
提升分類模型acc(二):圖像分類技巧實(shí)戰(zhàn)
【GiantPandaCV導(dǎo)語(yǔ)】
本篇文章是本系列的第二篇文章,主要是介紹張航的Bag of Tricks for Image Classification 中的一些方法以及自己實(shí)際使用的一些trick。
論文鏈接:https://arxiv.org/abs/1812.01187
R50-vd代碼: https://github.com/FlyEgle/ResNet50vd-pytorch
知乎專欄: https://zhuanlan.zhihu.com/p/409920002
1一、前言
如何提升業(yè)務(wù)分類模型的性能,一直是個(gè)難題,畢竟沒(méi)有99.999%的性能都會(huì)帶來(lái)一定程度的風(fēng)險(xiǎn),所以很多時(shí)候只能通過(guò)控制閾值來(lái)調(diào)整準(zhǔn)召以達(dá)到想要的效果。本系列主要探究哪些模型trick和數(shù)據(jù)的方法可以大幅度讓你的分類性能更上一層樓,不過(guò)要注意一點(diǎn)的是,tirck不一定是適用于不同的數(shù)據(jù)場(chǎng)景的,但是數(shù)據(jù)處理方法是普適的。
ps: 文章比較長(zhǎng),不喜歡長(zhǎng)文可以直接跳到結(jié)尾看結(jié)論。
簡(jiǎn)單的回顧一下第一篇文章的結(jié)論: 使用大的batchsize訓(xùn)練會(huì)略微降低acc,可以使用LARS進(jìn)行一定程度的提升,但是需要進(jìn)行適當(dāng)?shù)奈⒄{(diào),對(duì)于業(yè)務(wù)來(lái)說(shuō),使用1k的batchsize比較合適。
2二、實(shí)驗(yàn)配置
模型: ResNet50, CMT-tiny 數(shù)據(jù): ImageNet1k & 業(yè)務(wù)數(shù)據(jù) 環(huán)境: 8xV100
ps: 簡(jiǎn)單的說(shuō)明一下,由于部分實(shí)驗(yàn)是從實(shí)際的業(yè)務(wù)數(shù)據(jù)得到的結(jié)論,所以可能并不是完全適用于別的數(shù)據(jù)集,domain不同對(duì)應(yīng)的方法也不盡相同。
本文只是建議和參考,不能盲目的跟從。imagenet數(shù)據(jù)集的場(chǎng)景大部分是每個(gè)圖片里面都會(huì)包含一個(gè)物體,也就是有主體存在的,筆者這邊的業(yè)務(wù)數(shù)據(jù)的場(chǎng)景很多是理解性的,更加抽象,也更難。
3三、Bag of Tricks
數(shù)據(jù)增強(qiáng)
樸素?cái)?shù)據(jù)增強(qiáng)
通用且常用的數(shù)據(jù)增強(qiáng)有random flip, colorjitter, random crop,基本上可以適用于任意的數(shù)據(jù)集,colorjitter注意一點(diǎn)是一般不給hue賦值。
RandAug
AutoAug系列之RandAug,相比autoaug的是和否的搜索策略,randaug通過(guò)概率的方法來(lái)進(jìn)行搜索,對(duì)于大數(shù)據(jù)集的增益更強(qiáng),遷移能力更好。實(shí)際使用的時(shí)候,直接用搜索好的imagnet的策略即可。
mixup & cutmix
mixup和cutmix均在imagenet上有著不錯(cuò)的提升,實(shí)際使用發(fā)現(xiàn),cutmix相比mixup的通用性更強(qiáng),業(yè)務(wù)數(shù)據(jù)上mixup幾乎沒(méi)有任何的提升,cutmix會(huì)提高一點(diǎn)點(diǎn)。不過(guò)兩者都會(huì)帶來(lái)訓(xùn)練時(shí)間的開(kāi)銷, 因?yàn)槎紩?huì)導(dǎo)致簡(jiǎn)單的樣本變難,需要更多的iter次數(shù)來(lái)update,除非0.1%的提升都很重要,不然個(gè)人覺(jué)得收益不高。在物體識(shí)別上,兩者可以一起使用。公式如下:
gaussianblur和gray這些方法,除非是數(shù)據(jù)集有這樣的數(shù)據(jù),不然實(shí)際意義不大,用不用都沒(méi)啥影響。
實(shí)驗(yàn)結(jié)論:
20% imagenet數(shù)據(jù)集 & CMT-tiny
| 模型 | 數(shù)據(jù)集 | 數(shù)據(jù)增強(qiáng) | 訓(xùn)練周期 | acc@top-1 |
|---|---|---|---|---|
| CMT-tiny | imagenet-train-20%-val-all | randomcrop, randomflip | 120 | 0.55076 |
| CMT-tiny | imagenet-train-20%-val-all | randomcrop, randomflip, colorjitter, randaug | 120 | 0.59714 |
| CMT-tiny | imagenet-train-20%-val-all | randomcrop, randomflip, colorjitter, mixup | 300 | 0.60532 |
| CMT-tiny | imagenet-train-20%-val-all | randomcrop, randomflip, colorjitter, cutmix | 300 | 0.61192 |
業(yè)務(wù)數(shù)據(jù)上(ResNet50) autoaug&randaug沒(méi)有任何的提升(主要問(wèn)題還是domain不同,搜出來(lái)的不適用),cutmix提升很小(適用于物體而不是理解)。
學(xué)習(xí)率衰減
warmup 深度學(xué)習(xí)更新權(quán)重的計(jì)算公式為,如果bs過(guò)大,lr保持不變,會(huì)導(dǎo)致Weights更新的次數(shù)相對(duì)變少,最終的精度不高。
要調(diào)整lr隨著bs線性增加而增加,但是lr變大,會(huì)導(dǎo)致W更新過(guò)快,最終都接近于0,出現(xiàn)nan。
所以需要warmup,在訓(xùn)練前幾個(gè)epoch,按很小的概率線性增長(zhǎng)為初始的LR后再進(jìn)行LRdecay。
LRdecay
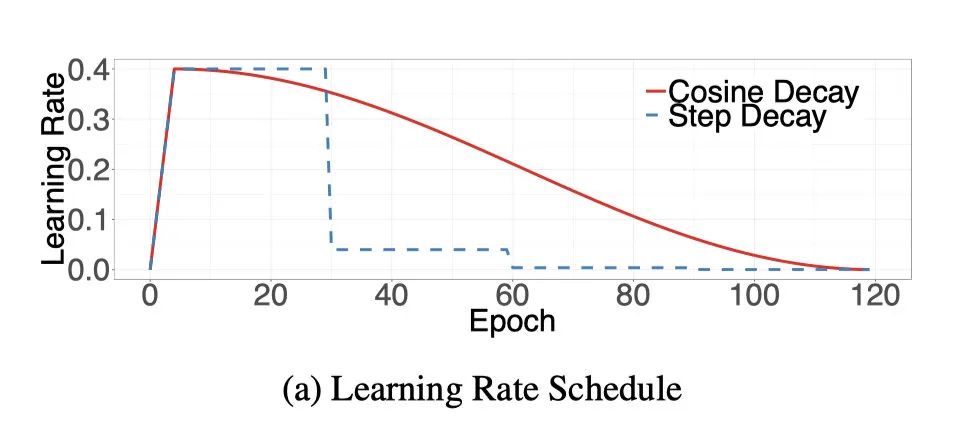
筆者常用的LR decay方法一般是Step Decay,按照epoch或者iter的范圍來(lái)進(jìn)行線性衰減,對(duì)于SGD等優(yōu)化器來(lái)說(shuō),效果穩(wěn)定,精度高。
進(jìn)一步提升精度,可以使用CosineDecay,但是需要更長(zhǎng)的訓(xùn)練周期。
CosineDecay公式如下:
如果不計(jì)較訓(xùn)練時(shí)間,可以使用更暴力的方法,余弦退火算法(Cosine Annealing Decay), 公式如下:
這里的表示的是重啟的序號(hào),表示學(xué)習(xí)率,表示當(dāng)前的epoch。
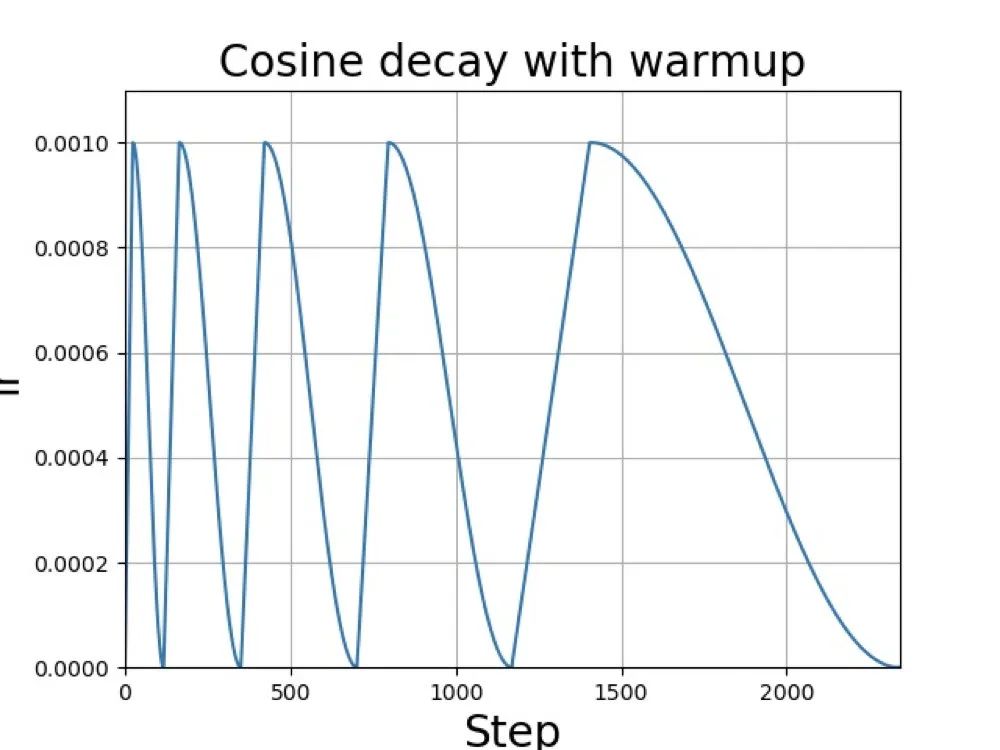
退火方法常用于圖像復(fù)原等用于L1損失的算法,有著不錯(cuò)的性能表現(xiàn)。
個(gè)人常用的方法就是cosinedecay,比較喜歡最后的acc曲線像一條"穿天猴", 不過(guò)要相對(duì)多訓(xùn)練幾k個(gè)iter,cosinedecay在最后的acc上升的比較快,前期的會(huì)比較緩慢。
跨卡同步bn&梯度累加
這兩個(gè)方法均是針對(duì)卡的顯存比較小,batchsize小(batchszie總數(shù)小于32)的情況。
SyncBN
雖然筆者在訓(xùn)練的時(shí)候采用的是ddp,實(shí)際上就是數(shù)據(jù)并行訓(xùn)練,每個(gè)卡的batchnorm只會(huì)更新自己的數(shù)據(jù),那么實(shí)際上得到的running_mean和running_std只是局部的而不是全局的。
如果bs比較大,那么可以認(rèn)為局部和全局的是同分布的,如果bs比較小,那么會(huì)存在偏差。
所以需要SyncBN同步一下mean和std以及后向的更新。
GradAccumulate
梯度累加和同步BN機(jī)制并不相同,也并不沖突,同步BN可以用于任意的bs情況,只是大的bs下沒(méi)必要用。
跨卡bn則是為了解決小bs的問(wèn)題所帶來(lái)的性能問(wèn)題,通過(guò)loss.backward的累加梯度來(lái)達(dá)到增大bs的效果,由于bn的存在只能近似不是完全等價(jià)。代碼如下:
for idx, (images, target) in enumerate(train_loader):
images = images.cuda()
target = target.cuda()
outputs = model(images)
losses = criterion(outputs, target)
loss = loss/accumulation_steps
loss.backward()
if((i+1)%accumulation_steps) == 0:
optimizer.step()
optimizer.zero_grad()
```backward```是bp以及保存梯度,```optimizer.step```是更新weights,由于accumulation_steps,所以需要增加訓(xùn)練的迭代次數(shù),也就是相應(yīng)的訓(xùn)練更多的epoch。
標(biāo)簽平滑
LabelSmooth目前應(yīng)該算是最通用的技術(shù)了
優(yōu)點(diǎn)如下:
可以緩解訓(xùn)練數(shù)據(jù)中錯(cuò)誤標(biāo)簽的影響; 防止模型過(guò)于自信,充當(dāng)正則,提升泛化性。
但是有個(gè)缺點(diǎn),使用LS后,輸出的概率值會(huì)偏小一些,這會(huì)使得如果需要考慮recall和precision,卡閾值需要更加精細(xì)。
代碼如下:
class LabelSmoothingCrossEntropy(nn.Module):
"""
NLL loss with label smoothing.
"""
def __init__(self, smoothing=0.1):
"""
Constructor for the LabelSmoothing module.
:param smoothing: label smoothing factor
"""
super(LabelSmoothingCrossEntropy, self).__init__()
assert smoothing < 1.0
self.smoothing = smoothing
self.confidence = 1. - smoothing
def forward(self, x, target):
logprobs = F.log_softmax(x, dim=-1)
nll_loss = -logprobs.gather(dim=-1, index=target.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = self.confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
4四、ResNet50-vd
ResNet50vd是由張航等人所提出的,相比于ResNet50,改進(jìn)點(diǎn)如下:
頭部的conv7x7改進(jìn)為3個(gè)conv3x3,直接使用7x7會(huì)損失比較多的信息,用多個(gè)3x3來(lái)緩解。 每個(gè)stage的downsample,由 (1x1 s2)->(3x3)->(1x1)修改為(1x1)->(3x3 s2)->(1x1), 同時(shí)修改shortcut從(1x1 s2)為avgpool(2) + (1x1)。1x1+s2會(huì)造成信息損失,所以用3x3和avgpool來(lái)緩解。
實(shí)驗(yàn)結(jié)論:
| 模型 | 數(shù)據(jù) | epoch | trick | acc@top-1 |
|---|---|---|---|---|
| R50-vd | imagenet1k | 300 | aug+mixup+cosine+ls | 78.25% |
上面的精度是筆者自己跑出來(lái)的比paper中的要低一些,不過(guò)paper里面用了蒸餾,相比于R50,提升了將近2個(gè)點(diǎn),推理速度和FLOPs幾乎沒(méi)有影響,所以直接用這個(gè)來(lái)替換R50了,個(gè)人感覺(jué)還算不錯(cuò),最近的業(yè)務(wù)模型都在用這個(gè)。
代碼和權(quán)重在git上,可以自行取用,ResNet50vd-pytorch。
5五、結(jié)論
LabelSmooth, CosineLR都可以用做是通用trick不依賴數(shù)據(jù)場(chǎng)景。 Mixup&cutmix,對(duì)數(shù)據(jù)場(chǎng)景有一定的依賴性,需要多次實(shí)驗(yàn)。 AutoAug,如果有能力去搜的話,就不用看筆者寫(xiě)的了,用就vans了。不具備搜的條件的話,如果domain和imagenet相差很多,那考慮用一下randaug,如果沒(méi)效果,autoaug這個(gè)系列可以放棄。 bs比較小的情況,可以試試Sycnbn和梯度累加,要適當(dāng)?shù)脑黾拥螖?shù)。
6六、結(jié)束語(yǔ)
本文是提升分類模型acc系列的第二篇,后續(xù)會(huì)講解一些通用的trick和數(shù)據(jù)處理的方法,敬請(qǐng)關(guān)注。

E N D
歡迎加入GiantPandaCV交流群