
北大計算機博士生先于OpenAI發(fā)表預(yù)訓練語言模型求解數(shù)學題論文,曾被頂會拒絕

??視學算法報道??
??視學算法報道??
來源:EMNLP
編輯:好困 小咸魚
【新智元導(dǎo)讀】北大博士生沈劍豪同學一篇關(guān)于「用語言模型來解決數(shù)學應(yīng)用題」的EMNLP投稿在綜合評審時被認為不夠重要,收錄于Findings而沒有被主會接收。有趣的是,OpenAI的最新工作與該論文的方法不謀而合,并表示非常好用。
北大博士生沈劍豪領(lǐng)銜的一篇關(guān)于「用語言模型來解決數(shù)學應(yīng)用題」(Generate & rank: A multi-task framework for math word problems)的EMNLP投稿在綜合評審時被認為不夠重要,最終收錄于Findings而沒有被主會接收。

「審稿人普遍喜歡這篇論文,但這看起來是一篇邊緣的論文。鑒于這是BART在數(shù)學問題上的應(yīng)用,而數(shù)學問題的解決對于NLP來說并不是一個真正重要的任務(wù),我懷疑這個任務(wù)的高度工程化解決方案的價值。」


拓展了特定任務(wù)的SOTA,但是對EMNLP社區(qū)而言,沒有新的見解或更廣泛的適用性; 有良好的、新穎的實驗,并提出了全面的分析和結(jié)論,但使用的方法不夠「新穎」。
雖然,但是OpenAI覺得這個論文很重要



沈劍豪,尹伊淳,李琳,尚利峰,蔣欣,張銘, 劉群,《生成&排序:一種數(shù)學文字問題的多任務(wù)框架》,EMNLP 2020 Findings。該工作由北大計算機學院和華為諾亞方舟實驗室合作完成。
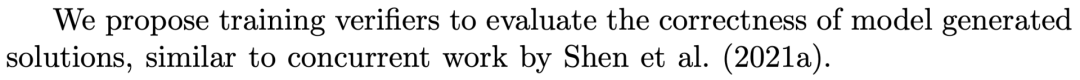

我們的工作與他們的方法有許多基本相似之處,盡管我們在幾個關(guān)鍵方面有所不同。

語言模型能解數(shù)學題嗎?
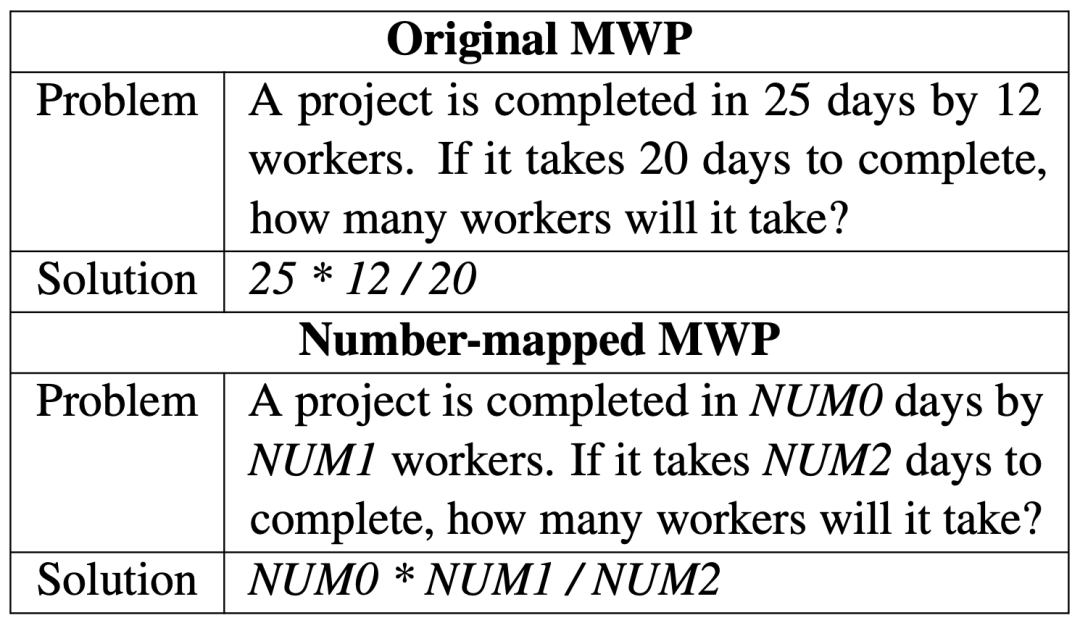
兩者內(nèi)容對比
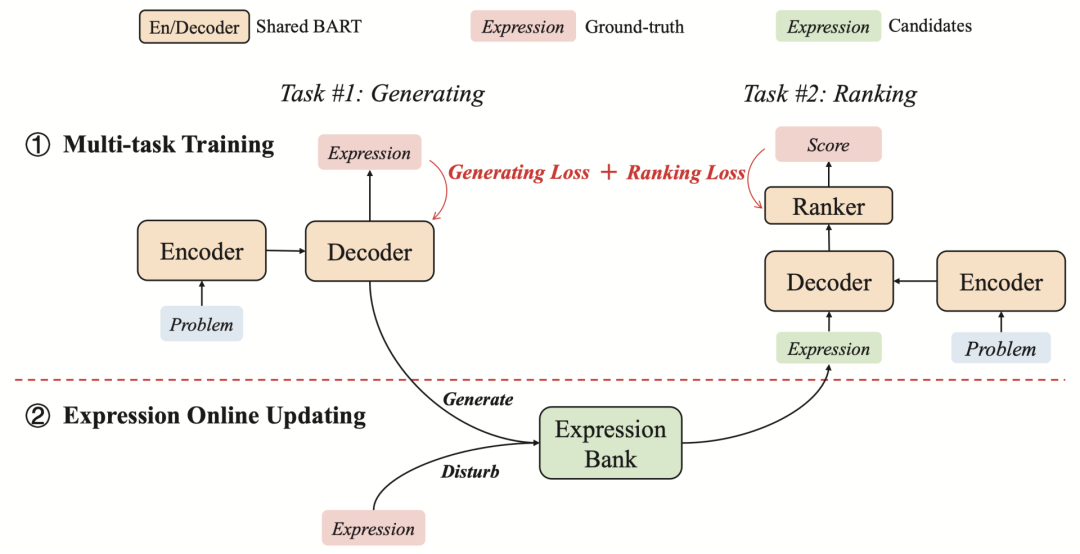
北大與華為諾亞的生成與重排序框架
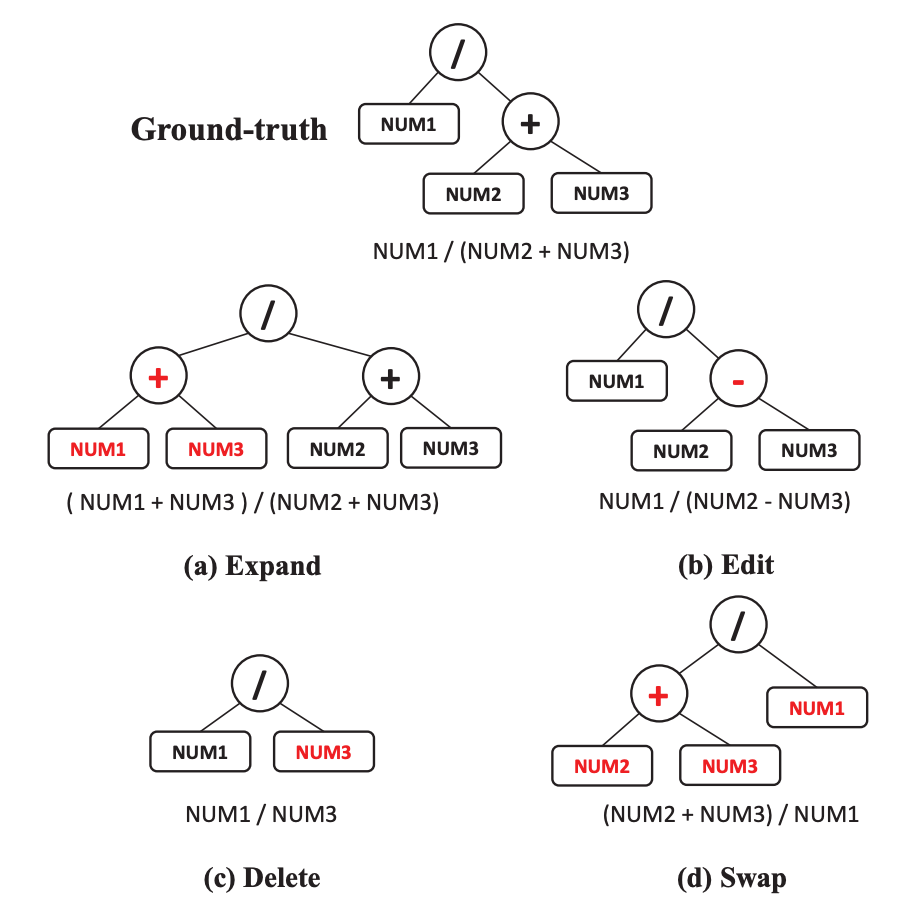
基于樹的干擾
訓練過程包括多任務(wù)訓練和表達式在線更新。首先為生成任務(wù)對預(yù)訓練的BART進行微調(diào)。之后,使用經(jīng)過微調(diào)的BART和基于樹的干擾來生成表達式,作為排序器的訓練樣本。然后,進行生成和排序的聯(lián)合訓練。
?
這個過程是以迭代的方式進行的,兩個模塊(即生成器和排序器)繼續(xù)相互促進。同時,用于排序器的訓練實例在每輪迭代后會被更新。

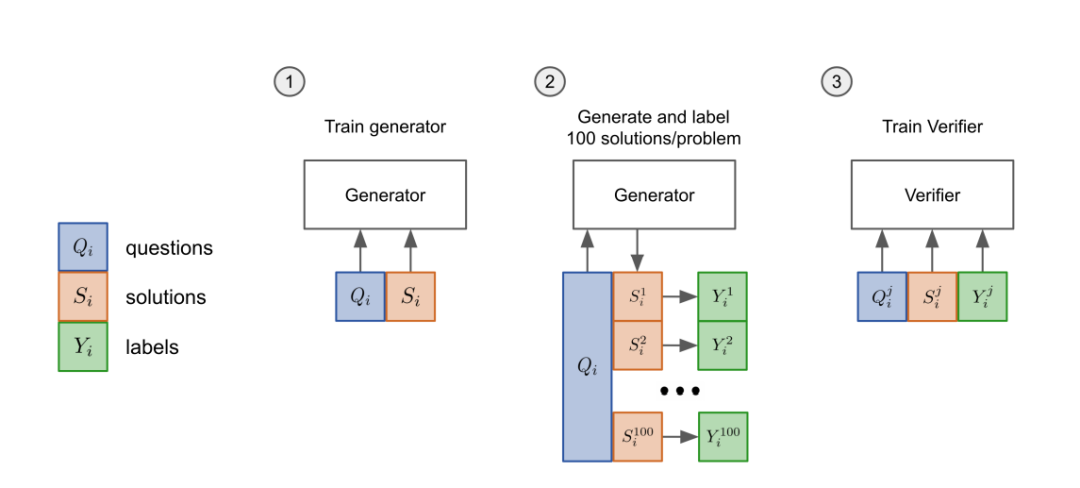
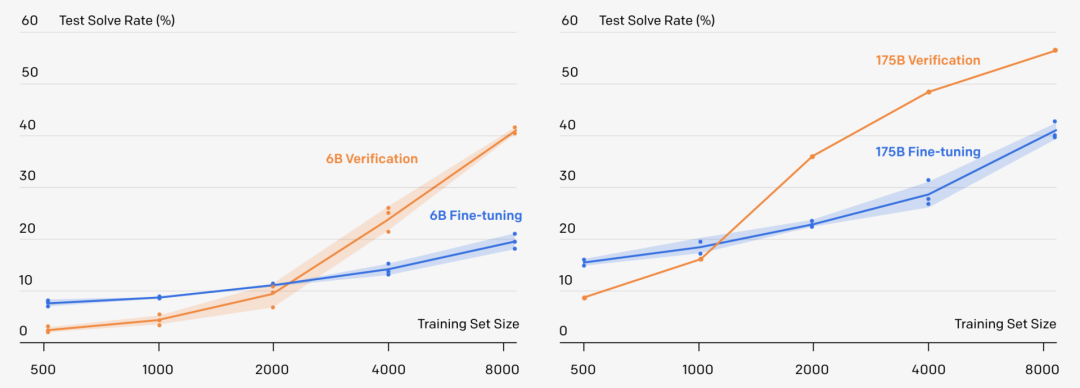
先把模型的「生成器」在訓練集上進行2個epoch的微調(diào)。 從生成器中為每個訓練問題抽取100個解答,并將每個解答標記為正確或不正確。 在數(shù)據(jù)集上,驗證器再訓練單個epoch。
參考資料:

點個在看 paper不斷!
評論
圖片
表情