
簡(jiǎn)單的 ConvMixer 會(huì)給 CV 帶來(lái)新范式嗎?
1Patch 就夠了?
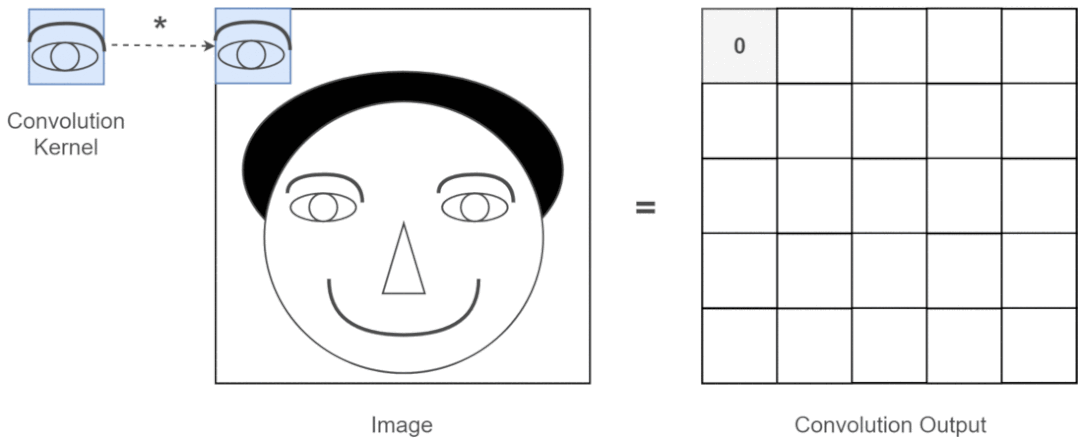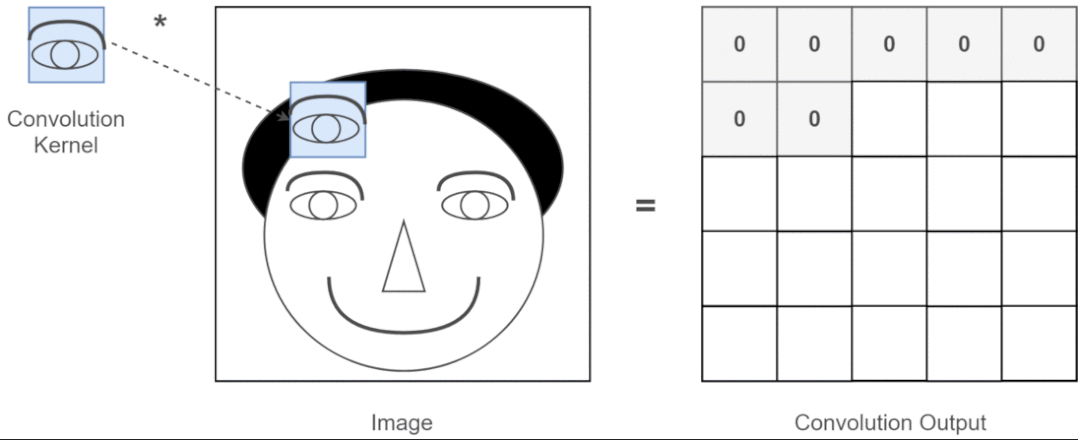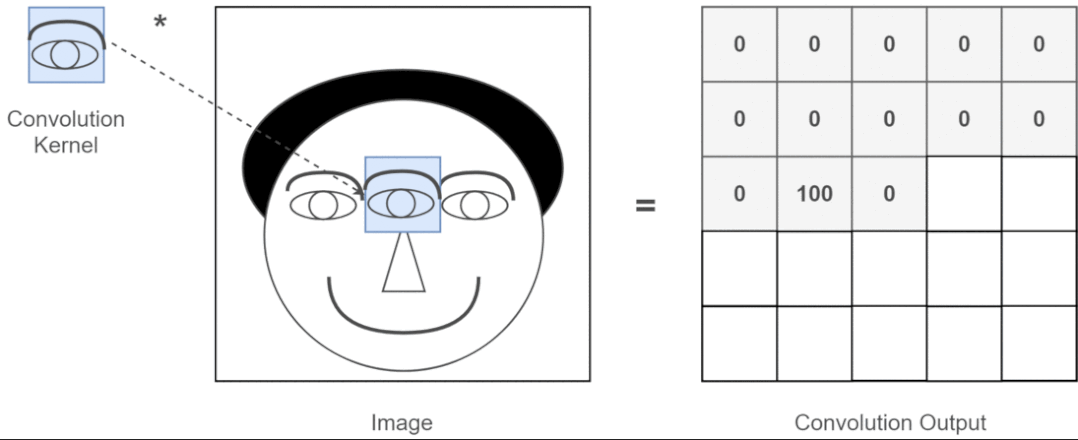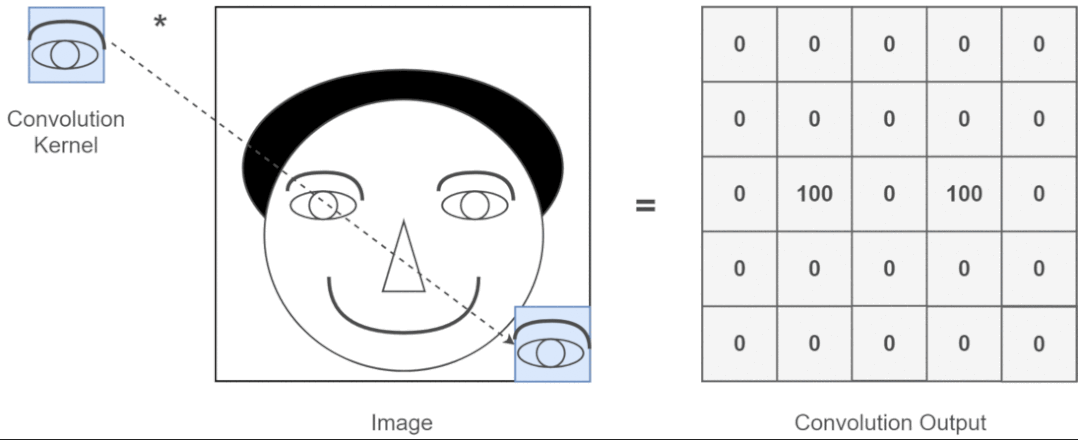
近年來(lái),卷積神經(jīng)網(wǎng)絡(luò)一直是視覺(jué)任務(wù)的主要架構(gòu),但最近的實(shí)驗(yàn)表明,基于 Transformer 的模型,尤其是 Vision Transformer (ViT),在某些情況下可能會(huì)超過(guò) CNN 的性能。
結(jié)合實(shí)例一文擼通 Vision Transformer
然而,由于 Transformer 中自注意力層的計(jì)算復(fù)雜度是關(guān)于 patch 數(shù)量的二次方,對(duì)于大圖的計(jì)算量可觀,因此后續(xù)一大波工作從這個(gè)角度作了一些改進(jìn),關(guān)于這點(diǎn)這里就不談了。
ViT 的成功同時(shí)也帶來(lái)了一個(gè)問(wèn)題,那就是它的性能主要是由于 Transformer 架構(gòu)(自注意力機(jī)制)的強(qiáng)大引起的,或者還是由于使用了 patch 作為輸入表示主導(dǎo)的呢?而本篇的主角,也是 ICLR 2022 還在審稿中的新作 ConvMixer,就為后者提供了一些證據(jù)。
具體而言,ConvMixer 是一個(gè)極其簡(jiǎn)單的模型,在架構(gòu)精神上與 ViT 以及更基本的 MLP-Mixer 相似,它也是直接將 patch 作為輸入進(jìn)行操作,但是它分離了空間和通道兩個(gè)維度上的混合,并在整個(gè)網(wǎng)絡(luò)中保持相同的通道數(shù)和分辨率。
所謂 ConvMixer,就是僅使用卷積來(lái)實(shí)現(xiàn)混合步驟。盡管它很簡(jiǎn)單,但作者表明 ConvMixer 的性能甚至優(yōu)于 ViT、MLP-Mixer 及其類(lèi)似的變體,此外還優(yōu)于 ResNet 等經(jīng)典視覺(jué)模型。
Patches Are All You Need從這個(gè)題目以及模型名字 ConvMixer 似乎可以感覺(jué)到,ViT 中的自注意力并不是必須的,只要使用合適大小的 patch,再加上通道內(nèi)以及通道間的分離卷積混合,照樣能抓取像素之間的遠(yuǎn)程關(guān)聯(lián),實(shí)現(xiàn)很好的數(shù)據(jù)表示。
該論文尚在評(píng)審中,有興趣的可以前往參觀 https://openreview.net/forum?id=TVHS5Y4dNvM。有些人認(rèn)為該論文似乎并沒(méi)有提供非常大的洞見(jiàn)以及理論,更偏向于從實(shí)驗(yàn)中發(fā)現(xiàn)了好用的結(jié)構(gòu)設(shè)計(jì)并給以大家一定的啟示。
2動(dòng)機(jī)
ConvMixer 架構(gòu)基于 patch 以及混合的基本思想。具體來(lái)說(shuō),
用 depthwise 卷積來(lái)混合通道內(nèi)的值, 用 pointwise 卷積來(lái)混合通道間的值。
以往工作的一個(gè)關(guān)鍵思想是 MLP 和自注意力可以混合較遠(yuǎn)的空間信息,即它們可以具有任意大的感受野。因此,該研究通過(guò)使用較大的卷積核來(lái)實(shí)現(xiàn)混合遠(yuǎn)程關(guān)聯(lián)。
3主要參數(shù)
ConvMixer 的實(shí)例化取決于四個(gè)參數(shù):
1、patch 大小 ; 2、patch 的嵌入維度 ; 3、深度 ,即 ConvMixer 層的重復(fù)次數(shù); 4、卷積層的 kernel 大小 。
可以根據(jù)它們的嵌入維度和深度命名具體的 ConvMixers,如 ConvMixer-h/d。
4ConvMixer 核心內(nèi)容
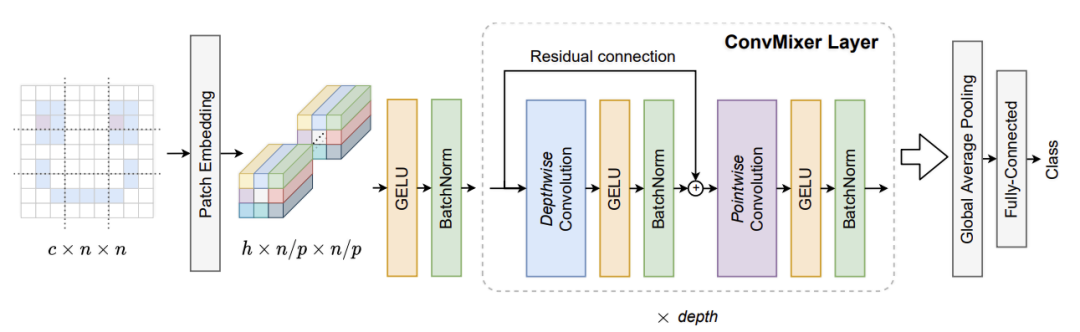
參看上圖,模型 ConvMixer 是由一個(gè) patch 嵌入層以及一個(gè)簡(jiǎn)單的全卷積塊的循環(huán)所構(gòu)成。patch 大小為
ConvMixer 塊本身由 depthwise 卷積(即,組數(shù)等于通道數(shù) h 的分組卷積)和 pointwise(即 kernel 大小為 1×1)卷積組成。
每個(gè)卷積之后是一個(gè)激活和 BatchNorm:
在多次應(yīng)用這個(gè)塊之后,執(zhí)行全局池化以獲得大小為
5實(shí) 驗(yàn)
from?tensorflow.keras?import?layers
from?tensorflow?import?keras
import?matplotlib.pyplot?as?plt
import?tensorflow_addons?as?tfa
import?tensorflow?as?tf
import?numpy?as?np
+超參數(shù)
learning_rate?=?0.001
weight_decay?=?0.0001
batch_size?=?128
num_epochs?=?10
為了快速看到結(jié)果,模型僅僅訓(xùn)練 10 個(gè) epoch,但后面可以看到,結(jié)果還是可以的。
+加載 CIFAR-10 數(shù)據(jù)集
(x_train,?y_train),?(x_test,?y_test)?=?keras.datasets.cifar10.load_data()
val_split?=?0.1
val_indices?=?int(len(x_train)?*?val_split)
new_x_train,?new_y_train?=?x_train[val_indices:],?y_train[val_indices:]
x_val,?y_val?=?x_train[:val_indices],?y_train[:val_indices]
print(f"Training?data?samples:?{len(new_x_train)}")
print(f"Validation?data?samples:?{len(x_val)}")
print(f"Test?data?samples:?{len(x_test)}")
Training data samples: 45000
Validation data samples: 5000
Test data samples: 10000
+數(shù)據(jù)增強(qiáng)
image_size?=?32
auto?=?tf.data.AUTOTUNE
data_augmentation?=?keras.Sequential(
????[layers.RandomCrop(image_size,?image_size),?layers.RandomFlip('horizontal'),],
????name='data_augmentation',
)
def?make_datasets(images,?labels,?is_train=False):
????dataset?=?tf.data.Dataset.from_tensor_slices((images,?labels))
????if?is_train:
????????dataset?=?dataset.shuffle(batch_size?*?10)
????dataset?=?dataset.batch(batch_size)
????if?is_train:
????????dataset?=?dataset.map(
????????????lambda?x,?y:?(data_augmentation(x),?y),?num_parallel_calls=auto
????????)
????return?dataset.prefetch(auto)
train_dataset?=?make_datasets(new_x_train.astype(np.float32),?new_y_train,?is_train=True)
val_dataset?=?make_datasets(x_val.astype(np.float32),?y_val)
test_dataset?=?make_datasets(x_test.astype(np.float32),?y_test)
6網(wǎng)絡(luò)實(shí)現(xiàn)
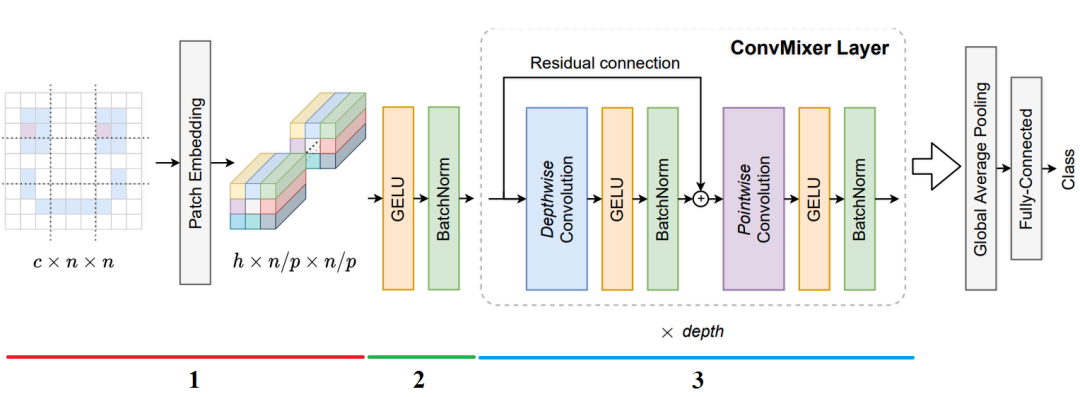
再次查看此圖,我們直接根據(jù)這個(gè)流程圖中的幾個(gè)步驟來(lái)擼代碼。
+1、計(jì)算 patch 的嵌入
塊大小為
def?conv_stem(x,?filters:?int,?patch_size:?int):
????x?=?layers.Conv2D(filters,?kernel_size=patch_size,?strides=patch_size)(x)
????return?activation_block(x)
+2、ConvMixer 前的激活塊
def?activation_block(x):
????x?=?layers.Activation('gelu')(x)
????return?layers.BatchNormalization()(x)
+3、ConvMixer 塊
def?conv_mixer_block(x,?filters:?int,?kernel_size:?int):
????#?Depthwise?卷積
????x0?=?x
????x?=?layers.DepthwiseConv2D(kernel_size=kernel_size,?padding='same')(x)
????x?=?layers.Add()([activation_block(x),?x0])??#?殘差連接
????#?Pointwise?卷積
????x?=?layers.Conv2D(filters,?kernel_size=1)(x)
????x?=?activation_block(x)
????return?x
+4、完整的網(wǎng)絡(luò)
def?get_conv_mixer_256_8(
????image_size=32,?filters=256,?depth=8,?kernel_size=5,?patch_size=2,?num_classes=10
):
????"""ConvMixer-256/8:?https://openreview.net/pdf?id=TVHS5Y4dNvM.
????The?hyperparameter?values?are?taken?from?the?paper.
????"""
????inputs?=?keras.Input((image_size,?image_size,?3))
????x?=?layers.Rescaling(scale=1.0?/?255)(inputs)
????#?計(jì)算?patch?的嵌入
????x?=?conv_stem(x,?filters,?patch_size)
????#?ConvMixer?塊,depth?層
????for?_?in?range(depth):
????????x?=?conv_mixer_block(x,?filters,?kernel_size)
????#?輸入分類(lèi)器
????x?=?layers.GlobalAvgPool2D()(x)
????outputs?=?layers.Dense(num_classes,?activation='softmax')(x)
????return?keras.Model(inputs,?outputs)
本實(shí)驗(yàn)中使用的模型稱(chēng)為 ConvMixer-256/8,其中 256 表示通道數(shù),8 表示深度。
7模型訓(xùn)練和評(píng)估
def?run_experiment(model):
????optimizer?=?tfa.optimizers.AdamW(
????????learning_rate=learning_rate,?weight_decay=weight_decay
????)
????model.compile(
????????optimizer=optimizer,
????????loss='sparse_categorical_crossentropy',
????????metrics=['accuracy'],
????)
????checkpoint_filepath?=?'./checkpoint'
????checkpoint_callback?=?keras.callbacks.ModelCheckpoint(
????????checkpoint_filepath,
????????monitor='val_accuracy',
????????save_best_only=True,
????????save_weights_only=True,
????)
????history?=?model.fit(
????????train_dataset,
????????validation_data=val_dataset,
????????epochs=num_epochs,
????????callbacks=[checkpoint_callback],
????)
????model.load_weights(checkpoint_filepath)
????_,?accuracy?=?model.evaluate(test_dataset)
????print(f'Test?accuracy:?{round(accuracy?*?100,?2)}%')
????return?history,?model
conv_mixer_model?=?get_conv_mixer_256_8()
history,?conv_mixer_model?=?run_experiment(conv_mixer_model)
Epoch 1/10
352/352 [==============================] - 84s 150ms/step - loss: 1.2139 - accuracy: 0.5626 - val_loss: 3.4178 - val_accuracy: 0.1010
Epoch 2/10
352/352 [==============================] - 52s 147ms/step - loss: 0.7774 - accuracy: 0.7291 - val_loss: 0.8245 - val_accuracy: 0.7088
Epoch 3/10
352/352 [==============================] - 52s 147ms/step - loss: 0.5902 - accuracy: 0.7955 - val_loss: 0.5996 - val_accuracy: 0.7938
Epoch 4/10
352/352 [==============================] - 52s 147ms/step - loss: 0.4836 - accuracy: 0.8330 - val_loss: 0.5909 - val_accuracy: 0.7966
Epoch 5/10
352/352 [==============================] - 52s 147ms/step - loss: 0.4038 - accuracy: 0.8619 - val_loss: 0.5585 - val_accuracy: 0.8062
Epoch 6/10
352/352 [==============================] - 52s 147ms/step - loss: 0.3450 - accuracy: 0.8803 - val_loss: 0.5237 - val_accuracy: 0.8168
Epoch 7/10
352/352 [==============================] - 52s 147ms/step - loss: 0.3019 - accuracy: 0.8970 - val_loss: 0.5351 - val_accuracy: 0.8270
Epoch 8/10
352/352 [==============================] - 52s 148ms/step - loss: 0.2618 - accuracy: 0.9096 - val_loss: 0.5051 - val_accuracy: 0.8352
Epoch 9/10
352/352 [==============================] - 51s 146ms/step - loss: 0.2363 - accuracy: 0.9168 - val_loss: 0.5453 - val_accuracy: 0.8260
Epoch 10/10
352/352 [==============================] - 51s 146ms/step - loss: 0.2128 - accuracy: 0.9269 - val_loss: 0.5667 - val_accuracy: 0.8290
79/79 [==============================] - 3s 39ms/step - loss: 0.5329 - accuracy: 0.8271
Test accuracy: 82.71%
雖然訓(xùn)練集和驗(yàn)證集上的性能差異較大,但這點(diǎn)可以通過(guò)額外的正則化技術(shù)來(lái)拉近。從結(jié)果看,具有 80 萬(wàn)個(gè)參數(shù)的網(wǎng)絡(luò)模型能夠在 10 個(gè) epochs 內(nèi)達(dá)到 ~83% 的準(zhǔn)確度是一個(gè)不錯(cuò)的結(jié)果。是不是感覺(jué)它還是值得進(jìn)一步學(xué)習(xí)和研究一下的。
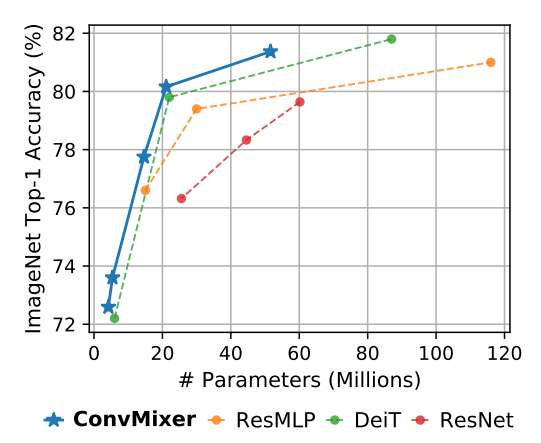
看一下論文中給出的在 ImageNet-1k 上的性能比較,
8可視化
我們可以可視化 patch 嵌入和學(xué)習(xí)到的卷積濾波器。這里,每個(gè) patch 嵌入和中間 feature map 都具有相同數(shù)量的通道數(shù),即 256。
def?visualization_plot(weights,?idx=1):
????p_min,?p_max?=?weights.min(),?weights.max()
????weights?=?(weights?-?p_min)?/?(p_max?-?p_min)
????num_filters?=?256
????plt.figure(figsize=(8,?8))
????for?i?in?range(num_filters):
????????current_weight?=?weights[:,?:,?:,?i]
????????if?current_weight.shape[-1]?==?1:
????????????current_weight?=?current_weight.squeeze()
????????ax?=?plt.subplot(16,?16,?idx)
????????ax.set_xticks([])
????????ax.set_yticks([])
????????plt.imshow(current_weight,?cmap='coolwarm')
????????idx?+=?1
#?可視化?patch?嵌入
patch_embeddings?=?conv_mixer_model.layers[2].get_weights()[0]
visualization_plot(patch_embeddings)

即使我們沒(méi)有訓(xùn)練網(wǎng)絡(luò)收斂,我們也可以注意到不同的 kernel 具有不同的模式。有些有相似之處,而有些則截然不同。這些可視化對(duì)于更大的圖像尺寸將更顯著。
同樣,我們也可以可視化學(xué)習(xí)到的卷積核。
for?i,?layer?in?enumerate(conv_mixer_model.layers):
????if?isinstance(layer,?layers.DepthwiseConv2D):
????????if?layer.get_config()['kernel_size']?==?(5,?5):
????????????print(i,?layer)
idx?=?26??#?靠近網(wǎng)絡(luò)中間選擇一層?depthwise?conv?展示
kernel?=?conv_mixer_model.layers[idx].get_weights()[0]
kernel?=?np.expand_dims(kernel.squeeze(),?axis=2)
visualization_plot(kernel)
5
12
19
26
33
40
47
54

總共 256 個(gè) filter,可以看到 kernel 中的不同 filter 具有不同的局部跨度,并且這種模式可能會(huì)隨著更多的訓(xùn)練而演變。
9附錄 - 深度可分離卷積
Separable convolution 早在 Google 的 Xception 以及 MobileNet 論文中就提出來(lái)了,這里僅供初學(xué)卷積神經(jīng)網(wǎng)絡(luò)的童鞋閱讀。
它的核心思想是將一個(gè)傳統(tǒng)卷積運(yùn)算分解為兩步進(jìn)行,分別為 Depthwise convolution 與 Pointwise convolution。可以認(rèn)為它將傳統(tǒng)卷積從通道內(nèi)與通道間兩個(gè)角度分離。
+傳統(tǒng)卷積運(yùn)算
先看一個(gè)動(dòng)畫(huà),感受一下傳統(tǒng)的卷積運(yùn)算。
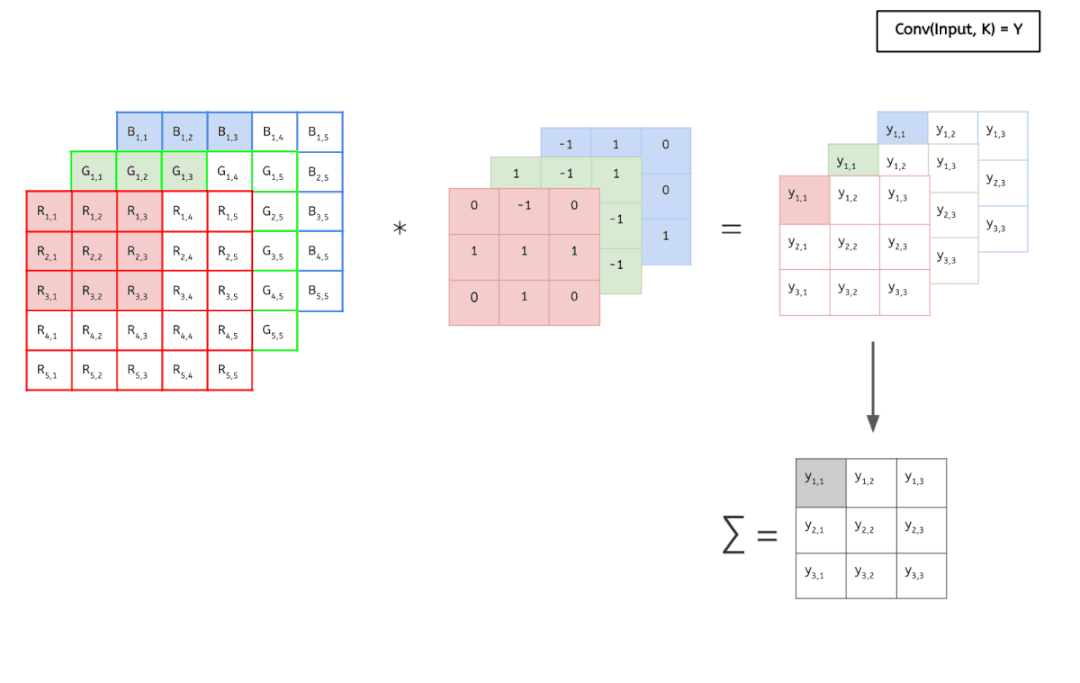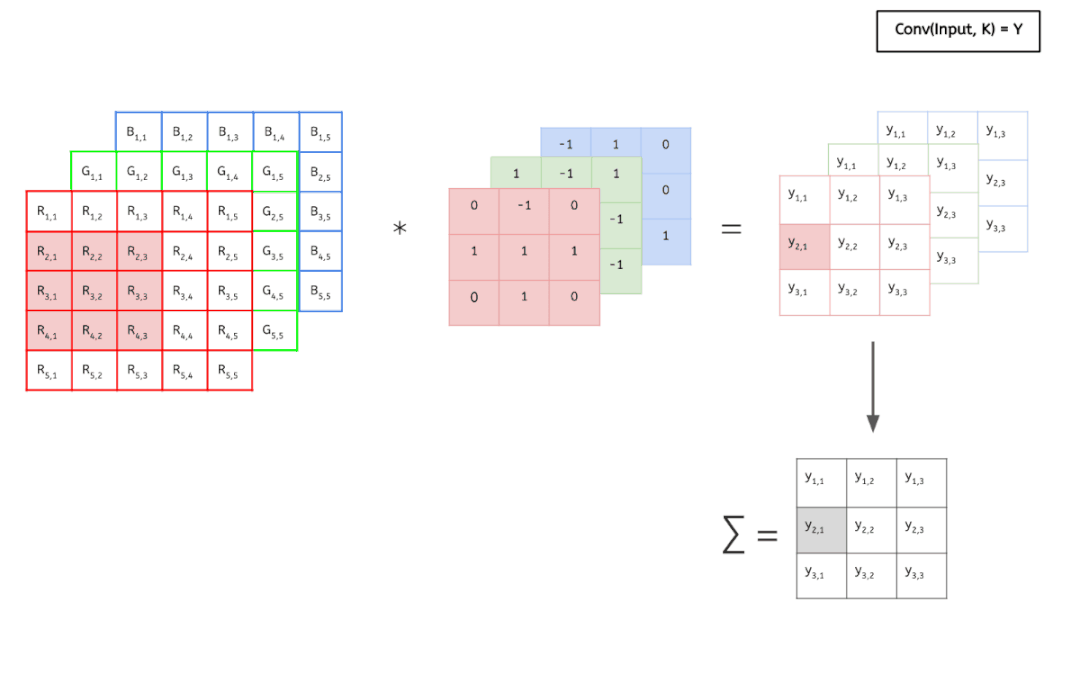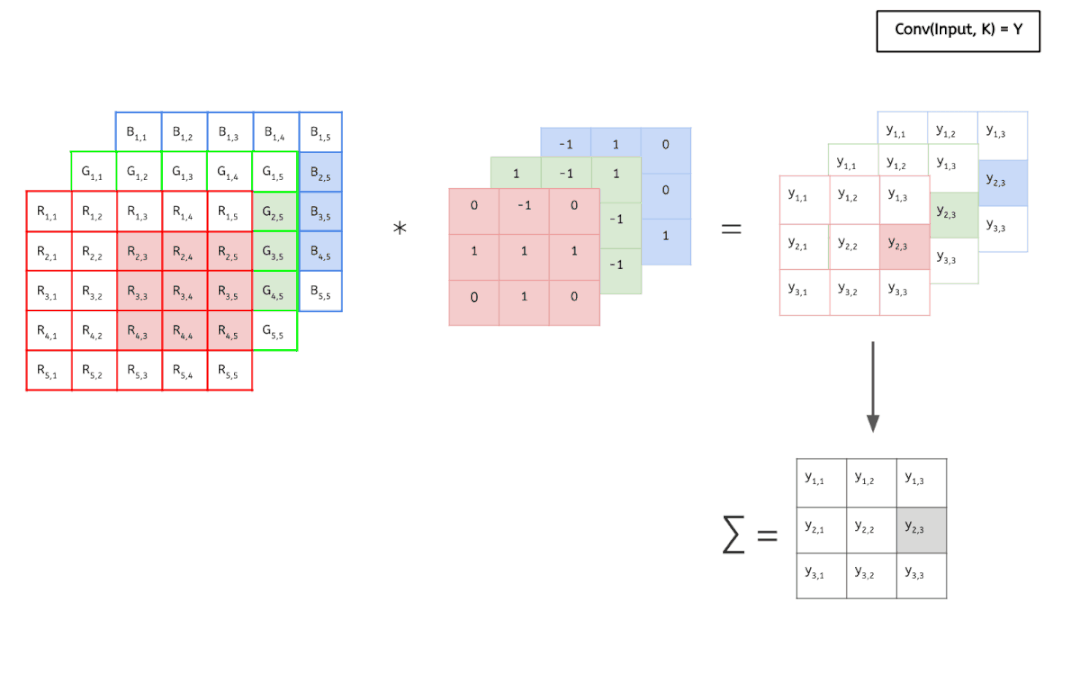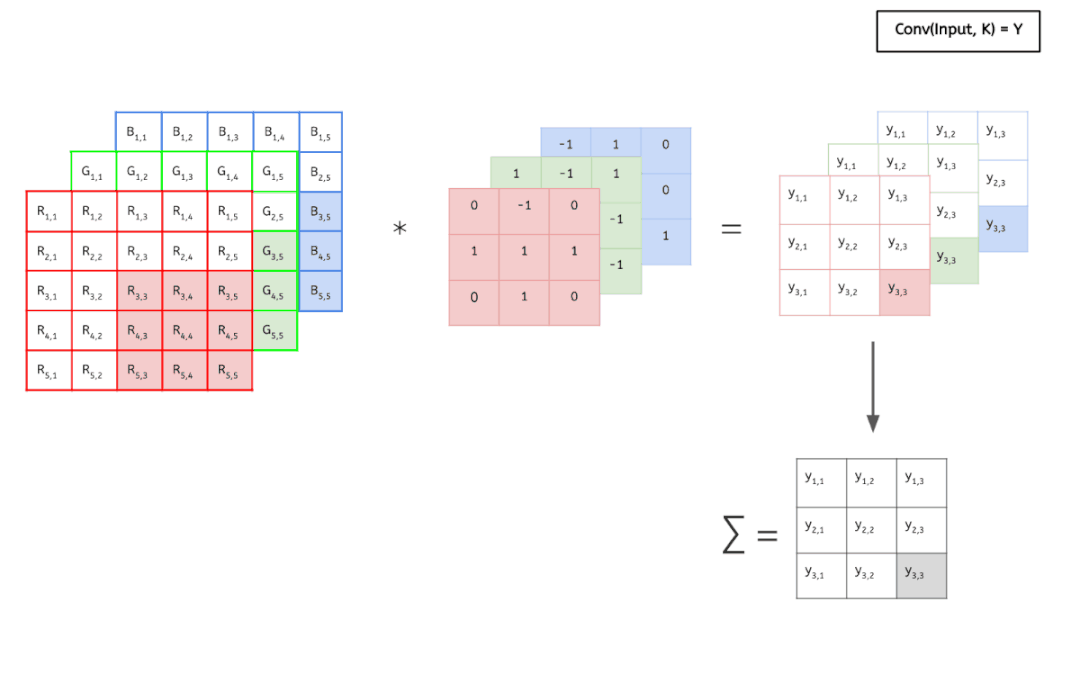
輸入數(shù)據(jù)具有 3 個(gè)大小為 5 × 5 的通道,即 ?3 × 5 × 5,而卷積核也同樣是 3 個(gè)通道,大小為 3 × 3,因此共有 3 × 3 × 3 個(gè)參數(shù)。這里只有一個(gè)卷積核,因此最終得到一張 feature map。
再來(lái)看一個(gè)有兩個(gè)卷積核從而得到兩張 feature map 的動(dòng)畫(huà)。
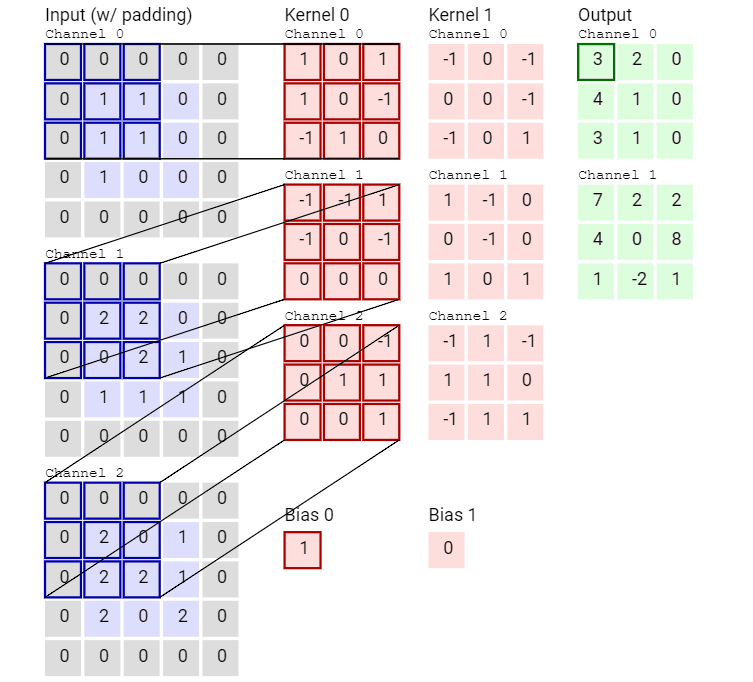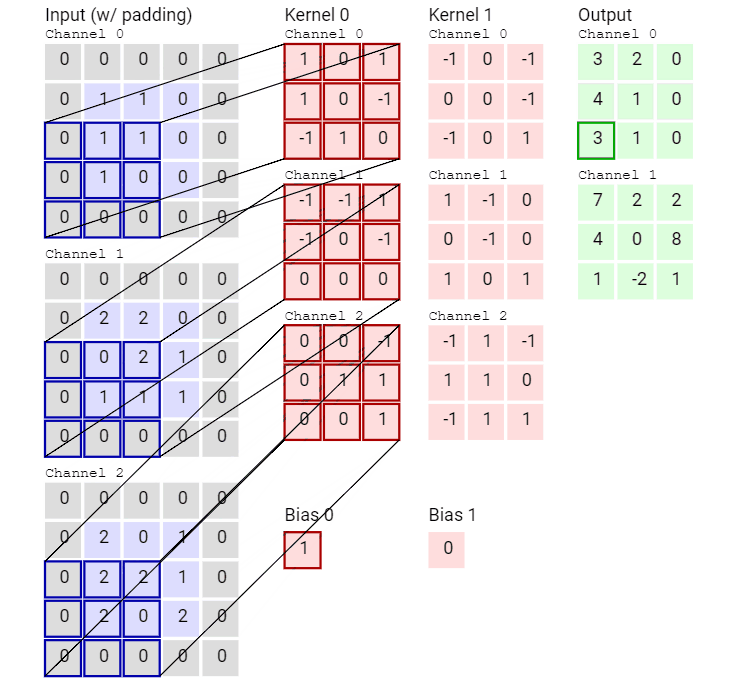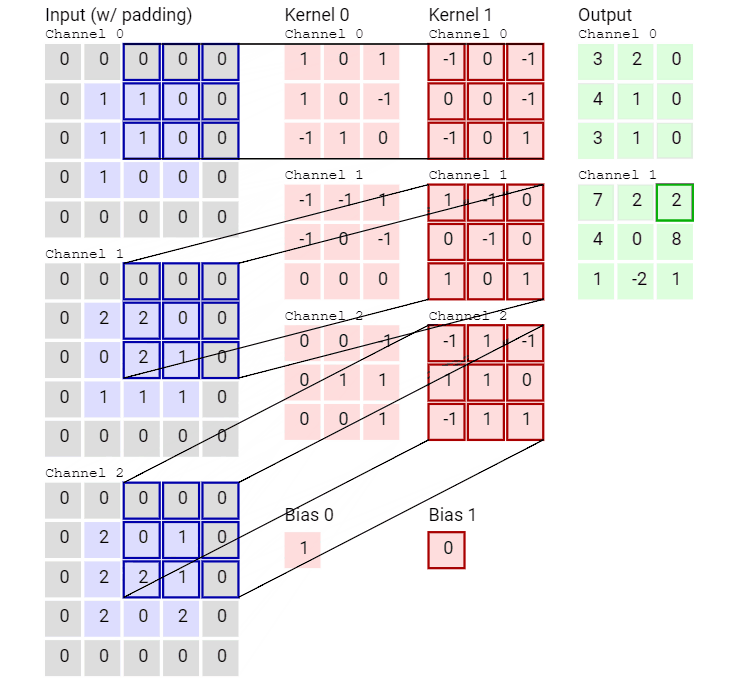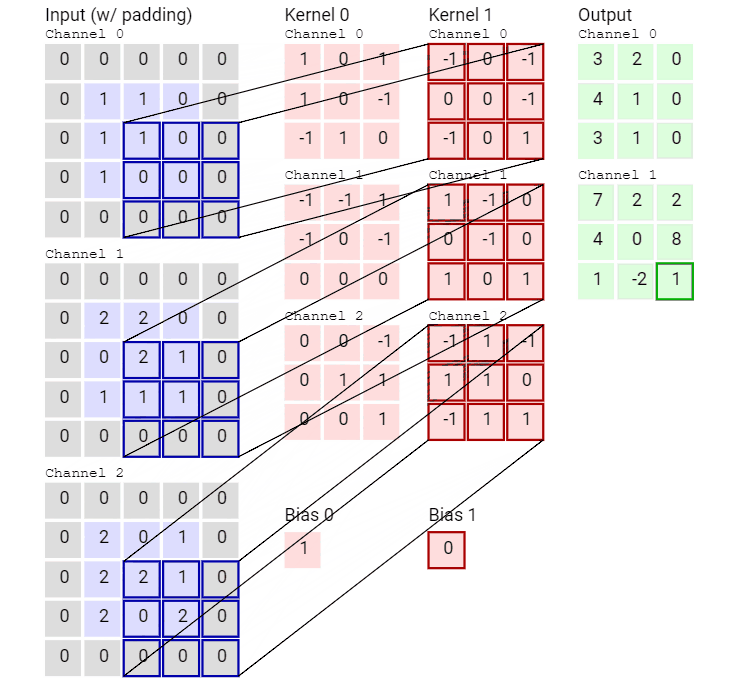
可以看到,這個(gè)卷積運(yùn)算每次都涉及空間三個(gè)維度。
好了,看過(guò)動(dòng)畫(huà)應(yīng)該就很清楚傳統(tǒng)卷積是怎么運(yùn)算的了,接下進(jìn)入靜態(tài)模式。
假設(shè)輸入層為一個(gè)大小為 5 × 5 像素、三通道彩色圖片。經(jīng)過(guò)一個(gè)包含 4 個(gè) filter 的卷積層,最終輸出 4 個(gè) feature Map。如果使用 padding='same' 來(lái)填充,則尺寸與輸入層相同 5 × 5,如果沒(méi)有則尺寸縮小為 3 × 3。這個(gè)過(guò)程可以用下圖來(lái)可視化,
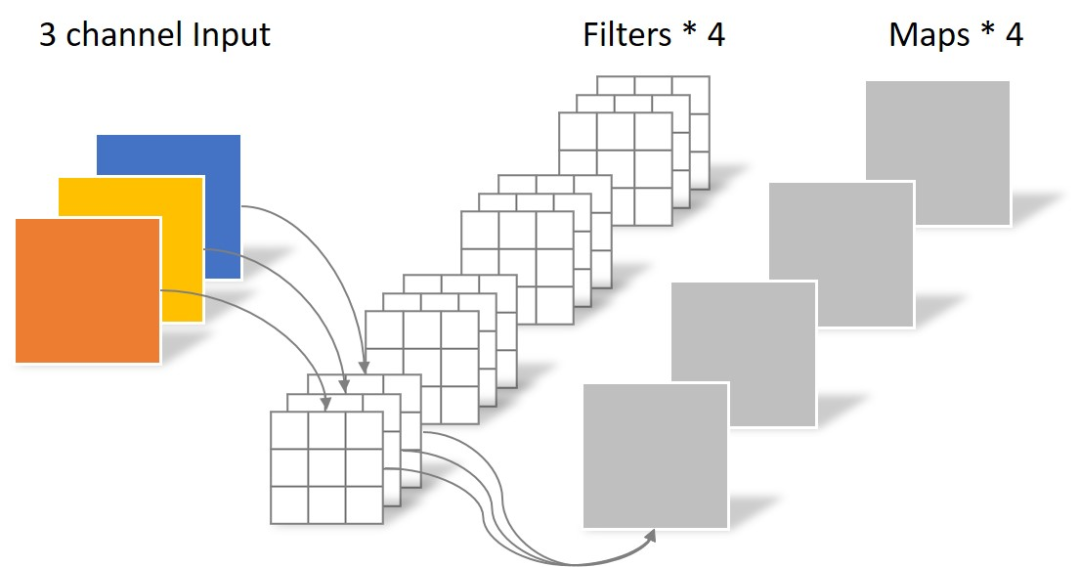
此時(shí),卷積層共 4 個(gè) filter,每個(gè) filter 包含了 3 個(gè) kernel,每個(gè) kernel 的大小為 3 × 3。因此該卷積層的參數(shù)數(shù)量為4 × 3 × 3 × 3。
傳統(tǒng)卷積運(yùn)算的特點(diǎn)是將通道內(nèi)和通道間同時(shí)卷積,一次性抓取特征的空間結(jié)構(gòu)。
+Depthwise Convolution
還是上述例子,大小為 5 × 5 像素、三通道彩色圖片首先經(jīng)過(guò)第一次卷積運(yùn)算,不同之處在于此次的卷積完全是在單個(gè)通道內(nèi)進(jìn)行,且 filter 的數(shù)量與上一層的 depth 相同。
因此,一個(gè)三通道的圖像經(jīng)過(guò)運(yùn)算后生成了 3 個(gè) feature map,如下圖所示。
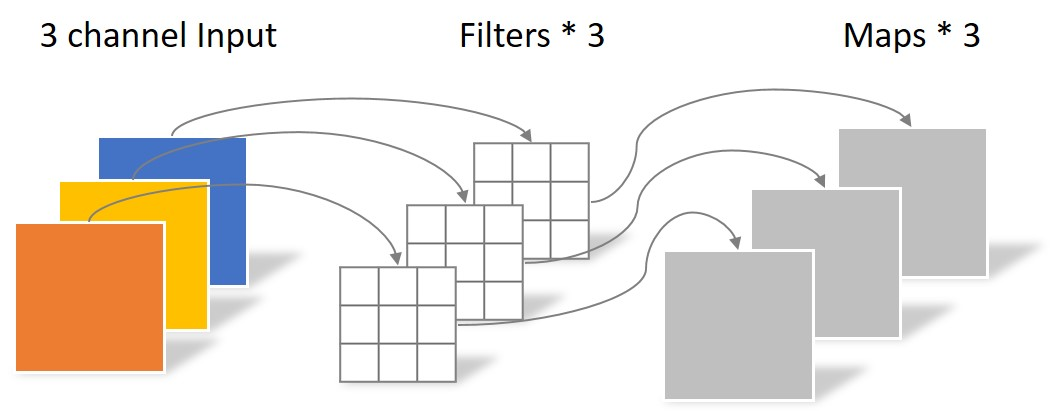
其中一個(gè) filter 只包含一個(gè)大小為 3 × 3 的 kernel,卷積部分的參數(shù)個(gè)數(shù)為 3 × 3 × 3 。
Depthwise convolution 完成后的 feature map 數(shù)量與輸入層的 depth(通道數(shù))相同。
該卷積操作并沒(méi)有利用不同通道在相同空間位置上的結(jié)構(gòu)。因此還需要將這些 feature map 進(jìn)行組合生成新的 feature map,即下面的 Pointwise convolution。
+Pointwise Convolution
Pointwise convolution 的卷積核尺寸為 1 × 1 × M,M 為上一層 feature map 的通道數(shù)。所以這里的卷積運(yùn)算會(huì)將上一步的 map 在不同通道間進(jìn)行加權(quán),生成新的 feature map。
有幾個(gè) filter 就有幾個(gè) feature map,如下圖所示,
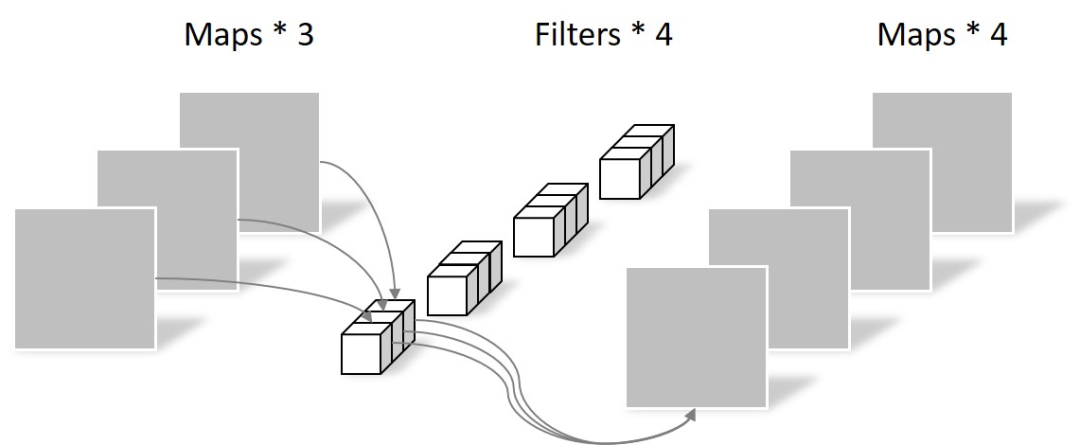
由于采用的是 1×1 卷積的方式,此步中卷積涉及到的參數(shù)個(gè)數(shù)為 1 × 1 × 3 × 4。
經(jīng)過(guò) Pointwise convolution 之后,同樣輸出了 4 張 feature map,與傳統(tǒng)卷積的輸出維度相同。
我們把上面兩種卷積放在一張圖里,
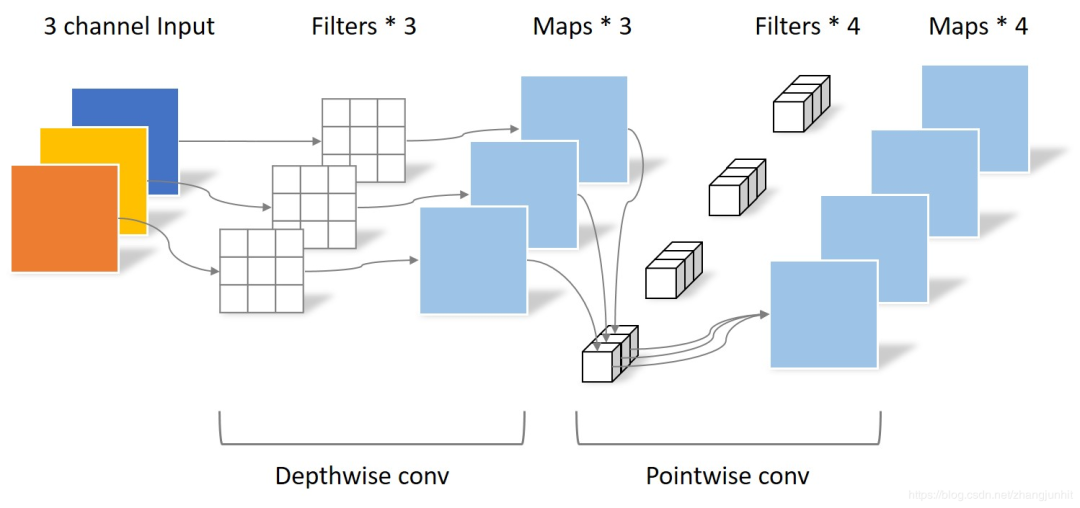
+參數(shù)對(duì)比
回顧一下,傳統(tǒng)卷積的參數(shù)個(gè)數(shù)為 4 × 3 × 3 × 3;而 Separable convolution 的參數(shù)個(gè)數(shù)為 3 × 3 × 3 + 1 × 1 × 3 × 4。
輸入相同,輸出也是 4 張 feature map,而 Separable convolution 的參數(shù)個(gè)數(shù)大大少于常規(guī)卷積。因此,假設(shè)參數(shù)量相同,那么采用 Separable convolution 的神經(jīng)網(wǎng)絡(luò)可以具有更深的層次。
這里通過(guò)一個(gè)簡(jiǎn)單例子介紹了 Depthwise 和 Pointwise 兩個(gè)卷積運(yùn)算以及與傳統(tǒng)卷積運(yùn)算的關(guān)系。如果之前對(duì)這些概念不了解的童鞋可以再回過(guò)頭去看 ConvMixer 了。
結(jié)合實(shí)例一文擼通 Vision Transformer