
CV新手避坑指南:計(jì)算機(jī)視覺(jué)常見(jiàn)的8個(gè)錯(cuò)誤
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自:機(jī)器學(xué)習(xí)實(shí)驗(yàn)室
人類(lèi)并不是完美的,我們經(jīng)常在編寫(xiě)軟件的時(shí)候犯錯(cuò)誤。有時(shí)這些錯(cuò)誤很容易找到:你的代碼根本不工作,你的應(yīng)用程序會(huì)崩潰。但有些 bug 是隱藏的,很難發(fā)現(xiàn),這使它們更加危險(xiǎn)。
在處理深度學(xué)習(xí)問(wèn)題時(shí),由于某些不確定性,很容易產(chǎn)生此類(lèi)錯(cuò)誤:很容易看到 web 應(yīng)用的端點(diǎn)路由請(qǐng)求是否正確,但卻不容易檢查梯度下降步驟是否正確。然而,在深度學(xué)習(xí)實(shí)踐例程中有很多 bug 是可以避免的。
我想和大家分享一下我在過(guò)去兩年的計(jì)算機(jī)視覺(jué)工作中所發(fā)現(xiàn)或產(chǎn)生的錯(cuò)誤的一些經(jīng)驗(yàn)。我在會(huì)議上談到過(guò)這個(gè)話題,很多人在會(huì)后告訴我:「是的,老兄,我也有很多這樣的 bug。」我希望我的文章能幫助你避免其中的一些問(wèn)題。
1.翻轉(zhuǎn)圖像和關(guān)鍵點(diǎn)
假設(shè)有人在研究關(guān)鍵點(diǎn)檢測(cè)問(wèn)題。它們的數(shù)據(jù)看起來(lái)像一對(duì)圖像和一系列關(guān)鍵點(diǎn)元組,例如 [(0,1),(2,2)],其中每個(gè)關(guān)鍵點(diǎn)是一對(duì) x 和 y 坐標(biāo)。
讓我們對(duì)這些數(shù)據(jù)進(jìn)行基本的增強(qiáng):
def flip_img_and_keypoints(img: np.ndarray, kpts:Sequence[Sequence[int]]):img = np.fliplr(img)h, w, *_ = img.shapekpts = [(y, w - x) for y, x in kpts]return img, kpts
上面的代碼看起來(lái)很對(duì),是不是?接下來(lái),讓我們對(duì)它進(jìn)行可視化:
image = np.ones((10, 10), dtype=np.float32)kpts = [(0, 1), (2, 2)]image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)img1 = image.copy()for y, x in kpts:img1[y, x] = 0img2 = image_flipped.copy()for y, x in kpts_flipped:img2[y, x] = 0_ = plt.imshow(np.hstack((img1, img2)))
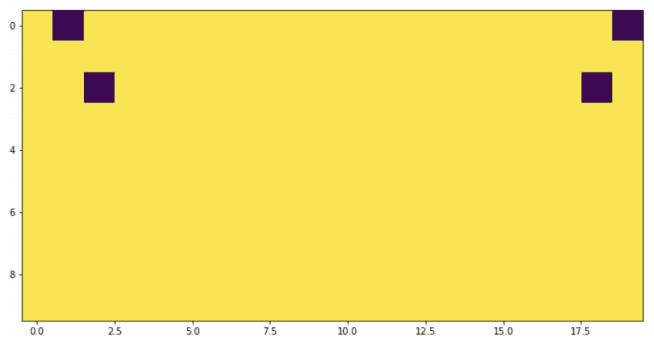
這個(gè)圖是不對(duì)稱(chēng)的,看起來(lái)很奇怪!如果我們檢查極值呢?
image = np.ones((10, 10), dtype=np.float32)kpts = [(0, 0), (1, 1)]image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)img1 = image.copy()for y, x in kpts:img1[y, x] = 0img2 = image_flipped.copy()for y, x in kpts_flipped:img2[y, x] = 0-------------------------------------------------------------------- -------IndexErrorTraceback (most recent call last)<ipython-input-5-997162463eae> in <module>8 img2 = image_flipped.copy()9 for y, x in kpts_flipped:---> 10 img2[y, x] = 0IndexError: index 10 is out of bounds for axis 1 with size 10
不好!這是一個(gè)典型的錯(cuò)誤。正確的代碼如下:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):img = np.fliplr(img)h, w, *_ = img.shapekpts = [(y, w - x - 1) for y, x in kpts]return img, kpts
我們已經(jīng)通過(guò)可視化檢測(cè)到這個(gè)問(wèn)題,但是,使用 x=0 點(diǎn)的單元測(cè)試也會(huì)有幫助。一個(gè)有趣的事實(shí)是:我們團(tuán)隊(duì)三個(gè)人(包括我自己)各自獨(dú)立地犯了幾乎相同的錯(cuò)誤。
2.繼續(xù)談?wù)勱P(guān)鍵點(diǎn)
即使上述函數(shù)已修復(fù),也存在危險(xiǎn)。接下來(lái)更多的是關(guān)于語(yǔ)義,而不僅僅是一段代碼。
假設(shè)一個(gè)人需要用兩只手掌來(lái)增強(qiáng)圖像。看起來(lái)很安全——手在左右翻轉(zhuǎn)后會(huì)還是手。

但是等等!我們對(duì)關(guān)鍵點(diǎn)語(yǔ)義一無(wú)所知。如果關(guān)鍵點(diǎn)真的是這樣的意思呢:
kpts = [(20, 20), # left pinky(20, 200), # right pinky...]
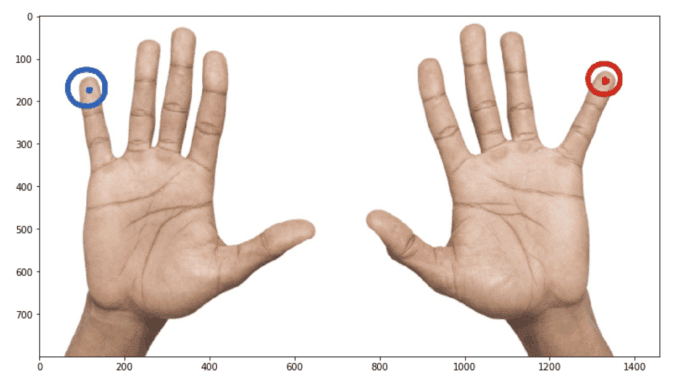
這意味著增強(qiáng)實(shí)際上改變了語(yǔ)義:left 變?yōu)?right,right 變?yōu)?left,但是我們不交換數(shù)組中的 keypoints 索引。它會(huì)給訓(xùn)練帶來(lái)巨大的噪音和更糟糕的指標(biāo)。
這里應(yīng)該吸取教訓(xùn):
在應(yīng)用增強(qiáng)或其他特性之前,了解并考慮數(shù)據(jù)結(jié)構(gòu)和語(yǔ)義;
保持你的實(shí)驗(yàn)的獨(dú)立性:添加一個(gè)小的變化(例如,一個(gè)新的轉(zhuǎn)換),檢查它是如何進(jìn)行的,如果分?jǐn)?shù)提高了再合并。
3.自定義損失函數(shù)
熟悉語(yǔ)義分割問(wèn)題的人可能知道 IoU (intersection over union)度量。不幸的是,我們不能直接用 SGD 來(lái)優(yōu)化它,所以一個(gè)常見(jiàn)的技巧是用可微損失函數(shù)來(lái)逼近它。讓我們編寫(xiě)相關(guān)代碼!
def iou_continuous_loss(y_pred, y_true):eps = 1e-6def _sum(x):return x.sum(-1).sum(-1)numerator = (_sum(y_true * y_pred) + eps)denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2) -_sum(y_true * y_pred) + eps)return (numerator / denominator).mean()
看起來(lái)很不錯(cuò),讓我們做一個(gè)小小的檢查:
In [3]: ones = np.ones((1, 3, 10, 10))...: x1 = iou_continuous_loss(ones * 0.01, ones)...: x2 = iou_continuous_loss(ones * 0.99, ones)In [4]: x1, x2Out[4]: (0.010099999897990103, 0.9998990001020204)
在 x1 中,我們計(jì)算了與標(biāo)準(zhǔn)答案完全不同的損失,x2 是非常接近標(biāo)準(zhǔn)答案的函數(shù)的結(jié)果。我們預(yù)計(jì) x1 會(huì)很大,因?yàn)轭A(yù)測(cè)結(jié)果并不好,x2 應(yīng)該接近于零。這其中發(fā)生了什么?
上面的函數(shù)是度量的一個(gè)很好的近似。度量不是損失:它通常越高越好。因?yàn)槲覀円?SGD 把損失降到最低,我們真的應(yīng)該采用用相反的方法:
def iou_continuous(y_pred, y_true):eps = 1e-6def _sum(x):return x.sum(-1).sum(-1)numerator = (_sum(y_true * y_pred) + eps)denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2)- _sum(y_true * y_pred) + eps)return (numerator / denominator).mean()def iou_continuous_loss(y_pred, y_true):return 1 - iou_continuous(y_pred, y_true)
這些問(wèn)題可以通過(guò)兩種方式確定:
編寫(xiě)一個(gè)單元測(cè)試來(lái)檢查損失的方向:形式化地表示一個(gè)期望,即更接近實(shí)際的東西應(yīng)該輸出更低的損失;
做一個(gè)全面的檢查,嘗試過(guò)擬合你的模型的 batch。
4.使用 Pytorch
假設(shè)一個(gè)人有一個(gè)預(yù)先訓(xùn)練好的模型,并且是一個(gè)時(shí)序模型。我們基于 ceevee api 編寫(xiě)預(yù)測(cè)類(lèi)。
from ceevee.base import AbstractPredictorclass MySuperPredictor(AbstractPredictor):def __init__(self, weights_path: str, ):super().__init__()self.model = self._load_model(weights_path=weights_path)def process(self, x, *kw):with torch.no_grad():res = self.model(x)return res@staticmethoddef _load_model(weights_path):model = ModelClass()weights = torch.load(weights_path, map_location='cpu')model.load_state_dict(weights)return model
這個(gè)代碼正確嗎?也許吧!對(duì)某些模型來(lái)說(shuō)確實(shí)是正確的。例如,當(dāng)模型沒(méi)有規(guī)范層時(shí),例如 torch.nn.BatchNorm2d;或者當(dāng)模型需要為每個(gè)圖像使用實(shí)際的 norm 統(tǒng)計(jì)信息時(shí)(例如,許多基于 pix2pix 的架構(gòu)需要它)。
但是對(duì)于大多數(shù)計(jì)算機(jī)視覺(jué)應(yīng)用程序來(lái)說(shuō),代碼遺漏了一些重要的東西:切換到評(píng)估模式。
如果試圖將動(dòng)態(tài) pytorch 圖轉(zhuǎn)換為靜態(tài) pytorch 圖,則很容易識(shí)別此問(wèn)題。有一個(gè) torch.jit 模塊是用于這種轉(zhuǎn)換的。
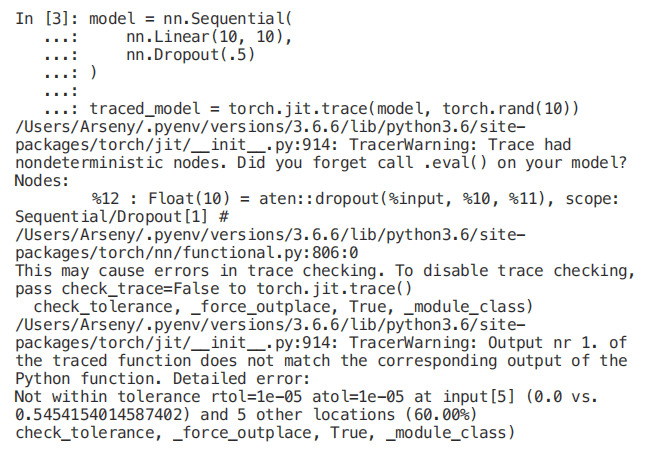
一個(gè)簡(jiǎn)單的修復(fù):
In [4]: model = nn.Sequential(...: nn.Linear(10, 10),...: nn.Dropout(.5)...: )...:...: traced_model = torch.jit.trace(model.eval(), torch.rand(10))# No more warnings!
此時(shí),torch.jit.trace 多次運(yùn)行模型并比較結(jié)果。這里看起來(lái)似乎沒(méi)有區(qū)別。然而,這里的 torch.jit.trace 不是萬(wàn)能的。這是一種應(yīng)該知道并記住的細(xì)微差別。
5.復(fù)制粘貼問(wèn)題
很多東西都是成對(duì)存在的:訓(xùn)練和驗(yàn)證、寬度和高度、緯度和經(jīng)度……如果仔細(xì)閱讀,你可以很容易地發(fā)現(xiàn)由一對(duì)成員之間的復(fù)制粘貼引起的錯(cuò)誤:
def make_dataloaders(train_cfg, val_cfg, batch_size):train = Dataset.from_config(train_cfg)val = Dataset.from_config(val_cfg)shared_params = {'batch_size': batch_size, 'shuffle': True,'num_workers': cpu_count()}train = DataLoader(train, **shared_params)val = DataLoader(train, **shared_params)return train, val
不僅僅是我犯了愚蠢的錯(cuò)誤。在流行庫(kù)中也有類(lèi)似的錯(cuò)誤。
#https://github.com/albu/albumentations/blob/0.3.0/albumentations/aug mentations/transforms.pydef apply_to_keypoint(self, keypoint, crop_height=0, crop_width=0, h_start=0, w_start= 0, rows=0, cols=0, **params):keypoint = F.keypoint_random_crop(keypoint, crop_height, crop_width, h_start, w_start, rows, cols)scale_x = self.width / crop_heightscale_y = self.height / crop_heightkeypoint = F.keypoint_scale(keypoint, scale_x, scale_y)return keypoint
別擔(dān)心,這個(gè)錯(cuò)誤已經(jīng)修復(fù)了。如何避免?不要復(fù)制粘貼代碼,盡量以不要以復(fù)制粘貼的方式進(jìn)行編碼。
datasets = []data_a = get_dataset(MyDataset(config['dataset_a']), config['shared_param'], param_a) datasets.append(data_a)data_b = get_dataset(MyDataset(config['dataset_b']), config['shared_param'], param_b) datasets.append(data_b)datasets = []for name, param in zip(('dataset_a', 'dataset_b'), (param_a, param_b), ):datasets.append(get_dataset(MyDataset(config[name]), config['shared_param'], param))
6.合適的數(shù)據(jù)類(lèi)型
讓我們?cè)僮鲆粋€(gè)增強(qiáng):
def add_noise(img: np.ndarray) -> np.ndarray:mask = np.random.rand(*img.shape) + .5img = img.astype('float32') * maskreturn img.astype('uint8')

圖像已經(jīng)改變了。這是我們期望的嗎?嗯,也許改變太多了。這里有一個(gè)危險(xiǎn)的操作:將 float32 轉(zhuǎn)到 uint8。這可能導(dǎo)致溢出:
def add_noise(img: np.ndarray) -> np.ndarray:mask = np.random.rand(*img.shape) + .5img = img.astype('float32') * maskreturn np.clip(img, 0, 255).astype('uint8')img = add_noise(cv2.imread('two_hands.jpg')[:, :, ::-1]) _ = plt.imshow(img)
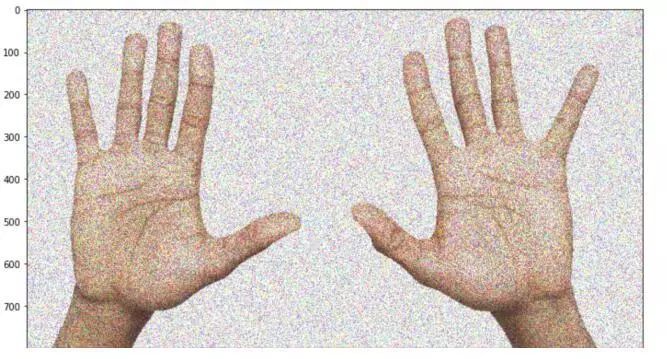
看起來(lái)好多了,是吧?順便說(shuō)一句,還有一個(gè)方法可以避免這個(gè)問(wèn)題:不要重新發(fā)明輪子,可以在前人的基礎(chǔ)上,修改代碼。例如:albumentations.augmentations.transforms.GaussNoise 。我又產(chǎn)生了同樣來(lái)源的 bug。

這里出了什么問(wèn)題?首先,使用三次插值調(diào)整 mask 的大小是個(gè)壞主意。將 float32 轉(zhuǎn)換為 uint8 也存在同樣的問(wèn)題:三次插值可以輸出大于輸入的值,并導(dǎo)致溢出。

我發(fā)現(xiàn)了這個(gè)問(wèn)題。在你的循環(huán)里面有斷言也是一個(gè)好主意。
7.打字錯(cuò)誤
假設(shè)需要對(duì)全卷積網(wǎng)絡(luò)(如語(yǔ)義分割問(wèn)題)和一幅巨大的圖像進(jìn)行處理。圖像太大了,你沒(méi)有機(jī)會(huì)把它放進(jìn)你的 gpu 中——例如,它可以是一個(gè)醫(yī)學(xué)或衛(wèi)星圖像。
在這種情況下,可以將圖像分割成一個(gè)網(wǎng)格,獨(dú)立地對(duì)每一塊進(jìn)行推理,最后合并。另外,一些預(yù)測(cè)交集可以用來(lái)平滑邊界附近的偽影。
我們來(lái)編碼吧!
from tqdm import tqdmclass GridPredictor:""" This class can be used to predict a segmentation mask for the big image when you have GPU memory limitation """def __init__(self, predictor: AbstractPredictor, size: int, stride: Optional[int] = None):self.predictor = predictorself.size = sizeself.stride = stride if stride is not None else size // 2def __call__(self, x: np.ndarray):h, w, _ = x.shapemask = np.zeros((h, w, 1), dtype='float32')weights = mask.copy()for i in tqdm(range(0, h - 1, self.stride)):for j in range(0, w - 1, self.stride):a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)patch = x[a:b, c:d, :]mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1) weights[a:b, c:d, :] = 1return mask / weights
有一個(gè)符號(hào)輸入錯(cuò)誤,代碼片段足夠大,因此可以很容易地找到它。我懷疑僅僅通過(guò)代碼就可以快速識(shí)別它,很容易檢查代碼是否正確:
class Model(nn.Module):def forward(self, x):return x.mean(axis=-1)model = Model()grid_predictor = GridPredictor(model, size=128, stride=64)simple_pred = np.expand_dims(model(img), -1)grid_pred = grid_predictor(img)np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)

調(diào)用方法的正確版本如下:
def __call__(self, x: np.ndarray):h, w, _ = x.shapemask = np.zeros((h, w, 1), dtype='float32')weights = mask.copy()for i in tqdm(range(0, h - 1, self.stride)):for j in range(0, w - 1, self.stride): a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)patch = x[a:b, c:d, :]mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1)weights[a:b, c:d, :] += 1return mask / weights
如果你仍然沒(méi)有看出問(wèn)題所在,請(qǐng)注意線寬 [a:b,c:d,:]+=1。
8.ImageNet 規(guī)范化
當(dāng)一個(gè)人需要進(jìn)行遷移學(xué)習(xí)時(shí),通常最好像訓(xùn)練 ImageNet 時(shí)那樣對(duì)圖像進(jìn)行標(biāo)準(zhǔn)化。
讓我們使用我們已經(jīng)熟悉的 albumentations 庫(kù)。
from albumentations import Normalizenorm = Normalize()img = cv2.imread('img_small.jpg')mask = cv2.imread('mask_small.png', cv2.IMREAD_GRAYSCALE)mask = np.expand_dims(mask, -1) # shape (64, 64) -> shape (64, 64, 1)normed = norm(image=img, mask=mask)img, mask = [normed[x] for x in ['image', 'mask']]def img_to_batch(x):x = np.transpose(x, (2, 0, 1)).astype('float32')return torch.from_numpy(np.expand_dims(x, 0))img, mask = map(img_to_batch, (img, mask))criterion = F.binary_cross_entropy
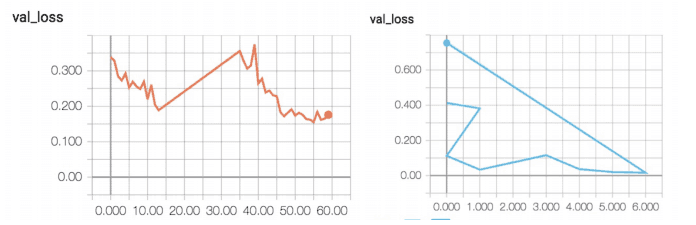
現(xiàn)在是時(shí)候訓(xùn)練一個(gè)網(wǎng)絡(luò)并使其過(guò)擬合某一張圖像了——正如我所提到的,這是一種很好的調(diào)試技術(shù):
model_a = UNet(3, 1)optimizer = torch.optim.Adam(model_a.parameters(), lr=1e-3)losses = []for t in tqdm(range(20)):loss = criterion(model_a(img), mask)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()_ = plt.plot(losses)
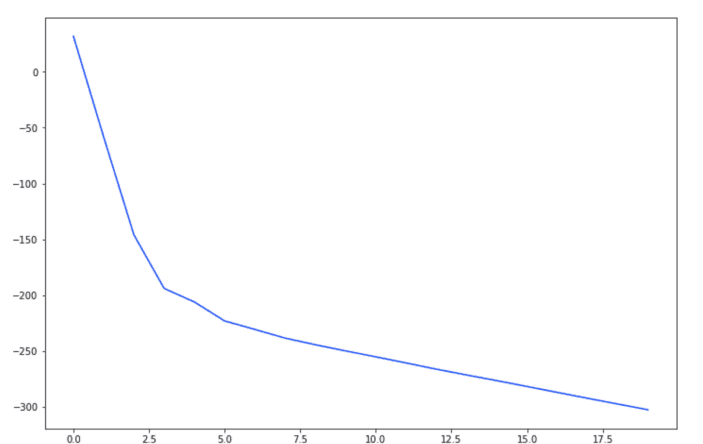
曲率看起來(lái)很好,但交叉熵的損失值預(yù)計(jì)不會(huì)是 -300。這是怎么了?圖像的標(biāo)準(zhǔn)化效果很好,需要手動(dòng)將其縮放到 [0,1]。
model_b = UNet(3, 1)optimizer = torch.optim.Adam(model_b.parameters(), lr=1e-3)losses = []for t in tqdm(range(20)):loss = criterion(model_b(img), mask / 255.)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()_ = plt.plot(losses)
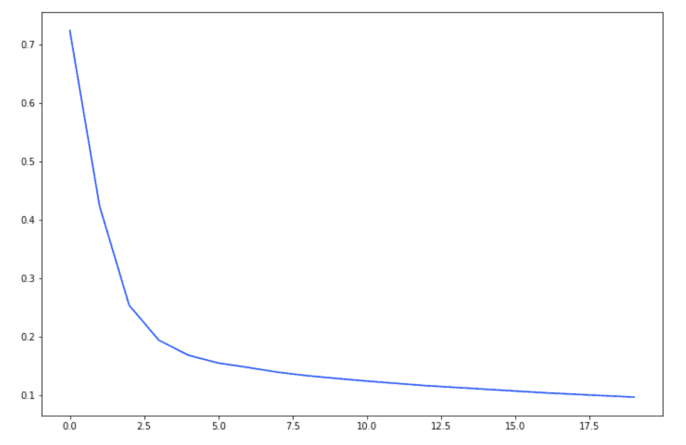
訓(xùn)練循環(huán)中一個(gè)簡(jiǎn)單的斷言(例如 assert mask.max()<=1)會(huì)很快檢測(cè)到問(wèn)題。同樣,單元測(cè)試也可以檢測(cè)到問(wèn)題。
原文鏈接:
https://medium.com/@arseny_info/8-deep-learning-computer-vision-bugs-and-how-i-could-have-avoided-them-d40b0e4b1da
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱(chēng)+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~