
優(yōu)酷大數(shù)據(jù) OLAP 技術(shù)選型
導(dǎo)讀:數(shù)據(jù)驅(qū)動的方法論已深入人心,無論是開發(fā)、產(chǎn)品還是運(yùn)營,根據(jù)數(shù)據(jù)進(jìn)行決策是必備環(huán)節(jié)。你是否好奇過,在優(yōu)酷這樣海量數(shù)據(jù)的場景下,是什么樣的引擎在支撐著業(yè)務(wù)上林林總總的分析需求?大數(shù)據(jù)領(lǐng)域中,Kylin、Druid、ES、ADB、GreenPlum、ODPS這些眼花繚亂的名字,它們之間又要什么區(qū)別和聯(lián)系、企業(yè)如何進(jìn)行選型?本文將為揭曉答案。
目前優(yōu)酷的工作類型廣泛,既有會員營銷這種比較復(fù)雜的分析,又有優(yōu)酷播放器性能優(yōu)化這種對實(shí)時性要求比較強(qiáng)的業(yè)務(wù)需求,在不同的業(yè)務(wù)場景里面需要使用不同OLAP引擎來達(dá)到不同的效果。本文的主要內(nèi)容包括:
大數(shù)據(jù)給傳統(tǒng)數(shù)據(jù)技術(shù)帶來的挑戰(zhàn)
市面上各類大數(shù)據(jù)OLAP技術(shù)方案一覽
優(yōu)酷不同業(yè)務(wù)場景的OLAP選型
我們知道,大數(shù)據(jù)在市場分析、性能診斷、客戶關(guān)系、數(shù)據(jù)運(yùn)營、廣告投放等都占據(jù)著重要的地位。同時,在利用大數(shù)據(jù)的過程中,也給我們帶來了諸多挑戰(zhàn):
1. 大數(shù)據(jù)帶來的挑戰(zhàn)
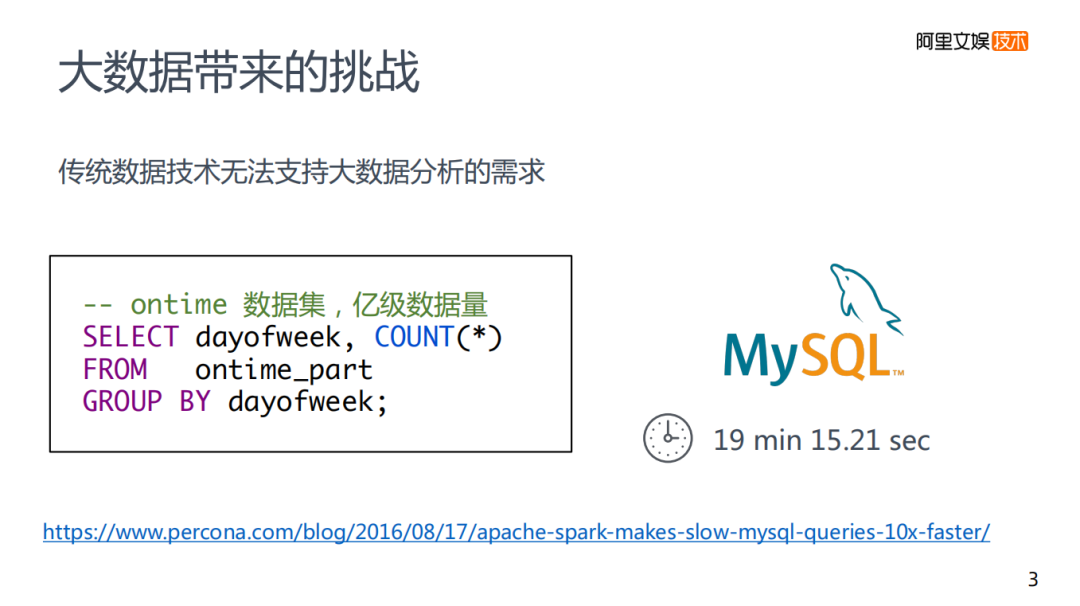
在實(shí)際應(yīng)用中的數(shù)據(jù)處理速度,假定是億級數(shù)據(jù)量,如果使用傳統(tǒng)的mysql進(jìn)行分析需要耗時19分鐘。
2. 應(yīng)對挑戰(zhàn)
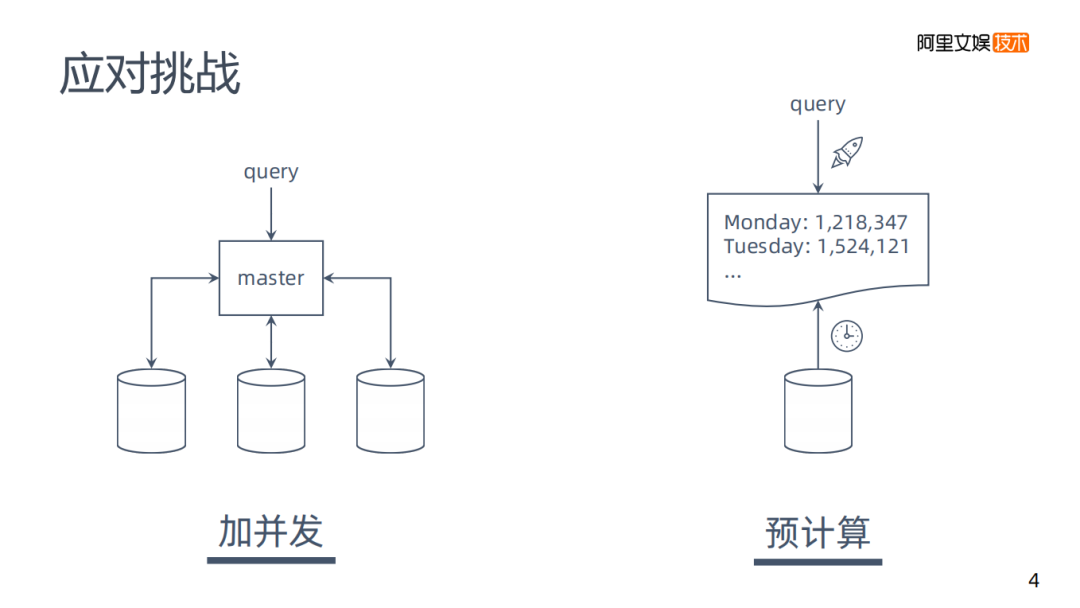
那遇到這樣的問題有什么樣的解決方案呢,通過對各OLAP引擎的觀察,我分成了兩大類:
加并發(fā):一個mysql處理需要19分鐘,那么添加多個數(shù)據(jù)實(shí)例并行計(jì)算,來減少時間。但實(shí)現(xiàn)是存在一定困難的。
預(yù)計(jì)算:雖然說19分鐘速度是挺慢的,但是可以在預(yù)定的時間來跑數(shù)據(jù),將數(shù)據(jù)存在性能較好的數(shù)據(jù)庫里,要求是不存在原始的零星數(shù)據(jù)。預(yù)計(jì)算以后再去查詢,速度會有很大改善。
這是我總結(jié)的兩個在大數(shù)據(jù)下處理速度很慢問題的解決方案。下面我們來看看市面上具體的解決方案有哪些。
1. 加并發(fā):MPP架構(gòu)
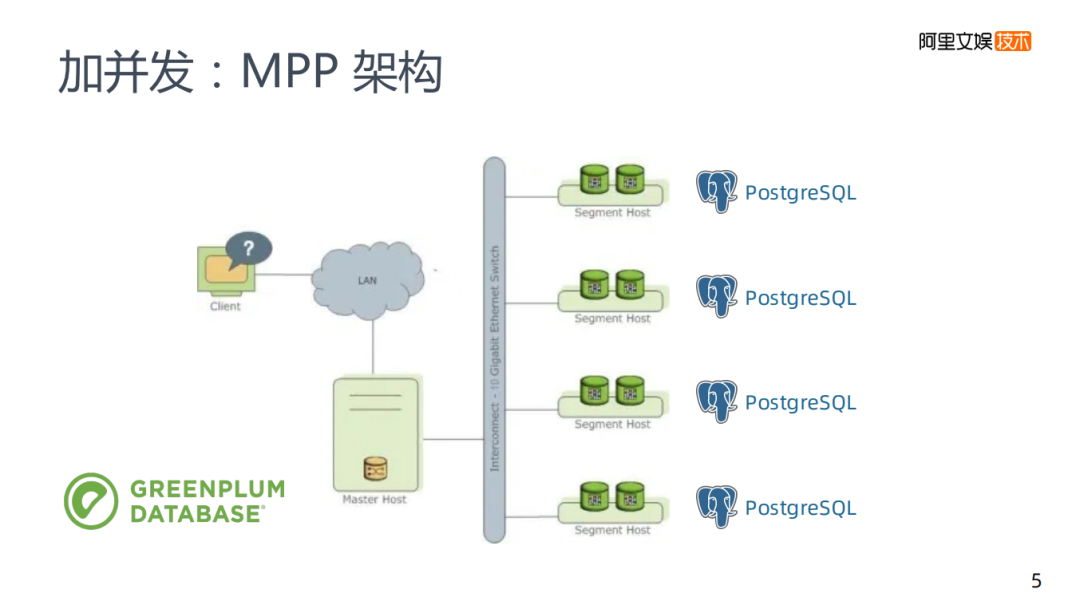
第一類的加并發(fā)方案,類似之前所說的添加多個mysql,GREENPLUM引擎也是基于一個傳統(tǒng)的關(guān)系型數(shù)據(jù)庫PostgreSQL,在GREENPLUM里面有多個PostgreSQL實(shí)例,每個實(shí)例都有Master節(jié)點(diǎn)去管理,再將接收到的請求拆分后分發(fā)到各實(shí)例,再將實(shí)例集中在一起返回,這就是一個MPP架構(gòu)的基本原理。
MPP架構(gòu)的缺陷
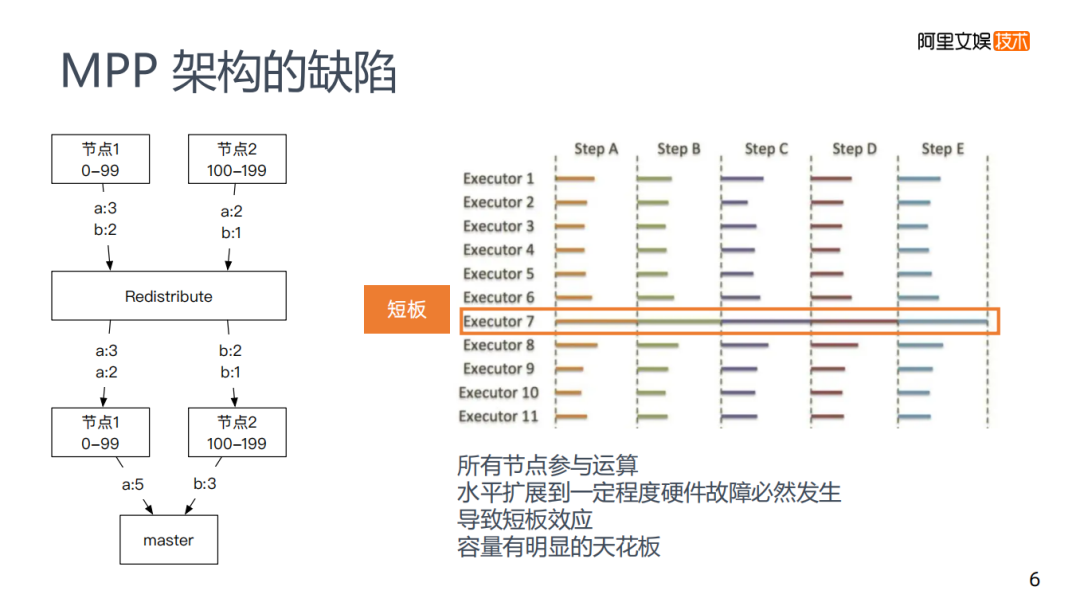
左邊圖是一個GREENPLUM的大致計(jì)算流程。不同的MPP架構(gòu)會有所區(qū)別,但是大致原理都是差不多的,每次計(jì)算是所有節(jié)點(diǎn)都參與計(jì)算。
舉個例子:使用group by將每個節(jié)點(diǎn)上a和b的數(shù)量計(jì)算出來,每個節(jié)點(diǎn)都做這樣的運(yùn)算,計(jì)算完之后會有一個Redistribute的過程,將所有key到一個節(jié)點(diǎn)上再去合并,最后master將數(shù)據(jù)收集起來完成計(jì)算。
存在的問題是所有的節(jié)點(diǎn)都參與計(jì)算,不存在特別強(qiáng)的水平拓展性,如果有千萬級的節(jié)點(diǎn)必然會發(fā)生硬件故障,導(dǎo)致容量存在明顯的天花板。
2. 加并發(fā):批處理架構(gòu)
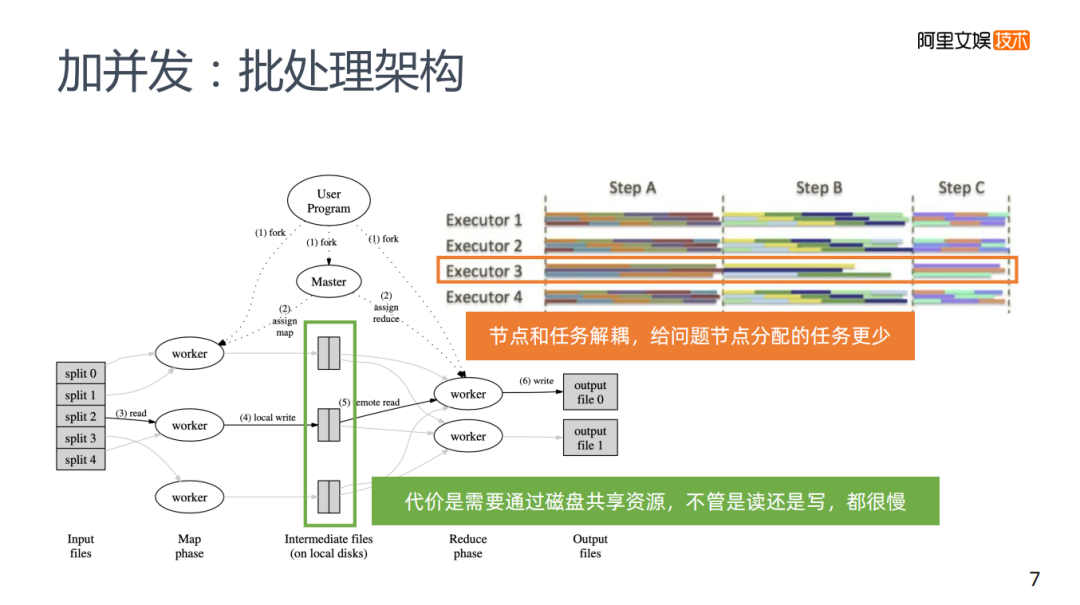
應(yīng)對這樣的問題的解決方案是使用批處理的架構(gòu)來解決。我們平常使用的批處理架構(gòu),MR和Spark,并不需要所有的節(jié)點(diǎn)都參與運(yùn)算,它在一個任務(wù)事件下發(fā)以后,控制節(jié)點(diǎn)會分配給一些集群中的節(jié)點(diǎn),而這些節(jié)點(diǎn)各自完成自己的計(jì)算,然后把計(jì)算結(jié)果寫到磁盤里,再交給下一個計(jì)算的節(jié)點(diǎn)去寫入,每次不需要所有的節(jié)點(diǎn)去參與運(yùn)算。因?yàn)楣?jié)點(diǎn)和它的任務(wù)是解耦的,控制節(jié)點(diǎn)可以調(diào)節(jié)分配任務(wù),來減少短板,大規(guī)模的水平擴(kuò)容不會有太大的問題,但卻需要一定的代價(jià)。
為什么MPP需要所有的節(jié)點(diǎn)去參與運(yùn)算?因?yàn)檫\(yùn)算的結(jié)果還要通過通信的方式給其他節(jié)點(diǎn)來進(jìn)行下一步的計(jì)算,包括資源存儲中各個節(jié)點(diǎn)是不共享的,所以需要所有的節(jié)點(diǎn)參與運(yùn)算。
批處理架構(gòu)需要節(jié)點(diǎn)和任務(wù)去進(jìn)行解耦,解耦的代價(jià)是,需要共享資源,勢必會帶來寫磁盤,不管是讀磁盤還是寫磁盤,相比MPP的通信方式來說顯然會更慢。
3. 批處理&MPP的互補(bǔ)

在實(shí)際使用中,兩者其實(shí)是一個互補(bǔ)的關(guān)系,批處理速度慢,但是它的運(yùn)行處理相對比較健壯,擴(kuò)展性也比較好。適用于離線數(shù)據(jù)清洗。
MPP的速度雖然相對較慢,且容量無法增大,每個部門相應(yīng)的集群資源需要單獨(dú)去搭建。適合于對清洗過的數(shù)據(jù)做交互式查詢。
4. MPP on Hadoop
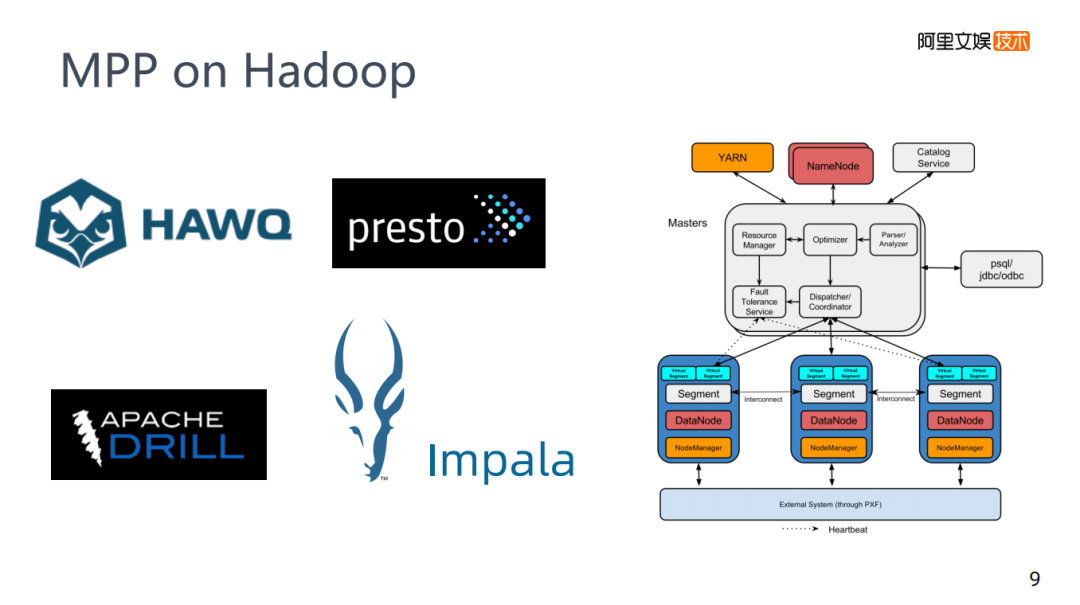
相對于互補(bǔ)的話,MPP on Hadoop就不得不提一下,網(wǎng)易使用Impala,還有相關(guān)的presto這些名字,在這里就把他們歸類為MPP on Hadoop技術(shù)。MPP技術(shù)它是GREENPLUM,它的各個節(jié)點(diǎn)是傳統(tǒng)關(guān)系型數(shù)據(jù)庫postgre。比如,剛才場景中是先批處理再M(fèi)PP,如果想用GREENPLUM,需要將Hadoop中的數(shù)據(jù)導(dǎo)入到GREENPLUM中,因?yàn)樗鼈兊讓拥拇鎯κ遣灰粯拥模琀adoop底層是HDFS,而GREENLUM底層是postgre,它們的存儲上是沒有關(guān)系的,必須要有一個導(dǎo)入的過程,正常來說Hadoop的生態(tài),Hive是一個常用的批處理技術(shù),它的速度比較慢,為了加速計(jì)算,就誕生了MPP on Hadoop這樣的技術(shù)。
這些技術(shù)大部分沒有自己的存儲,是一個類MPP的架構(gòu),需要控制節(jié)點(diǎn)把任務(wù)下發(fā)到對應(yīng)的MPP的任務(wù)節(jié)點(diǎn)上,而在MPP節(jié)點(diǎn)的底層是HDFS,等于是這兩者的一個結(jié)合,實(shí)際運(yùn)用起來查詢會比Hive更快一些。
5. 預(yù)計(jì)算
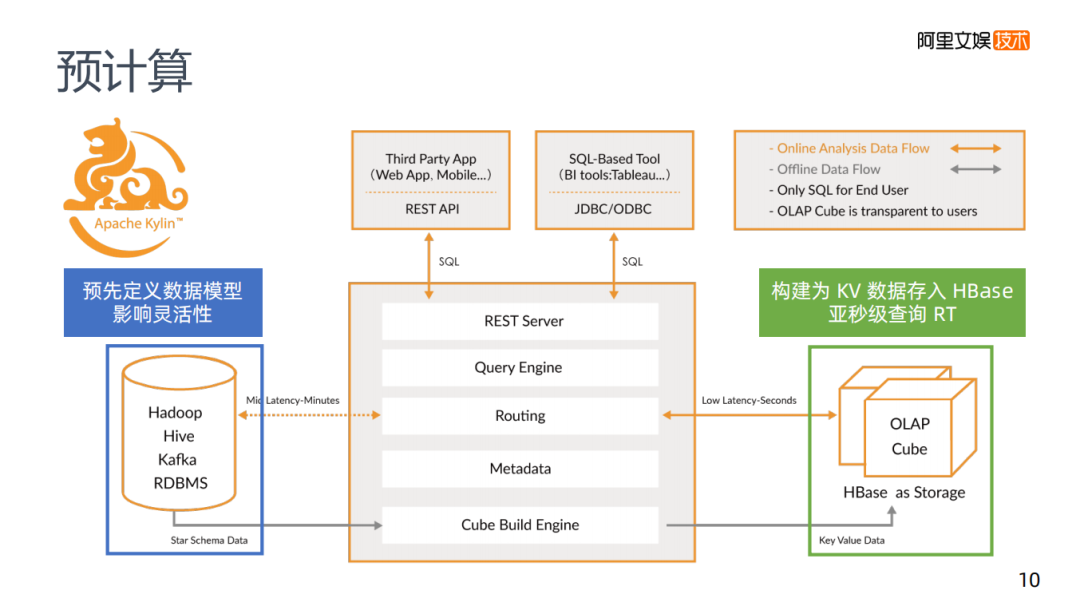
講到預(yù)計(jì)算,就不得不提到Apache Kylin,它的架構(gòu)如圖,需要預(yù)先定義查詢的內(nèi)容。
比如說我要對某個Key進(jìn)行計(jì)算,計(jì)算出A的數(shù)量,將其存在Kylin底下的HBase,它的Key是某某維度等于A,value等于A的值,因?yàn)檫@個Key還可能等于B,所以這個B的數(shù)據(jù)也存在HBase中,要達(dá)到這種情況,首先與Kylin之間一定要有一個交互式的協(xié)議,告訴它那些東西是我需要去查的,幫我做好計(jì)算。因?yàn)轭A(yù)計(jì)算中,當(dāng)維度特別多的時候,是無法枚舉所有要查詢的東西,所以你要預(yù)先定義好Kylin,這在Kylin中叫做Cube,就是要定義你的Cube模型,告訴Kylin你的查詢模式是怎么樣的,而Kylin會根據(jù)定義的數(shù)據(jù)模型,去生成對應(yīng)的Hive任務(wù),Hive任務(wù)會根據(jù)模型規(guī)則去完成計(jì)算,計(jì)算好之后寫入HBase里,在HBase中每一個查詢對應(yīng)一個Key,查詢速度會很快。
這個方案繞過了大數(shù)據(jù)查詢下會比較慢的問題,變成了一個HBase查詢的問題,構(gòu)建為KV數(shù)據(jù)存入HBase里,基本上可以達(dá)到一個亞秒級別的查詢,MPP的話當(dāng)數(shù)據(jù)量比較大時,需要幾十秒,使用Kylin基本上是一個亞秒級的RT。但我們需要預(yù)先去定義一個數(shù)據(jù)模型,肯定會影響數(shù)據(jù)的靈活性。
比如播放的數(shù)據(jù)有沒有發(fā)生卡頓,或者節(jié)點(diǎn)狀況。我們在查詢數(shù)據(jù)時,有分省份的查詢,有分運(yùn)營商的查詢,要告訴Kylin要分省份的去查,分運(yùn)營商的去查,還是需要省份和運(yùn)營商交叉去查,如果沒有明確,當(dāng)臨時的查詢使用Kylin是達(dá)不到對應(yīng)的效果的。業(yè)務(wù)上經(jīng)常有變化,重新通過Hive去刷新任務(wù),重新計(jì)算結(jié)果并寫入HBase,這本身就是一個非常費(fèi)時費(fèi)力的過程,是一個變化比較大的業(yè)務(wù)。另外在維度的復(fù)雜性上也是沒有上限,比如十幾個維度都要各自交叉,都要去交互到很深的話,這個模式其實(shí)是沒有辦法支持,它的預(yù)計(jì)算結(jié)果會膨脹的特別厲害,可能會比原來的數(shù)據(jù)還要多,這時就無法進(jìn)行下去。
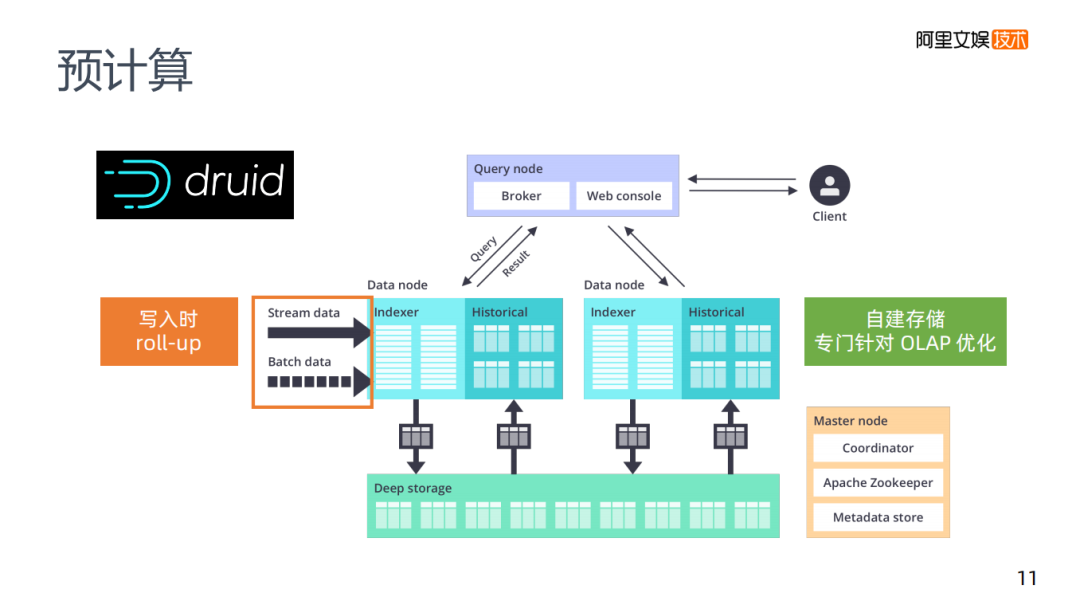
預(yù)計(jì)算還要介紹的是druid,將其歸類為預(yù)計(jì)算并不是特別明確,它有預(yù)計(jì)算的能力,當(dāng)數(shù)據(jù)寫入時,它有一個roll-up這樣的配置,在第一步數(shù)據(jù)寫入時會幫助你進(jìn)行一個數(shù)據(jù)減少的工作,在它本身內(nèi)部的架構(gòu)里,它不是Kylin需要HBase這樣的存儲,druid內(nèi)部有一個自己的存儲,專門針對OLAP進(jìn)行了優(yōu)化。druid還是一個時序的存儲,在時序上做優(yōu)化,讓老的數(shù)據(jù)存在老的存儲里,新的數(shù)據(jù)存在新的存儲里。在預(yù)計(jì)算和查詢的靈活性方面,如果說只能夠選擇一套方案的話,可以考慮只使用druid。
6. OLAP方案綜述
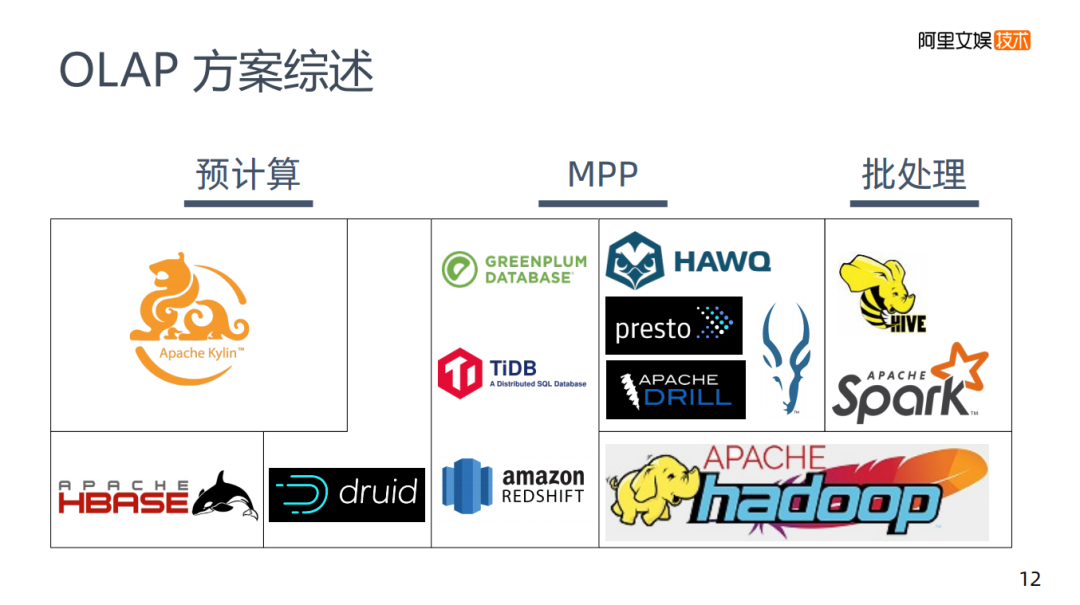
在這里將所說過的OLAP方案綜述一下,將市面上的OLAP分為兩種:
通過加并發(fā)的方式來解決問題:MPP架構(gòu)和批處理架構(gòu)
通過預(yù)計(jì)算來解決問題
圖中是市面上常見的OLAP,縱向是不同的架構(gòu)類型,橫向是查詢和存儲的關(guān)系。
Kylin可以說是一個計(jì)算框架,因?yàn)樗讓拥拇鎯κ褂玫氖荋Base,用Kylin來解決數(shù)據(jù)如何建模的問題。
再往右就是druid,它本身有預(yù)計(jì)算的能力是自建存儲的。比如說美團(tuán)做了一個Kylin on druid這樣的工作,計(jì)算仍然是Kylin,但是它把底層的HBase換成druid,這樣做的考慮將druid和HBase比較,實(shí)際在查詢的能力方面還是要強(qiáng)不少的。
GREENPLUM和TiDB或者amazon更偏向于傳統(tǒng)架構(gòu),都是關(guān)系型的數(shù)據(jù)庫,需要有自己的存儲。
再往右就是基于HDFS的架構(gòu),HIVE和Spark都是基礎(chǔ)HDFS上做的批處理。
1. 實(shí)戰(zhàn)性場景
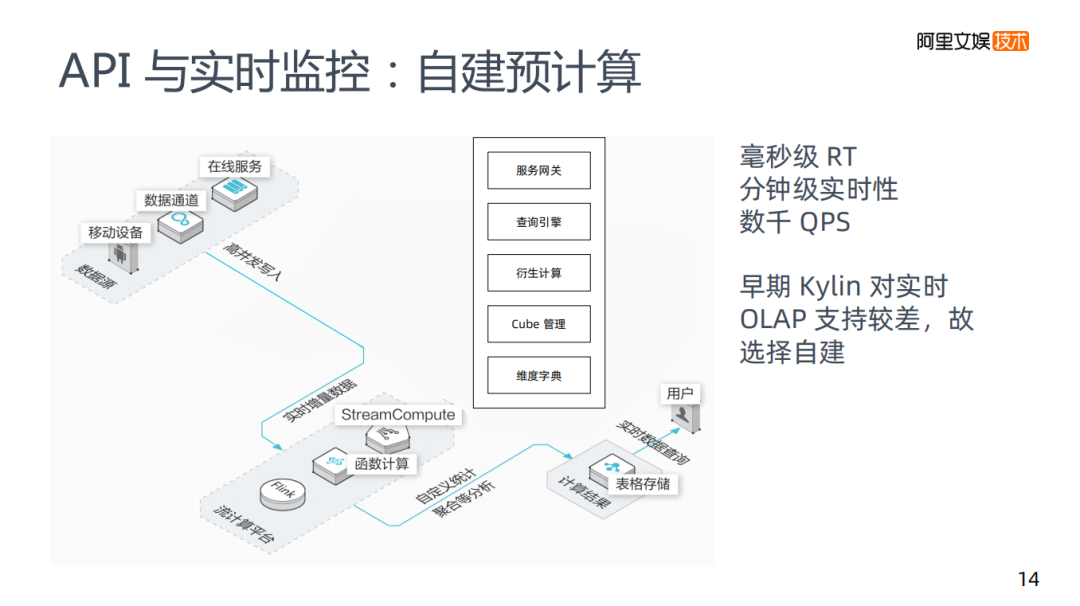
第一類場景是API與實(shí)時監(jiān)控:API是系統(tǒng)訪問,比如在我們的推薦系統(tǒng)里,需要用到一些實(shí)時特征,如用戶截至目前曝光了多少次,會存在非常大的QPS,以及對RT要求很高,數(shù)據(jù)也要有分鐘級的實(shí)時性要求。API與實(shí)時監(jiān)控,目前在優(yōu)酷是自建的預(yù)計(jì)算系統(tǒng)。
為什么早期沒有使用Kylin,是因?yàn)閷?shí)時OLAP當(dāng)時支持較差。Kylin和Hive還是有很強(qiáng)的依賴的。首先就是數(shù)據(jù)的收集,業(yè)界一般主要使用kafka,這里使用類似Kafka這種消息隊(duì)列,會把流式的信息導(dǎo)入進(jìn)來,流計(jì)算使用Flink,內(nèi)部也存在Cube管理這樣類似的協(xié)議,聚合得到和Kylin一樣的KV結(jié)構(gòu)數(shù)據(jù),存儲在阿里的表格存儲里,和HBase差別比較小,然后用戶去讀取數(shù)據(jù)。
從思路上來說和Kylin差別不是很大,在預(yù)計(jì)算系統(tǒng)里面我們會提供一些網(wǎng)關(guān)服務(wù),因?yàn)橐獙ν馓峁〢PI,如果是報(bào)表的話也要根據(jù)報(bào)表平臺來訪問的,然后會有自己的查詢引擎,解析類SQL這樣的語法,把它解析成表格存儲里面的數(shù)據(jù)。
另外也做了一塊叫做維度計(jì)算,針對業(yè)務(wù)上變化速度快,也會嘗試在KV結(jié)構(gòu)上做計(jì)算,可能包括一些數(shù)學(xué)運(yùn)算。
最后一個是維度字典,在實(shí)際使用中是非常重要的。比如版本的維度一直在變化,如果是在這樣一個HIVE的平臺里,可能使用Groupby可以查出具體版本,在將數(shù)據(jù)進(jìn)行預(yù)計(jì)算后,存儲在類似HBase的KV存儲中。制作維度字典對應(yīng)用性有比較好的提高,
2. BI報(bào)表:批處理+MPP
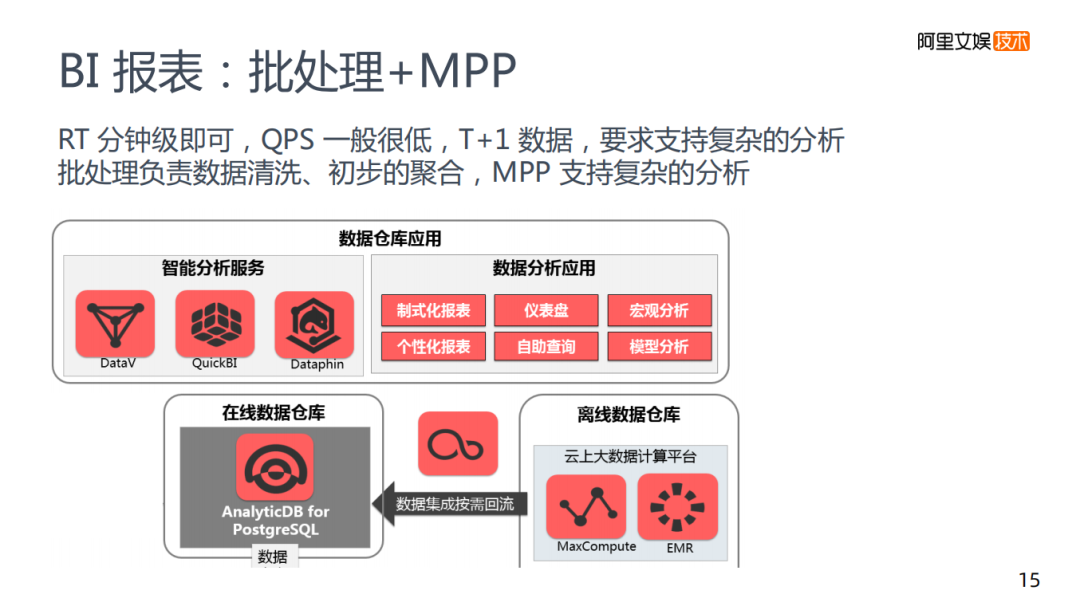
第二類是BI報(bào)表,是批處理+MPP組合的形式,其中對業(yè)務(wù)中的RT和QPS要求不高,重點(diǎn)在于需要支持非常復(fù)雜的分析,最好使用的方案其實(shí)是批處理+MPP,批處理這層主要是進(jìn)行數(shù)據(jù)清洗初步的聚合,如果是優(yōu)酷的數(shù)據(jù)量,基本上是一分鐘兩分鐘這種級別,速度上較慢。
通過對業(yè)務(wù)的理解,將關(guān)鍵的數(shù)據(jù)保留,通過批處理預(yù)先建好DWS層的模式處理,在這基礎(chǔ)之上,往MPP的表中導(dǎo)入從而支持這個復(fù)雜的分析,底層的架構(gòu)是一個離線的批處理的計(jì)算,批處理完成之后將數(shù)據(jù)放入離線的表中,并導(dǎo)入到阿里的數(shù)倉,使用MPP的數(shù)倉來支持,以及BI類工具來支持我們的業(yè)務(wù)需求,滿足復(fù)雜分析的要求。
3. 實(shí)時ad-hoc:類似ELK

第三類場景是實(shí)時查詢的一種場景,跟剛才的BI類又不相同,主要發(fā)生在優(yōu)酷性能的統(tǒng)計(jì)數(shù)據(jù)里面,在這個場景下我們一般做預(yù)計(jì)算,但偏向?qū)崟r的,分析比較復(fù)雜,通常適用于故障定位的場景。
比如如何去定位查找錯誤,查找機(jī)房存在問題,這都是一些比較常見的場景。這個場景對RT的要求較好。RT和QPS方面沒有API要求那么高,它的用戶人數(shù)也不是那么多,沒有一些高并發(fā)的場景,但是對數(shù)據(jù)的實(shí)時性和分析的復(fù)雜性還是存在要求的,這種的預(yù)計(jì)算也不大可能去滿足,為解決這類問題,我們做的是一個類似ELK的方案。
首先是需要收集log,在收集的過程中要做數(shù)據(jù)清洗,將數(shù)據(jù)存到es中,es在大數(shù)據(jù)里面也是比較常用的,適用于故障排查的場景,搜索關(guān)鍵詞、模糊搜索等。es的聚合能力,過濾能力都是相對比較經(jīng)典的。但確實(shí)模糊查詢也沒有很刻意的提出這個概念,甚至有些不支持模糊查詢,比如說Kylin,es主打是模糊查詢,但是es也實(shí)現(xiàn)了聚合功能,因?yàn)閑s里面是json,json里面某個字段,這個字段有多少Key,聚合以后有多少個,這種它也是能夠做的。而join就相對較差,它不是一個非常完備,但是在這種重聚合,過濾夾帶一些模糊查詢的的情況下,還是比較適合做一個引擎。在es后是一個Kibana,但我們使用的不是Kibana,是使用內(nèi)部的BI工具。
在這種場景下,當(dāng)錯誤發(fā)生了,我們可以很快的定位到錯誤位置,實(shí)現(xiàn)實(shí)時查詢的能力。