
OLAP如何選型?ClickHouse為何如此之快?
本次分享的題目為ClickHouse在有贊的實踐,主要介紹:
OLAP在有贊的發(fā)展
ClickHouse在有贊的平臺化工具建設
ClickHouse在有贊的應用
未來規(guī)劃和一些探索
嘉賓GitHub網址:https://github.com/kaka11chen
OLAP在有贊的發(fā)展
1.?有贊OLAP發(fā)展
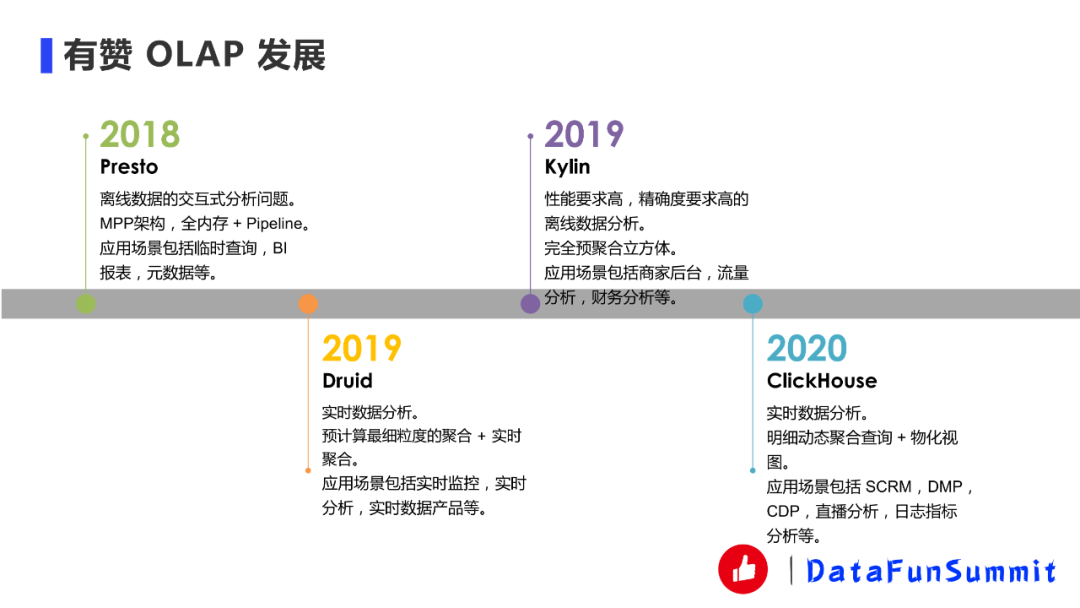
有贊在2018年引入了Presto以解決離線數據的交互式分析問題。Presto采用的是MPP架構,全內存?+ pipeline的技術實現,比較適合交互式分析。我們主要將Presto應用在臨時查詢、BI報表、元數據的分析等場景。
在2019年上半年我們引入了Druid。在沒有Druid之前,面對實時的場景我們只能通過Flink或者Storm去預計算好結果,將結果直接存儲在 KV (如Redis、HBase)里面然后再進行查詢,這種方式開發(fā)起來非常地繁瑣,因此我們引入了Druid來完成數據的實時分析。Druid的原理是預計算最細粒度的聚合,比如說我有三個維度A、B、C,Druid會預計算A、B、C三個維度再加上TimeStamp的粒度,然后整個預計算這些結果,查詢的時候再通過這份結果進行查詢,這種方式可以減少維度爆炸的問題,相對來說是一種比較平衡的方式。應用場景主要包括實時監(jiān)控、實時分析、實時數據產品等。
2019年的下半年我們也同時引入了Kylin,主要應用在對于一些精確度要求比較高,性能要求也比較高的離線數據分析場景比如商家后臺的一些場景。Kylin的實現原理是完全預聚合和立方體,它會把各種組合都在HBase里面算出來。當然現在Kylin4的版本也慢慢走向了不是所有的聚合結果都幫你算出來,我們這邊也在引入Kylin4,并且提交了一些patch。
2020年我們引入了ClickHouse,主要用來進行實時數據分析。ClickHouse的原理是明細動態(tài)聚合查詢,因為以前Druid都是幫你預聚合好,我們沒辦法直接通過明細數據進行查詢。此外ClickHouse還能通過物化視圖做到類似Druid的預聚合的功能,雖然物化視圖相對來說比較簡單一點,這個后面也會講一下。我們的應用場景包括SCRM、DMP、CDP、直播分析還有一些日志指標分析等。
2.?有贊OLAP發(fā)展和選型

這里主要對以上幾款產品在技術、延時、SQL支持程度、生產數據成本、支持Join、去重方式等方面的表現進行了對比。
Presto:技術方面,Presto采用的MPP系統(tǒng)和SQL On Hadoop;Presto的延時是天/小時級別,雖然現在數據湖IceBerg、HuDi比較火,他們希望把它達到分鐘級別,但是就目前來看還沒到很成熟大規(guī)模使用的階段;Presto的查詢延遲一般,因為它是從明細層開始查詢,沒有任何預聚合;SQL支持程度還是比較完善的;因為沒有預聚合,數據生產成本也比較低;Join也支持的比較好;去重的話也支持普通精確去重。
Druid:Druid采用了一些如位圖索引、字符串編碼、預聚合等的技術,剛才也講過它只預聚合最細的維度組合,這樣可以防止維度爆炸,但是會犧牲一點RT(響應時間),因此做了一個權衡;支持實時;查詢延遲相對Presto會低很多;SQL支持的相對完善,但是沒有Presto那么完善;Druid會做一部分的預聚合,自然需要一些成本;新版本開始慢慢準備支持Join了,但還不成熟,維度表的Lookup是一直支持的;去重方式采用的是HyperLogLog,快手我看到也有第三方的contributing去支持BitMap去重,但是這個我也沒有深入調研過,這邊就不多說了。
Kylin:Kylin采用的技術是完全預聚合的立方體,至少Kylin4之前的版本是這樣的;它是把結果存到HBase,微批量的延遲;查詢延遲也非常低,因為直接從HBase里面去做相應的結果查詢,如果一些比較輕微的聚合可以通過HBase的Coprocessor去做一些比較輕微的一些聚合;SQL支持程度也比較完善,生產成本由于要做預聚合的立方體成本就比較高,生產成本一高的話靈活性就會變得很差,比如修改一些字段,重刷數據成本就會比較高;Join也是支持的;Kylin有一個比較好的一個事情是可以做到BitMap去重這個會是一個比較大的優(yōu)勢。
ClickHouse:ClickHouse采用的技術是明細動態(tài)聚合查詢,當然也類似于Druid可以用一些物化視圖,做一些預聚合的表,再通過預聚合的表進行查詢;支持實時,明細查詢延時還是比較低的,對比Presto、Impala包括對比Apache Doris,ClickHouse單表的查詢性能確實很高;Join在一些情況下性能不佳,因為Join沒有Exchange或者Shuffle Join,物化視圖是預聚合的所以性能會更好一點;SQL支持只能說較完善,沒有Presto和Kylin那么完善;生產數據如果是物化視圖的話,會聚合一下,因此還是會有一些成本;Join剛才也講了只能有限支持,比如說沒有shuffle join,當數據量比較大的情況下,性能就不太佳甚至會查不出來,語法解析也不是很好,有時候比如說左邊是個Table右邊是個SubQuery這種,但是換一換可能性能就會更差;去重方式支持精確去重和HyperLogLog,但是沒有支持BitMap去重。
3. ClickHouse特性
ClickHouse主要具有以下特性:
靈活,支持明細數據SQL查詢,并用物化視圖加速。
多核(垂直擴展),可以在一臺機器上使用多線程去進行查詢;分布式處理,它有不同的分片,這樣的話可以進行水平擴展,MPP架構。
支持實時批量數據攝入。
列式存儲、向量化引擎、代碼編譯生成。向量化引擎和代碼編譯生成基本是為了解決算子瓶頸,如果不通過這些技術的話一般是個火山模型,火山模型會有一些虛函數以及分支判斷之間的一些開銷。通過這兩種方法,向量化可以去平攤開銷,代碼編譯可以把它轉成以數據為中心進而消除開銷。但是這兩種方法也不是萬能的,比如說當Aggregation或者Join數據量比較大時候需要物化到內存,物化到內存的時候瓶頸也就產生了,因此也不會有非常大的性能爭議。
主鍵索引,ClickHouse會按照用戶設置的主鍵進行排序,ClickHouse中MergeTree的文件就是按照這個逐漸進行排序的,Bloom Filter、minmax等做了二級索引。
當然,ClickHouse也不是萬能的,它在以下方面并不擅長:
沒有高速,低延遲的更新和刪除方法。不擅長單行數據,行級別數據的更新刪除方法一般都是異步進行。
稀疏索引使得點查性能不佳。點查沒辦法用ClickHouse,最好的是用KV類型的Redis或者HBASE。
不支持事務。盡管事務現在對OLAP也會有一些用途,但是不是非常大的用途。
ClickHouse的應用場景:
用戶行為分析,精細化運營分析:日活、留存率分析、路徑分析、有序漏斗轉化率分析、Session分析等。
實時日志分析,監(jiān)控分析,實時數倉。
4.?ClickHouse原理簡介
很多人接觸ClickHouse都會問的一個問題,ClickHouse為什么會快?
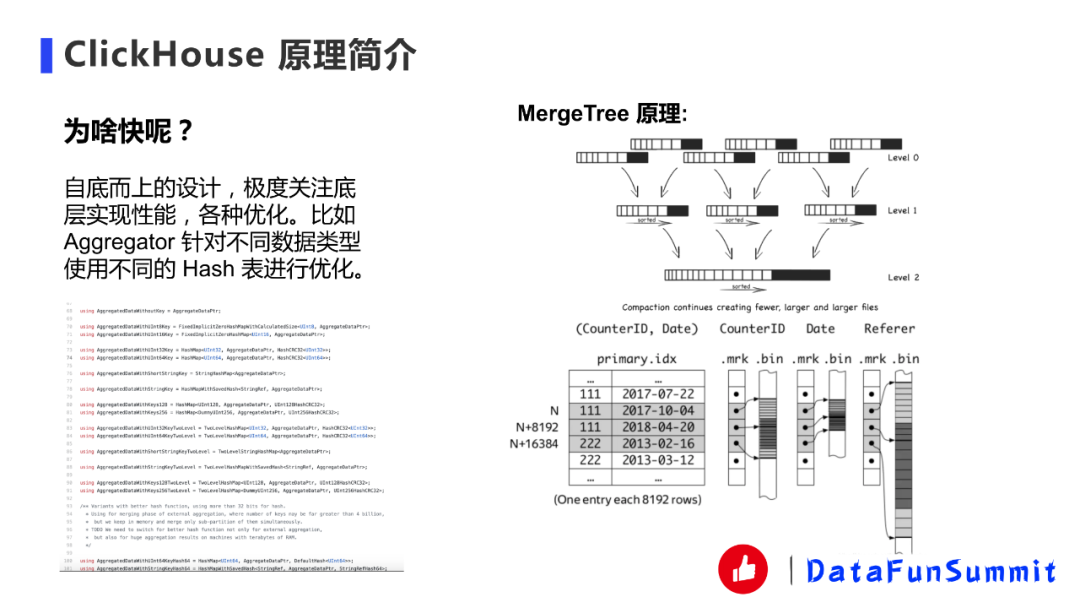
計算方面:ClickHouse采用的是自底而上的設計,極度關注性能,有各種優(yōu)化。如Aggregator,一般Aggregator沒有這么夸張的優(yōu)化,更多的是對Int數據的Hash表的優(yōu)化,其他類型可能就用一樣的Hash表。ClickHouse對不同的數據類型有不同的HashMap。前面的一些情況也是它的原因,比如向量化引擎和代碼編譯生成,向量化確實能夠提高,代碼編譯生成一般情況下大部分的數據也能提高,比如在表達式生成這種情況也會用代碼編譯生成。
存儲方面:采用的是MergeTree,一般我們寫ClickHouse都會按批次寫,就是一個批次Insert過去,然后會形成part(partition)文件,假如只有一個分區(qū),就形成一個part文件,part文件是按照主鍵進行排序的其內部有序,ClickHouse后天會默默地把這些文件進行合并,有點像LSM-Tree。主鍵包括以下幾個部分,首先有一個primary.idx是它是主鍵索引,該索引是稀疏索引而非稠密索引,這樣的好處是可以把稀疏索引放到內存中性能會更佳,而且OLAP不是OLTP,它更多的是聚合計算,所以瓶頸更多是在聚合計算的算子那里,但是比如很多小查詢那就不一定了。然后主鍵索引會去找到它相應的.mkr文件,是跟主鍵索引是一一對應的。mkr文件記載主鍵索引的比如說行號。后面是數據文件bin,記載了這兩個文件之間的offset。整體流程是先通過主鍵,然后找到MKR,然后再找到bin的offset。中間還有些壓縮之類的東西,會復雜一點,這里就先簡單講一下。
1. ClickHouse集群部署
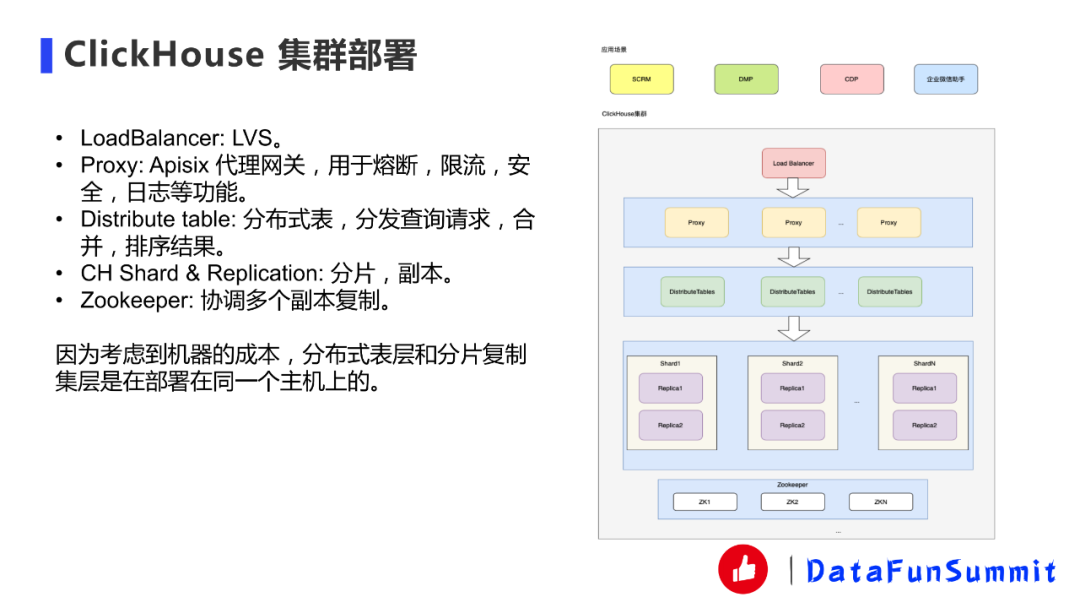
我們這邊大數據平臺是一個中臺部門,所以更希望是我們這邊把整個大數據組件給包裝起來統(tǒng)一管理,業(yè)務方只需要使用包裝后的系統(tǒng)。
上層是應用場景,剛才有講SCRM、DMP、CDP、企業(yè)微信助手。
應用場景這塊,我們在最前端會有個Load Balance,目前我們用的是LVS,其實HTTP代理也行。但是因為我們的統(tǒng)一全權代理會有一些限制,因此我們現在選用的是LVS會比較方便一點。
第二層Proxy部分,目前我們用的是Apisix代理網關,該網關是基于Nginx的,Nginx現在有一個基于OpenResty的Apisix的代理網關可以用來做一些網關或者邊緣網關。我們用它來做一些熔斷、限流、安全、日志這些功能。用起來也比較方便,DMP這邊我們還實現了一個自定義插件,這個后續(xù)會講。
下面一層是分布式表,分布式表之后就是每一個分片,每一個分片都有兩臺副本。比如說這邊三個分片的話就是3x2共6臺機器。Zookeeper的話我們是用SSD單獨部署的,因為ClickHouse在副本復制的時候需要Zookeeper去協(xié)調。上圖畫的不是那么的準,在分布式表跟分片之間我們是部署在同一些機器上面的,這樣比較省成本。
2.?ClickHouse寫入
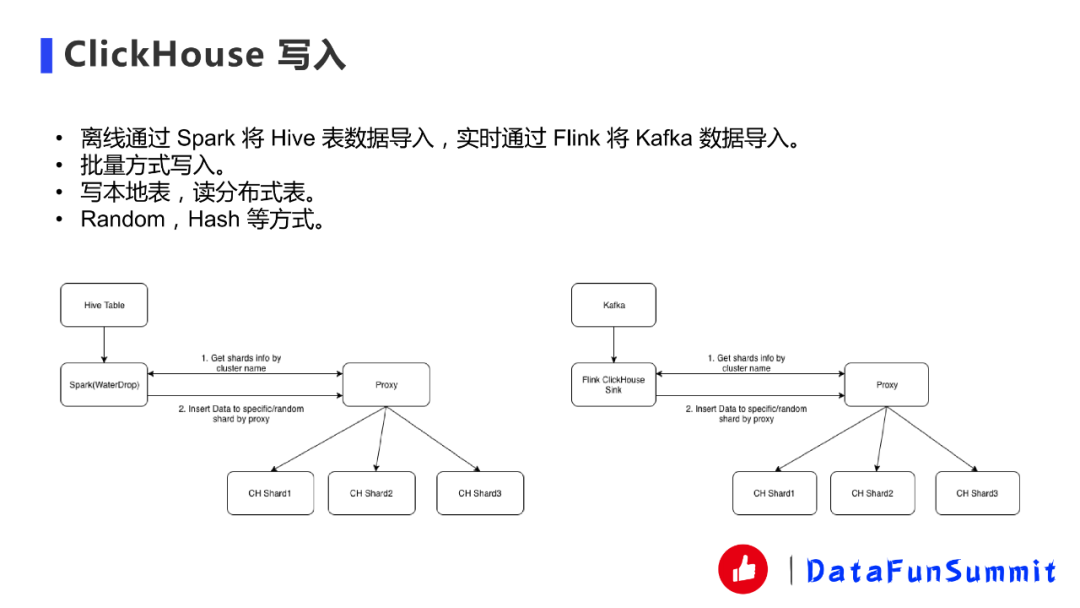
ClickHouse寫入部分,離線我們一般是通過Spark將Hive表導到ClickHouse里面,還有通過Flink將Kafka的數據進行導入。需要注意的是必須批量寫入,原因剛才也講過,因為ClickHouse每次寫入會根據partition形成parts文件,如果一條數據寫一個parts文件的話會合并不過來,因為后面合并的話就會看到合并比插入都慢的那種錯誤,官方推薦是用批量方式寫。
后面就是寫本地表,讀分布式表。ClickHouse也可以寫分布式表,但是對Zookeeper的性能壓力會比較大,整個性能也會比較差。我們有兩種寫入方式,一種是Random一種是Hash,Hash是為了后面DMP系統(tǒng)特殊設計的,這個后面會講。我們Spark用的WaterDrop,是比較出名的一個Spark的工具,我們進行了自己修改一些代碼定制。第一步是通過cluster name獲得分片的信息,我們是直接通過apisix代理獲得,apisix會寫一個插件獲得相應掛在后端的某一個ClickHouse Cluster分片的路徑,獲得之后我們就用Hash或者隨機的方式插入數據,Flink也是類似的。
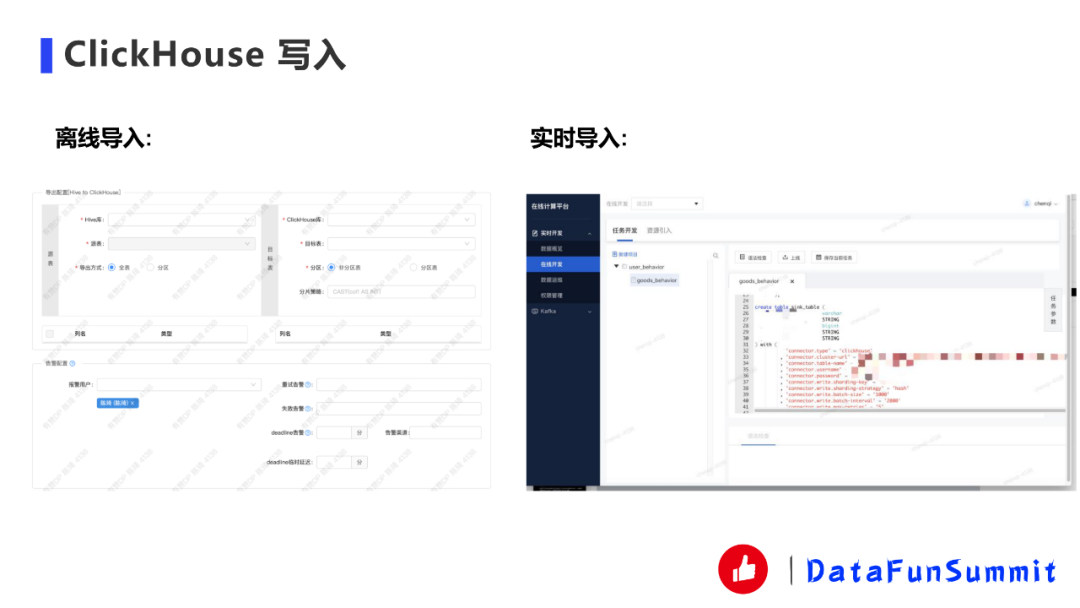
上圖展示的是我們離線導入和實時導入部分的。
離線導入:我們的數據平臺里面有一類任務需要離線導入,用戶可以直接選一張Hive表或者ClickHouse的目標表去導入。
分片策略:如果是Hash的話會需要采用分片策略。
實時導入:我們寫了Flink的ClickHouse Connector,基于JDBC根據剛才那些要素進行修改。并且它不僅SQL可以用這個Connector,SDK也能用這個Connector。
3.?ClickHouse離線讀寫分離
我們做好這套系統(tǒng)后發(fā)現有一個痛點就是業(yè)務場景很多都寫入量巨大,寫多讀少,離線會導入很多Hive表。很多公司其實做一些產品出來,查詢QPS都沒有很高,因為產品剛剛上線需要尋找業(yè)務爆發(fā)點,沒有辦法一下子讀很多,但是寫入量會很大。這種情況的話,我們針對寫入量只能擴分片來提高寫入吞吐,其實就是一種讀寫不分離的方法,所以資源會比較浪費。
去年的話我看了那個QQ音樂的,他們也有這個思路去做ClickHouse讀寫分離,我們這邊也就是同樣去做了一下。一般來說可行方案有兩種,一種就是用k8s ch臨時集群來寫入。可以用一個k8s集群,每次插入的時候用一個臨時的k8s集群構建起來,然后數據直接寫到臨時集群,等插完之后再把相應的數據文件直接弄到線上集群。第二種方法是使用Spark構建數據文件。這種方法是可行的,但是相對來說復雜度會高一點。我們采用的是k8s方案,因為比較容易實現。
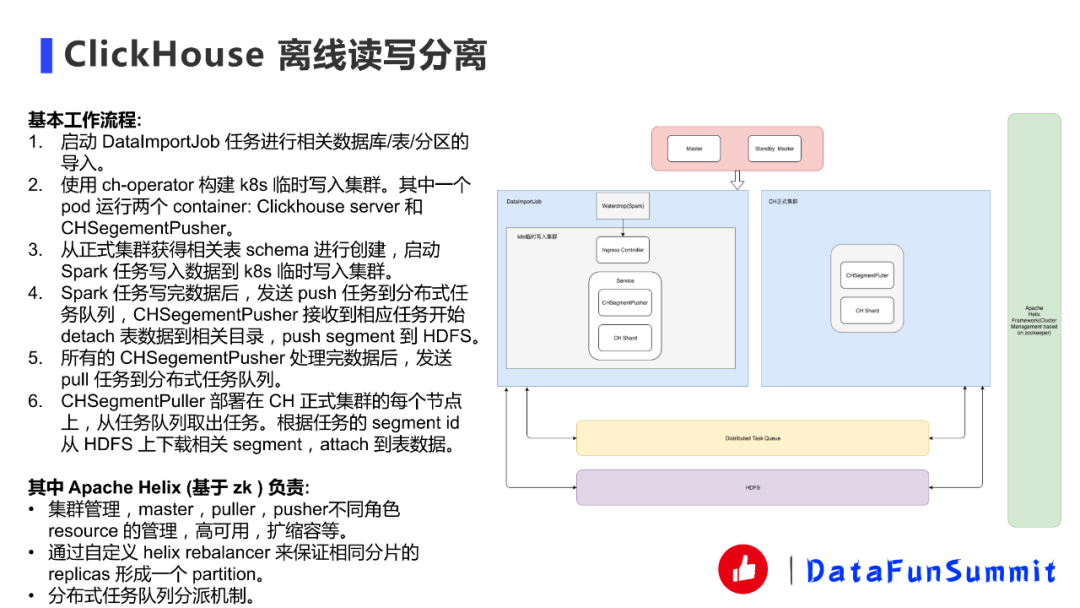
ClickHouse的基本工作流程如上圖所示:
我們先講一下架構,我這邊會設計一個Master節(jié)點和一個StandBy Master節(jié)點去管理這些組件,包括高可用、擴縮容這些。DataImportJob啟動起來之后通過WaterDrop直接導入到k8s臨時寫入集群,再導入某張表某個分區(qū)的時候會去啟動一個臨時的k8s集群。集群里面我們用的是官方的ch-operator,它除了本身的ClickHouse server服務,我們還自己寫了一個叫CHSegmentPusher,字面上理解就是當數據導入臨時集群之后,要把數據push到中間存儲(HDFS)里面去。相應的ClickHouse集群這邊我們也有相應的puller部署在正式集群的每個節(jié)點上,puller去從HDFS上取這個數據。
右側是Apache Helix,apache Helix Framework是基于Zookeeper去幫你管理集群心跳、存活、高可用、擴縮容等。包括這個分布式任務隊列,也是用zk實現的。其實這個架構有點像Druid那個segment加載,有了解Druid的小伙伴就比較清楚。
還有一些細節(jié),比如說Helix里面我們自己去實現一個balance來保證相同分片的replicas形成一個partition。因為一定要這么做。
1.?DMP人群畫像系統(tǒng)
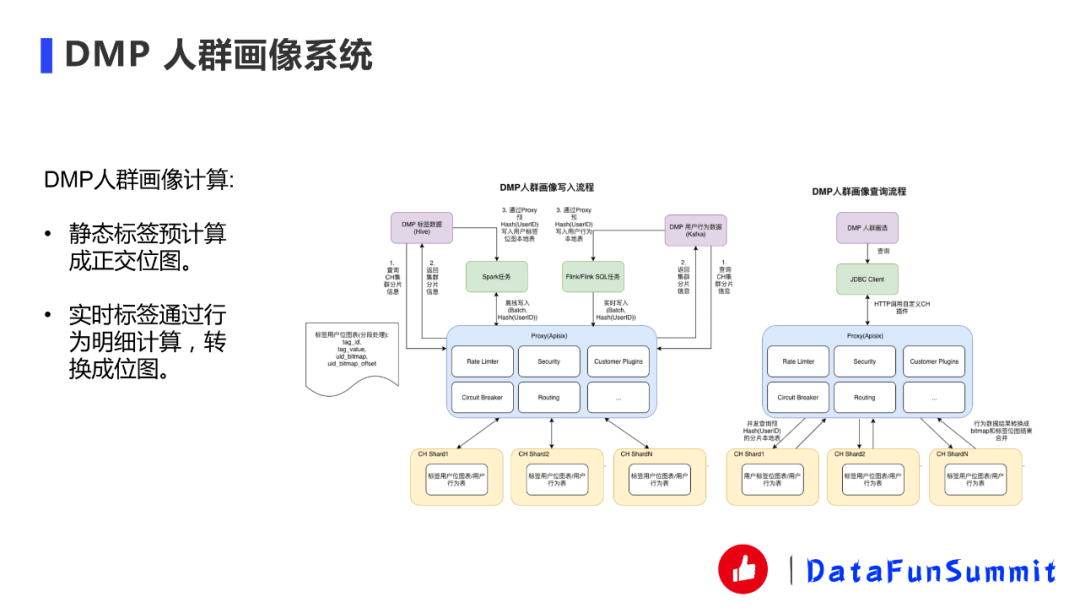
第一個是DMP人群畫像系統(tǒng),概括來說就是一個正交導入的方式。我們DMP人群畫像一般業(yè)務都要去進行人群圈選,通過一些tag去圈選出一些人群來進行營銷活動或者是預估人群的數目。如果把這些明細數據直接放到ClickHouse里面的話性能就會比較差,所以業(yè)界通常的做法是把它轉成位圖,這部分查詢的性能就會相對高一點。我們的標簽用戶位圖表基本上就是這樣設計的,首先是tag_id、tag_value、uid_bitmap、uid_bitmap_offset,比如說我性別是男,就有一個標簽uid_bitmap。至于為什么會有offset,是因為ClickHouse的bitmap只支持32位,如果ID大于32位怎么辦呢?我們采用offerset讓不同的bitmap來解決這樣的問題。在插入數據的時候,無論是實時還是批量數據我們都會通過UserID進行哈希,這樣的話某一個UID會在某一個分片上固定下來不會到別的分片,在性能方面這是一種最高效的做法。如果不采用這種方式,我們也試過用分布式表,結果可能三臺機器比單臺還慢,這肯定是接受不了的,因為沒有辦法橫向擴展或者縱向擴展來提高性能,因此我們采用的正交哈希寫入。一旦正交了之后,只要在自己的機器上面去處理本地的SQL,處理完之后直接將結果進行合并就行,甚至不用merge。比如說是人群的ID,那每個符合tag的人群的ID直接返回這個分片,然后另外一個也返回,然后他們把人群id疊加就行了,人數只要求個和就行了不用merge。這件事情我們不想讓用戶自己去客戶端去實現,所以我們有apisix寫了一個Customer Plugins,Customer Plugins去做這個事情,當你發(fā)了一個查詢請求過來之后,會通過你的查詢請求去不同的分片上面去并發(fā)進行查詢,然后結果按照剛才說的進行合并,讓用戶感到透明。但這個只針對靜態(tài)標簽,或者是可枚舉的一些靜態(tài)標簽。用戶還有一些實時標簽是不可枚舉的,這部分現在是用的用戶行為表,業(yè)務方直接用用戶行為表明細數據進行查詢,查詢完之后的結果轉換之后再跟剛才的靜態(tài)預計算位圖進行位圖方面的計算最后得到結果。這個確實是有隱患的,因為沒有預計算如果量很大的情況下可能會比較慢。
2.?SCRM商家會員管理系統(tǒng)
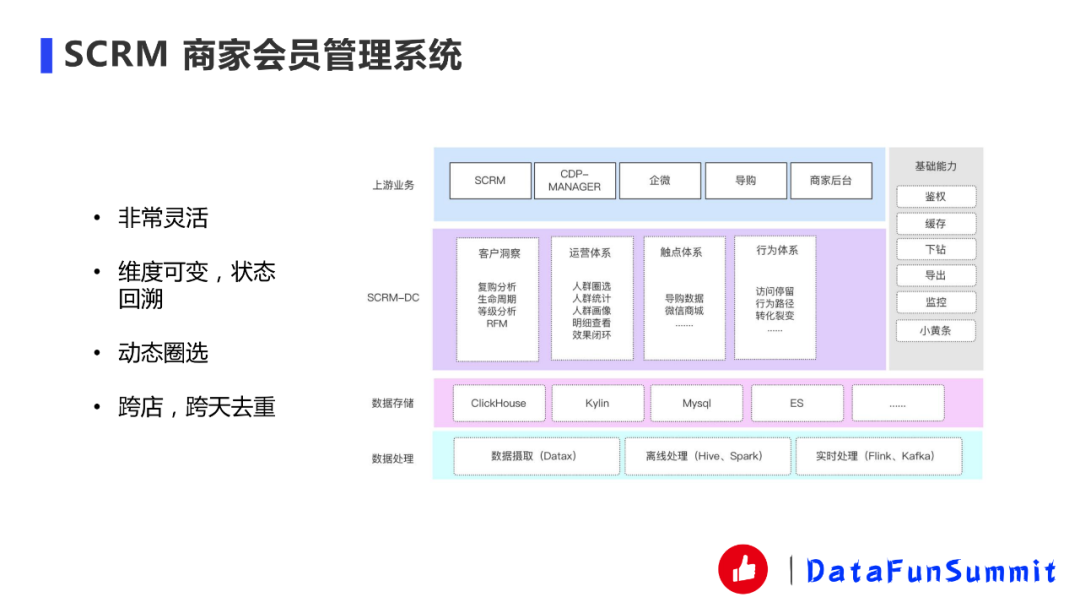
SCRM系統(tǒng)是一個比較靈活的商家分析系統(tǒng),它維度可變,狀態(tài)回溯;支持動態(tài)圈選;支持跨店、跨天去重。目前Druid做不了這個事情,所以說我們用的ClickHouse。
3.?天網日志監(jiān)控TopN系統(tǒng)

我們公司有一個日志分析軟件叫天網,全公司的應用層日志全部都存在這個系統(tǒng)里面,還有一些監(jiān)控的TopN,錯誤日志TopN、商家限流TopN、服務吞吐量TopN、特性/功能TopN。一開始這個技術是用Druid實現的,我們最近把它切換成了Flink + ClickHouse,并且使用物化視圖進行預聚合,整體效果還是不錯的。數據量也是比較大的,每秒100w行數據的Kafka寫入QPS。寫入QPS還是比較高的,換成ClickHouse這套方案可以比Druid節(jié)省60%的機器而且性能也大大提升。這個系統(tǒng)還有個特點就是查詢QPS沒有那么高,因為畢竟內部使用,不是ToC的。
04
最后我講一下ClickHouse在有贊的未來規(guī)劃和一些探索:
1.?ClickHouse在有贊的未來規(guī)劃
ClickHouse容器化部署:容器化部署更高擁有更好的彈性伸縮能力,也能和其他的服務進行混合部署來節(jié)省成本。我們覺得容器化部署是可以做的,雖然我們現在容器化部署的讀寫分離已經接入了這塊的支持,但是我們覺得如果把線上集群也進行k8s化會帶來更大的收益。
ClickHouse更多的推廣,更多業(yè)務的接入:因為ClickHouse在2020年剛流行起來,好多以前的系統(tǒng)還是通過Druid、Kylin等OLAP組件去滿足,所以未來可以去做更多的業(yè)務接入。
ClickHouse更好的平臺化以及故障防范:平臺化方面我們做還不是非常完善,特別是業(yè)務方易用性、多租戶隔離、限流、熔斷、監(jiān)控報警,業(yè)務治理等方面需要更多的投入。
一些業(yè)務以前是Druid單鏈路,我們準備把它改成Druid + ClickHouse的雙鏈路或者將Druid的業(yè)務遷移到ClickHouse。
2. ClickHouse當前痛點
我們在使用ClickHouse的過程中發(fā)現了ClickHouse還沒有到完美的程度。
ClickHouse不太像傳統(tǒng)意義上的分布式數據庫,整體來說比較“手動檔”,很多地方都需要用戶自己去設計一個流程去完善,包括寫入和物化視圖。
沒有自動Rebalance的能力,導致擴容縮容運維特別復雜。這個痛點還蠻大的,會增加運維的工作量。
Join不是采用Shuffle/Exchange Join,數據量大的時候性能差。并且ClickHouse的Join語法也不是支持的非常好。
行級別的Update/Delete性能差,官方也不推薦。這個其實從業(yè)務層面來說,他們真的很需要這個,但是很多OLAP就是不支持,因為支持這個功能非常影響性能。業(yè)界比較多的是采用impala + kudu方案。
據我了解很多大廠都針對這些痛點進行了嘗試改進。比如說存算分離,Exchange Join實現等很多大廠都在做。
那么Apache Doris呢?
現在Doris很火很多大廠已經開始嘗試使用了,相比ClickHouse,Doris更像是一個分布式數據庫,也解決了部分痛點,比如自動平衡、支持Shuffle Join等。而且是國人做的也是蠻驕傲的事情。但是就目前為止單表的性能包括成熟度、穩(wěn)定性還不如ClickHouse需要繼續(xù)發(fā)展。
還有一些是沒有開源的如Hologres、TIFlash等,這些可以嘗試以下,但是未知程度會比較高,穩(wěn)定性成熟度這些也不知道,也不知道未來是否開源。
3.?CliCkHouse + Doris POC實現
于是我們產生了一個想法:如果我們能夠把兩者結合,我們利用高性能的ClickHouse算子實現替換基于Impala的Apache Doris,在未來甚至能打造出更好的分布式OLAP數據庫。
當然現在只是POC實現階段,POC實現主要是驗證可行性的,因此實現起來以快為主,很多地方可能只是臨時Mock之類的。
驗證主要是分成以下幾個步驟:
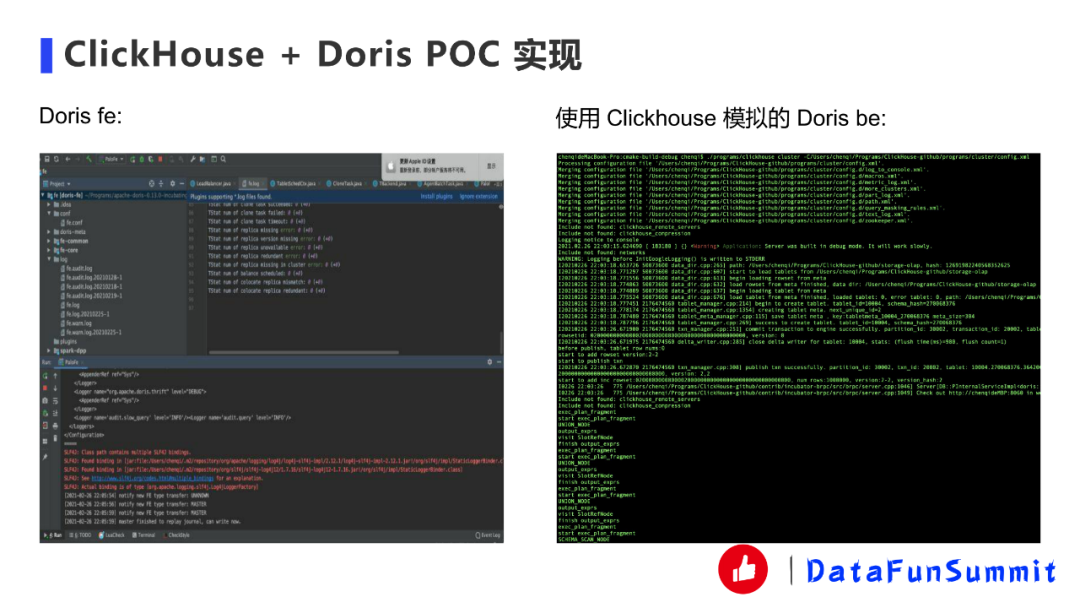
① 嘗試將Doris be的代碼一起編譯到ClickHouse中運行起來。(DONE)
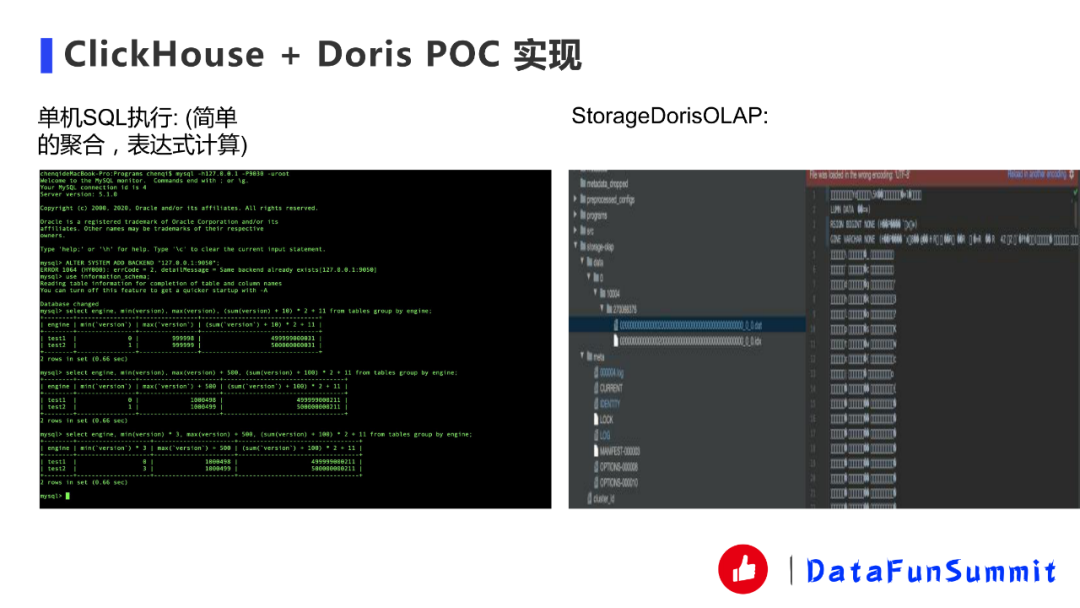
② 嘗試將解析相關fragments,Doris比較像分布式數據庫,所以前端會發(fā)一個分布式執(zhí)行計劃,然后再到后端去解析,以前的話是基于impala這套機制再加上自己改動去做這件事,現在把它映射成ClickHouse的幾個簡單算子(Storage掃描、聚合、表達式),目前能跑一個簡單的單機SQL。(DONE)
③ 嘗試將Doris OLAP的存儲實現成ClickHouse的Storage(StorageDorisOLAP),并且能跑一個簡單的單機SQL,如果能用Doris的相關存儲,也能使用其自動平衡能力。因為ClickHouse存儲一般是Storage xxx,比如說Storage MergeTree。我們實現了StorageDorisOLAP,最終是能夠用到Doris的存儲,Doris的存儲跟ClickHouse的存儲有點像,但Doris有一個最大的好處是可以自動進行平衡,并且最小單位是Tablit比物理的partition更小,在這方面會更有優(yōu)勢。(DONE)
④ 嘗試實現Doris exchange node的算子,能跑通一個簡單的分布式SQL。(DONE)
總體來說,我覺得應該是可行的,但是可能比較復雜,如果順利的話,后期我們會投入更多精力在這上面。
下面是一些運行時的截圖。
4.?大數據數據庫未來的趨勢
云原生:可任意擴縮容,存儲計算分離,多租戶,Serverless,按需付費(Snowflake、BigQuery、SaaS/Daas)。其實從國外Snowflake和BigQueue這兩款軟件基本上就概括了這些,特別是Snowflake。
多模數據庫:融合OLAP、OLTP能力,一站式解決(TiDB、TiFlash、Hologres)。我們面對很多用戶需求的比如說日志分析的時候,他們又要查明細又要去查一些指標分析,我們現在沒有辦法用一個數據庫,只能ClickHouse加上ES或者加上TiDB、MySQL這種去處理。
利用新硬件:現在也有一些GPU、FPGA等新硬件能夠加速整個數據庫的發(fā)展。
Q:一級索引和二級索引之間有沒有什么關系?
A:這個應該沒有什么關系的,一級索引就是它的主鍵,主鍵的索引就叫一級索引,主鍵索引就是你拿這個東西在MergeTree里進行排序的。二級索引的話這些Bloom Filter、minmax那些,會比如說你跳過整個塊,比如說minmax不符合范圍。
Q:Order by是不是完全可以取代主鍵?
A:Order by它是如果你不配主鍵它就是主鍵,但是好像也可以去配主鍵,但一般沒人搞這么復雜。
Q:ClickHouse讀寫分離下面的隊列是做什么的?
A:因為這里工作流程列的比較詳細,我就沒有更細致的講,其實比如說Spark把數據寫入到k8s臨時集群之后,那總要有個方法去通知我們這邊的CHSegementPusher,然后CHSegementPusher接到了這個任務通知才會去把數據發(fā)到HDFS上面某一個目錄。同樣puller也是這樣的,左邊pusher全部發(fā)完之后puller也要去同樣的我們主的DataImportJob也會去Distributed Task Queue發(fā)任務,讓相關的puller去從HDFS上面取這個數據。它就是用來push、puller這些通信的,但是push、puller這些東西其實是通過Apache Helix去管理的,Apache Helix是一套基于Zookeeper的一些集群管理的一套系統(tǒng),可以把這些東西定義成results,比如說master、puller、push,不同角色我可以定義成results。
Q:數據去重是怎么處理的?
A:數據去重是指哪方面需要去重,因為如果數據導入是沒有辦法做到Exactly-Once。從本質來講,雖然ClickHouse現在有個block防止比如說網絡抖動的時候,相同的block它可以不再導入,這種可以防止一下去重,但是理論上如果不是這種情況,它沒有辦法做到Exactly-Once。如果真的要去重,還有一種方法就是用ReplacingMergeTree可以異步地進行去重,當然也可以用一些方法比如每隔多少時間去做一下optimize強制聚合的這么一個事情,但是這個不能太頻繁,因為這個操作會非常重。