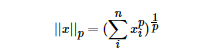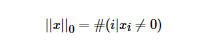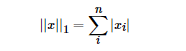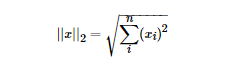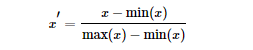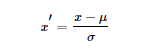點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
其實(shí)正則化的本質(zhì)很簡單,就是對(duì)某一問題加以先驗(yàn)的限制或約束以達(dá)到某種特定目的的一種手段或操作。在算法中使用正則化的目的是防止模型出現(xiàn)過擬合。一提到正則化,很多同學(xué)可能馬上會(huì)想到常用的L1范數(shù)和L2范數(shù),在匯總之前,我們先看下LP范數(shù)是什么。范數(shù)簡單可以理解為用來表征向量空間中的距離,而距離的定義很抽象,只要滿足非負(fù)、自反、三角不等式就可以稱之為距離。LP范數(shù)不是一個(gè)范數(shù),而是一組范數(shù),其定義如下:pp的范圍是[1,∞)[1,∞)。pp在(0,1)(0,1)范圍內(nèi)定義的并不是范數(shù),因?yàn)檫`反了三角不等式。根據(jù)pp的變化,范數(shù)也有著不同的變化,借用一個(gè)經(jīng)典的有關(guān)P范數(shù)的變化圖如下:?上圖表示了pp從0到正無窮變化時(shí),單位球(unit ball)的變化情況。在P范數(shù)下定義的單位球都是凸集,但是當(dāng)00<p<1時(shí),在該定義下的unit ball并不是凸集(這個(gè)我們之前提到,當(dāng)00<p<1時(shí)并不是范數(shù))。L0范數(shù)表示向量中非零元素的個(gè)數(shù),用公式表示如下:我們可以通過最小化L0范數(shù),來尋找最少最優(yōu)的稀疏特征項(xiàng)。但不幸的是,L0范數(shù)的最優(yōu)化問題是一個(gè)NP hard問題(L0范數(shù)同樣是非凸的)。因此,在實(shí)際應(yīng)用中我們經(jīng)常對(duì)L0進(jìn)行凸松弛,理論上有證明,L1范數(shù)是L0范數(shù)的最優(yōu)凸近似,因此通常使用L1范數(shù)來代替直接優(yōu)化L0范數(shù)。根據(jù)LP范數(shù)的定義我們可以很輕松的得到L1范數(shù)的數(shù)學(xué)形式:通過上式可以看到,L1范數(shù)就是向量各元素的絕對(duì)值之和,也被稱為是"稀疏規(guī)則算子"(Lasso regularization)。那么問題來了,為什么我們希望稀疏化?稀疏化有很多好處,最直接的兩個(gè):L2范數(shù)是最熟悉的,它就是歐幾里得距離,公式如下:L2范數(shù)有很多名稱,有人把它的回歸叫“嶺回歸”(Ridge Regression),也有人叫它“權(quán)值衰減”(Weight Decay)。以L2范數(shù)作為正則項(xiàng)可以得到稠密解,即每個(gè)特征對(duì)應(yīng)的參數(shù)ww都很小,接近于0但是不為0;此外,L2范數(shù)作為正則化項(xiàng),可以防止模型為了迎合訓(xùn)練集而過于復(fù)雜造成過擬合的情況,從而提高模型的泛化能力。???L1范數(shù)和L2范數(shù)的區(qū)別
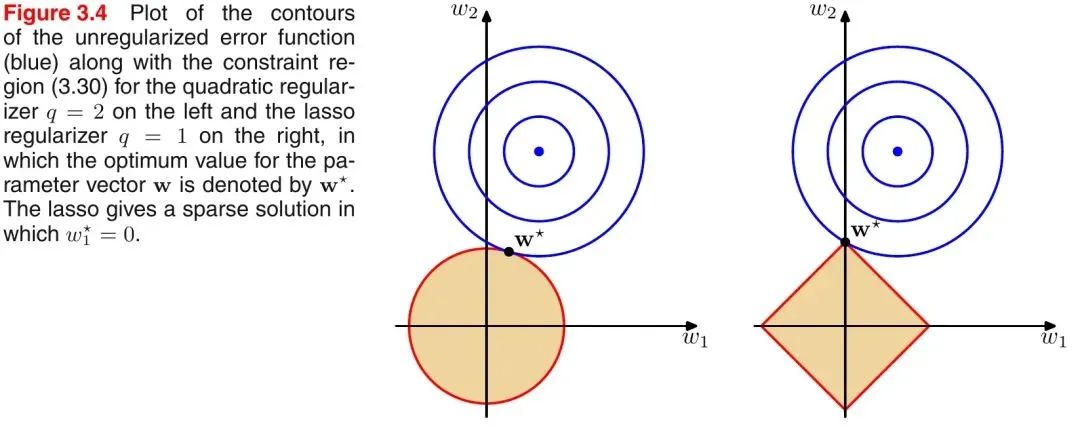
引入PRML一個(gè)經(jīng)典的圖來說明下L1和L2范數(shù)的區(qū)別,如下圖所示:如上圖所示,藍(lán)色的圓圈表示問題可能的解范圍,橘色的表示正則項(xiàng)可能的解范圍。而整個(gè)目標(biāo)函數(shù)(原問題+正則項(xiàng))有解當(dāng)且僅當(dāng)兩個(gè)解范圍相切。從上圖可以很容易地看出,由于L2范數(shù)解范圍是圓,所以相切的點(diǎn)有很大可能不在坐標(biāo)軸上,而由于L1范數(shù)是菱形(頂點(diǎn)是凸出來的),其相切的點(diǎn)更可能在坐標(biāo)軸上,而坐標(biāo)軸上的點(diǎn)有一個(gè)特點(diǎn),其只有一個(gè)坐標(biāo)分量不為零,其他坐標(biāo)分量為零,即是稀疏的。所以有如下結(jié)論,L1范數(shù)可以導(dǎo)致稀疏解,L2范數(shù)導(dǎo)致稠密解。從貝葉斯先驗(yàn)的角度看,當(dāng)訓(xùn)練一個(gè)模型時(shí),僅依靠當(dāng)前的訓(xùn)練數(shù)據(jù)集是不夠的,為了實(shí)現(xiàn)更好的泛化能力,往往需要加入先驗(yàn)項(xiàng),而加入正則項(xiàng)相當(dāng)于加入了一種先驗(yàn)。
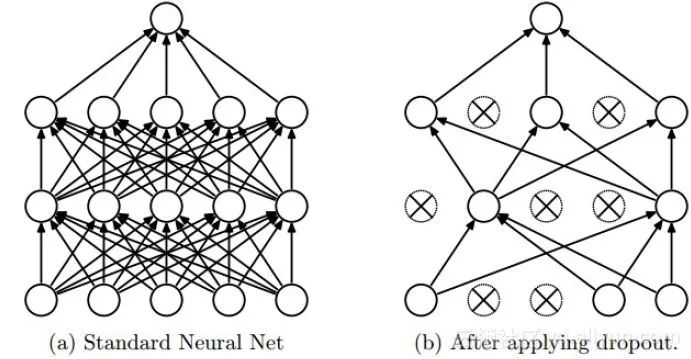
Dropout是深度學(xué)習(xí)中經(jīng)常采用的一種正則化方法。它的做法可以簡單的理解為在DNNs訓(xùn)練的過程中以概率pp丟棄部分神經(jīng)元,即使得被丟棄的神經(jīng)元輸出為0。Dropout可以實(shí)例化的表示為下圖:我們可以從兩個(gè)方面去直觀地理解Dropout的正則化效果:在Dropout每一輪訓(xùn)練過程中隨機(jī)丟失神經(jīng)元的操作相當(dāng)于多個(gè)DNNs進(jìn)行取平均,因此用于預(yù)測(cè)時(shí)具有vote的效果。
減少神經(jīng)元之間復(fù)雜的共適應(yīng)性。當(dāng)隱藏層神經(jīng)元被隨機(jī)刪除之后,使得全連接網(wǎng)絡(luò)具有了一定的稀疏化,從而有效地減輕了不同特征的協(xié)同效應(yīng)。也就是說,有些特征可能會(huì)依賴于固定關(guān)系的隱含節(jié)點(diǎn)的共同作用,而通過Dropout的話,就有效地組織了某些特征在其他特征存在下才有效果的情況,增加了神經(jīng)網(wǎng)絡(luò)的魯棒性。
批規(guī)范化(Batch Normalization)嚴(yán)格意義上講屬于歸一化手段,主要用于加速網(wǎng)絡(luò)的收斂,但也具有一定程度的正則化效果。
這里借鑒下魏秀參博士的知乎回答中對(duì)covariate shift的解釋(https://www.zhihu.com/question/38102762)。注:以下內(nèi)容引自魏秀參博士的知乎回答
大家都知道在統(tǒng)計(jì)機(jī)器學(xué)習(xí)中的一個(gè)經(jīng)典假設(shè)是“源空間(source domain)和目標(biāo)空間(target domain)的數(shù)據(jù)分布(distribution)是一致的”。如果不一致,那么就出現(xiàn)了新的機(jī)器學(xué)習(xí)問題,如transfer learning/domain adaptation等。而covariate shift就是分布不一致假設(shè)之下的一個(gè)分支問題,它是指源空間和目標(biāo)空間的條件概率是一致的,但是其邊緣概率不同。大家細(xì)想便會(huì)發(fā)現(xiàn),的確,對(duì)于神經(jīng)網(wǎng)絡(luò)的各層輸出,由于它們經(jīng)過了層內(nèi)操作作用,其分布顯然與各層對(duì)應(yīng)的輸入信號(hào)分布不同,而且差異會(huì)隨著網(wǎng)絡(luò)深度增大而增大,可是它們所能“指示”的樣本標(biāo)記(label)仍然是不變的,這便符合了covariate shift的定義。
BN的基本思想其實(shí)相當(dāng)直觀,因?yàn)樯窠?jīng)網(wǎng)絡(luò)在做非線性變換前的激活輸入值(X=WU+BX=WU+B,UU是輸入)隨著網(wǎng)絡(luò)深度加深,其分布逐漸發(fā)生偏移或者變動(dòng)(即上述的covariate shift)。之所以訓(xùn)練收斂慢,一般是整體分布逐漸往非線性函數(shù)的取值區(qū)間的上下限兩端靠近(對(duì)于Sigmoid函數(shù)來說,意味著激活輸入值X=WU+BX=WU+B是大的負(fù)值或正值),所以這導(dǎo)致后向傳播時(shí)低層神經(jīng)網(wǎng)絡(luò)的梯度消失,這是訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)收斂越來越慢的本質(zhì)原因。而BN就是通過一定的規(guī)范化手段,把每層神經(jīng)網(wǎng)絡(luò)任意神經(jīng)元這個(gè)輸入值的分布強(qiáng)行拉回到均值為0方差為1的標(biāo)準(zhǔn)正態(tài)分布,避免因?yàn)榧せ詈瘮?shù)導(dǎo)致的梯度彌散問題。所以與其說BN的作用是緩解covariate shift,倒不如說BN可緩解梯度彌散問題。???歸一化、標(biāo)準(zhǔn)化 & 正則化
正則化我們以及提到過了,這里簡單提一下歸一化和標(biāo)準(zhǔn)化。
歸一化(Normalization):歸一化的目標(biāo)是找到某種映射關(guān)系,將原數(shù)據(jù)映射到[a,b]區(qū)間上。一般a,b會(huì)取[?1,1],[0,1]這些組合。
標(biāo)準(zhǔn)化(Standardization):用大數(shù)定理將數(shù)據(jù)轉(zhuǎn)化為一個(gè)標(biāo)準(zhǔn)正態(tài)分布,標(biāo)準(zhǔn)化公式為:歸一化和標(biāo)準(zhǔn)化的區(qū)別:歸一化的縮放是“拍扁”統(tǒng)一到區(qū)間(僅由極值決定),而標(biāo)準(zhǔn)化的縮放是更加“彈性”和“動(dòng)態(tài)”的,和整體樣本的分布有很大的關(guān)系。歸一化:縮放僅僅跟最大、最小值的差別有關(guān)。標(biāo)準(zhǔn)化:縮放和每個(gè)點(diǎn)都有關(guān)系,通過方差(variance)體現(xiàn)出來。與歸一化對(duì)比,標(biāo)準(zhǔn)化中所有數(shù)據(jù)點(diǎn)都有貢獻(xiàn)(通過均值和標(biāo)準(zhǔn)差造成影響)。下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程
在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺。下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講在「小白學(xué)視覺」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~