
擼了幾行騷代碼,解放了雙手!
大家好,我是二哥呀~
作為一名技術博主,經常需要把同一份 MD 文件同步到不同的博客平臺,以求獲得更多的曝光,從而幫助到更多的小伙伴——瞧我這“達則兼濟天下”的雄心壯志。像 CSDN 和掘金這兩個博客平臺都有自己的外鏈圖片解析功能。
當我把 MD 源文檔復制到 CSDN 或者掘金的編輯器中,它們會自動地幫我把外鏈轉成內鏈,這樣我就不用再重新上傳圖片,也不需要配置自己的圖床了,否則圖片會因為防盜鏈的原因顯示不出來。
舉個例子,現在有這樣一段 MD 文檔,里面有一張圖片。

把上面的 MD 文檔復制到掘金編輯器的時候,就會出現「圖片解析中...」!但會一直卡在這里,再也解析不下去了。

這是因為圖片加了防盜鏈,掘金這么牛逼的社區(qū)在解析的時候也會失敗。CSDN 的轉鏈功能更牛逼一點,基本上可以無視防盜鏈。
還有一些博客平臺是沒有轉鏈功能的,比如說二哥的靜態(tài)小破站《Java 程序員進階之路》。怎么辦呢?我一開始的解決方案是:
先將圖片手動一張張下載到本地 再將本地圖片上傳到 GitHub 指定的倉庫 修改 MD 文檔中的圖片鏈接,使用 CDN 加速服務
這樣就能解決問題,但是需要手動去做這些重復的動作,尤其遇到一篇文章有二三十張圖片的時候就很煩。這有點喪失我作為程序員的尊嚴啊!
首先要解決的是圖片下載的問題,可以利用爬蟲技術:爬蟲爬得早,局子進的早。

二、關于 Java 爬蟲
Java 爬蟲的類庫非常多,比如說 crawler4j,我個人更喜歡 jsoup,它更輕量級。jsoup 是一款用于解析 HTML 的 Java 類庫,提供了一套非常便捷的 API,用于提取和操作數據。
官網地址:https://jsoup.org/
jsoup 目前在 GitHub 上已經收獲 9.3k+ 的 star,可以說是非常的受歡迎了。
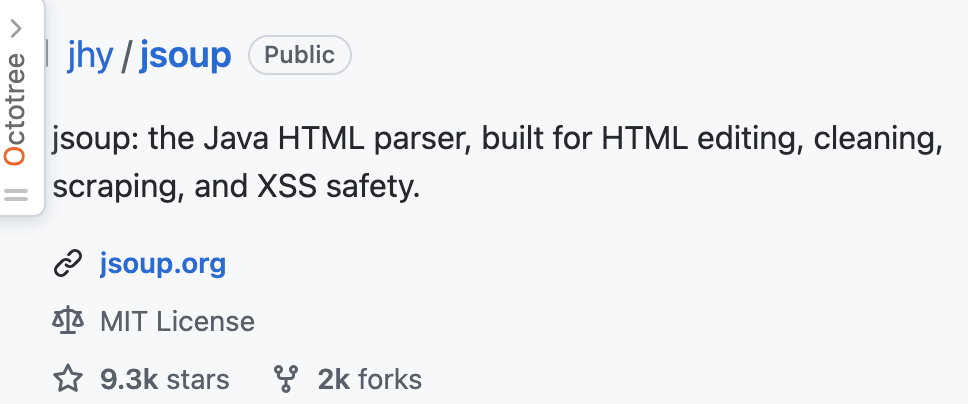
jsoup 有以下特性:
可以從 URL、文件或者字符串中抓取和解析 可以使用 DOM 遍歷或者 CSS 選擇器查找和提取數據 可以操作 HTML 元素、屬性和文本 可以輸出整潔的 HTML
三、實戰(zhàn) jsoup
第一步,添加 jsoup 依賴到項目中。
??
??org.jsoup
??jsoup
??1.14.3
第二步, 獲取網頁文檔。
就拿二哥之前發(fā)表的一篇文章《二哥的小破站終于上線了,顏值賊高》來舉例吧。通過以下代碼就可以拿到網頁文檔了。
Document?doc?=?Jsoup.connect("https://blog.csdn.net/qing_gee/article/details/122407829").get();
String?title?=?doc.title();
Jsoup 類是 jsoup 的入口類,通過 connect 方法可以從指定鏈接中加載 HTML 文檔(用 Document 對象來表示)。
第三步,獲取圖片節(jié)點。
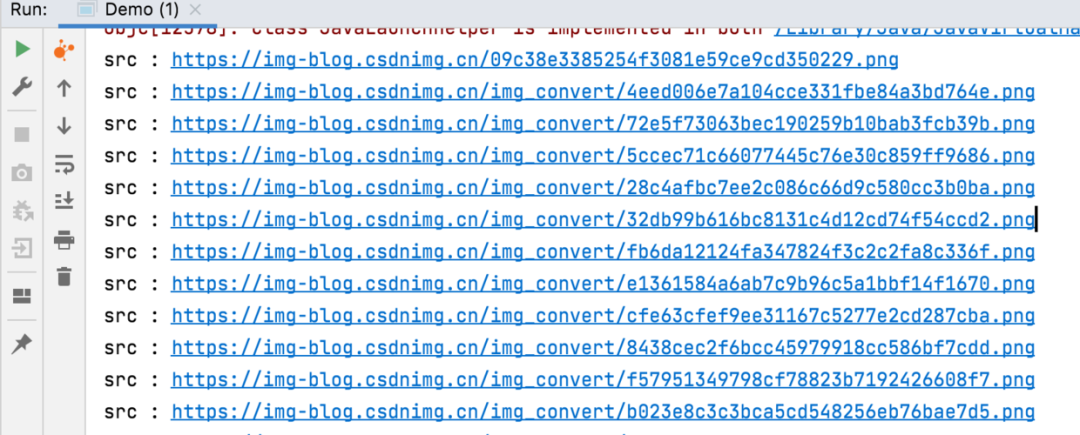
再通過以下代碼可以獲取文章所有的圖片節(jié)點:
Elements?images?=?doc.select(".article_content?img[src~=(?i)\\.(png|jpe?g|gif)]");
for?(Element?image?:?images)?{
????System.out.println("src?:?"?+?image.attr("src"));
}
輸出結構如下所示:
四、下載圖片
拿到圖片的 URL 地址后,事情就好辦了,可以直接通過 JDK 的原生 API 下載圖片到指定文件夾。
String?downloadPath?=?"/tobebetterjavaer-beian-";
for?(Element?image?:?images)?{
????URL?url?=?new?URL(image.attr("src"));
????InputStream?inputStream?=?url.openStream();
????OutputStream?outputStream?=?new?FileOutputStream(downloadPath?+?i?+?".png");
????byte[]?buffer?=?new?byte[2048];
????int?length?=?0;
????while?((length?=?inputStream.read(buffer))?!=?-1)?{
????????outputStream.write(buffer,?0,?length);
????}
}
如果想加快節(jié)奏的話,可以把上面的代碼封裝一下,然后開個多線程,簡單點的話,可以每張圖片起一個線程,速度杠杠的。
new?Thread(new?MyRunnable(originImgUrl,?destinationImgPath)).start()
五、使用 CDN 加速圖片
圖片下載到本地后,接下來的工作就更簡單了,讀取原 MD 文檔,修改圖片鏈接,使用 CDN 進行加速。我的圖床采用的是 GitHub+jsDelivr CDN 的方式,不過由于 jsDelivr 的國內節(jié)點逐漸撤離了,圖片在某些網絡環(huán)境下訪問的時候還是有點慢,后面打算用 OSS+CDN 的方式,更靠譜一點。
讀取文件可以借助一下 hutool 這款 GitHub 上開源的工具類庫,省去很多繁瑣的 IO 操作。
官網:https://hutool.cn/
第一步,將 hutool 添加到 pom.xml 文件中
????cn.hutool
????hutool-all
????5.7.20
第二步,按照行讀取 MD 文件,需要用到 hutool 的 FileReader 類:
FileReader?fileReader?=?FileReader.create(new?File(docPath?+fileName),
????????????????Charset.forName("utf-8"));
List?list?=?fileReader.readLines();
第三步,通過正則表達式來匹配是否有需要替換的圖片標簽,MD 中的圖片標記關鍵字為 ![]()。

如果匹配到,就替換為 jsDelivr CDN 鏈接的地址,寫文件時需要用到 hutool 的FileWriter 類。
FileWriter?writer?=?new?FileWriter(docPath?+?fileName);
for?(String?line?:?list)?{
????Matcher?m?=?pattern.matcher(line);
????if?(m.matches())?{
????????writer.append("\n");
????}?else?{
????????writer.append(line+"\n");
???}
}
writer.flush();
到此為止,整個代碼的編寫工作就告一段落了。很簡單,兩個類庫,幾行代碼就搞定了!
轉換前的 MD 文件如下所示:
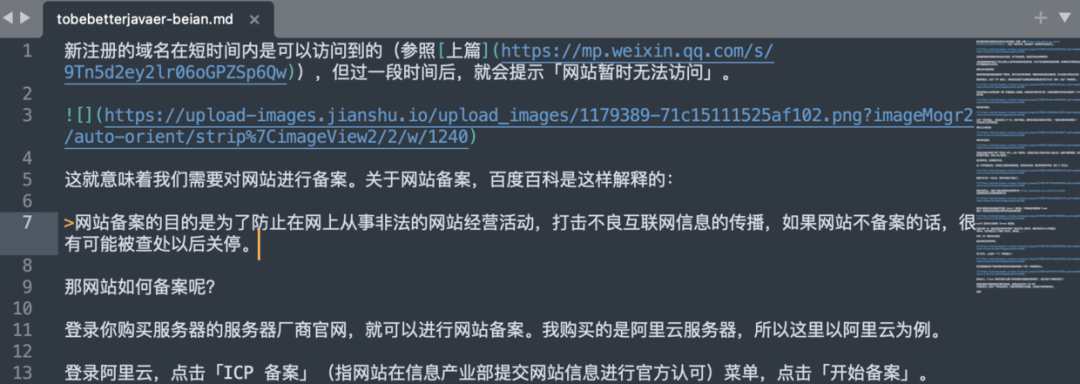
運行代碼轉換后,發(fā)現圖片地址已經變成 jsDelivr CDN 圖庫了。

使用 GitHub 桌面版把圖片和 MD 文檔提交到 GitHub 倉庫后,就可以看到圖片已經加載完成可以訪問了。

六、一點小心得
不得不說,懂點技術,還是非常爽的。擼了幾行代碼,解放了雙手,可以干點正經事了(狗頭)。
這不,重新把《Java 程序員進階之路》的小破站整理排版了一下,新增了不少優(yōu)質的內容。學習 Java 的小伙伴可以開卷了,有需要增加的內容也歡迎提交 issue 啊!
再次感謝各位小伙伴的厚愛,我也會一如既往地完善這個專欄,我們下期見~

沒有什么使我停留——除了目的,縱然岸旁有玫瑰、有綠蔭、有寧靜的港灣,我是不系之舟。
推薦閱讀: