
使用PyTorch實現(xiàn)對花朵的分類
PyTorch是一個非常適合初學者的高度可靠且強大的機器學習庫。自2016年10月以來,它已經(jīng)開源并由Facebook維護,并被開發(fā)人員用于研究其原型,以部署最先進的深度學習應用程序。與TensorFlow等其他機器學習庫相比,PyTorch更加直觀,并具有實現(xiàn)模型的Python方式。
 決定要分類什么?
決定要分類什么?
識別花朵的類型需要某種形式關于花朵的知識,人必須事先看過花朵才能識別花朵。同樣,對于計算機,很難對算法進行硬編碼以識別花朵的類型。到目前為止,機器學習是從給定的大量花朵圖片中識別花朵名稱的唯一選擇。這使得使用深度學習實現(xiàn)花識別任務對于每個初學者來說都非常有趣。

花朵識別數(shù)據(jù)集對于像我這樣的初學者而言,是一個很好的數(shù)據(jù)集,可用于實施和練習各種機器學習模型。
使用什么數(shù)據(jù)集?
我們將使用Kaggle上可用的花朵識別數(shù)據(jù)集。數(shù)據(jù)集鏈接:https ://www.kaggle.com/alxmamaev/flowers-recognition
預處理數(shù)據(jù)集
我們將使用神經(jīng)網(wǎng)絡對花朵進行分類。神經(jīng)網(wǎng)絡是深度學習的一種形式,最適合當今的圖像分類。我們首先導入所有需要的模塊以運行我們的代碼。
import numpy as np # linear algebraimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import osimport torchimport torchvisionfrom torchvision.datasets.utils import download_urlfrom torch.utils.data import random_splitfrom torchvision.datasets import ImageFolderfrom torchvision import transformsfrom torchvision.transforms import ToTensorfrom torch.utils.data.dataloader import DataLoaderimport torch.nn as nnimport torch.nn.functional as F
我們導入了PyTorch的組件以及NumPy和Pandas等數(shù)據(jù)科學庫。圖片是非結構化數(shù)據(jù),為了將其輸入到我們的深度學習模型中,我們必須將其轉(zhuǎn)換為張量。我們需要對圖像進行預處理,然后才能為模型做好準備。我們首先使用ImageFolder 存在于torchvision.datasets 來準備數(shù)據(jù)集。ImageFolder是一個非常有用的工具當圖像存儲在不同的文件夾中,其中每個文件夾都充當類名。PyTorch還具有其他更簡單的準備數(shù)據(jù)集的方式,我們可以在其中準備自己的自定義數(shù)據(jù)集。
transformer = torchvision.transforms.Compose([ # Applying Augmentationtorchvision.transforms.Resize((224, 224)),torchvision.transforms.RandomHorizontalFlip(p=0.5),torchvision.transforms.RandomVerticalFlip(p=0.5),torchvision.transforms.RandomRotation(30),torchvision.transforms.ToTensor(),torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])dataset = ImageFolder(base_dir, transform=transformer)
我們還習慣于transforms.Compose將圖像轉(zhuǎn)換為張量并應用其他圖像增強技術。此外,在將各種圖像加載到數(shù)據(jù)集時,請閱讀各種變換技術并應用于圖像。我們應該使用程序加載圖像,以便可以每次分批添加數(shù)據(jù)集,并且可以優(yōu)化效率。
定義模型
我們可以使用從PyTorch類繼承的類來定義深度學習模型的框架?nn.Module.
def accuracy(outputs, labels): _, preds = torch.max(outputs, dim=1)return torch.tensor(torch.sum(preds == labels).item() / len(preds))class ImageClassificationModel(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef __init__(self):super().__init__()self.network = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 64 x 16 x 16nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 128 x 8 x 8nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),nn.MaxPool2d(2, 2), # output: 256 x 4 x 4nn.Flatten(),nn.Linear(256*28*28, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 5))def forward(self, xb):return self.network(xb)def validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(????????????epoch,?result['train_loss'],?result['val_loss'],?result['val_ac']))
訓練模型
首先訓練模型,讓我們將超參數(shù)設置為:
num_epochs = 10opt_func = torch.optim.Adamlr = 0.001
現(xiàn)在,在將模型運行10個epoach后,我們可以看到使用基本的卷積神經(jīng)網(wǎng)絡(CNN)模型達到了約65%。
測試模型
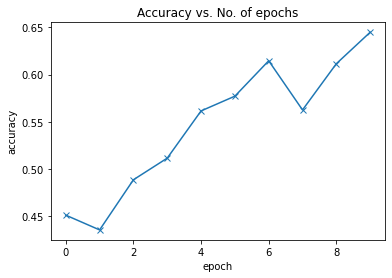
65%是一個很好的結果,因為我以前曾嘗試過使用帶有一些隱藏層的簡單神經(jīng)網(wǎng)絡(NN),結果僅為40%左右。因此,CNN非常適合對圖像進行分類,因為它們有比其他形式的機器學習更好的檢測模式。
使用轉(zhuǎn)移學習
現(xiàn)在讓我們再次嘗試使用已經(jīng)定義的模型(如Resnet-18)進行轉(zhuǎn)移學習,以改善模型的預測。使用相同的超參數(shù)集,我們的測試集中可以達到82%左右,這是非常令人印象深刻的。如果我們使用其他更好的CNN架構,例如Resnet50,Inception V3等,則可以進一步改善結果。
plot_accuracies(history)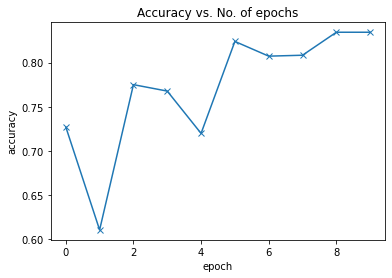
保存模型
訓練完成后,我們必須保存我們的模型,以便我們可以使用它來根據(jù)模型生成預測,甚至將來可以進行更多訓練。
weights_fname = 'flower-resnet.pth'torch.save(model.state_dict(), weights_fname)
產(chǎn)生預測
每個機器學習周期的目標是創(chuàng)建一個可被用于對常規(guī)數(shù)據(jù)進行分類的模型。這可以通過幾行python代碼為最終用戶實現(xiàn)模型。
def predict_image(img, model):# Convert to a batch of 1xb = to_device(img.unsqueeze(0), device)# Get predictions from modelyb = model(xb)# Pick index with highest probability_, preds = torch.max(yb, dim=1)# Retrieve the class labelreturn dataset.classes[preds[0].item()]img, label = test_ds[2]plt.imshow(img.permute(1, 2, 0))print('Label:', dataset.classes[label], ', Predicted:', predict_image(img, model))Label: sunflower , Predicted: sunflower

我們還可以使用服務器上的模型來識別花朵的類型。該模型可以輕松部署在服務器上,以供最終用戶識別不同類型的花朵。
·? END? ·