圖像分割的U-Net系列方法
作者:taigw
來源:https://zhuanlan.zhihu.com/p/57530767
本文已經(jīng)作者授權(quán),禁止二次轉(zhuǎn)載
在圖像分割任務(wù)特別是醫(yī)學圖像分割中,U-Net[1]無疑是最成功的方法之一,該方法在2015年MICCAI會議上提出,目前已達到四千多次引用。其采用的編碼器(下采樣)-解碼器(上采樣)結(jié)構(gòu)和跳躍連接是一種非常經(jīng)典的設(shè)計方法。目前已有許多新的卷積神經(jīng)網(wǎng)絡(luò)設(shè)計方式,但很多仍延續(xù)了U-Net的核心思想,加入了新的模塊或者融入其他設(shè)計理念。本文對U-Net及其幾種改進版做一個介紹。
U-Net和3D U-Net
U-Net最初是一個用于二維圖像分割的卷積神經(jīng)網(wǎng)絡(luò),分別贏得了ISBI 2015細胞追蹤挑戰(zhàn)賽和齲齒檢測挑戰(zhàn)賽的冠軍[2]。U-Net的一個Karas實現(xiàn)代碼:
https://github.com/zhixuhao/unet
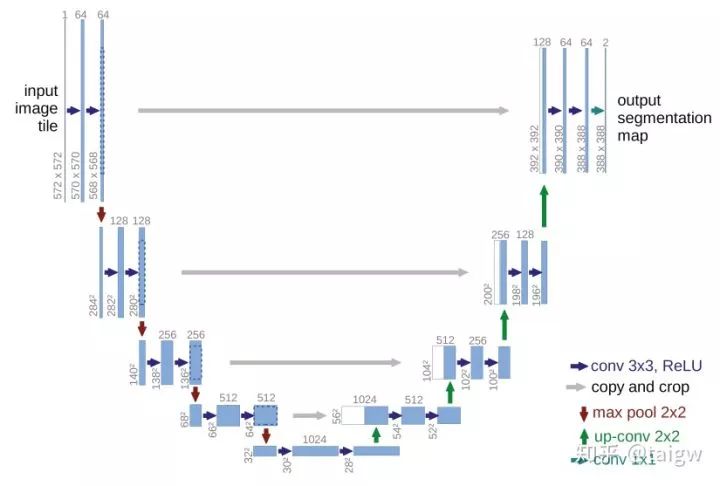
U-Net的結(jié)構(gòu)如下圖所示,左側(cè)可視為一個編碼器,右側(cè)可視為一個解碼器。編碼器有四個子模塊,每個子模塊包含兩個卷積層,每個子模塊之后有一個通過max pool實現(xiàn)的下采樣層。輸入圖像的分辨率是572x572, 第1-5個模塊的分辨率分別是572x572, 284x284, 140x140, 68x68和32x32。由于卷積使用的是valid模式,故這里后一個子模塊的分辨率等于(前一個子模塊的分辨率-4)/2。解碼器包含四個子模塊,分辨率通過上采樣操作依次上升,直到與輸入圖像的分辨率一致(由于卷積使用的是valid模式,實際輸出比輸入圖像小一些)。該網(wǎng)絡(luò)還使用了跳躍連接,將上采樣結(jié)果與編碼器中具有相同分辨率的子模塊的輸出進行連接,作為解碼器中下一個子模塊的輸入。
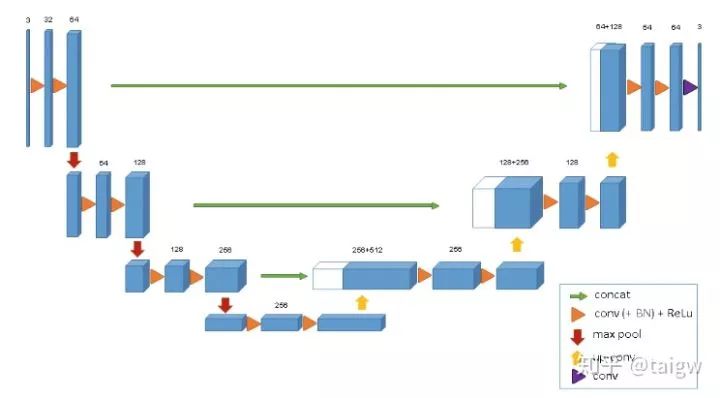
3D U-Net[3]是U-Net的一個簡單擴展,應(yīng)用于三維圖像分割,結(jié)構(gòu)如下圖所示。相比于U-Net,該網(wǎng)絡(luò)僅用了三次下采樣操作,在每個卷積層后使用了batch normalization,但3D U-Net和U-Net均沒有使用dropout。
在2018年MICCAI腦腫瘤分割挑戰(zhàn)賽(brats)中[4],德國癌癥研究中心的團隊使用3D U-Net,僅做了少量的改動,取得了該挑戰(zhàn)賽第二名的成績,發(fā)現(xiàn)相比于許多新的網(wǎng)絡(luò),3D U-Net仍然十分具有優(yōu)勢[5]。3D U-Net的一種Pytorch實現(xiàn):
https://github.com/wolny/pytorch-3dunet
TernausNet
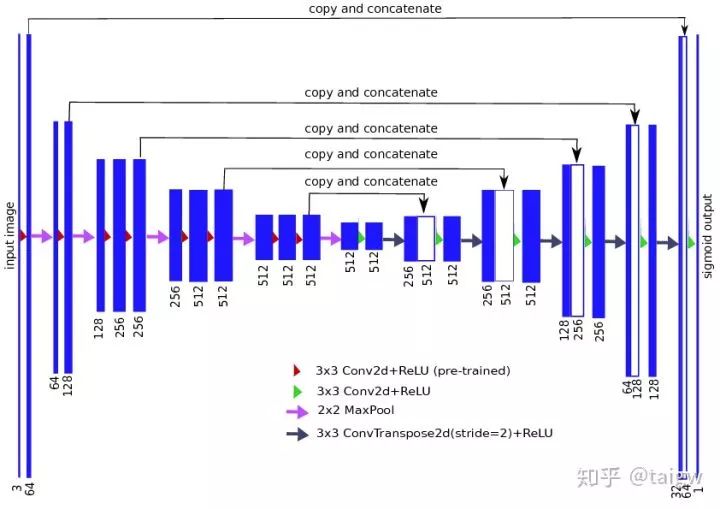
TernausNet全稱為"TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation"[6]。該網(wǎng)絡(luò)將U-Net中的編碼器替換為VGG11,并在ImageNet上進行預訓練,從735個參賽隊伍中脫穎而出,取得了Kaggle 二手車分割挑戰(zhàn)賽(Carvana Image Masking Challenge)第一名。代碼鏈接:
https://github.com/ternaus/TernausNet
下圖是該網(wǎng)絡(luò)的示意圖:
Res-UNet 和Dense U-Net
Res-UNet和Dense-UNet分別受到殘差連接和密集連接的啟發(fā),將UNet的每一個子模塊分別替換為具有殘差連接和密集連接的形式。[6] 中將Res-UNet用于視網(wǎng)膜圖像的分割,其結(jié)構(gòu)如下圖所示,其中灰色實線表示各個模塊中添加的殘差連接。
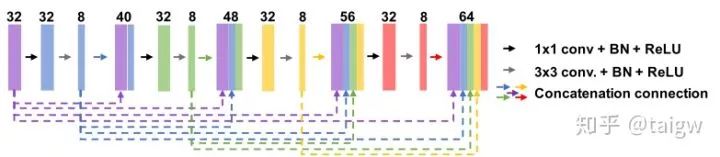
密集連接即將子模塊中某一層的輸出分別作為后續(xù)若干層的輸入的一部分,某一層的輸入則來自前面若干層的輸出的組合。下圖是[7]中的密集連接的一個例子。該文章中將U-Net的各個子模塊替換為這樣的密集連接模塊,提出Fully Dense UNet 用于去除圖像中的偽影。
MultiResUNet
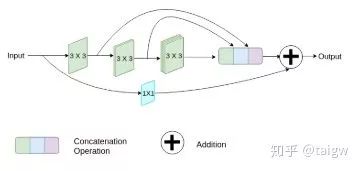
MultiResUNet[8]提出了一個MutiRes模塊與UNet結(jié)合。MutiRes模塊如下圖所示,是一個殘差連接的擴展,在該模塊中三個3x3的卷積結(jié)果拼接起來作為一個組合的特征圖,再與輸入特征圖經(jīng)過1x1卷積得到的結(jié)果相加。
該網(wǎng)絡(luò)的結(jié)構(gòu)圖如下圖所示,其中各個MultiRes模塊的內(nèi)部即為上圖所示。
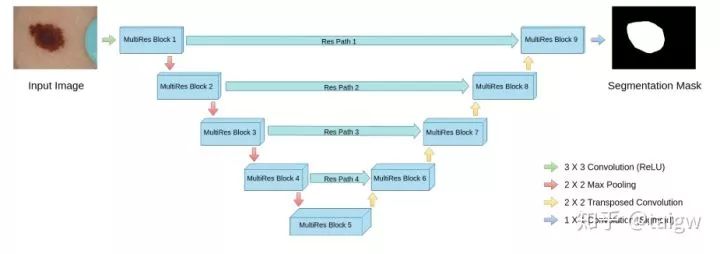
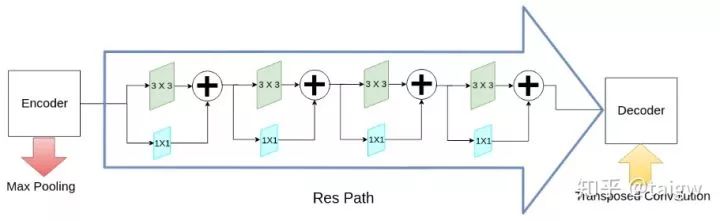
該網(wǎng)絡(luò)除了MultiRes模塊以外,還提出了一個殘差路徑(ResPath), 使編碼器的特征在與解碼器中的對應(yīng)特征拼接之前,先進行了一些額外的卷積操作,如下圖所示。作者認為編碼器中的特征由于卷積層數(shù)較淺,是低層次的特征,而解碼器中對應(yīng)的特征由于卷積層更深,是較高層次的特征,二者在語義上有較大差距,推測不宜直接將二者進行拼接。因此,使用額外的ResPath使二者在拼接前具有一致的深度,在ResPath1, 2, 3, 4中分別使用4,3,2,1個卷積層。
該文章在ISIC、CVC-ClinicDB、Brats等多個數(shù)據(jù)集上驗證了其性能。代碼鏈接為
https://github.com/nibtehaz/MultiResUNet
R2U-Net
R2U-Net全稱叫做Recurrent Residual CNN-based U-Net[9]。該方法將殘差連接和循環(huán)卷積結(jié)合起來,用于替換U-Net中原來的子模塊,如下圖所示
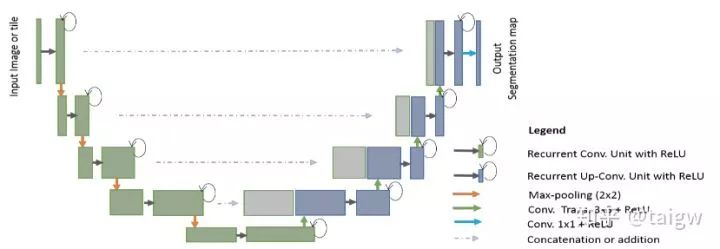
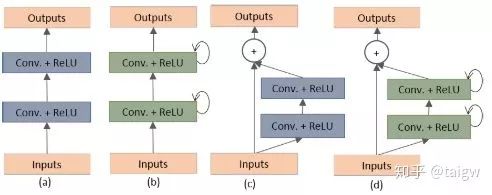
其中環(huán)形箭頭表示循環(huán)連接。下圖表示了幾種不同的子模塊內(nèi)部結(jié)構(gòu)圖,(a)是常規(guī)的U-Net中使用的方法,(b)是在(a)的基礎(chǔ)上循環(huán)使用包含激活函數(shù)的卷積層,(c)是使用殘差連接的方式,(d)是該文章提出的結(jié)合(b)和(c)的循環(huán)殘差卷積模塊。
該方法也在皮膚病圖像、視網(wǎng)膜圖像、肺部圖像等幾個公共數(shù)據(jù)集驗證了其性能,代碼鏈接:
https://github.com/LeeJunHyun/Image_Segmentation#r2u-net
Attention UNet
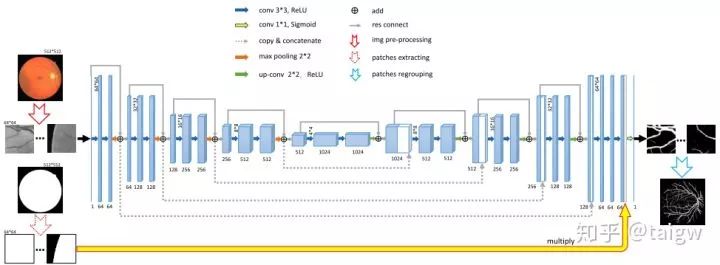
Attention UNet[10]在UNet中引入注意力機制,在對編碼器每個分辨率上的特征與解碼器中對應(yīng)特征進行拼接之前,使用了一個注意力模塊,重新調(diào)整了編碼器的輸出特征。該模塊生成一個門控信號,用來控制不同空間位置處特征的重要性,如下圖中紅色圓圈所示。
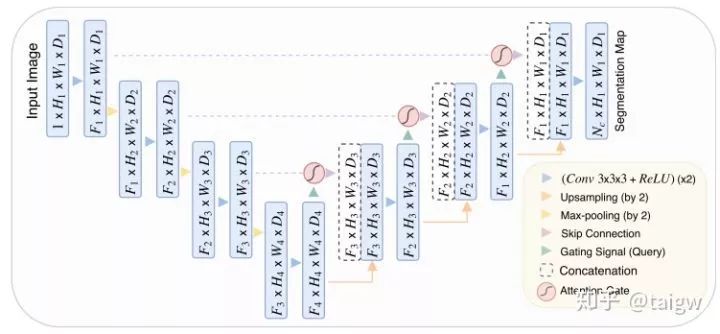
該方法的注意力模塊內(nèi)部如下圖所示,該模塊通過1x1x1的卷積分別與ReLU和Sigmoid結(jié)合,生成一個權(quán)重圖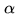 ?, 通過與編碼器中的特征相乘來對其進行校正。
?, 通過與編碼器中的特征相乘來對其進行校正。
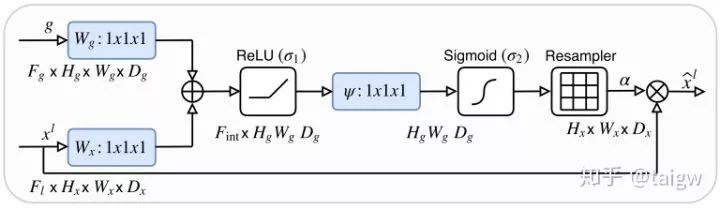
下圖展示了注意力權(quán)重圖的可視化效果。從左至右分別是一幅圖像和隨著訓練次數(shù)的增加該圖像中得到的注意力權(quán)重。可見得到的注意力權(quán)重傾向于在目標器官區(qū)域取得大的值,在背景區(qū)域取得較小的值,有助于提高圖像分割的精度。
該文章的代碼鏈接:
https://github.com/ozan-oktay/Attention-Gated-Networks
其他
基于U-Net框架設(shè)計的圖像分割網(wǎng)絡(luò)還有很多,難以一一列舉,這里再提供兩篇具有參考性的文章:
AnatomyNet: Deep 3D Squeeze-and-excitation U-Nets for fast and fully automated whole-volume anatomical segmentation
H-DenseUNet: Hybrid Densely Connected UNet for Liver and Liver Tumor Segmentation from CT Volumes
總結(jié)
UNet是一個經(jīng)典的網(wǎng)絡(luò)設(shè)計方式,在圖像分割任務(wù)中具有大量的應(yīng)用。也有許多新的方法在此基礎(chǔ)上進行改進,融合更加新的網(wǎng)絡(luò)設(shè)計理念,但目前幾乎沒有人對這些改進版本做過比較綜合的比較。由于同一個網(wǎng)絡(luò)結(jié)構(gòu)可能在不同的數(shù)據(jù)集上表現(xiàn)出不一樣的性能,在具體的任務(wù)場景中還是要結(jié)合數(shù)據(jù)集來選擇合適的網(wǎng)絡(luò)。希望本文對做圖像分割的同學有所啟發(fā)。
參考文章:
[1] Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." In?International Conference on Medical image computing and computer-assisted intervention, pp. 234-241. Springer, Cham, 2015.
[2]?U-Net: Convolutional Networks for Biomedical Image Segmentation
(鏈接:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ )
[3] ?i?ek, ?zgün, Ahmed Abdulkadir, Soeren S. Lienkamp, Thomas Brox, and Olaf Ronneberger. "3D U-Net: learning dense volumetric segmentation from sparse annotation." In?International conference on medical image computing and computer-assisted intervention, pp. 424-432. Springer, Cham, 2016.
[4]?Section for Biomedical Image Analysis (SBIA)
( 鏈接:https://www.med.upenn.edu/sbia/brats2018/data.html )
[5] Isensee, Fabian, Philipp Kickingereder, Wolfgang Wick, Martin Bendszus, and Klaus H. Maier-Hein. "No new-net." In?International MICCAI Brainlesion Workshop, pp. 234-244. Springer, Cham, 2018.
[6] Xiao, Xiao, Shen Lian, Zhiming Luo, and Shaozi Li. "Weighted Res-UNet for High-Quality Retina Vessel Segmentation." In?2018 9th International Conference on Information Technology in Medicine and Education (ITME), pp. 327-331. IEEE, 2018.
[7] Guan, Steven, Amir Khan, Siddhartha Sikdar, and Parag V. Chitnis. "Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal."?arXiv preprint arXiv:1808.10848?(2018).
[8] Ibtehaz, Nabil, and M. Sohel Rahman. "MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation."?arXiv preprint arXiv:1902.04049?(2019).
[9] Alom, Md Zahangir, Mahmudul Hasan, Chris Yakopcic, Tarek M. Taha, and Vijayan K. Asari. "Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation."?arXiv preprint arXiv:1802.06955?(2018).
[10] Oktay, Ozan, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori et al. "Attention U-Net: learning where to look for the pancreas."?arXiv preprint arXiv:1804.03999?(2018).