
面試必備:蝦皮服務(wù)端15連問
前言
大家好,我是小富,最近有位讀者去蝦皮面試啦,分享一下面試的真題~
排序鏈表 對稱與非對稱加密算法的區(qū)別 TCP如何保證可靠性 聊聊五種IO模型 hystrix 工作原理 延時場景處理 https請求過程 聊聊事務(wù)隔離級別,以及可重復讀實現(xiàn)原理 聊聊索引在哪些場景下會失效? 什么是虛擬內(nèi)存 排行榜的實現(xiàn),比如高考成績排序 分布式鎖實現(xiàn) 聊聊零拷貝 聊聊synchronized 分布式ID生成方案
1. 排序鏈表
給你鏈表的頭結(jié)點head ,請將其按升序排列并返回排序后的鏈表 。
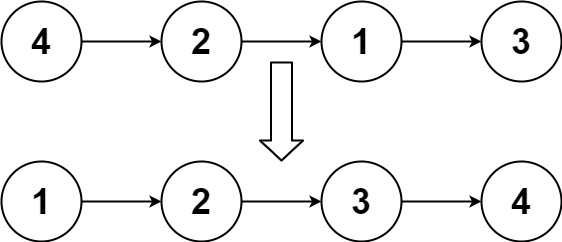
實例1:
輸入:head =?[4,2,1,3]
輸出:[1,2,3,4]
實例2:
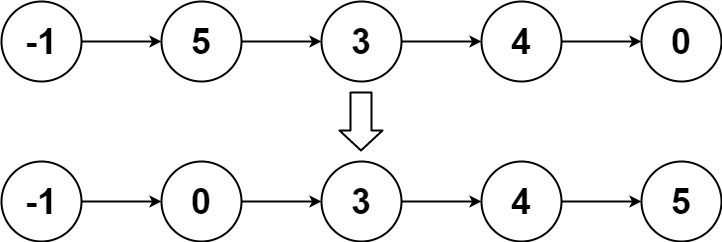
輸入:head =?[-1,5,3,4,0]
輸出:[-1,0,3,4,5]
這道題可以用雙指針+歸并排序算法解決,主要以下四個步驟
完整代碼如下:
class?Solution?{
????public?ListNode?sortList(ListNode?head)?{
????????//如果鏈表為空,或者只有一個節(jié)點,直接返回即可,不用排序
????????if?(head?==?null?||?head.next?==?null)
????????????return?head;
????????
????????//快慢指針移動,以尋找到中間節(jié)點
????????ListNode?slow?=?head;
????????ListNode?fast?=?head;
????????while(fast.next!=null?&&?fast.next.next?!=null){
??????????fast?=?fast.next.next;
??????????slow?=?slow.next;
????????}
????????//找到中間節(jié)點,slow節(jié)點的next指針,指向mid
????????ListNode?mid?=?slow.next;
????????//切斷鏈表
????????slow.next?=?null;
????????
????????//排序左子鏈表
????????ListNode?left?=?sortList(head);
????????//排序左子鏈表
????????ListNode?right?=?sortList(mid);
????????
????????//合并鏈表
????????return?merge(left,right);
????}
????
????public?ListNode?merge(ListNode?left,?ListNode?right)?{
???????ListNode?head?=?new?ListNode(0);
???????ListNode?temp?=?head;
???????while?(left?!=?null?&&?right?!=?null)?{
???????????if?(left.val?<=?right.val)?{
????????????????temp.next?=?left;
????????????????left?=?left.next;
????????????}?else?{
????????????????temp.next?=?right;
????????????????right?=?right.next;
????????????}
????????????temp?=?temp.next;
????????}
????????if?(left?!=?null)?{
????????????temp.next?=?left;
????????}?else?if?(right?!=?null)?{
????????????temp.next?=?right;
????????}
????????return?head.next;
????}
}
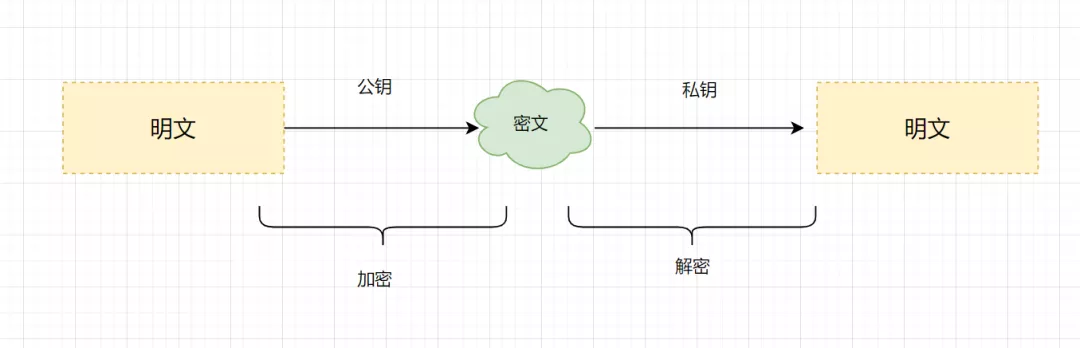
2.對稱與非對稱加密算法的區(qū)別
先復習一下相關(guān)概念:
明文:指沒有經(jīng)過加密的信息/數(shù)據(jù)。 密文:明文被加密算法加密之后,會變成密文,以確保數(shù)據(jù)安全。 密鑰:是一種參數(shù),它是在明文轉(zhuǎn)換為密文或?qū)⒚芪霓D(zhuǎn)換為明文的算法中輸入的參數(shù)。密鑰分為對稱密鑰與非對稱密鑰。 加密:將明文變成密文的過程。 解密:將密文還原為明文的過程。
對稱加密算法:加密和解密使用相同密鑰的加密算法。常見的對稱加密算法有AES、3DES、DES、RC5、RC6等。

非對稱加密算法:非對稱加密算法需要兩個密鑰(公開密鑰和私有密鑰)。公鑰與私鑰是成對存在的,如果用公鑰對數(shù)據(jù)進行加密,只有對應的私鑰才能解密。主要的非對稱加密算法有:RSA、Elgamal、DSA、D-H、ECC。
3. TCP如何保證可靠性
首先,TCP的連接是基于三次握手,而斷開則是四次揮手。確保連接和斷開的可靠性。 其次,TCP的可靠性,還體現(xiàn)在有狀態(tài);TCP會記錄哪些數(shù)據(jù)發(fā)送了,哪些數(shù)據(jù)被接受了,哪些沒有被接受,并且保證數(shù)據(jù)包按序到達,保證數(shù)據(jù)傳輸不出差錯。 再次,TCP的可靠性,還體現(xiàn)在可控制。它有報文校驗、ACK應答、超時重傳(發(fā)送方)、失序數(shù)據(jù)重傳(接收方)、丟棄重復數(shù)據(jù)、流量控制(滑動窗口)和擁塞控制等機制。
4. 聊聊五種IO模型
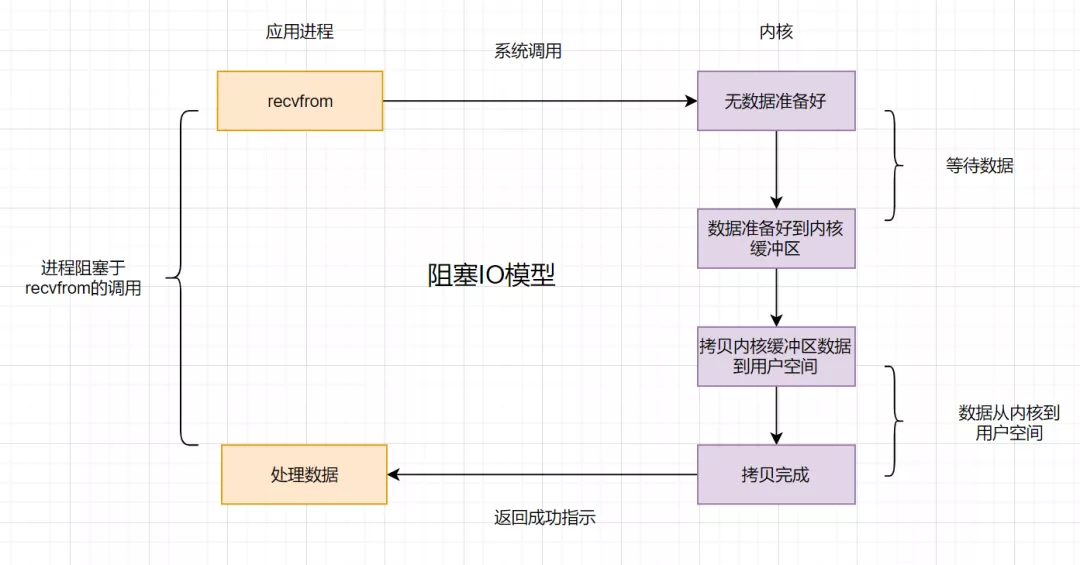
4.1 阻塞IO 模型
假設(shè)應用程序的進程發(fā)起IO調(diào)用,但是如果內(nèi)核的數(shù)據(jù)還沒準備好的話,那應用程序進程就一直在阻塞等待,一直等到內(nèi)核數(shù)據(jù)準備好了,從內(nèi)核拷貝到用戶空間,才返回成功提示,此次IO操作,稱之為阻塞IO。
4.2 非阻塞IO模型
如果內(nèi)核數(shù)據(jù)還沒準備好,可以先返回錯誤信息給用戶進程,讓它不需要等待,而是通過輪詢的方式再來請求。這就是非阻塞IO,流程圖如下:

4.3 IO多路復用模型
IO多路復用之select
應用進程通過調(diào)用select函數(shù),可以同時監(jiān)控多個fd,在select函數(shù)監(jiān)控的fd中,只要有任何一個數(shù)據(jù)狀態(tài)準備就緒了,select函數(shù)就會返回可讀狀態(tài),這時應用進程再發(fā)起recvfrom請求去讀取數(shù)據(jù)。

select有幾個缺點:
最大連接數(shù)有限,在Linux系統(tǒng)上一般為1024。 select函數(shù)返回后,是通過遍歷fdset,找到就緒的描述符fd。
IO多路復用之epoll
為了解決select存在的問題,多路復用模型epoll誕生,它采用事件驅(qū)動來實現(xiàn),流程圖如下:
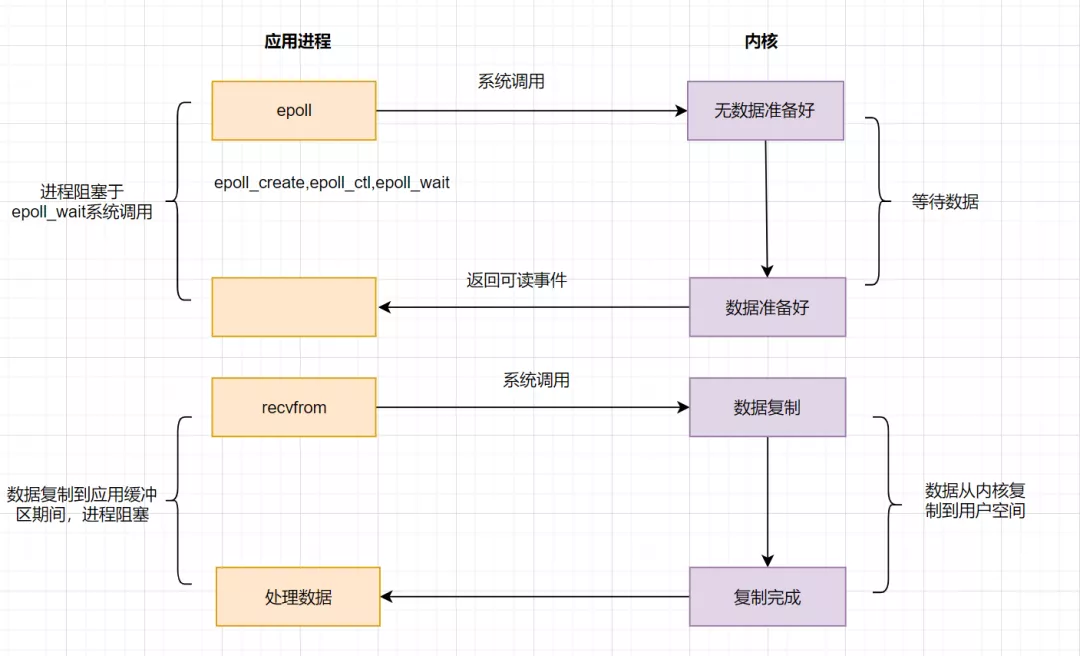
epoll先通過epoll_ctl()來注冊一個fd(文件描述符),一旦基于某個fd就緒時,內(nèi)核會采用回調(diào)機制,迅速激活這個fd,當進程調(diào)用epoll_wait()時便得到通知。這里去掉了遍歷文件描述符的坑爹操作,而是采用監(jiān)聽事件回調(diào)的機制。這就是epoll的亮點。
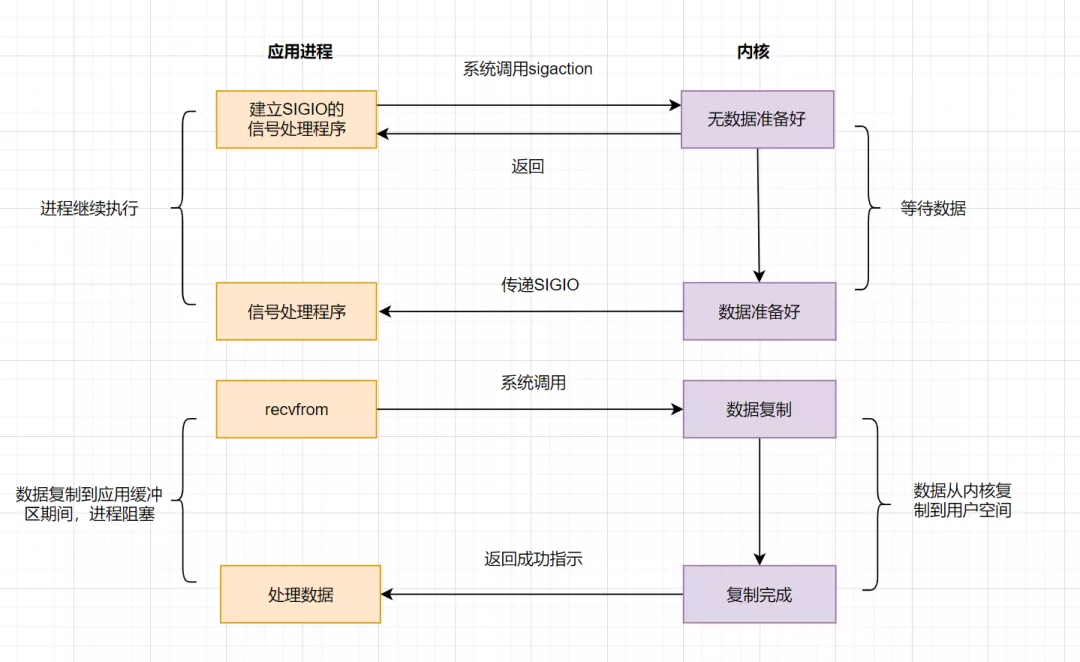
4.4 IO模型之信號驅(qū)動模型
信號驅(qū)動IO不再用主動詢問的方式去確認數(shù)據(jù)是否就緒,而是向內(nèi)核發(fā)送一個信號(調(diào)用sigaction的時候建立一個SIGIO的信號),然后應用用戶進程可以去做別的事,不用阻塞。當內(nèi)核數(shù)據(jù)準備好后,再通過SIGIO信號通知應用進程,數(shù)據(jù)準備好后的可讀狀態(tài)。應用用戶進程收到信號之后,立即調(diào)用recvfrom,去讀取數(shù)據(jù)。
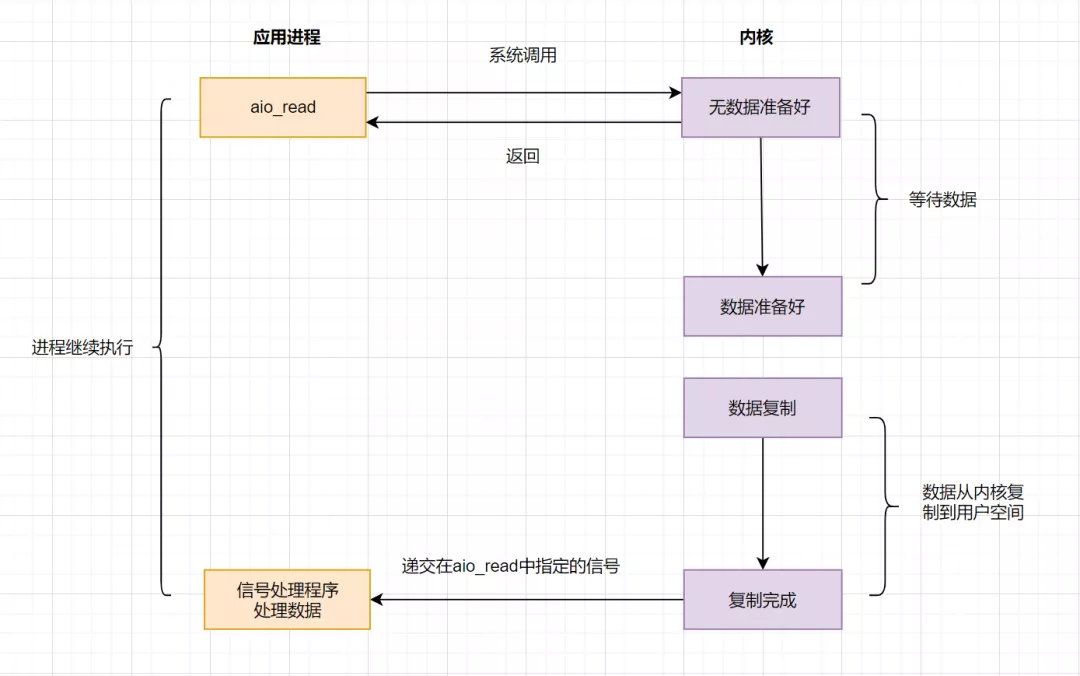
4.5 IO 模型之異步IO(AIO)
AIO實現(xiàn)了IO全流程的非阻塞,就是應用進程發(fā)出系統(tǒng)調(diào)用后,是立即返回的,但是立即返回的不是處理結(jié)果,而是表示提交成功類似的意思。等內(nèi)核數(shù)據(jù)準備好,將數(shù)據(jù)拷貝到用戶進程緩沖區(qū),發(fā)送信號通知用戶進程IO操作執(zhí)行完畢。
流程如下:
5. hystrix 工作原理
Hystrix 工作流程圖如下:
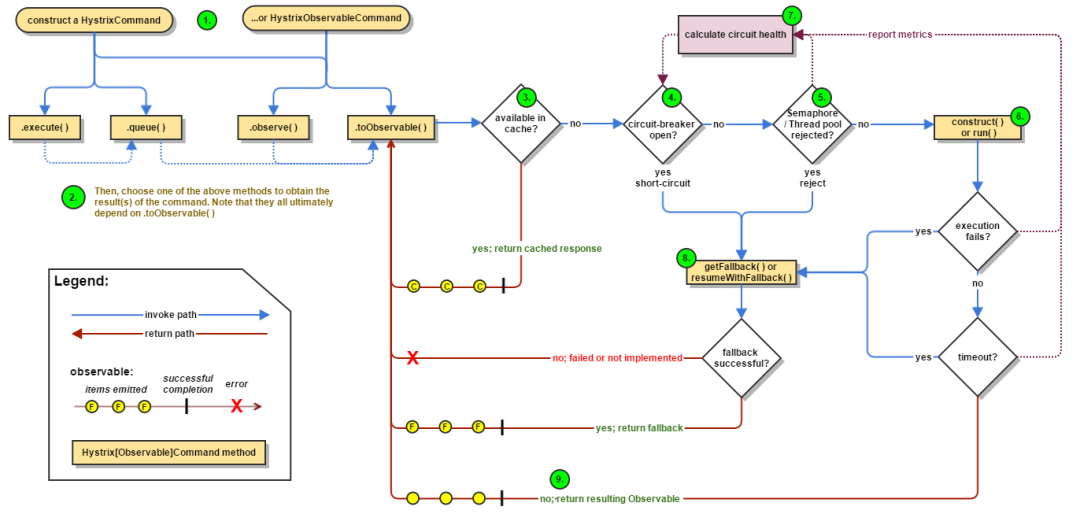
構(gòu)建命令
Hystrix 提供了兩個命令對象:HystrixCommand和HystrixObservableCommand,它將代表你的一個依賴請求任務(wù),向構(gòu)造函數(shù)中傳入請求依賴所需要的參數(shù)。
執(zhí)行命令
有四種方式執(zhí)行Hystrix命令。分別是:
R execute():同步阻塞執(zhí)行的,從依賴請求中接收到單個響應。 Future queue():異步執(zhí)行,返回一個包含單個響應的Future對象。 Observable observe():創(chuàng)建Observable后會訂閱Observable,從依賴請求中返回代表響應的Observable對象 Observable toObservable():cold observable,返回一個Observable,只有訂閱時才會執(zhí)行Hystrix命令,可以返回多個結(jié)果
檢查響應是否被緩存
如果啟用了 Hystrix緩存,任務(wù)執(zhí)行前將先判斷是否有相同命令執(zhí)行的緩存。如果有則直接返回包含緩存響應的Observable;如果沒有緩存的結(jié)果,但啟動了緩存,將緩存本次執(zhí)行結(jié)果以供后續(xù)使用。
檢查回路器是否打開 回路器(circuit-breaker)和保險絲類似,保險絲在發(fā)生危險時將會燒斷以保護電路,而回路器可以在達到我們設(shè)定的閥值時觸發(fā)短路(比如請求失敗率達到50%),拒絕執(zhí)行任何請求。
如果回路器被打開,Hystrix將不會執(zhí)行命令,直接進入Fallback處理邏輯。
檢查線程池/信號量/隊列情況 Hystrix 隔離方式有線程池隔離和信號量隔離。當使用Hystrix線程池時,Hystrix 默認為每個依賴服務(wù)分配10個線程,當10個線程都繁忙時,將拒絕執(zhí)行命令,,而是立即跳到執(zhí)行fallback邏輯。
執(zhí)行具體的任務(wù) 通過HystrixObservableCommand.construct() 或者 HystrixCommand.run() 來運行用戶真正的任務(wù)。
計算回路健康情況 每次開始執(zhí)行command、結(jié)束執(zhí)行command以及發(fā)生異常等情況時,都會記錄執(zhí)行情況,例如:成功、失敗、拒絕和超時等指標情況,會定期處理這些數(shù)據(jù),再根據(jù)設(shè)定的條件來判斷是否開啟回路器。
命令失敗時執(zhí)行Fallback邏輯 在命令失敗時執(zhí)行用戶指定的 Fallback 邏輯。上圖中的斷路、線程池拒絕、信號量拒絕、執(zhí)行執(zhí)行、執(zhí)行超時都會進入Fallback處理。
返回執(zhí)行結(jié)果 原始對象結(jié)果將以O(shè)bservable形式返回,在返回給用戶之前,會根據(jù)調(diào)用方式的不同做一些處理。
6. 延時場景處理
日常開發(fā)中,我們經(jīng)常遇到這種業(yè)務(wù)場景,如:外賣訂單超30分鐘未支付,則自動取消訂單;用戶注冊成功15分鐘后,發(fā)短信消息通知用戶等等。這就是延時任務(wù)處理場景。針對此類場景我們主要有以下幾種處理方案:
JDK的DelayQueue延遲隊列 時間輪算法 數(shù)據(jù)庫定時任務(wù)(如Quartz) Redis ZSet 實現(xiàn) MQ 延時隊列實現(xiàn)
7.https請求過程
HTTPS = HTTP + SSL/TLS,即用SSL/TLS對數(shù)據(jù)進行加密和解密,Http進行傳輸。 SSL,即Secure Sockets Layer(安全套接層協(xié)議),是網(wǎng)絡(luò)通信提供安全及數(shù)據(jù)完整性的一種安全協(xié)議。 TLS,即Transport Layer Security(安全傳輸層協(xié)議),它是SSL 3.0的后續(xù)版本。
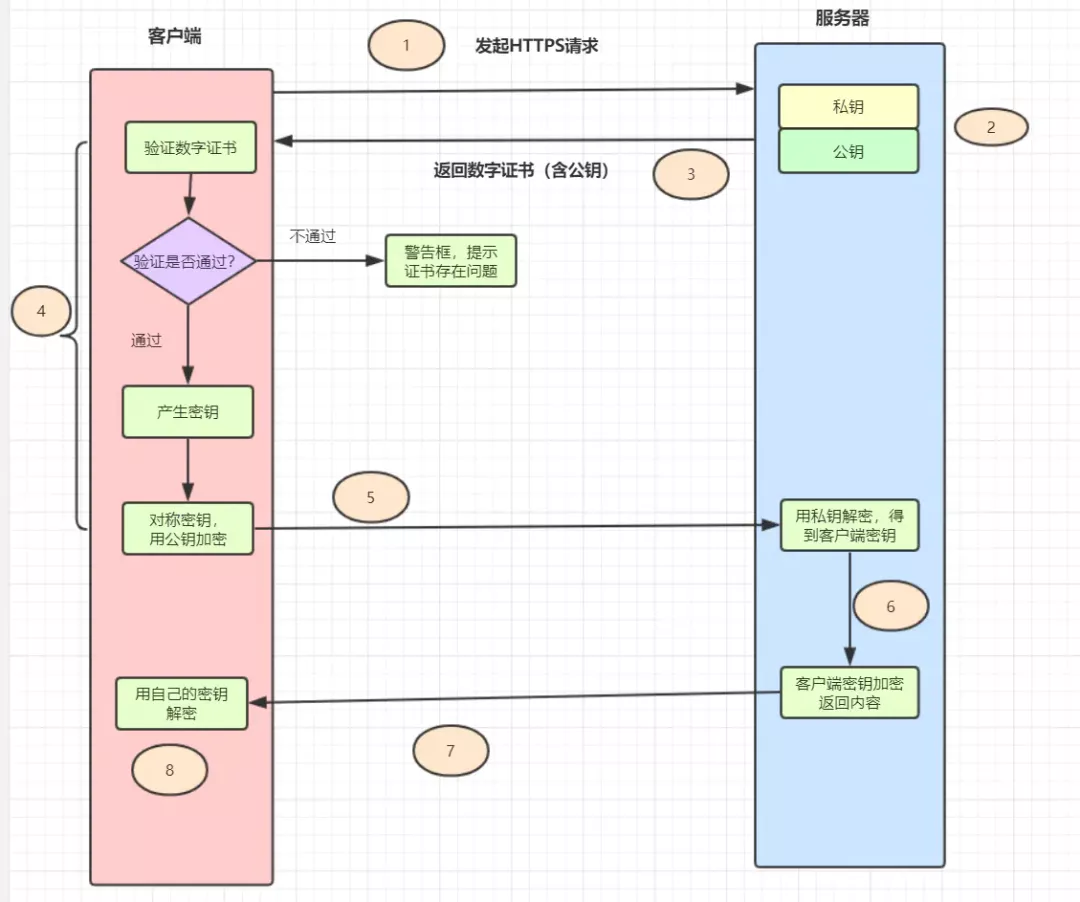
用戶在瀏覽器里輸入一個https網(wǎng)址,然后連接到server的443端口。 服務(wù)器必須要有一套數(shù)字證書,可以自己制作,也可以向組織申請,區(qū)別就是自己頒發(fā)的證書需要客戶端驗證通過。這套證書其實就是一對公鑰和私鑰。 服務(wù)器將自己的數(shù)字證書(含有公鑰)發(fā)送給客戶端。 客戶端收到服務(wù)器端的數(shù)字證書之后,會對其進行檢查,如果不通過,則彈出警告框。如果證書沒問題,則生成一個密鑰(對稱加密),用證書的公鑰對它加密。 客戶端會發(fā)起HTTPS中的第二個HTTP請求,將加密之后的客戶端密鑰發(fā)送給服務(wù)器。 服務(wù)器接收到客戶端發(fā)來的密文之后,會用自己的私鑰對其進行非對稱解密,解密之后得到客戶端密鑰,然后用客戶端密鑰對返回數(shù)據(jù)進行對稱加密,這樣數(shù)據(jù)就變成了密文。 服務(wù)器將加密后的密文返回給客戶端。 客戶端收到服務(wù)器發(fā)返回的密文,用自己的密鑰(客戶端密鑰)對其進行對稱解密,得到服務(wù)器返回的數(shù)據(jù)。
8. 聊聊事務(wù)隔離級別,以及可重復讀實現(xiàn)原理
8.1 數(shù)據(jù)庫四大隔離級別
為了解決并發(fā)事務(wù)存在的臟讀、不可重復讀、幻讀等問題,數(shù)據(jù)庫大叔設(shè)計了四種隔離級別。分別是讀未提交,讀已提交,可重復讀,串行化(Serializable)。
讀未提交隔離級別:只限制了兩個數(shù)據(jù)不能同時修改,但是修改數(shù)據(jù)的時候,即使事務(wù)未提交,都是可以被別的事務(wù)讀取到的,這級別的事務(wù)隔離有臟讀、重復讀、幻讀的問題; 讀已提交隔離級別:當前事務(wù)只能讀取到其他事務(wù)提交的數(shù)據(jù),所以這種事務(wù)的隔離級別解決了臟讀問題,但還是會存在重復讀、幻讀問題; 可重復讀:限制了讀取數(shù)據(jù)的時候,不可以進行修改,所以解決了重復讀的問題,但是讀取范圍數(shù)據(jù)的時候,是可以插入數(shù)據(jù),所以還會存在幻讀問題; 串行化:事務(wù)最高的隔離級別,在該級別下,所有事務(wù)都是進行串行化順序執(zhí)行的。可以避免臟讀、不可重復讀與幻讀所有并發(fā)問題。但是這種事務(wù)隔離級別下,事務(wù)執(zhí)行很耗性能。
四大隔離級別,都會存在哪些并發(fā)問題呢
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|
| 讀未提交 | √ | √ | √ |
| 讀已提交 | × | √ | √ |
| 可重復讀 | × | × | √ |
| 串行化 | × | × | × |
8.2 Read View可見性規(guī)則
| 變量 | 描述 |
|---|---|
| m_ids | 當前系統(tǒng)中那些活躍(未提交)的讀寫事務(wù)ID, 它數(shù)據(jù)結(jié)構(gòu)為一個List。 |
| max_limit_id | 表示生成Read View時,系統(tǒng)中應該分配給下一個事務(wù)的id值。 |
| min_limit_id | 表示在生成Read View時,當前系統(tǒng)中活躍的讀寫事務(wù)中最小的事務(wù)id,即m_ids中的最小值。 |
| creator_trx_id | 創(chuàng)建當前Read View的事務(wù)ID |
Read View的可見性規(guī)則如下:
如果數(shù)據(jù)事務(wù)ID trx_id < min_limit_id,表明生成該版本的事務(wù)在生成Read View前,已經(jīng)提交(因為事務(wù)ID是遞增的),所以該版本可以被當前事務(wù)訪問。如果 trx_id>= max_limit_id,表明生成該版本的事務(wù)在生成Read View后才生成,所以該版本不可以被當前事務(wù)訪問。如果 min_limit_id =
1)如果 m_ids包含trx_id,則代表Read View生成時刻,這個事務(wù)還未提交,但是如果數(shù)據(jù)的trx_id等于creator_trx_id的話,表明數(shù)據(jù)是自己生成的,因此是可見的。2)如果 m_ids包含trx_id,并且trx_id不等于creator_trx_id,則Read View生成時,事務(wù)未提交,并且不是自己生產(chǎn)的,所以當前事務(wù)也是看不見的;3)如果 m_ids不包含trx_id,則說明你這個事務(wù)在Read View生成之前就已經(jīng)提交了,修改的結(jié)果,當前事務(wù)是能看見的。
8.3 可重復讀實現(xiàn)原理
數(shù)據(jù)庫是通過加鎖實現(xiàn)隔離級別的,比如,你想一個人靜靜,不被別人打擾,你可以把自己關(guān)在房子,并在房門上加上一把鎖!串行化隔離級別就是加鎖實現(xiàn)的。但是如果頻繁加鎖,性能會下降。因此設(shè)計數(shù)據(jù)庫的大叔想到了MVCC。
可重復讀的實現(xiàn)原理就是MVCC多版本并發(fā)控制。在一個事務(wù)范圍內(nèi),兩個相同的查詢,讀取同一條記錄,卻返回了不同的數(shù)據(jù),這就是不可重復讀。可重復讀隔離級別,就是為了解決不可重復讀問題。
查詢一條記錄,基于MVCC,是怎樣的流程呢?
獲取事務(wù)自己的版本號,即事務(wù)ID 獲取Read View 查詢得到的數(shù)據(jù),然后Read View中的事務(wù)版本號進行比較。 如果不符合Read View的可見性規(guī)則, 即就需要Undo log中歷史快照; 最后返回符合規(guī)則的數(shù)據(jù)
InnoDB 實現(xiàn)MVCC,是通過Read View+ Undo Log實現(xiàn)的,Undo Log保存了歷史快照,Read View可見性規(guī)則幫助判斷當前版本的數(shù)據(jù)是否可見。
可重復讀(RR)隔離級別,是如何解決不可重復讀問題的?
假設(shè)存在事務(wù)A和B,SQL執(zhí)行流程如下
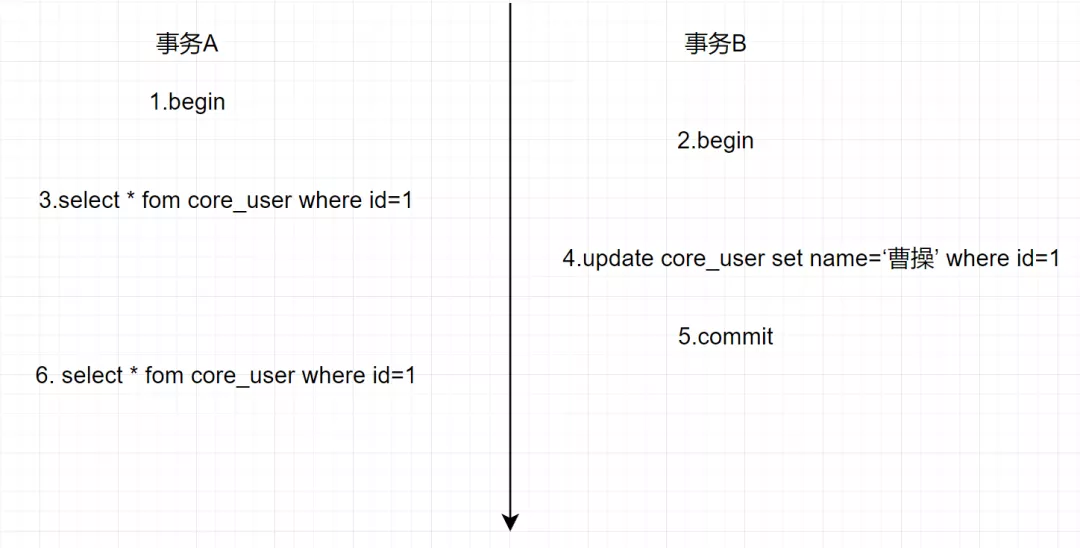
在可重復讀(RR)隔離級別下,一個事務(wù)里只會獲取一次read view,都是副本共用的,從而保證每次查詢的數(shù)據(jù)都是一樣的。
假設(shè)當前有一張core_user表,插入一條初始化數(shù)據(jù),如下:

基于MVCC,我們來看看執(zhí)行流程
A開啟事務(wù),首先得到一個事務(wù)ID為100 B開啟事務(wù),得到事務(wù)ID為101 事務(wù)A生成一個Read View,read view對應的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后回到版本鏈:開始從版本鏈中挑選可見的記錄:

由圖可以看出,最新版本的列name的內(nèi)容是孫權(quán),該版本的trx_id值為100。開始執(zhí)行read view可見性規(guī)則校驗:
min_limit_id(100)=creator_trx_id?=?trx_id?=100;
由此可得,trx_id=100的這個記錄,當前事務(wù)是可見的。所以查到是name為孫權(quán)的記錄。
事務(wù)B進行修改操作,把名字改為曹操。把原數(shù)據(jù)拷貝到undo log,然后對數(shù)據(jù)進行修改,標記事務(wù)ID和上一個數(shù)據(jù)版本在undo log的地址。
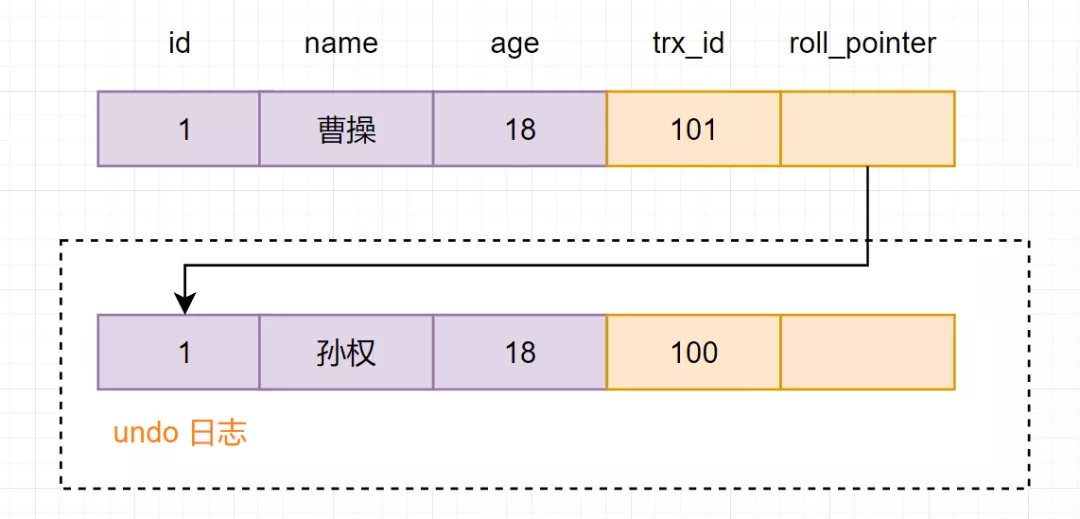
事務(wù)B提交事務(wù)
事務(wù)A再次執(zhí)行查詢操作,因為是RR(可重復讀)隔離級別,因此會復用老的Read View副本,Read View對應的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本鏈:從版本鏈中挑選可見的記錄:
從圖可得,最新版本的列name的內(nèi)容是曹操,該版本的trx_id值為101。開始執(zhí)行read view可見性規(guī)則校驗:
min_limit_id(100)=因為m_ids{100,101}包含trx_id(101),
并且creator_trx_id?(100)?不等于trx_id(101)
所以,trx_id=101這個記錄,對于當前事務(wù)是不可見的。這時候呢,版本鏈roll_pointer跳到下一個版本,trx_id=100這個記錄,再次校驗是否可見:
min_limit_id(100)=因為m_ids{100,101}包含trx_id(100),
并且creator_trx_id?(100)?等于trx_id(100)
所以,trx_id=100這個記錄,對于當前事務(wù)是可見的,所以兩次查詢結(jié)果,都是name=孫權(quán)的那個記錄。即在可重復讀(RR)隔離級別下,復用老的Read View副本,解決了不可重復讀的問題。
9. 聊聊索引在哪些場景下會失效?
10. 什么是虛擬內(nèi)存
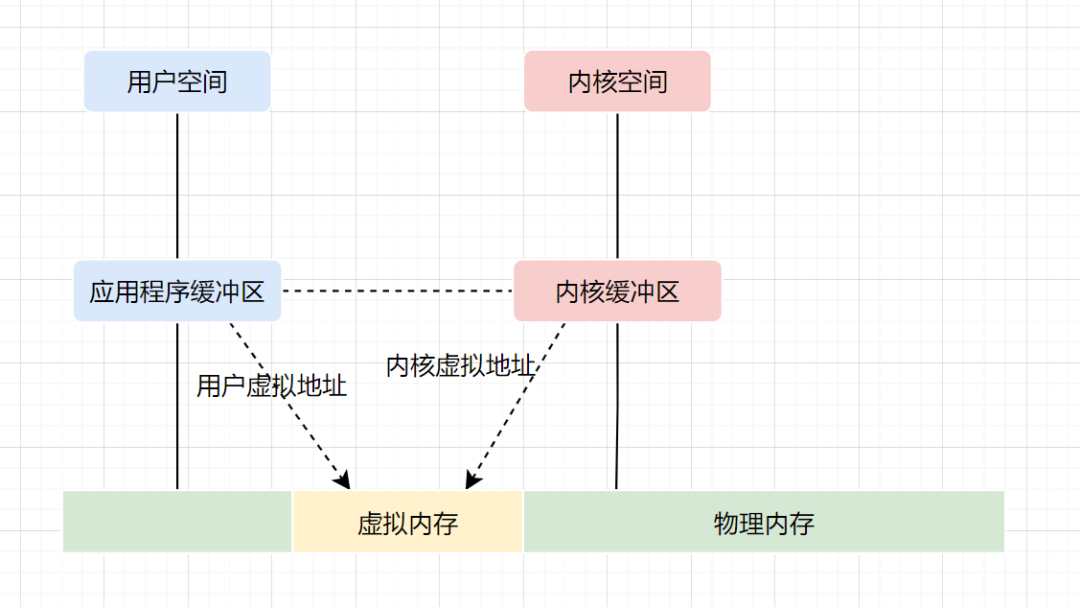
虛擬內(nèi)存,是虛擬出來的內(nèi)存,它的核心思想就是確保每個程序擁有自己的地址空間,地址空間被分成多個塊,每一塊都有連續(xù)的地址空間。同時物理空間也分成多個塊,塊大小和虛擬地址空間的塊大小一致,操作系統(tǒng)會自動將虛擬地址空間映射到物理地址空間,程序只需關(guān)注虛擬內(nèi)存,請求的也是虛擬內(nèi)存,真正使用卻是物理內(nèi)存。
現(xiàn)代操作系統(tǒng)使用虛擬內(nèi)存,即虛擬地址取代物理地址,使用虛擬內(nèi)存可以有2個好處:
虛擬內(nèi)存空間可以遠遠大于物理內(nèi)存空間 多個虛擬內(nèi)存可以指向同一個物理地址
零拷貝實現(xiàn)思想,就利用了虛擬內(nèi)存這個點:多個虛擬內(nèi)存可以指向同一個物理地址,可以把內(nèi)核空間和用戶空間的虛擬地址映射到同一個物理地址,這樣的話,就可以減少IO的數(shù)據(jù)拷貝次數(shù)啦,示意圖如下:
11. 排行榜的實現(xiàn),比如高考成績排序
排行版的實現(xiàn),一般使用redis的zset數(shù)據(jù)類型。
使用格式如下:
zadd?key?score?member?[score?member?...],zrank?key?member
層內(nèi)部編碼:ziplist(壓縮列表)、skiplist(跳躍表) 使用場景如排行榜,社交需求(如用戶點贊)
實現(xiàn)demo如下:

12.分布式鎖實現(xiàn)
分布式鎖,是控制分布式系統(tǒng)不同進程共同訪問共享資源的一種鎖的實現(xiàn)。秒殺下單、搶紅包等等業(yè)務(wù)場景,都需要用到分布式鎖,我們項目中經(jīng)常使用Redis作為分布式鎖。
選了Redis分布式鎖的幾種實現(xiàn)方法,大家來討論下,看有沒有啥問題哈。
命令setnx + expire分開寫 setnx + value值是過期時間 set的擴展命令(set ex px nx) set ex px nx + 校驗唯一隨機值,再刪除 Redisson
12.1 命令setnx + expire分開寫
if(jedis.setnx(key,lock_value)?==?1){?//加鎖
????expire(key,100);?//設(shè)置過期時間
????try?{
????????do?something??//業(yè)務(wù)請求
????}catch(){
??}
??finally?{
???????jedis.del(key);?//釋放鎖
????}
}
如果執(zhí)行完setnx加鎖,正要執(zhí)行expire設(shè)置過期時間時,進程crash掉或者要重啟維護了,那這個鎖就“長生不老”了,別的線程永遠獲取不到鎖啦,所以分布式鎖不能這么實現(xiàn)。
12.2 setnx + value值是過期時間
long?expires?=?System.currentTimeMillis()?+?expireTime;?//系統(tǒng)時間+設(shè)置的過期時間
String?expiresStr?=?String.valueOf(expires);
//?如果當前鎖不存在,返回加鎖成功
if?(jedis.setnx(key,?expiresStr)?==?1)?{
????????return?true;
}?
//?如果鎖已經(jīng)存在,獲取鎖的過期時間
String?currentValueStr?=?jedis.get(key);
//?如果獲取到的過期時間,小于系統(tǒng)當前時間,表示已經(jīng)過期
if?(currentValueStr?!=?null?&&?Long.parseLong(currentValueStr)?
?????//?鎖已過期,獲取上一個鎖的過期時間,并設(shè)置現(xiàn)在鎖的過期時間(不了解redis的getSet命令的小伙伴,可以去官網(wǎng)看下哈)
????String?oldValueStr?=?jedis.getSet(key_resource_id,?expiresStr);
????
????if?(oldValueStr?!=?null?&&?oldValueStr.equals(currentValueStr))?{
?????????//?考慮多線程并發(fā)的情況,只有一個線程的設(shè)置值和當前值相同,它才可以加鎖
?????????return?true;
????}
}
????????
//其他情況,均返回加鎖失敗
return?false;
}
筆者看過有開發(fā)小伙伴就是這么實現(xiàn)分布式鎖的,但是這種方案也有這些缺點:
過期時間是客戶端自己生成的,分布式環(huán)境下,每個客戶端的時間必須同步。 沒有保存持有者的唯一標識,可能被別的客戶端釋放/解鎖。 鎖過期的時候,并發(fā)多個客戶端同時請求過來,都執(zhí)行了 jedis.getSet(),最終只能有一個客戶端加鎖成功,但是該客戶端鎖的過期時間,可能被別的客戶端覆蓋。
12.3 set的擴展命令(set ex px nx)(注意可能存在的問題)
if(jedis.set(key,?lock_value,?"NX",?"EX",?100s)?==?1){?//加鎖
????try?{
????????do?something??//業(yè)務(wù)處理
????}catch(){
??}
??finally?{
???????jedis.del(key);?//釋放鎖
????}
}
這個方案可能存在這樣的問題:
鎖過期釋放了,業(yè)務(wù)還沒執(zhí)行完。 鎖被別的線程誤刪。
12.4 set ex px nx + 校驗唯一隨機值,再刪除
if(jedis.set(key,?uni_request_id,?"NX",?"EX",?100s)?==?1){?//加鎖
????try?{
????????do?something??//業(yè)務(wù)處理
????}catch(){
??}
??finally?{
???????//判斷是不是當前線程加的鎖,是才釋放
???????if?(uni_request_id.equals(jedis.get(key)))?{
????????jedis.del(key);?//釋放鎖
????????}
????}
}
在這里,判斷當前線程加的鎖和釋放鎖是不是一個原子操作。如果調(diào)用jedis.del()釋放鎖的時候,可能這把鎖已經(jīng)不屬于當前客戶端,會解除他人加的鎖。
一般也是用lua腳本代替。lua腳本如下:
if?redis.call('get',KEYS[1])?==?ARGV[1]?then?
???return?redis.call('del',KEYS[1])?
else
???return?0
end;
這種方式比較不錯了,一般情況下,已經(jīng)可以使用這種實現(xiàn)方式。但是存在鎖過期釋放了,業(yè)務(wù)還沒執(zhí)行完的問題(實際上,估算個業(yè)務(wù)處理的時間,一般沒啥問題了)。
12.5 Redisson
分布式鎖可能存在鎖過期釋放,業(yè)務(wù)沒執(zhí)行完的問題。有些小伙伴認為,稍微把鎖過期時間設(shè)置長一些就可以啦。其實我們設(shè)想一下,是否可以給獲得鎖的線程,開啟一個定時守護線程,每隔一段時間檢查鎖是否還存在,存在則對鎖的過期時間延長,防止鎖過期提前釋放。
當前開源框架Redisson就解決了這個分布式鎖問題。我們一起來看下Redisson底層原理是怎樣的吧: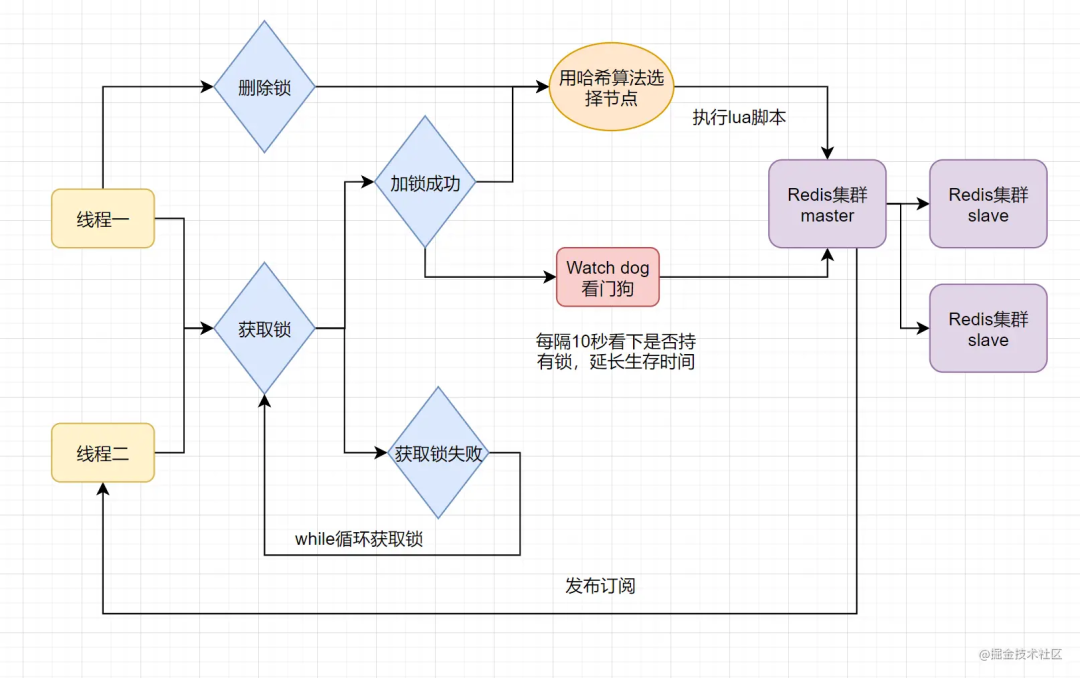
只要線程一加鎖成功,就會啟動一個watch dog看門狗,它是一個后臺線程,會每隔10秒檢查一下,如果線程1還持有鎖,那么就會不斷的延長鎖key的生存時間。因此,Redisson就是使用Redisson解決了鎖過期釋放,業(yè)務(wù)沒執(zhí)行完問題。
13. 零拷貝
零拷貝就是不需要將數(shù)據(jù)從一個存儲區(qū)域復制到另一個存儲區(qū)域。它是指在傳統(tǒng)IO模型中,指CPU拷貝的次數(shù)為0。它是IO的優(yōu)化方案
傳統(tǒng)IO流程 零拷貝實現(xiàn)之mmap+write 零拷貝實現(xiàn)之sendfile 零拷貝實現(xiàn)之帶有DMA收集拷貝功能的sendfile
13.1 傳統(tǒng)IO流程
流程圖如下:
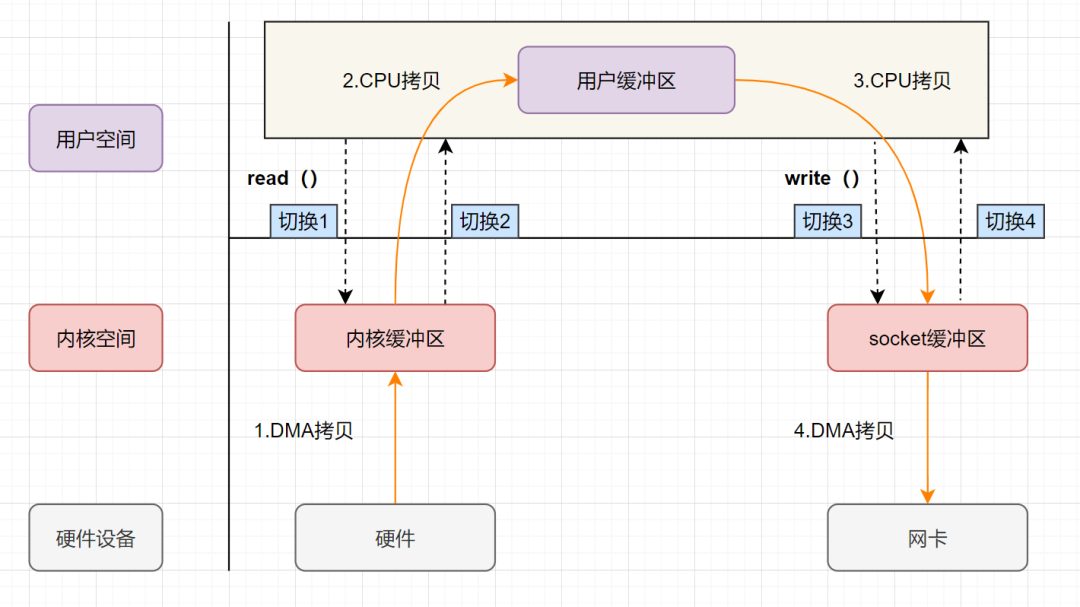
用戶應用進程調(diào)用read函數(shù),向操作系統(tǒng)發(fā)起IO調(diào)用,上下文從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài)(切換1) DMA控制器把數(shù)據(jù)從磁盤中,讀取到內(nèi)核緩沖區(qū)。 CPU把內(nèi)核緩沖區(qū)數(shù)據(jù),拷貝到用戶應用緩沖區(qū),上下文從內(nèi)核態(tài)轉(zhuǎn)為用戶態(tài)(切換2),read函數(shù)返回 用戶應用進程通過write函數(shù),發(fā)起IO調(diào)用,上下文從用戶態(tài)轉(zhuǎn)為內(nèi)核態(tài)(切換3) CPU將應用緩沖區(qū)中的數(shù)據(jù),拷貝到socket緩沖區(qū) DMA控制器把數(shù)據(jù)從socket緩沖區(qū),拷貝到網(wǎng)卡設(shè)備,上下文從內(nèi)核態(tài)切換回用戶態(tài)(切換4),write函數(shù)返回
從流程圖可以看出,傳統(tǒng)IO的讀寫流程,包括了4次上下文切換(4次用戶態(tài)和內(nèi)核態(tài)的切換),4次數(shù)據(jù)拷貝(兩次CPU拷貝以及兩次的DMA拷貝)。
13.2 mmap+write實現(xiàn)的零拷貝
mmap 的函數(shù)原型如下:
void?*mmap(void?*addr,?size_t?length,?int?prot,?int?flags,?int?fd,?off_t?offset);
addr:指定映射的虛擬內(nèi)存地址 length:映射的長度 prot:映射內(nèi)存的保護模式 flags:指定映射的類型 fd:進行映射的文件句柄 offset:文件偏移量
mmap使用了虛擬內(nèi)存,可以把內(nèi)核空間和用戶空間的虛擬地址映射到同一個物理地址,從而減少數(shù)據(jù)拷貝次數(shù)!
mmap+write實現(xiàn)的零拷貝流程如下:
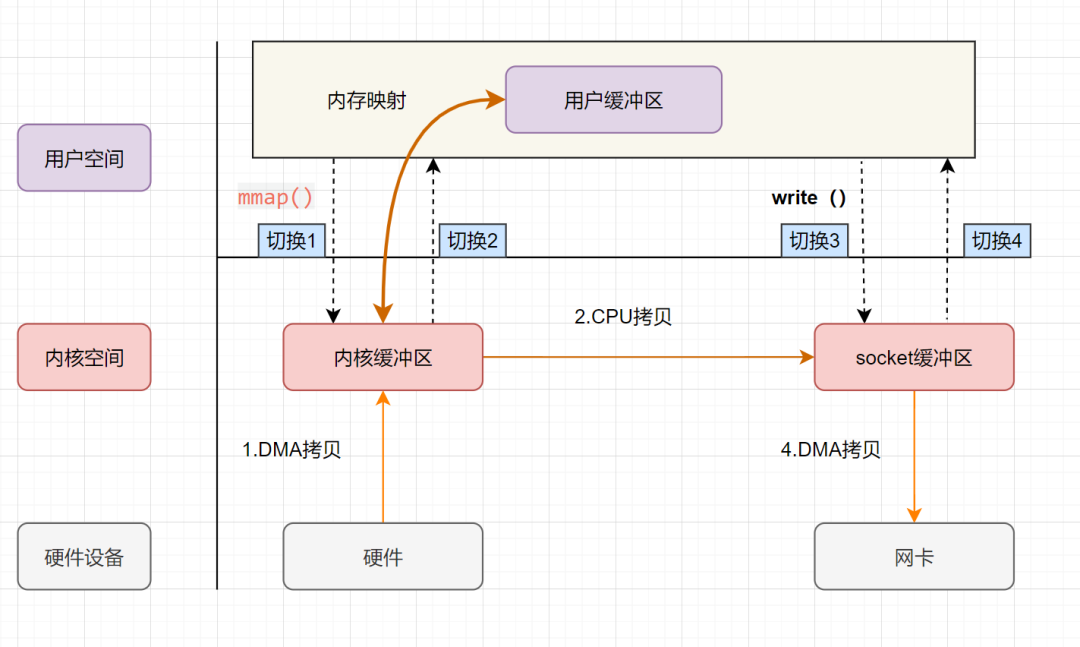
用戶進程通過 mmap方法向操作系統(tǒng)內(nèi)核發(fā)起IO調(diào)用,上下文從用戶態(tài)切換為內(nèi)核態(tài)。CPU利用DMA控制器,把數(shù)據(jù)從硬盤中拷貝到內(nèi)核緩沖區(qū)。 上下文從內(nèi)核態(tài)切換回用戶態(tài),mmap方法返回。 用戶進程通過 write方法向操作系統(tǒng)內(nèi)核發(fā)起IO調(diào)用,上下文從用戶態(tài)切換為內(nèi)核態(tài)。CPU將內(nèi)核緩沖區(qū)的數(shù)據(jù)拷貝到的socket緩沖區(qū)。 CPU利用DMA控制器,把數(shù)據(jù)從socket緩沖區(qū)拷貝到網(wǎng)卡,上下文從內(nèi)核態(tài)切換回用戶態(tài),write調(diào)用返回。
可以發(fā)現(xiàn),mmap+write實現(xiàn)的零拷貝,I/O發(fā)生了4次用戶空間與內(nèi)核空間的上下文切換,以及3次數(shù)據(jù)拷貝。其中3次數(shù)據(jù)拷貝中,包括了2次DMA拷貝和1次CPU拷貝。
mmap是將讀緩沖區(qū)的地址和用戶緩沖區(qū)的地址進行映射,內(nèi)核緩沖區(qū)和應用緩沖區(qū)共享,所以節(jié)省了一次CPU拷貝‘’并且用戶進程內(nèi)存是虛擬的,只是映射到內(nèi)核的讀緩沖區(qū),可以節(jié)省一半的內(nèi)存空間。
sendfile實現(xiàn)的零拷貝
sendfile是Linux2.1內(nèi)核版本后引入的一個系統(tǒng)調(diào)用函數(shù),API如下:
ssize_t?sendfile(int?out_fd,?int?in_fd,?off_t?*offset,?size_t?count);
out_fd:為待寫入內(nèi)容的文件描述符,一個socket描述符。, in_fd:為待讀出內(nèi)容的文件描述符,必須是真實的文件,不能是socket和管道。 offset:指定從讀入文件的哪個位置開始讀,如果為NULL,表示文件的默認起始位置。 count:指定在fdout和fdin之間傳輸?shù)淖止?jié)數(shù)。
sendfile表示在兩個文件描述符之間傳輸數(shù)據(jù),它是在操作系統(tǒng)內(nèi)核中操作的,避免了數(shù)據(jù)從內(nèi)核緩沖區(qū)和用戶緩沖區(qū)之間的拷貝操作,因此可以使用它來實現(xiàn)零拷貝。
sendfile實現(xiàn)的零拷貝流程如下:
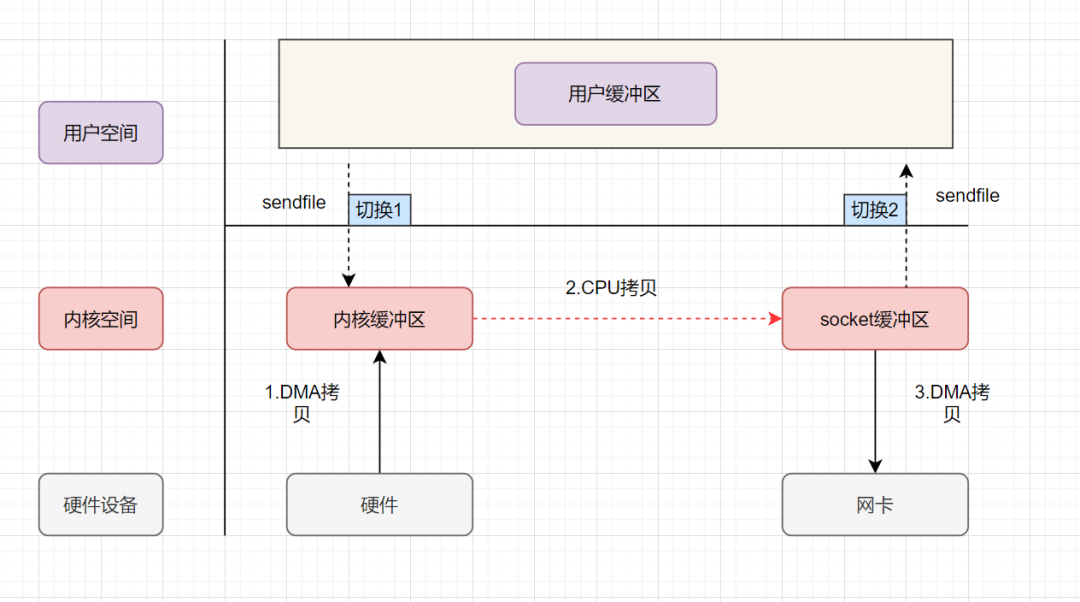
用戶進程發(fā)起sendfile系統(tǒng)調(diào)用,上下文(切換1)從用戶態(tài)轉(zhuǎn)向內(nèi)核態(tài) DMA控制器,把數(shù)據(jù)從硬盤中拷貝到內(nèi)核緩沖區(qū)。 CPU將讀緩沖區(qū)中數(shù)據(jù)拷貝到socket緩沖區(qū) DMA控制器,異步把數(shù)據(jù)從socket緩沖區(qū)拷貝到網(wǎng)卡, 上下文(切換2)從內(nèi)核態(tài)切換回用戶態(tài),sendfile調(diào)用返回。
可以發(fā)現(xiàn),sendfile實現(xiàn)的零拷貝,I/O發(fā)生了2次用戶空間與內(nèi)核空間的上下文切換,以及3次數(shù)據(jù)拷貝。其中3次數(shù)據(jù)拷貝中,包括了2次DMA拷貝和1次CPU拷貝。那能不能把CPU拷貝的次數(shù)減少到0次呢?有的,即帶有DMA收集拷貝功能的sendfile!
sendfile+DMA scatter/gather實現(xiàn)的零拷貝
linux 2.4版本之后,對sendfile做了優(yōu)化升級,引入SG-DMA技術(shù),其實就是對DMA拷貝加入了scatter/gather操作,它可以直接從內(nèi)核空間緩沖區(qū)中將數(shù)據(jù)讀取到網(wǎng)卡。使用這個特點搞零拷貝,即還可以多省去一次CPU拷貝。
sendfile+DMA scatter/gather實現(xiàn)的零拷貝流程如下:
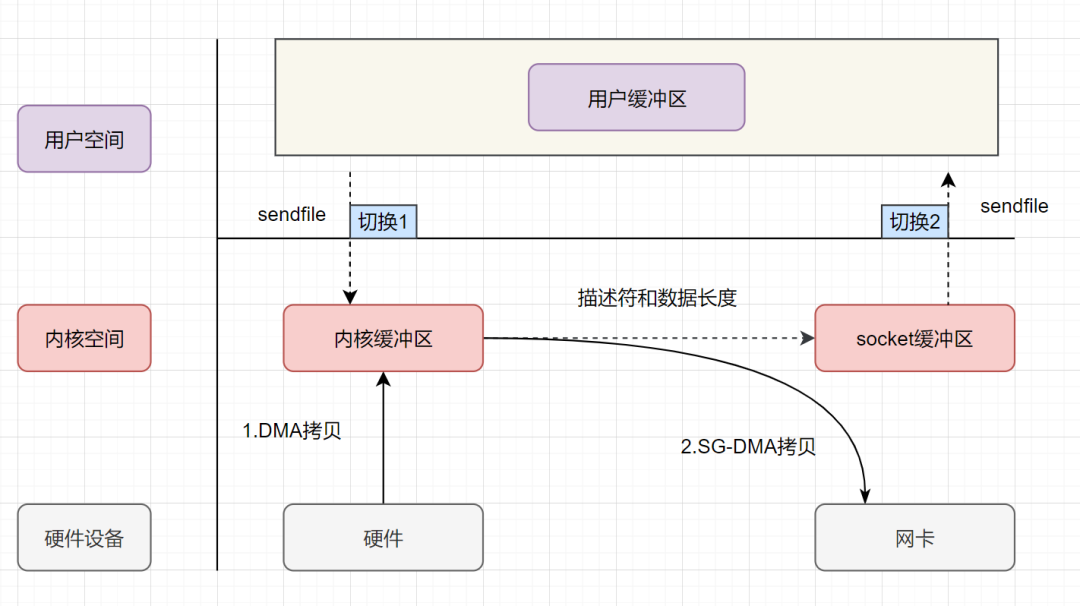
用戶進程發(fā)起sendfile系統(tǒng)調(diào)用,上下文(切換1)從用戶態(tài)轉(zhuǎn)向內(nèi)核態(tài) DMA控制器,把數(shù)據(jù)從硬盤中拷貝到內(nèi)核緩沖區(qū)。 CPU把內(nèi)核緩沖區(qū)中的文件描述符信息(包括內(nèi)核緩沖區(qū)的內(nèi)存地址和偏移量)發(fā)送到socket緩沖區(qū) DMA控制器根據(jù)文件描述符信息,直接把數(shù)據(jù)從內(nèi)核緩沖區(qū)拷貝到網(wǎng)卡 上下文(切換2)從內(nèi)核態(tài)切換回用戶態(tài),sendfile調(diào)用返回。
可以發(fā)現(xiàn),sendfile+DMA scatter/gather實現(xiàn)的零拷貝,I/O發(fā)生了2次用戶空間與內(nèi)核空間的上下文切換,以及2次數(shù)據(jù)拷貝。其中2次數(shù)據(jù)拷貝都是包DMA拷貝。這就是真正的 零拷貝(Zero-copy) 技術(shù),全程都沒有通過CPU來搬運數(shù)據(jù),所有的數(shù)據(jù)都是通過DMA來進行傳輸?shù)摹?/p>
14. synchronized
synchronized是Java中的關(guān)鍵字,是一種同步鎖。synchronized關(guān)鍵字可以作用于方法或者代碼塊。
一般面試時。可以這么回答:
反編譯后,monitorenter、monitorexit、ACC_SYNCHRONIZED monitor監(jiān)視器 Java Monitor 的工作機理 對象與monitor關(guān)聯(lián)
14.1 monitorenter、monitorexit、ACC_SYNCHRONIZED
如果synchronized作用于代碼塊,反編譯可以看到兩個指令:monitorenter、monitorexit,JVM使用monitorenter和monitorexit兩個指令實現(xiàn)同步;如果作用synchronized作用于方法,反編譯可以看到ACCSYNCHRONIZED標記,JVM通過在方法訪問標識符(flags)中加入ACCSYNCHRONIZED來實現(xiàn)同步功能。
同步代碼塊是通過 monitorenter和monitorexit來實現(xiàn),當線程執(zhí)行到monitorenter的時候要先獲得monitor鎖,才能執(zhí)行后面的方法。當線程執(zhí)行到monitorexit的時候則要釋放鎖。同步方法是通過中設(shè)置 ACCSYNCHRONIZED標志來實現(xiàn),當線程執(zhí)行有ACCSYNCHRONIZED標志的方法,需要獲得monitor鎖。每個對象都與一個monitor相關(guān)聯(lián),線程可以占有或者釋放monitor。
14.2 monitor監(jiān)視器
monitor是什么呢?操作系統(tǒng)的管程(monitors)是概念原理,ObjectMonitor是它的原理實現(xiàn)。
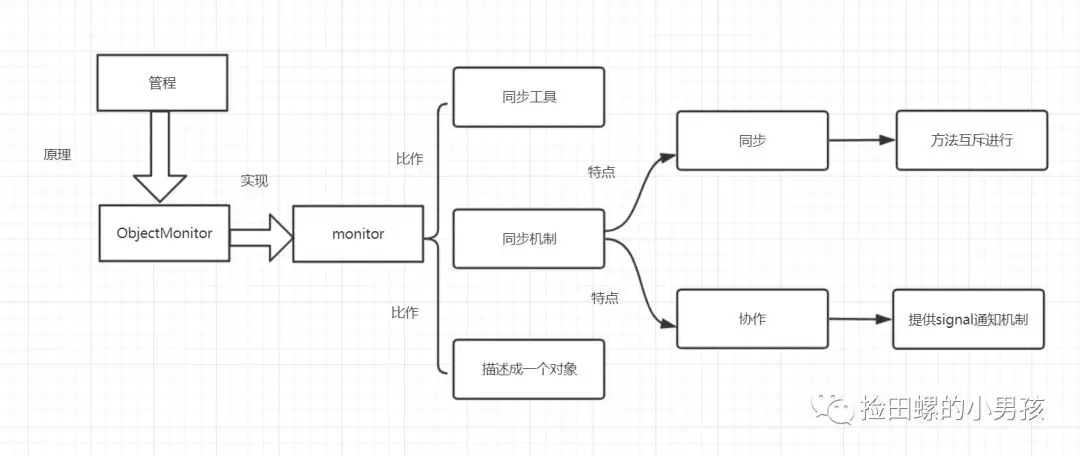
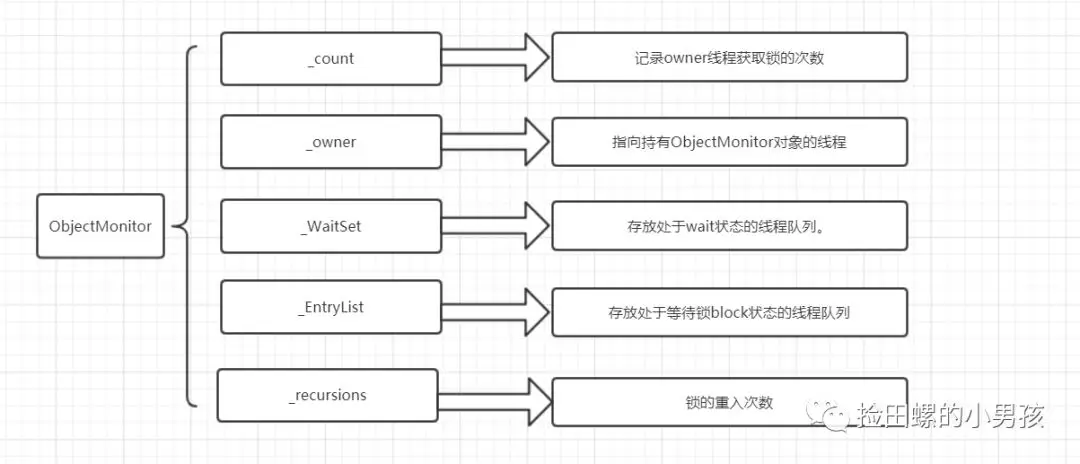
在Java虛擬機(HotSpot)中,Monitor(管程)是由ObjectMonitor實現(xiàn)的,其主要數(shù)據(jù)結(jié)構(gòu)如下:
?ObjectMonitor()?{
????_header???????=?NULL;
????_count????????=?0;?//?記錄個數(shù)
????_waiters??????=?0,
????_recursions???=?0;
????_object???????=?NULL;
????_owner????????=?NULL;
????_WaitSet??????=?NULL;??//?處于wait狀態(tài)的線程,會被加入到_WaitSet
????_WaitSetLock??=?0?;
????_Responsible??=?NULL?;
????_succ?????????=?NULL?;
????_cxq??????????=?NULL?;
????FreeNext??????=?NULL?;
????_EntryList????=?NULL?;??//?處于等待鎖block狀態(tài)的線程,會被加入到該列表
????_SpinFreq?????=?0?;
????_SpinClock????=?0?;
????OwnerIsThread?=?0?;
??}
ObjectMonitor中幾個關(guān)鍵字段的含義如圖所示:
14.3 Java Monitor 的工作機理
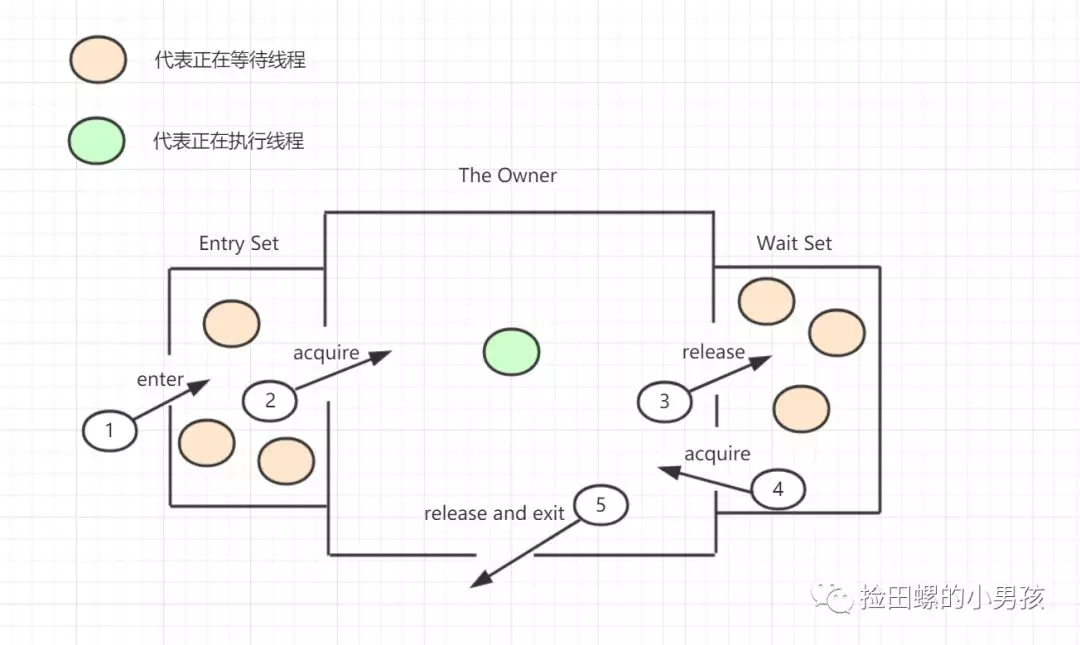
想要獲取monitor的線程,首先會進入_EntryList隊列。 當某個線程獲取到對象的monitor后,進入Owner區(qū)域,設(shè)置為當前線程,同時計數(shù)器count加1。 如果線程調(diào)用了wait()方法,則會進入WaitSet隊列。它會釋放monitor鎖,即將owner賦值為null,count自減1,進入WaitSet隊列阻塞等待。 如果其他線程調(diào)用 notify() / notifyAll() ,會喚醒WaitSet中的某個線程,該線程再次嘗試獲取monitor鎖,成功即進入Owner區(qū)域。 同步方法執(zhí)行完畢了,線程退出臨界區(qū),會將monitor的owner設(shè)為null,并釋放監(jiān)視鎖。
14.4 對象與monitor關(guān)聯(lián)
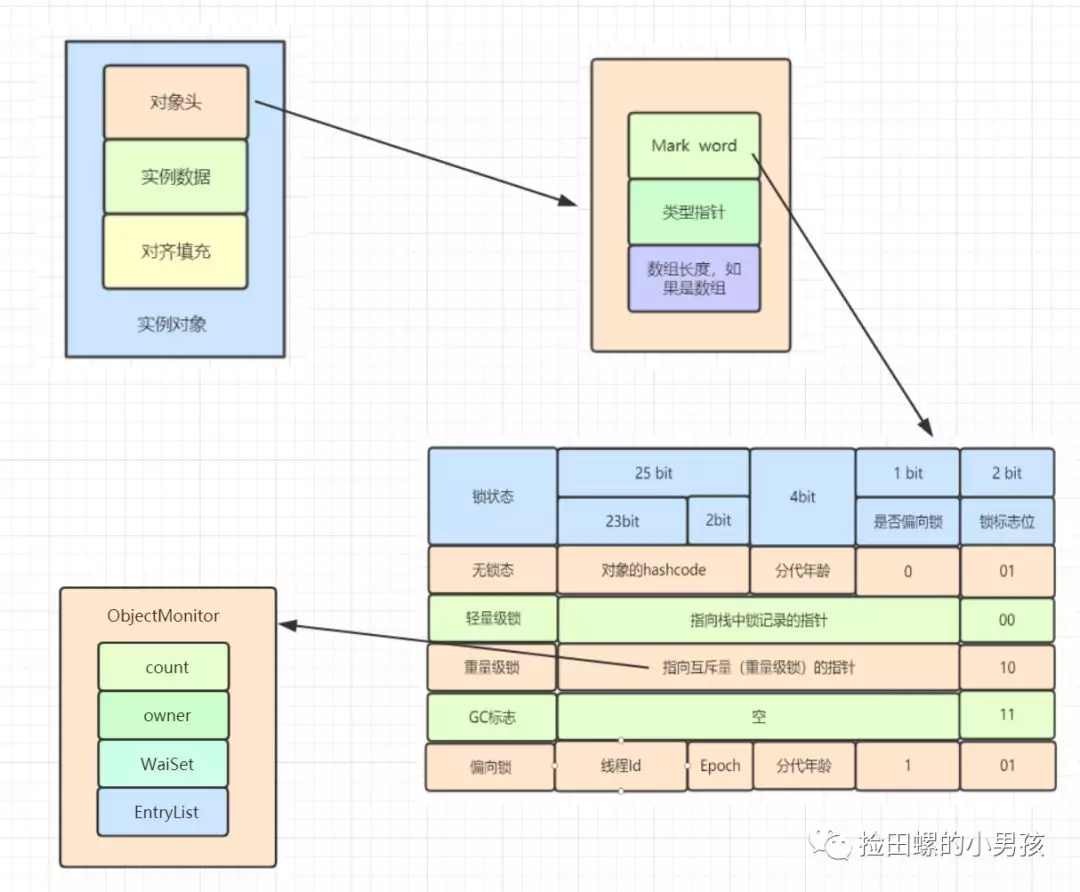
在HotSpot虛擬機中,對象在內(nèi)存中存儲的布局可以分為3塊區(qū)域:對象頭(Header),實例數(shù)據(jù)(Instance Data)和對象填充(Padding)。 對象頭主要包括兩部分數(shù)據(jù):Mark Word(標記字段)、Class Pointer(類型指針)。
Mark Word 是用于存儲對象自身的運行時數(shù)據(jù),如哈希碼(HashCode)、GC分代年齡、鎖狀態(tài)標志、線程持有的鎖、偏向線程 ID、偏向時間戳等。
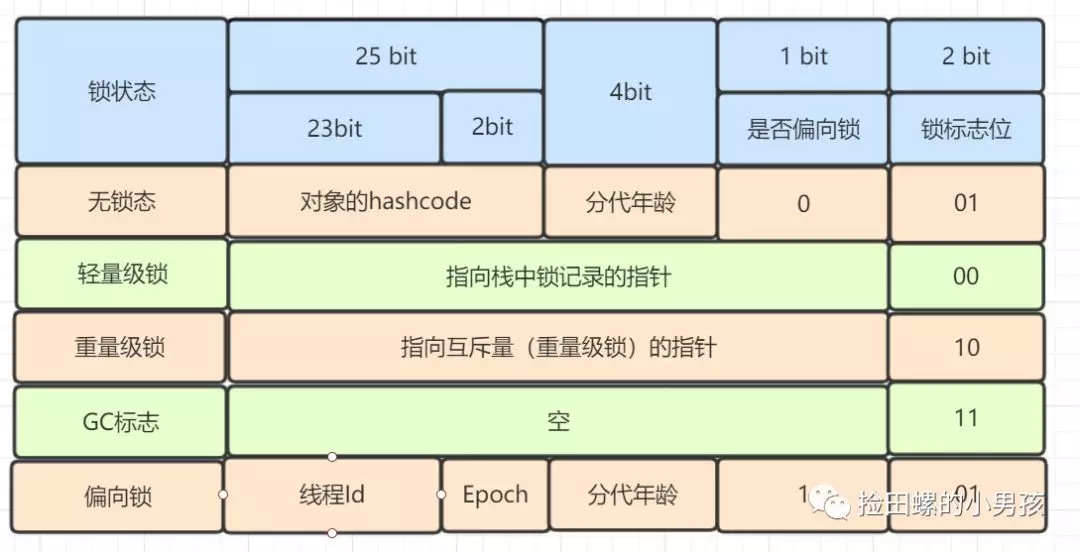
重量級鎖,指向互斥量的指針。其實synchronized是重量級鎖,也就是說Synchronized的對象鎖,Mark Word鎖標識位為10,其中指針指向的是Monitor對象的起始地址。
15. 分布式id生成方案有哪些?什么是雪花算法?
分布式id生成方案主要有:
UUID 數(shù)據(jù)庫自增ID 基于雪花算法(Snowflake)實現(xiàn) 百度 (Uidgenerator) 美團(Leaf)
什么是雪花算法?
雪花算法是一種生成分布式全局唯一ID的算法,生成的ID稱為Snowflake IDs。這種算法由Twitter創(chuàng)建,并用于推文的ID。
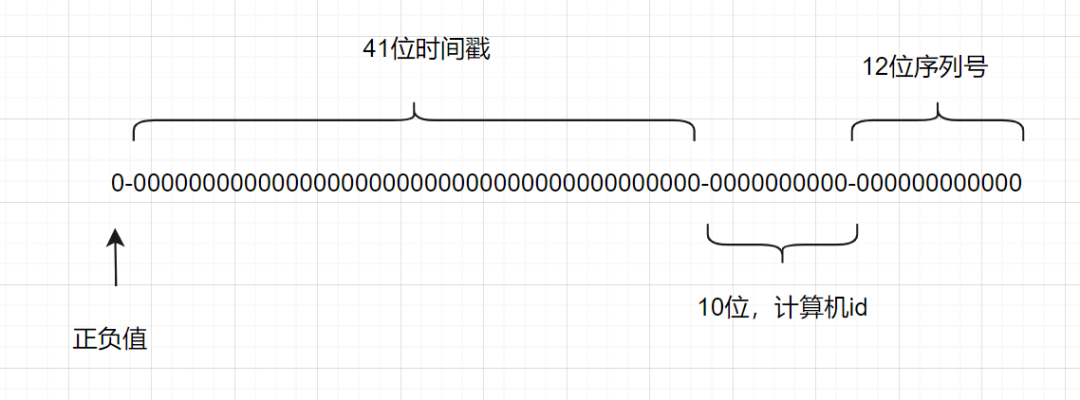
一個Snowflake ID有64位。
第1位:Java中l(wèi)ong的最高位是符號位代表正負,正數(shù)是0,負數(shù)是1,一般生成ID都為正數(shù),所以默認為0。 接下來前41位是時間戳,表示了自選定的時期以來的毫秒數(shù)。 接下來的10位代表計算機ID,防止沖突。 其余12位代表每臺機器上生成ID的序列號,這允許在同一毫秒內(nèi)創(chuàng)建多個Snowflake ID。
我是小富~,如果對你有用在看、關(guān)注支持下,咱們下期見~
?往期推薦?
??
面試官問:訂單30分鐘未支付,自動取消,該怎么實現(xiàn)?
11 張圖總結(jié)下,微服務(wù)增量拉取
給你一個億的keys,Redis如何統(tǒng)計?
在看、點贊、轉(zhuǎn)發(fā),是對我最大的鼓勵。
整理了幾百本各類技術(shù)電子書,有需要的同學公眾號內(nèi)回復[?666?]自取。技術(shù)群快滿了,想進的同學可以加我好友,和大佬們一起吹吹技術(shù)。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?你的每個贊和在看,我都喜歡!

