
一文通俗講透樹(shù)模型
前言
決策樹(shù)模型因?yàn)槠涮卣黝A(yù)處理簡(jiǎn)單、易于集成學(xué)習(xí)、良好的擬合能力及解釋性,是應(yīng)用最廣泛的機(jī)器學(xué)習(xí)模型之一。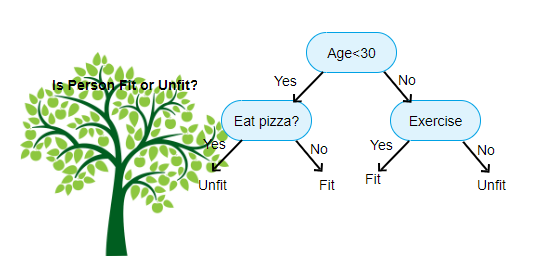
不同于線性模型【數(shù)學(xué)描述:f(W*X +b)】是通過(guò)數(shù)據(jù)樣本學(xué)習(xí)各個(gè)特征的合適權(quán)重,加權(quán)后做出決策。決策樹(shù)會(huì)選擇合適特征并先做特征劃分后,再做出決策(也就是決策邊界是非線性的,這提高了模型的非線性能力)。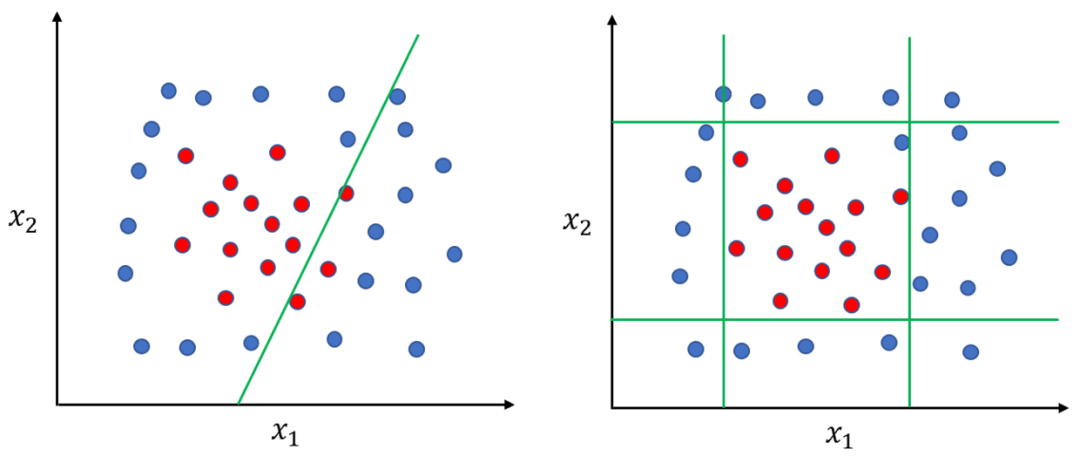
一、樹(shù)模型的概括
決策樹(shù)呈樹(shù)形結(jié)構(gòu),更通俗來(lái)講,樹(shù)模型的數(shù)學(xué)描述就是“分段函數(shù)”。如下一個(gè)簡(jiǎn)單判別西瓜質(zhì)量的決策樹(shù)模型示例(注:以下西瓜示例,數(shù)據(jù)隨機(jī)杜撰的,請(qǐng)忽略這么小的西瓜瓜~):

學(xué)習(xí)這樣樹(shù)模型的過(guò)程,簡(jiǎn)單來(lái)說(shuō)就是從有監(jiān)督的數(shù)據(jù)經(jīng)驗(yàn)中學(xué)習(xí)一個(gè)較優(yōu)的樹(shù)模型的結(jié)構(gòu):包含了依次地選擇特征、確定特征閾值做劃分的內(nèi)部節(jié)點(diǎn)及最終輸出葉子節(jié)點(diǎn)的數(shù)值或類別結(jié)果。

1、我們首先要拿到一些有關(guān)西瓜的有監(jiān)督數(shù)據(jù)(這些西瓜樣本已有標(biāo)注高/低質(zhì)量西瓜),并嘗試選用決策樹(shù)模型來(lái)學(xué)習(xí)這個(gè)劃分西瓜的任務(wù)。如下數(shù)據(jù)樣本示例:
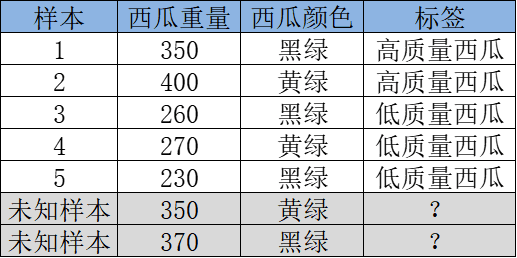
2、后面也就是,憑著已知西瓜樣本的特性/特征【如:西瓜重量、西瓜顏色】,學(xué)習(xí)如何正確地劃分這些西瓜(歸納出本質(zhì)規(guī)律)。開(kāi)始學(xué)習(xí)之前,我們得確定一個(gè)樹(shù)模型在生長(zhǎng)的目標(biāo)(學(xué)習(xí)的目標(biāo))。簡(jiǎn)單來(lái)說(shuō),也就是在當(dāng)前節(jié)點(diǎn)以什么為目標(biāo)來(lái)指導(dǎo)怎么選擇特征及分裂,而劃分得好也就是要?jiǎng)澐殖龅母鹘M的準(zhǔn)確率(純度)都比較高。
3、然后,根據(jù)學(xué)習(xí)目標(biāo),簡(jiǎn)單的我們可以通過(guò)遍歷計(jì)算所有特征不同閾值的劃分效果。選擇各個(gè)的特征及嘗試特征的所有實(shí)際取值,看以哪個(gè)特征閾值劃分西瓜質(zhì)量的效果較好。這個(gè)過(guò)程也就是確定選擇特征及特征閾值劃分的優(yōu)化算法。
4、最終的,按照上面的步驟,我們逐個(gè)特征及取值試著去劃分后發(fā)現(xiàn),根據(jù)西瓜重量的特征 以300g作為劃分出了兩組,我們以葉子節(jié)點(diǎn)的大多數(shù)類作為該節(jié)點(diǎn)的決策類別。可能發(fā)現(xiàn)<300的組 里面低質(zhì)量西瓜占比100%,>300 那組 高質(zhì)量西瓜占比99%,整體分類效果是不錯(cuò)的,最終就確定下了這樣的一個(gè)決策樹(shù)模型。
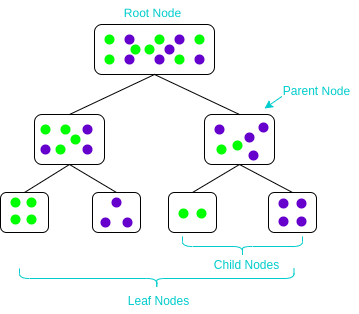
二、樹(shù)模型的要素
從上述例子,我們可以將樹(shù)模型的學(xué)習(xí)可以歸到經(jīng)典機(jī)器學(xué)習(xí)的4個(gè)要素:
2.0 已知(標(biāo)簽)的數(shù)據(jù) 2.1 樹(shù)模型的結(jié)構(gòu)(分段函數(shù)結(jié)構(gòu):特征劃分+決策結(jié)果) 2.2 學(xué)習(xí)目標(biāo) 2.3 優(yōu)化算法
樹(shù)模型通過(guò)結(jié)合這幾個(gè)要素,更快更好地劃分特征空間,得出比較準(zhǔn)確的決策。如下對(duì)這幾個(gè)要素具體解析。
2.1 樹(shù)模型的結(jié)構(gòu)
樹(shù)模型的結(jié)構(gòu)也就是個(gè)分段函數(shù),包含了 選定特征做閾值劃分(內(nèi)部節(jié)點(diǎn)),以及劃分后賦值的分?jǐn)?shù)或類別決策(葉子節(jié)點(diǎn))。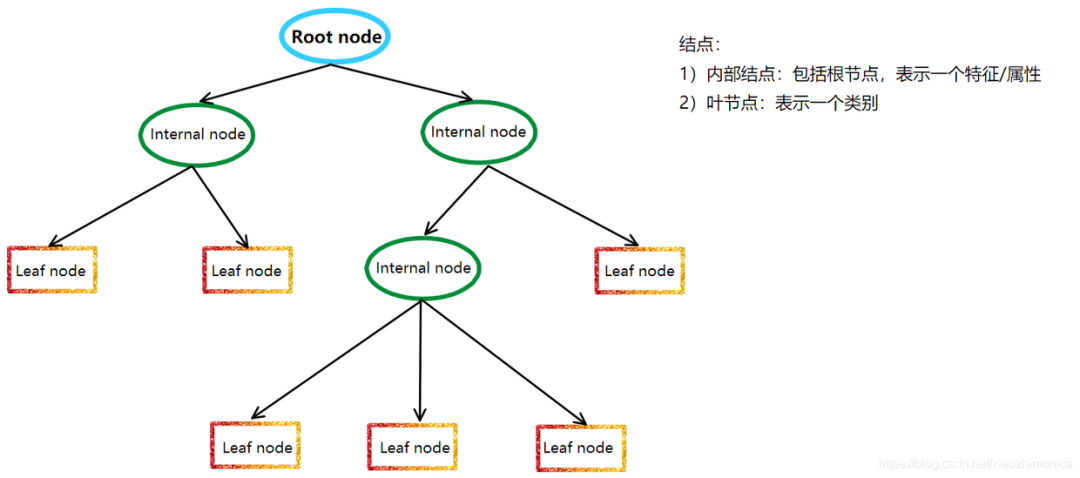
2.1.1學(xué)習(xí)樹(shù)結(jié)構(gòu)的過(guò)程
學(xué)習(xí)樹(shù)模型的關(guān)鍵在于依據(jù)某些學(xué)習(xí)目標(biāo)/指標(biāo)(如劃分準(zhǔn)確度、信息熵、Gini不純度、均方誤差的增益量)去選擇當(dāng)前最優(yōu)的特征并對(duì)樣本的特征空間做非線性準(zhǔn)確的劃分,如上面西瓜的例子選擇了一個(gè)特征做了一次劃分(一刀切),通常情況下僅僅一刀切的劃分準(zhǔn)確度是不夠的,可能還要在前面劃分的樣本基礎(chǔ)上,繼續(xù)多劃分幾次(也就多個(gè)切分條件的分段函數(shù),如 if a>300 且特征b>10 且特征c<100, then 決策結(jié)果1;),以達(dá)到更高的準(zhǔn)確度(純度)。 但是,隨著切分次數(shù)的變多,樹(shù)的復(fù)雜度提高也就容易過(guò)擬合,相應(yīng)每個(gè)切分出的小子特征空間的統(tǒng)計(jì)信息可能只是噪音。減少樹(shù)生長(zhǎng)過(guò)程的過(guò)擬合的風(fēng)險(xiǎn),一個(gè)重要的方法就是樹(shù)的剪枝,剪枝是一種正則化:由于決策樹(shù)容易對(duì)數(shù)據(jù)產(chǎn)生過(guò)擬合,即生長(zhǎng)出結(jié)構(gòu)過(guò)于復(fù)雜的樹(shù)模型,這時(shí)局部的特征空間會(huì)越分越“小”得到了不靠譜的“統(tǒng)計(jì)噪聲”。通過(guò)剪枝算法可以降低復(fù)雜度,減少過(guò)擬合的風(fēng)險(xiǎn)。
但是,隨著切分次數(shù)的變多,樹(shù)的復(fù)雜度提高也就容易過(guò)擬合,相應(yīng)每個(gè)切分出的小子特征空間的統(tǒng)計(jì)信息可能只是噪音。減少樹(shù)生長(zhǎng)過(guò)程的過(guò)擬合的風(fēng)險(xiǎn),一個(gè)重要的方法就是樹(shù)的剪枝,剪枝是一種正則化:由于決策樹(shù)容易對(duì)數(shù)據(jù)產(chǎn)生過(guò)擬合,即生長(zhǎng)出結(jié)構(gòu)過(guò)于復(fù)雜的樹(shù)模型,這時(shí)局部的特征空間會(huì)越分越“小”得到了不靠譜的“統(tǒng)計(jì)噪聲”。通過(guò)剪枝算法可以降低復(fù)雜度,減少過(guò)擬合的風(fēng)險(xiǎn)。
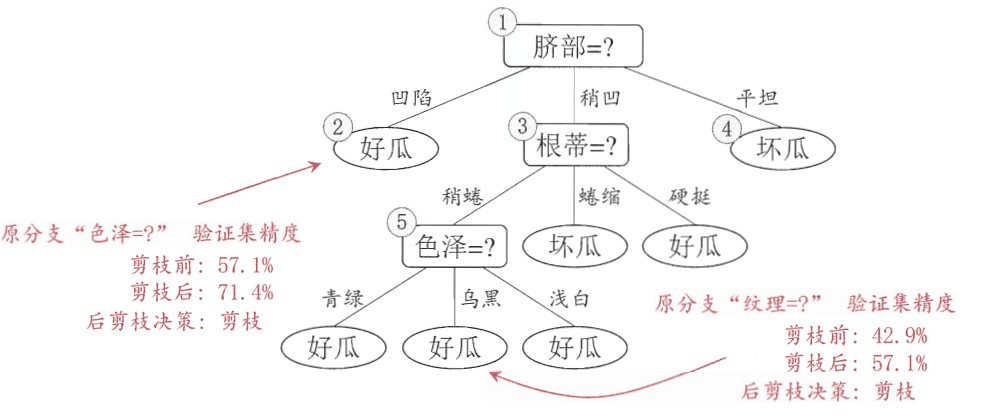
決策樹(shù)剪枝的目的是極小化經(jīng)驗(yàn)損失+結(jié)構(gòu)損失,基本策略有”預(yù)剪枝“和”后剪枝“兩種策略:①預(yù)剪枝:是在決策樹(shù)生成過(guò)程中,限制劃分的最大深度、葉子節(jié)點(diǎn)數(shù)和最小樣本數(shù)目等,以減少不必要的模型復(fù)雜度;②后剪枝:是先從訓(xùn)練集生成一棵完整的決策樹(shù),然后用用驗(yàn)證集自底向上地對(duì)非葉結(jié)點(diǎn)進(jìn)行考察,若將該節(jié)點(diǎn)對(duì)應(yīng)的子樹(shù)替換為葉子結(jié)點(diǎn)(剪枝)能帶來(lái)決策樹(shù)的泛化性能提升(即目標(biāo)函數(shù)損失更小,常用目標(biāo)函數(shù)如:loss = 模型經(jīng)驗(yàn)損失bias+ 模型結(jié)構(gòu)損失α|T|, T為節(jié)點(diǎn)數(shù)目, α為系數(shù)),則將該子樹(shù)替換為葉子結(jié)點(diǎn)。
2.1.2 復(fù)雜樹(shù)結(jié)構(gòu)的進(jìn)階
樹(shù)模型的集成學(xué)習(xí)
實(shí)踐中可以發(fā)現(xiàn),淺層的樹(shù)很容易欠擬合,而通過(guò)加深樹(shù)的深度,雖然可以提高訓(xùn)練集的準(zhǔn)確度,卻很容易過(guò)擬合。
這個(gè)角度來(lái)看,單個(gè)樹(shù)模型是比較弱的,且很容易根據(jù)特征選擇、深度等超參數(shù)調(diào)節(jié)各樹(shù)模型的多樣性。正因?yàn)檫@些特點(diǎn),決策樹(shù)很適合通過(guò)結(jié)合多個(gè)的樹(shù)模型做集成學(xué)習(xí)進(jìn)一步提升模型效果。
集成學(xué)習(xí)是結(jié)合一些的基學(xué)習(xí)器共同學(xué)習(xí),來(lái)改進(jìn)其泛化能力和魯棒性的方法,主流的有兩種集成思想:
并行方式(bagging):獨(dú)立的訓(xùn)練一些基學(xué)習(xí)器,然后(加權(quán))平均它們的預(yù)測(cè)結(jié)果。代表模型如:Random Forests;
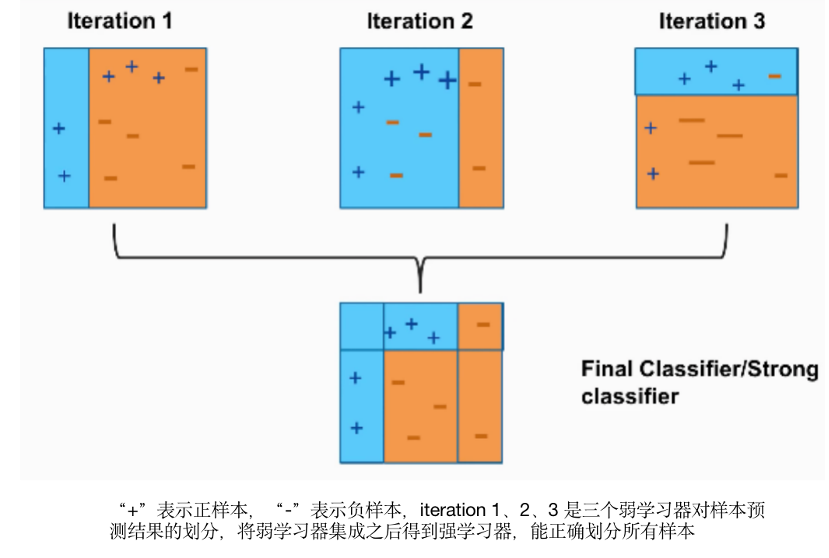
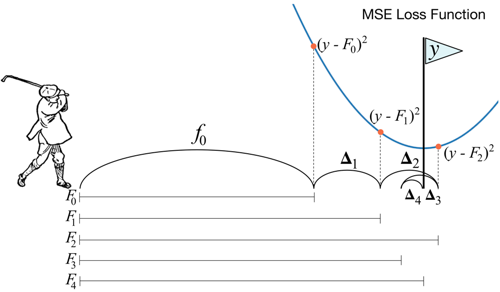
串行方式(boosting):一個(gè)接一個(gè)的(串行)訓(xùn)練基學(xué)習(xí)器,每一個(gè)基學(xué)習(xí)器主要用來(lái)修正前面學(xué)習(xí)器的偏差。代表模型如:AdaBoost、GBDT及XGBOOST;(擴(kuò)展:像基于cart回歸樹(shù)的GBDT集成方法,通過(guò)引入了損失函數(shù)的梯度去代替殘差,這個(gè)過(guò)程也類似局部的梯度下降算法)
線性決策樹(shù)
樹(shù)模型天然具有非線性的特點(diǎn),但與此有個(gè)缺陷,樹(shù)模型卻學(xué)習(xí)不好簡(jiǎn)單的線性回歸!可以簡(jiǎn)單構(gòu)想下傳統(tǒng)決策樹(shù)表達(dá) y=|2x|這樣規(guī)律,需要怎么做?如 if x=1,then 2; x =3, then 6 .....;這樣窮舉顯然不可能的。這里介紹下線性決策樹(shù),其實(shí)原理也很簡(jiǎn)單:把線性回歸加到?jīng)Q策樹(shù)的葉子節(jié)點(diǎn)里面(特征劃分完后,再用線性模型擬合做決策)。一個(gè)簡(jiǎn)單線性樹(shù)模型用分段函數(shù)來(lái)表示如:if x >0, then 2x;代表模型有 linear decision tree, GBDT-PL等模型。
2.2 學(xué)習(xí)目標(biāo)(目標(biāo)函數(shù))
上文有提到,樹(shù)模型的學(xué)習(xí)目標(biāo)就是讓各組的劃分的準(zhǔn)確率(純度)都比較高,減小劃分誤差損失(此處忽略了結(jié)構(gòu)損失T)。能達(dá)成劃分前后損失差異效果類似的指標(biāo)有很多:信息熵、基尼系數(shù)、MSE損失函數(shù)等等 都可以評(píng)估劃分前后的純度的增益 ,其實(shí)都是對(duì)分類誤差的一種衡量,不同指標(biāo)也對(duì)應(yīng)這不同類型的決策樹(shù)方法。

ID3決策樹(shù)的指標(biāo):信息增益(information gain) 信息增益定義為集合 D 的經(jīng)驗(yàn)熵 H(D) 與特征 A 給定條件下 D 的經(jīng)驗(yàn)條件熵 H(D|A) 之差,也就是信息熵減去條件信息熵,表示得知特征X的信息而使得Y的信息的不確定性減少的程度(信息增益越大,表示已知X的情況下, Y基本就確定了)。 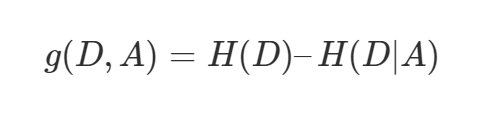
使用信息增益做特征劃分的缺點(diǎn)是:信息增益偏向取值較多的特征。當(dāng)特征的取值較多時(shí),根據(jù)此特征劃分更容易得到純度更高的子集,因此劃分之后的熵更低,由于劃分前的熵是一定的,因此信息增益更大,因此信息增益比較偏向取值較多的特征。
C4.5決策樹(shù)的指標(biāo):信息增益比
信息增益比也就是信息增益除以信息熵,這樣可以減少偏向取值較多信息熵較大的特征。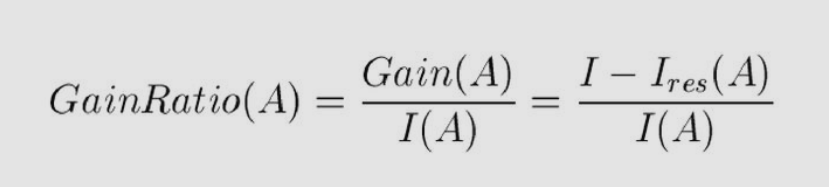
相應(yīng)的,使用信息增益比缺點(diǎn)是:信息增益比偏向取值較少的特征。綜上兩種指標(biāo),可以在候選特征中找出信息增益高于平均水平的特征,然后在這些特征中再選擇信息增益率最高的特征。
Cart決策樹(shù)的指標(biāo):基尼系數(shù)(分類樹(shù)) 或 平方誤差損失(回歸)
與信息熵一樣(信息熵 如下式)
基尼系數(shù)表征的也是事件的不確定性(不純度),也都可以看做是對(duì)分類誤差率的衡量。
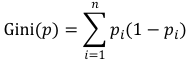
我們將熵定義式中的“-log(pi)”替換為 1-pi 也就是基尼系數(shù),因?yàn)?log(pi)的泰勒近似展開(kāi)第一項(xiàng)就是1-pi。基尼系數(shù)簡(jiǎn)單來(lái)看就是熵的“平替版”,在衡量分類誤差的同時(shí),也簡(jiǎn)化了大量計(jì)算。
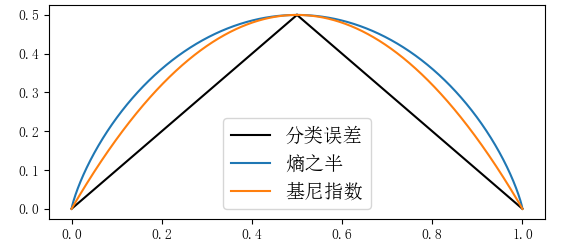
(注:由于分類誤差為分段函數(shù)=1-max(p, 1-p) ,不便于微分計(jì)算,實(shí)際中也比較少直接用)
當(dāng)Cart應(yīng)用于回歸任務(wù),平方誤差損失也就是Cart回歸樹(shù)的生長(zhǎng)指標(biāo)。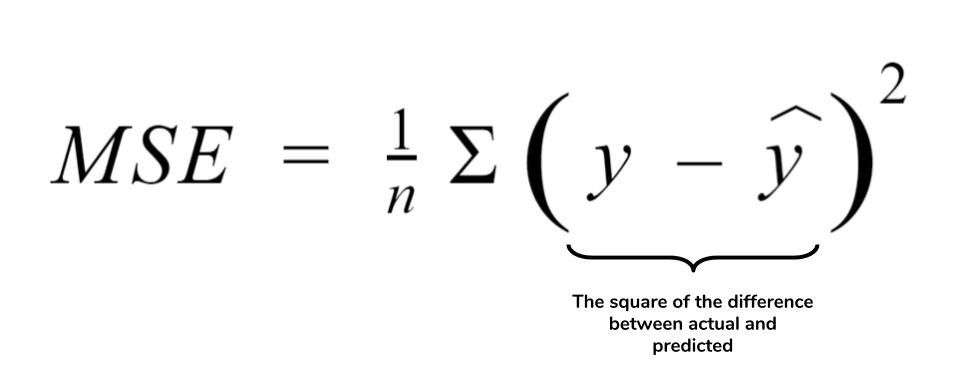
2.3 優(yōu)化算法
確認(rèn)學(xué)習(xí)目標(biāo),而依據(jù)這個(gè)指標(biāo)去學(xué)習(xí)具體樹(shù)結(jié)構(gòu)的方法(優(yōu)化算法),基本上有幾種思路:
暴力枚舉:嘗試所有可能的特征劃分及組合,以找到目標(biāo)函數(shù)最優(yōu)的樹(shù)結(jié)構(gòu)。但在現(xiàn)實(shí)任務(wù)中這基本是不可能的。
自上而下的貪心算法:每一步(節(jié)點(diǎn))都選擇現(xiàn)在最優(yōu)(信息增益、gini、平方誤差損失)的特征劃分,最終生成一顆決策樹(shù),這也是決策樹(shù)普遍的啟發(fā)式方法,代表有:cart樹(shù)、ID3、C4.5樹(shù)等等
隨機(jī)優(yōu)化:隨機(jī)選擇特征及劃分方式,通常這種方法單樹(shù)的生長(zhǎng)較快且復(fù)雜度較高。模型的隨機(jī)性、偏差比較大(模型的方差相對(duì)較小,不容易過(guò)擬合,但是bias較大),所以常用集成bagging的思路進(jìn)一步優(yōu)化收斂。代表有:Extremely randomized trees(極端隨機(jī)樹(shù))、孤立森林等等.
總結(jié)
樹(shù)模型也就是基于已知數(shù)據(jù)上, 通過(guò)以學(xué)習(xí)目標(biāo)(降低各劃分節(jié)點(diǎn)的誤差率)為指導(dǎo),啟發(fā)式地選擇特征去劃分特征空間,以各劃分的葉子節(jié)點(diǎn)做出較"優(yōu)"的決策結(jié)果。所以,樹(shù)模型有非常強(qiáng)的非線性能力,但是,由于是基于劃分的局部樣本做決策,過(guò)深(劃分很多次)的樹(shù),局部樣本的統(tǒng)計(jì)信息可能失準(zhǔn),容易過(guò)擬合。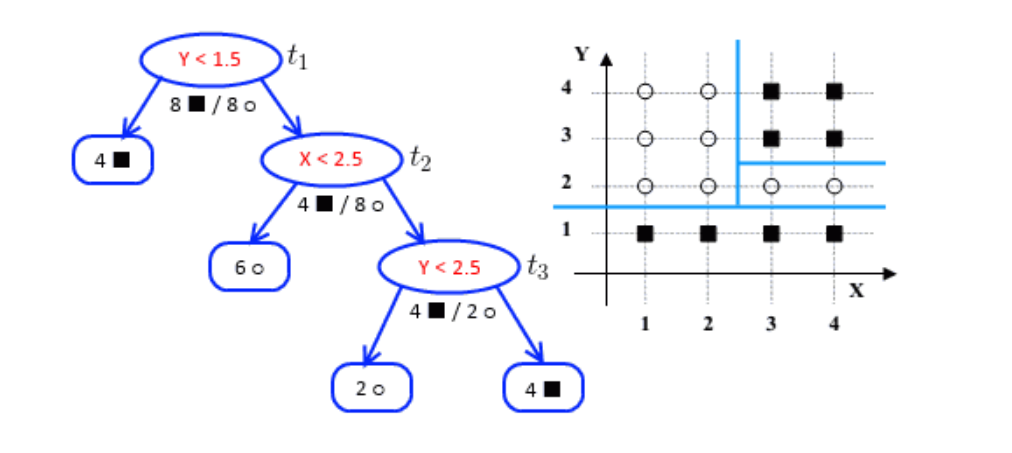
(END)
-?推薦閱讀?-
深度學(xué)習(xí)系列
2、一文搞定深度學(xué)習(xí)建模預(yù)測(cè)全流程(Python)
5、一文詳解RNN及股票預(yù)測(cè)實(shí)戰(zhàn)(Python)!
6、神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)到的是什么?(Python)
機(jī)器學(xué)習(xí)系列
1、一文全覽機(jī)器學(xué)習(xí)建模流程(Python代碼)
3、一文速覽機(jī)器學(xué)習(xí)的類別(Python代碼)
4、從深度學(xué)習(xí)到深度森林方法(Python)
文末,粉絲福利來(lái)了!!關(guān)注【算法進(jìn)階】↓
后臺(tái)回復(fù)【課程】,即可免費(fèi)領(lǐng)取Python|機(jī)器學(xué)習(xí)|AI 精品課程大全
機(jī)??器學(xué)習(xí)算法交流群,邀您加入!!!
入群:提問(wèn)求助;認(rèn)識(shí)行業(yè)內(nèi)同學(xué),交流進(jìn)步;共享資源...
掃描??下方二維碼,備注“加群”
更多GitHub博客文章|相關(guān)代碼|資料
↓點(diǎn)擊【閱讀原文】即可!? ?
有收獲的話,點(diǎn)贊 關(guān)注 再看三連↓