
深度學習中Dropout原理解析
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

目錄:
1. Dropout簡介
1.1 Dropout出現(xiàn)的原因
1.2 什么是Dropout
2. Dropout工作流程及使用
2.1 Dropout具體工作流程
2.2 Dropout在神經(jīng)網(wǎng)絡中的使用
3. 為什么說Dropout可以解決過擬合
4. Dropout在Keras中的源碼分析
1. Dropout簡介
1.1 Dropout出現(xiàn)的原因
在機器學習的模型中,如果模型的參數(shù)太多,而訓練樣本又太少,訓練出來的模型很容易產(chǎn)生過擬合的現(xiàn)象。在訓練神經(jīng)網(wǎng)絡的時候經(jīng)常會遇到過擬合的問題,過擬合具體表現(xiàn)在:模型在在訓練數(shù)據(jù)上損失函數(shù)較小,預測準確率較高;但是在測試數(shù)據(jù)上損失函數(shù)比較大,預測準確率較低。
過擬合是很多機器學習的通病。如果模型過擬合,那么得到的模型幾乎不能用。為了解決過擬合問題,一般會采樣模型集成的方法,即訓練多個模型進行組合。此時,訓練模型費時就成為一個很大的問題,不僅訓練多個模型費時,測試多個模型也是很費時。
綜上所述,訓練深度神經(jīng)網(wǎng)絡的時候,總是會遇到兩大缺點:
(1) 容易過擬合
(2) 費時
Dropout可以比較有效的緩解過擬合的發(fā)生,在一定程度上達到正則化的效果。
1.2 什么是Dropout
在2012年,Hinton在其論文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。當一個復雜的前饋神經(jīng)網(wǎng)絡被訓練在小的數(shù)據(jù)集時,容易造成過擬合。為了防止過擬合,可以通過阻止特征檢測器的共同作用來提高神經(jīng)網(wǎng)絡的性能。
在2012年,Alex、Hinton在其論文《ImageNet Classification with Deep Convolutional Neural Networks》中用到了Dropout算法,用于防止過擬合。并且,這篇論文提到的AlexNet網(wǎng)絡模型引爆了神經(jīng)網(wǎng)絡應用熱潮,并贏得了2012年圖像識別大賽冠軍,使得CNN成為圖像分類上的核心算法模型。
隨后,又有一些關于Dropout的文章《Dropout:A Simple Way to Prevent Neural Networks from Overfitting》、《Improving Neural Networks with Dropout》、《Dropout as data augmentation》。
從上面的論文中,我們能感受到Dropout在深度學習中的重要性。那么,到底什么是Dropout呢?
Dropout可以作為訓練深度神經(jīng)網(wǎng)絡的一種trick供選擇。在每個訓練批次中,通過忽略一半的特征檢測器(讓一半的隱層節(jié)點值為0),可以明顯地減少過擬合現(xiàn)象。這種方式可以減少特征檢測器(隱層節(jié)點)間的相互作用,檢測器相互作用是指某些檢測器依賴其他檢測器才能發(fā)揮作用。
Dropout說的簡單一點就是:我們在前向傳播的時候,讓某個神經(jīng)元的激活值以一定的概率p停止工作,這樣可以使模型泛化性更強,因為它不會太依賴某些局部的特征,如圖1所示。
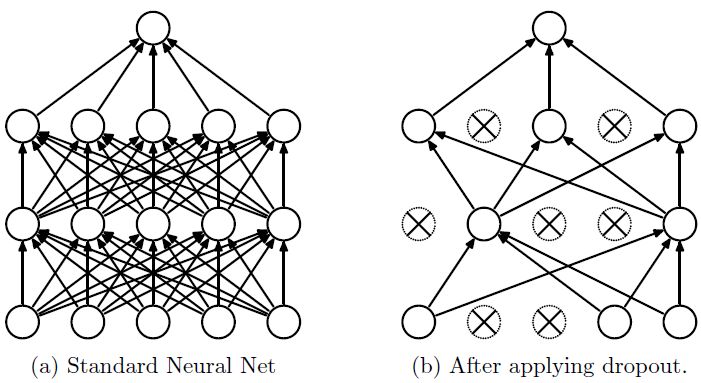
圖1:使用Dropout的神經(jīng)網(wǎng)絡模型
2. Dropout工作流程及使用
2.1 Dropout具體工作流程
假設我們要訓練這樣一個神經(jīng)網(wǎng)絡,如圖2所示。
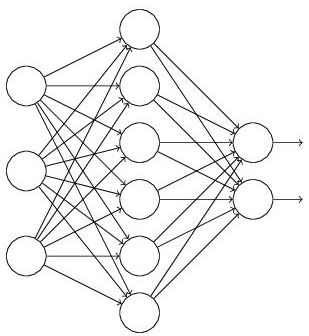
圖2:標準的神經(jīng)網(wǎng)絡
輸入是x輸出是y,正常的流程是:我們首先把x通過網(wǎng)絡前向傳播,然后把誤差反向傳播以決定如何更新參數(shù)讓網(wǎng)絡進行學習。使用Dropout之后,過程變成如下:
(1) 首先隨機(臨時)刪掉網(wǎng)絡中一半的隱藏神經(jīng)元,輸入輸出神經(jīng)元保持不變(圖3中虛線為部分臨時被刪除的神經(jīng)元)
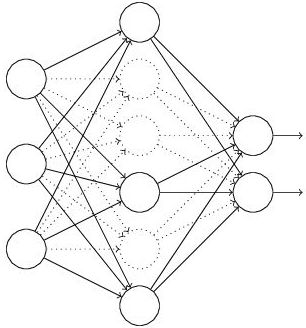
圖3:部分臨時被刪除的神經(jīng)元
(2) 然后把輸入x通過修改后的網(wǎng)絡前向傳播,然后把得到的損失結(jié)果通過修改的網(wǎng)絡反向傳播。一小批訓練樣本執(zhí)行完這個過程后,在沒有被刪除的神經(jīng)元上按照隨機梯度下降法更新對應的參數(shù)(w,b)。
(3) 然后繼續(xù)重復這一過程:
恢復被刪掉的神經(jīng)元(此時被刪除的神經(jīng)元保持原樣,而沒有被刪除的神經(jīng)元已經(jīng)有所更新)。
從隱藏層神經(jīng)元中隨機選擇一個一半大小的子集臨時刪除掉(備份被刪除神經(jīng)元的參數(shù))。
對一小批訓練樣本,先前向傳播然后反向傳播損失并根據(jù)隨機梯度下降法更新參數(shù)(w,b) (沒有被刪除的那一部分參數(shù)得到更新,刪除的神經(jīng)元參數(shù)保持被刪除前的結(jié)果)。
不斷重復這一過程。
2.2 Dropout在神經(jīng)網(wǎng)絡中的使用
Dropout的具體工作流程上面已經(jīng)詳細的介紹過了,但是具體怎么讓某些神經(jīng)元以一定的概率停止工作(就是被刪除掉)?代碼層面如何實現(xiàn)呢?
下面,我們具體講解一下Dropout代碼層面的一些公式推導及代碼實現(xiàn)思路。
(1) 在訓練模型階段
無可避免的,在訓練網(wǎng)絡的每個單元都要添加一道概率流程。
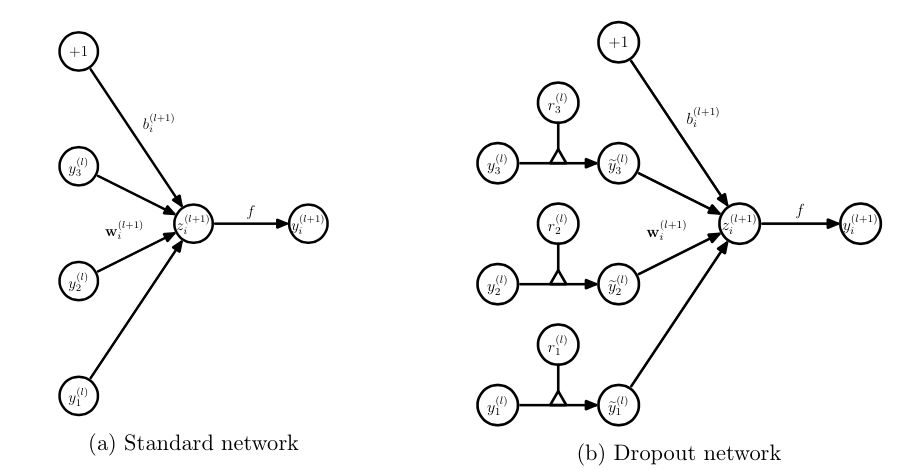
圖4:標準網(wǎng)絡和帶有Dropout網(wǎng)絡的比較
對應的公式變化如下:
沒有Dropout的網(wǎng)絡計算公式:
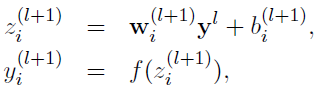
采用Dropout的網(wǎng)絡計算公式:
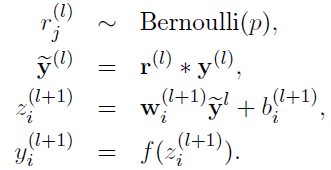
上面公式中Bernoulli函數(shù)是為了生成概率r向量,也就是隨機生成一個0、1的向量。
代碼層面實現(xiàn)讓某個神經(jīng)元以概率p停止工作,其實就是讓它的激活函數(shù)值以概率p變?yōu)?。比如我們某一層網(wǎng)絡神經(jīng)元的個數(shù)為1000個,其激活函數(shù)輸出值為y1、y2、y3、......、y1000,我們dropout比率選擇0.4,那么這一層神經(jīng)元經(jīng)過dropout后,1000個神經(jīng)元中會有大約400個的值被置為0。
注意: 經(jīng)過上面屏蔽掉某些神經(jīng)元,使其激活值為0以后,我們還需要對向量y1……y1000進行縮放,也就是乘以1/(1-p)。如果你在訓練的時候,經(jīng)過置0后,沒有對y1……y1000進行rescale,那么在測試的時候,就需要對權(quán)重進行縮放,操作如下。
(2)在測試模型階段
預測模型的時候,每一個神經(jīng)單元的權(quán)重參數(shù)要乘以概率p。
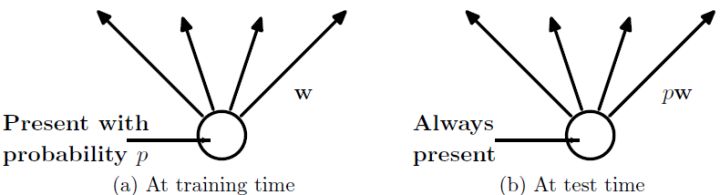
圖5:預測模型時Dropout的操作
測試階段Dropout公式:
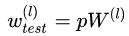
3. 為什么說Dropout可以解決過擬合?
(1)取平均的作用: 先回到標準的模型即沒有dropout,我們用相同的訓練數(shù)據(jù)去訓練5個不同的神經(jīng)網(wǎng)絡,一般會得到5個不同的結(jié)果,此時我們可以采用 “5個結(jié)果取均值”或者“多數(shù)取勝的投票策略”去決定最終結(jié)果。例如3個網(wǎng)絡判斷結(jié)果為數(shù)字9,那么很有可能真正的結(jié)果就是數(shù)字9,其它兩個網(wǎng)絡給出了錯誤結(jié)果。這種“綜合起來取平均”的策略通常可以有效防止過擬合問題。因為不同的網(wǎng)絡可能產(chǎn)生不同的過擬合,取平均則有可能讓一些“相反的”擬合互相抵消。dropout掉不同的隱藏神經(jīng)元就類似在訓練不同的網(wǎng)絡,隨機刪掉一半隱藏神經(jīng)元導致網(wǎng)絡結(jié)構(gòu)已經(jīng)不同,整個dropout過程就相當于對很多個不同的神經(jīng)網(wǎng)絡取平均。而不同的網(wǎng)絡產(chǎn)生不同的過擬合,一些互為“反向”的擬合相互抵消就可以達到整體上減少過擬合。
(2)減少神經(jīng)元之間復雜的共適應關系: 因為dropout程序?qū)е聝蓚€神經(jīng)元不一定每次都在一個dropout網(wǎng)絡中出現(xiàn)。這樣權(quán)值的更新不再依賴于有固定關系的隱含節(jié)點的共同作用,阻止了某些特征僅僅在其它特定特征下才有效果的情況 。迫使網(wǎng)絡去學習更加魯棒的特征 ,這些特征在其它的神經(jīng)元的隨機子集中也存在。換句話說假如我們的神經(jīng)網(wǎng)絡是在做出某種預測,它不應該對一些特定的線索片段太過敏感,即使丟失特定的線索,它也應該可以從眾多其它線索中學習一些共同的特征。從這個角度看dropout就有點像L1,L2正則,減少權(quán)重使得網(wǎng)絡對丟失特定神經(jīng)元連接的魯棒性提高。
(3)Dropout類似于性別在生物進化中的角色:物種為了生存往往會傾向于適應這種環(huán)境,環(huán)境突變則會導致物種難以做出及時反應,性別的出現(xiàn)可以繁衍出適應新環(huán)境的變種,有效的阻止過擬合,即避免環(huán)境改變時物種可能面臨的滅絕。
4. Dropout在Keras中的源碼分析
下面,我們來分析Keras中Dropout實現(xiàn)源碼。
Keras開源項目GitHub地址為:
https://github.com/fchollet/keras/tree/master/keras
其中Dropout函數(shù)代碼實現(xiàn)所在的文件地址:
https://github.com/fchollet/keras/blob/master/keras/backend/theano_backend.py
Dropout實現(xiàn)函數(shù)如下:

圖6:Keras中實現(xiàn)Dropout功能
我們對keras中Dropout實現(xiàn)函數(shù)做一些修改,讓dropout函數(shù)可以單獨運行。
# coding:utf-8
import numpy as np
# dropout函數(shù)的實現(xiàn)
def dropout(x, level):
if level < 0. or level >= 1: #level是概率值,必須在0~1之間
raise ValueError('Dropout level must be in interval [0, 1[.')
retain_prob = 1. - level
# 我們通過binomial函數(shù),生成與x一樣的維數(shù)向量。binomial函數(shù)就像拋硬幣一樣,我們可以把每個神經(jīng)元當做拋硬幣一樣
# 硬幣 正面的概率為p,n表示每個神經(jīng)元試驗的次數(shù)
# 因為我們每個神經(jīng)元只需要拋一次就可以了所以n=1,size參數(shù)是我們有多少個硬幣。
random_tensor = np.random.binomial(n=1, p=retain_prob, size=x.shape) #即將生成一個0、1分布的向量,0表示這個神經(jīng)元被屏蔽,不工作了,也就是dropout了
print(random_tensor)
x *= random_tensor
print(x)
x /= retain_prob
return x
#對dropout的測試,大家可以跑一下上面的函數(shù),了解一個輸入x向量,經(jīng)過dropout的結(jié)果
x=np.asarray([1,2,3,4,5,6,7,8,9,10],dtype=np.float32)
dropout(x,0.4)
函數(shù)中,x是本層網(wǎng)絡的激活值。Level就是dropout就是每個神經(jīng)元要被丟棄的概率。
注意: Keras中Dropout的實現(xiàn),是屏蔽掉某些神經(jīng)元,使其激活值為0以后,對激活值向量x1……x1000進行放大,也就是乘以1/(1-p)。
思考:上面我們介紹了兩種方法進行Dropout的縮放,那么Dropout為什么需要進行縮放呢?
因為我們訓練的時候會隨機的丟棄一些神經(jīng)元,但是預測的時候就沒辦法隨機丟棄了。如果丟棄一些神經(jīng)元,這會帶來結(jié)果不穩(wěn)定的問題,也就是給定一個測試數(shù)據(jù),有時候輸出a有時候輸出b,結(jié)果不穩(wěn)定,這是實際系統(tǒng)不能接受的,用戶可能認為模型有預測不準。那么一種”補償“的方案就是每個神經(jīng)元的權(quán)重都乘以一個p,這樣在“總體上”使得測試數(shù)據(jù)和訓練數(shù)據(jù)是大致一樣的。比如一個神經(jīng)元的輸出是x,那么在訓練的時候它有p的概率參與訓練,(1-p)的概率丟棄,那么它輸出的期望是 px+ (1-p) 0=px。因此測試的時候把這個神經(jīng)元d的權(quán)重乘以p可以得到同樣的期望。
總結(jié):
當前Dropout被大量利用于全連接網(wǎng)絡,而且一般認為設置為0.5或者0.3,而在卷積網(wǎng)絡隱藏層中由于卷積自身的稀疏化以及稀疏化的ReLu函數(shù)的大量使用等原因,Dropout策略在卷積網(wǎng)絡隱藏層中使用較少。總體而言,Dropout是一個超參,需要根據(jù)具體的網(wǎng)絡、具體的應用領域進行嘗試。
好消息!
小白學視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現(xiàn)20個實戰(zhàn)項目,實現(xiàn)OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~