
一個(gè)入門級(jí)python爬蟲教程詳解

這篇文章主要介紹了一個(gè)入門級(jí)python爬蟲教程詳解,本文給大家介紹的非常詳細(xì),對(duì)大家的學(xué)習(xí)或工作具有一定的參考借鑒價(jià)值,需要的朋友可以參考下
前言
本文目的:根據(jù)本人的習(xí)慣與理解,用最簡潔的表述,介紹爬蟲的定義、組成部分、爬取流程,并講解示例代碼。
基礎(chǔ)
爬蟲的定義:定向抓取互聯(lián)網(wǎng)內(nèi)容(大部分為網(wǎng)頁)、并進(jìn)行自動(dòng)化數(shù)據(jù)處理的程序。主要用于對(duì)松散的海量信息進(jìn)行收集和結(jié)構(gòu)化處理,為數(shù)據(jù)分析和挖掘提供原材料。
今日t條就是一只巨大的“爬蟲”。
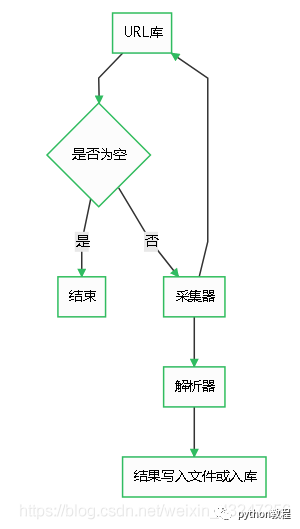
爬蟲由URL庫、采集器、解析器組成。
流程
如果待爬取的url庫不為空,采集器會(huì)自動(dòng)爬取相關(guān)內(nèi)容,并將結(jié)果給到解析器,解析器提取目標(biāo)內(nèi)容后進(jìn)行寫入文件或入庫等操作。
代碼
第一步:寫一個(gè)采集器
如下是一個(gè)比較簡單的采集器函數(shù)。需要用到requests庫。
首先,構(gòu)造一個(gè)http的header,里面有瀏覽器和操作系統(tǒng)等信息。如果沒有這個(gè)偽造的header,可能會(huì)被目標(biāo)網(wǎng)站的WAF等防護(hù)設(shè)備識(shí)別為機(jī)器代碼并干掉。
然后,用requests庫的get方法獲取url內(nèi)容。如果http響應(yīng)代碼是200 ok,說明頁面訪問正常,將該函數(shù)返回值設(shè)置為文本形式的html代碼內(nèi)容。
如果響應(yīng)代碼不是200 ok,說明頁面不能正常訪問,將函數(shù)返回值設(shè)置為特殊字符串或代碼。
第二步:解析器
解析器的作用是對(duì)采集器返回的html代碼進(jìn)行過濾篩選,提取需要的內(nèi)容。
作為一個(gè)14年忠實(shí)用戶,當(dāng)然要用豆瓣舉個(gè)栗子 _
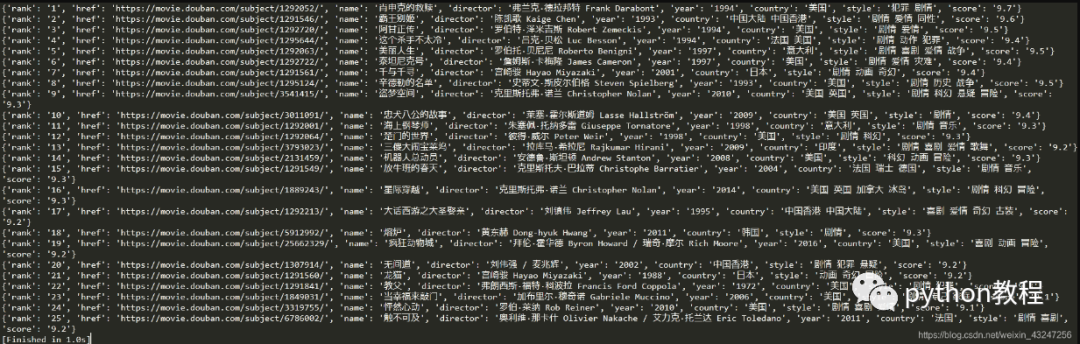
我們計(jì)劃爬取豆瓣排名TOP250電影的8個(gè)參數(shù):排名、電影url鏈接、電影名稱、導(dǎo)演、上映年份、國家、影片類型、評(píng)分。整理成字典并寫入文本文件。
待爬取的頁面如下,每個(gè)頁面包括25部電影,共計(jì)10個(gè)頁面。
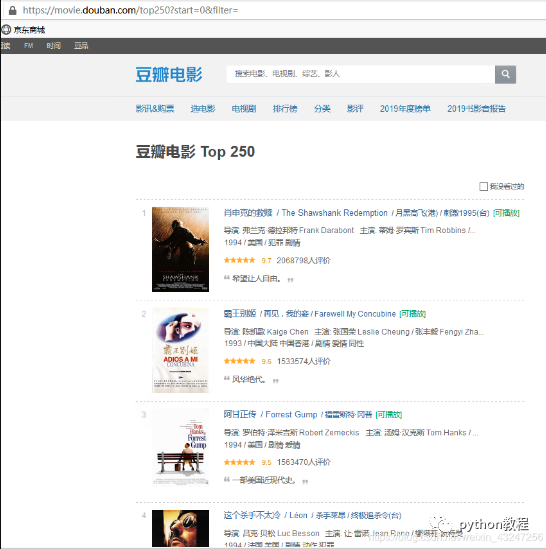
在這里,必須要表揚(yáng)豆瓣的前端工程師們,html標(biāo)簽排版非常工整具有層次,非常便于信息提取。
下面是“肖申克的救贖”所對(duì)應(yīng)的html代碼:(需要提取的8個(gè)參數(shù)用紅線標(biāo)注)
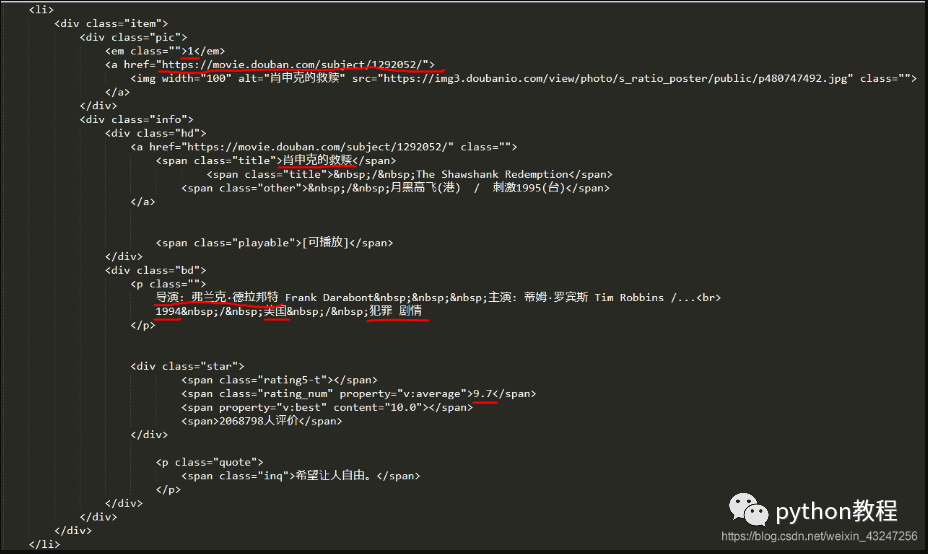
根據(jù)上面的html編寫解析器函數(shù),提取8個(gè)字段。該函數(shù)返回值是一個(gè)可迭代的序列。
我個(gè)人喜歡用re(正則表達(dá)式)提取內(nèi)容。8個(gè)(.*?)分別對(duì)應(yīng)需要提取的字段。

<b id="afajh"><abbr id="afajh"></abbr></b>