
可定制算法和環(huán)境,這個開源強化學習框架火了
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


提供 20 + 種強化學習算法和多種強化學習環(huán)境;
算法和環(huán)境可定制;
可以添加新的算法和環(huán)境;
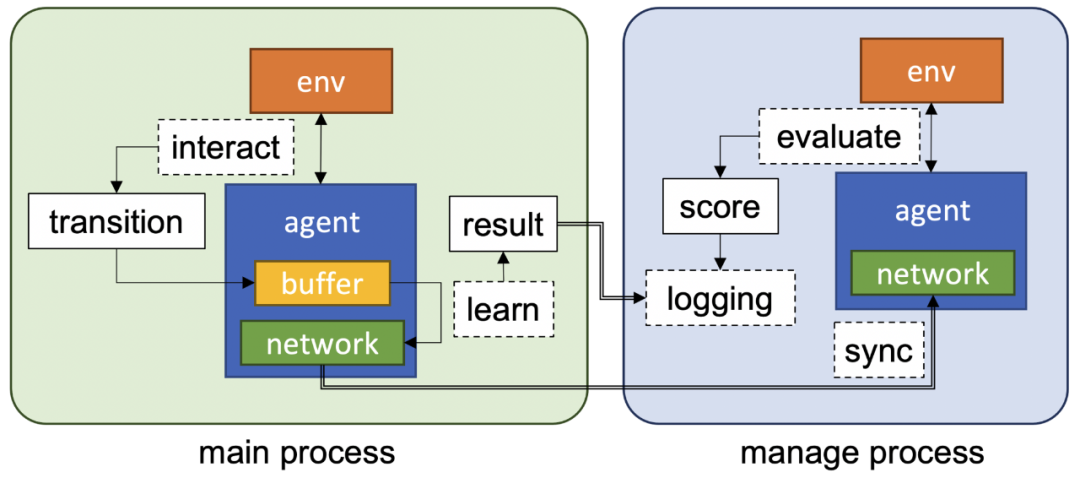
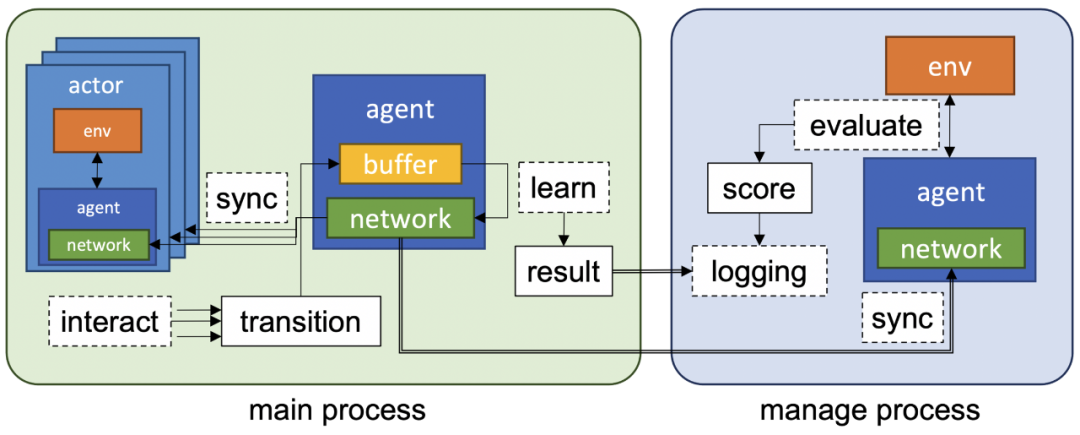
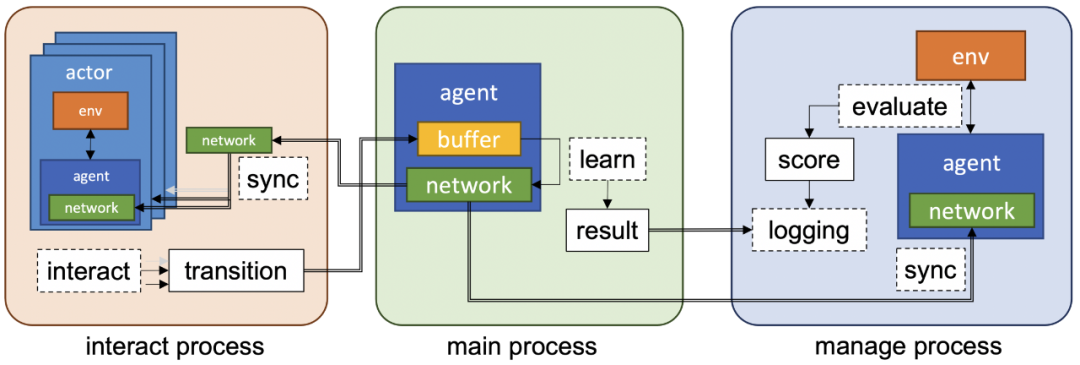
使用 ray 提供分布式 RL 算法;
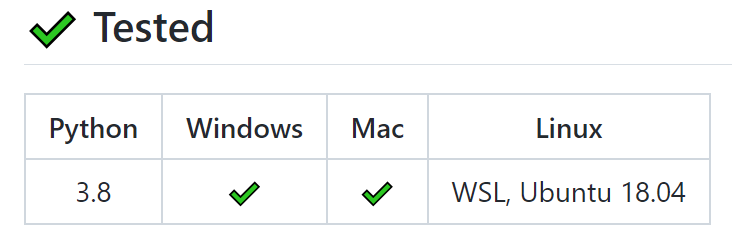
算法的基準測試是在許多 RL 環(huán)境中進行的。
git clone https://github.com/kakaoenterprise/JORLDY.gitcd JORLDYpip?install?-r?requirements.txt# linuxapt-get updateapt-get -y install libgl1-mesa-glx # for opencvapt-get -y install libglib2.0-0 # for opencvapt-get -y install gifsicle # for gif optimize
cd jorldy# Examples: python [script name] --config [config path]python single_train.py --config config.dqn.cartpolepython single_train.py --config config.rainbow.atari --env.name assault# Examples: python [script name] --config [config path] --[optional parameter key] [parameter value]python single_train.py --config config.dqn.cartpole --agent.batch_size 64python sync_distributed_train.py --config config.ppo.cartpole --train.num_workers 8
推薦閱讀
關(guān)于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質(zhì)量文章,喜歡總結(jié)知識,歡迎關(guān)注[程序員大白],大家一起學習進步!
評論
圖片
表情