
因果分析如何驅動用戶增長
導讀:將因果推理與機器學習相結合,可以幫助我們解決在大量數(shù)據集當中檢測到細微相關性,并判斷其預測準確性的問題。我們將探索因果機器學習在用戶增長中是如何應用的,采用了什么分析方法。
本文將圍繞下面四點展開:
基礎概念介紹
因果分析
因果機器學習
因果歸因
01
基礎概念介紹
1.?用戶增長指標
在用戶增長模型中,最顯著的一個指標便是DAU(日活躍用戶)的增長,在用戶生命周期中主要體現(xiàn)在留存和活躍兩個環(huán)節(jié)。另一方面是市場營銷的增長,體現(xiàn)在用戶付費、用戶裂變等。
留存、活躍,在推薦系統(tǒng)中是比較簡單的問題,因為它有明確的目標,即提升留存和活躍對應的指標。同時它又是復雜的,因為對于不同用戶的標簽具有延遲性,但在數(shù)學上是可解的。除此之外,它需要一定深度,需要通過層層剖析去間接優(yōu)化其模型。
2. 因果分析應用方法
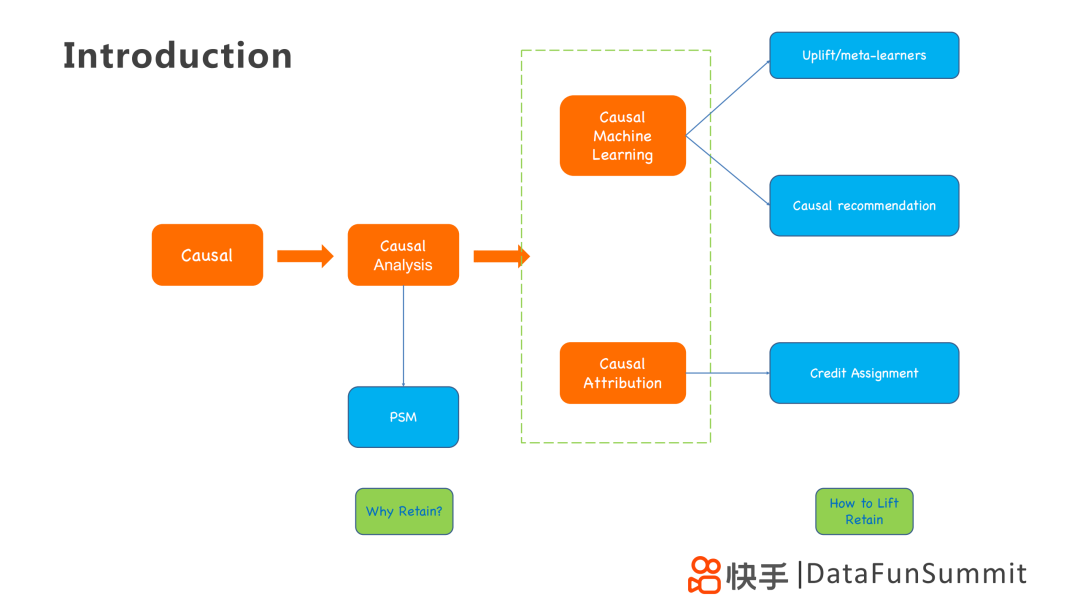
為解決上訴問題,可以從因果的角度出發(fā),利用PSM(傾向評分匹配)統(tǒng)計方法進行因果分析,解決WHY的問題。
在其基礎上,使用因果機器學習或者因果歸因的技術手段去尋找提升指標的關鍵信息,例如Uplift / Meta-learner、Causal Recommendation和Credit Assignment模型,解決HOW的問題。
02
因果分析
1. 相關性和因果性

在做因果分析之前,我們需要明確兩個事件是存在相關性還是因果性,我們如何判斷以及如何衡量呢?
第一個問題:一個回頭率高的用戶看了短視頻,我們是否可以認為這些短視頻促進了用戶的留存?顯然不是,這兩者有性質上的偏差。
第二個問題:我們如何量化用戶指標,例如用戶點擊、點贊、關注之類的指標,如何判斷與留存指標之間是相關性的還是因果性的?
因此我們需要通過構造和去偏的思維方式去分析兩個事件之間的關系,采用例如PSM的方法,以推進后續(xù)的因果分析。
下面我們就以考慮用戶點擊對留存的影響為例,介紹如何用因果分析和因果機器學習,解決用戶增長的業(yè)務問題。
2. PSM傾向評分匹配統(tǒng)計方法

首先,利用PSM可以幫助我們研究用戶點擊和點贊行為對于用戶的留存是否存在因果性。其檢驗方法如下:
第一步:通過傾向分數(shù)(propensity score),計算其實驗模型,例如LR/XGBT處理模型(LR/XGBT Treatment Model)。
第二步:將兩個對比實驗組,通過算法的匹配,實現(xiàn)去偏。
第三步:采用KS-檢驗,計算P-value,核查協(xié)變量的平衡。
第四步:計算ATE(Average Treatment Effect),檢驗指標對最后結果的影響。

經過PSM之后,我們假設得到結論:點擊會讓留存率提升5%,意味著一個用戶進行點擊行為后,其留存可以提升5%,反映到相應的指標便是click_dau(點擊日活躍人數(shù))。例如click_dau提升了1%,那么整體留存率應該提升5%×1%=0.05%。

當treatment是連續(xù)的,例如點擊不再是0→1的二元問題,而是從1變成更多的時候,我們會采取以下思路去解決問題:
得到回歸模型后,去預測用戶的點擊數(shù),但是這個方法比較復雜。
通過因果分析或其他一些match的方法解決。

在因果分析中,主要采用兩種方法:
第一種:PSM,可以等價為帶有權重的聚類。
第二種:Matching on Features,特征匹配,也是一種聚類,但是這個方法需要結合業(yè)務去挖掘有價值的特征和切合業(yè)務的指標進行匹配。
03
因果機器學習
接下來介紹因果推薦的因果機器學習模型的一些應用。
1. 機器學習中的因果推理VS因果推理中的機器學習

機器學習中的因果推理和因果推理中的機器學習兩個概念其實是不一樣的,兩者主要區(qū)別在于:
前者旨在把因果分析當做工具放到機器學習中去,后者旨在把機器學習當工具放到因果分析中去;
前者包含去偏算法和HTE非均勻處理效果模型,后者包含因果分析以及HTE非均勻處理效果模型。
2.?用戶留存中的HTE分析
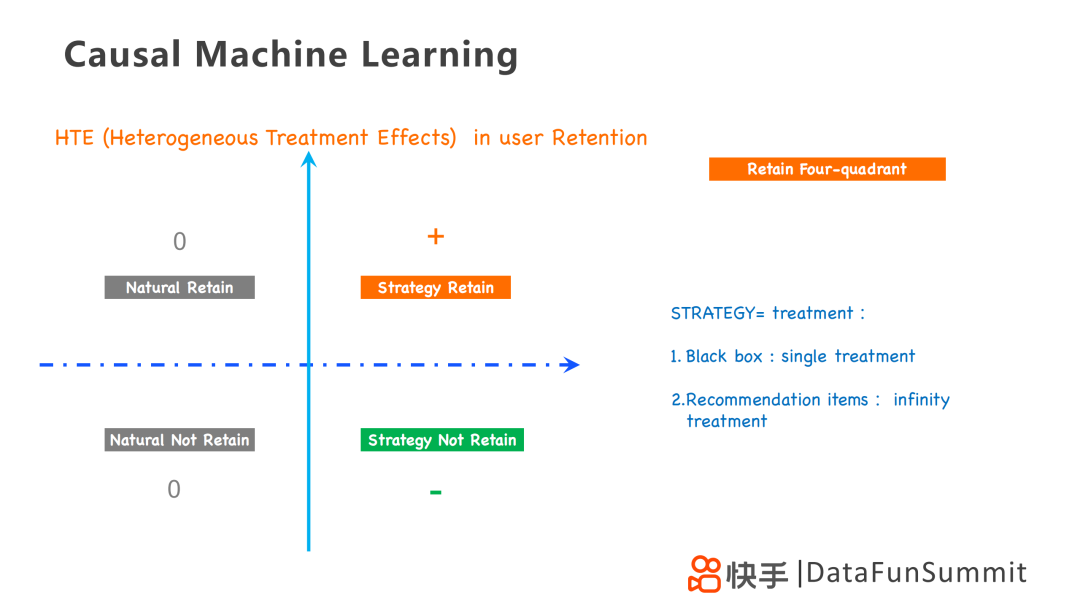
對于留存而言,HTE以是否采取策略和是否留存為維度劃分為四個區(qū)域,其中采用的策略針對不同的業(yè)務問題,可以采用單一處理的黑盒策略,也可以采用無限處理的推薦策略。因此HTE是一個四象限問題,分別為:
第一象限為+1,采用策略的用戶留存下來;
第二、三象限為0,自然用戶,即不采用策略用戶是否留存,其結果都為0;
第四象限為-1,采用策略的用戶沒有留存下來。

在自然模型中,采用打標簽的方法,類似于現(xiàn)實生活中的AB test,但是可以對每個實驗組設置一樣的條件,就像“平行世界”一樣,僅有是否treat和是否留存的標簽,便可以直觀的得到treatment對留存的影響。

在PML模型里,采用例如uplift模型,構造p_score相等的兩個目標形成一組Pair,去尋找事實相反的配對,構建深度學習模型,簡化深度學習網絡,剔除一些無效樣本,已形成有效的網絡結構。
在這個基礎上,我們有一些衍生的知識點:
Propensity dropout,即利用PSM去精簡和修正機器學習網絡。
將深度學習網絡或神經網絡中的一些網絡節(jié)點去掉,不會影響最后的結果,甚至能提升其結果。
剔除無效網絡的目的,是要保留有意義的部分,即使得lift的結果是正的或者是負的。
3.?用戶活躍中的HTE分析

針對用戶活躍,PML可以延伸為二元處理和連續(xù)處理的問題,然后基于可觀測數(shù)據對HTE模型進行訓練,使得模型更加穩(wěn)健。

我們以0.5作為分水嶺。指標active_days_sum為0-0.5的用戶其活躍會減少0.1%,為0.5-1的用戶其活躍會增加0.4%;指標duration_sum為0-0.5的用戶其活躍會減少0.4%,為0.5-1的用戶其活躍會增加0.5%。
得到這個結論,意味著當針對活躍天數(shù)的策略生效之后,dau的提升應該是0.2×0.4%=0.08%。
4. 數(shù)學模型:游戲幣回收
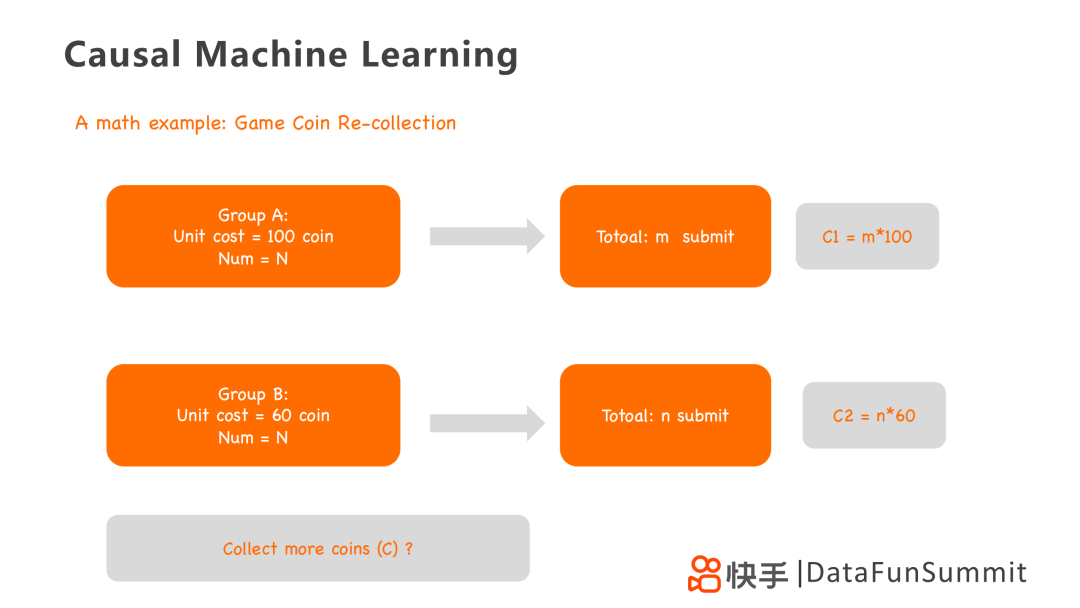
我們采用一個游戲幣回收的數(shù)學模型來詳細闡述采用Meta-learner和HTE模型來實現(xiàn)采取不同回收策略,以實現(xiàn)回收更多游戲幣的方法。我們主要有兩組回收策略:
A組:一次回收100個游戲幣,總共設置N組。有m個玩家回收成功,總共回收C1=100×m個游戲幣。
B組:一次回收60個游戲幣,總共設置N組。有n個玩家回收成功,總共回收C2=60×n個游戲幣。

可以采用的模型有Meta-learner、HTE和Online-learning,我們主要闡述前兩種。可以從兩個角度去評估我們的模型,一個是通過實驗數(shù)據去評估收益的數(shù)據;一個是通過理論推導,精確地評估收益和漲幅。

第一個方法是Meta-learner,是T-learner模型的一個拓展,通過訓練兩個模型,并畫出購買用戶的累計分布曲線,找到兩個策略最大的gap,在圖中即為h。我們可以通過累計分布曲線去優(yōu)化,得到第三個策略,是前兩個策略的線性疊加。?

累計分布曲線的計算方法如上圖所示,計算得到兩個策略在gap最大為h時,回收游戲幣的差距為△=60×n(b-a)。

第二個方法是HTE匹配模型,它實際上是通過以兩個策略為基礎,貼上不同的標簽,構造三組模型去構建模型,進行計算,主要分為以下三組:
第一組:Group 100,label=0 VS Group 60,label=0
第二組:Group 100,label=0 VS Group 60,label=1
第三組:Group 100,label=1 VS Group 60,label=1
這個模型的缺點在于計算過程中會有累積的誤差,效果不是很穩(wěn)定。但是利用這種方法,可以最大程度的簡化目標,將最優(yōu)化問題變成簡單的三分類問題,得到更加簡化的模型和明確的策略。
04
因果歸因理論

在做策略的時候,例如推薦,我們主要會遇到以下兩個問題:
多組(無限)處理,我們無法訓練太多的模型,如何簡化我們的推薦treatment。
效果延遲問題,例如做留存策略時,關注用戶點擊ctr等即時反饋之外,如何制定更長遠的指標策略。
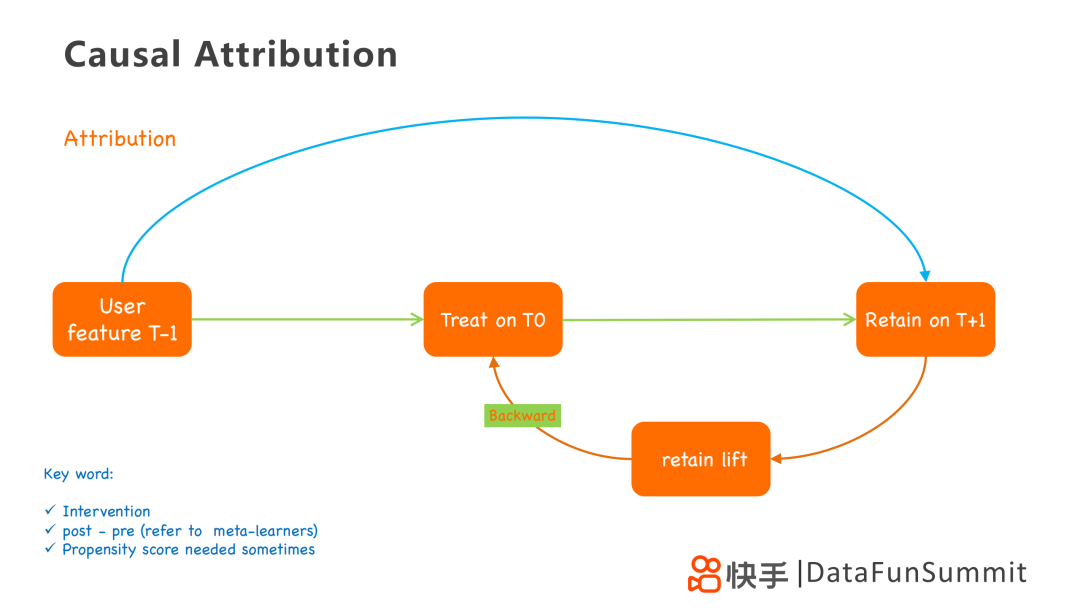
在這里我們再用這個框架圖來講解一下因果歸因的思路,它用到了用戶三個狀態(tài)T-1,T0和T+1。T0狀態(tài)即為用戶受到無限處理的影響的狀態(tài)。從T-1到T+1,是利用T-1狀態(tài)的一些特征去預測T+1狀態(tài)的留存情況,類似PSM傾向性得分。另一條路從T-1到T0再到T+1,是在經過treatment后,進行回溯。從T+1到T0,計算retain lift,這個lift可以認為是treatment帶來的,然后采用backward或者credit assignment的方式歸因到treatment上。
在因果分析里最主要的是解決去偏問題,在這個過程中我們解決了幾個bias,在T0增加treatment時,高留存的用戶未來留存也會高,因此會把用戶留存的bias去掉,留下lift的留存。同時形成treatment時,也會只考慮當天用戶的treatment帶來的lift。但是在這個過程中treatment的數(shù)量很多,難以算出每個treatment對應的lift,可以采用平均處理計算。但是這個方法存在很大的誤差,進一步可以采用權重,通過用戶like或者follow的行為增加對應treatment的權重,提高歸因的準確性。在有干預的情況下,去尋找干預帶來的影響,可以通過post-pre去偏的方法實現(xiàn)。除此之外,想要映射無限多treatment到對應的lift,有時還需要采用propensity score,帶有傾向得分計算,有助于幫助我們利用數(shù)學或matching的方法將bias消除掉。

最后總結一下因果分析,它源于一些傳統(tǒng)科學例如社會科學、生物學等,如今在數(shù)據科學領域也有了很深的發(fā)展,也在公司廣泛應用。它和機器學習、深度學習、推薦算法、強化學習和遷移學習是融合在一起的,其本質還是尋找有效的樣本,解決更本質的問題。
05
精彩問答
Q1:因果分析的這套模型主要應用在整個推薦技術的哪個階段?
A1:推薦系統(tǒng)主要經過召回→排序→重排階段,在我個人的實際應用中,是將其應用到推薦的最后重排階段,主要人類強干預增加的,進行一些結果的修正。常規(guī)情況,會將其應用到排序階段,因果推斷不是用于替代現(xiàn)有的資源系統(tǒng),而是輔助現(xiàn)有系統(tǒng),利用增加權重的方式進行改進,凸顯出有效樣本同時剔除無效樣本。
Q2:在大量的item的情況下,會不會根據內容或者屬性進行分類,減少歸因的復雜度?
A2:會的,我們最希望解決的是每個item對于留存的貢獻,但是這樣做是很困難的,通過不同品類不同作者等屬性分類,大致計算也可以獲得一些相對粗略的結果,利用每個用戶的policy推薦策略,將其從無限多treatment的問題變成多treatment的問題,使得這類問題可解。
Q3:中活和高活躍度用戶比起新用戶和低活用戶,他們的treatment和用戶行為數(shù)據是大量的,我們如何采用特征選擇或者數(shù)據壓縮等方法,將其應用到中活和高活躍度用戶群體上?
A3:中活和高活躍度用戶群體除了數(shù)據量上有區(qū)別以外,在收斂性質上也有區(qū)別。新用戶的數(shù)據樣本是具有一定隨機性的,因為推薦系統(tǒng)還沒有表現(xiàn)得特別好,相反高活用戶在推薦數(shù)據表現(xiàn)上已經具有很強的傾向性。而因果推斷就是要通過去偏,構造一個平均化的模型。因此根據因果推斷的本質思想,可以將exposure bias或者偏好bias剔除,將其恢復到一個隨機的分布,再用平均理論,反推其item的lift,理論上就可以實現(xiàn)。
Q4:如果在整個推薦系統(tǒng)中,增加一份1%的隨機流量,會怎樣利用這個隨機流量去構建因果推斷模型呢?
A4:隨機流量本身不能去替代matching或者PSM的分析方法,它的作用是幫助我們更好理解用戶本身的偏好。但擁有這個隨機流量,在模型修復模塊可以簡單的歸因到隨機流量上。但是隨機流量和非隨機流量是共同作用在用戶上的,會共同影響用戶的留存,也得考慮隨機和非隨機的差異,通過matching或者反事實的理論實現(xiàn)去偏。
今天的分享就到這里,謝謝大家。

·················END·················