
【數(shù)據(jù)分析】Python數(shù)據(jù)分析學(xué)習(xí)路線個(gè)人總結(jié)
數(shù)據(jù)分析人人都有必要掌握一點(diǎn),哪怕只是思維也行。下面探討Python數(shù)據(jù)分析需要學(xué)習(xí)的知識(shí)范疇,結(jié)合自己的經(jīng)歷和理解,總結(jié)的學(xué)習(xí)大綱,有些章節(jié)帶有解釋,有些沒(méi)有。當(dāng)然,關(guān)于學(xué)習(xí)范疇,可能每個(gè)人的理解都不太一樣,以下僅供參考。

1 數(shù)據(jù)分析思維
數(shù)據(jù)分析屬于分析思維的一個(gè)子類,有專門(mén)的數(shù)據(jù)方法論。只有先養(yǎng)成正確的分析思維,才能使用好數(shù)據(jù)。
大多數(shù)人的思維方式都依賴于生活和經(jīng)驗(yàn)做出直覺(jué)性的判斷,最直觀的體現(xiàn)是,在數(shù)據(jù)和業(yè)務(wù)分析中有時(shí)無(wú)從下手。
什么是好的分析思維?
用兩張?jiān)诰W(wǎng)絡(luò)上流傳甚廣的圖片說(shuō)明
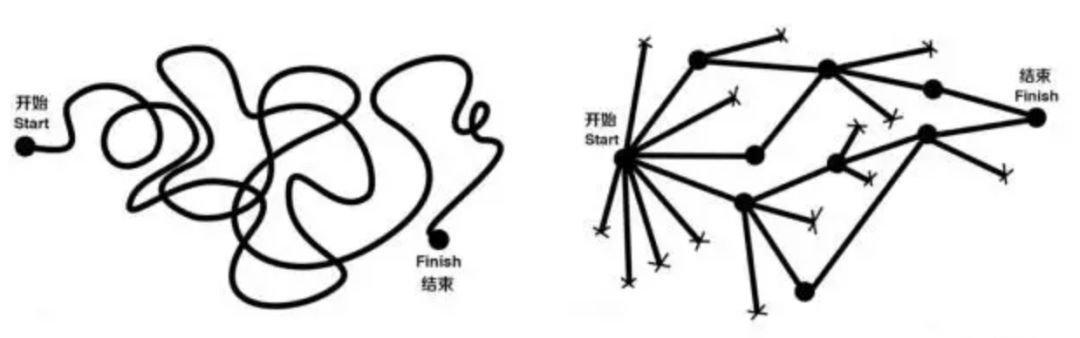
思維模式(圖片來(lái)源網(wǎng)絡(luò))
對(duì)應(yīng)以下兩種思維:
我們12月的銷售額度下降,我想是因?yàn)槟杲K的影響,我問(wèn)了幾個(gè)銷售員,他們都說(shuō)年終生意不太好做,各家都收緊了財(cái)務(wù)預(yù)算,談下的幾家費(fèi)用也比以前有縮水。我對(duì)他們進(jìn)行了電話拜訪,廠家都說(shuō)經(jīng)濟(jì)不景氣,希望我們價(jià)格方面再放寬點(diǎn)。
我們12月的銷售額度下降,低于去年同期和今年平均值,可以排除掉大環(huán)境的因素。其中A地區(qū)下降幅度最大,間接影響了整體銷售額。通過(guò)調(diào)查發(fā)現(xiàn),A地區(qū)的市場(chǎng)因?yàn)楦?jìng)爭(zhēng)對(duì)手涌入,進(jìn)行了低價(jià)銷售策略。除此之外,B地區(qū)的經(jīng)濟(jì)發(fā)展低于預(yù)期發(fā)展,企業(yè)縮減投入。
第一個(gè)分析思維是依賴經(jīng)驗(yàn)和直覺(jué)的線性思維,第二個(gè)分析思維則注重邏輯推導(dǎo),屬于結(jié)構(gòu)化的思維。兩種思維往往會(huì)導(dǎo)致不同的結(jié)果。
1.1 金子塔原理
麥肯錫思維中很重要的一條原理叫做金字塔原理,它的核心是層次化思考、邏輯化思考、結(jié)構(gòu)化思考。
1.1.1 什么是金字塔?
任何一件事情都有一個(gè)中心論點(diǎn),中心論點(diǎn)可以劃分成3~7個(gè)分論點(diǎn),分論點(diǎn)又可以由3~7個(gè)論據(jù)支撐。層層拓展,這個(gè)結(jié)構(gòu)由上至下呈金字塔狀。
1.1.2 結(jié)構(gòu)化思維

1.1.3 核心法則:MECE
金字塔原理有一個(gè)核心法則MECE,全稱 Mutually Exclusive Collectively Exhaustive,論點(diǎn)相互獨(dú)立,盡可能多的列舉。
1.1.4 假設(shè)先行
首先得有一個(gè)思考作為開(kāi)始。這是什么意思?因?yàn)榻鹱炙菑纳隙拢枰幸粋€(gè)中心論點(diǎn),也就是塔尖。我們可以先提出一個(gè)問(wèn)題,比如此產(chǎn)品的核心功能是某某功能嗎?
1.2 二八法則
1.2.1 20%的分析過(guò)程決定80%的分析結(jié)果
1.2.2 抓住關(guān)鍵因素
以上節(jié)選的兩個(gè)分析思維,都能在麥肯錫問(wèn)題分析與解決技巧中找到原型,感興趣的可查看下面這本書(shū)。
2 數(shù)據(jù)獲取
2.1 大數(shù)據(jù)平臺(tái)提取
各個(gè)公司都可能有自己專屬的大數(shù)據(jù)平臺(tái),進(jìn)入公司要首先掌握如何從這上面拿去我們需要的業(yè)務(wù)數(shù)據(jù)
2.2 第三方服務(wù)接口
合作企業(yè)或公司購(gòu)買(mǎi)的服務(wù)接口,我們可以直接調(diào)用拿到數(shù)據(jù)。
2.3 開(kāi)源公開(kāi)數(shù)據(jù)集
2.4 爬蟲(chóng)爬取網(wǎng)站數(shù)據(jù)
python的常用包:
requests
json
BeautifulSoup
requests庫(kù)就是用來(lái)進(jìn)行網(wǎng)絡(luò)請(qǐng)求的,說(shuō)白了就是模擬瀏覽器來(lái)獲取資源。
由于我們采集的是api接口,它的格式為json,所以要用到j(luò)son庫(kù)來(lái)解析。
BeautifulSoup是用來(lái)解析html文檔的,可以很方便的幫我們獲取指定div的內(nèi)容。
3 數(shù)據(jù)存儲(chǔ)
3.1 SQL分組,聚合,多表join操作
groupby, aggregate,join操作
join操作可參考 Python與算法社區(qū) 公眾號(hào)
3.2 大數(shù)據(jù)平臺(tái)Hadoop
大數(shù)據(jù)架構(gòu),分布式存儲(chǔ),詳細(xì)自行查閱
3.3 Mysql
這個(gè)大家應(yīng)該都不陌生
3.4 hive 拉鏈表
拉鏈表的知識(shí)大家需要好好理解體會(huì),dp 的狀態(tài) active 和 history
4 數(shù)據(jù)清理知識(shí)
4.1 理解數(shù)據(jù)背后的業(yè)務(wù),千萬(wàn)不要忽視!
我們?cè)谀玫叫枰治龅臄?shù)據(jù)后,千萬(wàn)不要急于立刻開(kāi)始做回歸、分類、聚類分析。
第一步應(yīng)該是認(rèn)真理解業(yè)務(wù)數(shù)據(jù),可以試著理解去每個(gè)特征,觀察每個(gè)特征,理解它們對(duì)結(jié)果的影響程度。
然后,慢慢研究多個(gè)特征組合后,它們對(duì)結(jié)果的影響。
4.2 明確各個(gè)特征的類型
如果這些數(shù)據(jù)類型不是算法部分期望的數(shù)據(jù)類型,你還得想辦法編碼成想要的。比如常見(jiàn)的數(shù)據(jù)自增列 id 這類數(shù)據(jù),是否有必要放到你的算法模型中,因?yàn)檫@類數(shù)字很可能被當(dāng)作數(shù)字讀入。
某些列的取值類型,雖然已經(jīng)是數(shù)字了,它們的取值大小表示什么含義你也要仔細(xì)捉摸。因?yàn)椋瑪?shù)字的相近相鄰,并不一定代表另一種層面的相鄰。
4.3 找出異常數(shù)據(jù)
統(tǒng)計(jì)中國(guó)家庭人均收入時(shí),如果源數(shù)據(jù)里面,有王建林,馬云等這種富豪,那么,人均收入的均值就會(huì)受到極大的影響,這個(gè)時(shí)候最好,繪制箱形圖,看一看百分位數(shù)。
4.4 處理缺失值
現(xiàn)實(shí)生產(chǎn)環(huán)境中,拿到的數(shù)據(jù)恰好完整無(wú)損、沒(méi)有任何缺失數(shù)據(jù)的概率,和買(mǎi)彩票中將的概率差不多。
數(shù)據(jù)缺失的原因太多了,業(yè)務(wù)系統(tǒng)版本迭代, 之前的某些字段不再使用了,自然它們的取值就變?yōu)?null 了;再或者,壓根某些數(shù)據(jù)字段在抽樣周期里,就是沒(méi)有寫(xiě)入數(shù)據(jù)……
4.5 頭疼的數(shù)據(jù)不均衡問(wèn)題
理論和實(shí)際總是有差距的,理論上很多算法都存在一個(gè)基本假設(shè),即數(shù)據(jù)分布總是均勻的。這個(gè)美好的假設(shè),在實(shí)際中,真的存在嗎?很可能不是!
算法基于不均衡的數(shù)據(jù)學(xué)習(xí)出來(lái)的模型,在實(shí)際的預(yù)測(cè)集上,效果往往差于訓(xùn)練集上的效果,這是因?yàn)閷?shí)際數(shù)據(jù)往往分布得很不均勻,這時(shí)候就要考慮怎么解決這些問(wèn)題。下面是一本數(shù)據(jù)清洗不錯(cuò)的書(shū)籍:
5 Python核心知識(shí)
5.1 理解Python的解釋性
Python 是解釋型語(yǔ)言,對(duì)于 Python 剛剛?cè)腴T(mén)的小伙伴,可能對(duì)解釋性有些疑惑。不過(guò),沒(méi)關(guān)系,我們可以通過(guò)大家已經(jīng)熟悉的編譯型語(yǔ)言,來(lái)幫助我們理解 Python 的解釋性。
編譯型語(yǔ)言,如 C++、Java,它們會(huì)在編譯階段做類型匹配檢查等,因此,數(shù)據(jù)類型不匹配導(dǎo)致的編譯錯(cuò)誤,在編譯階段就會(huì)被檢查出來(lái),例如:
Intger a = 0;
Double b = 0.0;
a = b; // Double類型的變量 b 試圖賦值給 Integer 型的變量 a, 編譯報(bào)錯(cuò)
// 因?yàn)?Integer 類型 和 Double 類型 不存在繼承關(guān)系,
// 類型不能互轉(zhuǎn)
但是,Python 就不會(huì)在編譯階段做類型匹配檢查,比如,Python 實(shí)現(xiàn)上面的幾行語(yǔ)句,會(huì)這樣寫(xiě):
a = 0 # 不做任何類型聲明
b = 0.
a = b # 這種賦值,Python 會(huì)有問(wèn)題嗎?
答案是不會(huì)的。此處就體現(xiàn)了 Python 的解釋特性,當(dāng)我們把 0 賦值給 a 時(shí),Python 解釋器會(huì)把它 a 解釋為 int 型,可以使用內(nèi)置函數(shù) type(variable) 顯示地檢查 variable 的類型:
In [70]: type(a)
Out[70]: int
In [69]: type(b)
Out[69]: float
In [71]: a = b # 在把 float 型 b 賦值給 a 后, # a 就被解釋為float
In [72]: type(a)
Out[72]: float
在把 float 型 b 賦值給 a 后, a 就被解釋為 float.
5.2 list,dict,tuple,set
深拷貝和淺拷貝的區(qū)別
5.3 Python列表生成式
如何靈活使用
5.4 Python函數(shù)式編程
閉包問(wèn)題
5.5 位置參數(shù)和關(guān)鍵字參數(shù)
如果介紹 Python 入門(mén),不介紹函數(shù)的位置參數(shù) ( positional argument ) 和關(guān)鍵字參數(shù)( keyword argument ) ,總是感覺(jué)缺少點(diǎn)什么,它們?cè)?Python 函數(shù)中到處可見(jiàn),理解和使用它們,為我們?nèi)蘸笊钊?Python 打下堅(jiān)實(shí)的根基。
6 Excel數(shù)據(jù)分析
6.1 Excel處理10萬(wàn)條以內(nèi)數(shù)據(jù)
6.2 以SUM函數(shù)為首的求和家族
6.3 以VLOOKUP函數(shù)為首的查找家族
6.4 以IF函數(shù)為首的邏輯函數(shù)家族
大家自行查閱學(xué)習(xí)
7 Pandas數(shù)據(jù)預(yù)處理
7.1 基于Python的向量化增強(qiáng)
7.2 必須掌握的傳播機(jī)制
廣播發(fā)生的條件
7.3 一維Series和二維DataFrame
7.4 Pandas中的20個(gè)統(tǒng)計(jì)學(xué)函數(shù)

7.5 Pandas三個(gè)函數(shù)搞定缺失值
7.6 1個(gè)函數(shù)搞定數(shù)據(jù)透視
8 數(shù)據(jù)建模分析
8.1 統(tǒng)計(jì)學(xué)基礎(chǔ)知識(shí)
首先,入門(mén)數(shù)據(jù)分析需要必備一些統(tǒng)計(jì)學(xué)的基本知識(shí),在這里我們簡(jiǎn)單列舉幾個(gè)入門(mén)級(jí)的重要概念。概率,平均值,中位數(shù),眾數(shù),四分位數(shù),期望,標(biāo)準(zhǔn)差,方差。在這些基本概念上,又衍生出的很多重要概念,比如協(xié)方差,相關(guān)系數(shù)等。
這一些列常用的統(tǒng)計(jì)指標(biāo),都在強(qiáng)大的數(shù)據(jù)分析包 Pandas 中實(shí)現(xiàn)了,非常方便。
8.2 統(tǒng)計(jì)量描述
說(shuō)統(tǒng)計(jì)學(xué)是一種基于事實(shí)的演繹學(xué)問(wèn),它是嚴(yán)謹(jǐn)?shù)模梢越o出確切解釋的。
不過(guò),機(jī)器學(xué)習(xí)就不一樣了,它是一門(mén)歸納思想的學(xué)問(wèn),比如深度學(xué)習(xí)得出的模型,你就很難解釋其中的具體參數(shù)為什么取值為某某某。它的應(yīng)用在于可以提供一種預(yù)測(cè),給我們未來(lái)提供一種建設(shè)性的指導(dǎo)。
數(shù)據(jù)分析師需要了解機(jī)器學(xué)習(xí)的基本理論、常見(jiàn)的那十幾種算法,這樣對(duì)于我們做回歸、分類、聚類分析,都是不可缺少的。
8.3 機(jī)器學(xué)習(xí)回歸分析
三 個(gè)假定是?
如何建立線性回歸模型?
最大似然估計(jì)求參數(shù)?
梯度下降求解優(yōu)化問(wèn)題?
手寫(xiě)不調(diào)包實(shí)現(xiàn)的 5 個(gè)算子
手寫(xiě)不調(diào)包實(shí)現(xiàn)的整體算法框架
8.4 基本的分類、聚類算法
高斯混合模型:不調(diào)包多維數(shù)據(jù)聚類分析
8.5 特征工程提高分析精度
一般來(lái)說(shuō),特征工程大體上可以分為三個(gè)方面,一是特征構(gòu)造,二是特征選擇,三是特征生成。
9 數(shù)據(jù)可視化
9.1 必備的繪圖原理知識(shí)
拿使用較多的 matplotlib 為列,整個(gè)圖像為一個(gè)Figure?對(duì)象,在?Figure?對(duì)象中可以包含一個(gè)或多個(gè)?Axes對(duì)象,每個(gè)Axes對(duì)象都是一個(gè)擁有自己坐標(biāo)系統(tǒng)的繪圖區(qū)域。
Axes?由?xaxis,?yaxis,?title,?data?構(gòu)成,xaxis?由坐標(biāo)軸的線 ,tick以及label構(gòu)成。
9.2 matplotlib繪圖

9.3 繪圖必備100行代碼
參考:關(guān)于數(shù)據(jù)分析的學(xué)習(xí)路線,我準(zhǔn)備寫(xiě)一篇 2 萬(wàn)+的 chat
10 數(shù)據(jù)挖掘分析
10.1 正則表達(dá)式
學(xué)習(xí)正則表達(dá)式語(yǔ)法,主要就是學(xué)習(xí)元字符以及它們?cè)谡齽t表達(dá)式上下文中的行為。常見(jiàn)的元字符比如普通字符、標(biāo)準(zhǔn)字符、特殊字符、限定字符(又叫量詞)、定位字符(也叫邊界字符)。
10.2 決策樹(shù)
10.3 貝葉斯方法
單詞拼寫(xiě)糾正器python實(shí)現(xiàn)
10.4 集成學(xué)習(xí)方法
XGBoost 安裝及實(shí)戰(zhàn)應(yīng)用? ?
10.5 NLP
往期精彩回顧