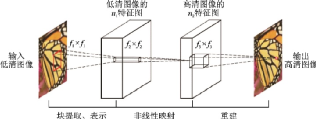
圖44??SRCNN流程圖[91]
Fig.44??Pipeline of SRCNN[91]
2016年Dong團(tuán)隊(duì)在之前SRCNN的基礎(chǔ)上提出了更快、實(shí)時(shí)性更好的FSRCNN[92],在原始網(wǎng)絡(luò)的最后加入反卷積層放大尺寸,摒棄了Bicubic插值方法,使用了更多的映射層和更小的卷積核,改變了特征維度,并共享其中的映射層,F(xiàn)SRCNN改進(jìn)示意圖如圖45所示。訓(xùn)練時(shí)FSRCNN只需要微調(diào)最后的反卷積層,因此訓(xùn)練速度很快。FSRCNN激活函數(shù)采用PReLU,損失函數(shù)仍采用均方誤差。
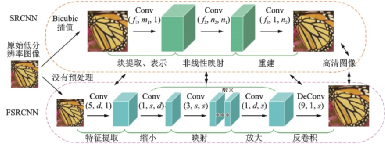
圖45??FSRCNN對(duì)SRCNN的改進(jìn)[92]
Fig.45??FSRCNN’s improvement on SRCNN[92]
2016年提出的ESPCN[93]在SRCNN基礎(chǔ)上進(jìn)一步提高了速度,其結(jié)構(gòu)如圖46所示。該工作提出了一種亞像素卷積層,可以直接在低分辨率圖像上提取特征,從而避免在高分辨率圖像上進(jìn)行卷積,降低了計(jì)算復(fù)雜度。ESPCN激活函數(shù)采用tanh,損失函數(shù)仍然采用均方誤差。
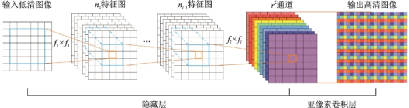
圖46??ESPCN示意圖[93]
Fig.46??Structure of ESPCN[93]
SRCNN的網(wǎng)絡(luò)輸入是經(jīng)過上采樣的低分辨率圖像,計(jì)算復(fù)雜度很高,因此FSRCNN和ESPCN都選擇在網(wǎng)絡(luò)末端上采樣以降低計(jì)算復(fù)雜度。但如果在上采樣后沒有足夠深的網(wǎng)絡(luò)提取特征,圖像信息就會(huì)損失。為了更好地使用更深的網(wǎng)絡(luò),很多工作引入了殘差網(wǎng)絡(luò)。2016年首爾國(guó)立大學(xué)Kim等提出的VDSR[94]是第一個(gè)引入全局殘差的模型,其結(jié)構(gòu)如圖47所示。Kim等指出,高低分辨率圖像攜帶的低頻信息很相近,因此事實(shí)上網(wǎng)絡(luò)只需要學(xué)習(xí)高頻信息之間的殘差即可。VSDR思想啟發(fā)了很多之后利用殘差結(jié)構(gòu)的工作。
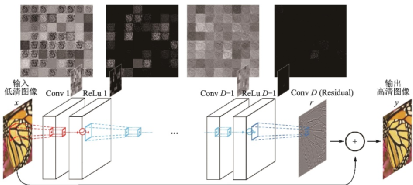
圖47??VSDR網(wǎng)絡(luò)結(jié)構(gòu)圖[94]
Fig.47??Structure of VSDR[94]
CARN[95]是NTIRE2018超分辨率挑戰(zhàn)賽的冠軍方案,該方案使用全局和局部級(jí)聯(lián),將ResNet的殘差塊替換成級(jí)聯(lián)模塊和1×11×1卷積模塊組合,并提出了一種殘差?E模塊,可以提升CARN的效率。CARN的改進(jìn)如圖48所示,其局部級(jí)聯(lián)模塊如圖49所示。
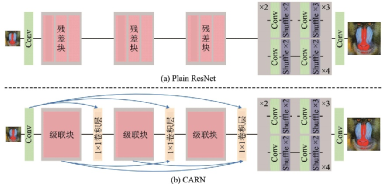
圖48??CARN對(duì)于ResNet的改進(jìn)[95]
Fig.48??Improvement of CARN based on ResNet[95]
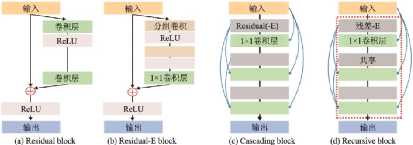
圖49??殘差-E模塊與其他常見模塊的對(duì)比[95]
Fig.49??Comparison between residual-E block and other common blocks[95]
EDVR[96]是商湯科技2019年提出的一種用于視頻修復(fù)的通用框架,在NITRE 2019 的4個(gè)賽道中均以較大的優(yōu)勢(shì)獲得了冠軍。視頻修復(fù)任務(wù)包括超分辨率、去噪聲等任務(wù),早期的研究者們簡(jiǎn)單地將視頻修復(fù)視作圖像修復(fù)的延伸,幀間冗余的時(shí)間信息并沒能被充分利用。EDVR通過增強(qiáng)的可變形卷積網(wǎng)絡(luò)實(shí)現(xiàn)視頻的修復(fù)和增強(qiáng),適用于各種視頻修復(fù)任務(wù),如超分辨率、去模糊等任務(wù)。EDVR框架示意圖如圖50所示。
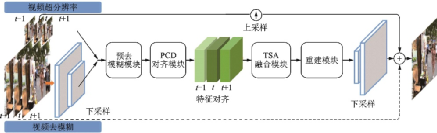
圖50??EVDR框架示意圖[96]
Fig.50??Pipeline of EDVR[96]
EDVR提出了PCD(Pyramid, cascading and deformable)對(duì)齊模塊和TSA(Temporal and spatial attention)融合模塊,其結(jié)構(gòu)如圖51所示。PCD模塊受TDAN[97]的啟發(fā),用一種金字塔結(jié)構(gòu)從低尺度到高尺度使用可變形卷積將每個(gè)相鄰幀與參考幀對(duì)齊。TSA模塊則用于在多個(gè)對(duì)齊的特征層之間融合信息,通過計(jì)算每個(gè)相鄰幀與參考幀特征之間的元素相關(guān)性引入時(shí)間注意力機(jī)制,相關(guān)系數(shù)代表每個(gè)位置上相鄰幀特征信息量的大小。在融合時(shí)間特征后進(jìn)一步應(yīng)用空間注意力機(jī)制,從而更有效地利用跨通道空間信息。
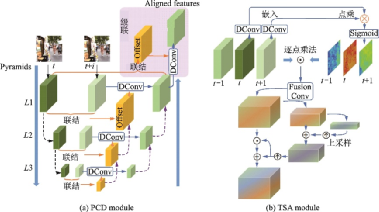
圖51??EVDR中的PCD模塊和 TSA模塊[96]
Fig.51??PCD and TSA modules in EVDR[96]
三維卷積是一種常見的利用視頻時(shí)空間信息的方法,但這種方法往往復(fù)雜度較高,限制了模型的深度。2019年提出的FSTRN[98]通過使用一種快速時(shí)空間殘差模塊將三維卷積用于視頻超分辨率任務(wù),將每個(gè)三維濾波器分解為2個(gè)維數(shù)更低的3位濾波器乘積,從而降低復(fù)雜度,實(shí)現(xiàn)更深的網(wǎng)絡(luò)和更好的性能。此外,F(xiàn)STRN還提出了一種跨空間殘差學(xué)習(xí)方法,直接連接低分辨率空間和高分辨率空間,減輕了特征融合和上采樣部分的計(jì)算負(fù)擔(dān)。FSTRN結(jié)構(gòu)如圖52所示。
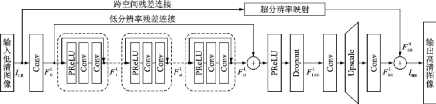
圖52??FSTRN結(jié)構(gòu)示意圖[98]
Fig.52??Pipeline of FSTRN[98]
隨著深度學(xué)習(xí)技術(shù)的興起,近20年來超分辨率領(lǐng)域發(fā)展迅速,出現(xiàn)了很多具有優(yōu)異性能的模型,但距離實(shí)際應(yīng)用還有一定的距離。圖像配準(zhǔn)技術(shù)對(duì)于多幀圖像超分辨率的重建效果至關(guān)重要,目前還沒有成熟的解決方案。另一個(gè)難點(diǎn)則是大量未知的密集計(jì)算限制了視頻超分辨率重建的計(jì)算效率,難以達(dá)到實(shí)時(shí)性的要求。超分辨率算法的魯棒性和可遷移性仍然是下階段的研究熱點(diǎn),現(xiàn)有的評(píng)價(jià)標(biāo)準(zhǔn),如均方誤差、峰值噪聲比、結(jié)構(gòu)相似性等還不能客觀地衡量重建效果,有時(shí)甚至?xí)霈F(xiàn)和人眼視覺相違背的情況。
4 神經(jīng)架構(gòu)搜索
深度學(xué)習(xí)技術(shù)在圖像分類、語(yǔ)音識(shí)別及機(jī)器翻譯等諸多領(lǐng)域上取得了舉世矚目的成功,可以自動(dòng)地學(xué)習(xí)數(shù)據(jù)信息,讓研究人員擺脫特征工程,這離不開GoogLeNet、ResNet等經(jīng)典的深度神經(jīng)網(wǎng)絡(luò)模型。然而一個(gè)具有優(yōu)異性能的網(wǎng)絡(luò)結(jié)構(gòu)往往需要花費(fèi)研究人員大量的時(shí)間資金投入,同時(shí)需要具備扎實(shí)的專業(yè)知識(shí)和豐富的經(jīng)驗(yàn)。因此人們開始研究讓機(jī)器代替人類,根據(jù)數(shù)據(jù)集和算法自動(dòng)設(shè)計(jì)網(wǎng)絡(luò)結(jié)構(gòu)。神經(jīng)架構(gòu)搜索技術(shù)(Neural architecture search,NAS)設(shè)計(jì)的模型如今已經(jīng)在很多任務(wù)上取得了超過人工設(shè)計(jì)深度模型的性能,如圖像分割領(lǐng)域的Auto?DeepLab[99],目標(biāo)檢測(cè)領(lǐng)域的NAS?FPN[100]。神經(jīng)架構(gòu)搜索技術(shù)是機(jī)器學(xué)習(xí)自動(dòng)化(Automated machine learning,AutoML)的子領(lǐng)域,代表了機(jī)器學(xué)習(xí)未來發(fā)展的方向。神經(jīng)架構(gòu)搜索技術(shù)的流程如圖53所示,首先從一個(gè)搜索空間中通過某種策略搜索候選網(wǎng)絡(luò)架構(gòu),然后對(duì)其精度、速度等指標(biāo)進(jìn)行評(píng)估,通過迭代不斷優(yōu)化直到找到最優(yōu)的網(wǎng)絡(luò)架構(gòu)。
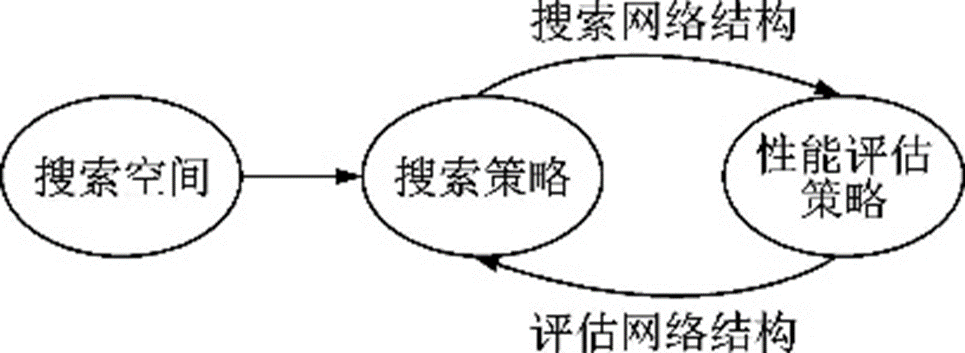
圖53??神經(jīng)架構(gòu)搜索流程圖
Fig.53??Pipeline of NAS
搜索空間內(nèi)定義了優(yōu)化問題的變量,如網(wǎng)絡(luò)架構(gòu)參數(shù)和超參數(shù),這些變量決定了模型的性能。常見的網(wǎng)絡(luò)架構(gòu)有鏈?zhǔn)浇Y(jié)構(gòu)和分支結(jié)構(gòu)等,每一個(gè)節(jié)點(diǎn)的網(wǎng)絡(luò)架構(gòu)參數(shù)包括卷積層、池化層和激活函數(shù)等,超參數(shù)包括卷積的尺寸、步長(zhǎng)、加法或連結(jié)等。典型的網(wǎng)絡(luò)架構(gòu)[101]如圖54所示。
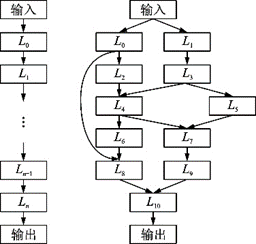
圖54??網(wǎng)絡(luò)架構(gòu)[101]
Fig.54??Network architecture[101]
搜索策略被用于探索神經(jīng)架構(gòu)空間,常見的策略包括隨機(jī)搜索、貝葉斯優(yōu)化、遺傳算法、強(qiáng)化學(xué)習(xí)[102?103]和梯度算法等,其中強(qiáng)化學(xué)習(xí)、遺傳算法及梯度算法是目前主流的搜索策略。在性能評(píng)估時(shí),由于訓(xùn)練和驗(yàn)證的時(shí)間成本較高,因此常常需要采用評(píng)估策略降低評(píng)估成本,如減少迭代次數(shù)、在訓(xùn)練集的子集上訓(xùn)練、減少卷積核數(shù)量等,但這些策略往往會(huì)導(dǎo)致一些偏差,可能會(huì)對(duì)最終的優(yōu)劣次序產(chǎn)生影響。更高級(jí)的策略包括權(quán)重共享、通過迭代時(shí)的表現(xiàn)推斷最終性能以及通過模塊預(yù)測(cè)網(wǎng)絡(luò)性能等方法。
DARTS[104]是第一個(gè)基于連續(xù)松弛的搜索空間的神經(jīng)網(wǎng)絡(luò)架構(gòu)技術(shù)。早期傳統(tǒng)的NAS方法如NasNet[105]、PNAS[106]和ENAS[107]等大多在離散不可微的搜索空間上應(yīng)用強(qiáng)化學(xué)習(xí)、進(jìn)化算法等搜索策略,由于搜索空間內(nèi)待搜索的參數(shù)不可導(dǎo),因此一個(gè)性能優(yōu)異的模型往往需要耗費(fèi)大量的計(jì)算資源和時(shí)間成本。事實(shí)上,當(dāng)時(shí)的研究者們將神經(jīng)架構(gòu)搜索技術(shù)視為一個(gè)在離散空間上的黑箱優(yōu)化問題,每次架構(gòu)的迭代優(yōu)化都需要性能評(píng)估,效率十分低下。而DARTS使用了松弛連續(xù)的結(jié)構(gòu)表示,使用梯度下降優(yōu)化網(wǎng)絡(luò)在驗(yàn)證集上的性能,實(shí)現(xiàn)了端到端的網(wǎng)絡(luò)搜索,大大減少了迭代次數(shù),把搜索時(shí)間從數(shù)千個(gè)GPU日降低到數(shù)個(gè)GPU日。
DARTS流程如圖55所示。其中:圖(a)表示邊上的初始未知操作;圖(b)在每條邊上放置候選操作的組合,連續(xù)松弛搜索空間,不斷放寬搜索條件;圖(c)通過解決一個(gè)雙層規(guī)劃問題聯(lián)合優(yōu)化混合概率與網(wǎng)絡(luò)權(quán)重;圖(d)用學(xué)到的混合概率求得最終的網(wǎng)絡(luò)架構(gòu)。DARTS是一種簡(jiǎn)單的NAS方法,適用于CNN和RNN,在CIFAR?10數(shù)據(jù)集[108]上用4個(gè)GPU日達(dá)到了2.76%的測(cè)試誤差,參數(shù)量?jī)H有330萬(wàn)個(gè);在PTB數(shù)據(jù)集[109]上用1個(gè)GPU日以2 300萬(wàn)個(gè)的參數(shù)量達(dá)到了55.7%的測(cè)試?yán)Щ蠖龋_(dá)到了當(dāng)時(shí)的最好性能。在CIFAR?10數(shù)據(jù)集上搜索出來的模型架構(gòu)在ImageNet[19]數(shù)據(jù)集上以470萬(wàn)個(gè)的參數(shù)量達(dá)到8.7%的top?5錯(cuò)誤率,在PTB數(shù)據(jù)集上搜索出來的模型架構(gòu)在WikiText?2數(shù)據(jù)集[110]上以3 300萬(wàn)個(gè)的參數(shù)量達(dá)到69.6%的困惑度,優(yōu)于很多手工設(shè)計(jì)的輕量化模型。
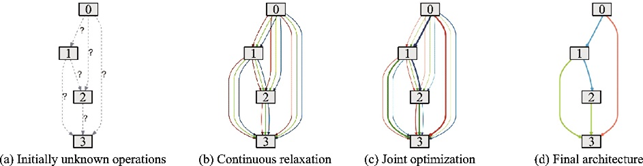
圖55??DARTS流程示意圖[104]
Fig.55??Pipeline of DARTS[104]
基于DARTS,一系列改進(jìn)算法被相繼提出。在DARTS中,搜索在一個(gè)有8個(gè)單元的網(wǎng)絡(luò)上進(jìn)行,搜索出來的架構(gòu)通過堆疊在一個(gè)具有20個(gè)單元的網(wǎng)絡(luò)上被評(píng)估,但深度網(wǎng)絡(luò)和淺層網(wǎng)絡(luò)的結(jié)構(gòu)往往不同。例如,在代理數(shù)據(jù)集(如CIFAR?10數(shù)據(jù)集)上搜索出來的網(wǎng)絡(luò)架構(gòu)可能在目標(biāo)數(shù)據(jù)集(如ImageNet數(shù)據(jù)集)上表現(xiàn)不理想。2019年華為諾亞方舟實(shí)驗(yàn)室提出P?DARTS[111],針對(duì)這一問題(被稱為Depth Gap)提出了一種漸進(jìn)式搜索的方法,如圖56所示。搜索網(wǎng)絡(luò)的深度從最初的5個(gè)單元增加到中期的11個(gè)和后期的17個(gè),而候選操作的數(shù)量(用不同的顏色表示)相應(yīng)地從5個(gè)減少到4個(gè)和2個(gè)。在上一階段得分最低的操作將被丟棄,最后結(jié)合分?jǐn)?shù)和可能的附加規(guī)則確定最終架構(gòu)[111]。

圖56??P-DARTS流程示意圖[111]
Fig.56??Pipeline of P-DARTS[111]
2019年MIT提出ProxylessNAS[112],針對(duì)DARTS只能在小型代理數(shù)據(jù)集上搜索而在大型數(shù)據(jù)集上則會(huì)出現(xiàn)顯存爆炸的問題提出了無代理神經(jīng)架構(gòu)搜索技術(shù),在訓(xùn)練時(shí)二值化路徑,用和DARTS雙層規(guī)劃類似的思想聯(lián)合訓(xùn)練權(quán)重參數(shù)和架構(gòu)參數(shù),從而達(dá)到降低顯存的目的,并首次提出針對(duì)不同的硬件平臺(tái)搜索滿足特定時(shí)延的神經(jīng)網(wǎng)絡(luò)架構(gòu)方法。ProxylessNAS不再采用搜索單元然后堆疊達(dá)到更深網(wǎng)絡(luò)的方法,而是選擇主干網(wǎng)絡(luò),如MobileNet[41]、ShuffleNet[42]等。ProxylessNAS在CIFAR?10數(shù)據(jù)集上以僅570萬(wàn)個(gè)的參數(shù)量達(dá)到2.08%的測(cè)試誤差。ProxylessNAS示意圖如圖57所示。
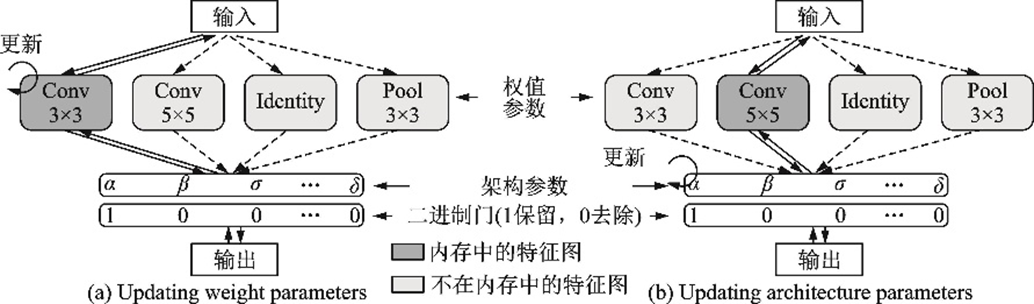
圖57??ProxylessNAS示意圖[112]
Fig.57??Pipeline of ProxylessNAS[112]
當(dāng)?shù)螖?shù)過大后,DARTS設(shè)計(jì)出的網(wǎng)絡(luò)架構(gòu)會(huì)包含很多跳接結(jié)構(gòu),使得性能變得很差,稱為DARTS的坍塌。2020年諾亞方舟實(shí)驗(yàn)室提出的DARTS+[113]通過引入早停機(jī)制,即當(dāng)一個(gè)正常單元出現(xiàn)2個(gè)或2個(gè)以上的跳接結(jié)構(gòu)時(shí)就停止搜索,縮短了DARTS搜索的時(shí)間,極大地提高了DARTS的性能,其示意圖如圖58所示。
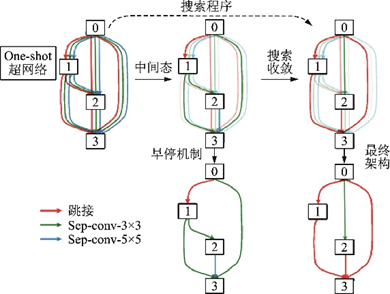
圖58??DARTS+中的早停機(jī)制示意圖[113]
Fig.58??Early Stopping in DARTS+[113]
2020年商湯研究院提出的隨機(jī)神經(jīng)架構(gòu)搜索SNAS[114]也是一種可微的端到端方法,但與DARTS相比,SNAS將NAS重新表述為在一個(gè)單元中搜索空間的聯(lián)合分布參數(shù)優(yōu)化問題,直接優(yōu)化損失函數(shù),偏差更小。在同一輪反向傳播中SNAS同時(shí)訓(xùn)練操作參數(shù)和架構(gòu)參數(shù),并提出了一種新的搜索梯度。相比基于強(qiáng)化學(xué)習(xí)的神經(jīng)架構(gòu)搜索技術(shù),SNAS優(yōu)化相同的目標(biāo)函數(shù),但更高效地只使用訓(xùn)練損失作為獎(jiǎng)勵(lì)。
PC?DARTS[115]是華為諾亞方舟實(shí)驗(yàn)室2020年提出的NAS技術(shù),在P?DARTS[111]的基礎(chǔ)上設(shè)計(jì)了部分通道連接機(jī)制,每次只有一部分通道進(jìn)行操作搜索,這節(jié)省了訓(xùn)練需要的顯存,減少了計(jì)算量,并采用邊正則化降低由于操作搜索不全造成的不確定性。PC?DARTS在CIFAR?10數(shù)據(jù)集[108]上用0.1個(gè)GPU日達(dá)到了2.57%的測(cè)試誤差,參數(shù)量?jī)H有360萬(wàn)個(gè);在ImageNet數(shù)據(jù)集[19]上用3.8個(gè)GPU日以530萬(wàn)個(gè)的參數(shù)量達(dá)到了7.3%的top?5錯(cuò)誤率,取得了更快更好的搜索效果。PC?DARTS結(jié)構(gòu)如圖59所示。
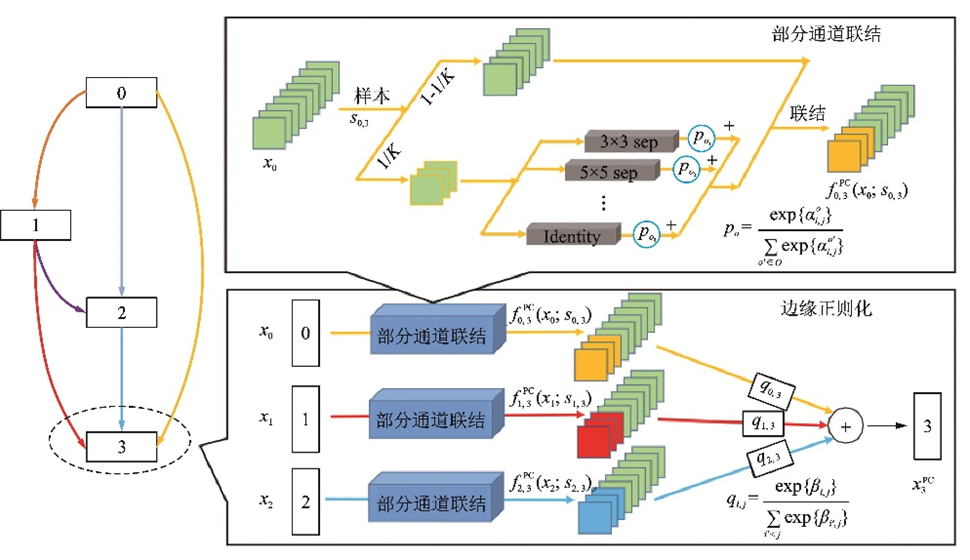
圖59??PC-DARTS結(jié)構(gòu)示意圖[115]
Fig.59??Structure of PC-DARTS[115]
當(dāng)前的神經(jīng)架構(gòu)搜索技術(shù)大多被用于圖像分類任務(wù),這促使許多研究人員試圖設(shè)計(jì)出更好的人工網(wǎng)絡(luò)。但一方面由于搜索空間的定義被局限在現(xiàn)有的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)經(jīng)驗(yàn)中,使得NAS設(shè)計(jì)出的網(wǎng)絡(luò)很難與人工網(wǎng)絡(luò)有本質(zhì)上的區(qū)別。另一方面,NAS技術(shù)設(shè)計(jì)的網(wǎng)絡(luò)可解釋性很差,由于研究人員采用的數(shù)據(jù)增強(qiáng)、搜索空間、訓(xùn)練方法及正則化策略等方法常常不同,這使得NAS設(shè)計(jì)出的架構(gòu)很難被復(fù)現(xiàn),不同網(wǎng)絡(luò)架構(gòu)的性能也難以比較。由此可見,神經(jīng)架構(gòu)搜索領(lǐng)域仍然存在很多挑戰(zhàn),如何解決這些問題將會(huì)是下一階段的熱門研究方向之一。
5 結(jié)束語(yǔ)
深度學(xué)習(xí)技術(shù)近年來在計(jì)算機(jī)視覺中的目標(biāo)檢測(cè)、圖像分割、超分辨率和模型壓縮等任務(wù)上都取得了卓越的成績(jī),充分證明了它的價(jià)值和潛力。然而深度學(xué)習(xí)領(lǐng)域仍然有不少難題無法解決,如對(duì)數(shù)據(jù)的依賴性強(qiáng)、模型難以在不同領(lǐng)域之間直接遷移、深度學(xué)習(xí)模型的可解釋性不強(qiáng)等,如何攻克這些難題將是下一階段的發(fā)展方向。為了追求極致的性能,很多科技巨頭投入了巨大的人力財(cái)力搭建巨型模型,如OpenAI發(fā)布的擁有1 750億個(gè)參數(shù)的GPT?3,谷歌發(fā)布的擁有1.6萬(wàn)億個(gè)參數(shù)的Switch Transformer,快手發(fā)布的擁有1.9萬(wàn)億個(gè)參數(shù)的推薦精排模型,這些模型需要大量的訓(xùn)練時(shí)間和計(jì)算資源,如何設(shè)計(jì)計(jì)算硬件、系統(tǒng)和算法來加速訓(xùn)練是一項(xiàng)新的挑戰(zhàn)。深度學(xué)習(xí)技術(shù)嚴(yán)重依賴大規(guī)模帶標(biāo)簽的數(shù)據(jù)集,因此無監(jiān)督學(xué)習(xí)技術(shù)、自監(jiān)督技術(shù),例如表示學(xué)習(xí)、預(yù)訓(xùn)練模型等,仍然是重要的研究方向。同時(shí)深度學(xué)習(xí)技術(shù)帶來的安全隱患也引起了重視,如何在保護(hù)用戶隱私的前提下優(yōu)化分布式訓(xùn)練是另一個(gè)具有潛力的研究方向。
本文僅做學(xué)術(shù)分享,如有侵權(quán),請(qǐng)聯(lián)系刪文。