
綜述 | 計(jì)算機(jī)視覺(jué)中的小樣本學(xué)習(xí)
點(diǎn)擊左上方藍(lán)字關(guān)注我們

前言

如今,在使用數(shù)十億張圖像來(lái)解決特定任務(wù)方面,計(jì)算機(jī)可以做到超過(guò)人類(lèi)。盡管如此,在現(xiàn)實(shí)世界中,很少能構(gòu)建或找到包含這么多樣本的數(shù)據(jù)集。
我們?nèi)绾慰朔@個(gè)問(wèn)題? 在計(jì)算機(jī)視覺(jué)領(lǐng)域,我們可以使用數(shù)據(jù)增強(qiáng) (DA),或者收集和標(biāo)記額外的數(shù)據(jù)。DA 是一個(gè)強(qiáng)大的技術(shù),可能是解決方案的重要組成部分。標(biāo)記額外的樣本是一項(xiàng)耗時(shí)且昂貴的任務(wù),但它確實(shí)提供了更好的結(jié)果。
如果數(shù)據(jù)集真的很小,這兩種技術(shù)可能都無(wú)濟(jì)于事。 想象一個(gè)任務(wù),我們需要建立一個(gè)分類(lèi),每個(gè)類(lèi)只有一兩個(gè)樣本,而每個(gè)樣本都非常難以找到。
這將需要?jiǎng)?chuàng)新的方法。小樣本學(xué)習(xí)(Few-Shot Learning, FSL)就是其中之一。
在本文中,我們將介紹:
什么是小樣本學(xué)習(xí)——定義、目的和 FSL 問(wèn)題示例
小樣本學(xué)習(xí)變體——N-Shot Learning、Few-shot Learning、One-Shot Learning、Zero-Shot Learning.
小樣本學(xué)習(xí)方法——Meta-Learning、Data-level、Parameter-level
元學(xué)習(xí)算法——定義、度量學(xué)習(xí)、基于梯度的元學(xué)習(xí)
Few-Shot圖像分類(lèi)算法——與模型無(wú)關(guān)的元學(xué)習(xí)、匹配、原型和關(guān)系網(wǎng)絡(luò)
Few-Shot目標(biāo)檢測(cè) – YOLOMAML
什么是小樣本學(xué)習(xí)?
Few-Shot Learning(以下簡(jiǎn)稱(chēng)FSL)是機(jī)器學(xué)習(xí)的一個(gè)子領(lǐng)域。在只有少數(shù)具有監(jiān)督信息的訓(xùn)練樣本情況下,訓(xùn)練模型實(shí)現(xiàn)對(duì)新數(shù)據(jù)進(jìn)行分類(lèi)。
FSL 是一個(gè)相當(dāng)年輕的領(lǐng)域,需要更多的研究和完善。計(jì)算機(jī)視覺(jué)模型可以在相對(duì)較少的訓(xùn)練樣本下很好地工作。在本文中,我們將重點(diǎn)關(guān)注計(jì)算機(jī)視覺(jué)中的 FSL。
例如:假設(shè)我們?cè)卺t(yī)療保健行業(yè)工作,在通過(guò) X 射線(xiàn)照片對(duì)骨骼疾病進(jìn)行分類(lèi)時(shí)遇到問(wèn)題。
一些罕見(jiàn)的病理可能缺乏足夠的圖像用于訓(xùn)練集中。這正是可以通過(guò)構(gòu)建 FSL 分類(lèi)器解決的問(wèn)題類(lèi)型。
小樣本學(xué)習(xí)變體
根據(jù)FSL的不同變化和極端情況可以分為四種類(lèi)型:
N-Shot Learning (NSL)
Few-shot Learning (FSL)
One-Shot Learning (OSL)
Zero-Shot Learning (ZSL)
當(dāng)我們談?wù)?/span> FSL 時(shí),我們通常指的是 N-way-K-Shot-classification。
N 代表類(lèi)別的數(shù)量,K 代表每個(gè)類(lèi)別要訓(xùn)練的樣本數(shù)量。
N-Shot 學(xué)習(xí)被視為比所有其他概念更廣泛的概念。這意味著,F(xiàn)ew-Shot、One-Shot 和 Zero-Shot Learning 是 NSL 的子領(lǐng)域。
Zero-Shot Learning (ZSL)
Zero-Shot Learning 的目標(biāo)是在沒(méi)有任何訓(xùn)練樣本的情況下對(duì)看不見(jiàn)的類(lèi)進(jìn)行分類(lèi)。
這可能看起來(lái)有點(diǎn)牛逼,可以這樣想:你能在沒(méi)有看到物體的情況下對(duì)它進(jìn)行分類(lèi)嗎? 如果你對(duì)一個(gè)對(duì)象、它的外觀、屬性和功能有一個(gè)大致的了解,那應(yīng)該不成問(wèn)題。這是在進(jìn)行 ZSL 時(shí)使用的方法,根據(jù)當(dāng)前的趨勢(shì),零樣本學(xué)習(xí)將很快變得更加有效。
One-Shot和Few-Shot
在One-Shot Learning中,每個(gè)類(lèi)只有一個(gè)樣本。Few-Shot 每個(gè)類(lèi)有 2 到 5 個(gè)樣本,使其成為更靈活的 OSL 版本。
當(dāng)我們談?wù)撜w概念時(shí),我們使用Few-Shot Learning術(shù)語(yǔ)。但是這個(gè)領(lǐng)域還很年輕,所以人們會(huì)以不同的方式使用這些術(shù)語(yǔ)。
小樣本學(xué)習(xí)方法
首先,讓我們定義一個(gè) N-way-K-Shot-分類(lèi)問(wèn)題。
假定一個(gè)訓(xùn)練集,包括N 類(lèi)標(biāo)簽,每類(lèi)K個(gè)標(biāo)記圖像(少量,每類(lèi)少于十個(gè)樣本),Q張測(cè)試圖片。
我們想在 N 個(gè)類(lèi)別中對(duì) Q 張測(cè)試圖片進(jìn)行分類(lèi)。 訓(xùn)練集中的 N * K 個(gè)樣本是我們僅有的樣本。這里的主要問(wèn)題是沒(méi)有足夠的訓(xùn)練數(shù)據(jù)。
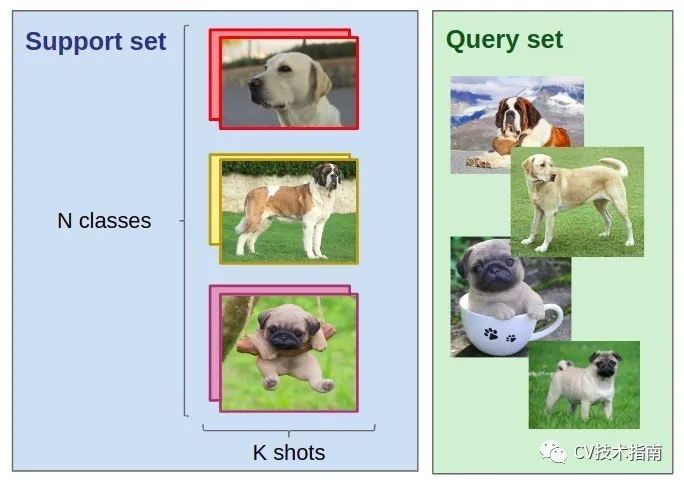
FSL 任務(wù)的第一步是從其他類(lèi)似問(wèn)題中獲得經(jīng)驗(yàn)。這就是為什么少樣本學(xué)習(xí)被描述為元學(xué)習(xí)問(wèn)題的原因。
在傳統(tǒng)的分類(lèi)問(wèn)題中,我們嘗試從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)如何分類(lèi),并使用測(cè)試數(shù)據(jù)進(jìn)行評(píng)估。在元學(xué)習(xí)中,我們學(xué)習(xí)如何學(xué)習(xí)給定一組訓(xùn)練數(shù)據(jù)進(jìn)行分類(lèi)。 我們將一組分類(lèi)問(wèn)題用于其他不相關(guān)的集合。
在解決 FSL 問(wèn)題時(shí),通常考慮兩種方法:
數(shù)據(jù)級(jí)方法 (Data-level approach,DLA)
參數(shù)級(jí)方法 (Parameter-level approach,PLA)
數(shù)據(jù)級(jí)方法
這個(gè)方法真的很簡(jiǎn)單。 它基于這樣一個(gè)概念:如果沒(méi)有足夠的數(shù)據(jù)來(lái)構(gòu)建可靠的模型并避免過(guò)度擬合和欠擬合,只需要簡(jiǎn)單地添加更多數(shù)據(jù)。
這就是為什么通過(guò)使用來(lái)自大型基礎(chǔ)數(shù)據(jù)集的附加信息來(lái)解決許多 FSL 問(wèn)題的原因。基礎(chǔ)數(shù)據(jù)集的關(guān)鍵特征是它沒(méi)有在訓(xùn)練集中為Few-Show任務(wù)提供的類(lèi)。 例如,如果想對(duì)特定鳥(niǎo)類(lèi)進(jìn)行分類(lèi),基礎(chǔ)數(shù)據(jù)集可以包含許多其他鳥(niǎo)類(lèi)的圖像。
我們也可以自己產(chǎn)生更多的數(shù)據(jù)。為了達(dá)到這個(gè)目標(biāo),我們可以使用數(shù)據(jù)增強(qiáng),甚至生成對(duì)抗網(wǎng)絡(luò) (GAN)。
參數(shù)級(jí)方法
從參數(shù)級(jí)別的角度來(lái)看,Few-Shot Learning 樣本很容易過(guò)擬合,因?yàn)樗鼈?/span>t通常具有廣泛的高維空間。
為了克服這個(gè)問(wèn)題,我們應(yīng)該限制參數(shù)空間并使用正則化和適當(dāng)?shù)膿p失函數(shù)。 該模型將對(duì)有限數(shù)量的訓(xùn)練樣本具有泛化能力。
另一方面,我們可以通過(guò)將其引導(dǎo)到廣泛的參數(shù)空間來(lái)提高模型性能。 如果我們使用標(biāo)準(zhǔn)的優(yōu)化算法,由于訓(xùn)練數(shù)據(jù)量很少,它可能無(wú)法給出可靠的結(jié)果。
這就是為什么在參數(shù)級(jí)別上訓(xùn)練的模型以在參數(shù)空間中找到最佳路線(xiàn)以提供最佳預(yù)測(cè)結(jié)果。正如我們上面已經(jīng)提到的,這種技術(shù)稱(chēng)為元學(xué)習(xí)。
元學(xué)習(xí)算法
在經(jīng)典范式中,當(dāng)我們有一個(gè)特定的任務(wù)時(shí),算法正在學(xué)習(xí)它的任務(wù)性能是否隨著經(jīng)驗(yàn)而提高。在元學(xué)習(xí)范式中,我們有一組任務(wù)。算法正在學(xué)會(huì)去學(xué)習(xí)它在每個(gè)任務(wù)上的性能是否隨著經(jīng)驗(yàn)和任務(wù)數(shù)量的增加而提高。該算法稱(chēng)為元學(xué)習(xí)算法。
假設(shè)我們有一個(gè)測(cè)試任務(wù) TEST。我們將在一批訓(xùn)練任務(wù) TRAIN 上訓(xùn)練我們的元學(xué)習(xí)算法。從嘗試解決 TRAIN 任務(wù)中獲得的訓(xùn)練經(jīng)驗(yàn)將用于解決 TEST 任務(wù)。
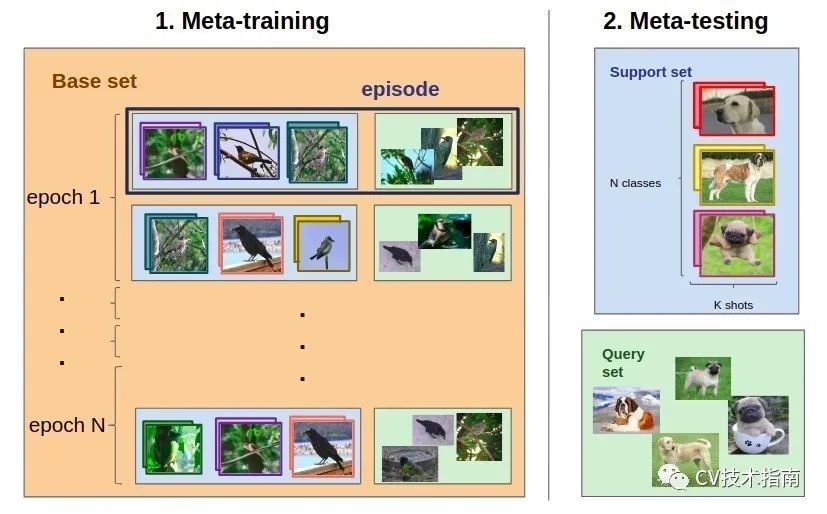
解決 FSL 任務(wù)有一系列步驟。想象一下我們之前提到的分類(lèi)問(wèn)題。首先,我們需要選擇一個(gè)基礎(chǔ)數(shù)據(jù)集。選擇基礎(chǔ)數(shù)據(jù)集至關(guān)重要。
現(xiàn)在我們有 N-way-K-Shot 分類(lèi)問(wèn)題(讓我們將其命名為 TEST)和一個(gè)大型基礎(chǔ)數(shù)據(jù)集,我們將用作元學(xué)習(xí)訓(xùn)練集 (TRAIN)。
整個(gè)元訓(xùn)練過(guò)程將在有限的episode(情節(jié),電視劇集)下完成。
從 TRAIN 中,我們對(duì)每個(gè)類(lèi)別的 N 個(gè)類(lèi)別和 K 個(gè)支持集圖像以及 Q張測(cè)試圖像進(jìn)行采樣。這樣,我們就形成了一個(gè)類(lèi)似于我們最終的 TEST 任務(wù)的分類(lèi)任務(wù)。
在每個(gè)episode結(jié)束時(shí),訓(xùn)練模型的參數(shù)以最大化測(cè)試集中 Q 圖像的準(zhǔn)確性。這是我們的模型學(xué)習(xí)解決看不見(jiàn)的分類(lèi)問(wèn)題的能力的地方。
模型的整體效率是通過(guò)其在 TEST 分類(lèi)任務(wù)上的準(zhǔn)確性來(lái)衡量的。
近年來(lái),研究人員發(fā)表了許多用于解決 FSL 分類(lèi)問(wèn)題的元學(xué)習(xí)算法。所有這些都可以分為兩大類(lèi):度量學(xué)習(xí) (Metric-Learning) 和基于梯度的元學(xué)習(xí) (Gradient-Based Meta-Learning) 算法。
度量學(xué)習(xí)
當(dāng)我們談?wù)摱攘繉W(xué)習(xí)時(shí),通常指的是在目標(biāo)上學(xué)習(xí)距離函數(shù)的技術(shù)。
一般來(lái)說(shuō),度量學(xué)習(xí)算法學(xué)習(xí)比較數(shù)據(jù)樣本。 在少樣本分類(lèi)問(wèn)題的情況下,他們根據(jù)測(cè)試樣本與訓(xùn)練樣本的相似性對(duì)測(cè)試樣本進(jìn)行分類(lèi)。如果我們處理圖像,我們基本上會(huì)訓(xùn)練一個(gè)卷積神經(jīng)網(wǎng)絡(luò)來(lái)輸出圖像嵌入向量,然后與其他嵌入向量進(jìn)行比較以預(yù)測(cè)類(lèi)別。
基于梯度的元學(xué)習(xí)
對(duì)于基于梯度的方法,需要構(gòu)建一個(gè)元學(xué)習(xí)器和一個(gè)基學(xué)習(xí)器。
元學(xué)習(xí)器是一個(gè)跨集學(xué)習(xí)的模型,而基礎(chǔ)學(xué)習(xí)器是一個(gè)由元學(xué)習(xí)器在每個(gè)集內(nèi)初始化和訓(xùn)練的模型。
想象一下元訓(xùn)練的一個(gè)片段,其中包含由 N * K 個(gè)圖像訓(xùn)練集和 Q 測(cè)試集定義的一些分類(lèi)任務(wù):
1. 選擇一個(gè)元學(xué)習(xí)器模型,
2. episode(情節(jié))開(kāi)始,
3. 初始化基礎(chǔ)學(xué)習(xí)器(通常是 CNN 分類(lèi)器),
4. 在訓(xùn)練集上訓(xùn)練它(用于訓(xùn)練基礎(chǔ)學(xué)習(xí)器的確切算法由元學(xué)習(xí)器定義),
5. Base-learner 預(yù)測(cè)測(cè)試集上的類(lèi),
6. 元學(xué)習(xí)器參數(shù)根據(jù)分類(lèi)錯(cuò)誤導(dǎo)致的損失進(jìn)行訓(xùn)練,
7. 從這一點(diǎn)來(lái)看,管道可能會(huì)根據(jù)選擇的元學(xué)習(xí)器而有所不同。
Few-Shot圖像分類(lèi)算法
在本節(jié)中,我們將介紹:
模型不可知元學(xué)習(xí) (Model-Agnostic Meta-Learning, MAML)
匹配網(wǎng)絡(luò)Matching Networks
原型網(wǎng)絡(luò)Prototypical Networks
關(guān)系網(wǎng)絡(luò)Relation Networks
模型不可知元學(xué)習(xí)
MAML 基于梯度元學(xué)習(xí) (GBML) 概念。GBML 是關(guān)于元學(xué)習(xí)器從訓(xùn)練基礎(chǔ)模型和學(xué)習(xí)所有任務(wù)的共同特征表示中獲取先前經(jīng)驗(yàn)。每當(dāng)有新任務(wù)需要學(xué)習(xí)時(shí),元學(xué)習(xí)器會(huì)利用新任務(wù)帶來(lái)的少量新訓(xùn)練數(shù)據(jù)對(duì)具有其先前經(jīng)驗(yàn)的元學(xué)習(xí)器進(jìn)行一點(diǎn)微調(diào)。
不過(guò),我們不想從隨機(jī)參數(shù)初始化開(kāi)始。如果我們這樣做,我們的算法在幾次更新后將不會(huì)收斂到良好的性能。
MAML 旨在解決這個(gè)問(wèn)題。
MAML 提供了元學(xué)習(xí)器參數(shù)的良好初始化,以在僅使用少量梯度步驟的新任務(wù)上實(shí)現(xiàn)最佳快速學(xué)習(xí),同時(shí)避免使用小數(shù)據(jù)集時(shí)可能發(fā)生的過(guò)度擬合。
這是它的完成方式:
1. 元學(xué)習(xí)器在每episode(情節(jié))開(kāi)始時(shí)創(chuàng)建自己的副本 (C),
2. C 接受了這一episode的訓(xùn)練(正如我們之前討論過(guò)的,在 base-model 的幫助下),
3. C 對(duì)測(cè)試集進(jìn)行預(yù)測(cè),
4. 根據(jù)這些預(yù)測(cè)計(jì)算的損失用于更新 C,
5. 這一直持續(xù)到對(duì)所有episode進(jìn)行了訓(xùn)練。

這種技術(shù)的最大優(yōu)點(diǎn)是它被認(rèn)為與元學(xué)習(xí)器算法選擇無(wú)關(guān)。 因此,MAML 方法被廣泛用于許多需要快速適應(yīng)的機(jī)器學(xué)習(xí)算法,尤其是深度神經(jīng)網(wǎng)絡(luò)。
匹配網(wǎng)絡(luò)
匹配網(wǎng)絡(luò) (MN) 是第一個(gè)旨在解決 FSL 問(wèn)題的度量學(xué)習(xí)算法。
對(duì)于匹配網(wǎng)絡(luò)算法,需要使用大型基礎(chǔ)數(shù)據(jù)集來(lái)解決小樣本學(xué)習(xí)任務(wù)。如上所示,這個(gè)數(shù)據(jù)集被分成了幾集(episodes)。之后,對(duì)于每一集,匹配網(wǎng)絡(luò)應(yīng)用以下步驟:
1. 來(lái)自訓(xùn)練集和測(cè)試集的每個(gè)圖像都被送進(jìn) CNN,輸出embeddings,
2. 每張測(cè)試圖像使用從其embeddings到訓(xùn)練集embeddings的余弦距離的 softmax 進(jìn)行分類(lèi),
3. 結(jié)果分類(lèi)的交叉熵?fù)p失通過(guò) CNN 反向傳播。
通過(guò)這種方式,匹配網(wǎng)絡(luò)學(xué)習(xí)計(jì)算圖像嵌入。這種方法允許 MN 在沒(méi)有特定類(lèi)的先驗(yàn)知識(shí)的情況下對(duì)圖像進(jìn)行分類(lèi)。一切都是通過(guò)比較類(lèi)的不同實(shí)例來(lái)完成的。
由于每一集中的類(lèi)別不同,匹配網(wǎng)絡(luò)計(jì)算與區(qū)分類(lèi)別相關(guān)的圖像特征。相反,在標(biāo)準(zhǔn)分類(lèi)的情況下,算法學(xué)習(xí)特定于每個(gè)類(lèi)的特征。
值得一提的是,作者實(shí)際上對(duì)初始算法提出了一些改進(jìn)。例如,他們用雙向 LSTM 增強(qiáng)了他們的算法。每個(gè)圖像的嵌入取決于其他圖像的嵌入。
所有改進(jìn)方案都可以在他們的初始文章中找到。不過(guò),提高算法的性能可能會(huì)使計(jì)算時(shí)間更長(zhǎng)。
原型網(wǎng)絡(luò)
原型網(wǎng)絡(luò) (PN) 類(lèi)似于匹配網(wǎng)絡(luò)。盡管如此,仍有一些細(xì)微的差異有助于提高算法的性能。PN 實(shí)際上獲得了比 MN 更好的結(jié)果。
PN 過(guò)程本質(zhì)上是相同的,但是測(cè)試圖像的embeddings不會(huì)與訓(xùn)練集中的每個(gè)圖像embeddings進(jìn)行比較。相反,原型網(wǎng)絡(luò)提出了一種替代方法。
在PN中,你需要形成類(lèi)原型。它們基本上是通過(guò)平均來(lái)自此類(lèi)的圖像的嵌入而形成的類(lèi)嵌入。然后將測(cè)試圖像嵌入僅與這些類(lèi)原型進(jìn)行比較。
值得一提的是,在 One-Shot Learning 問(wèn)題的情況下,算法類(lèi)似于 Matching Networks。
此外,PN 使用歐幾里得距離而不是余弦距離。它被視為算法改進(jìn)的主要部分。
關(guān)系網(wǎng)絡(luò)
為構(gòu)建匹配和原型網(wǎng)絡(luò)而進(jìn)行的所有實(shí)驗(yàn)實(shí)際上導(dǎo)致了關(guān)系網(wǎng)絡(luò) (RN) 的創(chuàng)建。RN 建立在 PN 概念之上,但對(duì)算法進(jìn)行了重大更改。
距離函數(shù)不是預(yù)先定義的,而是由算法學(xué)習(xí)的。 RN 有自己的關(guān)系模塊來(lái)執(zhí)行此操作。
整體結(jié)構(gòu)如下。關(guān)系模塊放在嵌入模塊的頂部,該模塊是從輸入圖像計(jì)算嵌入和類(lèi)原型的部分。關(guān)系模塊被輸入查詢(xún)圖像與每個(gè)類(lèi)原型的嵌入的串聯(lián),并輸出每對(duì)的關(guān)系分?jǐn)?shù)。 將 Softmax 應(yīng)用于關(guān)系分?jǐn)?shù),得到一個(gè)預(yù)測(cè)。

Few-Show目標(biāo)檢測(cè)
很明顯,我們可能會(huì)在所有計(jì)算機(jī)視覺(jué)任務(wù)中遇到 FSL 問(wèn)題。
一個(gè) N-way-K-Shot 目標(biāo)檢測(cè)任務(wù)包括一個(gè)訓(xùn)練集:N個(gè)類(lèi)標(biāo)簽,對(duì)于每一類(lèi),包含至少一個(gè)屬于該類(lèi)的對(duì)象的 K 個(gè)標(biāo)記圖像,Q張測(cè)試圖片。
注意,與Few-Shot 圖像分類(lèi)問(wèn)題有一個(gè)關(guān)鍵區(qū)別,因?yàn)?/span>目標(biāo)檢測(cè)任務(wù)存在一張圖像包含屬于N 個(gè)類(lèi)別中的一個(gè)或多個(gè)的多個(gè)目標(biāo)的情況。因此可能會(huì)面臨類(lèi)不平衡問(wèn)題,因?yàn)樗惴▽?duì)每個(gè)類(lèi)的至少 K 個(gè)樣本目標(biāo)進(jìn)行訓(xùn)練。
YOLOMAML
Few-Shot目標(biāo)檢測(cè)領(lǐng)域正在迅速發(fā)展,但有效的解決方案并不多。這個(gè)問(wèn)題最穩(wěn)定的解決方案是 YOLOMAML 算法。
YOLOMAML 有兩個(gè)混合部分:YOLOv3 對(duì)象檢測(cè)架構(gòu)和 MAML 算法。
如前所述,MAML 可以應(yīng)用于多種深度神經(jīng)網(wǎng)絡(luò),這就是為什么開(kāi)發(fā)人員很容易將這兩部分結(jié)合起來(lái)。
YOLOMAML 是 MAML 算法在 YOLO 檢測(cè)器上的直接應(yīng)用。如果想了解更多信息,請(qǐng)查看官方 Github 存儲(chǔ)庫(kù)。
https://github.com/ebennequin/FewShotVision
總結(jié)
在本文中,我們已經(jīng)弄清楚了什么是Few-Shot Learning,有哪些 FSL 變體和問(wèn)題解決方法,以及可以使用哪些算法來(lái)解決圖像分類(lèi)和目標(biāo)檢測(cè) FSL 任務(wù)。
Few-Shot Learning 是一個(gè)快速發(fā)展和有前途的領(lǐng)域,但仍然非常具有挑戰(zhàn)性和未經(jīng)研究,還有很多工作要做、研究和開(kāi)發(fā)。
原文鏈接:
https://neptune.ai/blog/understanding-few-shot-learning-in-computer-vision
END
整理不易,點(diǎn)贊三連↓