
如何使用 BERT 進(jìn)行自然語(yǔ)言處理?
點(diǎn)擊上方“視學(xué)算法”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
來(lái)源:AI前線 本文大約7510字,閱讀時(shí)間約10分鐘。 本文介紹并探索了基于 Transformer 架構(gòu)的神經(jīng)網(wǎng)絡(luò)BERT,并介紹了進(jìn)一步了解BERT的若干方法。

 迄今為止,在我們的 ML.NET 之旅中,我們主要關(guān)注計(jì)算機(jī)視覺(jué)問(wèn)題,例如圖像分類(lèi)和目標(biāo)檢測(cè)。在本文中,我們將轉(zhuǎn)向自然語(yǔ)言處理,并探索一些我們可以用機(jī)器學(xué)習(xí)來(lái)解決的問(wèn)題。
迄今為止,在我們的 ML.NET 之旅中,我們主要關(guān)注計(jì)算機(jī)視覺(jué)問(wèn)題,例如圖像分類(lèi)和目標(biāo)檢測(cè)。在本文中,我們將轉(zhuǎn)向自然語(yǔ)言處理,并探索一些我們可以用機(jī)器學(xué)習(xí)來(lái)解決的問(wèn)題。
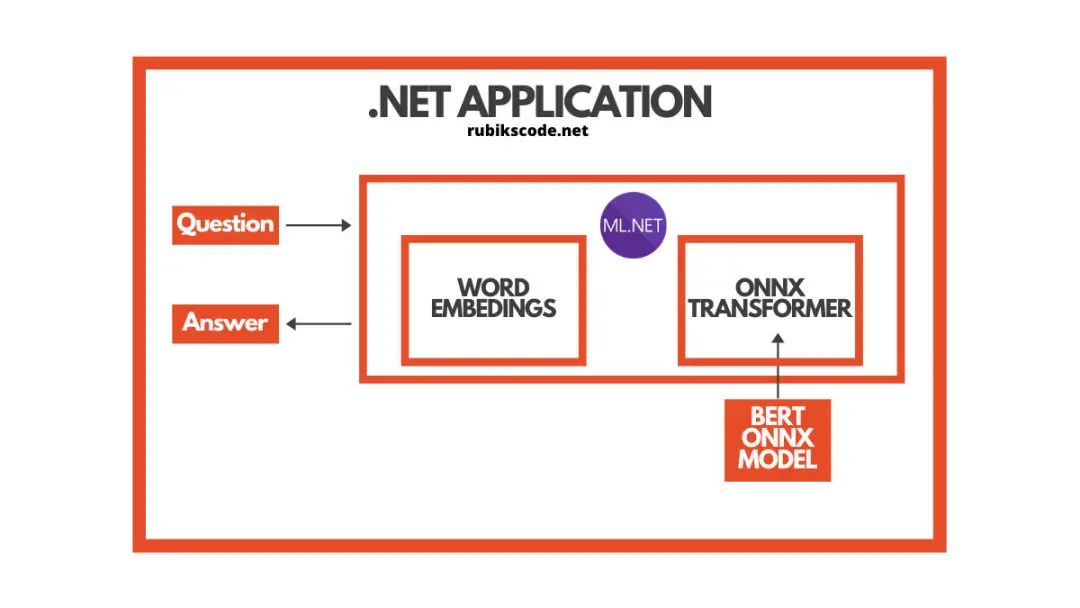
前提 理解 Transformer 架構(gòu) BERT 直覺(jué) ONNX 模型 用 ML.NET 實(shí)現(xiàn)
$ dotnet add package Microsoft.ML
$ dotnet add package Microsoft.ML.OnnxRuntime
$ dotnet add package Microsoft.ML.OnnxTransformer
你可以在 Package Manager Console 中執(zhí)行相同操作:
Install-Package Microsoft.ML
Install-Package Microsoft.ML.OnnxRuntime
Install-Package Microsoft.ML.OnnxTransformer
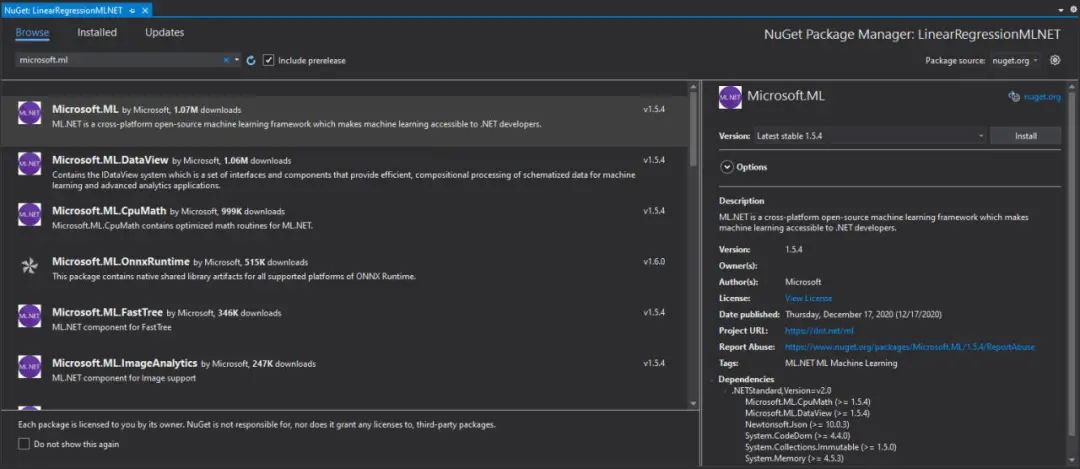
你可以使用 Visual Studio 的 Manage NuGetPackage 選項(xiàng)來(lái)執(zhí)行類(lèi)似操作:
假如你想了解使用 ML.NET 進(jìn)行機(jī)器學(xué)習(xí)的基本知識(shí),請(qǐng)看這篇文章:《使用 ML.NET 進(jìn)行機(jī)器學(xué)習(xí):簡(jiǎn)介》(Machine Learning with ML.NET – Introduction)(https://rubikscode.net/2021/01/04/machine-learning-with-ml-net-introduction/)。
2. 理解Transformer架構(gòu)
語(yǔ)言是順序數(shù)據(jù)。從根本上說(shuō),你可以把它看成是一個(gè)詞流,每個(gè)詞的含義都取決于它前面的詞和后面的詞。因此,計(jì)算機(jī)理解語(yǔ)言非常困難,因?yàn)橐肜斫庖粋€(gè)詞,你需要一個(gè) 上下文。
此外,有時(shí)候作為輸出,還需要提供數(shù)據(jù) 序列(詞)。把英語(yǔ)翻譯成塞爾維亞語(yǔ)就是一個(gè)好例子。我們將詞序列作為算法的輸入,同時(shí)對(duì)輸出也需要提供一個(gè)序列。
本例中,一種算法要求我們理解英語(yǔ),并理解如何將英語(yǔ)單詞映射到塞爾維亞語(yǔ)單詞(實(shí)質(zhì)上,這意味著對(duì)塞爾維亞語(yǔ)也有某種程度的理解)。在過(guò)去的幾年里,已經(jīng)有很多深度學(xué)習(xí)的架構(gòu)用于這種目的,例如遞歸神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)和長(zhǎng)短期記憶網(wǎng)絡(luò)(LSTM)。但是,Transformer 架構(gòu)的使用改變了一切。

由于 RNN 和 LSTM 難以訓(xùn)練,且已出現(xiàn)梯度消失(和爆炸),因此不能完全滿(mǎn)足需求。Transformer 的目的就是解決這些問(wèn)題,帶來(lái)更好的性能和更好的語(yǔ)言理解。它們于 2017 年推出,并被發(fā)表在一篇名為《注意力就是你所需要的一切》(Attention is all you need)(https://arxiv.org/pdf/1706.03762.pdf)的傳奇性論文上。
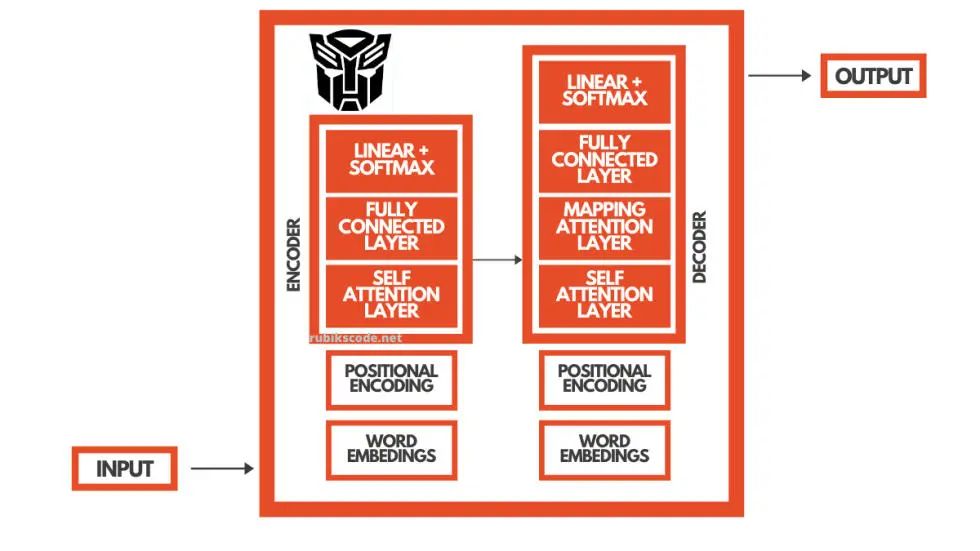
3. BERT直覺(jué)
BERT 使用這種 Transformer 架構(gòu)來(lái)理解語(yǔ)言。更為確切的是,它使用了編碼器。
這個(gè)架構(gòu)有兩大里程碑。首先,它實(shí)現(xiàn)了雙向性。也就是說(shuō),每個(gè)句子都是雙向?qū)W習(xí)的,并且更好地學(xué)習(xí)上下文,包括之前的上下文和將來(lái)的上下文。BERT 是首個(gè)采用純文本語(yǔ)料進(jìn)行訓(xùn)練的深度雙向、無(wú)監(jiān)督的語(yǔ)言表示。這也是最早應(yīng)用于自然語(yǔ)言處理的一種預(yù)訓(xùn)練模型。在計(jì)算機(jī)視覺(jué)中,我們了解了遷移學(xué)習(xí)。但是,在 BERT 出現(xiàn)之前,這一概念就沒(méi)有在自然語(yǔ)言處理領(lǐng)域得到重視。
這有很大的意義,因?yàn)槟憧梢栽诖罅康臄?shù)據(jù)上訓(xùn)練模型,并且一旦模型理解了語(yǔ)言,你就可以根據(jù)更具體的任務(wù)對(duì)它進(jìn)行微調(diào)。因此,BERT 的訓(xùn)練分為兩個(gè)階段:預(yù)訓(xùn)練和微調(diào)。
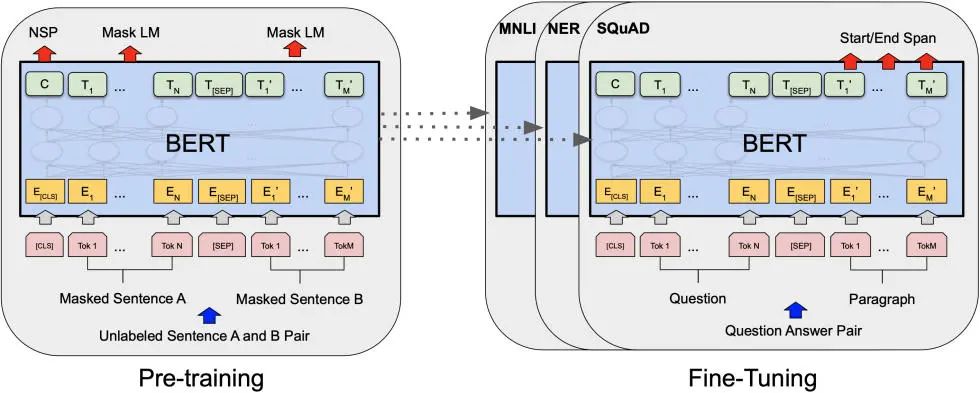
BERT 預(yù)訓(xùn)練采用兩種方法實(shí)現(xiàn)雙向性:
掩碼語(yǔ)言建模:MLM(Masked Language Modeling)
下一句預(yù)測(cè):NSP(Next Sentence Prediction)
掩碼語(yǔ)言建模使用掩碼輸入。這意味著句子中的一些詞被掩碼,BERT 的工作就是填補(bǔ)這些空白。下一句預(yù)測(cè)是給出兩個(gè)句子作為輸入,并期望 BERT 預(yù)測(cè)是一個(gè)句子接著另一個(gè)句子。在現(xiàn)實(shí)中,這兩種方法都是同時(shí)發(fā)生的。
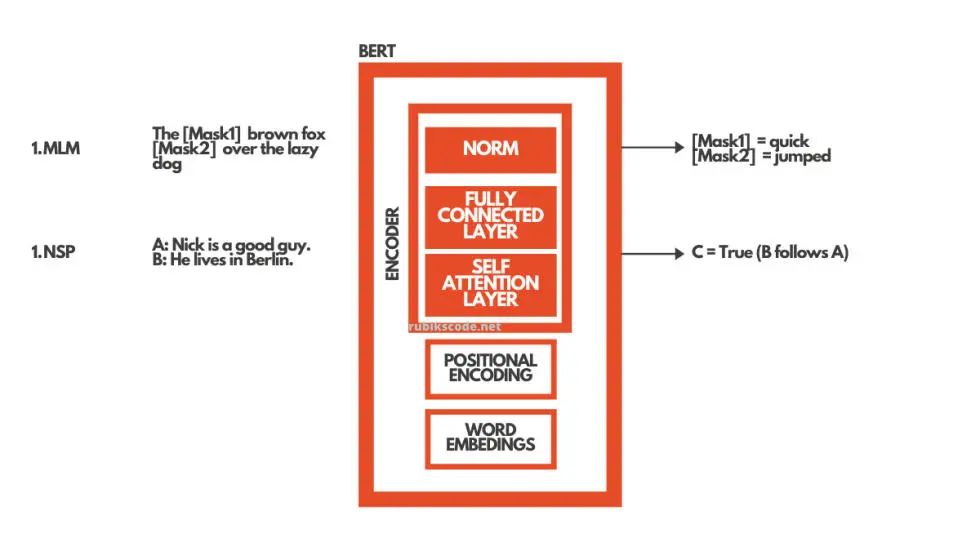
在微調(diào)階段,我們?yōu)樘囟ǖ娜蝿?wù)訓(xùn)練 BERT。這就是說(shuō),如果我們想要?jiǎng)?chuàng)建一個(gè)問(wèn)答系統(tǒng)的解決方案,我們只需要訓(xùn)練 BERT 的額外層。這正是我們?cè)诒窘坛讨兴龅摹K形覀冃枰龅木褪菍⒕W(wǎng)絡(luò)的輸出層替換為為我們特定目的設(shè)計(jì)的新層集。我們有文本段(或上下文)和問(wèn)題作為輸入,而作為輸出,我們想要問(wèn)題的答案。

舉例來(lái)說(shuō),我們的系統(tǒng),應(yīng)該使用兩個(gè)句子。為了提供答案“Jim”,可以使用“Jim is walking through the woods.”(段落或上下文)和“What is his name?” (問(wèn)題)。
4. ONNX模型
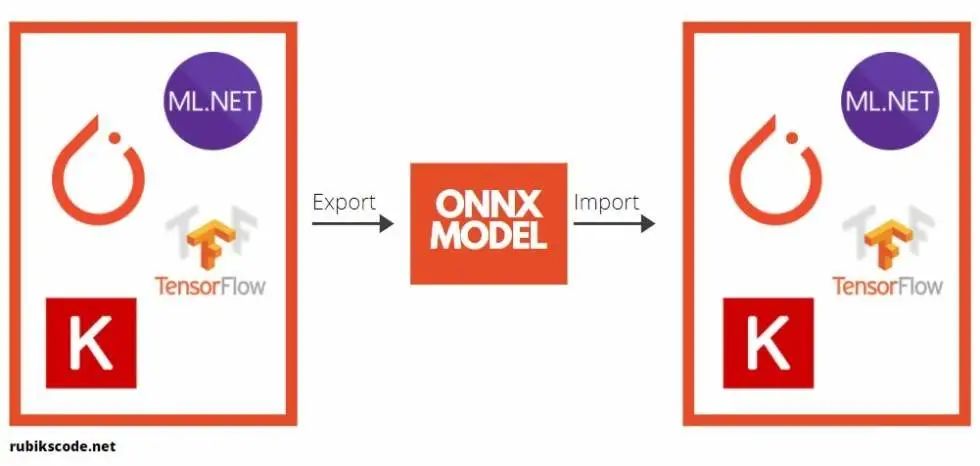
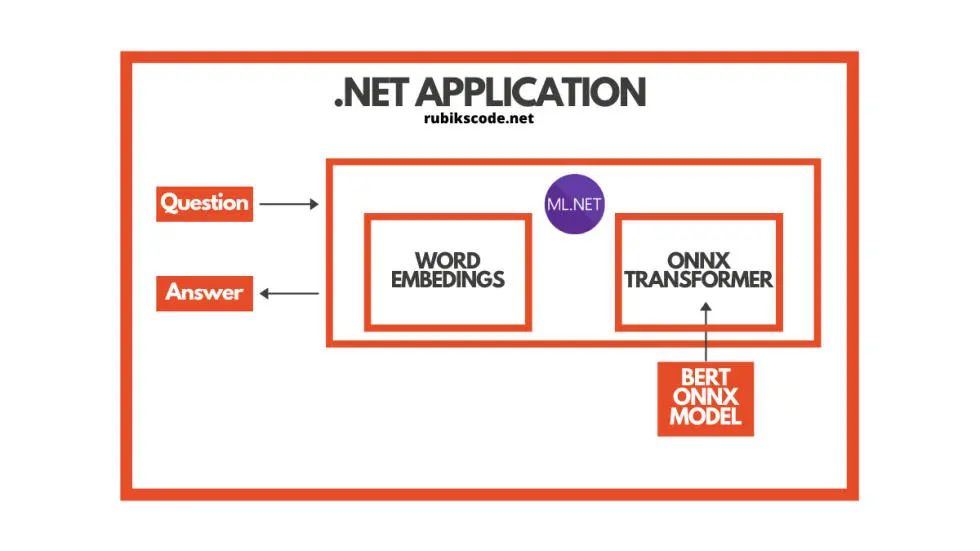
在進(jìn)一步探討利用 ML.NET 實(shí)現(xiàn)對(duì)象檢測(cè)應(yīng)用之前,我們還需要介紹一個(gè)理論上的內(nèi)容。那就是 開(kāi)放神經(jīng)網(wǎng)絡(luò)交換( Open Neural Network Exchange,ONNX)文件格式。這種文件格式是人工智能模型的一種開(kāi)源格式,它支持框架之間的 互操作性。
你可以用機(jī)器學(xué)習(xí)的框架(比如 PyTorch)來(lái)訓(xùn)練模型,保存模型,并將其轉(zhuǎn)換為 ONNX 格式。那么你就可以將 ONNX 模型用于另一個(gè)框架,比如 ML.NET。這正是我們?cè)诒窘坛讨兴龅膬?nèi)容。你可以在 ONNX 網(wǎng)站(https://onnx.ai/)上找到詳細(xì)信息。
在本教程中,我們使用了預(yù)訓(xùn)練 BERT 模型,在這里(https://github.com/onnx/models/tree/master/text/machine_comprehension/bert-squad)可以找到該模型,即 BERT SQUAD。簡(jiǎn)而言之就是,我們將這個(gè)模型導(dǎo)入到 ML.NET 中,并在應(yīng)用中運(yùn)行它。
在 ONNX 模型中,有一件非常有趣且有用的事情,那就是我們可以使用一系列工具來(lái)對(duì)模型進(jìn)行可視化表示。這在像本教程一樣使用預(yù)訓(xùn)練模型的情況下很有用。
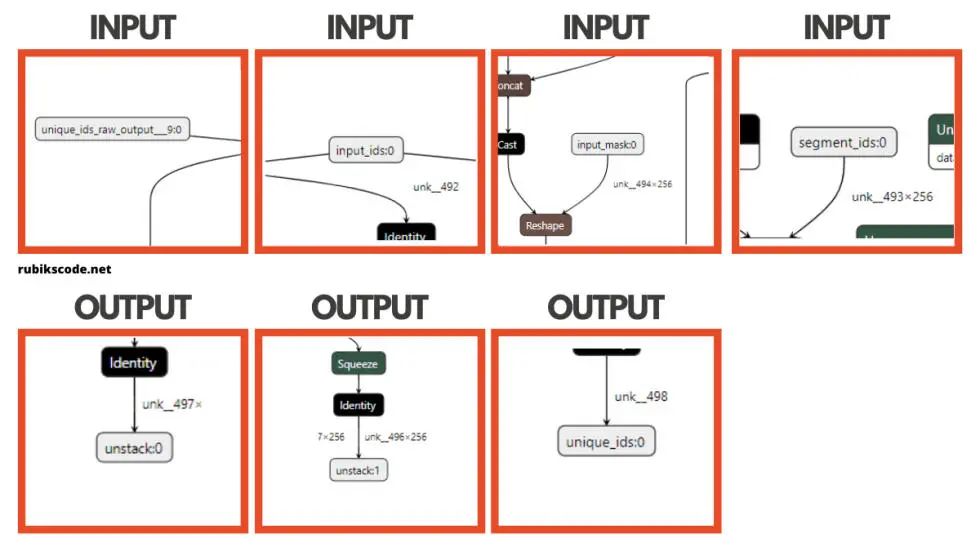
我們常常需要知道輸入層和輸出層的名字,而這個(gè)工具在這方面很有優(yōu)勢(shì)。所以,下載 BERT 模型之后,我們就可以使用這些工具中的一種來(lái)加載它,并進(jìn)行 可視化表示。我們?cè)谶@個(gè)指南中使用 Netron,這里只有一部分輸出:
我知道,這太瘋狂了,BERT 是個(gè)大模型。你可能會(huì)想,我怎么能用這個(gè),為什么我需要它?但是,為了使用 ONNX 模型,我們通常需要知道模型的輸入和輸出層的名稱(chēng)。BERT 看起來(lái)是下面這樣的:
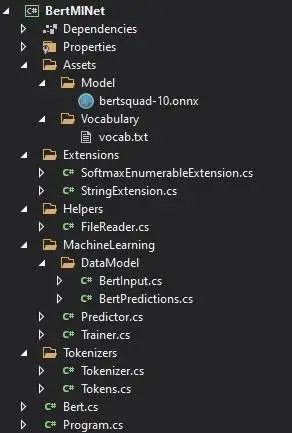
using Microsoft.ML.Data;
namespace BertMlNet.MachineLearning.DataModel
{
public class BertInput
{
[VectorType(1)]
[ColumnName("unique_ids_raw_output___9:0")]
public long[] UniqueIds { get; set; }
[VectorType(1, 256)]
[ColumnName("segment_ids:0")]
public long[] SegmentIds { get; set; }
[VectorType(1, 256)]
[ColumnName("input_mask:0")]
public long[] InputMask { get; set; }
[VectorType(1, 256)]
[ColumnName("input_ids:0")]
public long[] InputIds { get; set; }
}
}
Bertpredictions 類(lèi)使用 BERT 輸出層:
using Microsoft.ML.Data;
namespace BertMlNet.MachineLearning.DataModel
{
public class BertPredictions
{
[VectorType(1, 256)]
[ColumnName("unstack:1")]
public float[] EndLogits { get; set; }
[VectorType(1, 256)]
[ColumnName("unstack:0")]
public float[] StartLogits { get; set; }
[VectorType(1)]
[ColumnName("unique_ids:0")]
public long[] UniqueIds { get; set; }
}
}
Trainer(訓(xùn)練器)類(lèi)非常簡(jiǎn)單,它只有一個(gè)方法 BuildAndTrain,使用預(yù)訓(xùn)練模型的路徑。
using BertMlNet.MachineLearning.DataModel;
using Microsoft.ML;
using System.Collections.Generic;
namespace BertMlNet.MachineLearning
{
public class Trainer
{
private readonly MLContext _mlContext;
public Trainer()
{
_mlContext = new MLContext(11);
}
public ITransformer BuidAndTrain(string bertModelPath, bool useGpu)
{
var pipeline = _mlContext.Transforms
.ApplyOnnxModel(modelFile: bertModelPath,
outputColumnNames: new[] { "unstack:1",
"unstack:0",
"unique_ids:0" },
inputColumnNames: new[] {"unique_ids_raw_output___9:0",
"segment_ids:0",
"input_mask:0",
"input_ids:0" },
gpuDeviceId: useGpu ? 0 : (int?)null);
return pipeline.Fit(_mlContext.Data.LoadFromEnumerable(new List<BertInput>()));
}
}
在上述方法中,我們建立了管道。在這里,我們應(yīng)用 ONNX 模型并將數(shù)據(jù)模型與 BERT ONNX 模型的各個(gè)層連接起來(lái)。請(qǐng)注意,我們有一個(gè)標(biāo)志,可以用來(lái)在 CPU 或 GPU 上訓(xùn)練這個(gè)模型。最后,我們將該模型與空白數(shù)據(jù)進(jìn)行擬合。這么做的目的是加載數(shù)據(jù)模式,即加載模型。
5.3 預(yù)測(cè)器
Predictor(預(yù)測(cè)器)類(lèi)甚至更加簡(jiǎn)單。它接收一個(gè)經(jīng)過(guò)訓(xùn)練和加載的模型,并創(chuàng)建一個(gè)預(yù)測(cè)引擎。然后它使用這個(gè)預(yù)測(cè)引擎為新圖像創(chuàng)建預(yù)測(cè)。
using BertMlNet.MachineLearning.DataModel;
using Microsoft.ML;
namespace BertMlNet.MachineLearning
{
public class Predictor
{
private MLContext _mLContext;
private PredictionEngine<BertInput, BertPredictions> _predictionEngine;
public Predictor(ITransformer trainedModel)
{
_mLContext = new MLContext();
_predictionEngine = _mLContext.Model
.CreatePredictionEngine<BertInput, BertPredictions>(trainedModel);
}
public BertPredictions Predict(BertInput encodedInput)
{
return _predictionEngine.Predict(encodedInput);
}
}
}5.4 助手與擴(kuò)展
有一個(gè) helper(助手)類(lèi)和兩個(gè) extension(擴(kuò)展)類(lèi)。helper 類(lèi) FileReader 有一個(gè)讀取文本文件的方法。我們稍后用它來(lái)從文件中加載詞匯表。它非常簡(jiǎn)單:
using System.Collections.Generic;
using System.IO;
namespace BertMlNet.Helpers
{
public static class FileReader
{
public static List<string> ReadFile(string filename)
{
var result = new List<string>();
using (var reader = new StreamReader(filename))
{
string line;
while ((line = reader.ReadLine()) != null)
{
if (!string.IsNullOrWhiteSpace(line))
{
result.Add(line);
}
}
}
return result;
}
}
}
有兩個(gè) extension 類(lèi)。一個(gè)用于對(duì)元素集合進(jìn)行 Softmax 操作,另一個(gè)用于分割字符串并一次處理一個(gè)結(jié)果。
using System;
using System.Collections.Generic;
using System.Linq;
namespace BertMlNet.Extensions
{
public static class SoftmaxEnumerableExtension
{
public static IEnumerable<(T Item, float Probability)> Softmax<T>(
this IEnumerable<T> collection,
Func<T, float> scoreSelector)
{
var maxScore = collection.Max(scoreSelector);
var sum = collection.Sum(r => Math.Exp(scoreSelector(r) - maxScore));
return collection.Select(r => (r, (float)(Math.Exp(scoreSelector(r) - maxScore) / sum)));
}
}
}
using System.Collections.Generic;
namespace BertMlNet.Extensions
{
static class StringExtension
{
public static IEnumerable<string> SplitAndKeep(
this string inputString, params char[] delimiters)
{
int start = 0, index;
while ((index = inputString.IndexOfAny(delimiters, start)) != -1)
{
if (index - start > 0)
yield return inputString.Substring(start, index - start);
yield return inputString.Substring(index, 1);
start = index + 1;
}
if (start < inputString.Length)
{
yield return inputString.Substring(start);
}
}
}
}
到目前為止,我們已經(jīng)探索過(guò)解決方案的簡(jiǎn)單部分。接下來(lái),我們來(lái)看一看如何實(shí)現(xiàn)標(biāo)記化,從而了解更復(fù)雜和重要的部分。先定義一個(gè)默認(rèn)的 BERT 標(biāo)記列表。舉例來(lái)說(shuō),兩個(gè)句子都應(yīng)該使用 [SEP] 標(biāo)記來(lái)區(qū)分。[CLS] 標(biāo)記總是出現(xiàn)在文本的開(kāi)頭,并特定于分類(lèi)任務(wù)。
namespace BertMlNet.Tokenizers
{
public class Tokens
{
public const string Padding = "";
public const string Unknown = "[UNK]";
public const string Classification = "[CLS]";
public const string Separation = "[SEP]";
public const string Mask = "[MASK]";
}
}
在 Tokenizer(詞法分析器)類(lèi)中完成標(biāo)記化的過(guò)程。有兩個(gè)公共方法:Tokenize 和 Untokenize。第一個(gè)方法首先將接收的的文本分割成若干句子,然后對(duì)于每個(gè)句子,每個(gè)詞都被轉(zhuǎn)換為嵌入。需要注意的是,一個(gè)詞可能會(huì)出現(xiàn)用多個(gè)標(biāo)記表示的情況。
舉例來(lái)說(shuō),單詞“embeddings”表示為標(biāo)記數(shù)組:['em', '##bed', '##ding', '##s']。這個(gè)詞已經(jīng)被分割成更小的子詞和字符,其中一些子詞前面有兩個(gè) # 號(hào),這只是我們的詞法分析器的方式,表示這個(gè)子詞或字符是一個(gè)大詞的一部分,前面是另一個(gè)子詞。
因此,例如,'##bed' 標(biāo)記與 'bed' 標(biāo)記是分開(kāi)的。標(biāo)記方法所做的另一件事是返回詞匯索引和分割索引。這兩個(gè)都是 BERT 輸入。如果想知道更多的原因,請(qǐng)查閱這篇文章《BERT 詞嵌入教程》(BERT Word Embeddings Tutorial)(https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/)。
using BertMlNet.Extensions;
using System;
using System.Collections.Generic;
using System.Linq;
namespace BertMlNet.Tokenizers
{
public class Tokenizer
{
private readonly List<string> _vocabulary;
public Tokenizer(List<string> vocabulary)
{
_vocabulary = vocabulary;
}
public List<(string Token, int VocabularyIndex, long SegmentIndex)> Tokenize(params string[] texts)
{
IEnumerable<string> tokens = new string[] { Tokens.Classification };
foreach (var text in texts)
{
tokens = tokens.Concat(TokenizeSentence(text));
tokens = tokens.Concat(new string[] { Tokens.Separation });
}
var tokenAndIndex = tokens
.SelectMany(TokenizeSubwords)
.ToList();
var segmentIndexes = SegmentIndex(tokenAndIndex);
return tokenAndIndex.Zip(segmentIndexes, (tokenindex, segmentindex)
=> (tokenindex.Token, tokenindex.VocabularyIndex, segmentindex)).ToList();
}
public List<string> Untokenize(List<string> tokens)
{
var currentToken = string.Empty;
var untokens = new List<string>();
tokens.Reverse();
tokens.ForEach(token =>
{
if (token.StartsWith("##"))
{
currentToken = token.Replace("##", "") + currentToken;
}
else
{
currentToken = token + currentToken;
untokens.Add(currentToken);
currentToken = string.Empty;
}
});
untokens.Reverse();
return untokens;
}
public IEnumerable<long> SegmentIndex(List<(string token, int index)> tokens)
{
var segmentIndex = 0;
var segmentIndexes = new List<long>();
foreach (var (token, index) in tokens)
{
segmentIndexes.Add(segmentIndex);
if (token == Tokens.Separation)
{
segmentIndex++;
}
}
return segmentIndexes;
}
private IEnumerable<(string Token, int VocabularyIndex)> TokenizeSubwords(string word)
{
if (_vocabulary.Contains(word))
{
return new (string, int)[] { (word, _vocabulary.IndexOf(word)) };
}
var tokens = new List<(string, int)>();
var remaining = word;
while (!string.IsNullOrEmpty(remaining) && remaining.Length > 2)
{
var prefix = _vocabulary.Where(remaining.StartsWith)
.OrderByDescending(o => o.Count())
.FirstOrDefault();
if (prefix == null)
{
tokens.Add((Tokens.Unknown, _vocabulary.IndexOf(Tokens.Unknown)));
return tokens;
}
remaining = remaining.Replace(prefix, "##");
tokens.Add((prefix, _vocabulary.IndexOf(prefix)));
}
if (!string.IsNullOrWhiteSpace(word) && !tokens.Any())
{
tokens.Add((Tokens.Unknown, _vocabulary.IndexOf(Tokens.Unknown)));
}
return tokens;
}
private IEnumerable<string> TokenizeSentence(string text)
{
// remove spaces and split the , . : ; etc..
return text.Split(new string[] { " ", " ", "\r\n" }, StringSplitOptions.None)
.SelectMany(o => o.SplitAndKeep(".,;:\\/?!#$%()=+-*\"'–_`<>&^@{}[]|~'".ToArray()))
.Select(o => o.ToLower());
}
}
}
另一個(gè)公共方法是 Untokenize。這個(gè)方法被用于逆轉(zhuǎn)這一過(guò)程。從根本上說(shuō),BERT 的輸出會(huì)產(chǎn)生大量的嵌入信息。這個(gè)方法的目的是把這些信息轉(zhuǎn)化成有意義的句子。
該類(lèi)具有使該過(guò)程成為現(xiàn)實(shí)的多種方法。
5.6 BERT
Bert 類(lèi)將所有這些東西放在一起。在構(gòu)造函數(shù)中,我們讀取詞匯文件并實(shí)例化 Train、Tokenizer 和 Predictor 對(duì)象。這里只有一個(gè)公共方法:Predict。這個(gè)方法接收上下文和問(wèn)題。作為輸出,將檢索出具有概率的答案:
using BertMlNet.Extensions;
using BertMlNet.Helpers;
using BertMlNet.MachineLearning;
using BertMlNet.MachineLearning.DataModel;
using BertMlNet.Tokenizers;
using System.Collections.Generic;
using System.Linq;
namespace BertMlNet
{
public class Bert
{
private List<string> _vocabulary;
private readonly Tokenizer _tokenizer;
private Predictor _predictor;
public Bert(string vocabularyFilePath, string bertModelPath)
{
_vocabulary = FileReader.ReadFile(vocabularyFilePath);
_tokenizer = new Tokenizer(_vocabulary);
var trainer = new Trainer();
var trainedModel = trainer.BuidAndTrain(bertModelPath, false);
_predictor = new Predictor(trainedModel);
}
public (List<string> tokens, float probability) Predict(string context, string question)
{
var tokens = _tokenizer.Tokenize(question, context);
var input = BuildInput(tokens);
var predictions = _predictor.Predict(input);
var contextStart = tokens.FindIndex(o => o.Token == Tokens.Separation);
var (startIndex, endIndex, probability) = GetBestPrediction(predictions, contextStart, 20, 30);
var predictedTokens = input.InputIds
.Skip(startIndex)
.Take(endIndex + 1 - startIndex)
.Select(o => _vocabulary[(int)o])
.ToList();
var connectedTokens = _tokenizer.Untokenize(predictedTokens);
return (connectedTokens, probability);
}
private BertInput BuildInput(List<(string Token, int Index, long SegmentIndex)> tokens)
{
var padding = Enumerable.Repeat(0L, 256 - tokens.Count).ToList();
var tokenIndexes = tokens.Select(token => (long)token.Index).Concat(padding).ToArray();
var segmentIndexes = tokens.Select(token => token.SegmentIndex).Concat(padding).ToArray();
var inputMask = tokens.Select(o => 1L).Concat(padding).ToArray();
return new BertInput()
{
InputIds = tokenIndexes,
SegmentIds = segmentIndexes,
InputMask = inputMask,
UniqueIds = new long[] { 0 }
};
}
private (int StartIndex, int EndIndex, float Probability) GetBestPrediction(BertPredictions result, int minIndex, int topN, int maxLength)
{
var bestStartLogits = result.StartLogits
.Select((logit, index) => (Logit: logit, Index: index))
.OrderByDescending(o => o.Logit)
.Take(topN);
var bestEndLogits = result.EndLogits
.Select((logit, index) => (Logit: logit, Index: index))
.OrderByDescending(o => o.Logit)
.Take(topN);
var bestResultsWithScore = bestStartLogits
.SelectMany(startLogit =>
bestEndLogits
.Select(endLogit =>
(
StartLogit: startLogit.Index,
EndLogit: endLogit.Index,
Score: startLogit.Logit + endLogit.Logit
)
)
)
.Where(entry => !(entry.EndLogit < entry.StartLogit || entry.EndLogit - entry.StartLogit > maxLength || entry.StartLogit == 0 && entry.EndLogit == 0 || entry.StartLogit < minIndex))
.Take(topN);
var (item, probability) = bestResultsWithScore
.Softmax(o => o.Score)
.OrderByDescending(o => o.Probability)
.FirstOrDefault();
return (StartIndex: item.StartLogit, EndIndex: item.EndLogit, probability);
}
}
}
Predict 方法會(huì)執(zhí)行一些步驟。讓我們來(lái)詳細(xì)討論一下。
public (List<string> tokens, float probability) Predict(string context, string question)
{
var tokens = _tokenizer.Tokenize(question, context);
var input = BuildInput(tokens);
var predictions = _predictor.Predict(input);
var contextStart = tokens.FindIndex(o => o.Token == Tokens.Separation);
var (startIndex, endIndex, probability) = GetBestPrediction(predictions,
contextStart,
20,
30);
var predictedTokens = input.InputIds
.Skip(startIndex)
.Take(endIndex + 1 - startIndex)
.Select(o => _vocabulary[(int)o])
.ToList();
var connectedTokens = _tokenizer.Untokenize(predictedTokens);
return (connectedTokens, probability);
}
首先,該方法對(duì)問(wèn)題和傳遞的上下文(基于 BERT 應(yīng)該給出答案的段落)進(jìn)行標(biāo)記化。基于這些信息,我們建立了 BertInput。這是在 BertInput 方法中完成的。基本上,所有標(biāo)記化的信息都被填充了,因此可以將其作為 BERT 的輸入,并用于初始化 BertInput 對(duì)象。
然后我們從 Predictor 獲得模型的預(yù)測(cè)結(jié)果。這些信息會(huì)得到額外的處理,并且根據(jù)上下文找到最佳預(yù)測(cè)。也就是說(shuō),BERT 從上下文中選出最有可能是答案的詞,然后我們選出最好的詞。最后,這些詞都是未標(biāo)記的。
5.7 程序
Program(程序)是利用了我們?cè)?Bert 類(lèi)中實(shí)現(xiàn)的內(nèi)容。首先,讓我們定義啟動(dòng)設(shè)置:
{
"profiles": {
"BERT.Console": {
"commandName": "Project",
"commandLineArgs": "\"Jim is walking through the woods.\" \"What is his name?\""
}
}
}
我們定義了兩個(gè)命令行參數(shù):“Jim is walking throught the woods.”和“What is his name?”。正如我們已經(jīng)提到的,第一個(gè)參數(shù)是上下文,第二個(gè)參數(shù)是問(wèn)題。Main 方法是最小的。
using System;
using System.Text.Json;
namespace BertMlNet
{
class Program
{
static void Main(string[] args)
{
var model = new Bert("..\\BertMlNet\\Assets\\Vocabulary\\vocab.txt",
"..\\BertMlNet\\Assets\\Model\\bertsquad-10.onnx");
var (tokens, probability) = model.Predict(args[0], args[1]);
Console.WriteLine(JsonSerializer.Serialize(new
{
Probability = probability,
Tokens = tokens
}));
}
}
在技術(shù)上,我們用詞匯表文件的路徑和模型的路徑創(chuàng)建 Bert 對(duì)象。然后我們用命令行參數(shù)調(diào)用 Predict 方法。我們得到的輸出是這樣的:
{"Probability":0.9111285,"Tokens":["jim"]}
我們可以看到,BERT 有 91% 的把握認(rèn)為問(wèn)題的答案是“Jim”,而且是正確的。
結(jié)語(yǔ)
通過(guò)這篇文章,我們了解了 BERT 的工作原理。更具體地說(shuō),我們有機(jī)會(huì)探索 Transformer 架構(gòu)的工作原理,并了解 BERT 如何利用該架構(gòu)來(lái)理解語(yǔ)言。最后,我們學(xué)習(xí)了 ONNX 模型格式,以及如何將它用于 ML.NET。
作者介紹
Nikola M. Zivkovic 是 Rubik's Code 的首席人工智能官,也是《Deep Learning for Programmers》(尚無(wú)中譯本)一書(shū)的作者。熱愛(ài)知識(shí)分享,是一位經(jīng)驗(yàn)豐富的演講者,也是塞爾維亞諾維薩德大學(xué)的客座講師。
原文鏈接:
https://rubikscode.net/2021/04/19/machine-learning-with-ml-net-nlp-with-bert/

點(diǎn)個(gè)在看 paper不斷!