
全面綜述:基于3D骨架的深度學(xué)習(xí)行為識(shí)別方法

極市導(dǎo)讀
?本文對(duì)首篇基于3D骨架數(shù)據(jù)的深度學(xué)習(xí)行為識(shí)別方法的綜述論文進(jìn)行了論文翻譯和要點(diǎn)總結(jié),對(duì)基于RNN、CNN和GCN的主流行為識(shí)別技術(shù)進(jìn)行了全面的介紹,同時(shí)介紹了最大的3D骨架數(shù)據(jù)集及相關(guān)算法。>>>極市七夕粉絲福利活動(dòng):煉丹師們,七夕這道算法題,你會(huì)解嗎?
本文是對(duì)論文《A Survey on 3D Skeleton-Based Action Recognition Using Learning Method》學(xué)習(xí)時(shí)所做的記錄和總結(jié)。
論文鏈接:https://arxiv.org/pdf/2002.05907.pdf
發(fā)布時(shí)間:2020.2.14
作者團(tuán)隊(duì):北大&騰訊研究院
分類:計(jì)算機(jī)視覺-行為識(shí)別-基于3D骨架的行為識(shí)別-綜述
本文目錄:
一、論文翻譯
二、論文總結(jié)
一、論文翻譯
Abstract
由于關(guān)鍵點(diǎn)(骨架)檢測(cè)的潛在優(yōu)勢(shì),基于3D骨架的行為識(shí)別已經(jīng)成為計(jì)算機(jī)視覺中的活躍主題,因此多年來學(xué)者們提出了許多優(yōu)秀的方法,這些方法有的使用傳統(tǒng)手工特征,有的使用學(xué)習(xí)到的特征。
然而,之前的行為識(shí)別綜述大多數(shù)集中于調(diào)研以視頻或者RGB數(shù)據(jù)為輸入的方法,關(guān)于骨架數(shù)據(jù)為輸入的方法調(diào)研的很少,一般都是直接說一下骨架數(shù)據(jù)的表示或某些經(jīng)典技術(shù)在特定數(shù)據(jù)集上的表現(xiàn);此外,盡管深度學(xué)習(xí)方法已經(jīng)在這個(gè)領(lǐng)域應(yīng)用多年,但是仍然沒有相關(guān)的研究來從深度學(xué)習(xí)結(jié)構(gòu)的角度對(duì)其進(jìn)行介紹或總結(jié)。
為了打破這些限制,本綜述首先強(qiáng)調(diào)了行為識(shí)別的必要性和3D骨架數(shù)據(jù)的重要性;然后以數(shù)據(jù)驅(qū)動(dòng)的方式對(duì)基于RNN、CNN和GCN的主流行為識(shí)別技術(shù)進(jìn)行了全面的介紹;最后,我們簡(jiǎn)要介紹了一下最大的3D骨架數(shù)據(jù)集NTU-RGB+D及其最新版本NTU-RGB+D 120,并展示了這兩個(gè)數(shù)據(jù)集中包含的幾種現(xiàn)有的頂級(jí)算法。
據(jù)我們所知,本文是首次全面討論基于3D骨架數(shù)據(jù)的深度學(xué)習(xí)行為識(shí)別方法的綜述。
1、Introduction
行為識(shí)別(Action Recognition)是計(jì)算機(jī)視覺中極其重要也非常活躍的研究方向,它已經(jīng)被研究了數(shù)十年。因?yàn)槿藗兛梢杂脛?dòng)作(行為)來處理事情、表達(dá)感情,因此行為識(shí)別有非常廣泛但又未被充分解決的應(yīng)用領(lǐng)域,例如智能監(jiān)控系統(tǒng)、人機(jī)交互、虛擬現(xiàn)實(shí)、機(jī)器人[1-5]等。以往的方法中都使用RGB圖像序列[6-8],深度圖像序列[9,10],視頻或者這些模態(tài)的特定融合(例如RGB+光流)[11-15],也取得了超出預(yù)期的結(jié)果。然而,和骨架數(shù)據(jù)(人體關(guān)節(jié)和骨頭的一種拓?fù)浔硎荆┫啾龋笆瞿B(tài)會(huì)產(chǎn)生更多的計(jì)算消耗,且在面對(duì)復(fù)雜背景以及人體尺度變化、視角變化和運(yùn)動(dòng)速度變化[16]時(shí)魯棒性不足。此外,像Microsoft Kinect這樣的傳感器[17]和一些先進(jìn)的人體姿態(tài)估計(jì)算法[18-20]都可以讓我們更輕松地獲得準(zhǔn)確的3D骨架(關(guān)鍵點(diǎn))數(shù)據(jù)[21]。圖1展示了人體骨架數(shù)據(jù)的可視化效果。
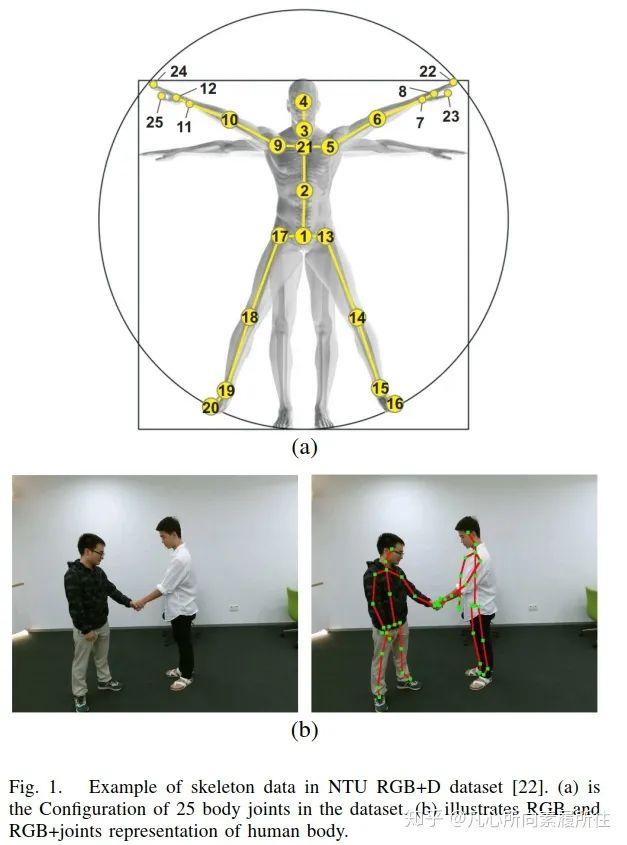
圖1. NTU RGB+D數(shù)據(jù)集[22]的一個(gè)示例.(a)數(shù)據(jù)集中的25個(gè)身體關(guān)節(jié)(b)人體RGB和RGB+關(guān)節(jié)展示
除了與其他模態(tài)數(shù)據(jù)相比具有的優(yōu)勢(shì),骨架序列還有如下三個(gè)主要的特點(diǎn):
i)空間信息Spatial information,相鄰關(guān)節(jié)之間存在很強(qiáng)的相關(guān)性,因此幀內(nèi)(intra-frame)可以獲取豐富的人體結(jié)構(gòu)信息。
ii)時(shí)域信息Temporal information,幀間inter-frame可以利用時(shí)域相關(guān)信息。
iii)時(shí)空域貢獻(xiàn)關(guān)系Co-occurrence relationship,當(dāng)考慮關(guān)節(jié)和骨骼的時(shí)候。
因此,許多研究人員使用骨架數(shù)據(jù)來做人體行為識(shí)別或檢測(cè),且一定會(huì)有越來越多的研究會(huì)使用骨架數(shù)據(jù)。
基于骨架序列的行為上和別主要是一個(gè)時(shí)序問題temporal problem,因此傳統(tǒng)的基于骨架的方法通常都是從特定的骨架序列中提取運(yùn)動(dòng)模式,這引出了許多手工特征的研究,這些手工特征經(jīng)常會(huì)利用不同關(guān)節(jié)間的相對(duì)3D旋轉(zhuǎn)和平移。然而,文獻(xiàn)[27]認(rèn)為這些手工特征只在一些特定數(shù)據(jù)集上表現(xiàn)良好,這進(jìn)一步說明了從一個(gè)數(shù)據(jù)集上提取的手工特征可能無法遷移到其他數(shù)據(jù)集上,這使得行為識(shí)別算法難以推廣或應(yīng)用到更廣泛的應(yīng)用領(lǐng)域。
隨著深度學(xué)習(xí)方法在其他在其他計(jì)算機(jī)視覺任務(wù)上的發(fā)展和先進(jìn)表現(xiàn),使用骨架數(shù)據(jù)的RNN[29],CNN[30]和GCN[31]也開始出現(xiàn)。圖2展示了基于3D骨架的深度學(xué)習(xí)行為識(shí)別方法的通用pipeline(從原始的RGB序列或者視頻到最后的行為類別)。
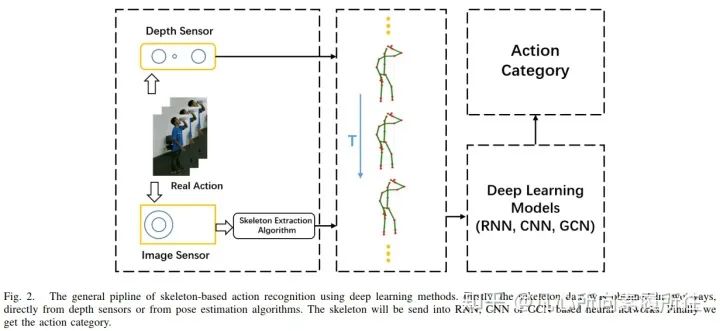
圖2. 基于骨架的深度學(xué)習(xí)行為識(shí)別方法的通用pipeline.首先,直接從深度傳感器或者姿態(tài)估計(jì)算法獲取骨架數(shù)據(jù);然后將骨架數(shù)據(jù)輸入到RNN,CNN,GCN等神經(jīng)網(wǎng)絡(luò);最后得到行為類別。
在基于RNN的方法中,骨架序列是關(guān)節(jié)坐標(biāo)的自然時(shí)間序列,這可以被視為序列向量,而RNN本身就適合于處理時(shí)間序列數(shù)據(jù)。此外,為了進(jìn)一步改善學(xué)習(xí)到的關(guān)節(jié)序列的時(shí)序上下文信息,一些別的RNN(LSTM,GRU)方法也被用到骨架行為識(shí)別中。
當(dāng)使用CNN來處理這一基于骨架的任務(wù)的時(shí)候,可以將其視為基于RNN方法的補(bǔ)充,因?yàn)镃NN結(jié)構(gòu)能更好地捕獲輸入數(shù)據(jù)的空間cues,而基于RNN的方法正缺乏空間信息的構(gòu)建。
最后,相對(duì)新的方法圖卷積神經(jīng)網(wǎng)絡(luò)GCN也有用于骨架數(shù)據(jù)處理中,因?yàn)楣羌軘?shù)據(jù)本身就是一個(gè)自然的拓?fù)鋱D數(shù)據(jù)結(jié)構(gòu)(關(guān)節(jié)點(diǎn)和骨頭可以被視為圖的節(jié)點(diǎn)和邊),而不是圖像或序列那樣的格式。
上述三種基于深度學(xué)習(xí)的方法都獲得了空前的表現(xiàn),但是大多數(shù)review文獻(xiàn)只是專注于傳統(tǒng)方法或者是基于RGB-(D)數(shù)據(jù)的深度學(xué)習(xí)方法(作者的意思就是說別的綜述在總結(jié)深度學(xué)習(xí)行為識(shí)別方法的時(shí)候都是專注于以RGB或者RGBD數(shù)據(jù)為輸入的那些方法,而本文是專注于將骨架數(shù)據(jù)作為輸入的那些深度學(xué)習(xí)行為識(shí)別方法)。
Ronald Poppe[32]首先解決了該領(lǐng)域的基本挑戰(zhàn),然后詳細(xì)介紹了關(guān)于直接分類和時(shí)間狀態(tài)空間模型的基本行為分類方法;Daniel和Remi[33]展示了行為表示在空間和時(shí)間域上的整體概況;這兩篇文章為輸入數(shù)據(jù)的預(yù)處理提供了一些啟發(fā),但是既沒有考慮骨架序列數(shù)據(jù)也沒有考慮深度學(xué)習(xí)策略。
最近,[34,35]總結(jié)了基于深度學(xué)習(xí)的視頻分類和看圖說話任務(wù),并在文中介紹了CNN和RNN的基本結(jié)構(gòu),其中[35]對(duì)常見的用于行為識(shí)別的深度結(jié)構(gòu)和定量分析進(jìn)行了分析。據(jù)我們所知,[36]是最近的第一篇深入研究3D骨架行為識(shí)別的文獻(xiàn),它總結(jié)了行為表示和分類方法,同時(shí)提供了一些常用的數(shù)據(jù)集,例如UCF,MHAD,MSR daily activity 3D[37-39]等,但是它沒有涵蓋到最新興起的基于GCN的方法。
最后,文獻(xiàn)[27]基于Kinect數(shù)據(jù)集寫了個(gè)行為識(shí)別算法綜述,該綜述對(duì)那些使用了該數(shù)據(jù)集的算法進(jìn)行了全面的比較,數(shù)據(jù)的類型包括RGB,Depth,RGB-D和skeleton sequences。
然而,上述所有工作都忽略了CNN-Based、RNN-Based、GCN-Based方法之間的區(qū)別和動(dòng)機(jī),尤其是將3D骨架序列考慮在內(nèi)的時(shí)候。
為了解決這些問題,我們基于骨架數(shù)據(jù),使用三種基本的深度學(xué)習(xí)結(jié)構(gòu)(RNN,CNN,GCN),對(duì)行為識(shí)別進(jìn)行了全面總結(jié),并進(jìn)一步地闡釋了這些模型的動(dòng)機(jī)和未來研究方向。
總的來說,我們的研究包含4個(gè)主要貢獻(xiàn):
i)以詳細(xì)且簡(jiǎn)明的方式全面介紹了3D骨架序列數(shù)據(jù)的優(yōu)越性和三種深度學(xué)習(xí)模型的特點(diǎn),并舉例說明了使用3D骨架數(shù)據(jù)的基于深度學(xué)習(xí)方法的行為識(shí)別pipeline。
ii)對(duì)每種深度模型,從數(shù)據(jù)驅(qū)動(dòng)的角度介紹了基于骨架數(shù)據(jù)的最新算法,例如時(shí)空建模、骨架數(shù)據(jù)表示、共現(xiàn)特征學(xué)習(xí)等方面,這些部分也是現(xiàn)存的待解決的經(jīng)典問題。
iii)首先討論最新的具有挑戰(zhàn)的數(shù)據(jù)集NTU-RGB+D 120及其附帶的幾種top-rank方法,然后討論未來的研究方向。
iv)我們是首個(gè) “在基于3D骨架數(shù)據(jù)的行為識(shí)別研究中考慮了各種深度模型(RNN CNN GCN)”的綜述。
2、3D Skeleton-Based Action Recognition with Deep Learning
現(xiàn)有的surveys已經(jīng)從基于RGB或基于骨架的角度對(duì)現(xiàn)有的行為識(shí)別技術(shù)進(jìn)行了定量和定性比較,但是沒有從神經(jīng)網(wǎng)絡(luò)的角度來比較。為此,我們分別對(duì)基于RNN的,基于CNN的,基于GCN方法進(jìn)行詳盡的討論和比較。對(duì)于每個(gè)部分,將基于某些缺陷(例如這三種模型之一的缺陷或者經(jīng)典的時(shí)空建模問題的缺陷)來引入一些最新的相關(guān)工作作為案例。
(1)RNN based Methods
RNN[40]通過將上一時(shí)刻的輸出作為當(dāng)前時(shí)刻的輸入來形成其結(jié)構(gòu)內(nèi)部的遞歸連接,這被證明是一種處理序列數(shù)據(jù)的有效方法。為了彌補(bǔ)標(biāo)準(zhǔn)RNN的不足(例如梯度消失問題和長(zhǎng)時(shí)建模問題),LSTM和GRU分別在RNN內(nèi)部引入了門和線性記憶單元,改進(jìn)了模型性能。
第一方面,時(shí)空建模算是行為識(shí)別任務(wù)的首要原則,由于RNN結(jié)構(gòu)缺乏空間建模能力,相關(guān)的方法通常也無法取得競(jìng)爭(zhēng)性的結(jié)果[41-43]。最近,Hong和Liang[44]提出了一個(gè)新穎的雙流RNN結(jié)構(gòu)來為骨架數(shù)據(jù)建模時(shí)域和空域特征,其中骨架軸的交換作為數(shù)據(jù)預(yù)處理來更好地學(xué)習(xí)空間域特征,該工作的框架如下圖3所示。
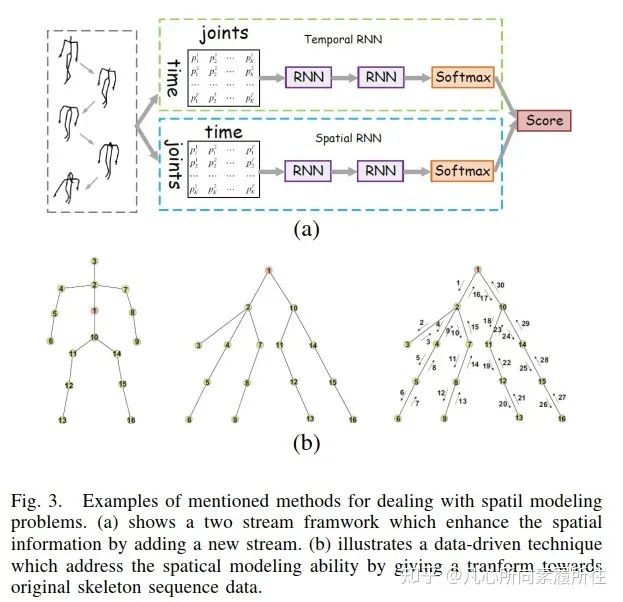
圖3. RNN-based Methods中提出的解決空間建模問題的示例[44].(a)在RNN的基礎(chǔ)上增加了一個(gè)新的stream來增強(qiáng)空間信息.(b)一種數(shù)據(jù)驅(qū)動(dòng)的技術(shù)(對(duì)原始骨架序列數(shù)據(jù)進(jìn)行轉(zhuǎn)換)來解決空間建模能力問題
和[44]不同的是,Jun和Amir[45]對(duì)骨架序列的遍歷方法進(jìn)行了研究,以此來獲取時(shí)空域的隱藏關(guān)系。一般的方法將將關(guān)節(jié)排列成簡(jiǎn)單的鏈,這忽略了相鄰關(guān)節(jié)的運(yùn)動(dòng)依賴關(guān)系,而[45]提出了基于樹結(jié)構(gòu)的關(guān)節(jié)遍歷方法,該方法在人體關(guān)節(jié)的聯(lián)系不夠牢固時(shí)也不會(huì)添加虛假連接。然后使用帶有信任門trust gate的LSTM來區(qū)分輸入,即如果樹狀輸入單元是可靠的,則將使用輸入的潛在空間信息來更新記憶單元。
受CNN適合建模空間信息這一特性的啟發(fā),Chunyu和Baochang[46]使用注意力RNN和CNN模型來改善復(fù)雜的時(shí)空建模。首先在殘差學(xué)習(xí)模塊中使用時(shí)域注意力子模型,來重新校準(zhǔn)骨架序列中的時(shí)域注意力,然后后接時(shí)空卷積子模型(將上一子模型輸出的校準(zhǔn)后的關(guān)節(jié)序列視為圖像)。
此外,[47]使用一個(gè)注意力循環(huán)關(guān)系LSTM網(wǎng)絡(luò)來學(xué)習(xí)骨架序列中的時(shí)空特征,其中循環(huán)關(guān)系網(wǎng)絡(luò)recurrent relation network學(xué)習(xí)空間特征、多層LSTM學(xué)習(xí)時(shí)域特征。
第二方面,網(wǎng)絡(luò)結(jié)構(gòu)也算是RNN的固有缺點(diǎn)。盡管RNN的性質(zhì)決定了其適合處理序列數(shù)據(jù), 但眾所周知的是梯度爆炸和消失問題不可避免。LSTM和GRU可以在一定程度上緩解這一問題,但tanh和sigmoid激活函數(shù)可能還是會(huì)導(dǎo)致層間的梯度衰減。為了解決這一缺陷,一些新型的RNN結(jié)構(gòu)被提出[48-50],Shuai和Wanqing[50]提出了一個(gè)獨(dú)立的循環(huán)神經(jīng)網(wǎng)絡(luò),該網(wǎng)絡(luò)可以解決梯度爆炸和消失問題,這使得構(gòu)建一個(gè)更長(zhǎng)更深的RNN網(wǎng)絡(luò)來學(xué)習(xí)魯棒性更好的高級(jí)語義特征成為可能。這一改進(jìn)的RNN不僅可以用于骨架行為識(shí)別,也可用用于其他領(lǐng)域例如語言模型。在這種結(jié)構(gòu)中,一層內(nèi)的神經(jīng)元彼此獨(dú)立,因此可以用于處理更長(zhǎng)的序列。
最后一個(gè)方面,即第三個(gè)方面,數(shù)據(jù)驅(qū)動(dòng)方面。考慮到并不是所有的關(guān)節(jié)對(duì)行為分析有用,[51]在LSTM網(wǎng)絡(luò)中添加了全局意識(shí)關(guān)注global contex-aware attention來選擇性地關(guān)注骨架序列中信息豐富的關(guān)節(jié)。圖4(a)展示了該方法的可視化效果,從中我們可以發(fā)現(xiàn)信息量更大的關(guān)節(jié)用紅色圓圈表示,表示這些關(guān)節(jié)對(duì)該特定的行為更重要。
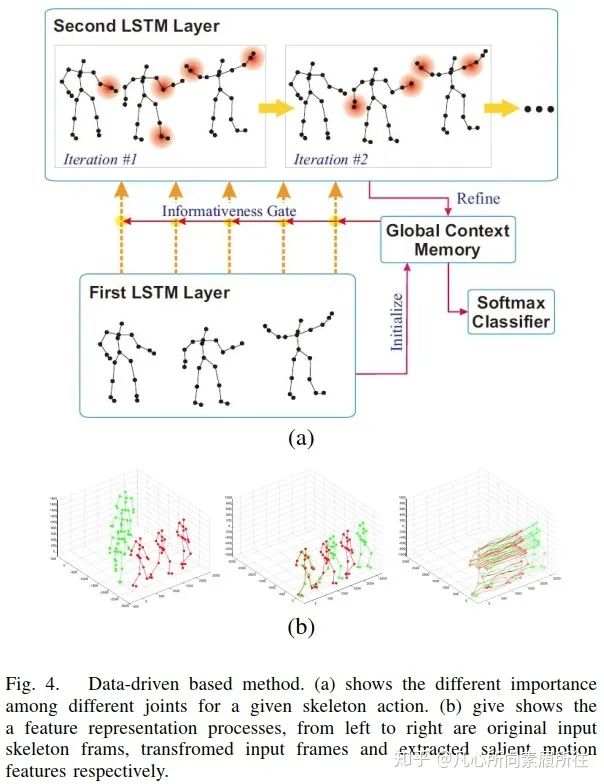
圖4. 基于數(shù)據(jù)驅(qū)動(dòng)的方法.(a)對(duì)于給定的骨架動(dòng)作,不同關(guān)節(jié)的重要性不同[51];(b)特征表示過程,從左至右分別是原始輸入的骨架幀、轉(zhuǎn)換后的輸入幀和提取到的顯著運(yùn)動(dòng)特征[52]
另外,由于數(shù)據(jù)集或深度傳感器所提供的骨架并不是完美的,這可能會(huì)影響行為識(shí)別任務(wù)的結(jié)果,所以[52]將骨架轉(zhuǎn)換為另一種坐標(biāo)系統(tǒng)來提升尺度變化、旋轉(zhuǎn)、平移的魯棒性,然后從轉(zhuǎn)換后的數(shù)據(jù)中提取顯著運(yùn)動(dòng)特征,而不是直接將原始骨架數(shù)據(jù)輸入到LSTM中,圖4(b)展示了這一特征表示過程。
除了上述這些,還有很多有價(jià)值的使用RNN的方法著眼于大視角變化、單個(gè)骨架中各關(guān)節(jié)的關(guān)系等問題。然而,我們必須承認(rèn)在特定的建模方面RNN-based的方法確實(shí)比CNN based方法弱,接下來討論另一個(gè)有趣的問題:CNN-based方法如果進(jìn)行時(shí)域信息建模以及如何找到時(shí)空信息的相對(duì)平衡點(diǎn)。
(2)CNN based Methods
卷積神經(jīng)網(wǎng)絡(luò)也被用于基于骨架的行為識(shí)別。和RNN不同的是,CNN憑借其自然、出色的高級(jí)信息提取能力可以有效且輕松地學(xué)習(xí)高級(jí)語義cues。不過CNN通常專注于image-based任務(wù),而基于骨架序列的行為識(shí)別任務(wù)毫無疑問是一個(gè)強(qiáng)時(shí)間依賴的問題。所以在基于CNN的架構(gòu)中,如何平衡且更充分地利用空間信息和時(shí)域信息就非常有挑戰(zhàn)了。
為了滿足CNN輸入的需要,3D骨架序列數(shù)據(jù)通常要從向量序列轉(zhuǎn)換為偽圖像,然而,要同時(shí)具有時(shí)空信息的相關(guān)表示pertinent representation并不容易,因此許多研究者將骨架關(guān)節(jié)編碼為多個(gè)2D偽圖像,然后將其輸入到CNN中來學(xué)習(xí)有用的特征[53,54]。
Wang[55]提出了關(guān)聯(lián)軌跡圖(Joint Trajectory Maps, JTM),它通過顏色編碼將關(guān)節(jié)軌跡的空間配置和動(dòng)態(tài)信息spatial configuration and dynamics of joint trajectories表示為三個(gè)紋理圖像。然而,這種方法有點(diǎn)復(fù)雜,且在映射過程中丟失了重要信息。為了克服這一缺陷,Bo和Mingyi[56]使用平移不變的圖像映射策略,先根據(jù)人體物體結(jié)構(gòu)把每幀圖像的人體骨架關(guān)節(jié)分為五個(gè)主要部分,然后把這些部分映射為2D形式。這種方法是的骨架圖像同時(shí)包含了時(shí)域信息和空間信息。然而,雖然性能得到改善,但是將人體骨架關(guān)節(jié)作為孤立的點(diǎn)是不合理的,因?yàn)樵谡媸鞘澜缰姓麄€(gè)身體的各個(gè)部分都會(huì)存在緊密的聯(lián)系。例如當(dāng)我們揮手的時(shí)候,不僅僅要考慮和手直接相關(guān)的關(guān)節(jié),還要考慮其他部分的情況,例如肩膀和腿也需要被考慮。
Yanshan和Rongjie[57]從幾何代數(shù)中提出了形狀運(yùn)動(dòng)表示法shape-motion representaion,解決了關(guān)節(jié)和骨骼的重要性,充分利用了骨架序列所提供的信息,如圖5(a)所示。
類似的,[2]也使用了增強(qiáng)的骨架可視化來表示骨架數(shù)據(jù),Carlos和Jessica[58]基于運(yùn)動(dòng)信息提出新的表示方法(命名為SkeleMotion),該方法通過顯式計(jì)算關(guān)節(jié)運(yùn)動(dòng)的幅度和方向值來編碼時(shí)間動(dòng)態(tài)信息,如圖5(b)所示。
此外,和SkeleMotion類似,[59]使用SkeleMotion的框架但是基于樹結(jié)構(gòu)和參考關(guān)節(jié)來表示骨架圖像。
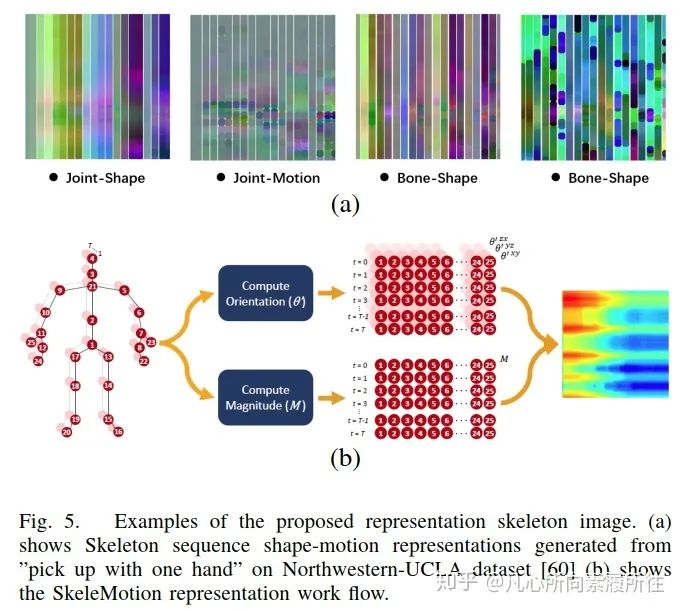
圖5. 骨架圖像表示方法展示.(a)Northwestern-UCLA數(shù)據(jù)集[60]上“單手俯臥撐”動(dòng)作的shape-motion表示[57];(b)SkeleMotion表示的工作流程[58].
這些CNN-based方法通常把時(shí)域動(dòng)態(tài)和關(guān)節(jié)簡(jiǎn)單地編碼為行和列,來將骨架序列表示為圖像,因此卷積的時(shí)候僅考慮了卷積核內(nèi)的相鄰關(guān)節(jié)來學(xué)習(xí)共現(xiàn)特征,也就是說,對(duì)每個(gè)關(guān)節(jié)來說,一些潛在相關(guān)的關(guān)節(jié)會(huì)被忽略,因此CNN不能學(xué)習(xí)到相應(yīng)的有用的特征。Chao和Qiaoyong[61]使用一個(gè)端到端的框架通過分層方法來學(xué)習(xí)共現(xiàn)特征,在該框架中逐步匯總不同層級(jí)的上下文信息。首先對(duì)點(diǎn)級(jí)point-level信息進(jìn)行獨(dú)立編碼,然后在時(shí)域和空域?qū)⑺鼈兘M合成語義表示。
在CNN-Based的技術(shù)中,除了3D骨架序列表示之外也有一些別的問題,例如模型的大小和速度[3],CNN的架構(gòu)(雙流或者單流[62]),遮擋,視角變化等等[2,3]。所以使用CNN來解決基于骨架的行為識(shí)別任務(wù)仍是一個(gè)開放的問題,需要研究人員進(jìn)行深入研究。
(3)GCN based Methods
人類3D骨架數(shù)據(jù)是自然的拓?fù)鋱D,而不是一系列向量(RNN-based方法中的思路)或是偽圖像(CNN-based方法中的思路),因此GCN(能夠有效表示圖形結(jié)構(gòu)數(shù)據(jù))最近被頻繁地用到骨架行為識(shí)別任務(wù)中。目前現(xiàn)存的兩種與圖相關(guān)的神經(jīng)網(wǎng)絡(luò)有圖循環(huán)神經(jīng)網(wǎng)絡(luò)GNN和圖卷積神經(jīng)網(wǎng)絡(luò)GCN,本綜述主要關(guān)注GCN,同時(shí)我們也會(huì)展示一些相關(guān)的先進(jìn)結(jié)果。而且僅從骨架的角度來看的話,把骨架序列簡(jiǎn)單地編碼為序列向量或2D網(wǎng)格并不能完全表達(dá)相關(guān)關(guān)節(jié)的依賴關(guān)系。圖卷積神經(jīng)網(wǎng)絡(luò)Graph convolutional neural networks作為CNN的一種泛化形式,可以應(yīng)用于骨架圖在內(nèi)的任意結(jié)構(gòu)。在基于GCN的骨架行為識(shí)別技術(shù)中,最重要的問題是如何把原始數(shù)據(jù)組織稱特定的圖結(jié)構(gòu)(還是和骨架數(shù)據(jù)的表達(dá)相關(guān))。
Sijie和Yuanjun[31]首次提出了一種基于骨架動(dòng)作識(shí)別的新模型--時(shí)空?qǐng)D卷積網(wǎng)絡(luò)ST-GCN,該網(wǎng)絡(luò)首先將人的關(guān)節(jié)作為時(shí)空?qǐng)D的頂點(diǎn)vertexs,將人體連通性和時(shí)間作為圖的邊edges;然后使用標(biāo)準(zhǔn)Softmax分類器來講ST-GCN上獲取的高級(jí)特征圖劃分為對(duì)應(yīng)的類別。這項(xiàng)工作讓更多人關(guān)注到使用GCN進(jìn)行骨架行為識(shí)別的優(yōu)越性,因此最近出現(xiàn)了許多相關(guān)工作。
最常見的研究集中于對(duì)骨架數(shù)據(jù)的有效使用[68,78],Maose和Siheng[68]提出的運(yùn)動(dòng)結(jié)構(gòu)圖卷積網(wǎng)絡(luò)(Action Structural Graph Convolutional Network, AS-GCN)不僅能夠識(shí)別人的動(dòng)作,還可以使用多任務(wù)學(xué)習(xí)策略來輸出目標(biāo)下一個(gè)可能的姿態(tài)pose。這項(xiàng)工作中構(gòu)造的圖結(jié)構(gòu)可以通過兩個(gè)子模塊Actional Links和Structual Links來捕獲關(guān)節(jié)間更豐富的依賴性。圖6展示了AS-GCN的特征學(xué)習(xí)過程和其廣義骨架圖結(jié)構(gòu),該模型中使用的多任務(wù)學(xué)習(xí)策略可能是一個(gè)很不錯(cuò)的方向,因?yàn)樾袨樽R(shí)別任務(wù)可能會(huì)從其他補(bǔ)充任務(wù)中得到提升。
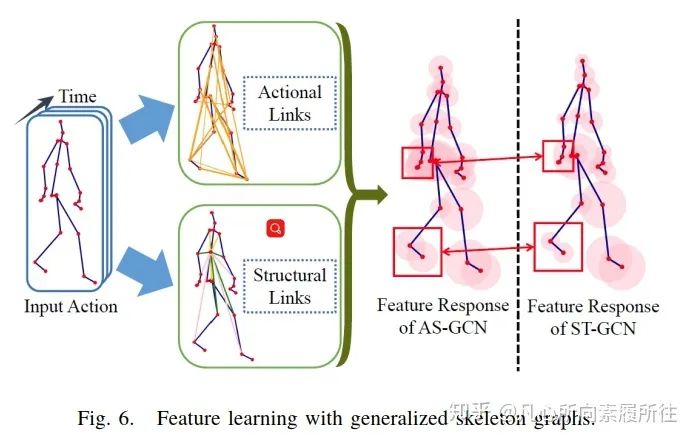
圖6.廣義骨架圖的特征學(xué)習(xí)
根據(jù)上述介紹和討論,最受關(guān)注的地方仍然是數(shù)據(jù)驅(qū)動(dòng)的,我們要做的就是獲取3D骨架序列數(shù)據(jù)背后的潛在信息,而GCN-based行為識(shí)別主要圍繞著“如何獲取”這一問題展開,這仍然是一個(gè)開放的具有挑戰(zhàn)的問題。尤其骨架數(shù)據(jù)本身就是時(shí)空耦合的,此外將骨架數(shù)據(jù)轉(zhuǎn)換為圖時(shí),關(guān)節(jié)和骨骼之間的連接也是時(shí)空耦合的。
3、Latest Datasets and Performance
骨架序列數(shù)據(jù)集主要有MSRAAction3D[79],3D Action Pairs[80],MSR Daily Activity3D[39]等,這些數(shù)據(jù)都在許多綜述中有過分析[27,35,36],所以我們這里主要分析如下兩個(gè)數(shù)據(jù)集NTU-RGB+D[22]和NTU-RGB+D 120[81]。
NTU-RGB+D數(shù)據(jù)集在2016年提出,包含56880個(gè)視頻samples,這些樣本都是從一個(gè)大規(guī)模骨架行為識(shí)別數(shù)據(jù)集Microsoft Kinect v2上收集的,NTU-RGB+D像圖1(a)那樣提供了每個(gè)人、每個(gè)動(dòng)作的25個(gè)關(guān)節(jié)的3D空間坐標(biāo)。在該數(shù)據(jù)集上,建議使用兩種協(xié)議對(duì)提出的方法進(jìn)行評(píng)估:跨子類Cross-Subject和跨視角Cross-View。其中Cross-Subject包含40320個(gè)訓(xùn)練樣本和16560個(gè)驗(yàn)證樣本,劃分規(guī)則是根據(jù)40個(gè)subjects進(jìn)行的;其中Cross-View將camera2和3作為訓(xùn)練集(37920個(gè)樣本),將camera1作為驗(yàn)證集(18960個(gè)樣本)。
近來,提出了NTU-RGB+D的擴(kuò)展版本NTU-RGB+D 120,包含120個(gè)動(dòng)作類別和114480個(gè)骨架序列,視角點(diǎn)是155個(gè)。我們將在表I中展示最近相關(guān)的骨架行為識(shí)別性能,其中CS表示Cross-Subject,CV在NTU-RGB+D表示Cross-View,在NTU-RGB+D 120表示Cross-Setting。
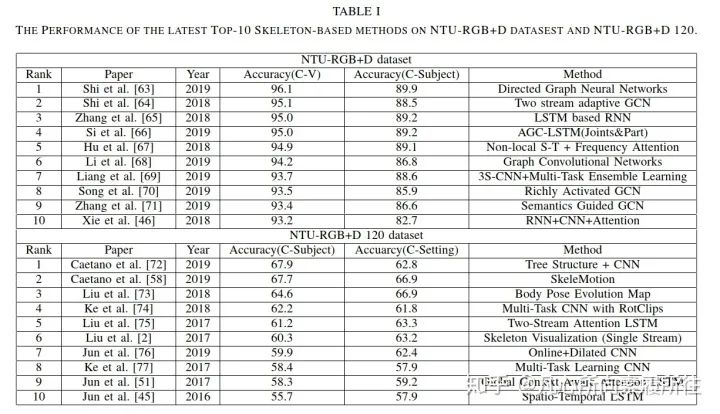
表1. 最新Top10骨架行為識(shí)別算法在NTU-RGB+D和NTU-RGB+D 120數(shù)據(jù)集上的性能
從表中可以看到現(xiàn)存的算法已經(jīng)在NTU-RGB+D數(shù)據(jù)集上取得了極好的性能,在NTU-RGB+D 120數(shù)據(jù)集上仍然還有很大進(jìn)步空間。
4、Conclusions and Discussion
本文分別基于三種主要的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)介紹了3D骨架序列數(shù)據(jù)上的行為識(shí)別問題,在介紹中我們強(qiáng)調(diào)了行為識(shí)別的含義、骨架數(shù)據(jù)的優(yōu)越性和不同深度框架的特性。
與之前的綜述數(shù)不同,我們的研究以數(shù)據(jù)驅(qū)動(dòng)的方式深入了解了基于深度學(xué)習(xí)的行為識(shí)別方法,涵蓋了基于CNN、RNN、GCN的最新行為識(shí)別算法。其中RNN-Based和CNN-Based方法通過骨架數(shù)據(jù)表示和詳細(xì)的網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)來解決時(shí)空特征問題,在GCN-based方法中,最重要的事情是如何充分利用關(guān)節(jié)和骨骼的信息和聯(lián)系。據(jù)此,我們得出結(jié)論:在三種不同的學(xué)習(xí)結(jié)構(gòu)中最常見的仍然是從3D骨架中獲取有效信息,而拓?fù)鋱D是人類骨架關(guān)節(jié)最自然的表示,這一點(diǎn)從各算法在NTU-RGB+D上的性能表現(xiàn)也可以看出來。然而, 這并不意味著CNN-based和RNN-based方法就不適合骨架行為識(shí)別任務(wù),相反的,當(dāng)在這些模型上應(yīng)用一些策略(例如多任務(wù)學(xué)習(xí))時(shí),CV和CS性能都會(huì)得到提升。然而,在NTU-RGB+D上的精度已經(jīng)很高了,很難去進(jìn)一步提升,所以注意力應(yīng)該放到更難的數(shù)據(jù)集上,例如NTU-RGB+D 120。
至于未來方向,長(zhǎng)期行為識(shí)別、更有效的3D骨架序列表示、實(shí)時(shí)識(shí)別等都是待解決的問題,此外無監(jiān)督和弱監(jiān)督策略以及zero-show學(xué)習(xí)也可能會(huì)得到發(fā)展。
Peferences
二.論文總結(jié)
綜述文章,也沒什么好總結(jié)的,就用自己的話簡(jiǎn)單總結(jié)一下這篇文章到底在review什么。
1.首先這篇綜述的主題是 3D Skeleton + Deeplearning + ActionRecognition
(1)深度學(xué)習(xí)不用說了,一般來說肯定比手工方法優(yōu)越
(2)至于3D Skeleton, 作者就開篇先論證了一下3D Skeleton 數(shù)據(jù)的優(yōu)越性(相比RGB RGB-D)
(3)作者給了個(gè)這個(gè)主題的基本pipeline
作者的意思就是說:我寫這個(gè)主題算是新穎的、有意義的。
2.以數(shù)據(jù)驅(qū)動(dòng)的方式對(duì)RNN-Based、CNN-Based、GCN-Based骨架行為識(shí)別方法進(jìn)行了總結(jié)
(1)所謂數(shù)據(jù)驅(qū)動(dòng)方式:討論的核心都是這三種結(jié)構(gòu)都是如何從3D骨架序列數(shù)據(jù)中構(gòu)建、獲取時(shí)空信息的。
(2)在總結(jié)這三類方法時(shí)都是以網(wǎng)絡(luò)結(jié)構(gòu)本身的缺陷為著手點(diǎn),引出各種相關(guān)方法的。最后就想說,RNN-Based和CNN-Based方法各有優(yōu)缺點(diǎn),但明顯GCN更能自然地描述3D骨架數(shù)據(jù)。
3.列舉了一下以前綜述中討論過的3D骨架行為識(shí)別數(shù)據(jù)集,然后著重描述了一下NTU-RGB+D和其擴(kuò)展版NTU-RGB+D 120兩個(gè)數(shù)據(jù)集,給出最近top10算法在這兩個(gè)數(shù)據(jù)集上的表現(xiàn)。
本篇綜述的翻譯和總結(jié)至此結(jié)束,歡迎討論~
推薦閱讀
two/one-stage,anchor-based/free目標(biāo)檢測(cè)發(fā)展及總結(jié):一文了解目標(biāo)檢測(cè):https://zhuanlan.zhihu.com/p/100823629
人體關(guān)鍵點(diǎn)檢測(cè)(姿態(tài)估計(jì))簡(jiǎn)介+分類匯總:https://zhuanlan.zhihu.com/p/102457223
一文了解通用行為識(shí)別ActionRecognition:了解及分類:https://zhuanlan.zhihu.com/p/103566134
