
基于 Flink 構(gòu)建萬(wàn)億數(shù)據(jù)量下的實(shí)時(shí)數(shù)倉(cāng)及實(shí)時(shí)查詢(xún)系統(tǒng)
一、背景介紹
推薦系統(tǒng)
對(duì)于推薦同學(xué)來(lái)說(shuō),想知道一個(gè)推薦策略在不同人群中的推薦效果是怎么樣的。
運(yùn)營(yíng)
對(duì)于運(yùn)營(yíng)的同學(xué)來(lái)說(shuō),想知道在廣東省的用戶(hù)中,最火的廣東地域內(nèi)容是哪些?方便做地域 push。
審核
對(duì)于審核的同學(xué),想知道過(guò)去 5 分鐘游戲類(lèi)被舉報(bào)最多的內(nèi)容和賬號(hào)是哪些,方便能夠及時(shí)處理。
內(nèi)容創(chuàng)作
對(duì)于內(nèi)容的作者,想知道今天到目前為止,內(nèi)容被多少個(gè)用戶(hù)觀看,收到了多少個(gè)點(diǎn)贊和轉(zhuǎn)發(fā),方便能夠及時(shí)調(diào)整他的策略。
老板決策
對(duì)于老板來(lái)說(shuō),想知道過(guò)去 10 分鐘有多少用戶(hù)消費(fèi)了內(nèi)容,對(duì)消費(fèi)人群有一個(gè)宏觀的了解。

2. 開(kāi)發(fā)前調(diào)研

■?2.1 離線數(shù)據(jù)分析平臺(tái)能否滿足這些需求
調(diào)研的結(jié)論是不能滿足離線數(shù)據(jù)分析平臺(tái),不行的原因如下:
首先用戶(hù)的消費(fèi)行為數(shù)據(jù)上報(bào)需要經(jīng)過(guò) Spark 的多層離線計(jì)算,最終結(jié)果出庫(kù)到 MySQL 或者 ES 提供給離線分析平臺(tái)查詢(xún)。這個(gè)過(guò)程的延時(shí)至少是 3-6 個(gè)小時(shí),目前比較常見(jiàn)的都是提供隔天的查詢(xún),所以很多實(shí)時(shí)性要求高的業(yè)務(wù)場(chǎng)景都不能滿足。
另一個(gè)問(wèn)題是騰訊看點(diǎn)的數(shù)據(jù)量太大,帶來(lái)的不穩(wěn)定性也比較大,經(jīng)常會(huì)有預(yù)料不到的延遲,所以離線分析平臺(tái)是無(wú)法滿足這些需求的。
■?2.2 準(zhǔn)實(shí)時(shí)數(shù)據(jù)分析平臺(tái)
3. 騰訊看點(diǎn)信息流的業(yè)務(wù)流程
第 1 步,內(nèi)容創(chuàng)作者發(fā)布內(nèi)容;
第 2 步,內(nèi)容會(huì)經(jīng)過(guò)內(nèi)容審核系統(tǒng)啟用或者下架;
第 3 步,啟用的內(nèi)容給到推薦系統(tǒng)和運(yùn)營(yíng)系統(tǒng),分發(fā)給 C 側(cè)用戶(hù);
第 4 步,內(nèi)容分發(fā)給 C 側(cè)用戶(hù)之后,用戶(hù)會(huì)產(chǎn)生各種行為,比如說(shuō)曝光、點(diǎn)擊舉報(bào)等,這些行為數(shù)據(jù)通過(guò)埋點(diǎn)上報(bào),實(shí)時(shí)接入到消息隊(duì)列中;
第 5 步,構(gòu)建實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù);
第 6 步,構(gòu)建實(shí)時(shí)數(shù)據(jù)查詢(xún)系統(tǒng)。
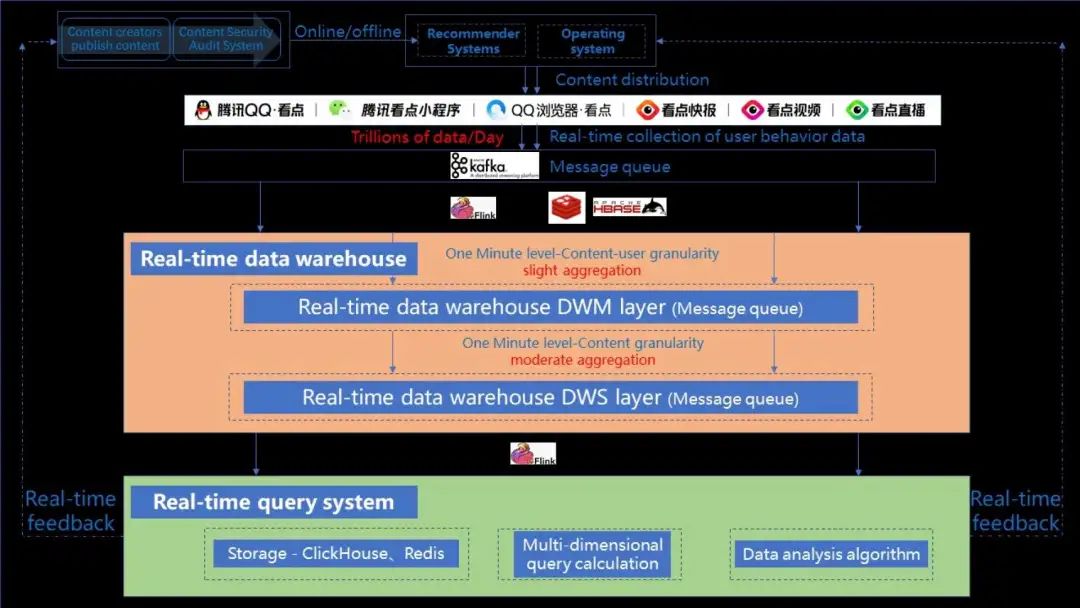
在業(yè)務(wù)流程圖中,我們主要做的兩部分工作,就是圖中有顏色的這兩部分:
橙色部分,我們構(gòu)建了一個(gè)騰訊看點(diǎn)的實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù);
綠色部分,我們基于了 OLAP 的存儲(chǔ)計(jì)算引擎,開(kāi)發(fā)了實(shí)時(shí)數(shù)據(jù)分析系統(tǒng)。
二、架構(gòu)設(shè)計(jì)
1. 設(shè)計(jì)的目標(biāo)與難點(diǎn)
首先來(lái)看一下數(shù)據(jù)分析系統(tǒng)的設(shè)計(jì)目標(biāo)與難點(diǎn)。我們的實(shí)時(shí)數(shù)據(jù)分析系統(tǒng)分為四大模塊:
實(shí)時(shí)計(jì)算引擎;
實(shí)時(shí)存儲(chǔ)引擎;
后臺(tái)服務(wù)層;
前端展示層。

難點(diǎn)主要在于前兩個(gè)模塊,實(shí)時(shí)計(jì)算引擎和實(shí)時(shí)存儲(chǔ)引擎。
千萬(wàn)級(jí)每秒的海量數(shù)據(jù)如何實(shí)時(shí)的接入,并且進(jìn)行極低延遲的維表關(guān)聯(lián)是有難度的;
實(shí)時(shí)存儲(chǔ)引擎如何支持高并發(fā)的寫(xiě)入。高可用分布式和高性能的索引查詢(xún)是比較難的,可以看一下我們的系統(tǒng)架構(gòu)設(shè)計(jì)來(lái)了解這幾個(gè)模塊的具體實(shí)現(xiàn)。
2. 系統(tǒng)架構(gòu)設(shè)計(jì)
■?2.1 實(shí)時(shí)計(jì)算
接入層主要是從千萬(wàn)級(jí)每秒的原始消息隊(duì)列中拆分出不同業(yè)務(wù)不同行為數(shù)據(jù)的微隊(duì)列。拿 QQ 看點(diǎn)的視頻內(nèi)容來(lái)說(shuō),拆分過(guò)后的數(shù)據(jù)就只有百萬(wàn)級(jí)每秒了。
實(shí)時(shí)計(jì)算層主要是負(fù)責(zé)多行行為流水?dāng)?shù)據(jù)進(jìn)行 "行轉(zhuǎn)列" 的操作,實(shí)時(shí)關(guān)聯(lián)用戶(hù)畫(huà)像數(shù)據(jù)和內(nèi)容維度數(shù)據(jù)。
實(shí)時(shí)數(shù)倉(cāng)存儲(chǔ)層主要就是設(shè)計(jì)出符合看點(diǎn)的業(yè)務(wù),下游好用的實(shí)時(shí)消息隊(duì)列。

我們暫時(shí)提供了兩個(gè)消息隊(duì)列,作為實(shí)時(shí)數(shù)倉(cāng)的兩層:
第一層是 DWM 層,它是內(nèi)容 ID 和用戶(hù) ID 粒度聚合的,就是說(shuō)一條數(shù)據(jù)包含了內(nèi)容 ID 和用戶(hù) ID,然后還有 B 側(cè)的內(nèi)容維度數(shù)據(jù),C 側(cè)的用戶(hù)行為數(shù)據(jù),還有用戶(hù)畫(huà)像數(shù)據(jù)。
第二層是 DWS 層,這一層是內(nèi)容 ID 粒度聚合的,就是一條數(shù)據(jù)包含了內(nèi)容 ID、B 側(cè)數(shù)據(jù)和 C 側(cè)數(shù)據(jù)。可以看到內(nèi)容 ID 和用戶(hù) ID 粒度的消息,隊(duì)列流量進(jìn)一步減小到了 10 萬(wàn)級(jí)每秒,內(nèi)容 ID 粒度更是減小到了萬(wàn)級(jí)每秒,并且格式更加清晰,維度信息更加豐富。

■?2.2 實(shí)時(shí)存儲(chǔ)
實(shí)時(shí)寫(xiě)入層主要是負(fù)責(zé) Hash 路由,將數(shù)據(jù)寫(xiě)入;
OLAP 存儲(chǔ)層是利用 MPP 的存儲(chǔ)引擎,設(shè)計(jì)出符合業(yè)務(wù)的索引和物化視圖,高效存儲(chǔ)海量數(shù)據(jù);
后臺(tái)接口層是提供了高效的多維實(shí)時(shí)查詢(xún)接口。

■?2.3 后臺(tái)服務(wù)
■?2.4 前端服務(wù)
3. 方案選型

■ 3.1 實(shí)時(shí)數(shù)倉(cāng)的選型
■?3.2 實(shí)時(shí)計(jì)算引擎的選型
■?3.3 實(shí)時(shí)存儲(chǔ)引擎
三、實(shí)時(shí)數(shù)倉(cāng)
實(shí)時(shí)數(shù)倉(cāng)也分為三塊來(lái)介紹:
第一是如何構(gòu)建實(shí)時(shí)數(shù)倉(cāng);
第二是實(shí)時(shí)數(shù)倉(cāng)的優(yōu)點(diǎn);
第三是基于實(shí)時(shí)數(shù)倉(cāng),利用 Flink 開(kāi)發(fā)實(shí)時(shí)應(yīng)用時(shí)候遇到的一些問(wèn)題。
1. 如何構(gòu)建實(shí)時(shí)數(shù)倉(cāng)

■?1.1數(shù)據(jù)清洗
■?1.2 高性能維表關(guān)聯(lián)
■?1.3 不同粒度聚合
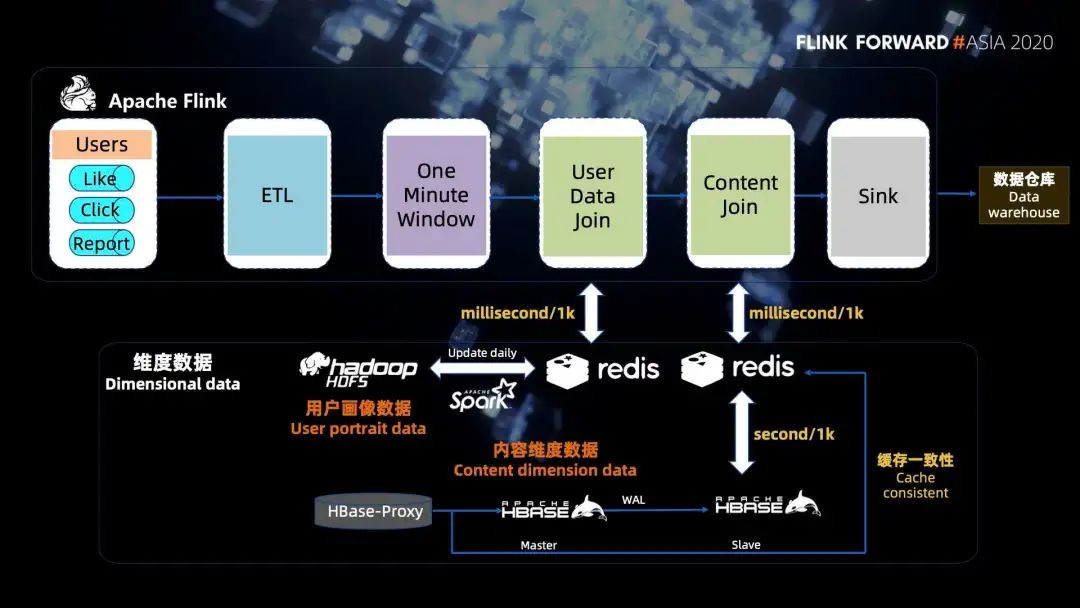
接下來(lái)詳細(xì)介紹一下第二步中高性能實(shí)時(shí)維表關(guān)聯(lián)是怎么處理的。
幾十億的用戶(hù)畫(huà)像數(shù)據(jù)存放在 HDFS 上,肯定是無(wú)法進(jìn)行高性能的維表關(guān)聯(lián)的,所以需要進(jìn)行緩存。由于數(shù)據(jù)量太大,本地緩存的代價(jià)不合理,我們采用的是 Redis 進(jìn)行緩存,具體實(shí)現(xiàn)是通過(guò) Spark 批量讀取 HDFS 上的畫(huà)像數(shù)據(jù),每天更新 Redis 緩存,內(nèi)容維度數(shù)據(jù)存放在 HBase 中。
為了不影響線上的業(yè)務(wù),我們?cè)L問(wèn)的是 HBase 的備庫(kù),而且由于內(nèi)容維度變化的頻率遠(yuǎn)高于用戶(hù)畫(huà)像,所以維度關(guān)聯(lián)的時(shí)候,我們需要盡量的關(guān)聯(lián)到實(shí)時(shí)的 HBase 數(shù)據(jù)。
一分鐘窗口的數(shù)據(jù),如果直接關(guān)聯(lián) HBase 的話,耗時(shí)是十幾分鐘,這樣會(huì)導(dǎo)致任務(wù)延遲。我們發(fā)現(xiàn) 1000 條數(shù)據(jù)訪問(wèn) HBase 是秒級(jí)的,而訪問(wèn) Redis 的話只是毫秒級(jí)的,訪問(wèn) Redis 的速度基本上是訪問(wèn) HBase 的 1000 倍,所以我們?cè)谠L問(wèn) HBase 的內(nèi)容之前設(shè)置了一層 Redis 緩存,然后通過(guò)了監(jiān)聽(tīng) HBase-proxy 寫(xiě)流水,通過(guò)這樣來(lái)保證緩存的一致性。
這樣一分鐘的窗口數(shù)據(jù),原本關(guān)聯(lián)內(nèi)容維度數(shù)據(jù)耗時(shí)需要十幾分鐘,現(xiàn)在就變成了秒級(jí)。我們?yōu)榱朔乐惯^(guò)期的數(shù)據(jù)浪費(fèi)緩存,緩存的過(guò)期時(shí)間我們?cè)O(shè)置成了 24 個(gè)小時(shí)。
最后還有一些小的優(yōu)化,比如說(shuō)內(nèi)容數(shù)據(jù)上報(bào)過(guò)程中會(huì)上報(bào)不少非常規(guī)的內(nèi)容 ID,這些內(nèi)容 ID 在 HBase 中是不存儲(chǔ)的,會(huì)造成緩存穿透的問(wèn)題。所以在實(shí)時(shí)計(jì)算的時(shí)候,我們直接過(guò)濾掉這些內(nèi)容 ID,防止緩存穿透,又減少了一些時(shí)間。另外,因?yàn)樵O(shè)置了定時(shí)緩存,會(huì)引入一個(gè)緩存雪崩的問(wèn)題,所以我們?cè)趯?shí)時(shí)計(jì)算的過(guò)程中進(jìn)行了削峰填谷的操作,錯(cuò)開(kāi)了設(shè)置緩存的時(shí)間,來(lái)緩解緩存雪崩的問(wèn)題。
2. 實(shí)時(shí)數(shù)倉(cāng)的優(yōu)點(diǎn)

我們可以看一下,在我們建設(shè)實(shí)時(shí)數(shù)倉(cāng)的前后,開(kāi)發(fā)一個(gè)實(shí)時(shí)應(yīng)用的區(qū)別。
沒(méi)有數(shù)倉(cāng)的時(shí)候,我們需要消費(fèi)千萬(wàn)級(jí)每秒的原始隊(duì)列,進(jìn)行復(fù)雜的數(shù)據(jù)清洗,然后再進(jìn)行用戶(hù)畫(huà)像關(guān)聯(lián)、內(nèi)容維度關(guān)聯(lián),才能夠拿到符合要求格式的實(shí)時(shí)數(shù)據(jù)。開(kāi)發(fā)和擴(kuò)展的成本都會(huì)比較高。如果想開(kāi)發(fā)一個(gè)新的應(yīng)用,又要走一遍流程。現(xiàn)在有了實(shí)時(shí)數(shù)倉(cāng)之后,如果再想開(kāi)發(fā)一個(gè)內(nèi)容 ID 粒度的實(shí)時(shí)應(yīng)用,就直接申請(qǐng) TPS 萬(wàn)級(jí)每秒的 DWS 層消息對(duì)列即可,開(kāi)發(fā)成本變低很多,資源消耗小了很多,可擴(kuò)展性也強(qiáng)了很多。
我們看一個(gè)實(shí)際的例子,開(kāi)發(fā)我們系統(tǒng)的實(shí)時(shí)數(shù)據(jù)大屏,原本需要進(jìn)行如上的所有操作才能夠拿到數(shù)據(jù),現(xiàn)在只需要消費(fèi) DWS 層消息隊(duì)列寫(xiě)一條 Flink SQL 即可,僅僅會(huì)消耗 2 個(gè) CPU 核心和 1GB 的內(nèi)存。以 50 個(gè)消費(fèi)者為例,建立實(shí)時(shí)數(shù)倉(cāng)的前后,下游開(kāi)發(fā)一個(gè)實(shí)時(shí)應(yīng)用,可以減少 98% 的資源消耗,包括了計(jì)算資源、存儲(chǔ)資源、人力成本和開(kāi)發(fā)人員的學(xué)習(xí)接入成本等等,并且隨著消費(fèi)者越多節(jié)省的就越多,就拿 Redis 存儲(chǔ)這一部分來(lái)說(shuō),一個(gè)月就能夠省下上百萬(wàn)的人民幣。
3. Flink 開(kāi)發(fā)過(guò)程中遇到的問(wèn)題總結(jié)
■?3.1 實(shí)時(shí)數(shù)據(jù)大屏

■?3.2 Flink state 的 TTL

■?3.3 使用 Flink valueState 和 mapState 經(jīng)驗(yàn)總結(jié)
雖然通過(guò) valueState 也可以存儲(chǔ) map 結(jié)構(gòu)的數(shù)據(jù),但是能夠使用 mapState 的地方盡量使用 mapState,最好不要通過(guò) valueState 來(lái)存儲(chǔ) map 結(jié)構(gòu)的數(shù)據(jù),因?yàn)?Flink 對(duì) mapState 是進(jìn)行了優(yōu)化的,效率會(huì)比 valuState 中存儲(chǔ) map 結(jié)構(gòu)的數(shù)據(jù)更加高效。
比如我們遇到過(guò)的一個(gè)問(wèn)題就是使用 valueState 存儲(chǔ)了 map 結(jié)構(gòu)的數(shù)據(jù),選擇的是 rocksDB backend。我們發(fā)現(xiàn)磁盤(pán)的 IO 變得越來(lái)越高,延遲也相應(yīng)的增加。后面發(fā)現(xiàn)是因?yàn)?valueState 中修改 map 中的任意一個(gè) key 都會(huì)把整個(gè) map 的數(shù)據(jù)給讀出來(lái),然后再寫(xiě)回去,這樣會(huì)導(dǎo)致 IO 過(guò)高。但是 mapState,它每一個(gè) key 在 rocksDB 中都是一條單獨(dú)的 key,磁盤(pán) IO 的代價(jià)就會(huì)小很多。

■?3.4 Checkpoint 超時(shí)問(wèn)題
我們還遇到過(guò)一些問(wèn)題,比如說(shuō) Checkpoint 超時(shí)了,當(dāng)時(shí)我們第一個(gè)想法就是計(jì)算資源不足,并行度不夠?qū)е碌某瑫r(shí),所以我們直接增加了計(jì)算資源,增大了并行度,但是超時(shí)的情況并沒(méi)有得到緩解。后面經(jīng)過(guò)研究才發(fā)現(xiàn)是數(shù)據(jù)傾斜,導(dǎo)致某個(gè)節(jié)點(diǎn)的 barrier 下發(fā)不及時(shí)導(dǎo)致的,通過(guò) rebalance 之后才能夠解決。
總的來(lái)說(shuō) Flink 功能還是很強(qiáng)的,它文檔比較完善,網(wǎng)上資料非常豐富,社區(qū)也很活躍,一般遇到問(wèn)題都能夠比較快的找到解決方案。
四、實(shí)時(shí)數(shù)據(jù)查詢(xún)系統(tǒng)
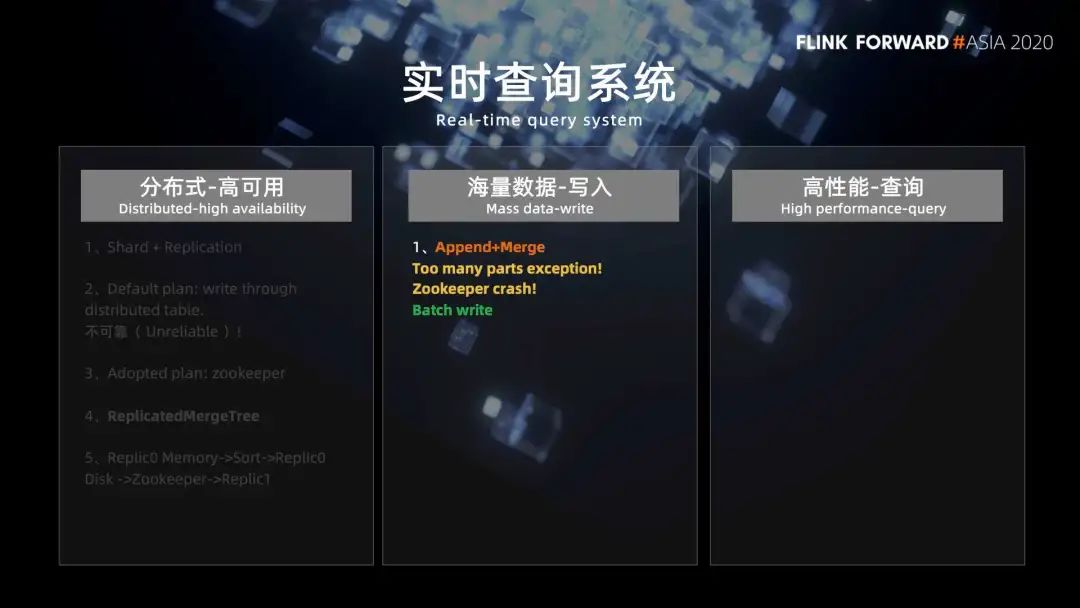
我們的實(shí)時(shí)查詢(xún)系統(tǒng),多維實(shí)時(shí)查詢(xún)系統(tǒng)用的是 Clickhouse 來(lái)實(shí)現(xiàn)的,這塊分為三個(gè)部分來(lái)介紹。第一是分布式高可用,第二是海量數(shù)據(jù)的寫(xiě)入,第三是高性能的查詢(xún)。
Click house 有很多表引擎,表引擎決定了數(shù)據(jù)以什么方式存儲(chǔ),以什么方式加載,以及數(shù)據(jù)表?yè)碛惺裁礃拥奶匦裕磕壳?Clickhouse 擁有 merge tree、replaceingMerge Tree、AggregatingMergeTree、外存、內(nèi)存、IO 等 20 多種表引擎,其中最體現(xiàn) Clickhouse 性能特點(diǎn)的是 merge tree 及其家族表引擎,并且當(dāng)前 Clickhouse 也只有 merge 及其家族表引擎支持了主鍵索引、數(shù)據(jù)分區(qū)、數(shù)據(jù)副本等優(yōu)秀的特性。我們當(dāng)前使用的也是 Clickhouse 的 merge tree 及其家族表引擎,接下來(lái)的介紹都是基于引擎展開(kāi)的。
1. 分布式高可用
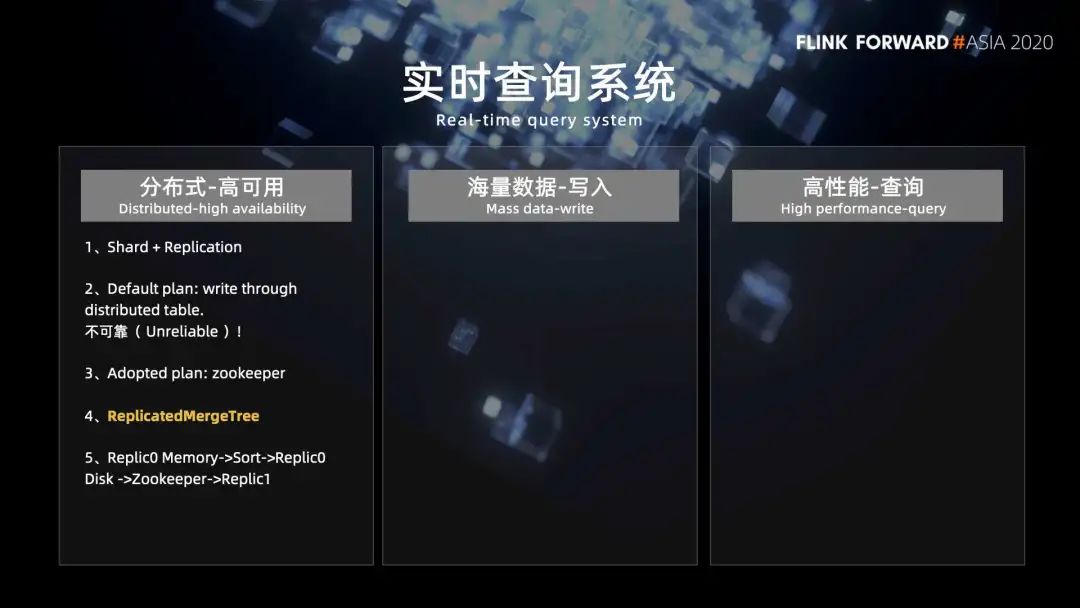
2. 海量數(shù)據(jù)的寫(xiě)入
■?2.1 Append + Merge
如果一次寫(xiě)入的數(shù)據(jù)太少,比如一條數(shù)據(jù)只寫(xiě)一次,就會(huì)產(chǎn)生大量的文件目錄。當(dāng)后臺(tái)合并線程來(lái)不及合并的時(shí)候,文件目錄的數(shù)量就會(huì)越來(lái)越多,這會(huì)導(dǎo)致 Clickhouse 拋出 too many parts 的異常,寫(xiě)入失敗。
另外,之前介紹的每一次寫(xiě)入除了數(shù)據(jù)本身,Clickhouse 還會(huì)需要跟 Zookeeper 進(jìn)行 10 來(lái)次的數(shù)據(jù)交互,而我們知道 Zookeeper 本身是不能夠承受很高的并發(fā)的,所以可以看到寫(xiě)入 Clickhouse QPS 過(guò)高,導(dǎo)致 zookeeper 的崩潰。
我們采用的解決方案是改用 batch 的方式寫(xiě)入,寫(xiě)入 zookeeper 一個(gè) batch 的數(shù)據(jù),產(chǎn)生一個(gè)數(shù)據(jù)目錄,然后再與 Zookeeper 進(jìn)行一次數(shù)據(jù)交互。那么 batch 設(shè)置多大?如果 batch 太小的話,就緩解不了 Zookeeper 的壓力;但是 batch 也不能設(shè)置的太大,要不然上游的內(nèi)存壓力以及數(shù)據(jù)的延遲都會(huì)比較大。所以通過(guò)實(shí)驗(yàn),最終我們選擇了大小幾十萬(wàn)的 batch,這樣可以避免了 QPS 太高帶來(lái)的問(wèn)題。
其實(shí)當(dāng)前的方案還是有優(yōu)化空間的,比如說(shuō) Zookeeper 無(wú)法線性擴(kuò)展,我有了解到業(yè)內(nèi)有些團(tuán)隊(duì)就把 Mark 和 date part 相關(guān)的信息不寫(xiě)入 Zookeeper。這樣能夠減少 Zookeeper 的壓力。不過(guò)這樣涉及到了對(duì)源代碼的修改,對(duì)于一般的業(yè)務(wù)團(tuán)隊(duì)來(lái)說(shuō),實(shí)現(xiàn)的成本就會(huì)比較高。
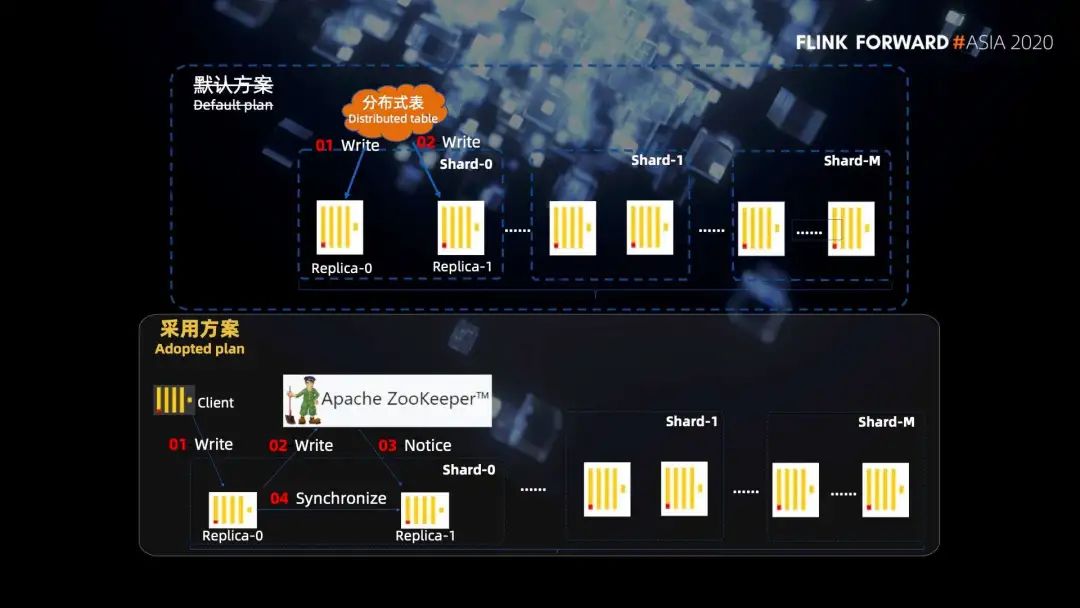
■?2.2 分布式表寫(xiě)入

這里有一個(gè)很容易誤解的地方,我們最開(kāi)始也是以為分布式表只是按照一定的規(guī)則做一個(gè)網(wǎng)絡(luò)的轉(zhuǎn)發(fā),以為萬(wàn)兆網(wǎng)卡的帶寬就足夠,不會(huì)出現(xiàn)單點(diǎn)的性能瓶頸。但是實(shí)際上 Clickhouse 是這樣做的,我們看一個(gè)例子,有三個(gè)分片 shard1,shard2 和 shard3,其中分布式表建立在 shard2 的節(jié)點(diǎn)上。
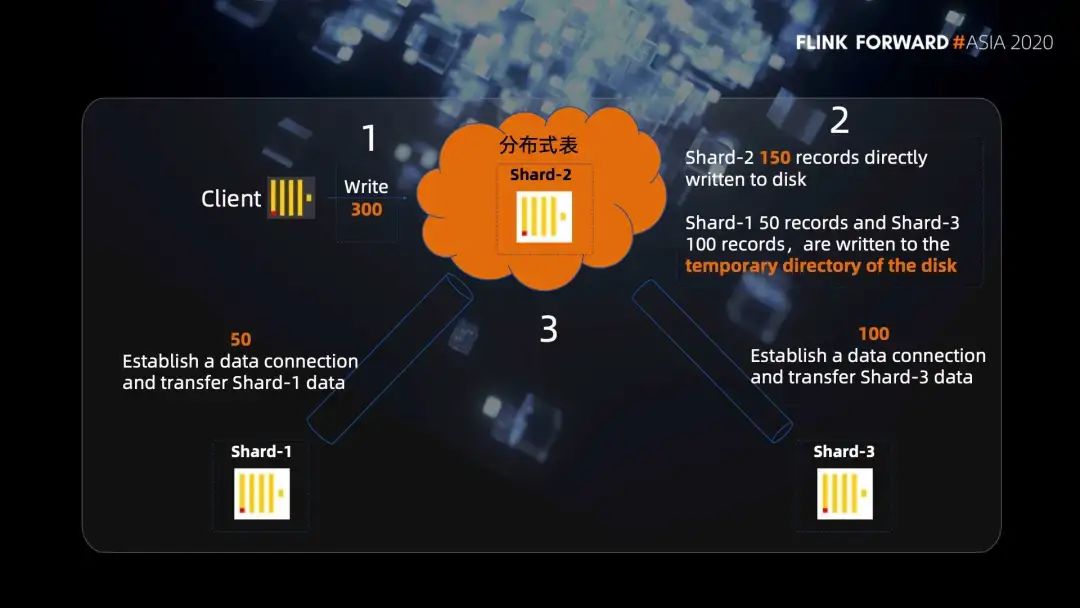
第一步,我們給分布式表寫(xiě)入 300 條數(shù)據(jù),分布式表會(huì)根據(jù)路由規(guī)則把數(shù)據(jù)進(jìn)行分組,假設(shè) shard1 分到 50 條,shard2 分到 150 條,shard3 分到 100 條。
第二步,因?yàn)榉植际奖砀?shard2 是在同一臺(tái)機(jī)器上,所以 shard2 的 150 條就直接寫(xiě)入磁盤(pán)了。然后 shard1 的 50 條和 shard3 的 100 條,并不是直接轉(zhuǎn)發(fā)給他們的,而是也會(huì)在分布式表的機(jī)器上先寫(xiě)入磁盤(pán)的臨時(shí)目錄。
第三步,分布式表節(jié)點(diǎn) shard2 會(huì)向 shard1 節(jié)點(diǎn)和 shard3 節(jié)點(diǎn)分別發(fā)起遠(yuǎn)程連接的請(qǐng)求,將對(duì)應(yīng)臨時(shí)目錄的數(shù)據(jù)發(fā)送給 shard1 和 shard3。
第一個(gè)就是對(duì)磁盤(pán)做了 RAID 提升了磁盤(pán)的 IO;
第二就是在寫(xiě)入之前,上游進(jìn)行了數(shù)據(jù)的劃分分表操作,直接分開(kāi)寫(xiě)入到不同的分片上,磁盤(pán)的壓力直接變?yōu)榱嗽瓉?lái)的 n 分之一,這樣就很好的避免了磁盤(pán)的單點(diǎn)的瓶頸。

■?2.3 局部 Top 并非全局 Top

第二是會(huì)造成數(shù)據(jù)錯(cuò)誤,我們做的優(yōu)化就是在寫(xiě)入之前加上了一層路由,我們將同一個(gè)內(nèi)容 ID 的數(shù)據(jù)全部路由到了同一個(gè)分片上,解決了該問(wèn)題。這里需要多說(shuō)一下,現(xiàn)在最新版的 Clickhouse 都是不存在這樣這個(gè)問(wèn)題的,對(duì)于有 group by 和 limit 的 SQL 命令,只把 group by 語(yǔ)句下發(fā)到本地表進(jìn)行執(zhí)行,然后各個(gè)本地表執(zhí)行完的全量結(jié)果都會(huì)傳到分布式表,在分布式表再進(jìn)行一次全局的 group by,最后再做 limit 的操作。
這樣雖然能夠保證全局 top N 的正確性,但代價(jià)就是犧牲了一部分的執(zhí)行性能。如果想要恢復(fù)到更高的執(zhí)行性能,我們可以通過(guò) Clickhouse 提供的 distributed_group_by_no_merge 參數(shù)來(lái)選擇執(zhí)行的方式。然后再將同一個(gè)內(nèi)容 ID 的記錄全部路由到同一個(gè)分片上,這樣在本地表也能夠執(zhí)行 limit 操作。
3. 高性能的存儲(chǔ)和查詢(xún)

舉個(gè)例子,通過(guò) summary merge tree 建立一個(gè)內(nèi)容 ID 粒度聚合的累積,累加 pv 的物化視圖,這樣相當(dāng)于提前進(jìn)行了 group by 的計(jì)算,等真正需要查詢(xún)聚合結(jié)果的時(shí)候,就直接查詢(xún)物化視圖,數(shù)據(jù)都是已經(jīng)聚合計(jì)算過(guò)的,且數(shù)據(jù)的掃描量只是原始流水的千分之一。
分布式表查詢(xún)還會(huì)有一個(gè)問(wèn)題,就是查詢(xún)單個(gè)內(nèi)容 ID 的時(shí)候,分布式表會(huì)將查詢(xún)請(qǐng)求下發(fā)到所有的分片上,然后再返回給查詢(xún)結(jié)果進(jìn)行匯總。實(shí)際上因?yàn)樽鲞^(guò)路由,一個(gè)內(nèi)容 ID 只存在于一個(gè)分片上,剩下的分片其實(shí)都是在空跑。針對(duì)這類(lèi)的查詢(xún),我們的優(yōu)化就是后臺(tái)按照同樣的規(guī)則先進(jìn)行路由,然后再查詢(xún)目標(biāo)分片,這樣減少了 n 分之 n -1 的負(fù)載,可以大量的縮短查詢(xún)時(shí)間。而且由于我們提供的是 OLAP 的查詢(xún),數(shù)據(jù)滿足最終的一致性即可。所以通過(guò)主從副本的讀寫(xiě)分離,也可以進(jìn)一步的提升性能。我們?cè)诤笈_(tái)還做了一個(gè)一分鐘的數(shù)據(jù)緩存,這樣針對(duì)相同條件的查詢(xún),后臺(tái)就可以直接返回。

4. Clickhouse 擴(kuò)容方案
比如說(shuō) HBase 原始數(shù)據(jù)是存放在 HDFS 上的,擴(kuò)容只是 region server 的擴(kuò)容,并不涉及到原始數(shù)據(jù)的遷移。
但是 Clickhouse 的每個(gè)分片數(shù)據(jù)都是在本地,更像是 RocksDB 的底層存儲(chǔ)引擎,不能像 HBase 那樣方便的擴(kuò)容。
然后是 Redis,Redis 是 Hash 槽這一種,類(lèi)似于一致性 Hash 的方式,是比較經(jīng)典的分布式緩存方案。
五、實(shí)時(shí)系統(tǒng)應(yīng)用成果總結(jié)
我們輸出了騰訊看點(diǎn)的實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù),DWM 層和 DWS 層兩個(gè)消息隊(duì)列,上線了騰訊看點(diǎn)的實(shí)時(shí)數(shù)據(jù)分析系統(tǒng),該系統(tǒng)能夠亞秒級(jí)的響應(yīng)多維條件查詢(xún)請(qǐng)求。在未命中緩存的情況下:
過(guò)去 30 分鐘的內(nèi)容查詢(xún),99% 的請(qǐng)求耗時(shí)在一秒內(nèi);
過(guò)去 24 小時(shí)的內(nèi)容查詢(xún) 90% 的請(qǐng)求耗時(shí)在 5 秒內(nèi),99% 的請(qǐng)求耗時(shí)在 10 秒內(nèi)。
