SSD目標檢測算法必須知道的幾個關鍵點
?上期一起學了
?SSD算法的框架流程,如下:
目標檢測算法SSD結構詳解
今天我們一起學下成功訓練SSD算法的一些注意點:
Loss計算 Match策略 數(shù)據(jù)增強 性能分析
Loss計算
SSD算法的目標函數(shù)分兩部分:計算相應的預選框與目標類別的confidence loss以及相應的位置回歸。如下公式:
其中N是match到Ground Truth的預選框數(shù)量(具體的match策略下面講),參數(shù)用于調(diào)整confidence loss和location loss之間的比例,默認.
其中confidence loss具體如下:
其中i表示第i個預選框,j表示第j個真實框,p表示第p個類別。其中表示第i個預選框是否匹配到了第j個類別為p的真實框,匹配到就為1,否則為0。
而我們在最小化上面代價函數(shù)的時候,就是將逼近于1的過程。而對于location loss,如下:
其實,位置回歸的loss是跟前面學的Faster RCNN中位置回歸損失是一樣,不在贅述,如下:
目標檢測算法Faster RCNN的損失函數(shù)以及如何訓練?
其中,
g:ground truth boxl:predicted boxd:prior boxw:widthh:heigth
Match策略
在訓練時,ground truth boxes與prior boxes按照如下方式進行配對:首先,尋找與每一個ground truth box有最大交并比(IoU)的prior box,這樣就能保證每一個真實標注框與至少會有一個預選框與之對應,之后又將剩余還沒有配對到的預選框與任意一個真實標注框嘗試配對,只要兩者之間的IoU大于閾值,則認為match上了。顯然在訓練的時候,配對到真實標注框的預選框就是正樣本,而沒有配對上的則為負樣本。如下圖: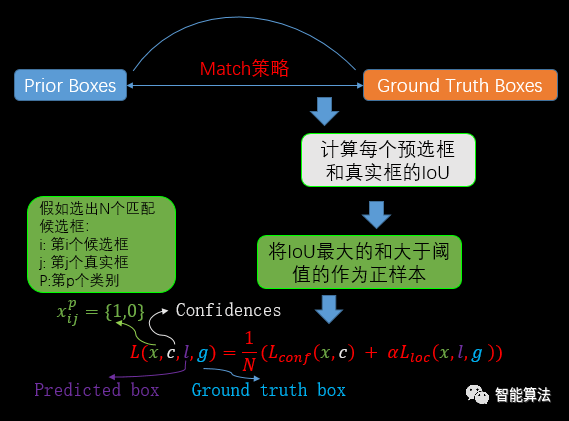 在進行
在進行match的時候,首先計算每個預選框和真實框的IoU,將IoU最大的預選框和大于閾值的預選框作為正樣本,其余的作為負樣本進行分類器訓練。其中公式中的x表示預選框信息,c為置信度,l為預測框,g為真實標注。
數(shù)據(jù)增強
值得注意的是,一般情況下負樣本預選框的數(shù)量是遠遠大于正樣本預選框的數(shù)量,如果直接進行訓練的話,會導致網(wǎng)絡過于重視負樣本,從而導致loss不穩(wěn)定。所以SSD在抽樣時按照置信度誤差(預測背景的置信度越小,誤差越大)進行降序排列,選取誤差較大的top-k作為訓練的負樣本,控制正負樣本比例為1:3,這樣可以導致模型更快的優(yōu)化和更穩(wěn)定的訓練。
另外為了使模型對于各種輸入對象大小和形狀更加魯棒,每個訓練圖像通過以下選項之一進行隨機采樣:
使用整個原始輸入圖像 采樣一個區(qū)域,使得采樣區(qū)域和原始圖片最小的交并比重疊為 0.1,0.3,0.5,0.7或0.9.隨機采樣一個區(qū)域
每個采樣區(qū)域的大小為原始圖像大小的[0.1,1],長寬比在1/2和2之間。如果真實標簽框中心在采樣區(qū)域內(nèi),則保留兩者重疊部分作為新圖片的真實標注。在上述采樣步驟之后,將每個采樣區(qū)域大小調(diào)整為固定大小,并以0.5的概率水平翻轉。如下圖: 上圖左圖為輸入圖片及真實標注,右側的
上圖左圖為輸入圖片及真實標注,右側的a,b,c,d為隨機采樣得到的4張圖片及標注。
性能分析
SSD算法和我們前面學的Faster RCNN以及后面要學的YOLO的性能對比如下表: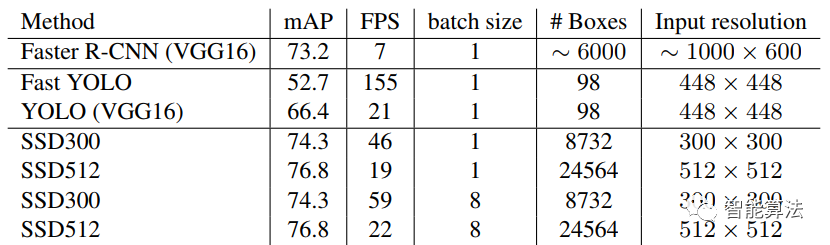 從上表中可以看到
從上表中可以看到SSD算法相比Faster RCNN和YOLO都有較高的mAP,FPS也比Faster RCNN高。而由于SSD512輸入圖片比300大,所以SSD512相對于SSD300有更好的mAP。
SSD缺點
需要人工設置預選框的 min-size,max_size和aspect_ratio值。網(wǎng)絡中預選框的基礎大小和形狀需要手工設置。而網(wǎng)絡中每一層feature使用的預選框大小和形狀不一樣,導致調(diào)試過程非常依賴經(jīng)驗。雖然采用了特征金字塔的思路,但是對小目標的識別效果依然一般,可能是因為 SSD使用了VGG16中的conv4_3低級feature去檢測小目標,而低級特征卷積層數(shù)少,存在特征提取不充分的問題。
至此結果上期,我們基本上了解了SSD算法的大致原理,下期,我們一起看下另一個牛哄哄的檢測算法YOLO,一起加油!