
ICCV 2023 | 圖像分割類擴散模型diffusion的 8 篇論文
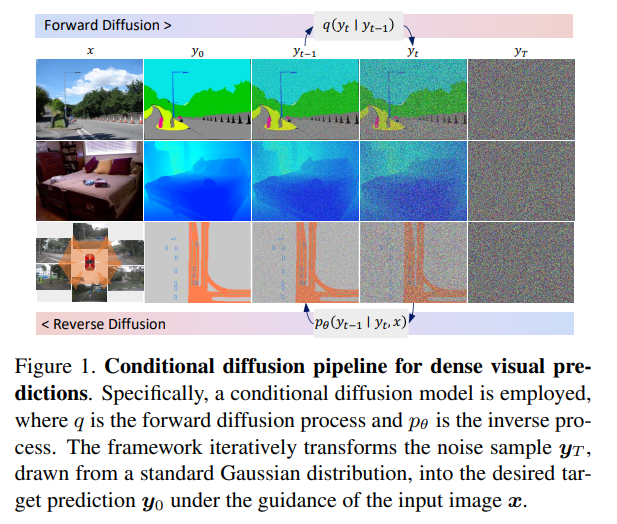
提出一種簡單、高效但功能強大的基于條件擴散流程(density visual predictions)的框架。方法采用“噪聲到分割圖”(noise-to-map)的生成范式進行預(yù)測,通過逐步從隨機高斯分布中去除噪聲來引導(dǎo)圖像生成。這種方法稱為DDP,無需特定于任務(wù)的設(shè)計和架構(gòu)定制,易于推廣到大多數(shù)密集預(yù)測任務(wù),例如語義分割和深度估計。
DDP在六個不同的基準任務(wù)上展示了三個代表性任務(wù)的頂級結(jié)果。例如,語義分割在Cityscapes上的mIoU達到83.9,BEV地圖分割在nuScenes上的mIoU達到70.6,深度估計在KITTI上的REL達到0.05。https://github.com/JiYuanFeng/DDP
2、Unleashing Text-to-Image Diffusion Models for Visual Perception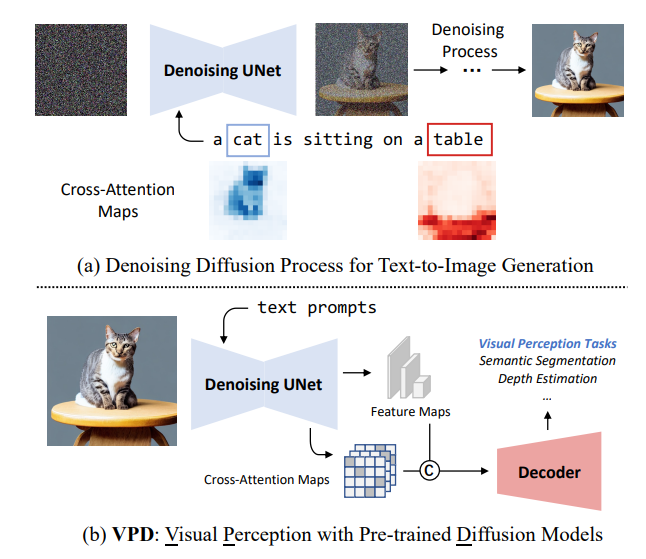
本文提出VPD(視覺感知與預(yù)訓(xùn)練的擴散模型),利用預(yù)訓(xùn)練的文本到圖像擴散模型,在視覺感知任務(wù)中利用語義信息。不使用擴散預(yù)訓(xùn)練去噪自編碼器,而將其簡單地用作主干,并旨在研究如何充分利用所學(xué)知識。
用適當?shù)奈谋据斎胩崾救ピ虢獯a器,并通過適配器改進文本特征,從而更好地與預(yù)訓(xùn)練階段對齊,并使視覺內(nèi)容與文本提示進行交互。還提出利用視覺特征和文本特征之間的交叉注意力圖來提供明確的引導(dǎo)。與其他預(yù)訓(xùn)練方法相比,展示了利用視覺語言預(yù)訓(xùn)練的擴散模型可以更快地適應(yīng)基于視覺感知任務(wù)的提出的VPD的有效性。
對語義分割、引用圖像分割和深度估計的廣泛實驗證明了方法的有效性。值得注意的是,VPD在NYUv2深度估計上達到了0.254的RMSE和RefCOCO-val引用圖像分割上的73.3%的oIoU,創(chuàng)造了這兩個基準的新紀錄。已開源在:https://github.com/wl-zhao/VPD
3、Open-vocabulary Object Segmentation with Diffusion Models 本文的目標是從預(yù)訓(xùn)練文本到圖像擴散模型中提取視覺語言對應(yīng)關(guān)系,以分割圖的形式,即同時生成圖像和分割掩模,描述文本提示中相應(yīng)的視覺實體。
本文的目標是從預(yù)訓(xùn)練文本到圖像擴散模型中提取視覺語言對應(yīng)關(guān)系,以分割圖的形式,即同時生成圖像和分割掩模,描述文本提示中相應(yīng)的視覺實體。
(i)將現(xiàn)有的擴散模型與一種新的基于定位的模塊配對,只需要少量目標類別的訓(xùn)練可以使擴散模型的視覺和文本嵌入空間對齊;(ii)建立一個自動的流水線來構(gòu)建數(shù)據(jù)集,其中包含{圖像、分割掩模、文本提示}三元組,以訓(xùn)練所提出的定位模塊;(iii)評估從文本到圖像擴散模型生成的圖像上的開放詞匯定位的性能,并展示了該模塊可以很好地對訓(xùn)練時已見過的類別之外的類別的對象進行分割;(iv)采用增強的擴散模型構(gòu)建了一個合成的語義分割數(shù)據(jù)集,并展示了在這樣的數(shù)據(jù)集上訓(xùn)練標準分割模型在零樣本分割(ZS3)基準測試中表現(xiàn)出有競爭力的性能,為采用強大的擴散模型用于判別任務(wù)開辟了新的機會。
已開源在:https://github.com/Lipurple/Grounded-Diffusion
4、Diffusion Action Segmentation
時間動作分割對于理解長事件視頻至關(guān)重要。以往針對這個任務(wù)的作品通常采用迭代細化范式,使用多階段模型。本文提出一種通過去噪擴散模型的新框架,然而它與這種迭代優(yōu)化的本質(zhì)精神是相同的。
根據(jù)輸入視頻特征,動作預(yù)測是從隨機噪聲中迭代生成。為增強對人類動作的三個顯著特征建模,包括位置先驗、邊界模糊度和關(guān)系依賴性,為條件輸入設(shè)計了統(tǒng)一的遮罩策略。對GTEA、50Salads和Breakfast三個基準數(shù)據(jù)集進行大量實驗,方法在性能上達到了優(yōu)于或與最先進方法可比的結(jié)果,顯示了采用生成方法進行動作分割的有效性。已開源在:https://github.com/Finspire13/DiffAct
5、LD-ZNet: A Latent Diffusion Approach for Text-Based Image Segmentation
大規(guī)模的預(yù)訓(xùn)練任務(wù),如圖像分類、描述生成或自監(jiān)督技術(shù),并不鼓勵學(xué)習(xí)對象的語義邊界。然而,使用基于文本的潛在擴散技術(shù)構(gòu)建的最新生成基礎(chǔ)模型可能會學(xué)習(xí)語義邊界。這是因為它們必須基于文本描述綜合生成圖像中所有對象的細節(jié)。因此,提出一種在互聯(lián)網(wǎng)規(guī)模數(shù)據(jù)集上訓(xùn)練的潛在擴散模型(LDMs)來對實際圖像和AI生成圖像進行分割的技術(shù)。
首先表明LDMs的潛在空間(z空間)作為輸入表示相對于其他特征表示如RGB圖像或CLIP編碼而言更好用于基于文本的圖像分割。通過在潛在z空間上訓(xùn)練分割模型,該模型在各種形式的藝術(shù)、卡通、插圖和照片等不同領(lǐng)域之間創(chuàng)建了壓縮表示,也能夠彌合實際圖像和AI生成圖像之間的領(lǐng)域差距。
展示了LDMs的內(nèi)部特征包含豐富的語義信息,并提出LD-ZNet,進一步提高基于文本的分割的性能。總體而言,在自然圖像的文本到圖像分割上顯示了超過標準基線的6%改進。對于AI生成的圖像,與最先進技術(shù)相比,接近20%改進。已開源在:https://github.com/koutilya-pnvr/LD-ZNet
6、Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation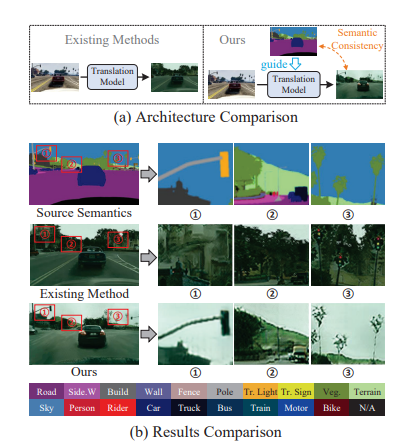
將圖像從源域轉(zhuǎn)換到目標域以學(xué)習(xí)目標模型是域自適應(yīng)語義分割(DASS)中最常見的策略之一。然而,現(xiàn)有方法仍然很難在原始圖像和轉(zhuǎn)換后的圖像之間保持語義一致的局部細節(jié)。
這項工作提出一種新方法,通過使用源域標簽作為顯式引導(dǎo)來進行圖像轉(zhuǎn)換,以解決這個挑戰(zhàn)。具體而言,將跨域圖像轉(zhuǎn)換形式化為去噪擴散過程,并利用一種新穎的語義梯度引導(dǎo)(SGG)方法來約束轉(zhuǎn)換過程,將其作為像素級源標簽的條件。此外,設(shè)計漸進式轉(zhuǎn)換學(xué)習(xí)(PTL)策略,使SGG方法能夠在具有較大差距的域之間可靠地工作。廣泛實驗證明了方法優(yōu)越性。
7、DiffuMask: Synthesizing Images with Pixel-level Annotations for Semantic Segmentation Using Diffusion Models
收集和標注像素級標簽的圖像耗時且費力。相比下,用生成模型(例如DALL-E、Stable Diffusion)可自由生成數(shù)據(jù)。本文展示通過Off-the-shelf Stable Diffusion模型生成,自動獲取準確的語義掩膜,該模型在訓(xùn)練過程中僅用文本-圖像對。
方法稱為DiffuMask,利用文本和圖像之間的交叉注意力圖的潛力,將文本驅(qū)動的圖像合成擴展到語義掩膜生成中。DiffuMask利用文本引導(dǎo)的交叉注意力信息來定位類別/詞特定的區(qū)域,結(jié)合實用技術(shù)創(chuàng)建一個新的高分辨率和類別區(qū)分的像素級掩膜。這些方法有助于顯著降低數(shù)據(jù)收集和標注成本。實驗表明,使用DiffuMask的合成數(shù)據(jù)訓(xùn)練的現(xiàn)有分割方法在與真實數(shù)據(jù)(VOC 2012、Cityscapes)相比的性能上取得了競爭力。對于某些類別(例如鳥類),DiffuMask呈現(xiàn)出有希望的性能,接近真實數(shù)據(jù)的最新結(jié)果(mIoU誤差在3%以內(nèi))。
此外,在開放式詞匯分割(零點)設(shè)置中,DiffuMask在VOC 2012的未見類別上取得了新的最新結(jié)果。已開源在:https://weijiawu.github.io/DiffusionMask/
8、Stochastic Segmentation with Conditional Categorical Diffusion Models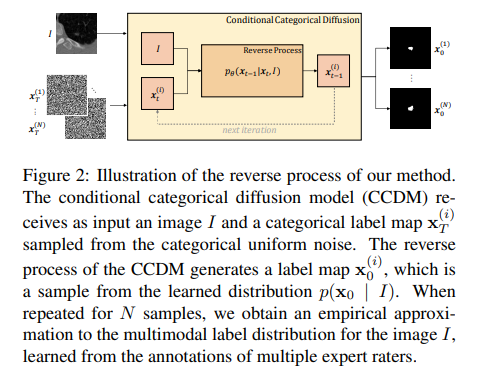
近年來深度神經(jīng)網(wǎng)絡(luò)發(fā)展,語義分割取得重大進展,但對于醫(yī)學(xué)診斷和自動駕駛等安全關(guān)鍵領(lǐng)域而言,生成與圖像內(nèi)容精確匹配的單一分割輸出可能并不合適。相反,可能需要多個正確的分割圖來反映標注圖的真實分布。在這種情況下,隨機語義分割方法必須學(xué)習(xí)預(yù)測在給定圖像的條件下標簽的條件分布,但是由于通常是多模態(tài)分布、高維輸出空間和有限的標注數(shù)據(jù),這是一項具有挑戰(zhàn)性的任務(wù)。
為解決這些挑戰(zhàn),提出一種基于去噪擴散概率模型的條件分類擴散模型(CCDM),用于語義分割。模型以輸入圖像為條件,能夠生成多個分割標簽圖,考慮到由不同的真實標注產(chǎn)生的aleatoric不確定性。實驗結(jié)果表明,CCDM在LIDC(一種隨機語義分割數(shù)據(jù)集)上取得了最新的最佳性能,并在經(jīng)典分割數(shù)據(jù)集Cityscapes上優(yōu)于已經(jīng)建立的基線。
關(guān)注公眾號【機器學(xué)習(xí)與AI生成創(chuàng)作】,更多精彩等你來讀
不是一杯奶茶喝不起,而是我T M直接用來跟進 AIGC+CV視覺 前沿技術(shù),它不香?!
臥剿,6萬字!30個方向130篇!CVPR 2023 最全 AIGC 論文!一口氣讀完
深入淺出stable diffusion:AI作畫技術(shù)背后的潛在擴散模型論文解讀
深入淺出ControlNet,一種可控生成的AIGC繪畫生成算法!
 戳我,查看GAN的系列專輯~! 最新最全100篇匯總!生成擴散模型Diffusion Models ECCV2022 | 生成對抗網(wǎng)絡(luò)GAN部分論文匯總
戳我,查看GAN的系列專輯~! 最新最全100篇匯總!生成擴散模型Diffusion Models ECCV2022 | 生成對抗網(wǎng)絡(luò)GAN部分論文匯總 CVPR 2022 | 25+方向、最新50篇GAN論文
ICCV 2021 | 35個主題GAN論文匯總
超110篇!CVPR 2021最全GAN論文梳理
超100篇!CVPR 2020最全GAN論文梳理
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實戰(zhàn)》
附下載 |《計算機視覺中的數(shù)學(xué)方法》分享
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》
《禮記·學(xué)記》有云:獨學(xué)而無友,則孤陋而寡聞
點擊 跟進 AIGC+CV視覺 前沿技術(shù),真香! ,加入 AI生成創(chuàng)作與計算機視覺 知識星球!