
【Python私活案例】500元,提供exe實(shí)現(xiàn)批量excel文件的存入mysql數(shù)據(jù)庫
下午的時(shí)候我正無聊的刷著手機(jī),就聽叮咚一聲,我就順便看了一眼,好家伙是老師在發(fā)賺錢的單子,我再一看,這不是我剛剛學(xué)過去的知識(shí)嗎,二話不說立馬就開啟了‘搶單’模式。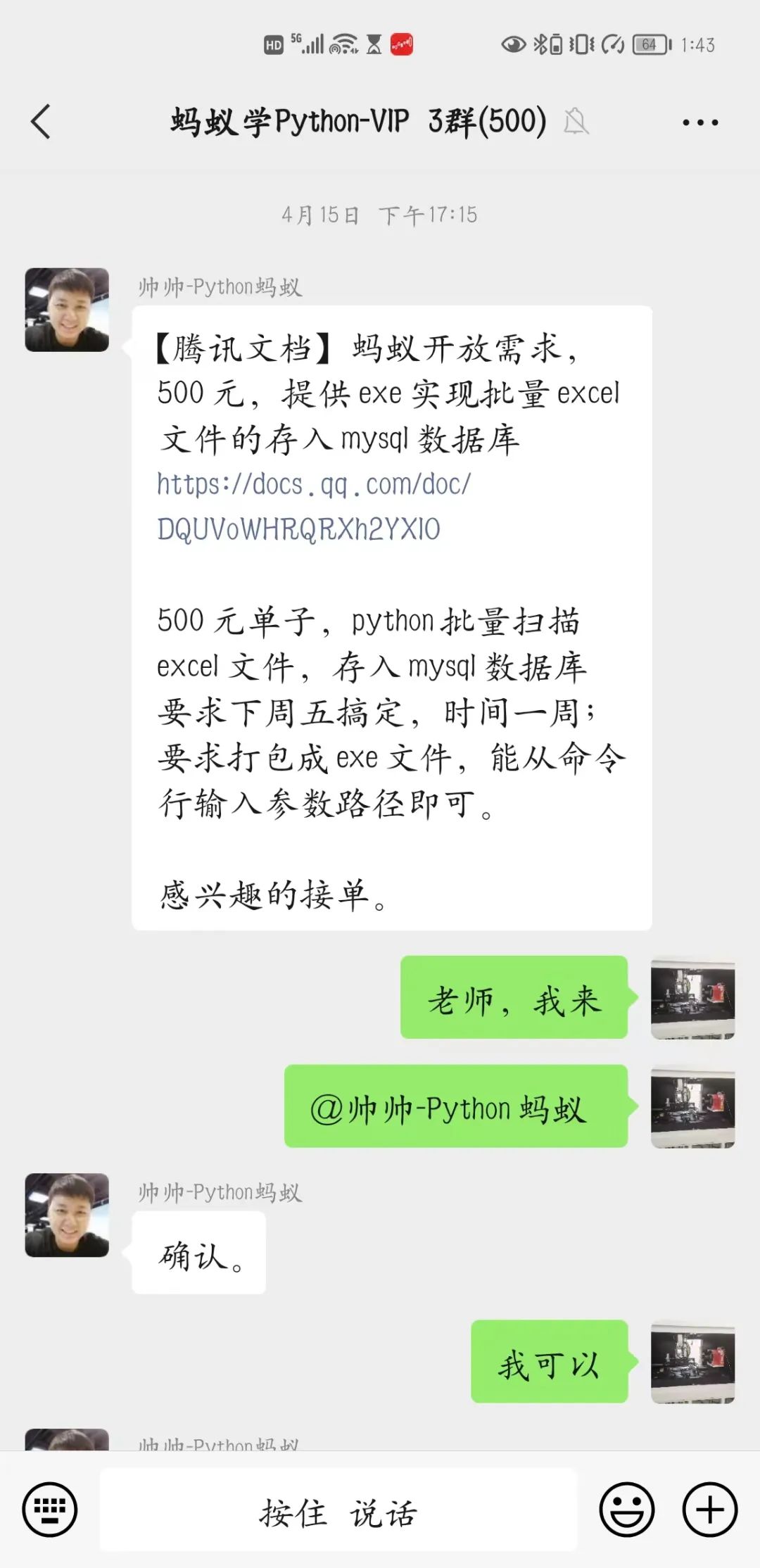 感謝老師讓我得到了批量將excel文件存入mysql數(shù)據(jù)庫的單子,本來以為很簡(jiǎn)單的單子,但是遇到幾個(gè)我忽略的問題,讓我著實(shí)頭疼了一番,看來還是要多學(xué)習(xí)才行。
感謝老師讓我得到了批量將excel文件存入mysql數(shù)據(jù)庫的單子,本來以為很簡(jiǎn)單的單子,但是遇到幾個(gè)我忽略的問題,讓我著實(shí)頭疼了一番,看來還是要多學(xué)習(xí)才行。
【業(yè)務(wù)需求】
打開exe后,彈出一個(gè)exe命令行窗口,輸入路徑,執(zhí)行遞歸掃描很多個(gè)excel文件,存入mysql數(shù)據(jù)庫
【代碼實(shí)現(xiàn)分析】
需求分析:
需要批量讀取excel; 需要存入mysql; 需要將py文件打包為exe
看起來就是如此簡(jiǎn)單 不過經(jīng)過進(jìn)一步溝通才知道:
是有很多excel文件存在不同級(jí)別的文件夾里,每個(gè)excel里面又有很多的表數(shù)據(jù),幸好表的格式基本相同。 批量讀取excel表內(nèi)容,并簡(jiǎn)單處理用pandas更加的方便一點(diǎn),果斷選擇pandas,不過to_sql命令我比較陌生,又去學(xué)習(xí)了一番; 打包工具,也比較簡(jiǎn)單pyinstaller,網(wǎng)上教程一大堆,沒啥可說的。
【代碼實(shí)現(xiàn)】
首先我想到的是編一個(gè)函數(shù),來找到目錄內(nèi)所有的excel相關(guān)文件的位置,這里我用的是pathlib2的Path下的rglob函數(shù),直接可以選出目錄內(nèi)包含子文件夾下的所有符合條件的文件(這里要感謝船長的提醒,讓我少走了好多的彎路,不然我鐵定要用循環(huán)遍歷的。。。。)
#得到目錄里面所有的excel文件和csv文件
def?get_path():
????while?True:
????????path?=?input("請(qǐng)輸入需要查找的目錄:")
????????if?Path(path).exists():
????????????break
????????else:
????????????print('您輸入的目錄不存在,請(qǐng)檢查!!!!')
????print('正在查找中。。。。')
????return?Path(path).rglob('**/*.xls*'),?Path(path).rglob('**/*.csv')
其次就是根據(jù)得到的文件路徑用pandas來讀取,由于一個(gè)excel文件有很多表,所以我是這么寫的,你發(fā)現(xiàn)什么問題了嗎?
def?readAllFiles():
????excel_file_list,csv_file_list?=?get_path()
????print('查找完成,數(shù)據(jù)整理中.....')
????for?file_e?in?excel_file_list:
????????df?=?pd.read_excel(file_e,?sheet_name=None)
????????for?sheet_name?in?df.keys():
????????????df_1?=?pd.read_excel(file_e,sheet_name=sheet_name,nrows=1)
????????????df_2?=?pd.read_excel(file_e,sheet_name=sheet_name,header=2)
????????????wash_data(df_1,df_2)
需要處理的表如下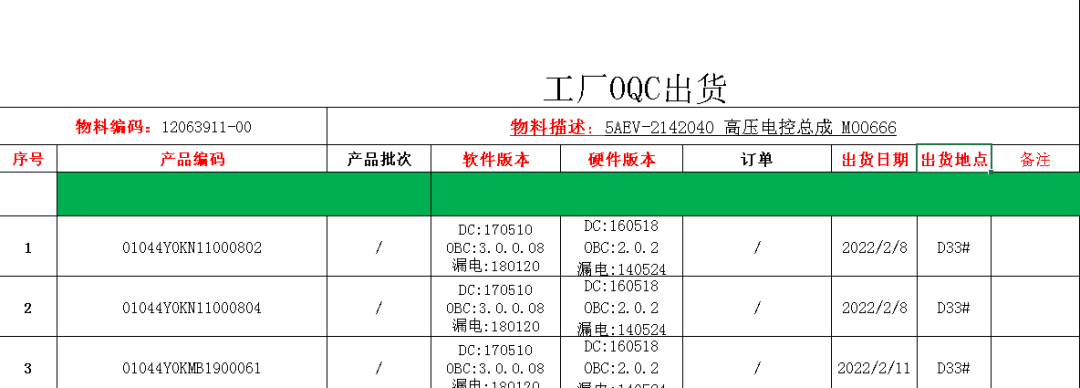
因?yàn)槲乙玫郊t色字對(duì)應(yīng)的信息,所以我用了2個(gè)pd.read_excel()來實(shí)現(xiàn)各自的目的,實(shí)現(xiàn)以后程序運(yùn)行竟然很慢很慢,想了很多方法———多線程,更改處理數(shù)據(jù)方式都沒有讓程序快起來,為什么這么慢呢?WHY??
在我百思不得要領(lǐng)的時(shí)候突然看到了pandas讀取,腦中靈光一現(xiàn),原來就是這么簡(jiǎn)單。你想到了嗎?對(duì)的,就是pandas讀取數(shù)據(jù)非常慢,而我竟然讓它讀了3遍——罪過罪過。然后我就改成了這樣:
excel_file_list,csv_file_list = get_path()
print('查找完成,數(shù)據(jù)整理中.....')
for file_e in excel_file_list:
try:
df = pd.read_excel(file_e, sheet_name=None)
for sheet_name in df.keys():
df_1 = df[sheet_name].loc[0:0,:]
df_2 = df[sheet_name].iloc[2:,:-1]
df_e = wash_data(df_1,df_2)
當(dāng)改成用pandas只讀取一次后,程序飛了起來,我也飛了起來——哈哈哈哈哈哈哈哈——此處允許我瘋一下!
剩下的數(shù)據(jù)處理,添加列,對(duì)列排隊(duì),存入數(shù)據(jù)庫等等都是小意思。直接看代碼吧!
#獲取物料編碼和物料描述
def?get_wlbm_wlms(s_list):
????wlbm?=?s_list[0].split(':')[-1].strip()
????wlms?=?s_list[1]?if?'物料描述'?not?in?s_list[1]?else?s_list[1].replace('(物料描述)','')
????return?wlbm,wlms
#數(shù)據(jù)清洗和排列
def?wash_data(df_1,df_2):
????df_1.dropna(axis=1,?how='all',?inplace=True)
????list_s?=?df_1.loc[0].values
????wlbm,?wlms?=?get_wlbm_wlms(list_s)
????if?not?df_2.empty:
????????df_2.columns?=?['序號(hào)',?'條碼',?'產(chǎn)品批次',?'軟件版本',?'硬件版本',?'訂單',?'出貨日期',?'出貨地點(diǎn)',?'備注']
????????#?刪除沒有用的列
????????df_2.dropna(axis=0,how='all',inplace=True)
????????df_2.drop(columns=['產(chǎn)品批次',?'訂單'],?inplace=True)
????????df_2?=?df_2.replace('/',np.NaN)
????????df_2['物料編碼']?=?wlbm
????????df_2['產(chǎn)品名稱']?=?wlms
????????df?=?df_2[['序號(hào)',?'條碼',?'出貨日期',?'產(chǎn)品名稱',?'出貨地點(diǎn)',?'物料編碼',?'軟件版本',?'硬件版本',?'備注']]
????else:
????????data?=?[[np.NaN,?np.NaN,?np.NaN,?wlms,?np.NaN,?wlbm,?np.NaN,?np.NaN,?np.NaN]]
????????df?=?pd.DataFrame(data,columns=['序號(hào)',?'條碼',?'出貨日期',?'產(chǎn)品名稱',?'出貨地點(diǎn)',?'物料編碼',?'軟件版本',?'硬件版本',?'備注'])
????return?df
def?get_sheet_data(sheet_name,df):
????????df_1?=?df[sheet_name].loc[0:0,:]
????????df_2?=?df[sheet_name].iloc[2:,:-1]
????????df_e?=?wash_data(df_1,df_2)
????????#?print(df_e)
????????df_e.to_sql(sql_info['TABLE_NAME'],?chunksize=10000,con=engine,?if_exists='append',?index=False,dtype=DATA_TYPE)
當(dāng)然這里有一個(gè)細(xì)節(jié)被我忽略了,在調(diào)試的時(shí)候才發(fā)現(xiàn),就是warning,看圖: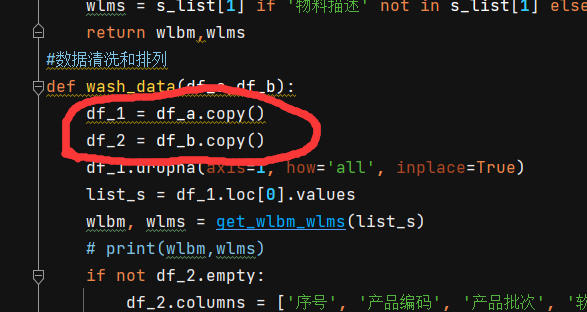 就是這里,記得一定要用copy()一下,不然你就會(huì)看到warning,想看的可以試試!!
就是這里,記得一定要用copy()一下,不然你就會(huì)看到warning,想看的可以試試!!
雖然我感覺數(shù)據(jù)清洗和處理是比較簡(jiǎn)單的,但是實(shí)際上也花了我一些的時(shí)間,由于pandas才剛剛開始學(xué),有些東西真的是邊學(xué)邊寫,幸好老師有很多東西都已經(jīng)給出了例子,照著來一遍就可以實(shí)現(xiàn)效果。這個(gè)要大大的感謝一下老師,老師的視頻做的實(shí)在是太詳細(xì)了!!
我雖然在我的電腦上數(shù)據(jù)庫用的沒有任何問題,但是到了客戶那邊就出了各種問題,說實(shí)話我真的對(duì)數(shù)據(jù)庫了解的不多,只能是有問題搜一下,根據(jù)自己的理解在自己的電腦上試一下。感慨一下,數(shù)據(jù)庫真的是一個(gè)細(xì)心的功夫活!!總的來說還是解決了~~
最后就是增加了一些記錄,防錯(cuò),防重復(fù)的一些小功能,至少要讓客戶用起來舒服,客戶可是上帝!!
另外多說一下,存到數(shù)據(jù)庫時(shí),一定要一一對(duì)應(yīng),類型格式也不能錯(cuò),不然就是存不進(jìn)去,讓我白白浪費(fèi)了一天時(shí)間才找到問題。感謝大家的閱讀!
最后附上全部的代碼:
import?os
import?numpy?as?np
import?pandas?as?pd
from?pathlib2?import?Path
import?pymysql
from?sqlalchemy?import?create_engine
from?sqlalchemy.types?import?DATE,INT,VARCHAR
DATA_TYPE?=?{'序號(hào)':INT,'條碼':VARCHAR(255),'出貨日期':DATE,'產(chǎn)品名稱':VARCHAR(255),?'出貨地點(diǎn)':VARCHAR(255),?'物料編碼':VARCHAR(255),?'軟件版本':VARCHAR(255),?'硬件版本':VARCHAR(255),?'備注':VARCHAR(255)}
pymysql.install_as_MySQLdb()
#讀取配置文件
def?get_sql_info():
????sql_dict?=?{}
????with?open('mysql_info.txt','r')as?f:
????????f_r_l?=?f.readlines()
????????for?f_r?in?f_r_l:
????????????sql_dict[f_r.split(':')[0].strip()]?=?f_r.split(':')[1].strip()
????return?sql_dict
sql_info?=?get_sql_info()
DB_STRING?=?f"mysql+mysqldb://{sql_info['USER']}:{sql_info['PASSWORD']}@{sql_info['HOST']}/{sql_info['db_name']}?charset=utf8"
engine?=?create_engine(DB_STRING)
def?clean_txt(path):
????with?open(path,?'w',?encoding='utf-8')?as?f:
????????f.truncate()
#讀取已經(jīng)完成的sheet
def?read_txt(path):
????if?not?os.path.exists(path):
????????clean_txt(path)
????????return
?????with?open(path,'r',encoding='utf-8')as?f:
????????sheetnames?=?f.readlines()
????return?[i.strip()?for?i?in?sheetnames]
def?write_txt(path,s):
????with?open(path,'a',encoding='utf-8')as?f:
????????f.write(s+'\n')
#得到目錄里面所有的excel文件和csv文件
def?get_path():
????while?True:
????????path?=?input("請(qǐng)輸入需要查找的目錄:")
????????print(path)
????????if?Path(path).exists():
????????????break
????????else:
????????????print('您輸入的目錄不存在,請(qǐng)檢查!!!!')
????print('正在查找中。。。。')
????return?Path(path).rglob('**/*.xls*'),?Path(path).rglob('**/*.csv')
#獲取物料編碼和物料描述
def?get_wlbm_wlms(s_list):
????wlbm?=?s_list[0].split(':')[-1].strip()
????wlms?=?s_list[1]?if?'物料描述'?not?in?s_list[1]?else?s_list[1].replace('(物料描述)','')
????return?wlbm,wlms
#數(shù)據(jù)清洗和排列
def?wash_data(df_a,df_b):
????df_1?=?df_a.copy()
????df_2?=?df_b.copy()
????df_1.dropna(axis=1,?how='all',?inplace=True)
????list_s?=?df_1.loc[0].values
????wlbm,?wlms?=?get_wlbm_wlms(list_s)
????#?print(wlbm,wlms)
????if?not?df_2.empty:
????????df_2.columns?=?['序號(hào)',?'條碼',?'產(chǎn)品批次',?'軟件版本',?'硬件版本',?'訂單',?'出貨日期',?'出貨地點(diǎn)',?'備注']
????????#?刪除沒有用的列
????????df_2.dropna(axis=0,how='all',inplace=True)
????????df_2.drop(columns=['產(chǎn)品批次',?'訂單'],?inplace=True)
????????df_2?=?df_2.replace('/',np.NaN)
????????df_2['物料編碼']?=?wlbm
????????df_2['產(chǎn)品名稱']?=?wlms
????????df?=?df_2[['序號(hào)',?'條碼',?'出貨日期',?'產(chǎn)品名稱',?'出貨地點(diǎn)',?'物料編碼',?'軟件版本',?'硬件版本',?'備注']]
????else:
????????data?=?[[np.NaN,?np.NaN,?np.NaN,?wlms,?np.NaN,?wlbm,?np.NaN,?np.NaN,?np.NaN]]
????????df?=?pd.DataFrame(data,columns=['序號(hào)',?'條碼',?'出貨日期',?'產(chǎn)品名稱',?'出貨地點(diǎn)',?'物料編碼',?'軟件版本',?'硬件版本',?'備注'])
????return?df
def?get_sheet_data(sheet_name,df):
????????try:
????????????df_1?=?df[sheet_name].loc[0:0,:]
????????????df_2?=?df[sheet_name].iloc[2:,:-1]
????????????df_e?=?wash_data(df_1,df_2)
????????????#?print(df_e)
????????????df_e.to_sql(sql_info['TABLE_NAME'],?chunksize=10000,con=engine,?if_exists='append',?index=False,dtype=DATA_TYPE)
????????except?Exception?as?e:
????????????print(e)
def?readAllFiles():
????excel_file_list,csv_file_list?=?get_path()
????print('查找完成,數(shù)據(jù)整理中.....')
????excel_names?=?read_txt(path_excel)
????i?=?0
????for?file_e?in?excel_file_list:
????????if?file_e?in?excel_names:
????????????continue
????????try:
????????????df?=?pd.read_excel(file_e,?sheet_name=None)
????????????#?print(sheets)
????????????sheetnames?=?read_txt(path_sheet)
????????????j?=?1
????????????for?sheet_name?in?df.keys():
????????????????if?sheet_name?in?sheetnames:
????????????????????continue
????????????????get_sheet_data(sheet_name,df)
????????????????write_txt(path_sheet,sheet_name)
????????????????print(f'當(dāng)前完成度{j}/{len(df.keys())}....')
????????????????j?+=?1
????????????write_txt(path_excel,str(file_e))
????????????clean_txt(path_sheet)
????????????i?+=?1
????????????print(f'已完成{i}個(gè)文件。。。。')
????????except?Exception?as?e:
????????????print(e)
????for?file_c?in?csv_file_list:
????????try:
????????????df_c?=?pd.read_csv(file_c,encoding='gbk')
????????????df_1?=?df_c.loc[0:0,?:]
????????????df_2?=?df_c.iloc[2:,?:-1]
????????????df_c?=?wash_data(df_1,?df_2)
????????????df_c.to_sql(sql_info['TABLE_NAME'],?chunksize=10000,?con=engine,?if_exists='append',?index=False,dtype=DATA_TYPE)
????????????write_txt(path_excel,?str(file_c))
????????????i?+=?1
????????????print(f'已完成{i}個(gè)文件。。。。')
????????except?Exception?as?e:
????????????print(e)
if?__name__?==?"__main__":
????path_excel?=?'excel_log.txt'
????path_sheet?=?'sheetlog.txt'
????while?True:
????????readAllFiles()
????????print('該目錄已完成!')
????????clean_txt(path_excel)
????????input('繼續(xù)就回車,不需要請(qǐng)直接關(guān)閉掉!')
螞蟻老師的全棧套餐,在抖音掃碼購買;有答疑服務(wù)、副業(yè)介紹等福利
