
機(jī)器學(xué)習(xí)必備:如何防止過(guò)擬合?
↓推薦關(guān)注↓
導(dǎo)讀
本文對(duì)幾種常用的防止模型過(guò)擬合的方法進(jìn)行了詳細(xì)的匯總和講解。
LP范數(shù)



L1范數(shù)

特征選擇
可解釋性
L2范數(shù)
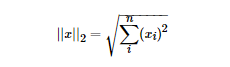
L1范數(shù)和L2范數(shù)的區(qū)別
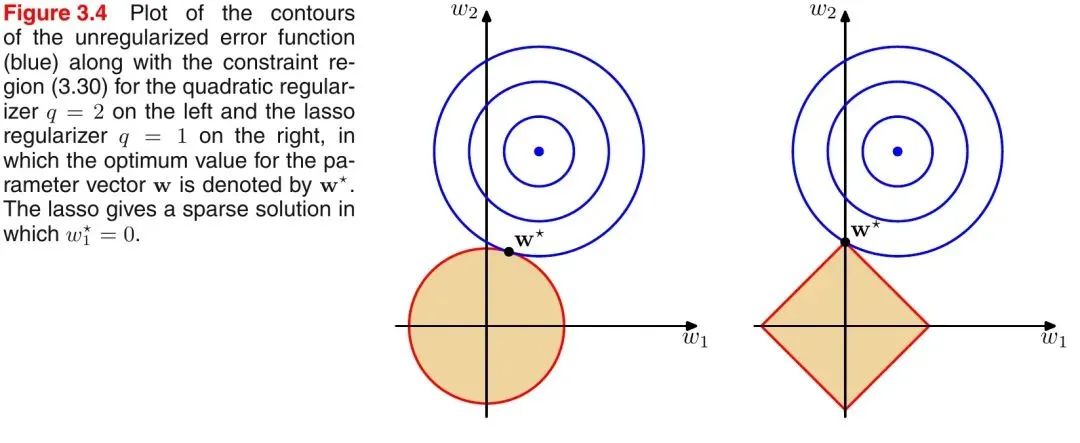
L1范數(shù)相當(dāng)于加入了一個(gè)Laplacean先驗(yàn);
L2范數(shù)相當(dāng)于加入了一個(gè)Gaussian先驗(yàn)。

Dropout

在Dropout每一輪訓(xùn)練過(guò)程中隨機(jī)丟失神經(jīng)元的操作相當(dāng)于多個(gè)DNNs進(jìn)行取平均,因此用于預(yù)測(cè)時(shí)具有vote的效果。
減少神經(jīng)元之間復(fù)雜的共適應(yīng)性。當(dāng)隱藏層神經(jīng)元被隨機(jī)刪除之后,使得全連接網(wǎng)絡(luò)具有了一定的稀疏化,從而有效地減輕了不同特征的協(xié)同效應(yīng)。也就是說(shuō),有些特征可能會(huì)依賴(lài)于固定關(guān)系的隱含節(jié)點(diǎn)的共同作用,而通過(guò)Dropout的話(huà),就有效地組織了某些特征在其他特征存在下才有效果的情況,增加了神經(jīng)網(wǎng)絡(luò)的魯棒性。
Batch Normalization
歸一化、標(biāo)準(zhǔn)化 & 正則化
把數(shù)變?yōu)?0, 1)之間的小數(shù)
把有量綱的數(shù)轉(zhuǎn)化為無(wú)量綱的數(shù)
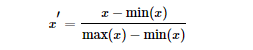
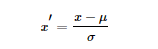
歸一化和標(biāo)準(zhǔn)化的區(qū)別:
歸一化:縮放僅僅跟最大、最小值的差別有關(guān)。
標(biāo)準(zhǔn)化:縮放和每個(gè)點(diǎn)都有關(guān)系,通過(guò)方差(variance)體現(xiàn)出來(lái)。與歸一化對(duì)比,標(biāo)準(zhǔn)化中所有數(shù)據(jù)點(diǎn)都有貢獻(xiàn)(通過(guò)均值和標(biāo)準(zhǔn)差造成影響)。
為什么要標(biāo)準(zhǔn)化和歸一化?
提升模型精度:歸一化后,不同維度之間的特征在數(shù)值上有一定比較性,可以大大提高分類(lèi)器的準(zhǔn)確性。
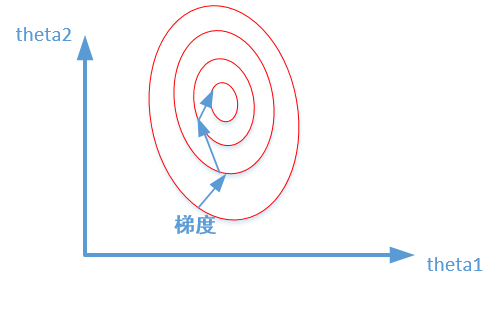
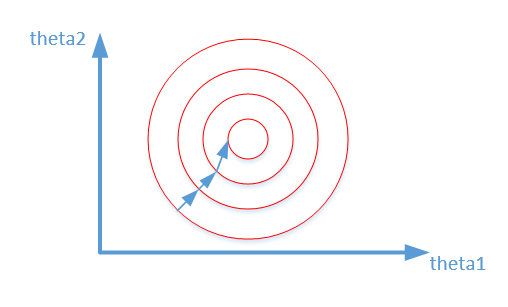
加速模型收斂:標(biāo)準(zhǔn)化后,最優(yōu)解的尋優(yōu)過(guò)程明顯會(huì)變得平緩,更容易正確的收斂到最優(yōu)解。如下圖所示:
長(zhǎng)按或掃描下方二維碼,后臺(tái)回復(fù):加群,即可申請(qǐng)入群。一定要備注:來(lái)源+研究方向+學(xué)校/公司,否則不拉入群中,見(jiàn)諒!
(長(zhǎng)按三秒,進(jìn)入后臺(tái))
推薦閱讀
