
一文深層解決模型過擬合
一、過擬合的本質(zhì)及現(xiàn)象
過擬合是指模型只過分地匹配特定訓(xùn)練數(shù)據(jù)集,以至于對訓(xùn)練集外數(shù)據(jù)無良好地擬合及預(yù)測。其本質(zhì)原因是模型從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)到了一些統(tǒng)計噪聲,即這部分信息僅是局部數(shù)據(jù)的統(tǒng)計規(guī)律,該信息沒有代表性,在訓(xùn)練集上雖然效果很好,但未知的數(shù)據(jù)集(測試集)并不適用。
1.1 評估擬合效果
 通常由訓(xùn)練誤差及測試誤差(泛化誤差)評估模型的學(xué)習(xí)程度及泛化能力。
通常由訓(xùn)練誤差及測試誤差(泛化誤差)評估模型的學(xué)習(xí)程度及泛化能力。
欠擬合時訓(xùn)練誤差和測試誤差在均較高,隨著訓(xùn)練時間及模型復(fù)雜度的增加而下降。在到達(dá)一個擬合最優(yōu)的臨界點之后,訓(xùn)練誤差下降,測試誤差上升,這個時候就進(jìn)入了過擬合區(qū)域。它們的誤差情況差異如下表所示: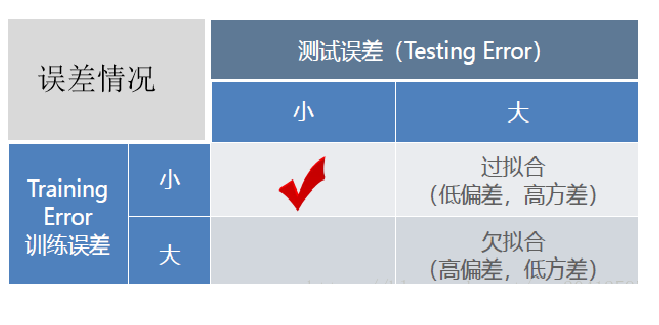
1.2 擬合效果的深入分析
對于擬合效果除了通過訓(xùn)練、測試的誤差估計其泛化誤差及判斷擬合程度之外,我們往往還希望了解它為什么具有這樣的泛化性能。統(tǒng)計學(xué)常用“偏差-方差分解”(bias-variance decomposition)來分析模型的泛化性能:泛化誤差為偏差+方差+噪聲之和。

噪聲(ε) 表達(dá)了在當(dāng)前任務(wù)上任何學(xué)習(xí)算法所能達(dá)到的泛化誤差的下界,即刻畫了學(xué)習(xí)問題本身(客觀存在)的難度。
偏差(bias) 是指用所有可能的訓(xùn)練數(shù)據(jù)集訓(xùn)練出的所有模型的輸出值與真實值之間的差異,刻畫了模型的擬合能力。偏差較小即模型預(yù)測準(zhǔn)確度越高,表示模型擬合程度越高。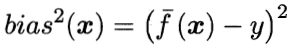
方差(variance) 是指不同的訓(xùn)練數(shù)據(jù)集訓(xùn)練出的模型對同預(yù)測樣本輸出值之間的差異,刻畫了訓(xùn)練數(shù)據(jù)擾動所造成的影響。方差較大即模型預(yù)測值越不穩(wěn)定,表示模型(過)擬合程度越高,受訓(xùn)練集擾動影響越大。 如下用靶心圖形象表示不同方差及偏差下模型預(yù)測的差異:
如下用靶心圖形象表示不同方差及偏差下模型預(yù)測的差異:
偏差越小,模型預(yù)測值與目標(biāo)值差異越小,預(yù)測值越準(zhǔn)確;
方差越小,不同的訓(xùn)練數(shù)據(jù)集訓(xùn)練出的模型對同預(yù)測樣本預(yù)測值差異越小,預(yù)測值越集中;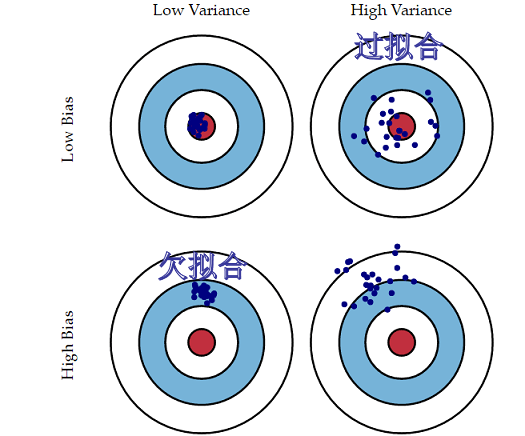
“偏差-方差分解” 說明,模型擬合過程的泛化性能是由學(xué)習(xí)算法的能力、數(shù)據(jù)的充分性以及學(xué)習(xí)任務(wù)本身的難度所共同決定的。
當(dāng)模型欠擬合時:模型準(zhǔn)確度不高(高偏差),受訓(xùn)練數(shù)據(jù)的擾動影響較小(低方差),其泛化誤差大主要由高的偏差導(dǎo)致。
當(dāng)模型過擬合時:模型準(zhǔn)確度較高(低偏差),模型容易學(xué)習(xí)到訓(xùn)練數(shù)據(jù)擾動的噪音(高方差),其泛化誤差大由高的方差導(dǎo)致。
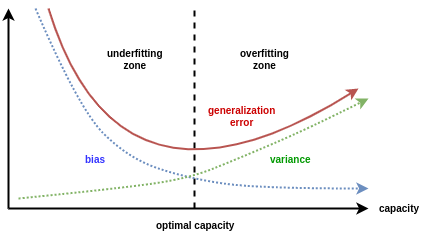 實踐中通常欠擬合不是問題,可以通過使用強(qiáng)特征及較復(fù)雜的模型提高學(xué)習(xí)的準(zhǔn)確度。而解決過擬合,即如何減少泛化誤差,提高泛化能力,通常才是優(yōu)化模型效果的重點。
實踐中通常欠擬合不是問題,可以通過使用強(qiáng)特征及較復(fù)雜的模型提高學(xué)習(xí)的準(zhǔn)確度。而解決過擬合,即如何減少泛化誤差,提高泛化能力,通常才是優(yōu)化模型效果的重點。
二、如何解決過擬合
2.1 解決思路
上文說到學(xué)習(xí)統(tǒng)計噪聲是過擬合的本質(zhì)原因,而模型學(xué)習(xí)是以經(jīng)驗損失最小化,現(xiàn)實中學(xué)習(xí)的訓(xùn)練數(shù)據(jù)難免有統(tǒng)計噪音的。一個簡單的思路,通過提高數(shù)據(jù)量數(shù)量或者質(zhì)量解決統(tǒng)計噪音的影響:
通過足夠的數(shù)據(jù)量就可以有效區(qū)分哪些信息是片面的,然而現(xiàn)實情況數(shù)據(jù)通常都很有限的。
通過提高數(shù)據(jù)的質(zhì)量,可以結(jié)合先驗知識加工特征以及對數(shù)據(jù)中噪聲進(jìn)行剔除(噪聲如訓(xùn)練集有個“用戶編號尾數(shù)是否為9”的特征下,偶然有正樣本的占比很高的現(xiàn)象,而憑業(yè)務(wù)知識理解這個特征是沒有意義的噪聲,就可以考慮剔除)。但這樣,一來過于依賴人工,人工智障?二來先驗領(lǐng)域知識過多的引入,如果領(lǐng)域知識有誤,不也是噪聲。
當(dāng)數(shù)據(jù)層面的優(yōu)化有限,接下來登場主流的方法——正則化策略。
在以(可能)增加經(jīng)驗損失為代價,以降低泛化誤差為目的,解決過擬合,提高模型泛化能力的方法,統(tǒng)稱為正則化策略。
2.2 常見的正則化策略及原理
本節(jié)嘗試以不一樣的角度去理解正則化策略,歡迎留言交流。
正則化策略經(jīng)常解讀為對模型結(jié)構(gòu)風(fēng)險的懲罰,崇尚簡單模型。并不盡然!如前文所講學(xué)到統(tǒng)計噪聲是過擬合的本質(zhì)原因,所以模型復(fù)雜度容易引起過擬合(只是影響因素)。然而工程中,對于困難的任務(wù)需要足夠復(fù)雜的模型,這種情況縮減模型復(fù)雜度不就和“減智商”一樣?所以,通常足夠復(fù)雜且有正則化的模型才是我們追求的,且正則化不是只有減少模型容量這方式。
機(jī)器學(xué)習(xí)是從訓(xùn)練集經(jīng)驗損失最小化為學(xué)習(xí)目標(biāo),而學(xué)習(xí)的訓(xùn)練集里面不可避免有統(tǒng)計噪聲。除了提高數(shù)據(jù)質(zhì)量和數(shù)量方法,我們不也可以在模型學(xué)習(xí)的過程中,給一些指導(dǎo)性的先驗假設(shè)(即根據(jù)一些已知的知識對參數(shù)的分布進(jìn)行一定的假設(shè)),幫助模型更好避開一些“噪聲”的信息并關(guān)注到本質(zhì)特征,更好地學(xué)習(xí)模型結(jié)構(gòu)及參數(shù)。這些指導(dǎo)性的先驗假設(shè),也就是正則化策略,常見的正則化策略如下:
L2 正則化
L2 參數(shù)正則化 (也稱為嶺回歸、Tikhonov 正則) 通常被稱為權(quán)重衰減 (weight decay),是通過向?標(biāo)函數(shù)添加?個正則項 ?(θ) ,使權(quán)重更加接近原點,模型更為簡單(容器更小)。從貝葉斯角度,L2的約束項可以視為模型參數(shù)引入先驗的高斯分布(參見Bob Carpenter的 Lazy Sparse Stochastic Gradient Descent for Regularized )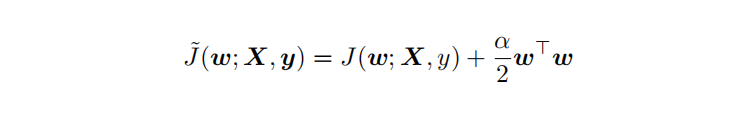 對帶L2目標(biāo)函數(shù)的模型參數(shù)更新權(quán)重,?學(xué)習(xí)率:
對帶L2目標(biāo)函數(shù)的模型參數(shù)更新權(quán)重,?學(xué)習(xí)率: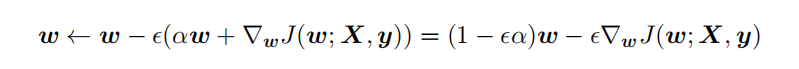
從上式可以看出,加?權(quán)重衰減后會導(dǎo)致學(xué)習(xí)規(guī)則的修改,即在每步執(zhí)?梯度更新前先收縮權(quán)重 (乘以 1 ? ?α ),有權(quán)重衰減的效果,但是w比較不容易為0。
L1 正則化
L1 正則化(Lasso回歸)是通過向?標(biāo)函數(shù)添加?個參數(shù)懲罰項 ?(θ),為各個參數(shù)的絕對值之和。從貝葉斯角度,L1的約束項也可以視為模型參數(shù)引入拉普拉斯分布。

對帶L1目標(biāo)函數(shù)的模型參數(shù)更新權(quán)重(其中 sgn(x) 為符號函數(shù),取參數(shù)的正負(fù)號): 可見,在-αsgn(w)項的作用下, w各元素每步更新后的權(quán)重向量都會平穩(wěn)地向0靠攏,w的部分元素容易為0,造成稀疏性。模型更簡單,容器更小。
可見,在-αsgn(w)項的作用下, w各元素每步更新后的權(quán)重向量都會平穩(wěn)地向0靠攏,w的部分元素容易為0,造成稀疏性。模型更簡單,容器更小。
對比L1,L2,兩者的有效性都體現(xiàn)在限制了模型的解空間w,降低了模型復(fù)雜度(容量)。L2范式約束具有產(chǎn)生平滑解的效果,沒有稀疏解的能力,即參數(shù)并不會出現(xiàn)很多零。假設(shè)我們的決策結(jié)果與兩個特征有關(guān),L2正則傾向于綜合兩者的影響(可以看作符合bagging多釋準(zhǔn)則的先驗),給影響大的特征賦予高的權(quán)重;而L1正則傾向于選擇影響較大的參數(shù),而盡可能舍棄掉影響較小的那個( 可以看作符合了“奧卡姆剃刀定律--如無必要勿增實體”的先驗)。在實際應(yīng)用中 L2正則表現(xiàn)往往會優(yōu)于 L1正則,但 L1正則會壓縮模型,降低計算量。

在Keras中,可以使用regularizers模塊來在某個層上應(yīng)用L1及L2正則化,如下代碼:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l1_l2(l1=α1, l2=α2) # α為超參數(shù)懲罰系數(shù)
earlystop
earlystop(早停法)可以限制模型最小化代價函數(shù)所需的訓(xùn)練迭代次數(shù),如果迭代次數(shù)太少,算法容易欠擬合(方差較小,偏差較大),而迭代次數(shù)太多,算法容易過擬合(方差較大,偏差較小),早停法通過確定迭代次數(shù)解決這個問題。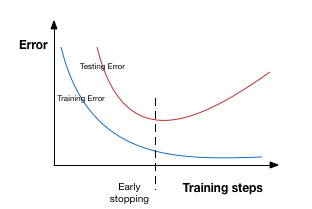 earlystop可認(rèn)為是將優(yōu)化過程的參數(shù)空間限制在初始參數(shù)值 θ0 的小鄰域內(nèi)(Bishop 1995a 和Sj?berg and Ljung 1995 ),在這角度上相當(dāng)于L2正則化的作用。
earlystop可認(rèn)為是將優(yōu)化過程的參數(shù)空間限制在初始參數(shù)值 θ0 的小鄰域內(nèi)(Bishop 1995a 和Sj?berg and Ljung 1995 ),在這角度上相當(dāng)于L2正則化的作用。
在Keras中,可以使用callbacks函數(shù)實現(xiàn)早期停止,如下代碼:
from keras.callbacks import EarlyStopping
callback =EarlyStopping(monitor='loss', patience=3)
model = keras.models.Sequential([tf.keras.layers.Dense(10)])
model.compile(keras.optimizers.SGD(), loss='mse')
history = model.fit(np.arange(100).reshape(5, 20), np.zeros(5),
epochs=10, batch_size=1, callbacks=[callback],
verbose=0)
數(shù)據(jù)增強(qiáng)
數(shù)據(jù)增強(qiáng)是提升算法性能、滿足深度學(xué)習(xí)模型對大量數(shù)據(jù)的需求的重要工具。數(shù)據(jù)增強(qiáng)通過向訓(xùn)練數(shù)據(jù)添加轉(zhuǎn)換或擾動來增加訓(xùn)練數(shù)據(jù)集。數(shù)據(jù)增強(qiáng)技術(shù)如水平或垂直翻轉(zhuǎn)圖像、裁剪、色彩變換、擴(kuò)展和旋轉(zhuǎn)(此外還有生成模型偽造的對抗樣本),通常應(yīng)用在視覺表象和圖像分類中,通過數(shù)據(jù)增強(qiáng)有助于更準(zhǔn)確的學(xué)習(xí)到輸入數(shù)據(jù)所分布的流形(manifold)。
在keras中,你可以使用ImageDataGenerator來實現(xiàn)上述的圖像變換數(shù)據(jù)增強(qiáng),如下代碼:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal_flip=True)
datagen.fit(train)
引入噪聲
與清洗數(shù)據(jù)的噪音相反,引入噪聲也可以明顯增加神經(jīng)網(wǎng)絡(luò)模型的魯棒性(很像是以毒攻毒)。對于某些模型而言,向輸入添加方差極小的噪聲等價于對權(quán)重施加范數(shù)懲罰 (Bishop, 1995a,b)。常用有三種方式:
在輸入層引入噪聲,可以視為是一種數(shù)據(jù)增強(qiáng)的方法。
在模型權(quán)重引入噪聲
這項技術(shù)主要用于循環(huán)神經(jīng)網(wǎng)絡(luò) (Jim et al., 1996; Graves, 2011)。向網(wǎng)絡(luò)權(quán)重注入噪聲,其代價函數(shù)等于無噪聲注入的代價函數(shù)加上一個與噪聲方差成正比的參數(shù)正則化項。
在標(biāo)簽引入噪聲
原實際標(biāo)簽y可能多少含有噪聲,當(dāng) y 是錯誤的,直接使用0或1作為標(biāo)簽,對最大化 log p(y | x)效果變差。另外,使用softmax 函數(shù)和最大似然目標(biāo),可能永遠(yuǎn)無法真正輸出預(yù)測值為 0 或 1,因此它會繼續(xù)學(xué)習(xí)越來越大的權(quán)重,使預(yù)測更極端。使用標(biāo)簽平滑的優(yōu)勢是能防止模型追求具體概率又不妨礙正確分類。如標(biāo)簽平滑 (label smoothing) 基于 k 個輸出的softmax 函數(shù),把明確分類 0 和 1 替換成 ? /(k?1) 和 1 ? ?,對模型進(jìn)行正則化。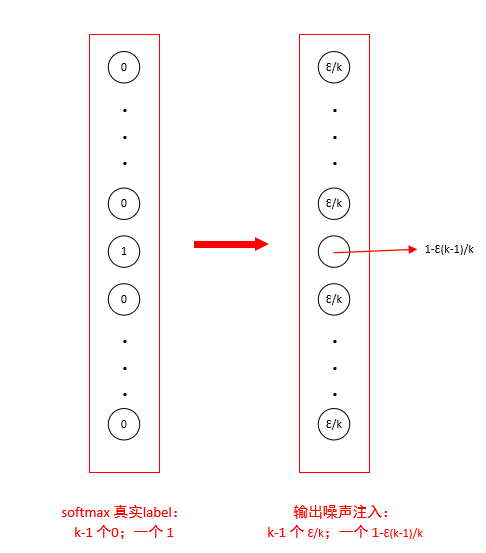
半監(jiān)督學(xué)習(xí)
半監(jiān)督學(xué)習(xí)思想是在標(biāo)記樣本數(shù)量較少的情況下,通過在模型訓(xùn)練中直接引入無標(biāo)記樣本,以充分捕捉數(shù)據(jù)整體潛在分布,以改善如傳統(tǒng)無監(jiān)督學(xué)習(xí)過程盲目性、監(jiān)督學(xué)習(xí)在訓(xùn)練樣本不足導(dǎo)致的學(xué)習(xí)效果不佳的問題 。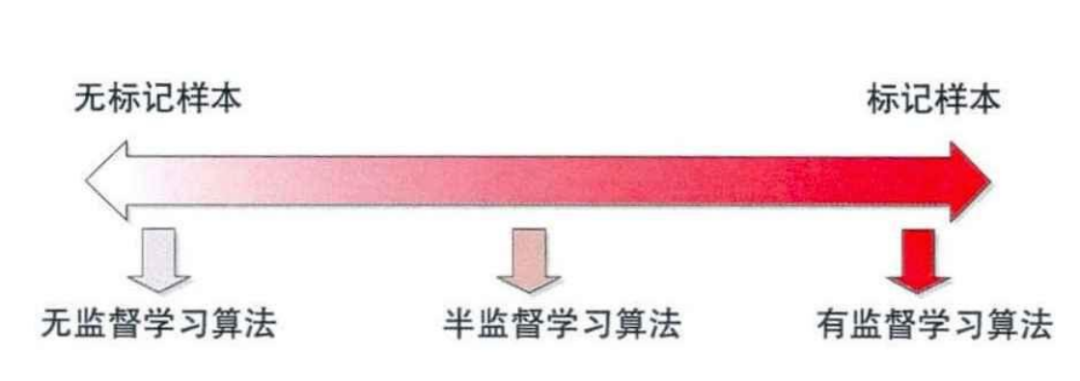 依據(jù)“流形假設(shè)——觀察到的數(shù)據(jù)實際上是由一個低維流形映射到高維空間上的。由于數(shù)據(jù)內(nèi)部特征的限制,一些高維中的數(shù)據(jù)會產(chǎn)生維度上的冗余,實際上只需要比較低的維度就能唯一地表示”,無標(biāo)簽數(shù)據(jù)相當(dāng)于提供了一種正則化(regularization),有助于更準(zhǔn)確的學(xué)習(xí)到輸入數(shù)據(jù)所分布的流形(manifold),而這個低維流形就是數(shù)據(jù)的本質(zhì)表示。
依據(jù)“流形假設(shè)——觀察到的數(shù)據(jù)實際上是由一個低維流形映射到高維空間上的。由于數(shù)據(jù)內(nèi)部特征的限制,一些高維中的數(shù)據(jù)會產(chǎn)生維度上的冗余,實際上只需要比較低的維度就能唯一地表示”,無標(biāo)簽數(shù)據(jù)相當(dāng)于提供了一種正則化(regularization),有助于更準(zhǔn)確的學(xué)習(xí)到輸入數(shù)據(jù)所分布的流形(manifold),而這個低維流形就是數(shù)據(jù)的本質(zhì)表示。
多任務(wù)學(xué)習(xí)
多任務(wù)學(xué)習(xí)(Caruana, 1993) 是通過合并幾個任務(wù)中的樣例(可以視為對參數(shù)施加的軟約束)來提高泛化的一種方法,其引入一個先驗假設(shè):這些不同的任務(wù)中,能解釋數(shù)據(jù)變化的因子是跨任務(wù)共享的。常見有兩種方式:基于參數(shù)的共享及基于正則化的共享。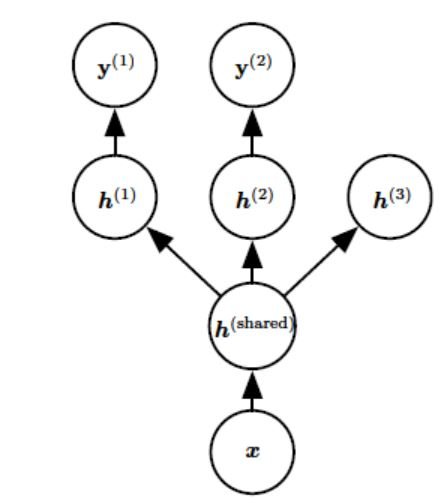
額外的訓(xùn)練樣本以同樣的方式將模型的參數(shù)推向泛化更好的方向,當(dāng)模型的一部分在任務(wù)之間共享時,模型的這一部分更多地被約束為良好的值(假設(shè)共享是合理的),往往能更好地泛化。
bagging
bagging是機(jī)器學(xué)習(xí)集成學(xué)習(xí)的一種。依據(jù)多釋準(zhǔn)則,結(jié)合了多個模型(符合經(jīng)驗觀察的假設(shè))的決策達(dá)到更好效果。具體如類似隨機(jī)森林的思路,對原始的m個訓(xùn)練樣本進(jìn)行有放回隨機(jī)采樣,構(gòu)建t組m個樣本的數(shù)據(jù)集,然后分別用這t組數(shù)據(jù)集去訓(xùn)練t個的DNN,最后對t個DNN模型的輸出用加權(quán)平均法或者投票法決定最終輸出。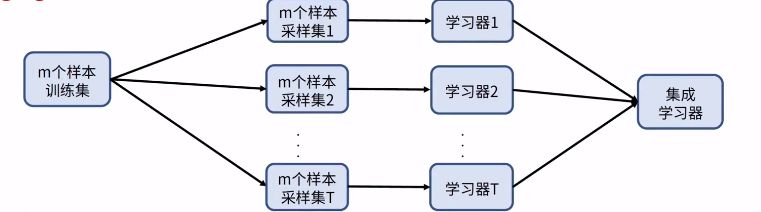
bagging 可以通過平滑效果降低了方差,并中和些噪聲帶來的誤差,因此有更高的泛化能力。
Dropout
Dropout是正則化技術(shù)簡單有趣且有效的方法,在神經(jīng)網(wǎng)絡(luò)很常用。其方法是:在每個迭代過程中,以一定概率p隨機(jī)選擇輸入層或者隱藏層的(通常隱藏層)某些節(jié)點,并且刪除其前向和后向連接(讓這些節(jié)點暫時失效)。權(quán)重的更新不再依賴于有“邏輯關(guān)系”的隱藏層的神經(jīng)元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情況,迫使網(wǎng)絡(luò)學(xué)習(xí)更加魯棒(指系統(tǒng)的健壯性)的特征,達(dá)到減小過擬合的效果。這也可以近似為機(jī)器學(xué)習(xí)中的集成bagging方法,通過bagging多樣的的網(wǎng)絡(luò)結(jié)構(gòu)模型,達(dá)到更好的泛化效果。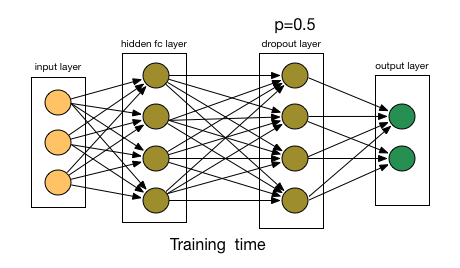 相似的還有Drop Connect ,它和 Dropout 相似的地方在于它涉及在模型結(jié)構(gòu)中引入稀疏性,不同之處在于它引入的是權(quán)重的稀疏性而不是層的輸出向量的稀疏性。
相似的還有Drop Connect ,它和 Dropout 相似的地方在于它涉及在模型結(jié)構(gòu)中引入稀疏性,不同之處在于它引入的是權(quán)重的稀疏性而不是層的輸出向量的稀疏性。
在Keras中,我們可以使用Dropout層實現(xiàn)dropout,代碼如下:
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25)
])
(end)
文章首發(fā)公眾號“算法進(jìn)階”,更多原創(chuàng)文章敬請關(guān)注。
個人github博客:https://github.com/aialgorithm