
【深度學(xué)習(xí)】NetAug(網(wǎng)絡(luò)增強(qiáng))—Dropout的反面
Large Model vs Tiny Model
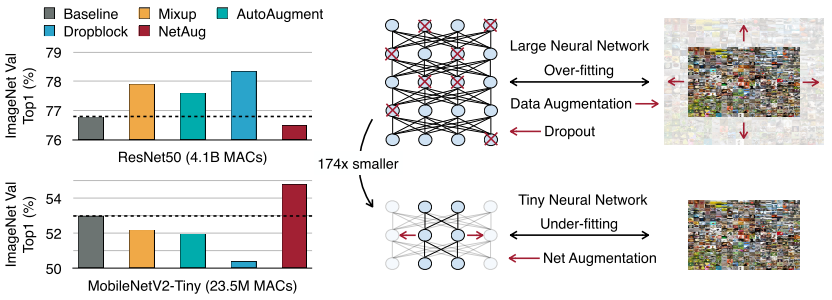
本文明確指出大模型過擬合,需要通過dropout等正則化技術(shù)和數(shù)據(jù)增強(qiáng)來提升精度;而小模型是欠擬合的,需要增強(qiáng)網(wǎng)絡(luò)技術(shù),正則化技術(shù)對(duì)小網(wǎng)絡(luò)是有害的。
如上圖所示ResNet50(大模型)正則化后,精度都有所提升,NetAug會(huì)掉點(diǎn);而MobileNetV2-Tiny(小模型)正則化會(huì)掉點(diǎn),NetAug會(huì)提升精度。
Formulation
標(biāo)準(zhǔn)的隨機(jī)梯度下降公式為:
?
因?yàn)樾∧P偷娜萘渴芟蓿绕鸫竽P透菀紫萑刖植孔顑?yōu),最終導(dǎo)致不能得到最佳性能。為了提升小模型的精度,就需要引入額外的監(jiān)督信號(hào)(比如KD和multi-task learning方法)。dropout方法鼓勵(lì)模型的子集進(jìn)行預(yù)測(cè),而本文提出的NetAug則鼓勵(lì)小模型作為一組大模型的子模型進(jìn)行預(yù)測(cè)(這組大模型通過增強(qiáng)小模型的width構(gòu)建的)。總的loss函數(shù)可以寫成:
?
?
Constructing Augmented Models
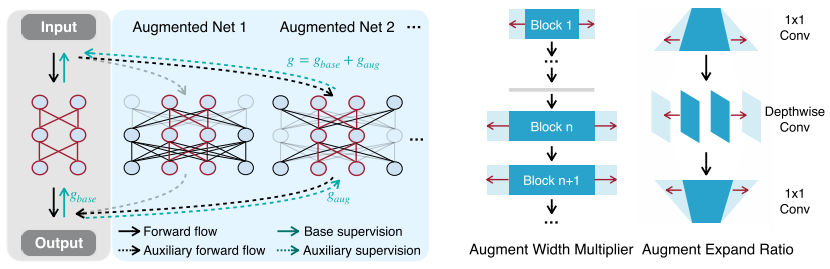
如左圖所示,構(gòu)建一個(gè)最大的增強(qiáng)模型(包含需要的小模型,參數(shù)共享),其他增強(qiáng)模型從最大增強(qiáng)模型中采樣。這種參數(shù)共享構(gòu)建supernet的方式,之前在one-shot NAS中非常流行,詳細(xì)可以看我之前的文章:https://zhuanlan.zhihu.com/p/74985066。
如右圖所示,NetAug通過調(diào)整width構(gòu)建其他增強(qiáng)模型,比起通過調(diào)整depth構(gòu)建增強(qiáng)模型,訓(xùn)練開銷更小。構(gòu)建增強(qiáng)模型引入augmentation factor r和diversity factor s兩個(gè)超參數(shù),假設(shè)我們需要的小模型其中一個(gè)卷積寬度是w,最大增強(qiáng)模型的卷積寬度就是rxw,s表示從w到rw寬度之間等間距采樣s個(gè)增強(qiáng)模型卷積寬度。比如r=3,s=2,那么widths=[w, 2w, 3w]。
訓(xùn)練階段,NetAug在每個(gè)step采樣一個(gè)增強(qiáng)模型進(jìn)行輔助訓(xùn)練。NetAug訓(xùn)練額外開銷相比baseline增加了16.7%,推理額外開銷為0。
Experiments
1.Effectiveness of NetAug for Tiny Deep Learning

可以看到,NetAug和KD是正交的,可以在KD基礎(chǔ)上繼續(xù)提升性能。
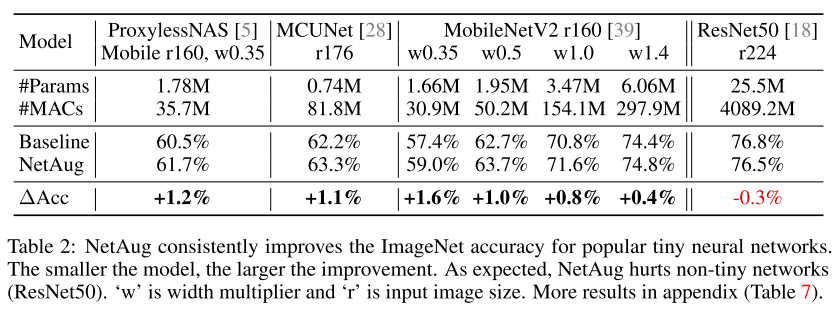
在流行的小模型和NAS模型基礎(chǔ)上,NetAug可以繼續(xù)提升性能,但是對(duì)于大模型(ResNet50)來說,NetAug是有害的。
2.Comparison with Regularization Methods
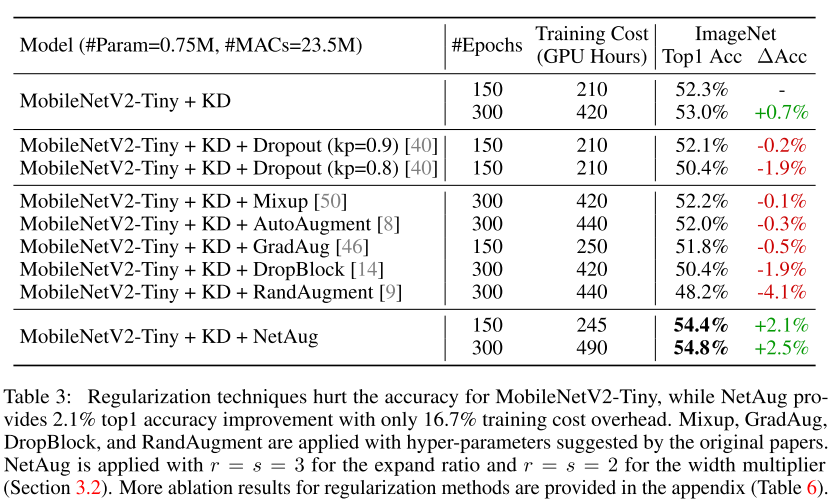
正則化技術(shù)對(duì)于小模型來說是有害的。
3.Combined with Network Pruning
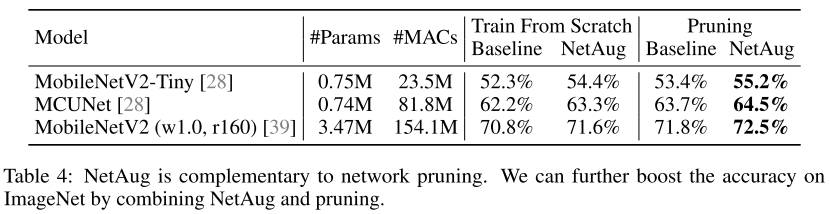
在Pruning的基礎(chǔ)上,NetAug也能提升性能。
4.Large Model vs Tiny Model
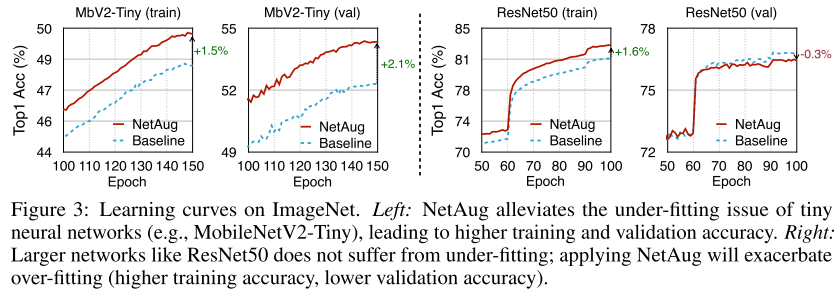
上圖清晰的揭示了本文提出的結(jié)論,小模型欠擬合,NetAug可以提升性能;大模型過擬合,NetAug是有害的。
5.The Number of Augmented Model
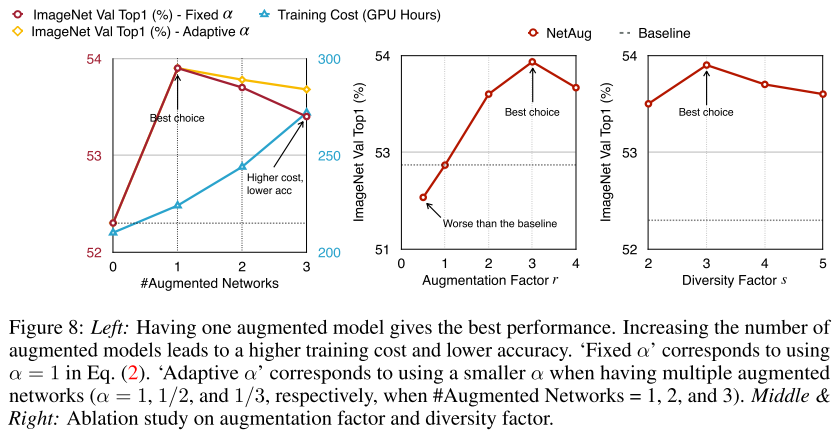
實(shí)驗(yàn)表明,每個(gè)step采樣一個(gè)augmented model是最有的,r和s超參數(shù)都設(shè)置為3最優(yōu)。
總結(jié)
NetAug vs OFA
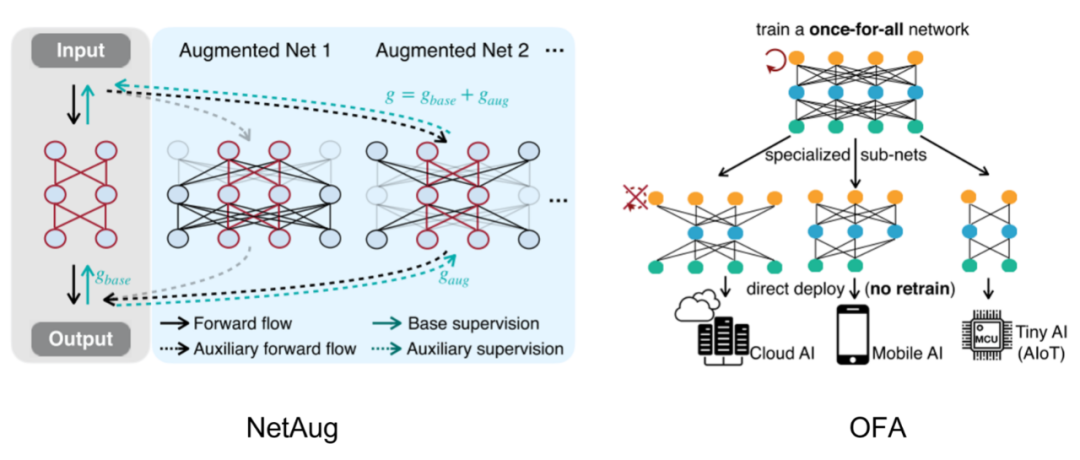
NetAug和之前的OFA非常相似,OFA先構(gòu)建一個(gè)大模型,然后訓(xùn)練這個(gè)大模型,最后通過搜索的方式得到小模型。
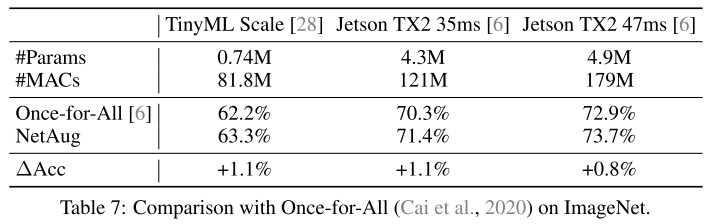
從上表可以看到,在OFA搜索得到模型的基礎(chǔ)上,NetAug還可以繼續(xù)提升性能,也驗(yàn)證了NetAug可以進(jìn)行網(wǎng)絡(luò)增強(qiáng)的作用。
OFA和NetAug其實(shí)是一體兩面:一個(gè)是自上而下通過supernet搜索最好的子網(wǎng)絡(luò),另一個(gè)是自下而上通過supernet輔助訓(xùn)練小網(wǎng)絡(luò)。一個(gè)是終點(diǎn)未知,找最優(yōu)終點(diǎn)(類似搜索);另一個(gè)是終點(diǎn)已知,增強(qiáng)終點(diǎn)性能(類似動(dòng)態(tài)規(guī)劃)。
OFA的問題在于,大量的時(shí)間資源花費(fèi)在可能跟最終目的無關(guān)的子模型上,而NetAug的優(yōu)勢(shì)在于,已知想要的小模型,通過supernet來提升小模型的精度。
小模型欠擬合,需要增加而外的監(jiān)督信息(NetAug、KD、multi-task learning);大模型過擬合,需要正則化。
NetAug和KD的差別在于,KD是通過outer network來輔助訓(xùn)練(提供信息),而NetAug是通過inner network來輔助訓(xùn)練(共享參數(shù))。
正如標(biāo)題所言,NetAug(網(wǎng)絡(luò)增強(qiáng))是Dropout的反面。
Reference
1.https://zhuanlan.zhihu.com/p/74985066
2.ONCE-FOR-ALL: TRAIN ONE NETWORK AND SPE- CIALIZE IT FOR EFFICIENT DEPLOYMENT
3.NETWORK AUGMENTATION FOR TINY DEEP LEARNING
往期精彩回顧 本站qq群554839127,加入微信群請(qǐng)掃碼: