
Transformer新架構(gòu):DPT!替代卷積網(wǎng)絡(luò)做密集預(yù)測
點擊下方“AI算法與圖像處理”,一起進(jìn)步!
重磅干貨,第一時間送達(dá)
機(jī)器之心編輯部
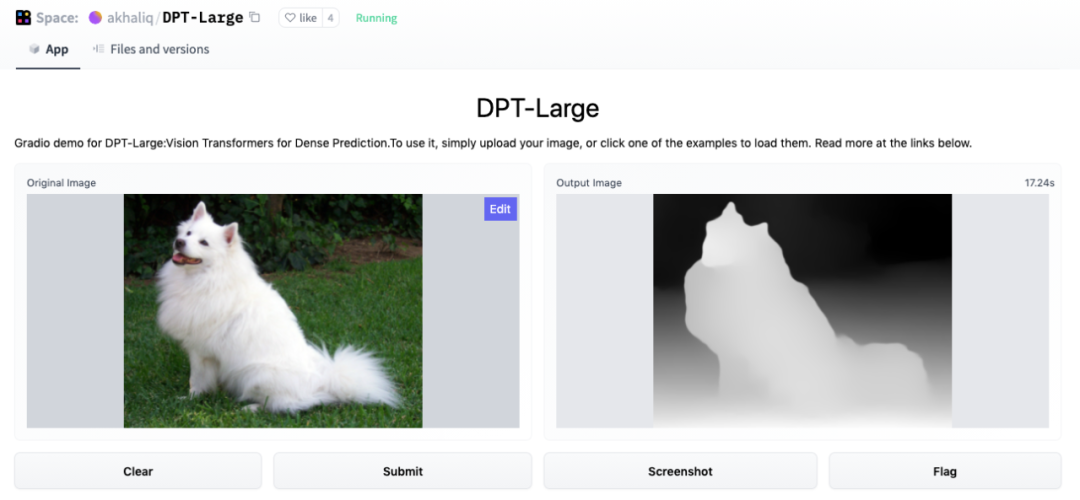
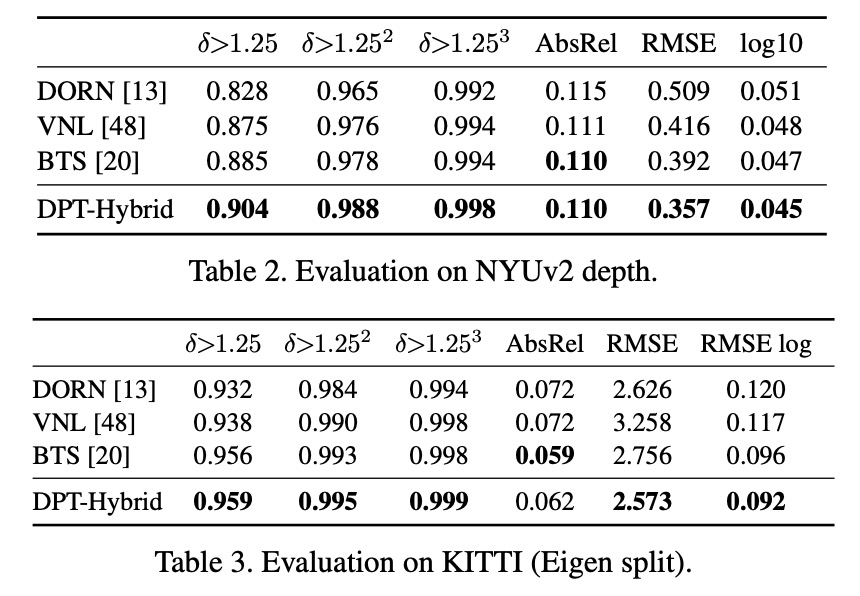
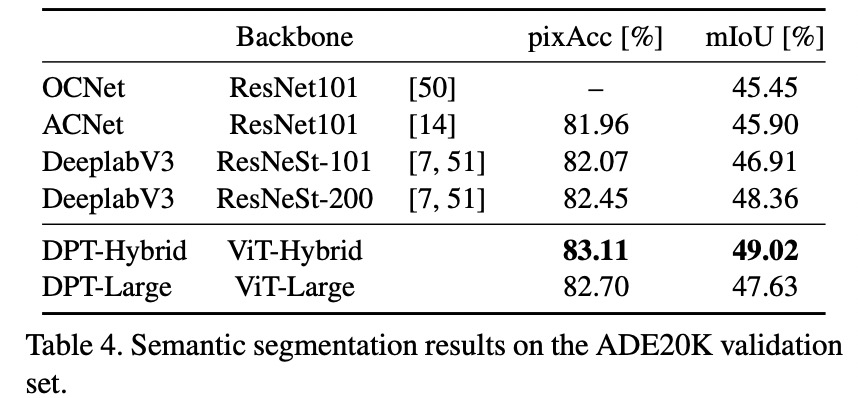
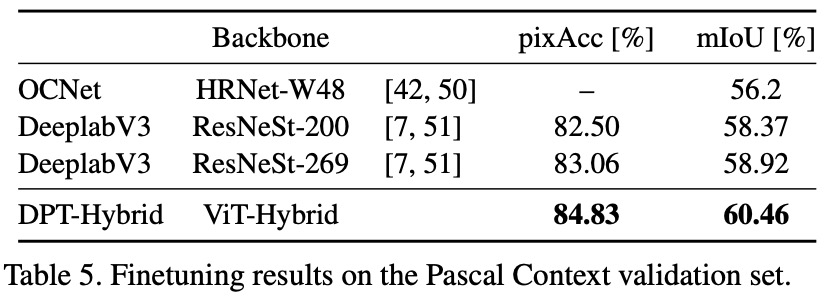
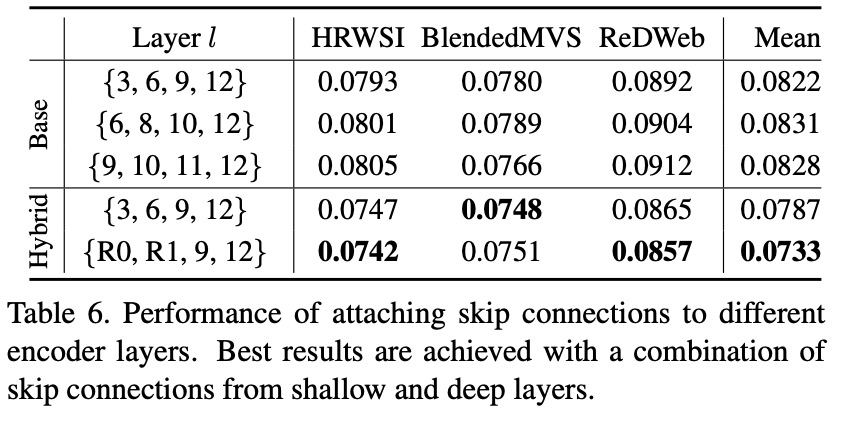
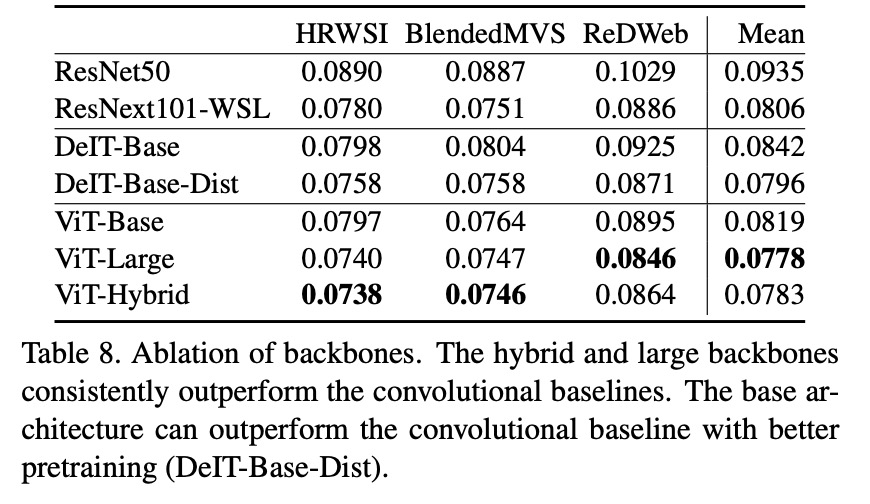
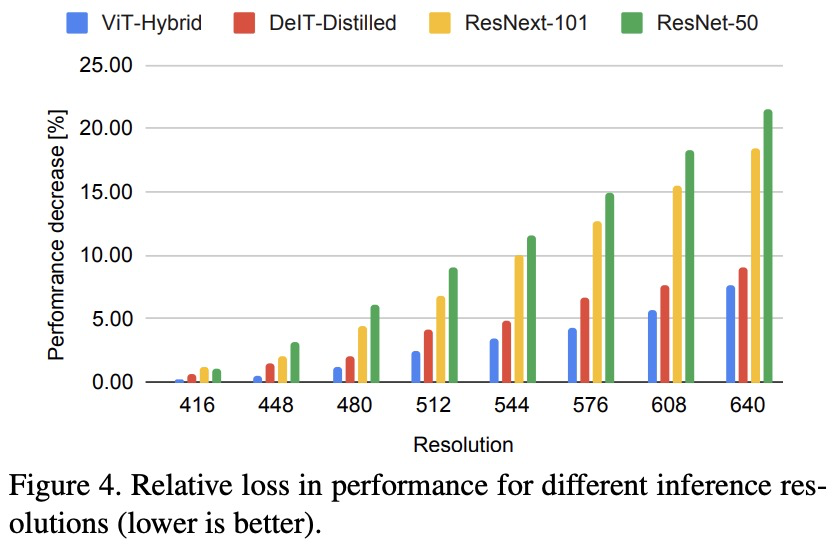
在這項研究中,研究者提出了 DPT 架構(gòu)。這種 ViT 架構(gòu)代替了卷積網(wǎng)絡(luò)作為密集預(yù)測任務(wù)的主干網(wǎng)絡(luò),獲得了更好的細(xì)粒度和更全局一致的預(yù)測。

論文地址:https://arxiv.org/abs/2103.13413
代碼地址:https://github.com/intel-isl/dpt
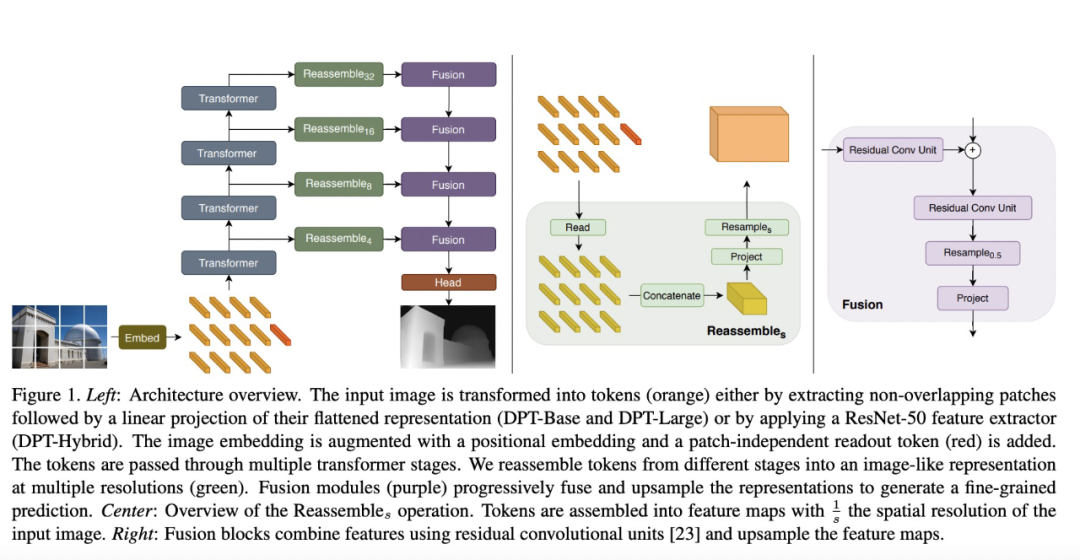
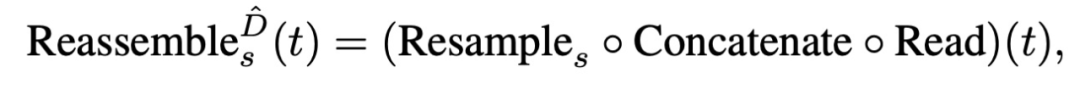
 代表輸出特征維度。
代表輸出特征維度。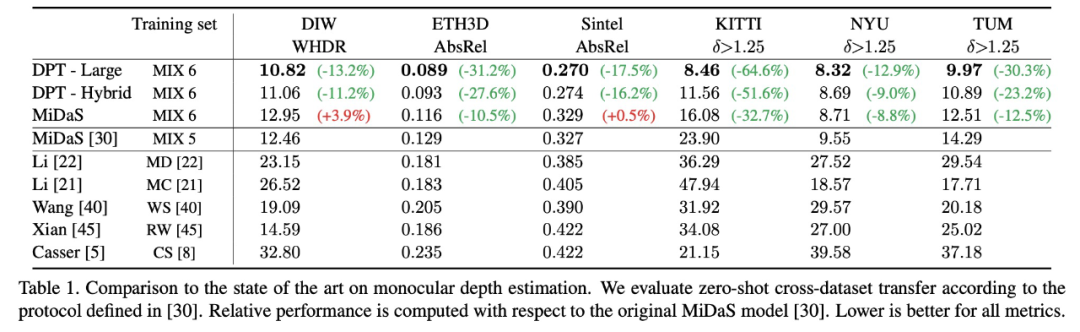



交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR?2020論文 和 CVPR 2021 最新論文

評論
圖片
表情