
太強了!這個建模神器可以玩一輩子

公眾號:Python數(shù)據(jù)科學
作者:東哥起飛
一、前言
大家好,我是東哥。本次給大家推薦一個模型的神器工具,在特征工程和模型驗證等方面使用真的太好用了,極大的簡化了操作,并且提供可視化分析。
玩過建模的朋友都知道,在建立模型之前有很長的一段特征工程工作要做,而在特征工程的過程中,探索性數(shù)據(jù)分析又是必不可少的一部分,因為如果我們要對各個特征進行細致的分析,那么必然會進行一些可視化以輔助我們來做選擇和判斷。
可視化的工具有很多,但是能夠針對特征探索性分析而進行專門可視化的不多,今天給大家介紹一款功能十分強大的工具:yellowbrick,希望通過這個工具的輔助可以節(jié)省更多探索的時間,快速掌握特征信息。
二、功能
1、雷達 RadViz
RadViz雷達圖是一種多變量數(shù)據(jù)可視化算法,它圍繞圓周均勻地分布每個特征,并且標準化了每個特征值。一般數(shù)據(jù)科學家使用此方法來檢測類之間的關(guān)聯(lián)。例如,是否有機會從特征集中學習一些東西或是否有太多的噪音?
# 加載數(shù)據(jù)
data = load_data("occupancy")
# 特征和目標變量
features = ["temperature", "relative humidity", "light", "C02", "humidity"]
classes = ["unoccupied", "occupied"]
# 賦值x和y
X = data[features]
y = data.occupancy
# 導入 visualizer
from yellowbrick.features import RadViz
# 調(diào)用visualizer
visualizer = RadViz(classes=classes, features=features)
visualizer.fit(X, y)
visualizer.transform(X)
visualizer.poof()
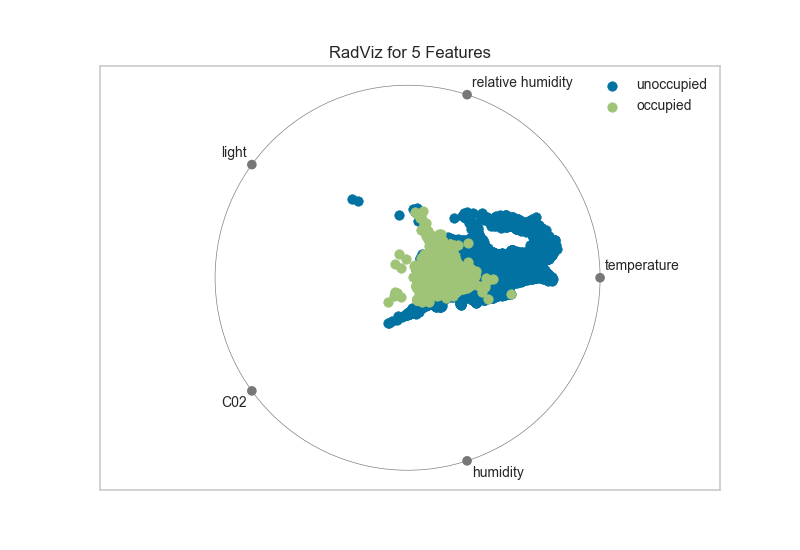 從上面雷達圖可以看出5個維度中,溫度對于目標類的影響是比較大的。
從上面雷達圖可以看出5個維度中,溫度對于目標類的影響是比較大的。
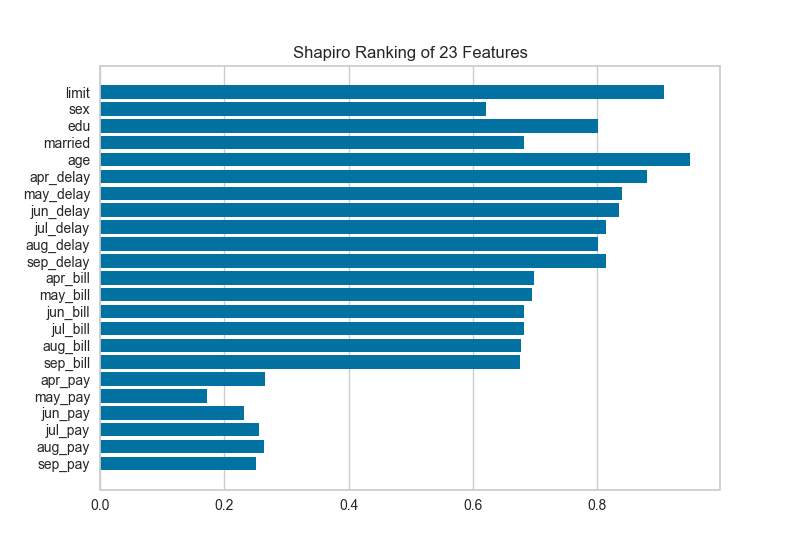
2、一維排序 Rank 1D
特征的一維排序利用排名算法,僅考慮單個特征,默認情況下使用Shapiro-Wilk算法來評估各特征樣本分布的正態(tài)性,通過繪制一個條形圖,展示每個特征的檢驗值。
from yellowbrick.features import Rank1D
# 使用 Sharpiro ranking算法調(diào)用Rank1D
visualizer = Rank1D(features=features, algorithm='shapiro')
visualizer.fit(X, y)
visualizer.transform(X)
visualizer.poof()
3、PCA Projection
PCA分解可視化利用主成分分析將高維數(shù)據(jù)分解為二維或三維,以便可以在散點圖中繪制每個實例。PCA的使用意味著可以沿主要變化軸分析投影數(shù)據(jù)集,并且可以解釋該數(shù)據(jù)集以確定是否可以利用球面距離度量。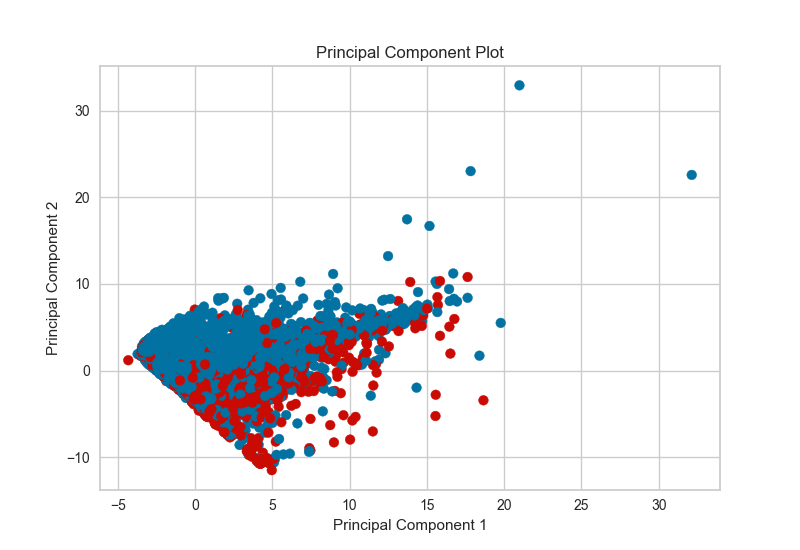
4、雙重圖 Biplot
PCA投影可以增強到雙點,其點是投影實例,其矢量表示高維空間中數(shù)據(jù)的結(jié)構(gòu)。通過使用proj_features = True標志,數(shù)據(jù)集中每個要素的向量將在散點圖上以該要素的最大方差方向繪制。這些結(jié)構(gòu)可用于分析特征對分解的重要性或查找相關(guān)方差的特征以供進一步分析。
# 導入數(shù)據(jù)
data = load_data('concrete')
# 選擇特征和目標變量
target = "strength"
features = [
'cement', 'slag', 'ash', 'water', 'splast', 'coarse', 'fine', 'age'
]
# 設(shè)置x和y
X = data[features]
y = data[target]
visualizer = PCADecomposition(scale=True, proj_features=True)
visualizer.fit_transform(X, y)
visualizer.poof()
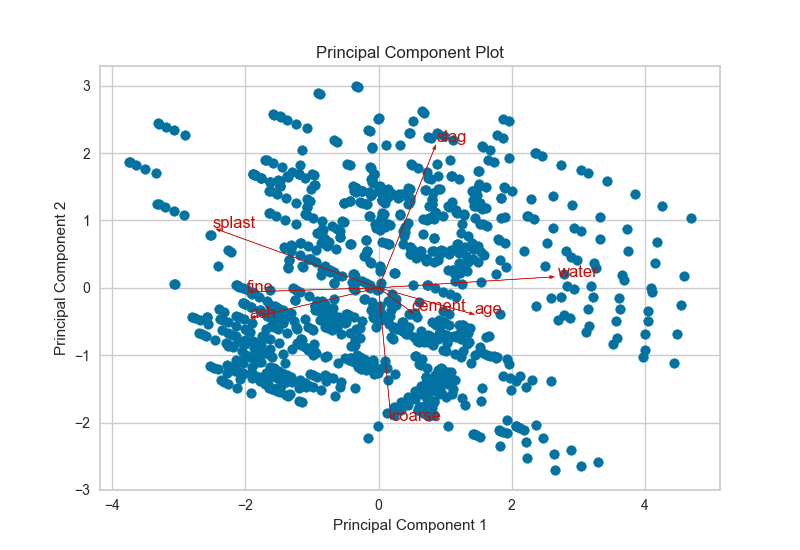
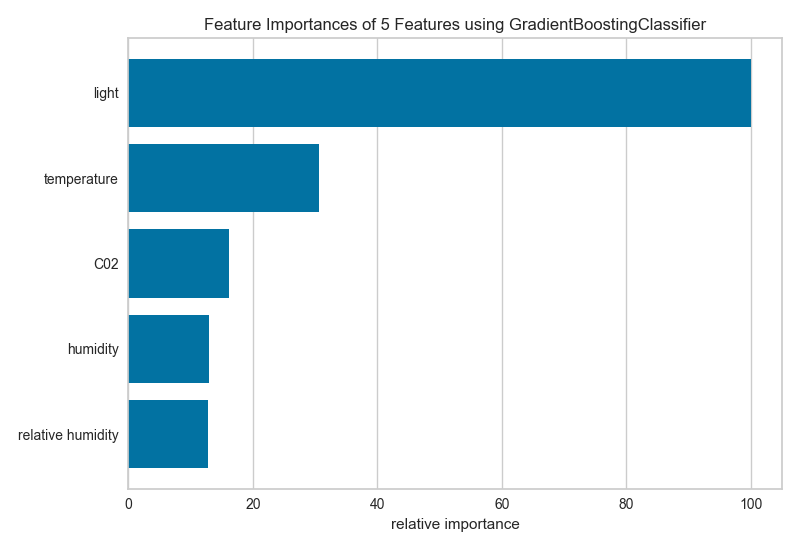
5、特征重要性 Feature Importance
特征工程過程涉及選擇生成有效模型所需的最小特征,因為模型包含的特征越多,它就越復雜(數(shù)據(jù)越稀疏),因此模型對方差的誤差越敏感。消除特征的常用方法是描述它們對模型的相對重要性,然后消除弱特征或特征組合并重新評估以確定模型在交叉驗證期間是否更好。
在scikit-learn中,Decision Tree模型和樹的集合(如Random Forest,Gradient Boosting和AdaBoost)在擬合時提供feature_importances_屬性。Yellowbrick FeatureImportances可視化工具利用此屬性對相對重要性進行排名和繪制。
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingClassifier
from yellowbrick.features.importances import FeatureImportances
# 繪圖
fig = plt.figure()
ax = fig.add_subplot()
viz = FeatureImportances(GradientBoostingClassifier(), ax=ax)
viz.fit(X, y)
viz.poof()
6、遞歸特征消除 Recursive Feature Elimination
遞歸特征消除(RFE)是一種特征選擇方法,它訓練模型并刪除最弱的特征(或多個特征),直到達到指定數(shù)量的特征。特征按模型的coef_或feature_importances_屬性排序,并通過遞歸消除每個循環(huán)的少量特征,RFE嘗試消除模型中可能存在的依賴性和共線性。
RFE需要保留指定數(shù)量的特征,但事先通常不知道有多少特征有效。為了找到最佳數(shù)量的特征,交叉驗證與RFE一起用于對不同的特征子集進行評分,并選擇最佳評分特征集合。RFECV可視化繪制模型中的特征數(shù)量以及它們的交叉驗證測試分數(shù)和可變性,并可視化所選數(shù)量的特征。
from sklearn.svm import SVC
from sklearn.datasets import make_classification
from yellowbrick.features import RFECV
# 造數(shù)據(jù)集
X, y = make_classification(
n_samples=1000, n_features=25, n_informative=3, n_redundant=2,
n_repeated=0, n_classes=8, n_clusters_per_class=1, random_state=0
)
# linear SVM 分類器創(chuàng)建遞歸特征消除
viz = RFECV(SVC(kernel='linear', C=1))
viz.fit(X, y)
viz.poof()
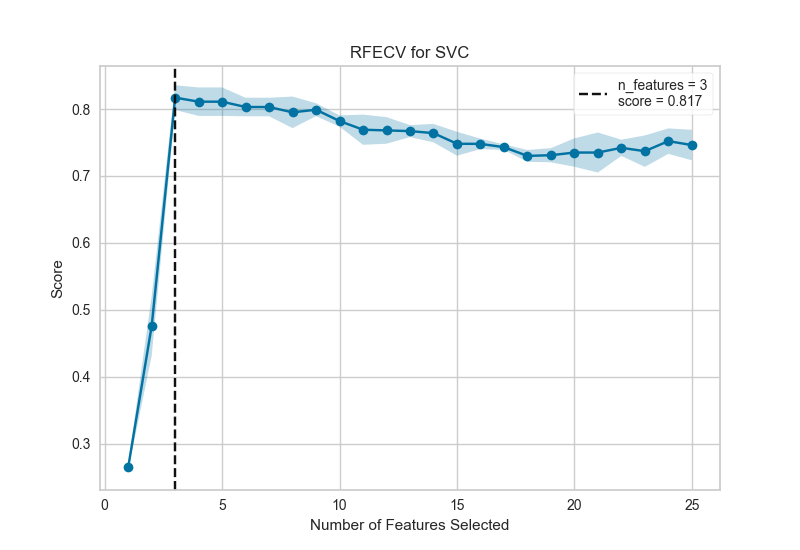
該圖顯示了理想的RFECV曲線,當捕獲三個信息特征時,曲線跳躍到極好的準確度,然后隨著非信息特征被添加到模型中,精度逐漸降低。陰影區(qū)域表示交叉驗證的可變性,一個標準偏差高于和低于曲線繪制的平均精度得分。
下面是一個真實數(shù)據(jù)集,我們可以看到RFECV對信用違約二元分類器的影響。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import StratifiedKFold
df = load_data('credit')
target = 'default'
features = [col for col in data.columns if col != target]
X = data[features]
y = data[target]
cv = StratifiedKFold(5)
oz = RFECV(RandomForestClassifier(), cv=cv, scoring='f1_weighted')
oz.fit(X, y)
oz.poof()
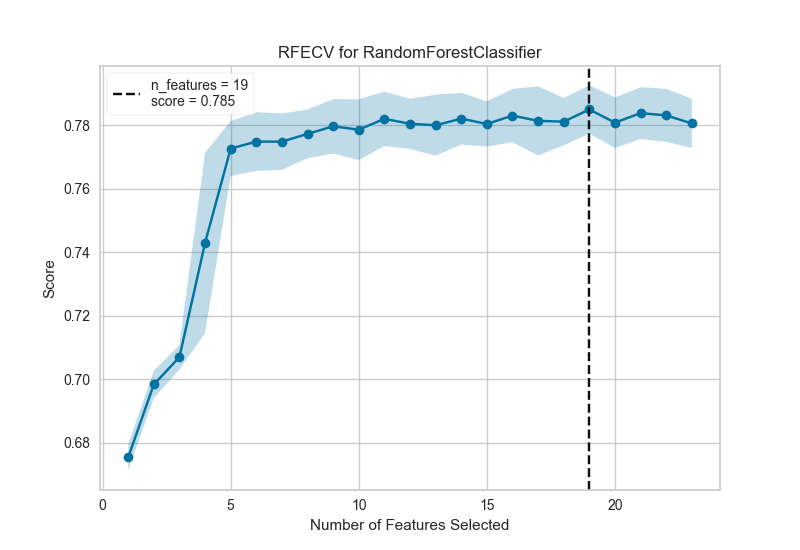
在這個例子中,我們可以看到選擇了19個特征,盡管在大約5個特征之后模型的f1分數(shù)似乎沒有太大改善。選擇要消除的特征在確定每個遞歸的結(jié)果中起著重要作用;修改步驟參數(shù)以在每個步驟中消除多個特征可能有助于盡早消除最差特征,增強其余特征(并且還可用于加速具有大量特征的數(shù)據(jù)集的特征消除)。
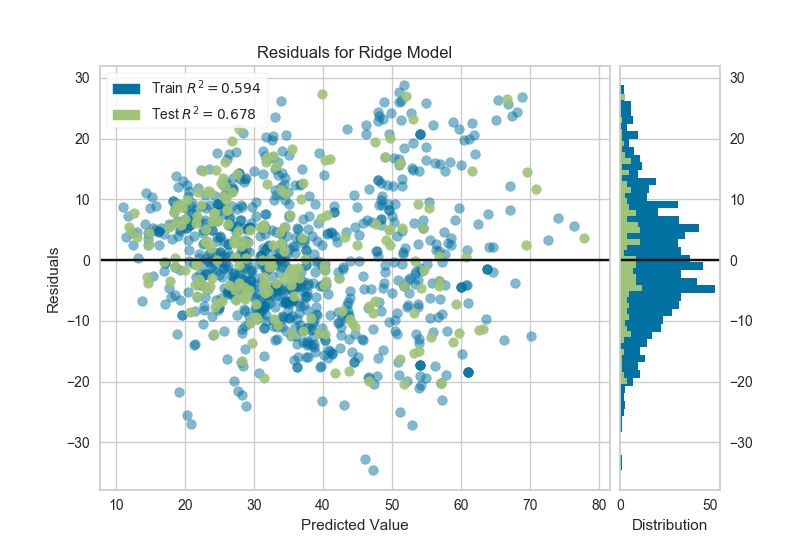
7、殘差圖 Residuals Plot
在回歸模型的上下文中,殘差是目標變量(y)的觀測值與預測值(?)之間的差異,例如,預測的錯誤。殘差圖顯示垂直軸上的殘差與水平軸上的因變量之間的差異,允許檢測目標中可能容易出錯或多或少的誤差的區(qū)域。
from sklearn.linear_model import Ridge
from yellowbrick.regressor import ResidualsPlot
# 創(chuàng)建嶺回歸和殘差圖
ridge = Ridge()
visualizer = ResidualsPlot(ridge)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
8、正則化 Alpha Selection
正則化旨在懲罰模型復雜性,因此α越高,模型越復雜,由于方差(過度擬合)而減少誤差。另一方面,太高的Alpha會因偏差(欠調(diào))而增加誤差。因此,重要的是選擇最佳α,以便在兩個方向上最小化誤差。
AlphaSelection Visualizer演示了不同的α值如何影響線性模型正則化過程中的模型選擇。一般而言,α增加了正則化的影響,例如,如果alpha為零,則沒有正則化,α越高,正則化參數(shù)對最終模型的影響越大。
import numpy as np
from sklearn.linear_model import LassoCV
from yellowbrick.regressor import AlphaSelection
# 創(chuàng)建alpha進行交叉驗證
alphas = np.logspace(-10, 1, 400)
# 創(chuàng)建線性模型和可視化
model = LassoCV(alphas=alphas)
visualizer = AlphaSelection(model)
visualizer.fit(X, y)
g = visualizer.poof()
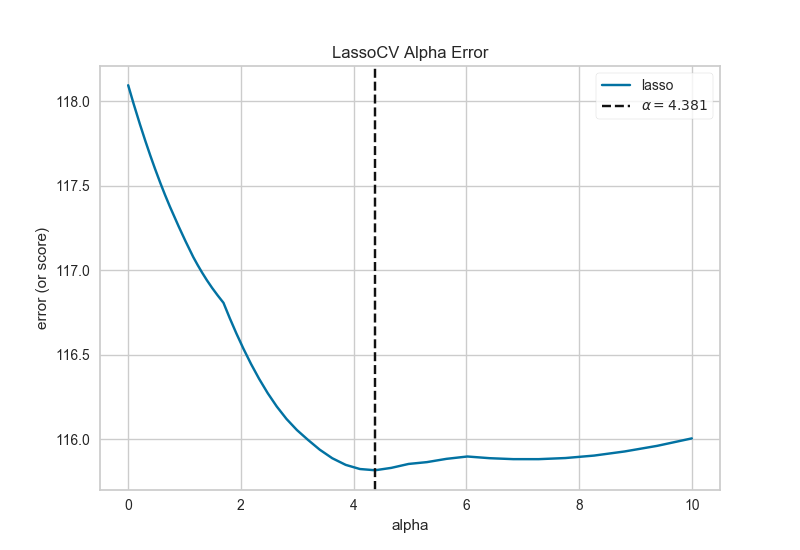
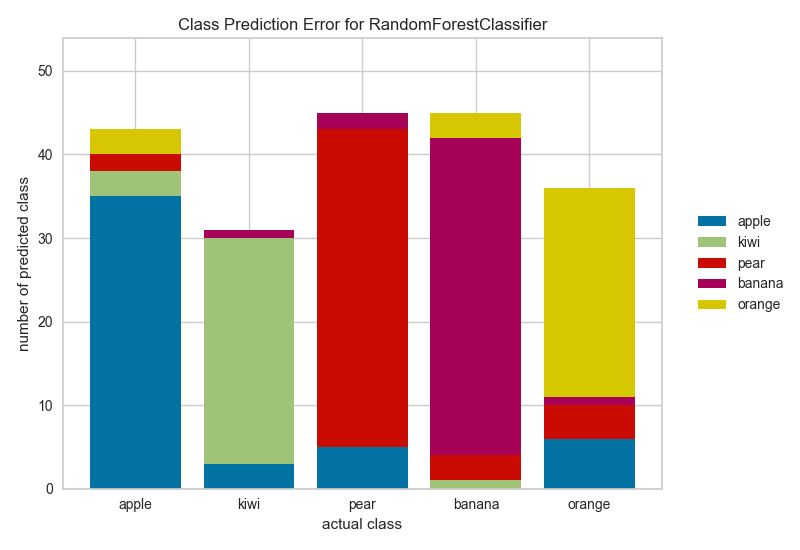
9、分類預測誤差 Class Prediction Error
分類預測誤差圖提供了一種快速了解分類器在預測正確類別方面有多好的方法。
from sklearn.ensemble import RandomForestClassifier
from yellowbrick.classifier import ClassPredictionError
# 創(chuàng)建分類器和可視化
visualizer = ClassPredictionError(
RandomForestClassifier(), classes=classes
)
# 訓練visualizer
visualizer.fit(X_train, y_train)
# 用測試數(shù)據(jù)驗證模型
visualizer.score(X_test, y_test)
# 繪圖
g = visualizer.poof()
 當然也同時有分類評估指標的可視化,包括混淆矩陣、AUC/ROC、召回率/精準率等等。
當然也同時有分類評估指標的可視化,包括混淆矩陣、AUC/ROC、召回率/精準率等等。
10、二分類辨別閾值 Discrimination Threshold
關(guān)于二元分類器的辨別閾值的精度,召回,f1分數(shù)和queue rate的可視化。辨別閾值是在陰性類別上選擇正類別的概率或分數(shù)。通常,將其設(shè)置為50%,但可以調(diào)整閾值以增加或降低對誤報或其他應用因素的敏感度。
from sklearn.linear_model import LogisticRegression
from yellowbrick.classifier import DiscriminationThreshold
# 創(chuàng)建分類器和可視化
logistic = LogisticRegression()
visualizer = DiscriminationThreshold(logistic)
visualizer.fit(X, y)
visualizer.poof()
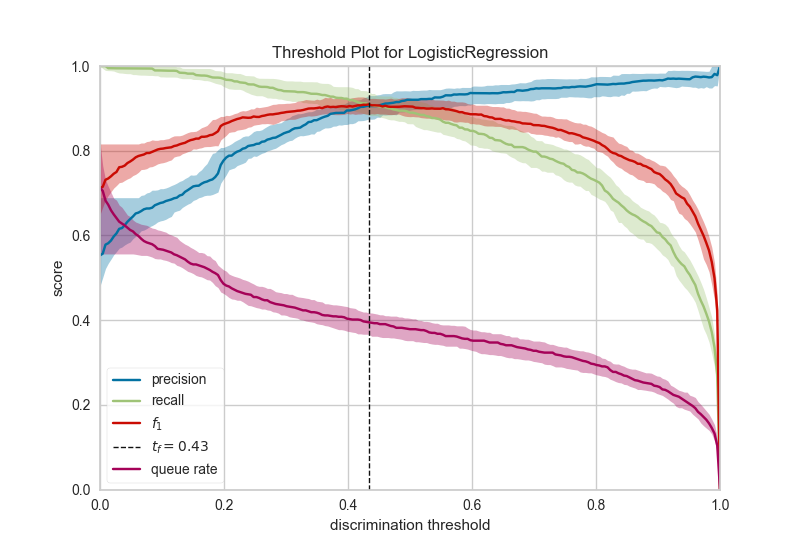
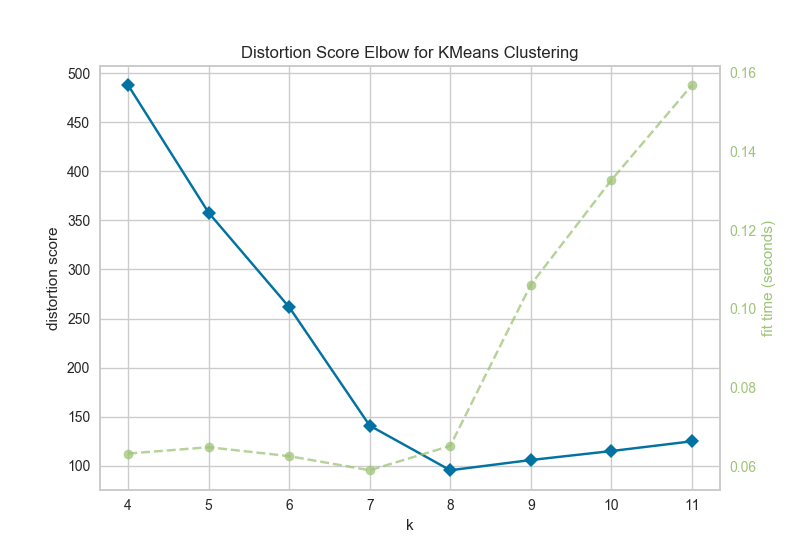
11、聚類肘部法則 Elbow Method
KElbowVisualizer實現(xiàn)了“肘部”法則,通過使模型具有K的一系列值來幫助數(shù)據(jù)科學家選擇最佳簇數(shù)。如果折線圖類似于手臂,那么“肘”(拐點)就是曲線)是一個很好的跡象,表明基礎(chǔ)模型最適合那一點。
在下面的示例中,KElbowVisualizer在具有8個隨機點集的樣本二維數(shù)據(jù)集上適合KMeans模型,以獲得4到11的K值范圍。當模型適合8個聚類時,我們可以在圖中看到“肘部”,在這種情況下,我們知道它是最佳數(shù)字。
from sklearn.datasets import make_blobs
# 創(chuàng)建8個隨機的簇
X, y = make_blobs(centers=8, n_features=12, shuffle=True, random_state=42)
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
# 創(chuàng)建Kmeans聚類模型和可視化
model = KMeans()
visualizer = KElbowVisualizer(model, k=(4,12))
visualizer.fit(X)
visualizer.poof()
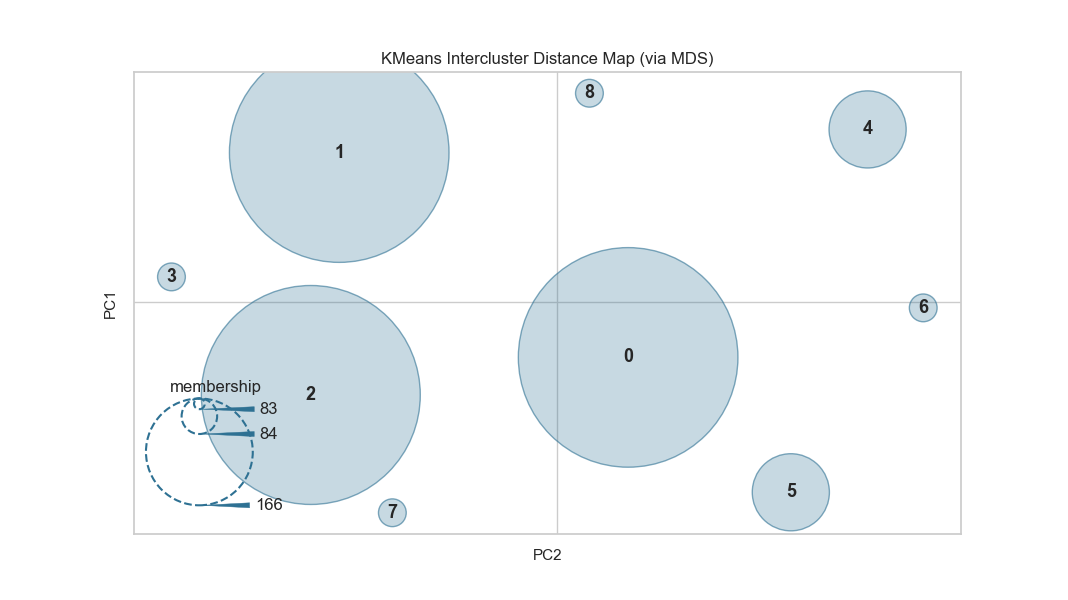
12、集群間距離圖 Intercluster Distance Maps
集群間距離地圖以2維方式顯示集群中心的嵌入,并保留與其他中心的距離。例如。中心越靠近可視化,它們就越接近原始特征空間。根據(jù)評分指標調(diào)整集群的大小。默認情況下,它們按內(nèi)部數(shù)據(jù)的多少,例如屬于每個中心的實例數(shù)。這給出了集群的相對重要性。但請注意,由于兩個聚類在2D空間中重疊,因此并不意味著它們在原始特征空間中重疊。
from sklearn.datasets import make_blobs
# 創(chuàng)建簇數(shù)12的數(shù)據(jù)集
X, y = make_blobs(centers=12, n_samples=1000, n_features=16, shuffle=True)
from sklearn.cluster import KMeans
from yellowbrick.cluster import InterclusterDistance
# 創(chuàng)建Kmeans聚類模型和可視化
visualizer = InterclusterDistance(KMeans(9))
visualizer.fit(X)
visualizer.poof()
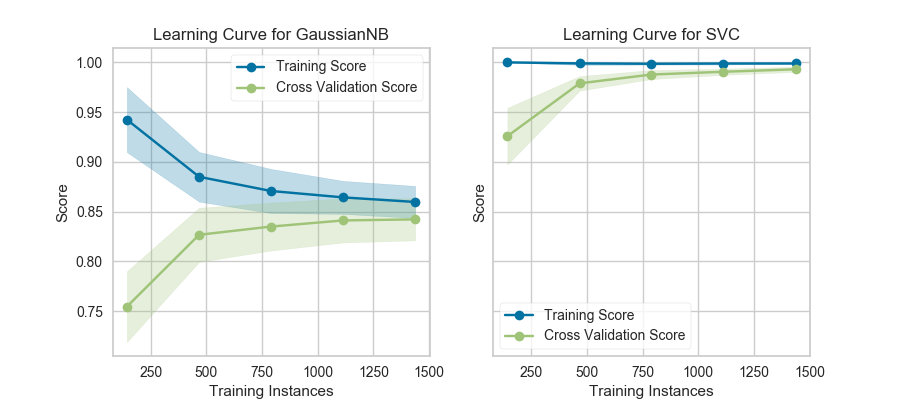
13、模型選擇-學習曲線 Learning Curve
學習曲線基于不同數(shù)量的訓練樣本,檢驗模型訓練分數(shù)與交叉驗證測試分數(shù)的關(guān)系。這種可視化通常用來表達兩件事:
1. 模型會不會隨著數(shù)據(jù)量增多而效果變好
2. 模型對偏差和方差哪個更加敏感
下面是利用yellowbrick生成的學習曲線可視化圖。該學習曲線對于分類、回歸和聚類都可以適用。
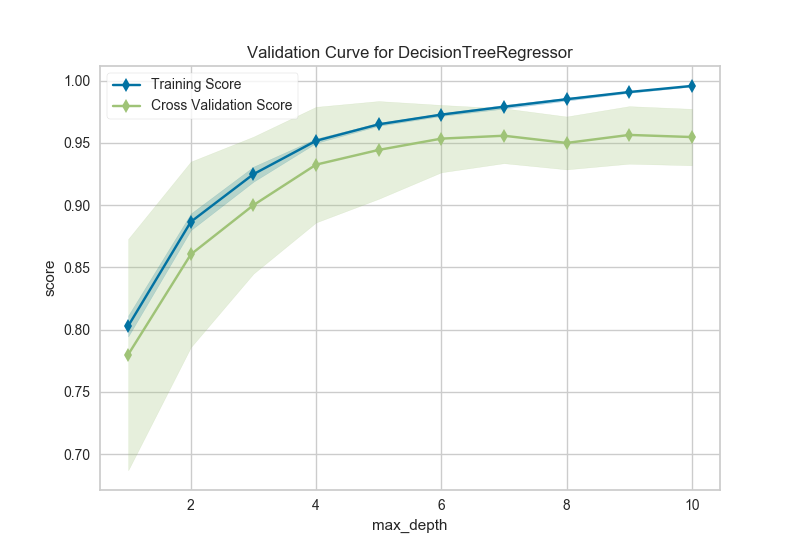
14、模型選擇-驗證曲線 Validation Curve
模型驗證用于確定模型對其已經(jīng)過訓練的數(shù)據(jù)的有效性以及它對新輸入的泛化程度。為了測量模型的性能,我們首先將數(shù)據(jù)集拆分為訓練和測試,將模型擬合到訓練數(shù)據(jù)上并在保留的測試數(shù)據(jù)上進行評分。
為了最大化分數(shù),必須選擇模型的超參數(shù),以便最好地允許模型在指定的特征空間中操作。大多數(shù)模型都有多個超參數(shù),選擇這些參數(shù)組合的最佳方法是使用網(wǎng)格搜索。然而,繪制單個超參數(shù)對訓練和測試數(shù)據(jù)的影響有時是有用的,以確定模型是否對某些超參數(shù)值不適合或過度擬合。
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from yellowbrick.model_selection import ValidationCurve
# 導入數(shù)據(jù)集
data = load_data('energy')
# 選擇特征和目標變量
targets = ["heating load", "cooling load"]
features = [col for col in data.columns if col not in targets]
# 設(shè)置x和y
X = data[features]
y = data[targets[0]]
viz = ValidationCurve(
DecisionTreeRegressor(), param_name="max_depth",
param_range=np.arange(1, 11), cv=10, scoring="r2"
)
# 訓練和可視化
viz.fit(X, y)
viz.poof()
三、總結(jié)
yellowbrick這個工具太棒了,有木有?東哥認為原因有兩點:
1、解決了特征工程和建模過程中的可視化問題,極大地簡化了操作;
2、通過各種可視化也可以補充自己對建模的一些盲區(qū)。
本篇僅展示了建模中部分可視化功能,詳細的完整功能可以下面這個鏈接:
https://www.scikit-yb.org/en/latest/index.html

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」