
深度學(xué)習(xí)的可解釋性!

一、深度學(xué)習(xí)的可解釋性研究概述
隨著深度學(xué)習(xí)模型在人們?nèi)粘I钪械脑S多場(chǎng)景下扮演著越來(lái)越重要的角色,模型的「可解釋性」成為了決定用戶(hù)是否能夠「信任」這些模型的關(guān)鍵因素(尤其是當(dāng)我們需要機(jī)器為關(guān)系到人類(lèi)生命健康、財(cái)產(chǎn)安全等重要任務(wù)給出預(yù)測(cè)和決策結(jié)果時(shí))。在本章,我們將從深度學(xué)習(xí)可解釋性的定義、研究意義、分類(lèi)方法 3 個(gè)方面對(duì)這一話(huà)題展開(kāi)討論。
1.1
?何為可解釋性
對(duì)于深度學(xué)習(xí)的用戶(hù)而言,模型的可解釋性是一種較為主觀(guān)的性質(zhì),我們無(wú)法通過(guò)嚴(yán)謹(jǐn)?shù)臄?shù)學(xué)表達(dá)方法形式化定義可解釋性。通常,我們可以認(rèn)為深度學(xué)習(xí)的可解釋性刻畫(huà)了「人類(lèi)對(duì)模型決策或預(yù)測(cè)結(jié)果的理解程度」,即用戶(hù)可以更容易地理解解釋性較高的模型做出的決策和預(yù)測(cè)。
?
從哲學(xué)的角度來(lái)說(shuō),為了理解何為深度學(xué)習(xí)的可解釋性,我們需要回答以下幾個(gè)問(wèn)題:首先,我們應(yīng)該如何定義對(duì)事務(wù)的「解釋」,怎樣的解釋才足夠好?許多學(xué)者認(rèn)為,要判斷一個(gè)解釋是否足夠好,取決于這個(gè)解釋需要回答的問(wèn)題是什么。對(duì)于深度學(xué)習(xí)任務(wù)而言,我們最感興趣的兩類(lèi)問(wèn)題是「為什么會(huì)得到該結(jié)果」和「為什么結(jié)果應(yīng)該是這樣」。而理想狀態(tài)下,如果我們能夠通過(guò)溯因推理的方式恢復(fù)出模型計(jì)算出輸出結(jié)果的過(guò)程,就可以實(shí)現(xiàn)較強(qiáng)的模型解釋性。
?
實(shí)際上,我們可以從「可解釋性」和「完整性」這兩個(gè)方面來(lái)衡量一種解釋是否合理。「可解釋性」旨在通過(guò)一種人類(lèi)能夠理解的方式描述系統(tǒng)的內(nèi)部結(jié)構(gòu),它與人類(lèi)的認(rèn)知、知識(shí)和偏見(jiàn)息息相關(guān);而「完整性」旨在通過(guò)一種精確的方式來(lái)描述系統(tǒng)的各個(gè)操作步驟(例如,剖析深度學(xué)習(xí)網(wǎng)絡(luò)中的數(shù)學(xué)操作和參數(shù))。然而,不幸的是,我們很難同時(shí)實(shí)現(xiàn)很強(qiáng)的「可解釋性」和「完整性」,這是因?yàn)榫_的解釋術(shù)語(yǔ)往往對(duì)于人們來(lái)說(shuō)晦澀難懂。同時(shí),僅僅使用人類(lèi)能夠理解的方式進(jìn)行解釋由往往會(huì)引入人類(lèi)認(rèn)知上的偏見(jiàn)。
?
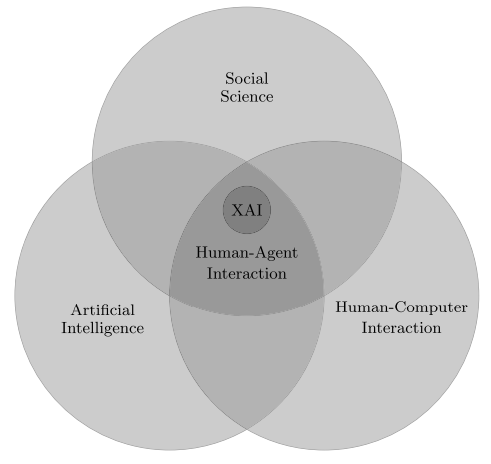
此外,我們還可以從更宏大的角度理解「可解釋性人工智能」,將其作為一個(gè)「人與智能體的交互」問(wèn)題。如圖 1 所示,人與智能體的交互涉及人工智能、社會(huì)科學(xué)、人機(jī)交互等領(lǐng)域。
? ? ? ?
? ? ?
圖 1:可解釋的人工智能?
?
1.2
為什么需要可解釋性
在當(dāng)下的深度學(xué)習(xí)浪潮中,許多新發(fā)表的工作都聲稱(chēng)自己可以在目標(biāo)任務(wù)上取得良好的性能。盡管如此,用戶(hù)在諸如醫(yī)療、法律、金融等應(yīng)用場(chǎng)景下仍然需要從更為詳細(xì)和具象的角度理解得出結(jié)論的原因。為模型賦予較強(qiáng)的可解釋性也有利于確保其公平性、隱私保護(hù)性能、魯棒性,說(shuō)明輸入到輸出之間個(gè)狀態(tài)的因果關(guān)系,提升用戶(hù)對(duì)產(chǎn)品的信任程度。下面,我們從「完善深度學(xué)習(xí)模型」、「深度學(xué)習(xí)模型與人的關(guān)系」、「深度學(xué)習(xí)模型與社會(huì)的關(guān)系」3 個(gè)方面簡(jiǎn)介研究機(jī)器深度學(xué)習(xí)可解釋性的意義。
(1)完善深度學(xué)習(xí)模型
大多數(shù)深度學(xué)習(xí)模型是由數(shù)據(jù)驅(qū)動(dòng)的黑盒模型,而這些模型本身成為了知識(shí)的來(lái)源,模型能提取到怎樣的知識(shí)在很大程度上依賴(lài)于模型的組織架構(gòu)、對(duì)數(shù)據(jù)的表征方式,對(duì)模型的可解釋性可以顯式地捕獲這些知識(shí)。
盡管深度學(xué)習(xí)模型可以取得優(yōu)異的性能,但是由于我們難以對(duì)深度學(xué)習(xí)模型進(jìn)行調(diào)試,使其質(zhì)量保證工作難以實(shí)現(xiàn)。對(duì)錯(cuò)誤結(jié)果的解釋可以為修復(fù)系統(tǒng)提供指導(dǎo)。
(2)深度學(xué)習(xí)模型與人的關(guān)系
在人與深度學(xué)習(xí)模型交互的過(guò)程中,會(huì)形成經(jīng)過(guò)組織的知識(shí)結(jié)構(gòu)來(lái)為用戶(hù)解釋模型復(fù)雜的工作機(jī)制,即「心理模型」。為了讓用戶(hù)得到更好的交互體驗(yàn),滿(mǎn)足其好奇心,就需要賦予模型較強(qiáng)的可解釋性,否則用戶(hù)會(huì)感到沮喪,失去對(duì)模型的信任和使用興趣。
人們希望協(xié)調(diào)自身的知識(shí)結(jié)構(gòu)要素之間的矛盾或不一致性。如果機(jī)器做出了與人的意愿有出入的決策,用戶(hù)則會(huì)試圖解釋這種差異。當(dāng)機(jī)器的決策對(duì)人的生活影響越大時(shí),對(duì)于這種決策的解釋就更為重要。
當(dāng)模型的決策和預(yù)測(cè)結(jié)果對(duì)用戶(hù)的生活會(huì)產(chǎn)生重要影響時(shí),對(duì)模型的可解釋性與用戶(hù)對(duì)模型的信任程度息息相關(guān)。例如,對(duì)于醫(yī)療、自動(dòng)駕駛等與人們的生命健康緊密相關(guān)的任務(wù),以及保險(xiǎn)、金融、理財(cái)、法律等與用戶(hù)財(cái)產(chǎn)安全相關(guān)的任務(wù),用戶(hù)往往需要模型具有很強(qiáng)的可解釋性才會(huì)謹(jǐn)慎地采用該模型。
(3)深度學(xué)習(xí)模型與社會(huì)的關(guān)系
由于深度學(xué)習(xí)高度依賴(lài)于訓(xùn)練數(shù)據(jù),而訓(xùn)練數(shù)據(jù)往往并不是無(wú)偏的,會(huì)產(chǎn)生對(duì)于人種、性別、職業(yè)等因素的偏見(jiàn)。為了保證模型的公平性,用戶(hù)會(huì)要求深度學(xué)習(xí)模型具有檢測(cè)偏見(jiàn)的功能,能夠通過(guò)對(duì)自身決策的解釋說(shuō)明其公平。
深度學(xué)習(xí)模型作為一種商品具有很強(qiáng)的社會(huì)交互屬性,具有強(qiáng)可解釋性的模型也會(huì)具有較高的社會(huì)認(rèn)可度,會(huì)更容易被公眾所接納。
1.3
可解釋性的分類(lèi)
根據(jù)可解釋性方法的作用時(shí)間、可解釋性方法與模型的匹配關(guān)系、可解釋性方法的作用范圍,我們可以將深度學(xué)習(xí)的可解釋性方法分為:本質(zhì)可解釋性和事后可解釋性、針對(duì)特定模型的可解釋性和模型無(wú)關(guān)可解釋性、局部可解釋性和全局可解釋性。
?
其中,本質(zhì)可解釋性指的是對(duì)模型的架構(gòu)進(jìn)行限制,使其工作原理和中間結(jié)果能夠較為容易地為人們所理解(例如,結(jié)構(gòu)簡(jiǎn)單的決策樹(shù)模型);事后可解釋性則指的是通過(guò)各種統(tǒng)計(jì)量、可視化方法、因果推理等手段,對(duì)訓(xùn)練后的模型進(jìn)行解釋。
?
由于深度模型的廣泛應(yīng)用,本文將重點(diǎn)關(guān)注深度學(xué)習(xí)的可解釋性,并同時(shí)設(shè)計(jì)一些深度學(xué)習(xí)方法的解釋。
二、深度學(xué)習(xí)的可解釋性
對(duì)于深度學(xué)習(xí)模型來(lái)說(shuō),我們重點(diǎn)關(guān)注如何解釋「網(wǎng)絡(luò)對(duì)于數(shù)據(jù)的處理過(guò)程」、「網(wǎng)絡(luò)對(duì)于數(shù)據(jù)的表征」,以及「如何構(gòu)建能夠生成自我解釋的深度學(xué)習(xí)系統(tǒng)」。網(wǎng)路對(duì)于數(shù)據(jù)的處理過(guò)程將回答「輸入為什么會(huì)得到相應(yīng)的的特定輸出?」,這一解釋過(guò)程與剖析程序的執(zhí)行過(guò)程相類(lèi)似;網(wǎng)絡(luò)對(duì)于數(shù)據(jù)的表征將回答「網(wǎng)絡(luò)包含哪些信息?」,這一過(guò)程與解釋程序內(nèi)部的數(shù)據(jù)結(jié)構(gòu)相似。下文將重點(diǎn)從以上三個(gè)方面展開(kāi)討論。
?
2.1
深度學(xué)習(xí)過(guò)程的可解釋性
?
常用的深度網(wǎng)絡(luò)使用大量的基本操作來(lái)得出決策:例如,ResNet使用了約5×107個(gè)學(xué)習(xí)參數(shù),1010個(gè)浮點(diǎn)運(yùn)算來(lái)對(duì)單個(gè)圖像進(jìn)行分類(lèi)。解釋這種復(fù)雜模型的基本方法是降低其復(fù)雜度。這可以通過(guò)設(shè)計(jì)表現(xiàn)與原始模型相似但更易于解釋的代理模型來(lái)完成(線(xiàn)性代理模型、決策樹(shù)模型等),或者也可以構(gòu)建顯著性圖(salience map),來(lái)突出顯示最相關(guān)的一部分計(jì)算,從而提供可解釋性。
?
(1)線(xiàn)性代理模型(Proxy Models)
?
目前被廣泛采用的深度學(xué)習(xí)模型,大多仍然是「黑盒模型」。在根據(jù)預(yù)測(cè)結(jié)果規(guī)劃行動(dòng)方案,或者選擇是否部署某個(gè)新模型時(shí),我們需要理解預(yù)測(cè)背后的推理過(guò)程,從而評(píng)估模型的可信賴(lài)程度。一種可能的方法是,使用線(xiàn)性可解釋的模型近似“黑盒模型”。
?
Marco et. al [1]提出了一種新的模型無(wú)關(guān)的模型解釋技術(shù)「LIME」,它可以通過(guò)一種可解釋的、準(zhǔn)確可靠的方式,通過(guò)學(xué)習(xí)一個(gè)圍繞預(yù)測(cè)結(jié)果的可解釋模型,解釋任意的分類(lèi)器或回歸模型的預(yù)測(cè)結(jié)果。本文作者還通過(guò)簡(jiǎn)潔地展示具有代表性的個(gè)體預(yù)測(cè)結(jié)果及其解釋?zhuān)瑢⒃撊蝿?wù)設(shè)計(jì)成了一種子模塊優(yōu)化問(wèn)題。
?
文中指出,一種優(yōu)秀的解釋方法需要具備以下幾點(diǎn)特質(zhì):
(1)可解釋性:給出對(duì)輸入變量和響應(yīng)的關(guān)系的定性理解,可解釋性需要考慮用戶(hù)自身的限制。
(2)局部保真:解釋方法至少需要在局部是可靠的,它必須與模型在被預(yù)測(cè)實(shí)例附近的表現(xiàn)相對(duì)應(yīng)。需要指出的是,在全局上重要的特征不一定在局部環(huán)境下仍然重要,反之亦然。
(3)模型無(wú)關(guān):解釋方法需要能夠解釋各種各樣的模型。
(4)全局視角:準(zhǔn)確度有時(shí)并不是一個(gè)很好的模型評(píng)價(jià)指標(biāo),解釋器旨在給出一些具有代表性的對(duì)樣本的解釋。
?
文中的方法可以基于對(duì)分類(lèi)器局部可靠的可解釋表征,來(lái)鑒別器模型的可解釋性。LIME 會(huì)對(duì)輸入樣本進(jìn)行擾動(dòng),識(shí)別出對(duì)于預(yù)測(cè)結(jié)果影響最大的特征(人類(lèi)可以理解這些特征)。
?
? ? ? ? ? ? ??
? ? ??
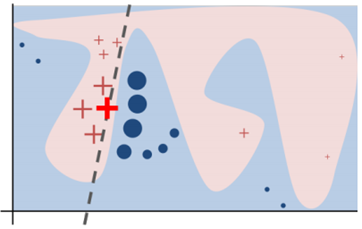
圖 2
如圖 2?所示,加粗的紅色十字樣本有待解釋。從全局來(lái)看,很難判斷紅色十字和藍(lán)色圓圈對(duì)于帶解釋樣本的影響。我們可以將視野縮小到黑色虛線(xiàn)周?chē)木植糠秶鷥?nèi),在加粗紅色十字樣本周?chē)鷮?duì)原始樣本特征做一些擾動(dòng),將擾動(dòng)后的采樣樣本作為分類(lèi)模型的輸入,LIME 的目標(biāo)函數(shù)如下:
? ? ? ?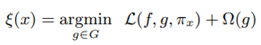 ? ? ??
? ? ??
?
其中,f 為分類(lèi)器,g 為解釋器,π_x 為臨近度度量,Ω(g) 為解釋器 g 的復(fù)雜度,L 為損失函數(shù)。
? ? ? ?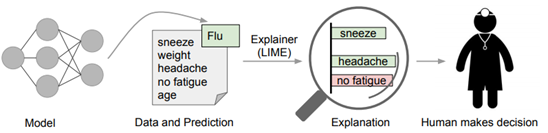
圖 3
因?yàn)榇砟P吞峁┝四P蛷?fù)雜度與可信度之間的量化方法,因此方法間可以互相作為參考,吸引了許多研究工作。
?
(2)決策樹(shù)方法
?
另一種代理模型的方法是決策樹(shù)。將神經(jīng)網(wǎng)絡(luò)分解成決策樹(shù)的工作從1990年代開(kāi)始,該工作能夠解釋淺層網(wǎng)絡(luò),并逐漸泛化到深度神經(jīng)網(wǎng)絡(luò)的計(jì)算過(guò)程中。
?
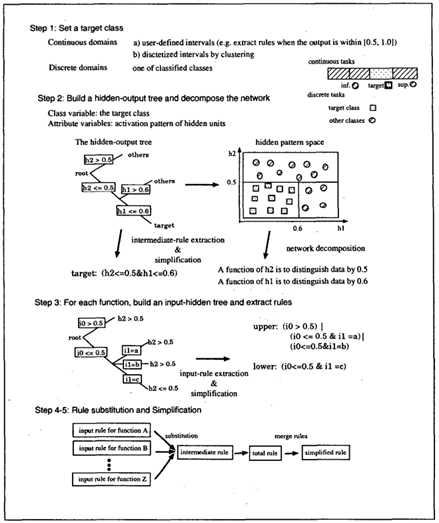
一個(gè)經(jīng)典的例子是Makoto et. al [2]。文中提出了一種新的規(guī)則抽取(Rule Extraction)方法CRED,使用決策樹(shù)對(duì)神經(jīng)網(wǎng)絡(luò)進(jìn)行分解,并通過(guò)c/d-rule算法合并生成的分支,產(chǎn)生不同分類(lèi)粒度,能夠考慮連續(xù)與離散值的神經(jīng)網(wǎng)絡(luò)輸入輸出的解釋。具體算法如下:
?
? ? ? ? ? ??
? ??
圖 4 :CRED算法
DeepRED [3]將CRED的工作拓展到了多層網(wǎng)絡(luò)上,并采用了多種結(jié)構(gòu)優(yōu)化生成樹(shù)的結(jié)構(gòu)。另一種決策樹(shù)結(jié)構(gòu)是ANN-DT[4],同樣使用模型的結(jié)點(diǎn)結(jié)構(gòu)建立決策樹(shù),對(duì)數(shù)據(jù)進(jìn)行劃分。不同的是,判斷節(jié)點(diǎn)是采用正負(fù)兩種方法判斷該位置的函數(shù)是否被激活,以此劃分?jǐn)?shù)據(jù)。決策樹(shù)生成后,通過(guò)在樣本空間采樣、實(shí)驗(yàn),獲得神經(jīng)網(wǎng)絡(luò)的規(guī)則。
?
這階段的工作對(duì)較淺的網(wǎng)絡(luò)生成了可靠的解釋?zhuān)瑔l(fā)了很多工作,但由于決策樹(shù)節(jié)點(diǎn)個(gè)數(shù)依賴(lài)于網(wǎng)絡(luò)大小,對(duì)于大規(guī)模的網(wǎng)絡(luò),方法的計(jì)算開(kāi)銷(xiāo)將相應(yīng)增長(zhǎng)。
?
(3)自動(dòng)規(guī)則生成
?
自動(dòng)規(guī)則生成是另一種總結(jié)模型決策規(guī)律的方法,上世紀(jì)80年代, Gallant將神經(jīng)網(wǎng)絡(luò)視作存儲(chǔ)知識(shí)的數(shù)據(jù)庫(kù),為了從網(wǎng)絡(luò)中發(fā)掘信息和規(guī)則,他在工作[4]中提出了從簡(jiǎn)單網(wǎng)絡(luò)中提取規(guī)則的方法,這可以被看作是規(guī)則抽取在神經(jīng)網(wǎng)絡(luò)中應(yīng)用的起源。現(xiàn)今,神經(jīng)網(wǎng)絡(luò)中的規(guī)則生成技術(shù)主要講輸出看作規(guī)則的集合,利用命題邏輯等方法從中獲取規(guī)則。
?
Hiroshi Tsukimoto [6]提出了一種從訓(xùn)練完成的神經(jīng)網(wǎng)絡(luò)中提取特征提取規(guī)則的方法,該方法屬于分解法,可以適用在輸出單調(diào)的神經(jīng)網(wǎng)絡(luò)中,如sigmoid函數(shù)。該方法不依賴(lài)訓(xùn)練算法,計(jì)算復(fù)雜度為多項(xiàng)式,其計(jì)算思想為:用布爾函數(shù)擬合神經(jīng)網(wǎng)絡(luò)的神經(jīng)元,同時(shí)為了解決該方法導(dǎo)致計(jì)算復(fù)雜度指數(shù)增加的問(wèn)題,將算法采用多項(xiàng)式表達(dá)。最后將該算法推廣到連續(xù)域,提取規(guī)則采用了連續(xù)布爾函數(shù)。
?
Towell [7]形式化了從神經(jīng)網(wǎng)絡(luò)中提取特征的方法,文章從訓(xùn)練完成的神經(jīng)網(wǎng)絡(luò)中提取網(wǎng)絡(luò)提取特征的方法,MoFN,該方法的提取規(guī)則與所提取的網(wǎng)絡(luò)的精度相近,同時(shí)優(yōu)于直接細(xì)化規(guī)則的方法產(chǎn)生的規(guī)則,更加利于人類(lèi)理解網(wǎng)絡(luò)。
?
MoFN分為6步:1)聚類(lèi);2)求平均;3)去誤差;4)優(yōu)化;5)提取;6)簡(jiǎn)化。
聚類(lèi)采用標(biāo)準(zhǔn)聚類(lèi)方法,一次組合兩個(gè)相近的族進(jìn)行聚類(lèi),聚類(lèi)結(jié)束后對(duì)聚類(lèi)的結(jié)果進(jìn)行求平均處理,計(jì)算時(shí)將每組中所有鏈路的權(quán)重設(shè)置為每個(gè)組權(quán)重的平均值,接下來(lái)將鏈接權(quán)重較低的組去除,將留下的組進(jìn)行單位偏差優(yōu)化,優(yōu)化后的組進(jìn)行提取工作,通過(guò)直接將每個(gè)單元的偏差和傳入權(quán)重轉(zhuǎn)換成具有加權(quán)前因的規(guī)則來(lái)創(chuàng)建,最后對(duì)提取到的規(guī)則簡(jiǎn)化。MOFN的算法示例如下圖所示。
? ? ? ?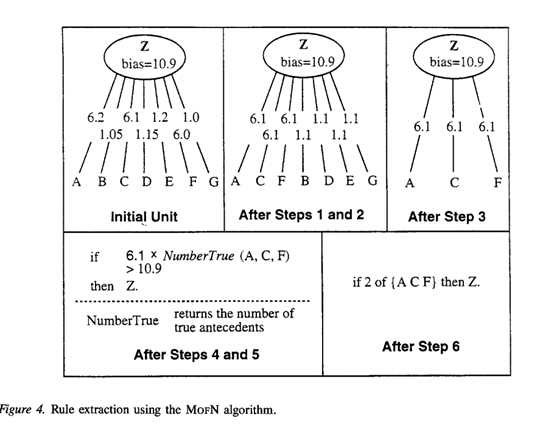
圖5:MOFN 算法
規(guī)則生成可以總結(jié)出可靠可信的神經(jīng)網(wǎng)絡(luò)的計(jì)算規(guī)則,他們有些是基于統(tǒng)計(jì)分析,或者是從模型中推導(dǎo),在保障神經(jīng)網(wǎng)絡(luò)在關(guān)鍵領(lǐng)域的應(yīng)用提供了安全保障的可能。
?
(4)顯著性圖
?
顯著性圖方法使用一系列可視化的技術(shù),從模型中生成解釋?zhuān)摻忉屚ǔ1磉_(dá)了樣本特征對(duì)于模型輸出的影響,從而一定程度上解釋模型的預(yù)測(cè)。常見(jiàn)方法有反卷積、梯度方法等。Zeiler [8]提出了可視化的技巧,使用反卷積觀(guān)察到訓(xùn)練過(guò)程中特征的演化和影響,對(duì)CNN內(nèi)部結(jié)構(gòu)與參數(shù)進(jìn)行了一定的“解讀”,可以分析模型潛在的問(wèn)題,網(wǎng)絡(luò)深度、寬度、數(shù)據(jù)集大小對(duì)網(wǎng)絡(luò)性能的影響,也可以分析了網(wǎng)絡(luò)輸出特征的泛化能力以及泛化過(guò)程中出現(xiàn)的問(wèn)題。
?
利用反卷積實(shí)現(xiàn)特征可視化
?
為了解釋卷積神經(jīng)網(wǎng)絡(luò)如何工作,就需要解釋CNN的每一層學(xué)習(xí)到了什么東西。為了理解網(wǎng)絡(luò)中間的每一層,提取到特征,論文通過(guò)反卷積的方法,進(jìn)行可視化。反卷積網(wǎng)絡(luò)可以看成是卷積網(wǎng)絡(luò)的逆過(guò)程。反卷積可視化以各層得到的特征圖作為輸入,進(jìn)行反卷積,得到反卷積結(jié)果,用以驗(yàn)證顯示各層提取到的特征圖。
Eg:假如你想要查看Alexnet的conv5提取到了什么東西,就用conv5的特征圖后面接一個(gè)反卷積網(wǎng)絡(luò),然后通過(guò):反池化、反激活、反卷積,這樣的一個(gè)過(guò)程,把本來(lái)一張13*13大小的特征圖(conv5大小為13*13),放大回去,最后得到一張與原始輸入圖片一樣大小的圖片(227*227)。
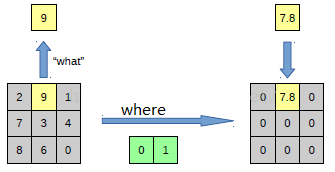
反池化過(guò)程
?
池化是不可逆的過(guò)程,然而可以通過(guò)記錄池化過(guò)程中,最大激活值的坐標(biāo)位置。然后在反池化的時(shí)候,只把池化過(guò)程中最大激活值所在的位置坐標(biāo)的值激活,其它的值置為0,當(dāng)然這個(gè)過(guò)程只是一種近似,因?yàn)樵诔鼗倪^(guò)程中,除了最大值所在的位置,其它的值也是不為0的。
? ? ? ? ? ?
? ?
圖 6?
?
反激活
?
在Alexnet中,relu函數(shù)是用于保證每層輸出的激活值都是正數(shù),因此對(duì)于反向過(guò)程,同樣需要保證每層的特征圖為正值,也就是說(shuō)這個(gè)反激活過(guò)程和激活過(guò)程沒(méi)有什么差別,都是直接采用relu函數(shù)。
?
另一些可視化方法可視化方法主要是通過(guò)deconv的方法將某一層特征圖的Top-k激活反向投射到原圖像上,從而判斷該激活值主要識(shí)別圖像的什么部分。這就要求針對(duì)每一層都必須有對(duì)應(yīng)的逆向操作。
具體而言,對(duì)于MaxPooling層,在前饋時(shí)使用switch變量來(lái)記錄最大值來(lái)源的index,然后以此近似得到Unpooling。對(duì)于Relu層,直接使用Relu層。而對(duì)于conv層,使用deconv,即使用原來(lái)卷積核的轉(zhuǎn)置作為卷積核。通過(guò)可視化方法,對(duì)訓(xùn)練完成的模型在ImageNet的數(shù)據(jù)各層可視化后,可以得到不同結(jié)構(gòu)的重建特征圖,與原圖進(jìn)行對(duì)比能夠直觀(guān)地看到網(wǎng)絡(luò)各層學(xué)習(xí)到的信息:
? ? ? ? ?
?
圖 7:第二層學(xué)習(xí)邊緣,角落信息;第三層學(xué)到了一些比較復(fù)雜的模式,網(wǎng)狀,輪胎;第四層展示了一些比較明顯的變化,但是與類(lèi)別更加相關(guān)了,比如狗臉,鳥(niǎo)腿;第五層則看到了整個(gè)物體,比如鍵盤(pán),狗。
同時(shí),通過(guò)可視化,我們也可以發(fā)現(xiàn)模型的缺陷,例如某些層學(xué)習(xí)到的特征雜亂無(wú)章,通過(guò)單獨(dú)訓(xùn)練,可以提升模型效果。另外的方法也被采用,例如使用遮擋的方法,通過(guò)覆蓋輸入的某部分特征,分析輸出和模型計(jì)算的中間參數(shù),得到模型對(duì)被遮擋部分的敏感性,生成敏感性圖,或者用梯度方法得到輸出對(duì)于輸入圖像像素的梯度,生成梯度熱力圖。
總結(jié)性的工作來(lái)自ETH Zurch的Enea Ceolini [9]證明了基于梯度的歸因方法(gradient-based Attribution methods)存在形式上\聯(lián)系,文章證明了在一定情況下,諸如sigma-LRP[10]、DeepLIF[11]方法間存在的等價(jià)和近似關(guān)系,并基于統(tǒng)一的數(shù)學(xué)表達(dá),提出了一個(gè)更普適的梯度歸因方法框架Sensitivity-n,用于解釋模型輸入輸出之間的關(guān)聯(lián)。
?
深度學(xué)習(xí)的歸因分析用于解釋輸入的每個(gè)變量對(duì)于神經(jīng)網(wǎng)絡(luò)的貢獻(xiàn)(contribution),或相關(guān)程度(relevance),嚴(yán)格來(lái)說(shuō),假設(shè)網(wǎng)絡(luò)的輸入為x = [x1, ..., xN ],C個(gè)輸出神經(jīng)元對(duì)應(yīng)的輸出為S(x) = [S1(x), ..., SC (x)],歸因分析的目標(biāo)便是找到xi對(duì)于每個(gè)神經(jīng)元輸出的貢獻(xiàn),Rc = [Rc 1 , ..., Rc N ]。
基于梯度的方法可以被看作直接使用輸出對(duì)輸出的特征求梯度,用梯度的一定變換形式表示其重要性,工作中展示的考慮不同大小特征區(qū)域熱力圖如下:
? ? ? ?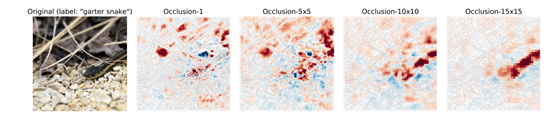
圖 8
文章分析了不同方法的效果差異:
? ? ? ? ?
?
圖?9
?
通過(guò)證明,得到通用的梯度方法表示為:
? ? ? ? ? ? ??
? ? ??
基于上述推導(dǎo),作者得以提出了sensitivity-n方法,總結(jié)了相似的梯度方法,并使后續(xù)工作可以在更廣泛的框架下討論。
2.2
深度網(wǎng)絡(luò)表示的可解釋性
?
盡管存在大量神經(jīng)網(wǎng)絡(luò)運(yùn)算,深度神經(jīng)網(wǎng)絡(luò)內(nèi)部由少數(shù)的子組件構(gòu)成:例如,數(shù)十億個(gè)ResNet的操作被組織為約100層,每層計(jì)算64至2048信息通道像素。對(duì)深層網(wǎng)絡(luò)表示的解釋旨在了解流經(jīng)這些信息瓶頸的數(shù)據(jù)的作用和結(jié)構(gòu)。可以按其粒度劃分為三個(gè)子類(lèi):基于層的解釋,將流經(jīng)層的所有信息一起考慮;基于神經(jīng)元的解釋,用來(lái)說(shuō)明單個(gè)神經(jīng)元或單個(gè)filter通道的情況;此外基于(其他)表示向量的解釋,例如概念激活向量(CAV)[12]是通過(guò)識(shí)別和探測(cè)與人類(lèi)可解釋概念一致的方向來(lái)解釋神經(jīng)網(wǎng)絡(luò)表示,用單個(gè)單元的線(xiàn)性組合所形成的表示向量空間中的其他方向作為其表征向量。
?
(1)基于層的解釋
Bengio等人[13]分析了在圖片分類(lèi)任務(wù)中,不同層的神經(jīng)網(wǎng)絡(luò)的功能和可遷移性,以及不同遷移方法對(duì)結(jié)果的影響。從實(shí)驗(yàn)的角度分析了神經(jīng)網(wǎng)絡(luò)不同層參數(shù)具有的一些性質(zhì),證明了模型遷移方法的普遍效果。作者驗(yàn)證了淺層神經(jīng)網(wǎng)絡(luò)在特征抽取功能上的通用性和可復(fù)用性,針對(duì)實(shí)驗(yàn)結(jié)果提出了可能的解釋?zhuān)砻饔绊戇w移學(xué)習(xí)效果的因素有二:
?
1)?共同訓(xùn)練變量的影響
通過(guò)反向傳播算法訓(xùn)練的神經(jīng)網(wǎng)絡(luò),結(jié)點(diǎn)參數(shù)并非單獨(dú)訓(xùn)練,其梯度計(jì)算依賴(lài)于一系列相關(guān)結(jié)點(diǎn),因此遷移部分結(jié)點(diǎn)參數(shù)會(huì)引起相關(guān)結(jié)點(diǎn)的訓(xùn)練困難。
?
2)?遷移參數(shù)的通用性能和專(zhuān)用性
網(wǎng)絡(luò)中較淺層網(wǎng)絡(luò)的功能較為通用,而高層網(wǎng)絡(luò)與網(wǎng)絡(luò)的訓(xùn)練目標(biāo)更加相關(guān)。若A、B任務(wù)不想關(guān),則專(zhuān)用于A的參數(shù)遷移后會(huì)影響對(duì)B任務(wù)的學(xué)習(xí)。
? ? ? ?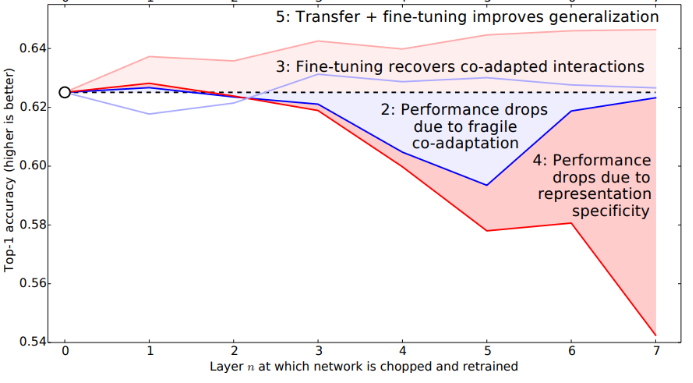
圖10
實(shí)驗(yàn)結(jié)果發(fā)現(xiàn),在不同的實(shí)驗(yàn)條件下,兩種因素會(huì)不同程度決定遷移學(xué)習(xí)的效果。例如,當(dāng)遷移較深層網(wǎng)絡(luò)并固定參數(shù)時(shí),高層參數(shù)的專(zhuān)用性會(huì)導(dǎo)致在遷移到的任務(wù)上表現(xiàn)不佳,但這時(shí)共同訓(xùn)練的變量影響會(huì)減小,因?yàn)榇蟛糠謪?shù)都被遷移獲得;當(dāng)遷移自身的參數(shù)并固定時(shí),在層數(shù)較小的情況下出現(xiàn)了性能下降,這說(shuō)明了共同訓(xùn)練的變量對(duì)表現(xiàn)的影響。另外,實(shí)驗(yàn)發(fā)現(xiàn)完全不相關(guān)的任務(wù)對(duì)應(yīng)的遷移,在經(jīng)過(guò)充分微調(diào)后仍然能提升模型的性能,這證明了參數(shù)遷移是一個(gè)通用的提升模型性能的方法。
?
牛津大學(xué)Karen Simonyan等人[14]為解決深層卷積神經(jīng)網(wǎng)絡(luò)分類(lèi)模型的可視化問(wèn)題,提出了兩種方法:第一種生成圖像使得類(lèi)得分最大化,再將類(lèi)可視化;第二種計(jì)算給定圖像和類(lèi)的類(lèi)顯著性映射,同時(shí)還證明了這種方法可以使用分類(lèi)轉(zhuǎn)換網(wǎng)絡(luò)的弱監(jiān)督對(duì)象分類(lèi)。整個(gè)文章主要有三個(gè)貢獻(xiàn):證明了理解分類(lèi)CNN模型可以使用輸入圖像的數(shù)值優(yōu)化;提出了一種在圖像中提取指定類(lèi)別的空間表征信息(image-specific class saliency map)的方法(只通過(guò)一次back-propagation),并且這種saliency maps可以用于弱監(jiān)督的物體定位。證明gradient-based的可視化方法可以推廣到deconvolutional network的重構(gòu)過(guò)程。
?
在第一類(lèi)方法中,文中采用公式(1)進(jìn)行圖像分類(lèi)模型的可視化操作,其中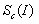 表示c的分?jǐn)?shù),由ConvNet的分類(lèi)層對(duì)圖像I計(jì)算得到,
表示c的分?jǐn)?shù),由ConvNet的分類(lèi)層對(duì)圖像I計(jì)算得到, 是正則化參數(shù)。可視化過(guò)程與ConvNet訓(xùn)練過(guò)程類(lèi)似,不同之處在于對(duì)圖像的輸入做了優(yōu)化,權(quán)重則固定為訓(xùn)練階段得到的權(quán)重。圖1所示為使用零圖像初始化優(yōu)化,然后將訓(xùn)練集的均值圖像添加到結(jié)果中的輸出圖。
是正則化參數(shù)。可視化過(guò)程與ConvNet訓(xùn)練過(guò)程類(lèi)似,不同之處在于對(duì)圖像的輸入做了優(yōu)化,權(quán)重則固定為訓(xùn)練階段得到的權(quán)重。圖1所示為使用零圖像初始化優(yōu)化,然后將訓(xùn)練集的均值圖像添加到結(jié)果中的輸出圖。
? ? ? ?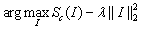 ? ? ? ? (1)
? ? ? ? (1)
? ? ? ?
圖 11?
在第二類(lèi)方法中,給定一張圖像I0,在I0附近使用一階泰勒展開(kāi)的線(xiàn)性函數(shù)來(lái)近似Sc(I):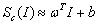 ,其中w即為Sc對(duì)于圖像I的導(dǎo)數(shù)在I0點(diǎn)的值:
,其中w即為Sc對(duì)于圖像I的導(dǎo)數(shù)在I0點(diǎn)的值: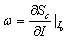 。
。
?
在給定的圖像I0(m行n列)和對(duì)應(yīng)的類(lèi)別c中,要求得它對(duì)應(yīng)saliency map M (M∈Rmxn),首先按照上述公式利用back-propagation 可以求得導(dǎo)數(shù)w,然后對(duì)w元素進(jìn)行重新排列即可得到Saliency Map。Saliency Map是利用訓(xùn)練好的CNN直接提取的,無(wú)需使用額外的標(biāo)注,而且對(duì)于某個(gè)特定類(lèi)別的image-specific saliency map的求解是很快的,只需要一次back-propagation。可視化結(jié)果如圖2所示
? ? ? ?
圖 12
在第二類(lèi)方法中得到的Saliency Map編碼了給定圖像中特定類(lèi)別的物體位置信息,所以它可以被用來(lái)進(jìn)行物體定位(盡管它在分類(lèi)任務(wù)上得到訓(xùn)練,弱監(jiān)督學(xué)習(xí))。給定一張圖像和其對(duì)應(yīng)的Saliency Map,可以使用GraphCut顏色分割模型來(lái)得到物體分割mask。要使用顏色分割模型主要是因?yàn)镾aliency Map只能捕捉到一個(gè)物體最具有區(qū)分性的部分,它無(wú)法highlight整個(gè)物體,因此需要將threshold map傳遞到物體的其他區(qū)域,本文使用colour continuity cues來(lái)達(dá)到這個(gè)目的。前景和背景模型都被設(shè)置為高式混合模型,高于圖像Saliency distribution 95%的像素被視為前景,Saliency低于30%的像素被視為背景。標(biāo)記了前景和背景像素之后,前景像素的最大連接區(qū)域即為對(duì)應(yīng)物體的分割mask(使用GraphCut算法),效果如圖3所示。
?

圖 13
此外,Zhang et. al. 的工作[15]發(fā)現(xiàn)網(wǎng)絡(luò)淺層具有統(tǒng)計(jì)輸入信息的功能,并發(fā)現(xiàn)其和共享的特征信息一樣,對(duì)遷移帶來(lái)的性能提升起到了幫助。通過(guò)從相同checkpoint訓(xùn)練,發(fā)現(xiàn)參數(shù)遷移,可以使模型損失每次都保持在相同的平面內(nèi)(basin),具有相似的地形,但隨機(jī)初始化的參數(shù)每次損失所在的訓(xùn)練平面不同。文章支持了高層、低層網(wǎng)絡(luò)具有的不同功能,發(fā)現(xiàn)高層網(wǎng)路對(duì)于參數(shù)的改變更加敏感。
?
(2)基于神經(jīng)元的解釋
?
香港中文大學(xué)助理教授周博磊的工作[16]為 CAM 技術(shù)的奠定了基礎(chǔ),發(fā)現(xiàn)了 CNN 中卷積層對(duì)目標(biāo)的定位功能。在改文中,作者對(duì)場(chǎng)景分類(lèi)任務(wù)中訓(xùn)練 CNN 時(shí)得到的目標(biāo)檢測(cè)器展開(kāi)了研究。由于場(chǎng)景是由物體組成的,用于場(chǎng)景分類(lèi)的 CNN 會(huì)自動(dòng)發(fā)現(xiàn)有意義的目標(biāo)檢測(cè)器,它們對(duì)學(xué)到的場(chǎng)景類(lèi)別具有代表性。作者發(fā)現(xiàn),單個(gè)網(wǎng)絡(luò)可以支持多個(gè)級(jí)別的抽象(如邊緣、紋理、對(duì)象、場(chǎng)景),同一個(gè)網(wǎng)絡(luò)可以在無(wú)監(jiān)督環(huán)境下,在單個(gè)前向傳播過(guò)程中同時(shí)完成場(chǎng)景識(shí)別和目標(biāo)定位。
? ? ? ?
圖 14:估計(jì)每個(gè)神經(jīng)元的感受野
針對(duì)每個(gè)神經(jīng)元,作者估計(jì)出了其確切地感受野,并觀(guān)察到激活區(qū)域傾向于隨著層的深度增加而在語(yǔ)義上變得更有意義(這是啟發(fā)后來(lái)一系列計(jì)算機(jī)視覺(jué)神經(jīng)網(wǎng)絡(luò)框架的理論基礎(chǔ))。
?
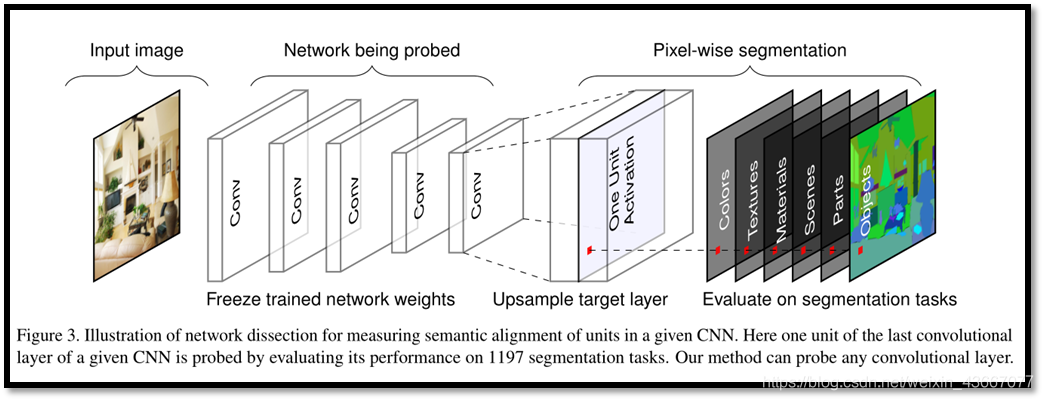
周博磊CVPR 2017[17]提出了一種名為“Network Dissection”的通用框架,假設(shè)“單元的可解釋性等同于單元的隨機(jī)線(xiàn)性結(jié)合”,通過(guò)評(píng)估單個(gè)隱藏單元與一系列語(yǔ)義概念間的對(duì)應(yīng)關(guān)系,來(lái)量化 CNN 隱藏表征的可解釋性。
這種方法利用大量的視覺(jué)概念數(shù)據(jù)集來(lái)評(píng)估每個(gè)中間卷積層隱藏單元的語(yǔ)義。這些帶有語(yǔ)義的單元被賦予了大量的概念標(biāo)簽,這些概念包括物體、組成部分、場(chǎng)景、紋理、材料和顏色等。該方法揭示 CNN 模型和訓(xùn)練方法的特性,而不僅僅是衡量他們的判別能力。
論文發(fā)現(xiàn):人類(lèi)可解釋的概念有時(shí)候會(huì)以單一隱藏變量的形式出現(xiàn)在這些網(wǎng)絡(luò)中;當(dāng)網(wǎng)絡(luò)未受限于只能用可解釋的方式分解問(wèn)題時(shí),就會(huì)出現(xiàn)這種內(nèi)部結(jié)構(gòu)。這種可解釋結(jié)構(gòu)的出現(xiàn)意味著,深度神經(jīng)網(wǎng)絡(luò)也許可以自發(fā)學(xué)習(xí)分離式表征(disentangled representations)。
眾所周知,神經(jīng)網(wǎng)絡(luò)可以學(xué)習(xí)某種編碼方式,高效利用隱藏變量來(lái)區(qū)分其狀態(tài)。如果深度神經(jīng)網(wǎng)絡(luò)的內(nèi)部表征是部分分離的,那么檢測(cè)斷分離式結(jié)構(gòu)并讀取分離因數(shù)可能是理解這種機(jī)制的一種方法。同時(shí)該論文指出可解釋性是與坐標(biāo)軸對(duì)齊(axis-aligned)的,對(duì)表示(representation)進(jìn)行翻轉(zhuǎn)(rotate),網(wǎng)絡(luò)的可解釋能力會(huì)下降,但是分類(lèi)性能不變。越深的結(jié)構(gòu)可解釋性越好,訓(xùn)練輪數(shù)越多越好。而與初始化無(wú)關(guān)dropout會(huì)增強(qiáng)可解釋性而B(niǎo)atch normalization會(huì)降低可解釋性。
? ?圖 15
?圖 15
麻省理工大學(xué)CSAIL的Jonathan Frankle和Michael Carbin論文[18]中指出神經(jīng)網(wǎng)絡(luò)剪枝技術(shù)可以將受過(guò)訓(xùn)練的網(wǎng)絡(luò)的參數(shù)減少90%以上,在不影響準(zhǔn)確性的情況下,降低存儲(chǔ)要求并提高計(jì)算性能。
然而,目前的經(jīng)驗(yàn)是通過(guò)剪枝產(chǎn)生的稀疏架構(gòu)很難從頭訓(xùn)練,也很難提高訓(xùn)練性能。作者發(fā)現(xiàn)標(biāo)準(zhǔn)的剪枝技術(shù)自然而然地可以得到子網(wǎng)絡(luò),它們能在某些初始化條件下有效地進(jìn)行訓(xùn)練。在此基礎(chǔ)之上,作者提出了彩票假設(shè):任何密集、隨機(jī)初始化的包含子網(wǎng)絡(luò)(中獎(jiǎng)彩票)的前饋網(wǎng)絡(luò) ,當(dāng)它們被單獨(dú)訓(xùn)練時(shí),可以在相似的迭代次數(shù)內(nèi)達(dá)到與原始網(wǎng)絡(luò)相當(dāng)?shù)臏y(cè)試精度。
?
具體而言,作者通過(guò)迭代式而定剪枝訓(xùn)練網(wǎng)絡(luò),并剪掉最小的權(quán)重,從而得到「中獎(jiǎng)彩票」。通過(guò)大量實(shí)驗(yàn),作者發(fā)現(xiàn),剪枝得到的中獎(jiǎng)彩票網(wǎng)絡(luò)比原網(wǎng)絡(luò)學(xué)習(xí)得更快,泛化性能更強(qiáng),準(zhǔn)確率更高。剪枝的主要的步驟如下:
?
(1)隨機(jī)初始化一個(gè)神經(jīng)網(wǎng)絡(luò)? ? ? ? ?
? ? ? ?
(2)將網(wǎng)絡(luò)訓(xùn)練 j 輪,得到參數(shù)![]() ? ? ??
? ? ??
(3)剪掉![]() ?中 p% 的參數(shù),得到掩模 m
?中 p% 的參數(shù),得到掩模 m
(4)將剩余的參數(shù)重置為![]() 中的值,生成中獎(jiǎng)彩票
中的值,生成中獎(jiǎng)彩票![]() ?
?
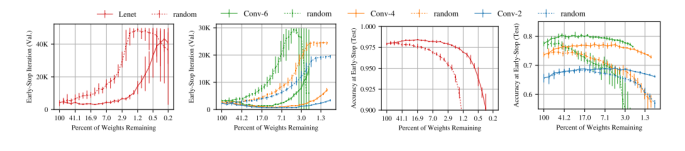
圖 16:虛線(xiàn)為隨機(jī)才應(yīng)該能得到的稀疏網(wǎng)絡(luò),實(shí)現(xiàn)為中獎(jiǎng)彩票。
?
此外,加利福尼亞大學(xué)的ZHANG ?Quanshi和ZHU ?Song-chun 綜述了近年來(lái)神經(jīng)網(wǎng)絡(luò)可解釋性方面的研究進(jìn)展[19]。文章以卷積神經(jīng)網(wǎng)絡(luò)(CNN)為研究對(duì)象,回顧了CNN表征的可視化、預(yù)訓(xùn)練CNN表征的診斷方法、預(yù)訓(xùn)練CNN表征的分離方法、帶分離表示的CNN學(xué)習(xí)以及基于模型可解釋性的中端學(xué)習(xí)。
最后,討論了可解釋人工智能的發(fā)展趨勢(shì),并且指出了以下幾個(gè)未來(lái)可能的研究方向:1)將conv層的混沌表示分解為圖形模型或符號(hào)邏輯;2)可解釋神經(jīng)網(wǎng)絡(luò)的端到端學(xué)習(xí),其中間層編碼可理解的模式(可解釋的cnn已經(jīng)被開(kāi)發(fā)出來(lái),其中高轉(zhuǎn)換層中的每個(gè)過(guò)濾器代表一個(gè)特定的對(duì)象部分);3)基于CNN模式的可解釋性表示,提出了語(yǔ)義層次的中端學(xué)習(xí),以加快學(xué)習(xí)過(guò)程;4)基于可解釋網(wǎng)絡(luò)的語(yǔ)義層次結(jié)構(gòu),在語(yǔ)義級(jí)別調(diào)試CNN表示將創(chuàng)建新的可視化應(yīng)用程序。
?
網(wǎng)絡(luò)模型自身也可以通過(guò)不同的設(shè)計(jì)方法和訓(xùn)練使其具備一定的解釋性,常見(jiàn)的方法主要有三種:注意力機(jī)制網(wǎng)絡(luò);分離表示法;生成解釋法。基于注意力機(jī)制的網(wǎng)絡(luò)可以學(xué)習(xí)一些功能,這些功能提供對(duì)輸入或內(nèi)部特征的加權(quán),以引導(dǎo)網(wǎng)絡(luò)其他部分可見(jiàn)的信息。分離法的表征可以使用單獨(dú)的維度來(lái)描述有意義的和獨(dú)立的變化因素,應(yīng)用中可以使用深層網(wǎng)絡(luò)訓(xùn)練顯式學(xué)習(xí)的分離表示。在生成解釋法中,深層神經(jīng)網(wǎng)絡(luò)也可以把生成人類(lèi)可理解的解釋作為系統(tǒng)顯式訓(xùn)練的一部分。
2.3
生成自我解釋的深度學(xué)習(xí)系統(tǒng)
網(wǎng)絡(luò)模型自身也可以通過(guò)不同的設(shè)計(jì)方法和訓(xùn)練使其具備一定的解釋性,常見(jiàn)的方法主要有三種:注意力機(jī)制網(wǎng)絡(luò);分離表示法;生成解釋法。基于注意力機(jī)制的網(wǎng)絡(luò)可以學(xué)習(xí)一些功能,這些功能提供對(duì)輸入或內(nèi)部特征的加權(quán),以引導(dǎo)網(wǎng)絡(luò)其他部分可見(jiàn)的信息。分離法的表征可以使用單獨(dú)的維度來(lái)描述有意義的和獨(dú)立的變化因素,應(yīng)用中可以使用深層網(wǎng)絡(luò)訓(xùn)練顯式學(xué)習(xí)的分離表示。在生成解釋法中,深層神經(jīng)網(wǎng)絡(luò)也可以把生成人類(lèi)可理解的解釋作為系統(tǒng)顯式訓(xùn)練的一部分。
(1)注意力機(jī)制網(wǎng)絡(luò)
?
注意力機(jī)制的計(jì)算過(guò)程可以被解釋為:計(jì)算輸入與其中間過(guò)程表示之間的相互權(quán)重。計(jì)算得到的與其他元素的注意力值可以被直觀(guān)的表示。
在Dong Huk Park 發(fā)表于CVPR2018的[20]一文中,作者提出的模型可以同時(shí)生成圖像與文本的解釋。其方法在于利用人類(lèi)的解釋糾正機(jī)器的決定,但當(dāng)時(shí)并沒(méi)有通用的包含人類(lèi)解釋信息與圖像信息的數(shù)據(jù)集,因此,作者整理了數(shù)據(jù)集ACT-X與VQA-X,并在其上訓(xùn)練提出了P-JX(Pointing and Justification Explanation)模型,檢測(cè)結(jié)果如圖所示。
? ? ? ?
圖 17:P-JX模型檢測(cè)結(jié)果
模型利用「attention」機(jī)制得到圖像像素的重要性,并據(jù)此選擇輸出的視覺(jué)圖,同時(shí),數(shù)據(jù)集中的人類(lèi)解釋文本對(duì)模型的預(yù)測(cè)作出糾正,這樣模型可以同時(shí)生成可視化的解釋?zhuān)嗄芡ㄟ^(guò)文字說(shuō)明描述關(guān)注的原因。例如在上圖中,對(duì)問(wèn)題「Is this a healthy meal」,針對(duì)圖片,關(guān)注到了熱狗,因此回答「No」,圖片的注意力熱力圖給出了可視化的解釋?zhuān)瑫r(shí)文本亦生成了對(duì)應(yīng)的文本解釋。作者認(rèn)為,利用多模態(tài)的信息可以更好地幫助模型訓(xùn)練,同時(shí)引入人類(lèi)的知識(shí)糾錯(cuò)有利于提高模型的可解釋性。
?
由于類(lèi)別之間只有通過(guò)細(xì)微局部的差異才能夠被區(qū)分出來(lái),因此「fine-grained」分類(lèi)具有挑戰(zhàn)性,在Xiao et. al. 的[21]中,作者將視覺(jué)「attention」應(yīng)用到「fine-grained」分類(lèi)問(wèn)題中,盡管注意力的單元不是出于可解釋性的目的而訓(xùn)練的,但它們可以直接揭示信息在網(wǎng)絡(luò)種的傳播地圖,可以作為一種解釋。由于細(xì)粒度特征不適用bounding box標(biāo)注,因此該文章采用「弱監(jiān)督學(xué)習(xí)」的知識(shí)來(lái)解決這一問(wèn)題。
?
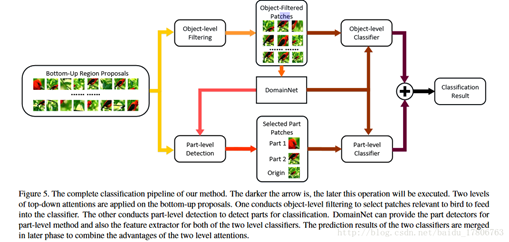
該文章中整合了3種attention模型:「bottom-up」(提供候選者patch),「object-level top-down」(certain object相關(guān)patch),和「part-level top-down 」(定位具有分辨能力的parts),將其結(jié)合起來(lái)訓(xùn)練「domain-specific深度網(wǎng)絡(luò)」。
? ? ? ? ? ? ?
? ? ?
圖 18:Domain-specific深度網(wǎng)絡(luò)結(jié)構(gòu)示意圖
domain-specific深度網(wǎng)絡(luò)結(jié)構(gòu)示意圖如圖 18 所示:實(shí)現(xiàn)細(xì)粒度圖像分類(lèi)需要先看到物體,然后看到它最容易判別的部分。通過(guò)bottom-up生成候選patches,這個(gè)步驟會(huì)提供多尺度,多視角的原始圖像。
如果object很小,那么大多數(shù)的patches都是背景,因此需要top-down的方法來(lái)過(guò)濾掉這些噪聲patches,選擇出相關(guān)性比較高的patches。尋找前景物體和物體的部分分別采用「object-level」和「part-level」兩個(gè)過(guò)程,二者由于接受的patch不同,使其功能和優(yōu)勢(shì)也不同。在object-level中對(duì)產(chǎn)生的patches選出包含基本類(lèi)別對(duì)象的patch,濾掉背景。part-level分類(lèi)器專(zhuān)門(mén)對(duì)包含有判別力的局部特征進(jìn)行處理。
有的patch被兩個(gè)分類(lèi)器同時(shí)使用,但該部分代表不同的特征,將每幅圖片的object-level和part-level的分?jǐn)?shù)相加,得到最終的分?jǐn)?shù),即分類(lèi)結(jié)果。
?
(2)分離表示法
?
分離表示目標(biāo)是用高低維度的含義不同的獨(dú)立特征表示樣本,過(guò)去的許多方法提供了解決該問(wèn)題的思路,例如PCA、ICA、NMF等。深度網(wǎng)絡(luò)同樣提供了處理這類(lèi)問(wèn)題的方法。
?
Chen et. al. 在加州大學(xué)伯克利分校的工作[22]曾被 OpenAI 評(píng)為 2016 年 AI 領(lǐng)域的五大突破之一,在 GAN 家族的發(fā)展歷史上具有里程碑式的意義。對(duì)于大多數(shù)深度學(xué)習(xí)模型而言,其學(xué)習(xí)到的特征往往以復(fù)雜的方式在數(shù)據(jù)空間中耦合在一起。如果可以對(duì)學(xué)習(xí)到的特征進(jìn)行解耦,就可以得到可解釋性更好的編碼。對(duì)于原始的 GAN 模型而言,生成器的輸入為連續(xù)的噪聲輸入,無(wú)法直觀(guān)地將輸入的維度與具體的數(shù)據(jù)中的語(yǔ)義特征相對(duì)應(yīng),即無(wú)法得到可解釋的數(shù)據(jù)表征。為此,InfoGAN 的作者以無(wú)監(jiān)督的方式將 GAN 的輸入解耦為兩部分:
(1)不可壓縮的 z,該部分不存在可以被顯式理解的語(yǔ)義信息。
(2)可解釋的隱變量 c,該部分包含我們關(guān)心的語(yǔ)義特征(如 MNIST 數(shù)據(jù)集中數(shù)字的傾斜程度、筆畫(huà)的粗細(xì)),與生成的數(shù)據(jù)之間具有高相關(guān)性(即二者之間的互信息越大越好)。
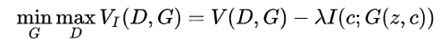 ? ? ??
? ? ??
?
若 c 對(duì)生成數(shù)據(jù) G(z,c)的可解釋性強(qiáng),則 c 與 G(z,c) 之間的交互信息較大。為了實(shí)現(xiàn)這一目標(biāo),作者向原始 GAN 的目標(biāo)函數(shù)中加入了一個(gè)互信息正則化項(xiàng),得到了如下所示的目標(biāo)函數(shù):
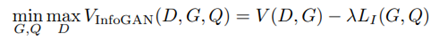 ? ? ??
? ? ??
?
然而,在計(jì)算新引入的正則項(xiàng)過(guò)程中,模型難以對(duì)后驗(yàn)分布 P(C|X) 進(jìn)行采樣和估計(jì)。因此,作者采用變分推斷的方法,通過(guò)變分分布 Q(C|X) 逼近 P(C|X)。最終,InfoGAN 被定義為了如下所示的帶有變分互信息正則化項(xiàng)和超參數(shù) λ 的 minmax 博弈:
? ? ? ?
圖 19:InfoGAN 框架示意圖
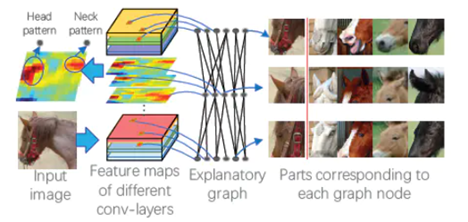
張拳石團(tuán)隊(duì)的[23]一文中,提出了一種名為「解釋圖」的圖模型,旨在揭示預(yù)訓(xùn)練的 CNN 中隱藏的知識(shí)層次。
?
在目標(biāo)分類(lèi)和目標(biāo)檢測(cè)等任務(wù)中,端到端的「黑盒」CNN模型取得了優(yōu)異的效果,但是對(duì)于其包含豐富隱藏模式的卷積層編碼,仍然缺乏合理的解釋?zhuān)獙?duì) CNN 的卷積編碼進(jìn)行解釋?zhuān)枰鉀Q以下問(wèn)題:
CNN 的每個(gè)卷積核記憶了多少種模式?
哪些模式會(huì)被共同激活,用來(lái)描述同一個(gè)目標(biāo)部分?
兩個(gè)模式之間的空間關(guān)系如何?
? ? ? ? ?
?
圖 20:解釋圖結(jié)構(gòu)示意圖
?
解釋圖結(jié)構(gòu)示意圖表示了隱藏在 CNN 卷積層中的知識(shí)層次。預(yù)訓(xùn)練 CNN 中的每個(gè)卷積核可能被不同的目標(biāo)部分激活。本文提出的方法是以一種無(wú)監(jiān)督的方式將不同的模式從每個(gè)卷積核中解耦出來(lái),從而使得知識(shí)表征更為清晰。
?
具體而言,解釋圖中的各層對(duì)應(yīng)于 CNN 中不同的卷積層。解釋圖的每層擁有多個(gè)節(jié)點(diǎn),它們被用來(lái)表示所有候選部分的模式,從而總結(jié)對(duì)應(yīng)的卷積層中隱藏于無(wú)序特征圖中的知識(shí),圖中的邊被用來(lái)連接相鄰層的節(jié)點(diǎn),從而編碼它們對(duì)某些部分的共同激活邏輯和空間關(guān)系。將一張給定的圖像輸入給 CNN,解釋圖應(yīng)該輸出:(1)某節(jié)點(diǎn)是否被激活(2)某節(jié)點(diǎn)在特征圖中對(duì)應(yīng)部分的位置。由于解釋圖學(xué)習(xí)到了卷積編碼中的通用知識(shí),因此可以將卷積層中的知識(shí)遷移到其它任務(wù)中。
? ? ? ? ??
??
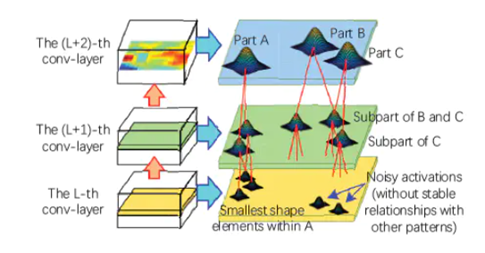
圖 21:解釋圖中各部分模式之間的空間關(guān)系和共同激活關(guān)系圖
?
解釋圖中各部分模式之間的空間關(guān)系和共同激活關(guān)系。高層模式將噪聲濾除并對(duì)低層模式進(jìn)行解耦。從另一個(gè)層面上來(lái)說(shuō),可以將低層模式是做高層模式的組成部分。
?
另外,張拳石[24]認(rèn)為在傳統(tǒng)的CNN中,一個(gè)高層過(guò)濾器可能會(huì)描述一個(gè)混合的模式,例如過(guò)濾器可能被貓的頭部和腿部同時(shí)激活。這種高卷積層的復(fù)雜表示會(huì)降低網(wǎng)絡(luò)的可解釋性。針對(duì)此類(lèi)問(wèn)題,作者將過(guò)濾器的激活與否交由某個(gè)部分控制,以達(dá)到更好的可解釋性,通過(guò)這種方式,可以明確的識(shí)別出CNN中哪些對(duì)象部分被記憶下來(lái)進(jìn)行分類(lèi),而不會(huì)產(chǎn)生歧義。
模型通過(guò)對(duì)高卷積層的每個(gè)filter計(jì)算loss,種loss降低了類(lèi)間激活的熵和神經(jīng)激活的空間分布的熵,每個(gè)filter必須編碼一個(gè)單獨(dú)的對(duì)象部分,并且過(guò)濾器必須由對(duì)象的單個(gè)部分來(lái)激活,而不是重復(fù)地出現(xiàn)在不同的對(duì)象區(qū)域。
? ? ? ?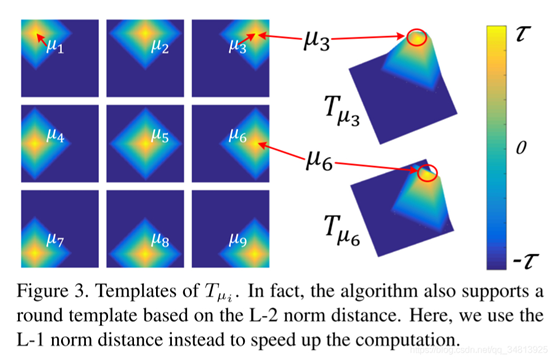
圖 22
Hinton的膠囊網(wǎng)絡(luò) [25],是當(dāng)年的又一里程碑式著作。作者通過(guò)對(duì)CNN的研究發(fā)現(xiàn)CNN存在以下問(wèn)題:1) CNN只關(guān)注要檢測(cè)的目標(biāo)是否存在,而不關(guān)注這些組件之間的位置和相對(duì)的空間關(guān)系;2) CNN對(duì)不具備旋轉(zhuǎn)不變性,學(xué)習(xí)不到3D空間信息;3)神經(jīng)網(wǎng)絡(luò)一般需要學(xué)習(xí)大量案例,訓(xùn)練成本高。為了解決這些問(wèn)題,作者提出了「膠囊網(wǎng)絡(luò)」,使網(wǎng)絡(luò)在減少訓(xùn)練成本的情況下,具備更好的表達(dá)能力和解釋能力。
?
「膠囊(Capsule)」可以表示為一組神經(jīng)元向量,用向量的長(zhǎng)度表示物體「存在概率」,再將其壓縮以保證屬性不變,用向量的方向表示物體的「屬性」,例如位置,大小,角度,形態(tài),速度,反光度,顏色,表面的質(zhì)感等。
和傳統(tǒng)的CNN相比,膠囊網(wǎng)絡(luò)的不同之處在于計(jì)算單位不同,傳統(tǒng)神經(jīng)網(wǎng)絡(luò)以單個(gè)神經(jīng)元作為單位,capsule以一組神經(jīng)元作為單位。相同之處在于,CNN中神經(jīng)元與神經(jīng)元之間的連接,capsNet中capsule與capsule之間的連接,都是通過(guò)對(duì)輸入進(jìn)行加權(quán)的方式操作。
膠囊網(wǎng)絡(luò)在計(jì)算的過(guò)程中主要分為四步:
輸入向量ui的W矩陣乘法;
輸入向量ui的標(biāo)量權(quán)重c;
加權(quán)輸入向量的總和;
向量到向量的非線(xiàn)性變換。
網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示,其中「ReLI Conv1」是常規(guī)卷積層;「PrimaryCaps」構(gòu)建了32個(gè)channel的capsules,得到6*6*8的輸出;「DigiCaps」對(duì)前面1152個(gè)capules進(jìn)行傳播與「routing」更新,輸入是1152個(gè)capsules,輸出是10個(gè)capules,表示10個(gè)數(shù)字類(lèi)別,最后用這10個(gè)capules去做分類(lèi)。
? ? ? ?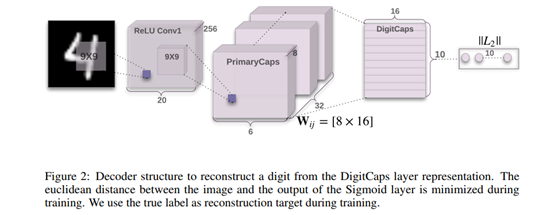
圖23:膠囊網(wǎng)絡(luò)網(wǎng)絡(luò)結(jié)構(gòu)示意圖
(3)生成解釋法
?
除了上文介紹的諸多方法外,在模型訓(xùn)練的同時(shí),可以設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)模型,令其產(chǎn)生能被人類(lèi)理解的證據(jù),生成解釋的過(guò)程也可被顯式地定義為模型訓(xùn)練的一部分。
?
Wagner 2019[26]首次實(shí)現(xiàn)了圖像級(jí)別的細(xì)粒度解釋。文中提出的「FGVis」,避免了圖像的可解釋方法中對(duì)抗證據(jù)的問(wèn)題,傳統(tǒng)方法采用添加正則項(xiàng)的方式緩解,但由于引入了超參,人為的控制導(dǎo)致無(wú)法生成更加可信的,細(xì)粒度的解釋。文中的FGVis方法基于提出的「對(duì)抗防御(Adversarial Defense)」方法,通過(guò)過(guò)濾可能導(dǎo)致對(duì)抗證據(jù)的樣本梯度,從而避免這個(gè)問(wèn)題。該方法并不基于任何模型或樣本,而是一種優(yōu)化方法,并單獨(dú)對(duì)生成解釋圖像中的每個(gè)像素優(yōu)化,從而得到細(xì)粒度的圖像解釋?zhuān)瑱z測(cè)示意圖如圖[24] 所示。
? ? ? ?
圖24:FGVis檢測(cè)結(jié)果示意圖
?
另一個(gè)視覺(jué)的例子來(lái)自Antol et. 的Vqa[27],文章將視覺(jué)問(wèn)題的「回答任務(wù)(Vqa)」定義為給定一個(gè)圖像和一個(gè)開(kāi)放式的、關(guān)于圖像的自然語(yǔ)言問(wèn)題,并提出了Vqa的「基準(zhǔn)」和「回答方法」,同時(shí)還開(kāi)發(fā)了一個(gè)兩通道的視覺(jué)圖像加語(yǔ)言問(wèn)題回答模型。
文章首先對(duì)Vqa任務(wù)所需的數(shù)據(jù)集進(jìn)行采集和分析,然后使用baselines為「基準(zhǔn)」對(duì)「方法」進(jìn)行評(píng)估,基準(zhǔn)滿(mǎn)足4個(gè)條件:1) 隨機(jī),2)答案先驗(yàn), 3)問(wèn)題先驗(yàn),4)最近鄰。
「方法」使用文中開(kāi)發(fā)的兩個(gè)視覺(jué)(圖像)通道加語(yǔ)言(問(wèn)題)通道通過(guò)多層感知機(jī)結(jié)合的模型,結(jié)構(gòu)圖如圖所示。視覺(jué)圖像通道利用 VGGNet最后一層隱藏層的激活作為 4096- dim 圖像嵌入,語(yǔ)言問(wèn)題通道使用三種方法嵌入:
構(gòu)建「詞袋問(wèn)題(BoW Q)」;
「LSTM Q 」具有一個(gè)隱藏層的lstm對(duì)1024維的問(wèn)題進(jìn)行嵌入;
「deeper LSTM Q」。最終使用softmax方法輸出K個(gè)可能的答案。
? ? ? ?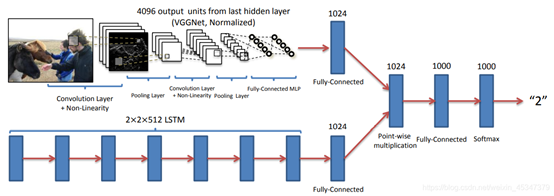
圖 25:deeper LSTM Q + norm I 結(jié)構(gòu)圖
?
三. 總結(jié)
為了使深度學(xué)習(xí)模型對(duì)用戶(hù)而言更加「透明」,研究人員近年來(lái)從「可解釋性」和「完整性」這兩個(gè)角度出發(fā),對(duì)深度學(xué)習(xí)模型得到預(yù)測(cè)、決策結(jié)果的工作原理和深度學(xué)習(xí)模型本身的內(nèi)部結(jié)構(gòu)和數(shù)學(xué)操作進(jìn)行了解釋。至今,可解釋性深度學(xué)習(xí)領(lǐng)域的研究人員在「網(wǎng)絡(luò)對(duì)于數(shù)據(jù)的處理過(guò)程」、「網(wǎng)絡(luò)對(duì)于數(shù)據(jù)的表征」,以及「如何構(gòu)建能夠生成自我解釋的深度學(xué)習(xí)系統(tǒng)」三個(gè)層次上均取得了可喜的進(jìn)展:
就網(wǎng)絡(luò)工作過(guò)程而言,研究人員通過(guò)設(shè)計(jì)線(xiàn)性代理模型、決策樹(shù)模型等于原始模型性能相當(dāng),但具有更強(qiáng)可解釋性的模型來(lái)解釋原始模型;此外,研究人員還開(kāi)發(fā)出了顯著性圖、CAM 等方法將于預(yù)測(cè)和決策最相關(guān)的原始數(shù)據(jù)與計(jì)算過(guò)程可視化,給出一種對(duì)深度學(xué)習(xí)模型的工作機(jī)制十分直觀(guān)的解釋。
就數(shù)據(jù)表征而言,現(xiàn)有的深度學(xué)習(xí)解釋方法涉及「基于層的解釋」、「基于神經(jīng)元的解釋」、「基于表征向量的解釋」三個(gè)研究方向,分別從網(wǎng)絡(luò)層的設(shè)計(jì)、網(wǎng)絡(luò)參數(shù)規(guī)模、神經(jīng)元的功能等方面探究了影響深度學(xué)習(xí)模型性能的重要因素。
就自我解釋的深度學(xué)習(xí)系統(tǒng)而言,目前研究者們從注意力機(jī)制、表征分離、解釋生成等方面展開(kāi)了研究,在「視覺(jué)-語(yǔ)言」多模態(tài)任務(wù)中實(shí)現(xiàn)了對(duì)模型工作機(jī)制的可視化,并且基于 InfoGAN、膠囊網(wǎng)絡(luò)等技術(shù)將對(duì)學(xué)習(xí)有不同影響表征分離開(kāi)來(lái),實(shí)現(xiàn)了對(duì)數(shù)據(jù)表征的細(xì)粒度控制。
?
然而,現(xiàn)有的對(duì)深度學(xué)習(xí)模型的解釋方法仍然存在諸多不足,面臨著以下重大的挑戰(zhàn):
現(xiàn)有的可解釋性研究往往針對(duì)「任務(wù)目標(biāo)」和「完整性」其中的一個(gè)方向展開(kāi),然而較少關(guān)注如何將不同的模型解釋技術(shù)合并起來(lái),構(gòu)建更為強(qiáng)大的模型揭示方法。
缺乏對(duì)于解釋方法的度量標(biāo)準(zhǔn),無(wú)法通過(guò)更加嚴(yán)謹(jǐn)?shù)姆绞胶饬繉?duì)模型的解釋結(jié)果。
現(xiàn)有的解釋方法往往針對(duì)單一模型,模型無(wú)關(guān)的解釋方法效果仍有待進(jìn)一步提升。
對(duì)無(wú)監(jiān)督、自監(jiān)督方法的解釋工作仍然存在巨大的探索空間。
推薦閱讀
[0]?Gilpin, Leilani H., et al. "Explaining explanations: An overview of interpretability of machine learning." 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA). IEEE, 2018.
[1] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. "'Why should I trust you?'?Explaining the predictions of any classifier."?Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016.
[2] Sato, Makoto, and Hiroshi Tsukimoto. "Rule extraction from neural networks via decision tree induction."?IJCNN'01. International Joint Conference on Neural Networks. Proceedings (Cat. No. 01CH37222). Vol. 3. IEEE, 2001.
[3] Zilke, Jan Ruben, Eneldo Loza Mencía, and Frederik Janssen. "Deepred–rule extraction from deep neural networks."?International Conference on Discovery Science. Springer, Cham, 2016.
[4] Schmitz, Gregor PJ, Chris Aldrich, and Francois S. Gouws. "ANN-DT: an algorithm for extraction of decision trees from artificial neural networks."?IEEE Transactions on Neural Networks?10.6 (1999): 1392-1401.
[5] Gallant, Stephen I. "Connectionist expert systems."?Communications of the ACM?31.2 (1988): 152-169.
[6] Tsukimoto, Hiroshi. "Extracting rules from trained neural networks."?IEEE Transactions on Neural networks?11.2 (2000): 377-389.
[7] Towell, Geoffrey G., and Jude W. Shavlik. "Extracting refined rules from knowledge-based neural networks."?Machine learning?13.1 (1993): 71-101.
[8] Zeiler, Matthew D., and Rob Fergus. "Visualizing and understanding convolutional networks."?European conference on computer vision. Springer, Cham, 2014.
[9] Ancona, Marco, et al. "Towards better understanding of gradient-based attribution methods for deep neural networks."?arXiv preprint arXiv:1711.06104?(2017).
[10] Bach, Sebastian, et al. "On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation."?PloS one?10.7 (2015): e0130140.
[11] Shrikumar, Avanti, Peyton Greenside, and Anshul Kundaje. "Learning important features through propagating activation differences."?arXiv preprint arXiv:1704.02685?(2017).
[12] Kim, Been, et al. "Tcav: Relative concept importance testing with linear concept activation vectors." (2018).
[13] Yosinski, Jason, et al. "How transferable are features in deep neural networks?."?Advances in neural information processing systems. 2014.
[14] Simonyan, Karen, Andrea Vedaldi, and Andrew Zisserman. "Deep inside convolutional networks: Visualising image classification models and saliency maps."?arXiv preprint arXiv:1312.6034?(2013).
[15] Neyshabur, Behnam, Hanie Sedghi, and Chiyuan Zhang. "What is being transferred in transfer learning?."?Advances in Neural Information Processing Systems?33 (2020).
[16] Zhou, Bolei, et al. "Object detectors emerge in deep scene cnns."?arXiv preprint arXiv:1412.6856?(2014).
[17] Bau, David, et al. "Network dissection: Quantifying interpretability of deep visual representations."?Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[18] Frankle, Jonathan, and Michael Carbin. "The lottery ticket hypothesis: Training pruned neural networks."?arXiv preprint arXiv:1803.03635?2 (2018).
[19] Zhang, Quan-shi, and Song-Chun Zhu. "Visual interpretability for deep learning: a survey."?Frontiers of Information Technology & Electronic Engineering?19.1 (2018): 27-39.
[20] Huk Park, Dong, et al. "Multimodal explanations: Justifying decisions and pointing to the evidence."?Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[21] Xiao, Tianjun, et al. "The application of two-level attention models in deep convolutional neural network for fine-grained image classification."?Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[22] Chen, Xi, et al. "Infogan: Interpretable representation learning by information maximizing generative adversarial nets."?Advances in neural information processing systems. 2016.
[23] Zhang, Quanshi, et al. "Interpreting cnn knowledge via an explanatory graph."?arXiv preprint arXiv:1708.01785?(2017).
[24] Zhang, Quanshi, Ying Nian Wu, and Song-Chun Zhu. "Interpretable convolutional neural networks."?Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[25] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules."?Advances in neural information processing systems. 2017.
[26] Wagner, Jorg, et al. "Interpretable and fine-grained visual explanations for convolutional neural networks."?Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
[27] Antol, Stanislaw, et al. "Vqa: Visual question answering."?Proceedings of the IEEE international conference on computer vision. 2015.
? ? ??