
數(shù)據(jù)庫(kù)分庫(kù)分表的應(yīng)用場(chǎng)景及解決方案
作者:末日攜手(來(lái)自:CSDN博客)
原文鏈接:
https://blog.csdn.net/yang_guang3/article/details/83347479
現(xiàn)實(shí)業(yè)務(wù)場(chǎng)景中,為了保障客戶體驗(yàn)并滿足業(yè)務(wù)的線性增長(zhǎng)。會(huì)對(duì)數(shù)據(jù)量巨大,且業(yè)務(wù)會(huì)始終進(jìn)行的產(chǎn)品進(jìn)行分表分庫(kù)策略。但是如何合理的根據(jù)業(yè)務(wù)采取爭(zhēng)取的分表分庫(kù)策略至關(guān)重要。下面以具體實(shí)例來(lái)進(jìn)行分析。
場(chǎng)景一:用戶中心數(shù)據(jù)庫(kù)切分架構(gòu)實(shí)踐|場(chǎng)景介紹
? ? 用戶中心是一個(gè)十分常見(jiàn)的業(yè)務(wù)系統(tǒng),涵蓋用戶登錄、注冊(cè)、信息查詢與修改等服務(wù)。
??????用戶的核心元數(shù)據(jù)為:
?????? User(uid,login_name,nickname,password,sex,age)
??????其中?? ●???uid :用戶ID,主鍵
??????????????? ●??? login_name,nickname,password,sex,age :用戶的其他屬性
在業(yè)務(wù)初期,單表單庫(kù)就能滿足業(yè)務(wù)需求:
 場(chǎng)景一:用戶中心數(shù)據(jù)庫(kù)切分方法|范圍法
場(chǎng)景一:用戶中心數(shù)據(jù)庫(kù)切分方法|范圍法
? 當(dāng)數(shù)據(jù)量越來(lái)越大時(shí),需要對(duì)數(shù)據(jù)庫(kù)進(jìn)行水平切分,常見(jiàn)的切分算法有“范圍法”和“哈希法”。
?????? 范圍法:以用戶中心的業(yè)務(wù)uid為劃分依據(jù),將數(shù)據(jù)水平切分到兩個(gè)數(shù)據(jù)庫(kù)實(shí)例上去:
?? ??
范圍法的優(yōu)點(diǎn)是:
? 切分策略簡(jiǎn)單,根據(jù)uid,按照范圍,user- center很快能夠定位到數(shù)據(jù)在哪個(gè)庫(kù)上
? 擴(kuò)容簡(jiǎn)單,如果容量不夠,只要增加user-db3即可
范圍法的不足是:
? uid必須要滿足遞增的特性
? 數(shù)據(jù)量不均,新增的user-db3,在初期的數(shù)據(jù)會(huì)比較少
? 請(qǐng)求量不均,一般來(lái)說(shuō),新注冊(cè)的用戶活躍度會(huì)比較高,故user-db2往往會(huì)比user-db1負(fù)載要高,導(dǎo)致服務(wù)器利用率不平衡
場(chǎng)景一:用戶中心數(shù)據(jù)庫(kù)切分方法|哈希法
哈希法:以用戶中心的業(yè)務(wù)uid為劃分依據(jù),將數(shù)據(jù)水平切分到兩個(gè)數(shù)據(jù)庫(kù)實(shí)例上去:

哈希法的優(yōu)點(diǎn)是:
?切分策略簡(jiǎn)單,根據(jù)uid,按照范圍,user- center很快能夠定位到數(shù)據(jù)在哪個(gè)庫(kù)上
?數(shù)據(jù)量均衡:只要uid是均衡的,數(shù)據(jù)在各個(gè)庫(kù)上的分布一定是均衡的
?請(qǐng)求量均衡:只要uid是均衡的,負(fù)載在各個(gè)庫(kù)上的分布一定是均衡的
哈希法的不足是:
?擴(kuò)容麻煩,如果需要增加一個(gè)庫(kù),需要重新hash,這有可能會(huì)導(dǎo)致數(shù)據(jù)遷移,給平滑升級(jí)帶來(lái)困難。
場(chǎng)景一:用戶中心數(shù)據(jù)查詢需求分析
? ?任何脫離業(yè)務(wù)的架構(gòu)設(shè)計(jì)都是耍流氓,在進(jìn)行架構(gòu)討論之前,首先要對(duì)業(yè)務(wù)進(jìn)行簡(jiǎn)要分析,看看表結(jié)構(gòu)上有哪些查詢需求。
? ?根據(jù)業(yè)務(wù)經(jīng)驗(yàn),用戶中心往往有以下幾類業(yè)務(wù)需求:
??(1)用戶側(cè),前臺(tái)訪問(wèn),最典型的有兩類需求
???????用戶登錄:通過(guò)login_name/email/phone查詢用戶實(shí)體,1%的請(qǐng)求屬于這種類型。
???????用戶信息查詢:登錄之后,通過(guò)uid來(lái)查詢用戶的實(shí)例,99%請(qǐng)求屬于這種類型。
? ? ? ?用戶側(cè)查詢的基本特點(diǎn)是:基本是單條記錄查詢,訪問(wèn)量大,服務(wù)要求高可用,并且對(duì)一致性要求較高。
??(2)運(yùn)營(yíng)側(cè),后臺(tái)訪問(wèn)。
? ? ? ?需要滿足產(chǎn)品及運(yùn)營(yíng)層面的各類需求,訪問(wèn)模式各異,按照年齡、性別、登錄時(shí)間、注冊(cè)時(shí)間等屬性來(lái) 進(jìn)行查詢。運(yùn)營(yíng)側(cè)需求的的基本特點(diǎn)是:大量的批量分頁(yè)查詢需求,訪問(wèn)量較低,對(duì)可用性要求不高,對(duì)一致性的要求也沒(méi)有這么嚴(yán)格。
場(chǎng)景一:用戶中心數(shù)據(jù)查詢需求解決方案-用戶側(cè)
1.索引表法:
? 思路:uid可以直接定位到數(shù)據(jù)庫(kù),login_name不可以直接定位到庫(kù)。建立login_name到login_id的映射關(guān)系。
??解決方案:
? ? ? ?? 建立一個(gè)索引表記錄login_name->uid的映射關(guān)系
? ? ? ?? 用login_name來(lái)訪問(wèn)時(shí),先通過(guò)索引表查詢到uid,再定位相應(yīng)的庫(kù)
? ? ? ?? 索引表屬性較少,可以容納非常多數(shù)據(jù),一般不需要分庫(kù)
? ? ? ?? 如果數(shù)據(jù)量過(guò)大,可以通過(guò)login_name來(lái)分庫(kù)
??不足:多一次數(shù)據(jù)庫(kù)查詢,性能下降一倍。
2.緩存映射法:
? ?思路:訪問(wèn)索引表的性能比較低。將映射放在緩存中可以獲得更好的性能體驗(yàn)。
? ?解決方案:
? ? ? ?? login_name查詢先到cache中查詢uid,再根據(jù)uid定位數(shù)據(jù)庫(kù)
? ? ? ?? 假設(shè)cachemiss,采用掃全庫(kù)法獲取login_name對(duì)應(yīng)的uid,放入cache
? ? ? ?? login_name到uid的映射關(guān)系不會(huì)變化,映射關(guān)系一旦放入緩存,不會(huì)更改,無(wú)需淘汰,緩存命中率超高
? ? ? ?? 如果數(shù)據(jù)量過(guò)大,可以通過(guò)login_name進(jìn)行cache水平切分
? ?不足:多一次cache查詢。
3.login_name生成uid
? ? 思路:不進(jìn)行遠(yuǎn)程查詢,由login_name直接得到uid
? ??解決方案:
? ? ? ? 在用戶注冊(cè)時(shí),設(shè)計(jì)函數(shù)login_name生成uid,uid=f(login_name),按uid分庫(kù)插入數(shù)據(jù)
? ? ? ? 用login_name進(jìn)行登錄時(shí),先通過(guò)函數(shù)計(jì)算出uid,再由uid路由到對(duì)應(yīng)數(shù)據(jù)庫(kù)進(jìn)行查詢。
? ??不足:對(duì)login_name到uid的生成函數(shù)要求較高,有uid生成沖突的風(fēng)險(xiǎn)
4.login_name基因融入uid
? ? 思路:從login_name抽取“基因” 融入uid中。

? ?解決方案:
? ? ? ? 在用戶注冊(cè)時(shí),設(shè)計(jì)函數(shù)login_name生成4bit基因,login_name_gene=f(login_name),如上圖粉色部分
? ? ? ? 同時(shí),生成60bit的全局唯一id,作為用戶的標(biāo)識(shí),如上圖綠色部分
? ? ? ? 接著把4bit的login_name_gene也作為uid的一部分,如上圖屎黃色部分
? ? ? ? 生成64bit的uid,由id和login_name_gene拼裝而成,并按照uid分庫(kù)插入數(shù)據(jù)
? ? ? ? 用login_name來(lái)訪問(wèn)時(shí),先通過(guò)函數(shù)由login_name再次復(fù)原4bit基因,login_name_gene=f(login_name),通過(guò)login_name_gene%8直接定位到庫(kù)。
場(chǎng)景一:用戶中心數(shù)據(jù)查詢需求解決方案-運(yùn)營(yíng)側(cè)
?后臺(tái)運(yùn)營(yíng)側(cè)的查詢需求各異,基本是批量的分頁(yè)查詢,計(jì)算量和返回?cái)?shù)據(jù)量較大,比較消耗數(shù)據(jù)庫(kù)性能。
此時(shí)如果后臺(tái)業(yè)務(wù)和前臺(tái)業(yè)務(wù)共用一批服務(wù)和同一個(gè)數(shù)據(jù)庫(kù)。有可能會(huì)導(dǎo)致后臺(tái)少數(shù)幾個(gè)請(qǐng)求的批量查詢的低效訪問(wèn)造成數(shù)據(jù)庫(kù)服務(wù)器cpu瞬時(shí)100%,影響前臺(tái)用戶的正常訪問(wèn)。
另外,由于后臺(tái)業(yè)務(wù)的查詢需求多種多樣,需要在數(shù)據(jù)庫(kù)上建立多種索引,這些索引會(huì)占用大量的內(nèi)存和磁盤(pán),從而造成前臺(tái)業(yè)務(wù)的uid/login_name的查詢和寫(xiě)入性能大幅度降低,處理時(shí)間增長(zhǎng)。
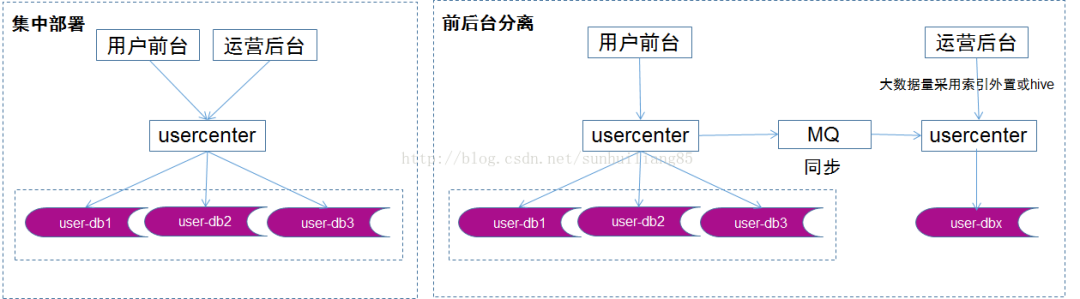
對(duì)這一類業(yè)務(wù),應(yīng)該采用“前后臺(tái)分離”的架構(gòu)方案:
場(chǎng)景二:訂單中心數(shù)據(jù)查詢需求分析
? ? 還是那句話,任何脫離業(yè)務(wù)的架構(gòu)設(shè)計(jì)都是耍流氓,在進(jìn)行架構(gòu)討論之前,首先要對(duì)業(yè)務(wù)進(jìn)行簡(jiǎn)要分析,看看表結(jié)構(gòu)上有哪些查詢需求。
? ? 根據(jù)業(yè)務(wù)經(jīng)驗(yàn),訂單中心往往有以下幾類業(yè)務(wù)需求:
???(1)用戶側(cè),前臺(tái)訪問(wèn),最典型的有三類需求
????????訂單實(shí)體查詢:通過(guò)oid查詢訂單實(shí)體,90%都是這種需求。
????????用戶訂單列表查詢:通過(guò)buyer_id分頁(yè)查詢用戶歷史訂單列表,9%流量屬于這種需求。
????????商家訂單列表查詢:通過(guò)seller_uid分頁(yè)查詢商家歷史訂單列表,1%流量屬于這類需求。??????????
? ? ? ? 前臺(tái)訪問(wèn)的特點(diǎn)是:吞吐量大,服務(wù)要求高可用,對(duì)一致性要求較高。其中商家對(duì)一致性要求較低,可以接受一定程度的延遲。
? ?(2)運(yùn)營(yíng)側(cè),后臺(tái)訪問(wèn)。
根據(jù)產(chǎn)品、運(yùn)營(yíng)需求,訪問(wèn)模式各異:按照時(shí)間,架構(gòu),商品和詳情來(lái)進(jìn)行查詢
? ? ? ? 后臺(tái)訪問(wèn)的特點(diǎn):運(yùn)營(yíng)側(cè)的查詢基本上是批量的分頁(yè)查詢,訪問(wèn)量低,對(duì)可用性一致性的要求不高,允許秒甚至十秒級(jí)別的查詢延遲。
場(chǎng)景二:訂單中心數(shù)據(jù)查詢需求解決方案
后臺(tái)運(yùn)營(yíng)側(cè)的查詢需求各異,基本是批量的分頁(yè)查詢,計(jì)算量和返回?cái)?shù)據(jù)量較大,比較消耗數(shù)據(jù)庫(kù)性能。
此時(shí)如果后臺(tái)業(yè)務(wù)和前臺(tái)業(yè)務(wù)共用一批服務(wù)和同一個(gè)數(shù)據(jù)庫(kù)。有可能會(huì)導(dǎo)致后臺(tái)少數(shù)幾個(gè)請(qǐng)求的批量查詢的低效訪問(wèn)造成數(shù)據(jù)庫(kù)服務(wù)器cpu瞬時(shí)100%,影響前臺(tái)用戶的正常訪問(wèn)。
對(duì)這一類業(yè)務(wù),應(yīng)該采用“前后臺(tái)分離”的架構(gòu)方案:前臺(tái)業(yè)務(wù)架構(gòu)不變,站點(diǎn)訪問(wèn),服務(wù)分層,數(shù)據(jù)庫(kù)水平切分。
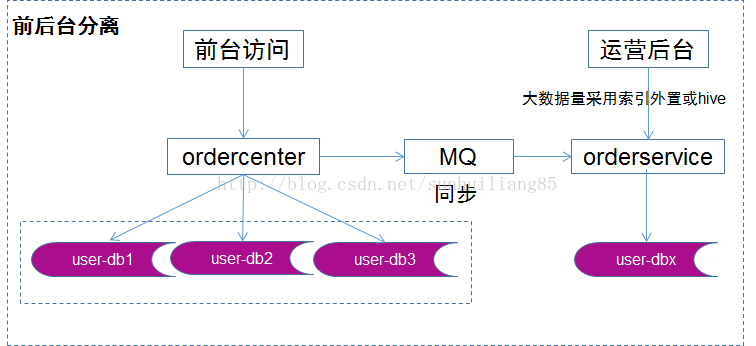
場(chǎng)景二:訂單中心數(shù)據(jù)庫(kù)切分方法
? ? 明確了訂單中心的訪問(wèn)需求后,問(wèn)題轉(zhuǎn)化為,前臺(tái)的oid,buyer_id,seller_id如何來(lái)進(jìn)行數(shù)據(jù)庫(kù)的水平切分呢?
??????需要同時(shí)滿足以下條件:
????? 1.根據(jù)buyer_uid%n,可以定位到數(shù)據(jù)庫(kù)
????? 2.根據(jù)oid%n,可以定位到數(shù)據(jù)庫(kù)
????? 3.根據(jù)seller_uid%n,可以定位到數(shù)據(jù)庫(kù)
???? 以上業(yè)務(wù)是一個(gè)1:N(1個(gè)買家:N個(gè)訂單)和N:N(1個(gè)買家:N個(gè)賣家, 1個(gè)賣家:N個(gè)買家)的業(yè)務(wù)場(chǎng)景,對(duì)于“多對(duì)多”的業(yè)務(wù),水平切分應(yīng)該使用“數(shù)據(jù)冗余法”
場(chǎng)景二:訂單中心數(shù)據(jù)庫(kù)切分方法
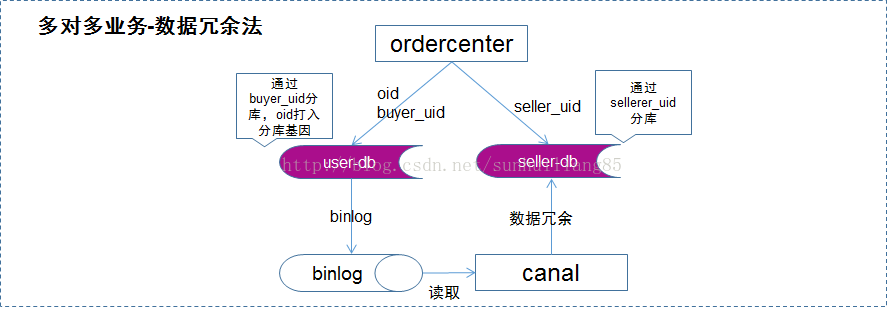
? ? ?? 當(dāng)有訂單生成時(shí),通過(guò)buyer_uid分庫(kù),oid中融入分庫(kù)基因,寫(xiě)入DB-buyer庫(kù)
? ? ?? 通過(guò)線下異步的方式,通過(guò)binlog+canal,將數(shù)據(jù)冗余到DB-seller庫(kù)中
? ? ?? buyer庫(kù)通過(guò)buyer_uid分庫(kù),seller庫(kù)通過(guò)seller_uid分庫(kù),前者滿足oid和buyer_uid的查詢需求,后者滿足seller_uid的查詢需求。
場(chǎng)景二:訂單中心數(shù)據(jù)庫(kù)切分方法|數(shù)據(jù)冗余法
為什么要冗余數(shù)據(jù)?
互聯(lián)網(wǎng)數(shù)據(jù)量很大的業(yè)務(wù)場(chǎng)景,往往數(shù)據(jù)庫(kù)需要進(jìn)行水平切分來(lái)降低單庫(kù)數(shù)據(jù)量。
水平切分會(huì)有一個(gè)patitionkey,通過(guò)patition key的查詢能夠直接定位到庫(kù),但是非patitionkey上的查詢可能就需要掃描多個(gè)庫(kù)了。
此時(shí)常見(jiàn)的架構(gòu)設(shè)計(jì)方案,是使用數(shù)據(jù)冗余這種反范式設(shè)計(jì)來(lái)滿足分庫(kù)后不同維度的查詢需求。
例如:訂單業(yè)務(wù),對(duì)用戶和商家都有訂單查詢需求:
Order(oid,info_detail);
T(buyer_uid,seller_uid,oid);
如果用buyer_uid來(lái)分庫(kù),seller_uid的查詢就需要掃描多庫(kù)。
如果用seller_uid來(lái)分庫(kù),buyer_uid的查詢就需要掃描多庫(kù)。
此時(shí)可以使用數(shù)據(jù)冗余來(lái)分別滿足buyer_uid和seller_uid上的查詢需求:
T1(buyer_uid,seller_uid,oid)
T2(seller_uid,buyer_uid,oid)
同一個(gè)數(shù)據(jù),冗余兩份,一份以buyer_uid來(lái)分庫(kù),滿足買家的查詢需求;一份以seller_uid來(lái)分庫(kù),滿足賣家的查詢需求。
場(chǎng)景二:訂單中心數(shù)據(jù)庫(kù)切分方法|如何實(shí)現(xiàn)數(shù)據(jù)冗余
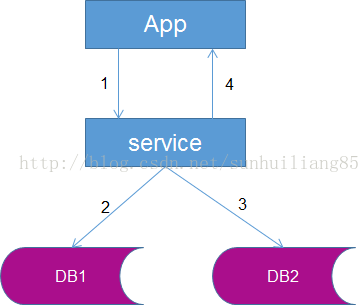
1.服務(wù)同步雙寫(xiě)
??服務(wù)同步雙寫(xiě),即由服務(wù)層同步寫(xiě)冗余數(shù)據(jù)。
?? 流程如右圖:
?? (1)業(yè)務(wù)應(yīng)用代用服務(wù)層,寫(xiě)入數(shù)據(jù)
?? (2)服務(wù)層將數(shù)據(jù)寫(xiě)入DB1
?? (3)服務(wù)層將數(shù)據(jù)寫(xiě)入DB2
?? (4)服務(wù)層返回新增數(shù)據(jù)成功給業(yè)務(wù)應(yīng)用
優(yōu)點(diǎn):
?簡(jiǎn)單,服務(wù)層由單寫(xiě),改為兩次寫(xiě)人
?數(shù)據(jù)一致性較高,雙寫(xiě)成功后才返回
缺點(diǎn):
? 因?yàn)橛蓡螌?xiě)變?yōu)榱藘纱螌?xiě)入,請(qǐng)求時(shí)間增長(zhǎng)
? 數(shù)據(jù)仍有可能不一致(數(shù)據(jù)寫(xiě)入DB1后,服務(wù)宕機(jī)或重啟,則數(shù)據(jù)無(wú)法寫(xiě)人DB2)
3.線下異步雙寫(xiě)
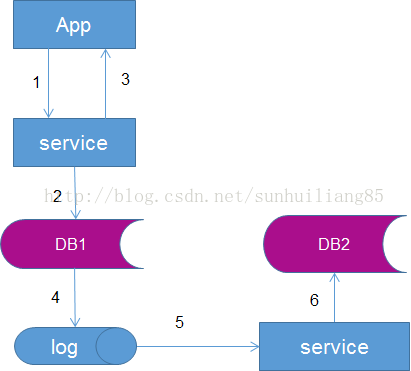
?? 為了屏蔽“復(fù)雜性”,數(shù)據(jù)雙寫(xiě)由線下服務(wù)或者任務(wù)來(lái)完成,不再由服務(wù)層完成。
流程如右圖:
?? (1)業(yè)務(wù)應(yīng)用代用服務(wù)層,寫(xiě)入數(shù)據(jù)
?? (2)服務(wù)層將數(shù)據(jù)寫(xiě)入DB1
?? (3)服務(wù)層返回新增數(shù)據(jù)成功給業(yè)務(wù)應(yīng)用
?? (4)數(shù)據(jù)會(huì)被寫(xiě)入到數(shù)據(jù)庫(kù)的log中
?? (5)線下服務(wù)或者任務(wù)讀取數(shù)據(jù)庫(kù)log
?? (6)線下服務(wù)或者任務(wù)插入T2數(shù)據(jù)
優(yōu)點(diǎn):
?數(shù)據(jù)雙寫(xiě)與業(yè)務(wù)完全解耦
?請(qǐng)求處理時(shí)間短
缺點(diǎn):
?返回業(yè)務(wù)新增成功時(shí),會(huì)存在一個(gè)數(shù)據(jù)不一致的時(shí)間窗口,但能保證最終一致性
?數(shù)據(jù)一致性依賴于線下服務(wù)或者任務(wù)的可凹陷