
Data Fabric,下一個(gè)風(fēng)口?

導(dǎo)讀:Data Fabric,又名數(shù)據(jù)經(jīng)緯,是近期橫空出世的一個(gè)概念。之前對(duì)其了解甚少,近期做了個(gè)小調(diào)研,對(duì)這一概念內(nèi)涵與外延、產(chǎn)品及定位、業(yè)務(wù)與前景、未來(lái)及趨勢(shì)等做了簡(jiǎn)單整理總結(jié),分享給大家。

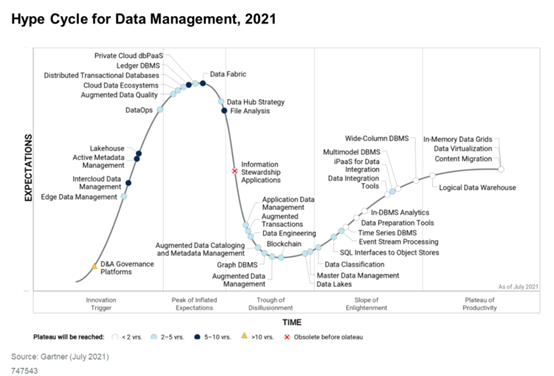


激增的暗數(shù)據(jù)&數(shù)據(jù)孤島
低效的數(shù)據(jù)交付方式
日益嚴(yán)峻的數(shù)據(jù)質(zhì)量問(wèn)題
不斷擴(kuò)大的安全合規(guī)風(fēng)險(xiǎn)
在過(guò)去的十年里,數(shù)據(jù)和應(yīng)用孤島的數(shù)量激增,而數(shù)據(jù)和分析(D&A)團(tuán)隊(duì)的技能型人才數(shù)量卻保持不變,甚至下降。作為一種跨平臺(tái)和業(yè)務(wù)用戶的靈活、彈性數(shù)據(jù)整合方式,Data Fabric能夠簡(jiǎn)化企業(yè)機(jī)構(gòu)的數(shù)據(jù)整合基礎(chǔ)設(shè)施并創(chuàng)建一個(gè)可擴(kuò)展架構(gòu),減少大多數(shù)數(shù)據(jù)和分析團(tuán)隊(duì)因整合難度上升而出現(xiàn)的技術(shù)債務(wù)。 其真正價(jià)值在于:通過(guò)內(nèi)置的分析技術(shù)動(dòng)態(tài)改進(jìn)數(shù)據(jù)的使用,使數(shù)據(jù)管理工作量減少70%并加快價(jià)值實(shí)現(xiàn)時(shí)間。 Gartner最新預(yù)測(cè)顯示,至2024年,Data Fabric可減少50%人力數(shù)據(jù)管理成本,與此同時(shí),數(shù)據(jù)使用效率會(huì)因Data Fabric的部署使用伴隨著數(shù)據(jù)類型日益多樣化、數(shù)據(jù)孤島不斷林立、數(shù)據(jù)結(jié)構(gòu)愈加復(fù)雜,企業(yè)在分布式數(shù)據(jù)環(huán)境中高效管理和利用多維數(shù)據(jù)成為亟待解決的難題。 與此同時(shí),企業(yè)上云成為一大趨勢(shì),混合數(shù)據(jù)環(huán)境下企業(yè)該如何跨平臺(tái)、跨環(huán)境,以實(shí)時(shí)的速度收集、訪問(wèn)、管理、共享數(shù)據(jù),從不斷變化、高度關(guān)聯(lián)、卻又四處分散的數(shù)據(jù)中獲得可執(zhí)行洞見,實(shí)現(xiàn)智能化決策?面對(duì)上述數(shù)據(jù)管理難題,Data Fabric提出了一套治理“良方”。 Data Fabric是一種新興的數(shù)據(jù)集成和管理理念,意在獨(dú)立于部署平臺(tái)、數(shù)據(jù)流程、地理位置和架構(gòu)方法,在不移動(dòng)數(shù)據(jù)位置的前提下,為企業(yè)內(nèi)的所有數(shù)據(jù)提供單一訪問(wèn)點(diǎn),保證數(shù)據(jù)使用端在正確的時(shí)間、正確的地點(diǎn)以實(shí)時(shí)的速度拿到正確的數(shù)據(jù)。
連接數(shù)據(jù),而非集中數(shù)據(jù)
自助服務(wù),而非專家服務(wù)
主動(dòng)智能,而非被動(dòng)人工
萬(wàn)物鏈接,而非簡(jiǎn)單替代
5. 關(guān)聯(lián)對(duì)比

API 的訪問(wèn)方式不同。Data Mesh是面向開發(fā)同學(xué)、API驅(qū)動(dòng)的解決方案,需要為API編寫實(shí)現(xiàn)代碼,而Data Fabric相反,其通過(guò)低代碼、無(wú)代碼的方式進(jìn)行設(shè)計(jì),API集成在架構(gòu)內(nèi)進(jìn)行實(shí)現(xiàn),而不是直接使用它。 思想不同。雖然Data Fabric和Data Mesh 都提供了跨技術(shù)、跨平臺(tái)的使用數(shù)據(jù)的架構(gòu),但前者以技術(shù)為中心,是將多種技術(shù)進(jìn)行組合使用,由 AI/ML 驅(qū)動(dòng)的增強(qiáng)和自動(dòng)化、智能元數(shù)據(jù)基礎(chǔ)和強(qiáng)大的技術(shù)骨干(即云原生、基于微服務(wù)、API 驅(qū)動(dòng)、可互操作和彈性)支持,更多的是關(guān)于管理數(shù)據(jù)技術(shù)(集成架構(gòu)),而后者則側(cè)重于組織結(jié)構(gòu)和文化變革來(lái)實(shí)現(xiàn)敏捷性,可以在于技術(shù)無(wú)關(guān)的框架內(nèi)指導(dǎo)方案設(shè)計(jì),各數(shù)據(jù)領(lǐng)域團(tuán)隊(duì)可以在更理解其所管理的數(shù)據(jù)的基礎(chǔ)下實(shí)現(xiàn)相應(yīng)的數(shù)據(jù)產(chǎn)品的交付,更多的是管理人員和流程。 數(shù)據(jù)產(chǎn)品的實(shí)現(xiàn)思路不同。Data Mesh 將數(shù)據(jù)的產(chǎn)品思維作為核心設(shè)計(jì)原則,其數(shù)據(jù)是分布式的,每類數(shù)據(jù)都是一個(gè)獨(dú)立的域(即數(shù)據(jù)產(chǎn)品),存儲(chǔ)在對(duì)應(yīng)的組織中,而Data Fabric所有的數(shù)據(jù)都會(huì)集中在一個(gè)位置(物理集中或虛擬集中),對(duì)外提供能力。其實(shí),基于數(shù)據(jù)虛擬化集成技術(shù)的Data Fabric,其數(shù)據(jù)也是分布式的,通過(guò)虛擬邏輯數(shù)據(jù)模型對(duì)外統(tǒng)一提供數(shù)據(jù)使用。 數(shù)據(jù)資產(chǎn)的自動(dòng)化方式不同。Data Fabric利用基于豐富的企業(yè)元數(shù)據(jù)基礎(chǔ)(例如知識(shí)圖)來(lái)發(fā)現(xiàn)、連接、識(shí)別、建議和向數(shù)據(jù)消費(fèi)者提供數(shù)據(jù)資產(chǎn)的自動(dòng)化,而Data Mesh則依賴于數(shù)據(jù)產(chǎn)品/域所有者來(lái)推動(dòng)數(shù)據(jù)需求。 依賴關(guān)系不同。Data Fabric無(wú)需依賴Data Mesh的實(shí)踐即可實(shí)施,而Data Mesh則必須利用Data Fabric來(lái)支持?jǐn)?shù)據(jù)對(duì)象和產(chǎn)品的驗(yàn)證。 自動(dòng)化程度不同。Data Fabric鼓勵(lì)增強(qiáng)數(shù)據(jù)管理和跨平臺(tái)編排,以最大限度地減少人工設(shè)計(jì)、部署和維護(hù)工作。Data Mesh則傾向于對(duì)現(xiàn)有系統(tǒng)的手動(dòng)設(shè)計(jì)和編排,由業(yè)務(wù)領(lǐng)域執(zhí)行持續(xù)維護(hù)。 解決方案的成熟度不同。成熟度上看,Data Fabric目前被廣泛應(yīng)用于各種數(shù)據(jù)應(yīng)用場(chǎng)景,而Data Mesh仍然處在一個(gè)未開發(fā)的階段。
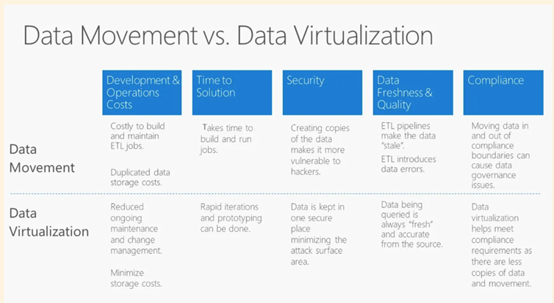
數(shù)據(jù)虛擬化技術(shù)
數(shù)據(jù)集成
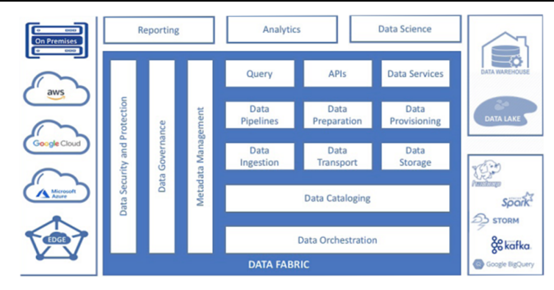
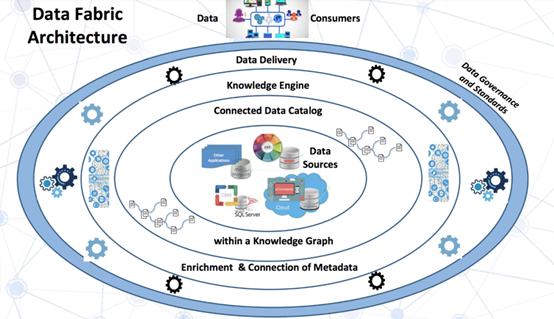
更快地適應(yīng)業(yè)務(wù)
更好的洞察力
更有效地消除孤島
更低的成本和實(shí)施風(fēng)險(xiǎn)
更高效的業(yè)務(wù)協(xié)作
更安全的業(yè)務(wù)
1)Forrester 定義的能力要求
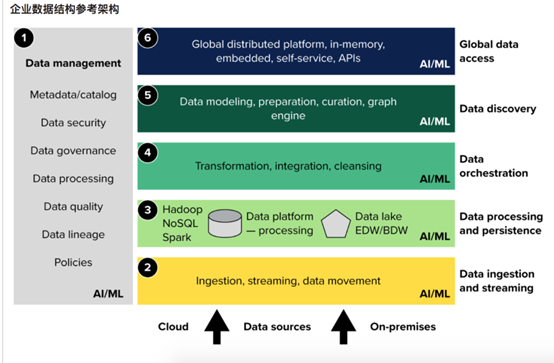
數(shù)據(jù)管理
數(shù)據(jù)攝取和流式傳輸
數(shù)據(jù)處理和持久化
數(shù)據(jù)編排
數(shù)據(jù)發(fā)現(xiàn)
數(shù)據(jù)訪問(wèn)
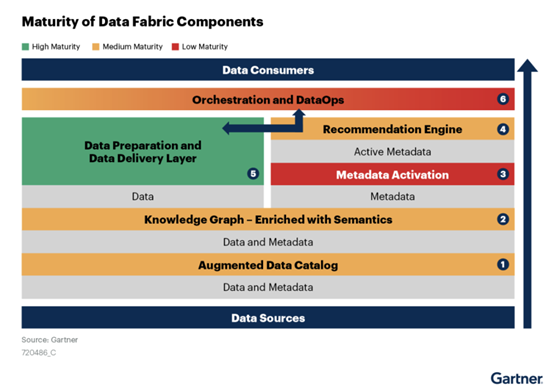
增強(qiáng)數(shù)據(jù)目錄
語(yǔ)義知識(shí)圖譜
主動(dòng)元數(shù)據(jù)
推薦引擎
數(shù)據(jù)準(zhǔn)備和數(shù)據(jù)交付
數(shù)據(jù)編排和DataOps
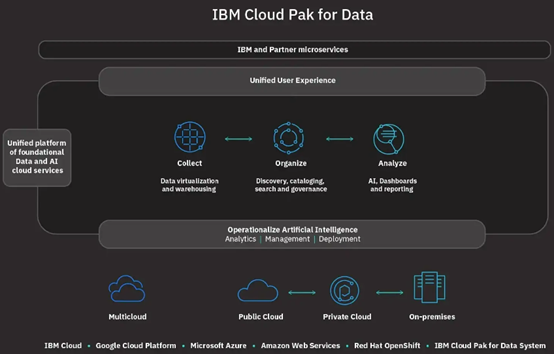
AutoCatalog:元數(shù)據(jù)的管理是挖掘數(shù)據(jù)價(jià)值,把各個(gè)不同來(lái)源的數(shù)據(jù)很好利用起來(lái)的重要技術(shù)環(huán)節(jié)。AutoCatalog 可以看成是 IBM 研發(fā) AI 賦能的分類大腦,可以根據(jù)發(fā)現(xiàn)數(shù)據(jù)和分類的流程實(shí)現(xiàn)自動(dòng)化,進(jìn)行自動(dòng)分類之后建立自動(dòng)化目錄,維護(hù)來(lái)自不同數(shù)據(jù)環(huán)境數(shù)據(jù)資產(chǎn)的 Dynamic 的實(shí)時(shí)目錄。 AutoAI:AutoAI 的主要功能是盡量降低 AI 模型開發(fā)、模型校正、模型自我重新培訓(xùn)的技術(shù)門檻和人力付出,從而對(duì)動(dòng)態(tài)的數(shù)據(jù)和整個(gè) AI 本身算法生命的周期進(jìn)行自動(dòng)化。 AutoPrivacy:實(shí)際上 AutoPrivacy 主要是通過(guò)數(shù)據(jù)隱私框架當(dāng)中的關(guān)鍵能力,使用 AI 的能力智能化地識(shí)別企業(yè)內(nèi)部的敏感數(shù)據(jù),當(dāng)被調(diào)用的時(shí)候系統(tǒng)能夠識(shí)別到、監(jiān)控到,甚至在后續(xù)當(dāng)定義敏感數(shù)據(jù)的使用和保護(hù)時(shí),就可以為企業(yè)內(nèi)部的政策實(shí)施自動(dòng)化提供了技術(shù)和智能化的保障。 AutoSQL:因?yàn)槲覀儸F(xiàn)在要解決的問(wèn)題是跨混合多云環(huán)境實(shí)現(xiàn)數(shù)據(jù)訪問(wèn)的自動(dòng)化,當(dāng)寫一個(gè)傳統(tǒng) SQL 的時(shí)候,首先要知道這個(gè)數(shù)據(jù)在什么地方。我們通過(guò) AutoSQL 的技術(shù)來(lái)實(shí)現(xiàn)訪問(wèn)數(shù)據(jù)的自動(dòng)化,無(wú)須物理地移動(dòng)這些數(shù)據(jù),從而提高了數(shù)據(jù)查詢的速度,也降低了使用數(shù)據(jù)的人對(duì)數(shù)據(jù)來(lái)源所需要的了解。
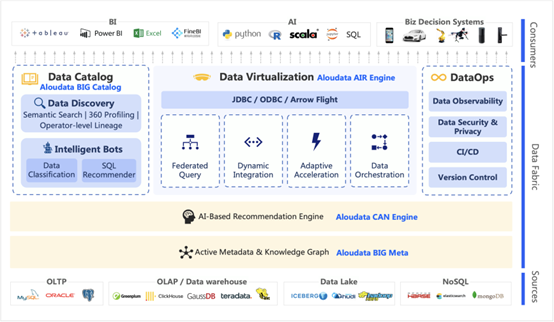
主動(dòng)元數(shù)據(jù)
推薦引擎
增強(qiáng)數(shù)據(jù)目錄
數(shù)據(jù)虛擬化
DataOps

數(shù)據(jù)接入的融合:基于成熟開源組件,穩(wěn)定可靠,兼容MySQL協(xié)議和技術(shù)生態(tài)體系 數(shù)據(jù)存儲(chǔ)的融合:可實(shí)現(xiàn)數(shù)據(jù)多副本、水平彈性伸縮、數(shù)據(jù)一致性、透明高可用、分層解耦融合 數(shù)據(jù)引擎融合:多引擎融合解決數(shù)據(jù)多樣性存儲(chǔ)的橫向打通 數(shù)據(jù)接入的擴(kuò)展:支持信息系統(tǒng)結(jié)構(gòu)化數(shù)據(jù)、工業(yè)物聯(lián)網(wǎng)時(shí)序數(shù)據(jù)、科學(xué)引擎接口數(shù)據(jù)的可擴(kuò)展接入 數(shù)據(jù)輸出的擴(kuò)展:數(shù)據(jù)服務(wù)化要作為數(shù)據(jù)庫(kù)的標(biāo)準(zhǔn)能力 數(shù)據(jù)引擎的擴(kuò)展:針對(duì)數(shù)據(jù)類型與計(jì)算需求可擴(kuò)展至 在線事務(wù)處理、在線分析處理、時(shí)序數(shù)據(jù)處理、全文檢索、知識(shí)庫(kù)等多種引擎

延伸閱讀??

延伸閱讀《數(shù)據(jù)庫(kù)高效優(yōu)化》
作者:馬立和 高振嬌 韓鋒
推薦語(yǔ):本書以大量案例為依托,系統(tǒng)講解了SQL語(yǔ)句優(yōu)化的原理、方法及技術(shù)要點(diǎn),尤為注重實(shí)踐,在章節(jié)中引入了大量的案例,便于學(xué)習(xí)者實(shí)踐、測(cè)試,反復(fù)揣摩。
評(píng)論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>