
Flink 和 Pulsar 的批流融合
Apache Pulsar 是什么
Pulsar 的數(shù)據(jù)視圖
Pulsar 與 Flink 的批流融合
Pulsar 現(xiàn)有能力和進展
Apache Pulsar 相對比較新,它于 2017 年加入 Apache 軟件基金會,2018 年才從 Apache 軟件基金會畢業(yè)并成為一個頂級項目。Pulsar 由于原生采用了存儲計算分離的架構(gòu),并且有專門為消息和流設(shè)計的存儲引擎 BookKeeper,結(jié)合 Pulsar 本身的企業(yè)級特性,得到了越來越多開發(fā)者的關(guān)注。
一、Apache Pulsar 是什么
下圖是屬于消息領(lǐng)域的開源工具,從事消息或者基礎(chǔ)設(shè)施的開發(fā)者對這些一定不會陌生。雖然 Pulsar 在 2012 年開始開發(fā),直到 2016 年才開源,但它在跟大家見面之前已經(jīng)在雅虎的線上運行了很長時間。這也是為什么它一開源就得到了很多開發(fā)者關(guān)注的原因,它已經(jīng)是一個經(jīng)過線上檢驗的系統(tǒng)。

Pulsar 跟其他消息系統(tǒng)最根本的不同在于兩個方面:
一方面,Pulsar 采用存儲計算分離的云原生架構(gòu);
另一方面,Pulsar 有專門為消息而設(shè)計的存儲引擎,Apache BookKeeper。
架構(gòu)
下圖展示了 Pulsar 存儲計算分離的架構(gòu):
首先在計算層,Pulsar Broker 不保存任何狀態(tài)數(shù)據(jù)、不做任何數(shù)據(jù)存儲,我們也稱之為服務(wù)層。
其次,Pulsar 擁有一個專門為消息和流設(shè)計的存儲引擎 BookKeeper,我們也稱之為數(shù)據(jù)層。
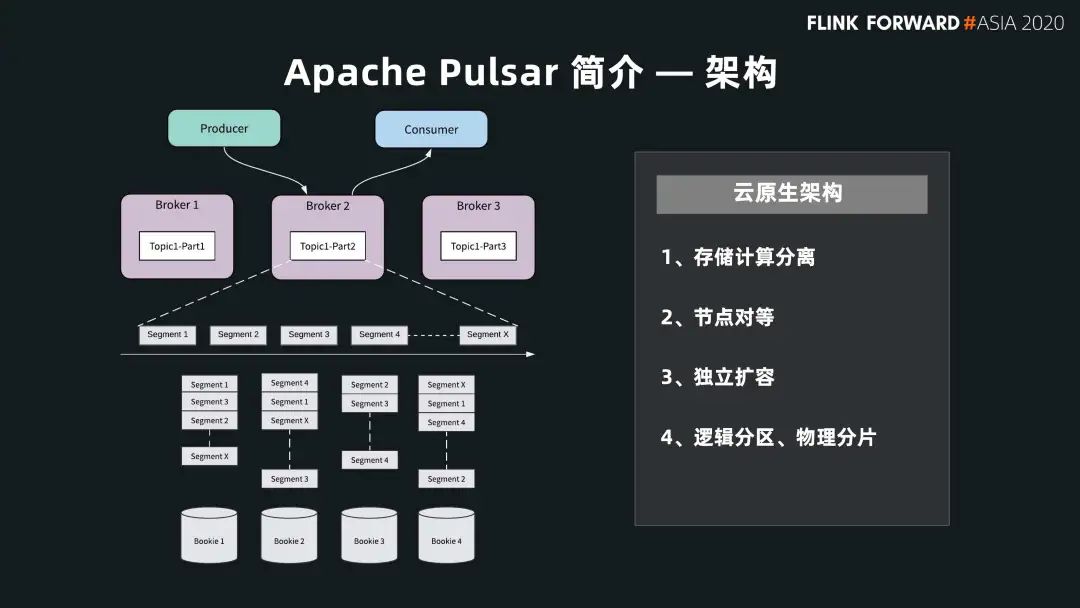
這個分層的架構(gòu)對用戶的集群擴展十分方便:
如果想要支持更多的 Producer 和 Consumer,可以擴充上面無狀態(tài)的 Broker 層;
如果要做更多的數(shù)據(jù)存儲,可以單獨擴充底層存儲層。
這個云原生的架構(gòu)有兩個主要特點:
第一個是存儲計算的分離;
另外一個特點是每一層都是一個節(jié)點對等的架構(gòu)。
從節(jié)點對等來說,Broker 層不存儲數(shù)據(jù),所以很容易實現(xiàn)節(jié)點對等。但是 Pulsar 在底層的存儲也是節(jié)點對等狀態(tài):在存儲層,BookKeeper 沒有采用 master/slave 這種主從同步的方式,而是通過 Quorum 的方式。
如果是要保持多個數(shù)據(jù)備份,用戶通過一個 broker 并發(fā)地寫三個存儲節(jié)點,每一份數(shù)據(jù)都是一個對等狀態(tài),這樣在底層的節(jié)點也是一個對等的狀態(tài),用戶要做底層節(jié)點的擴容和管理就會很容易。有這樣節(jié)點對等的基礎(chǔ),會給用戶帶來很大的云原生的便捷,方便用戶在每一層單獨擴容,也會提高用戶的線上系統(tǒng)的可用性和維護性。
同時,這種分層的架構(gòu)為我們在 Flink 做批流融合打好了基礎(chǔ)。因為它原生分成了兩層,可以根據(jù)用戶的使用場景和批流的不同訪問模式,來提供兩套不同的 API。
如果是實時數(shù)據(jù)的訪問,可以通過上層 Broker 提供的 Consumer 接口;
如果是歷史數(shù)據(jù)的訪問,可以跳過 Broker,用存儲層的 reader 接口,直接訪問底層存儲層。
存儲 BookKeeper
Pulsar 另一個優(yōu)勢是有專門為流和消息設(shè)計的存儲引擎 Apache BookKeeper。它是一個簡單的 write-ahead-log 抽象。Log 抽象和流的抽象類似,所有的數(shù)據(jù)都是源源不斷地從尾部直接追加。
它給用戶帶來的好處就是寫入模式比較簡單,可以帶來比較高的吞吐。在一致性方面,BookKeeper 結(jié)合了 PAXOS 和 ZooKeeper ZAB 這兩種協(xié)議。BookKeeper 暴露給大家的就是一個 log 抽象。你可以簡單認為它的一致性很高,可以實現(xiàn)類似 Raft 的 log 層存儲。BookKeeper 的誕生是為了服務(wù)我們在 HDFS naming node 的 HA,這種場景對一致性要求特別高。這也是為什么在很多關(guān)鍵性的場景里,大家會選擇 Pulsar 和 BookKeeper 做存儲的原因。
BookKeeper 的設(shè)計中,有專門的讀寫隔離,簡單理解就是,讀和寫是發(fā)生在不同的磁盤。這樣的好處是在批流融合的場景可以減少與歷史數(shù)據(jù)讀取的相互干擾,很多時候用戶讀最新的實時數(shù)據(jù)時,不可避免會讀到歷史數(shù)據(jù),如果有一個專門為歷史數(shù)據(jù)而準(zhǔn)備的單獨的磁盤,歷史數(shù)據(jù)和實時數(shù)據(jù)的讀寫不會有 IO 的爭搶,會對批流融合的 IO 服務(wù)帶來更好的體驗。

應(yīng)用場景
Pulsar 場景應(yīng)用廣泛。下面是 Pulsar 常見的幾種應(yīng)用場景:
第一,因為 Pulsar 有 BookKeeper,數(shù)據(jù)一致性特別高,Pulsar 可以用在計費平臺、支付平臺和交易系統(tǒng)等,對數(shù)據(jù)服務(wù)質(zhì)量,一致性和可用性要求很高的場景。
第二種應(yīng)用場景是 Worker Queue / Push Notifications / Task Queue,主要是為了實現(xiàn)系統(tǒng)之間的相互解耦。
第三種場景,與 Pulsar 對消息和隊列兩種場景的支持比較相關(guān)。Pulsar 支持 Queue 消費模式,也支持 Kafka 高帶寬的消費模型。后面我會專門講解 Queue 消費模型與 Flink 結(jié)合的優(yōu)勢。
第四個場景是 IoT 應(yīng)用,因為 Pulsar 在服務(wù)端有 MQTT 協(xié)議的解析,以及輕量級的計算 Pulsar Functions。
第五個方面是 unified data processing,把 Pulsar 作為一個批流融合的存儲的基礎(chǔ)。
我們在 2020 年 11 月底的 Pulsar Summit 亞洲峰會,邀請 40 多位講師來分享他們的 Pulsar 落地案例。如果大家對 Pulsar 應(yīng)用場景比較感興趣,可以關(guān)注 B 站上 StreamNative 的賬號,觀看相關(guān)視頻。
二、Pulsar 的數(shù)據(jù)視圖
在這些應(yīng)用場景中,Unified Data Processing 尤為重要。關(guān)于批流融合,很多國內(nèi)用戶的第一反應(yīng)是選擇 Flink。我們來看 Pulsar 和 Flink 結(jié)合有什么樣的優(yōu)勢?為什么用戶會選擇 Pulsar 和 Flink 做批流融合。
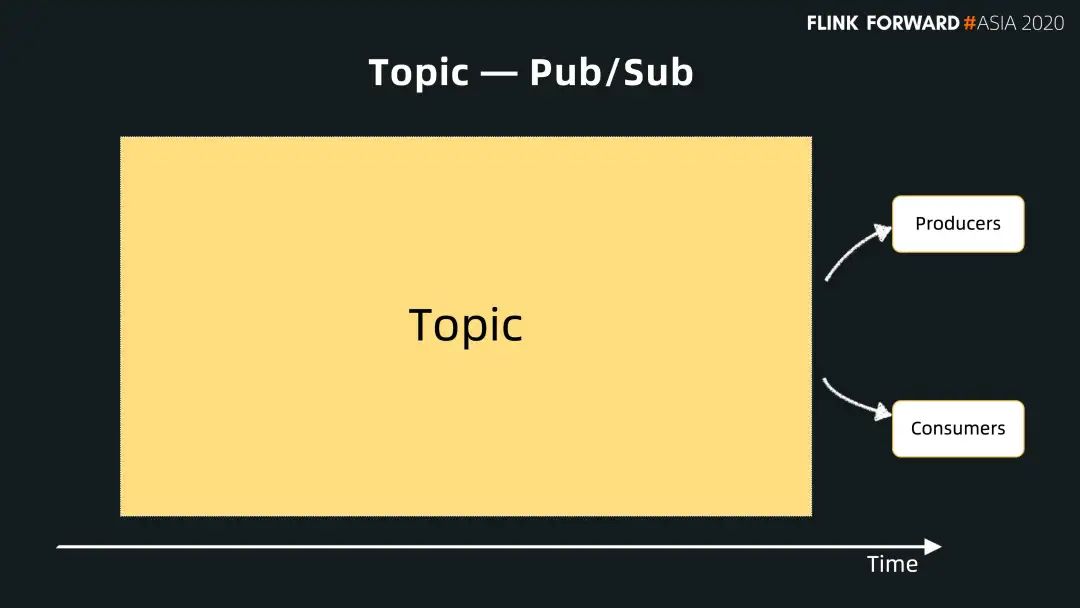
首先,我們先從 Pulsar 的數(shù)據(jù)視圖來展開。跟其他的消息系統(tǒng)一樣,Pulsar 也是以消息為主體,以 Topic 為中心。所有的數(shù)據(jù)都是 producer 交給 topic,然后 consumer 從 topic 訂閱消費消息。
Partition 分區(qū)
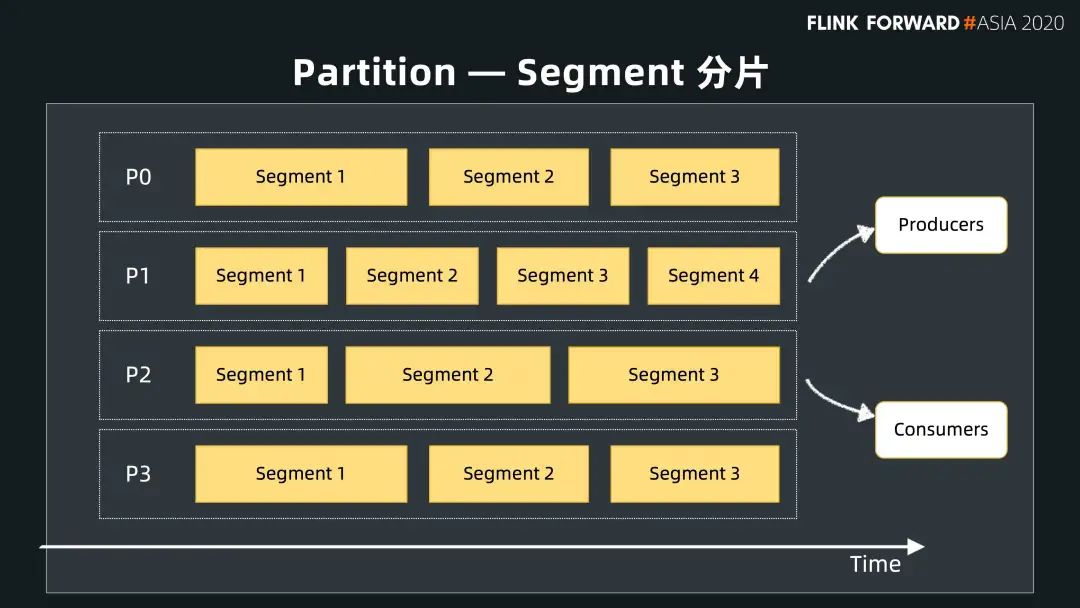
為了方便擴展,Pulsar 在 topic 內(nèi)部也有分區(qū)的概念,這跟很多消息系統(tǒng)都類似。上面提到 Pulsar 是一個分層的架構(gòu),它采用分區(qū)把 topic 暴露給用戶,但是在內(nèi)部,實際上每一個分區(qū)又可以按照用戶指定的時間或者大小切成一個分片。一個 Topic 最開始創(chuàng)建的時候只有一個 active 分片,隨著用戶指定的時間到達以后,會再切一個新的分片。在新開一個分片的過程中,存儲層可以根據(jù)各個節(jié)點的容量,選擇容量最多的節(jié)點來存儲這個新的分片。
這樣的好處是,topic 的每一個分片都會均勻地散布在存儲層的各個節(jié)點上,實現(xiàn)數(shù)據(jù)存儲的均衡。如果用戶愿意,就可以用整個存儲集群來存儲分區(qū),不再被單個節(jié)點容量所限制。如下圖所示,該 Topic 有 4 個分區(qū),每一個分區(qū)被拆成多個分片,用戶可以按照時間(比如 10 分鐘或者一個小時),也可以按照大小(比如 1G 或者 2G)切一個分片。分片本身有順序性,按照 ID 逐漸遞增,分片內(nèi)部所有消息按照 ID 單調(diào)遞增,這樣很容易保證順序性。
Stream 流存儲
我們再從單個分片來看一下,在常見流(stream)數(shù)據(jù)處理的概念。用戶所有的數(shù)據(jù)都是從流的尾部不斷追加,跟流的概念相似,Pulsar 中 Topic 的新數(shù)據(jù)不斷的添加在 Topic 的最尾部。不同的是,Pulsar 的 Topic 抽象提供了一些優(yōu)勢:
首先,它采用了存儲和計算分離的架構(gòu)。在計算層,它更多的是一個消息服務(wù)層,可以快速地通過 consumer 接口,把最新的數(shù)據(jù)返回給用戶,用戶可以實時的獲取最新的數(shù)據(jù);
另外一個好處是,它分成多個分片,如果用戶指定時間,從元數(shù)據(jù)可以找到對應(yīng)的分片,用戶可以繞過實時的流直接讀取存儲層的分片;
還有一個優(yōu)勢是,Pulsar 可以提供無限的流存儲。
做基礎(chǔ)設(shè)施的同學(xué),如果看到按照時間分片的架構(gòu),很容易想到把老的分片搬到二級存儲里面去,在 Pulsar 里也是這樣做的。用戶可以根據(jù) topic 的消費熱度,設(shè)置把老的,或者超過時限或大小的數(shù)據(jù)自動搬到二級存儲中。用戶可以選擇使用 Google,微軟的 Azure 或者 AWS 來存儲老的分片,同時也支持 HDFS 存儲。
這樣的好處是:對最新的數(shù)據(jù)可以通過 BookKeeper 做快速返回,對于老的冷數(shù)據(jù)可以利用網(wǎng)絡(luò)存儲云資源做一個無限的流存儲。這就是 Pulsar 可以支持無限流存儲的原因,也是批流融合的一個基礎(chǔ)。
總體來說,Pulsar 通過存儲計算分離,為大家提供了實時數(shù)據(jù)和歷史數(shù)據(jù)兩套不同的訪問接口。用戶可以依據(jù)內(nèi)部不同的分片位置,根據(jù) metadata 來選擇使用哪種接口來訪問數(shù)據(jù)。同時根據(jù)分片機制可以把老的分片放到二級存儲中,這樣可以支撐無限的流存儲。
Pulsar 的統(tǒng)一體現(xiàn)在對分片元數(shù)據(jù)管理的方面。每個分片可以按照時間存放成不同的存儲介質(zhì)或格式,但 Pulsar 通過對每個分片的 metadata 管理,來對外提供一個分區(qū)的邏輯概念。在訪問分區(qū)中的一個分片的時候我可以拿到它的元數(shù)據(jù),知道它的在分區(qū)中的順序,數(shù)據(jù)的存放位置和保存類型 Pulsar 對每一個分片的 metadata 的管理,提供了統(tǒng)一的 topic 的抽象。
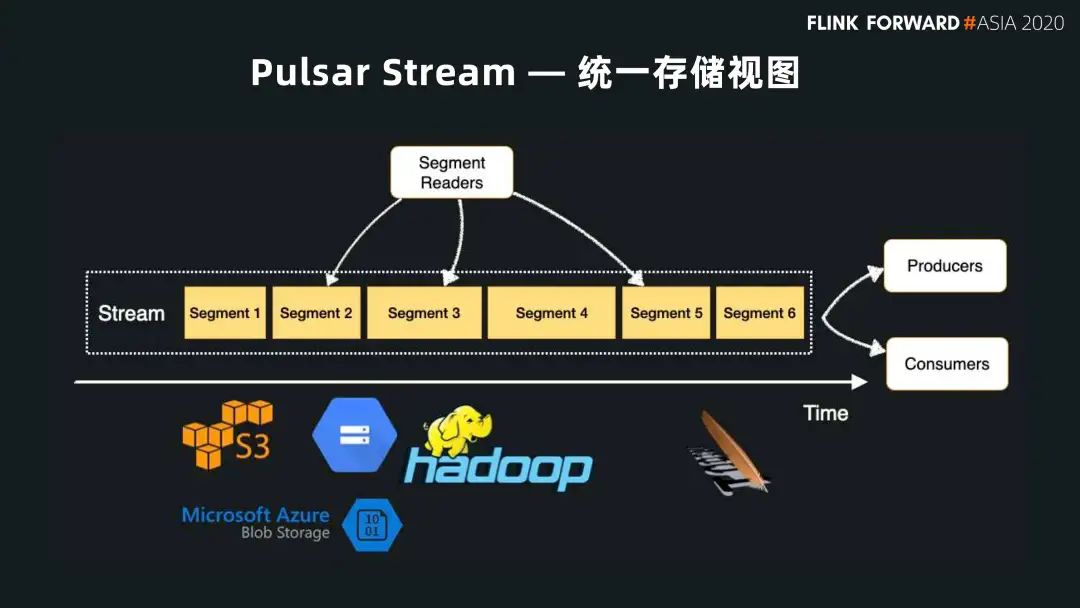
三、Pulsar 和 Flink 的批流融合
在 Flink 中,流是一個基礎(chǔ)的概念,Pulsar 可以作為流的載體來存儲數(shù)據(jù)。如果用戶做一個批的計算,可以認為它是一個有界的流。對 Pulsar 來說,這就是一個 Topic 有界范圍內(nèi)的分片。
在圖中我們可以看到,topic 有很多的分片,如果確定了起止的時間,用戶就可以根據(jù)這個時間來確定要讀取的分片范圍。對實時的數(shù)據(jù),對應(yīng)的是一個連續(xù)的查詢或訪問。對 Pulsar 的場景來說就是不停的去消費 Topic 的尾部數(shù)據(jù)。這樣,Pulsar 的 Topic 的模型就可以和 Flink 流的概念很好的結(jié)合,Pulsar 可以作為 Flink 流計算的載體。
有界的計算可以視為一個有界的流,對應(yīng) Pulsar 一些限定的分片;
實時的計算就是一個無界的流,對 Topic 中最新的數(shù)據(jù)做查詢和訪問。
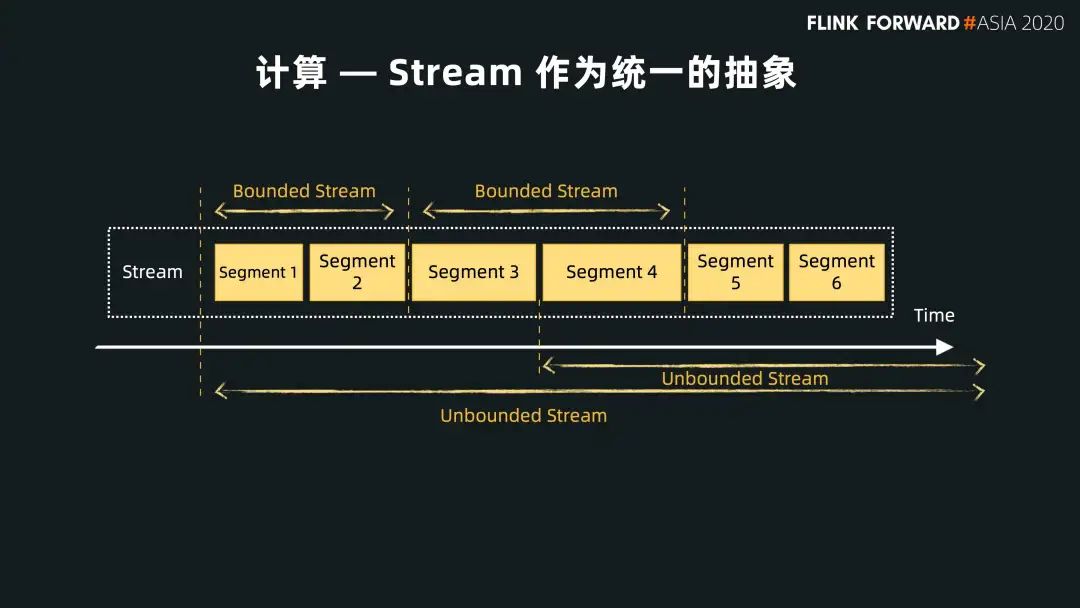
對有界的流和無界的流,Pulsar 采取不同的響應(yīng)模式:
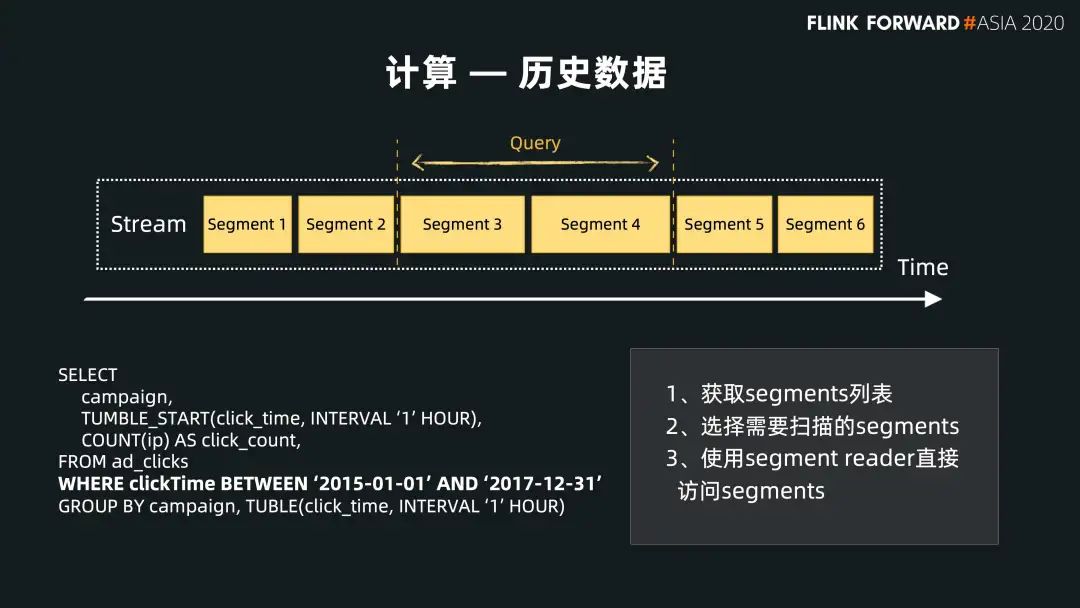
第一種是對歷史數(shù)據(jù)的響應(yīng)。如下圖所示,左下角是用戶的 query,給定起止的時間限定流的范圍。對 Pulsar 的響應(yīng)分為幾步:
第一步,找到 Topic,根據(jù)我們統(tǒng)一管理的 metadata,可以獲取這個 topic 里面所有分片的 metadata 的列表;
第二步,根據(jù)時間限定在 metadata 列表中,通過兩分查找的方式來獲取起始分片和終止的分片,選擇需要掃的分片;
第三步,找到這些分片以后通過底層存儲層的接口訪問需要訪問的這些分片,完成一次歷史數(shù)據(jù)的查找。
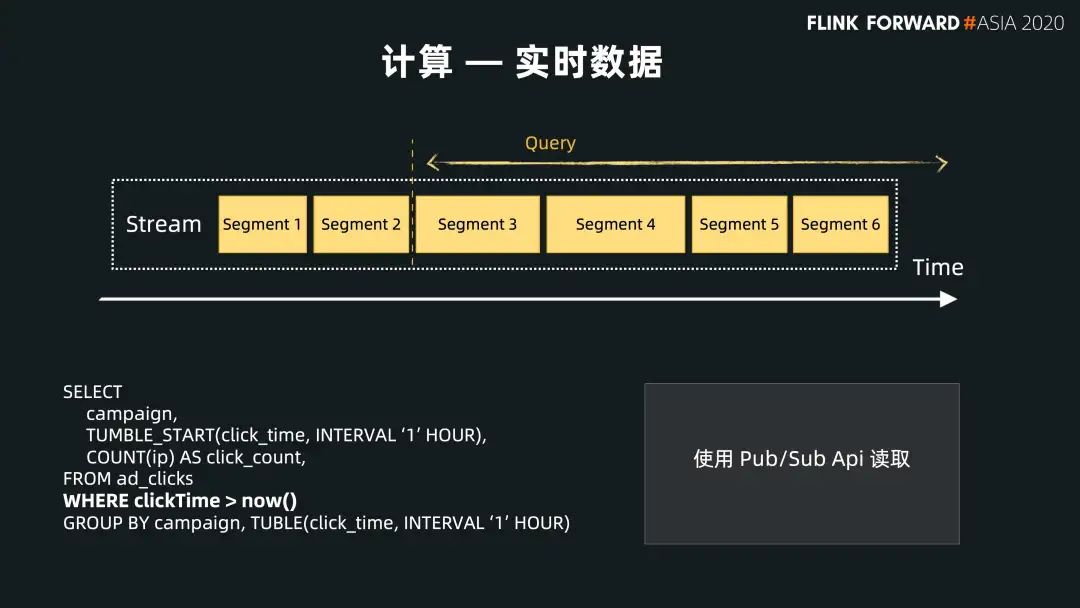
對實時數(shù)據(jù)的查找,Pulsar 也提供和 Kafka 相同的接口,可以通過 consumer 的方式來讀取最尾端分片(也就是最新的數(shù)據(jù)),通過 consumer 接口對數(shù)據(jù)進行實時訪問。它不停地查找最新的數(shù)據(jù),完成之后再進行下一次查找。這種情況下,使用 Pulsar Pub/Sub 接口是一種最直接最有效的方式。
簡單來說,F(xiàn)link 提供了統(tǒng)一的視圖讓用戶可以用統(tǒng)一的 API 來處理 streaming 和歷史數(shù)據(jù)。以前,數(shù)據(jù)科學(xué)家可能需要編寫兩套應(yīng)用分別用來處理實時數(shù)據(jù)和歷史數(shù)據(jù),現(xiàn)在只需要一套模型就能夠解決這種問題。
Pulsar 主要提供一個數(shù)據(jù)的載體,通過基于分區(qū)分片的架構(gòu)為上面的計算層提供流的存儲載體。因為 Pulsar 采用了分層分片的架構(gòu),它有針對流的最新數(shù)據(jù)訪問接口,也有針對批的對并發(fā)有更高要求的存儲層訪問接口。同時它提供無限的流存儲和統(tǒng)一的消費模型。

四、Pulsar 現(xiàn)有能力和進展
最后我們額外說一下 Pulsar 現(xiàn)在有怎樣的能力和最近的一些進展。
現(xiàn)有能力
■ schema
在大數(shù)據(jù)中,schema 是一個特別重要的抽象。在消息領(lǐng)域里面也是一樣,在 Pulsar 中,如果 producer 和 consumer 可以通過 schema 來簽訂一套協(xié)議,那就不需要生產(chǎn)端和消費端的用戶再線下溝通數(shù)據(jù)的發(fā)送和接收的格式。在計算引擎中我們也需要同樣的支持。
在 Pulsar-Flink connector 中,我們借用 Flink schema 的 interface,對接 Pulsar 自帶的 Schema,F(xiàn)link 能夠直接解析存儲在Pulsar 數(shù)據(jù)的 schema。這個 schema 包括兩種:
第一種是我們常見的對每一個消息的元數(shù)據(jù)(meatdata)包括消息的 key、消息產(chǎn)生時間、或是其他元數(shù)據(jù)的信息。
另一種是對消息的內(nèi)容的數(shù)據(jù)結(jié)構(gòu)的描述,常見的是 Avro 格式,在用戶訪問的時候就可以通過Schema知道每個消息對應(yīng)的數(shù)據(jù)結(jié)構(gòu)。
同時我們結(jié)合 Flip-107,整合 Flink metadata schema 和 Avro 的 metadata,可以將兩種 Schema 結(jié)合在一起做更復(fù)雜的查詢。

■ source
有了這個 schema,用戶可以很容易地把它作為一個 source,因為它可以從 schema 的信息理解每個消息。
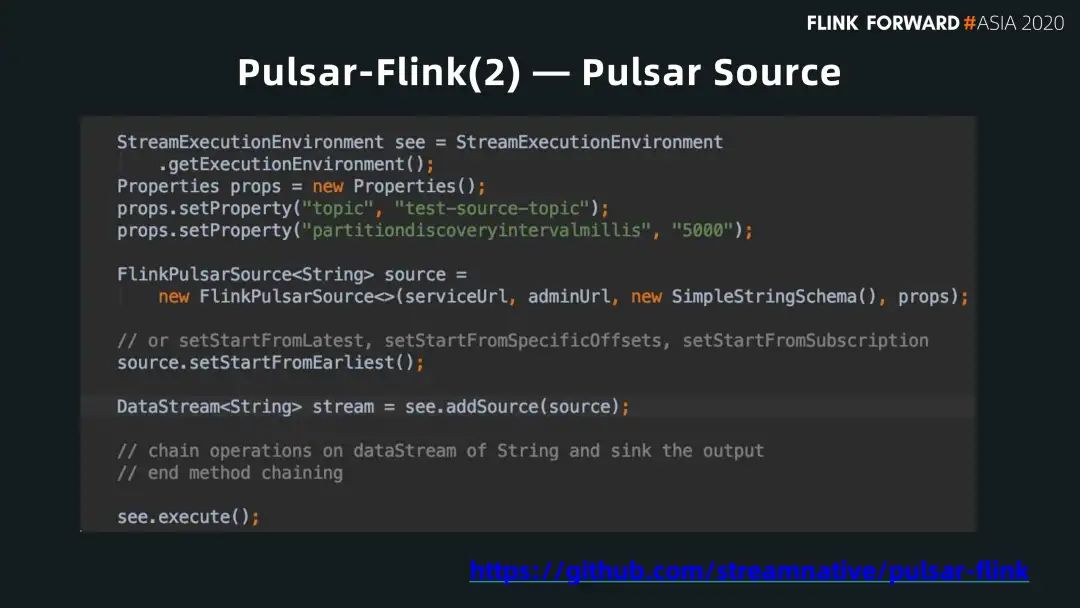
■ Pulsar Sink
我們也可以把在 Flink 中的計算結(jié)果返回給 Pulsar 把它做為 Sink。

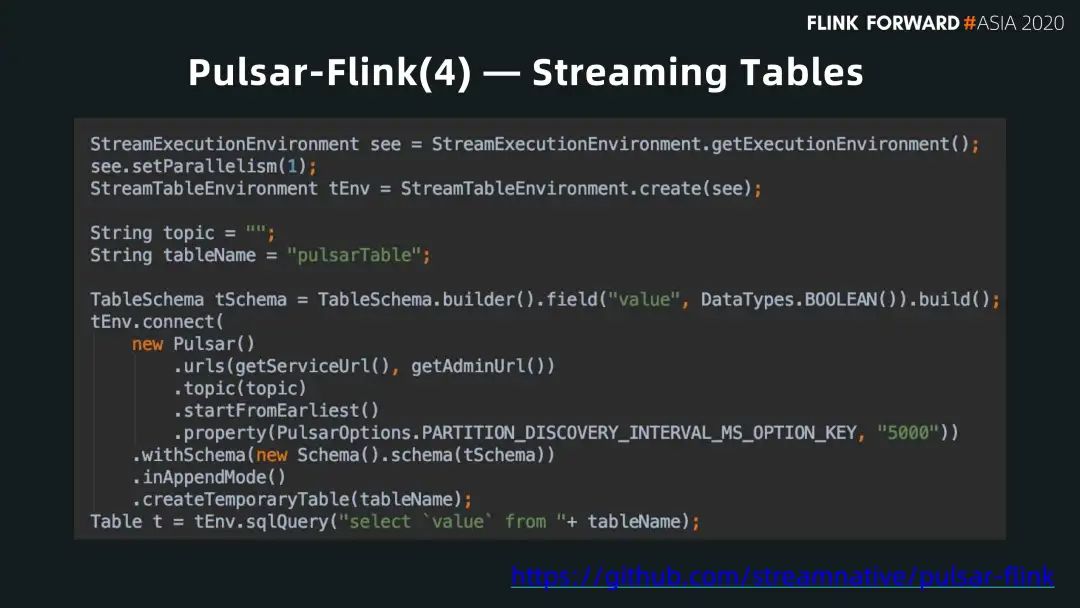
■ Streaming Tables
有了 Sink 和 Source 的支持,我們就可以把 Flink table 直接暴露給用戶。用戶可以很簡單的把 Pulsar 作為 Flink 的一個 table,查找數(shù)據(jù)。
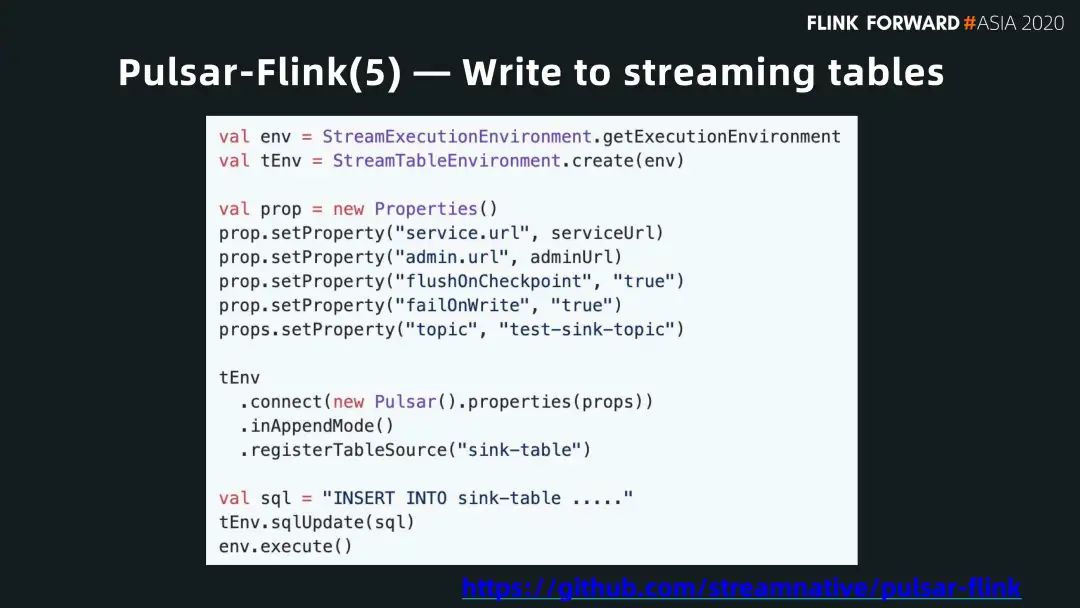
■write to straming tables
下圖展示如何把計算結(jié)果或數(shù)據(jù)寫到 Pulsar 的 Topic 中去。
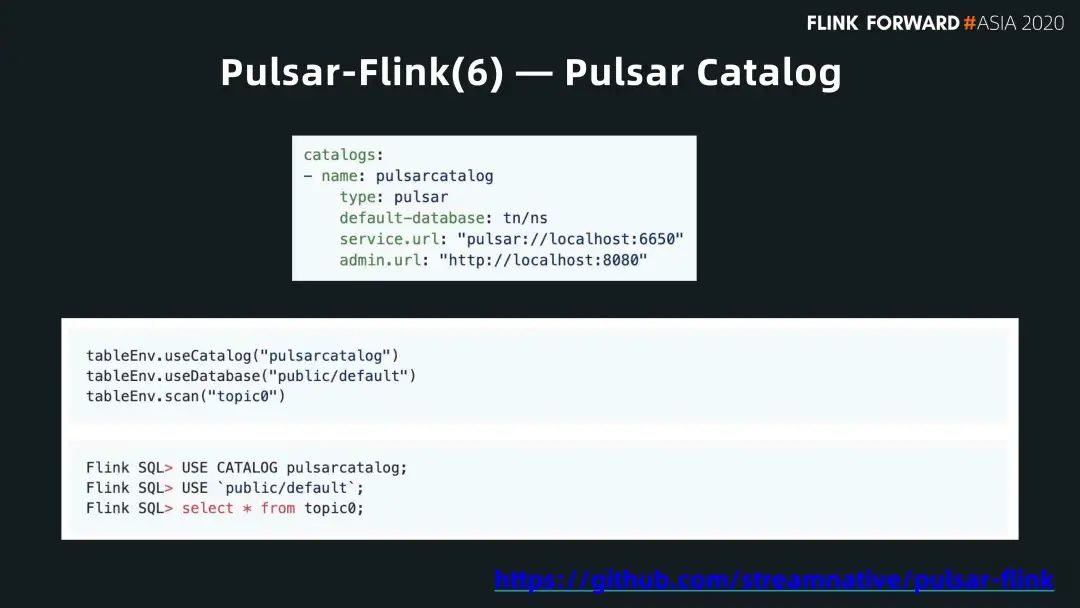
■ Pulsar Catalog
Pulsar 自帶了很多企業(yè)流的特性。Pulsar 的 topic(e.g. persistent://tenant_name/namespace_name/topic_name)不是一個平鋪的概念,而是分很多級別。有 tenant 級別,還有 namespace 級別。這樣可以很容易得與 Flink 常用的 Catalog 概念結(jié)合。
如下圖所示,定義了一個 Pulsar Catalog,database 是 tn/ns,這是一個路徑表達,先是 tenant,然后是 namespace,最后再掛一個 topic。這樣就可以把Pulsar 的 namespace 當(dāng)作 Flink 的 Catalog,namespace 下面會有很多 topic,每個 topic 都可以是 Catalog 的 table。這就可以很容易地跟 Flink Cataglog 做很好的對應(yīng)。在下圖中,上方的是 Catalog 的定義,下方則演示如何使用這個 Catalog。不過,這里還需要進一步完善,后邊也有計劃做 partition 的支持。
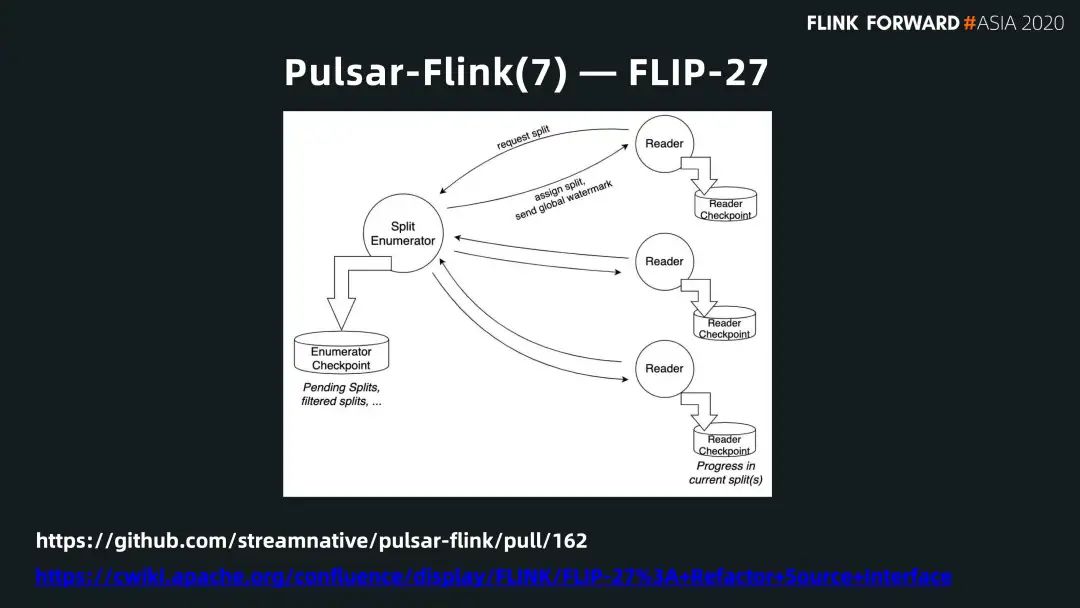
■ FLIP-27
FLIP-27 是 Pulsar - Flink 批流融合的一個代表。前面介紹了 Pulsar 提供統(tǒng)一的視圖,管理所有 topic 的 metadata。在這個視圖中,根據(jù) metadata 標(biāo)記每個分片的信息,再依靠 FLIP-27 的 framework 達到批流融合的目的。FLIP-27 中有兩個概念:Splitter 和 reader。
它的工作原理是這樣的,首先會有一個 splitter 把數(shù)據(jù)源做切割,之后交給 reader 讀取數(shù)據(jù)。對 Pulsar 來說,splitter 處理的還是 Pulsar 的一個 topic。抓到 Pulsar topic 的 metadata 之后,根據(jù)每個分片的元數(shù)據(jù)來判斷這個分片存儲在什么位置,再選最合適的 reader 進行訪問。Pulsar 提供統(tǒng)一的存儲層,F(xiàn)link 根據(jù) splitter 對每個分區(qū)的不同位置和格式的信息,選擇不同的 reader 讀取 Pulsar 中的數(shù)據(jù)。
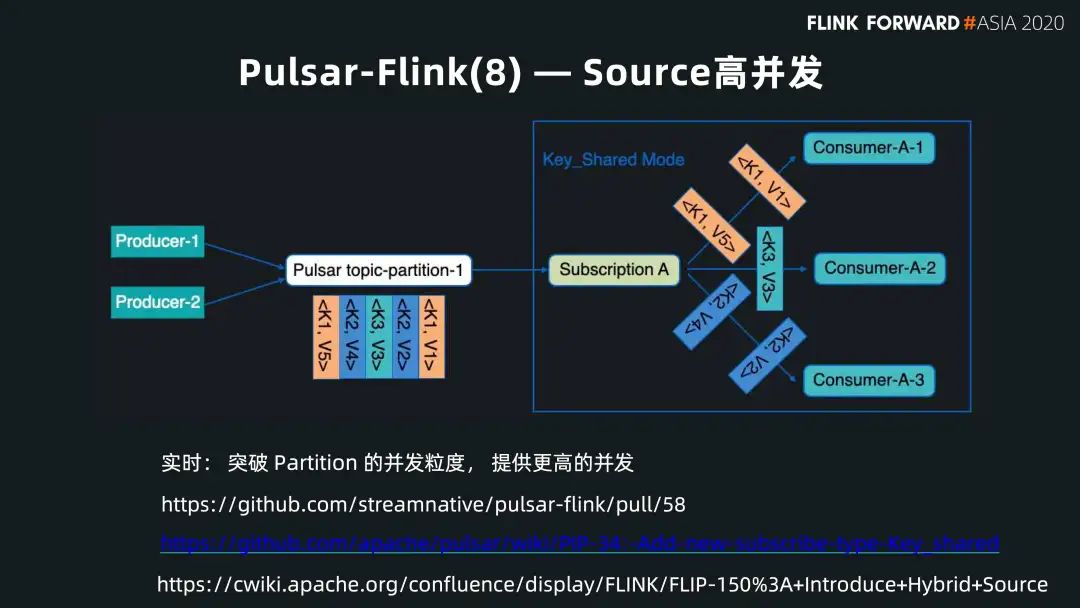
■ Source 高并發(fā)
另一個和 Pulsar 消費模式緊密相關(guān)的是。很多 Flink 用戶面臨的問題是如何讓 Flink 更快地執(zhí)行任務(wù)。例如,用戶給了 10 個并發(fā)度,它會有 10 個 job 并發(fā),但假如一個 Kafka 的 topic 只有 5 個分區(qū),由于每個分區(qū)只能被一個 job 消費,就會有 5 個 Flink job 是空閑的。如果想要加快消費的并發(fā)度,只能跟業(yè)務(wù)方協(xié)調(diào)多開幾個分區(qū)。這樣的話,從消費端到生產(chǎn)端和后邊的運維方都會覺得特別復(fù)雜。并且它很難做到實時的按需更新。
而 Pulsar 不僅支持 Kafka 這種每個分區(qū)只能被一個 active 的 consumer 消費的情況,也支持 Key-Shared 的模式,多個 consumer 可以共同對一個分區(qū)進行消費,同時保證每個 key 的消息只發(fā)給一個 consumer,這樣就保證了 consumer 的并發(fā),又同時保證了消息的有序。
對前面的場景,我們在 Pulsar Flink 里做了 Key-shared 消費模式的支持。同樣是 5 個分區(qū),10 個并發(fā) Flink job。但是我可以把 key 的范圍拆成 10 個。每一個 Flink 的子任務(wù)消費在 10 個 key 范圍中的一個。這樣從用戶消費端來說,就可以很好解耦分區(qū)的數(shù)量和 Flink 并發(fā)度之間的關(guān)系,也可以更好提供數(shù)據(jù)的并發(fā)。
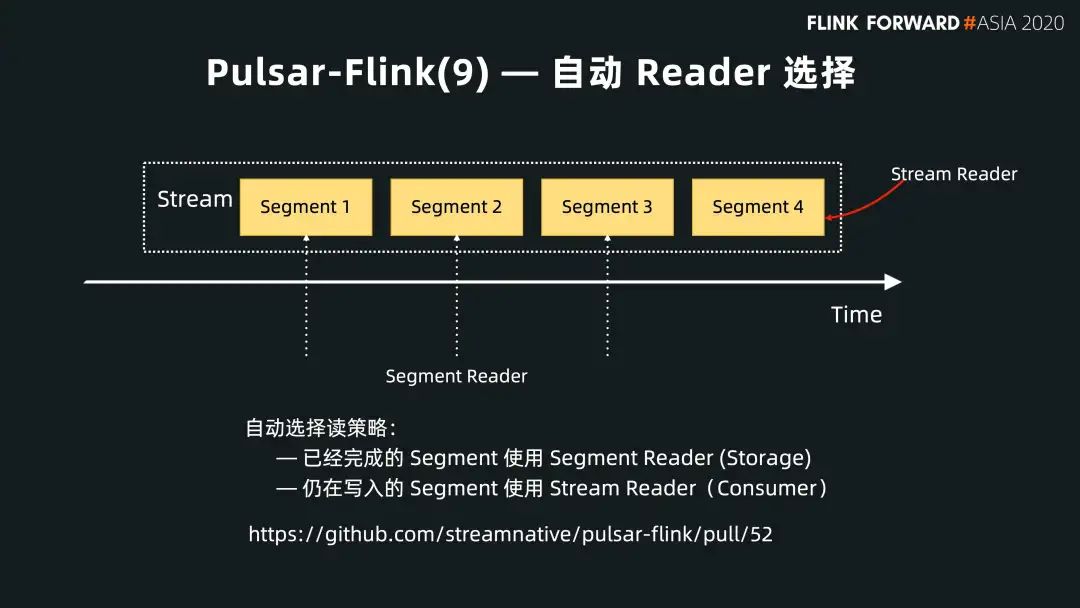
■ 自動 Reader 選擇
另外一個方向是上文提到的 Pulsar 已經(jīng)有統(tǒng)一的存儲基礎(chǔ)。我們可以在這個基礎(chǔ)上根據(jù)用戶不同的 segment metadata 選擇不同的 reader。目前,我們已經(jīng)實現(xiàn)該功能。
近期工作
最近,我們也在做和 Flink 1.12 整合相關(guān)的工作。Pulsar-Flink 項目也在不停地做迭代,比如我們增加了對 Pulsar 2.7 中事務(wù)的支持,并且把端到端的 Exactly-Once 整合到 Pulsar Flink repo 中;另外的工作是如何讀取 Parquet 格式的二級存儲的列數(shù)據(jù);以及使用 Pulsar 存儲層做 Flink 的 state 存儲等。
