
手把手教你用Python網(wǎng)絡(luò)爬蟲獲取頭條所有好友信息
回復(fù)“書籍”即可獲贈(zèng)Python從入門到進(jìn)階共10本電子書
前言
大家好,我是黃偉。今日頭條我發(fā)覺做的挺不錯(cuò),啥都不好爬,出于好奇心的驅(qū)使,小編想獲取到自己所有的頭條好友,
看似簡單,那么情況確實(shí)是這樣嗎,下面我們來看下吧。
項(xiàng)目目標(biāo)
獲取所有頭條好友昵稱
項(xiàng)目實(shí)踐
編輯器:sublime text 3
瀏覽器:360瀏覽器,順帶一個(gè)頭條號(hào)
實(shí)驗(yàn)步驟
1.登陸自己的頭條號(hào):
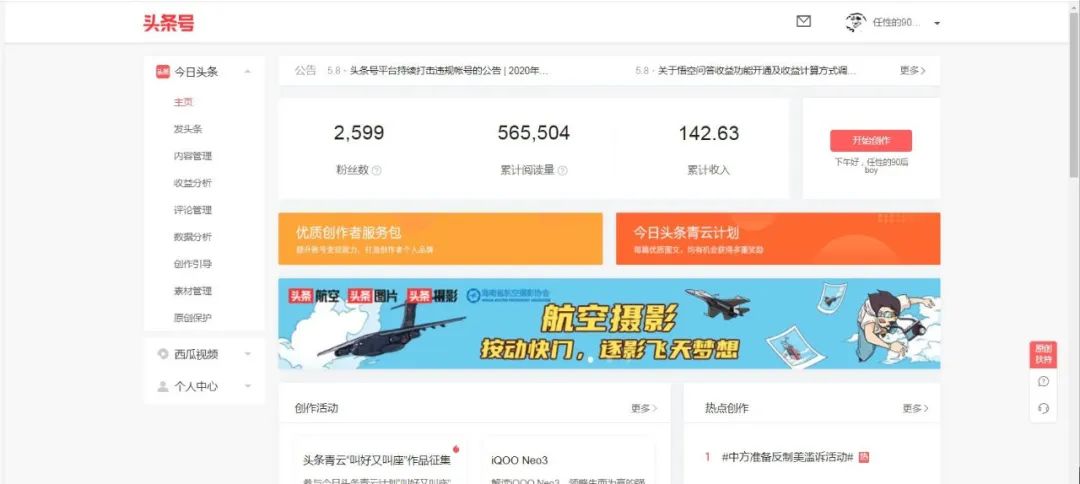
可以看到2599,不知道誰會(huì)是下一個(gè)幸運(yùn)觀眾了,哈哈哈哈哈,下面我們老樣子,打開瀏覽器,因?yàn)槲覀兪且@取到所有的好友啊,所以我們得先進(jìn)入粉絲列表看看有哪些粉絲吧:
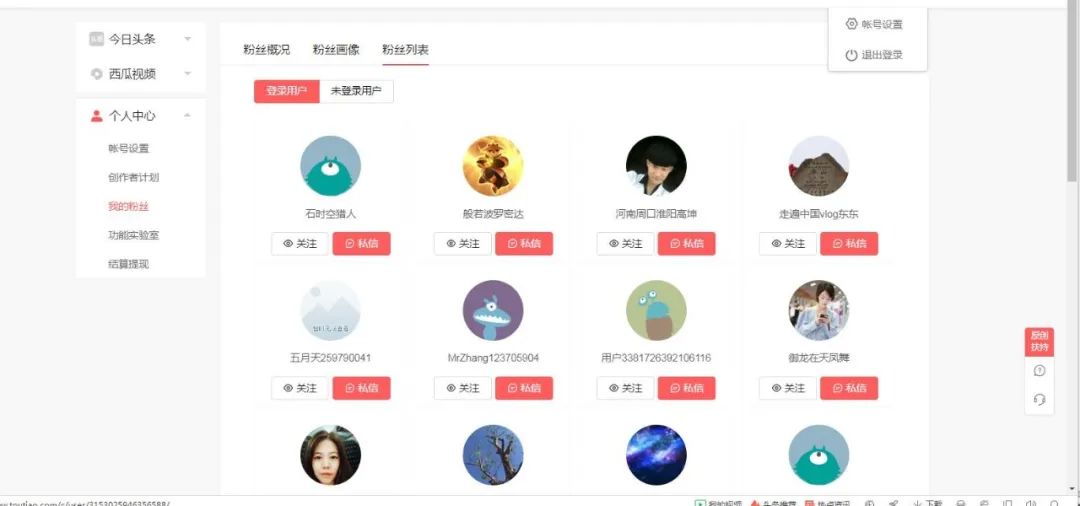
然后右鍵--審查元素,來一波騷操作,定位粉絲的位置:
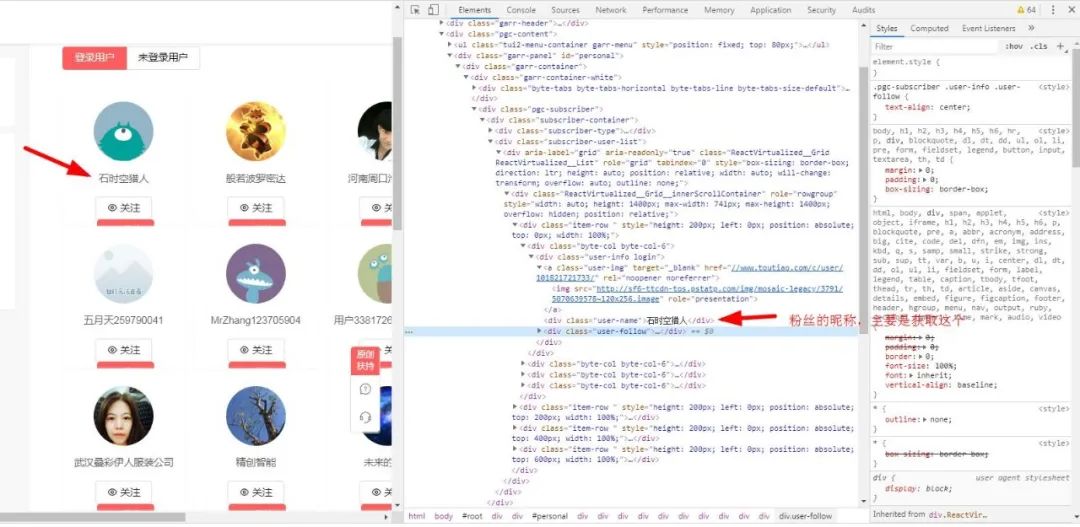
接下來我們要做的就是獲取粉絲的昵稱,從上面的圖可以看出我余下的粉絲都隱藏在ajax加載的動(dòng)態(tài)頁面中,如果我不進(jìn)行滾動(dòng)則看不到后面的粉絲,那怎么辦呢?不過不要緊,遇到問題先不慌,淡定。
2.查找粉絲列表的接口
打開network:
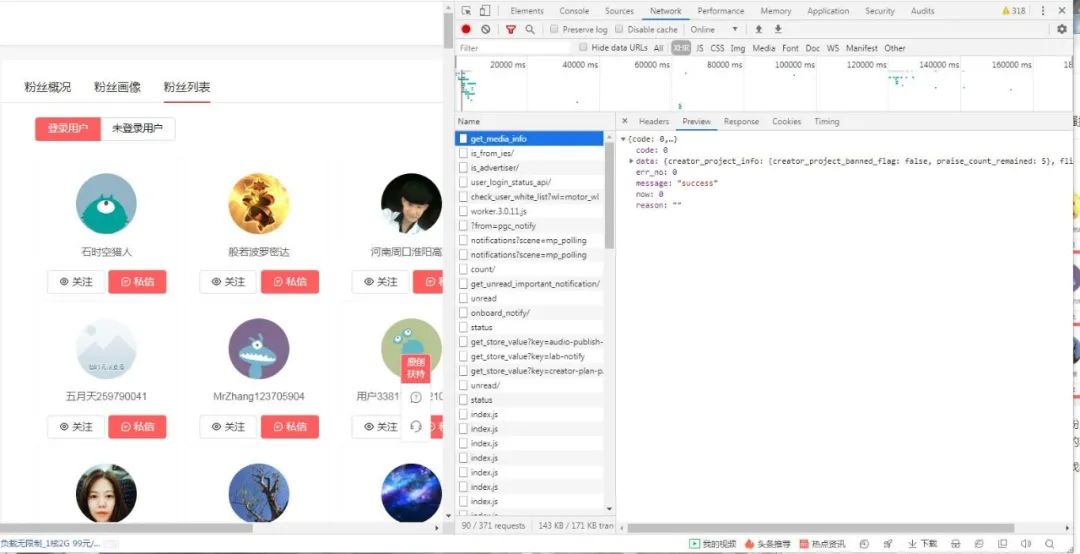
然后你會(huì)發(fā)現(xiàn)有很多get_info_list 中文譯為獲取信息列表,我想這應(yīng)該很重要,打開一看:
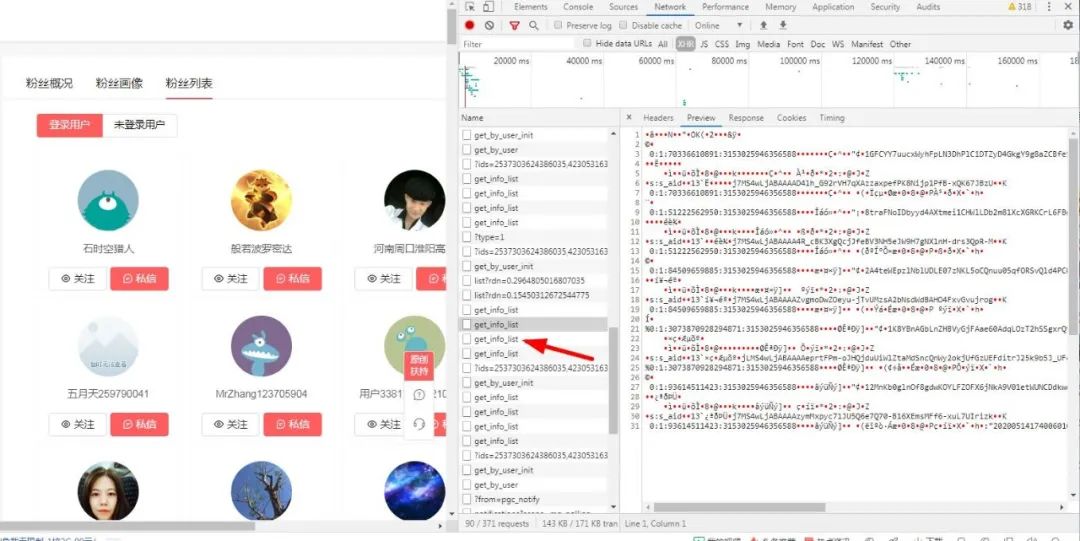
媽媽耶,這啥玩意,嚇得我都不會(huì)說話了。
3.加載所有請(qǐng)求
于是只好滿滿滾動(dòng)鼠標(biāo)滾輪期待發(fā)現(xiàn)點(diǎn)什么,終于,功夫不負(fù)苦心人,終于讓我滾到了有用的結(jié)果:
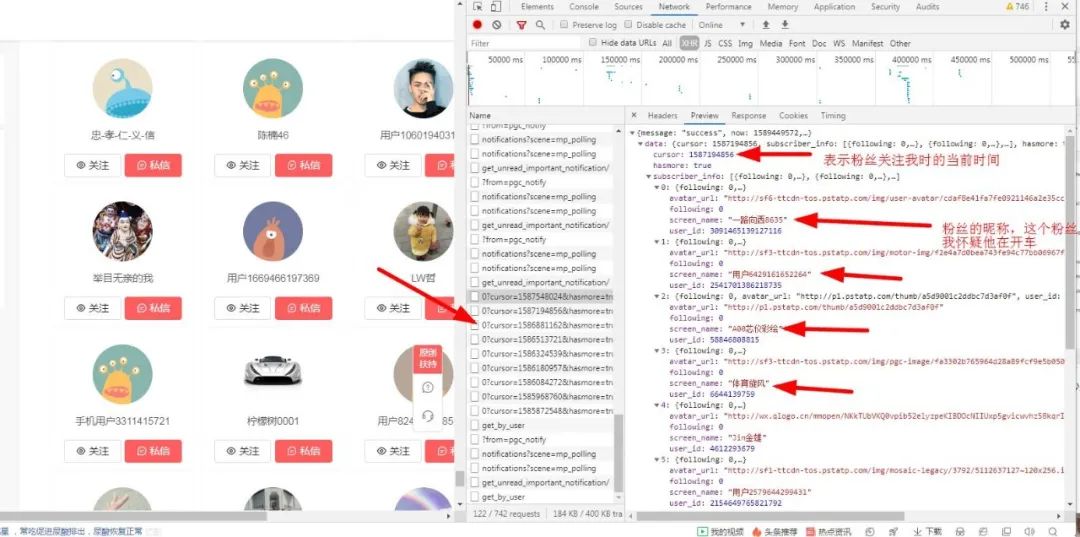
于是我在看看它的頭部信息,有重大發(fā)現(xiàn):
4.找接口分析內(nèi)容,轉(zhuǎn)換Unicode
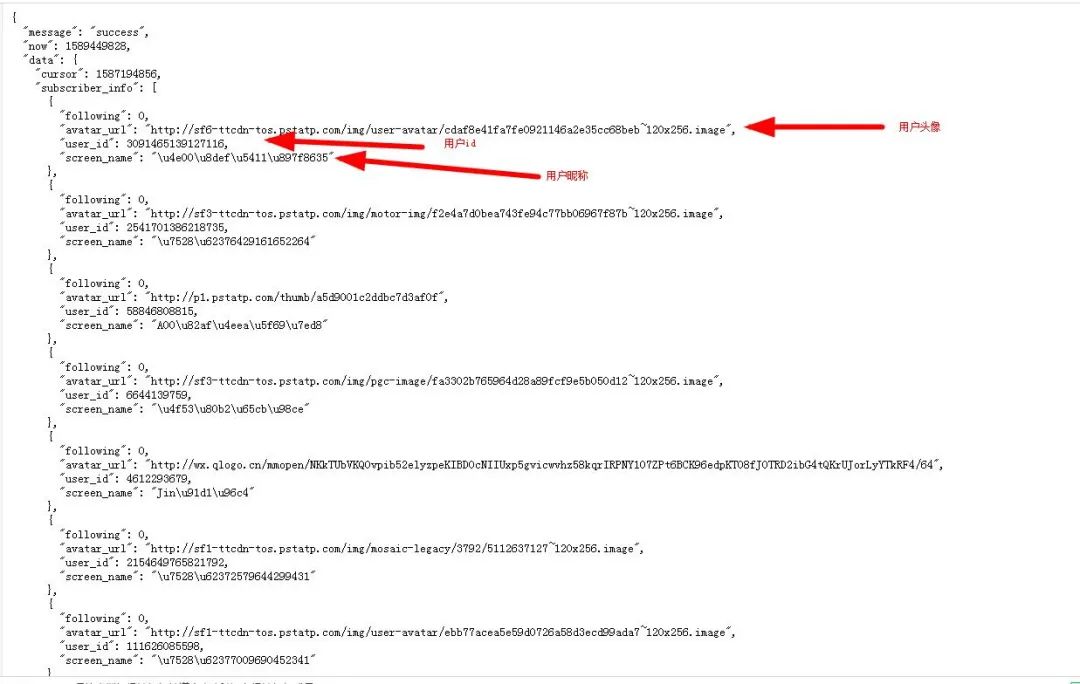
可以看到用戶的昵稱使用Unicode碼表示,所以我們需要將他們轉(zhuǎn)換為中文,關(guān)于Unicode轉(zhuǎn)中文,兩種方法:
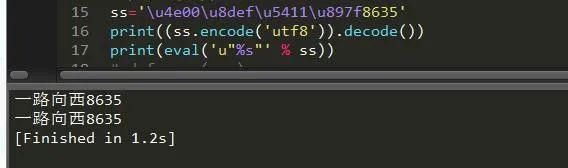
ss='\u4e00\u8def\u5411\u897f8635'print((ss.encode('utf8')).decode())print(eval('u"%s"' % ss))
沒毛病,老鐵。
5.獲取頁面文件
那我們現(xiàn)在就要獲取這個(gè)頁面的所有結(jié)果啦:
發(fā)現(xiàn)既然和結(jié)果不一樣,這是什么騷操作,好吧,我服了。
6.對(duì)頁面數(shù)據(jù)進(jìn)行猜解
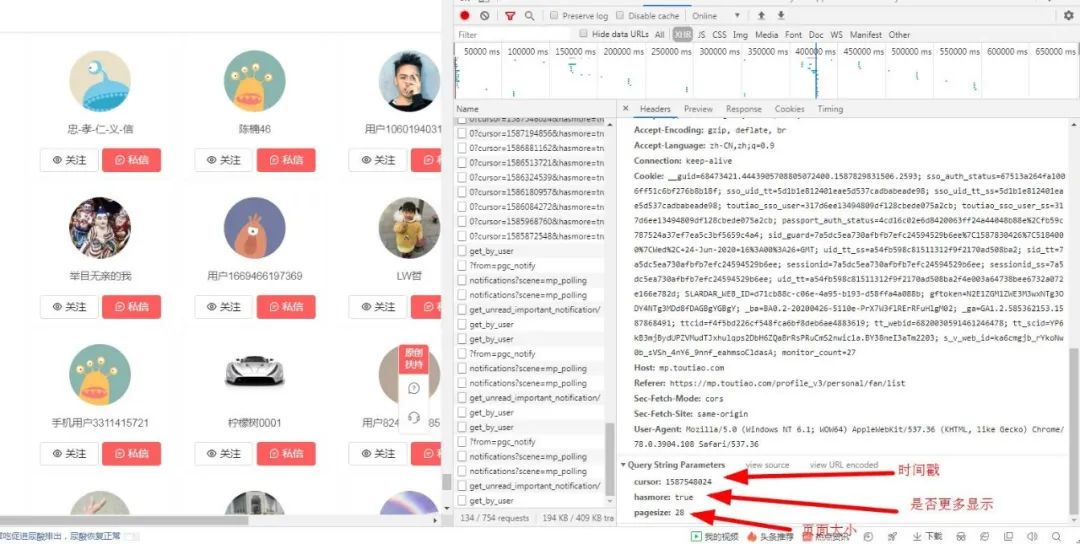
通過對(duì)上上個(gè)圖的反復(fù)分析,我發(fā)現(xiàn)一個(gè)很重要的信息,那就是pagesize的值就等于當(dāng)前頁面所顯示的粉絲的數(shù)量,那小編有2599個(gè)粉絲,那pagesize不就是2599嗎?哈哈,說干就干:
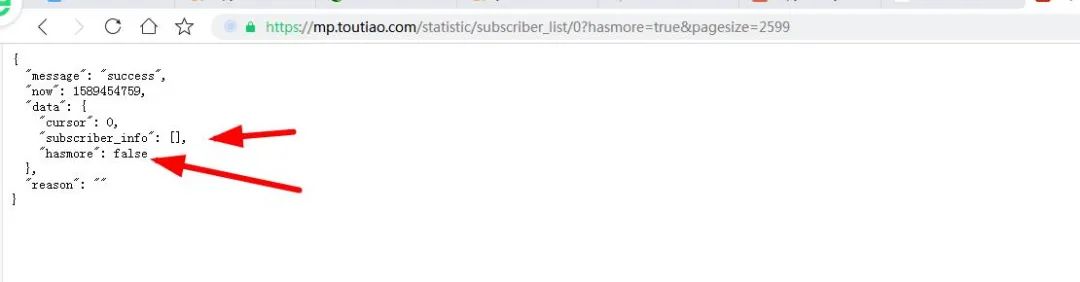
然后小編不斷對(duì)頁面的粉絲進(jìn)行請(qǐng)求:
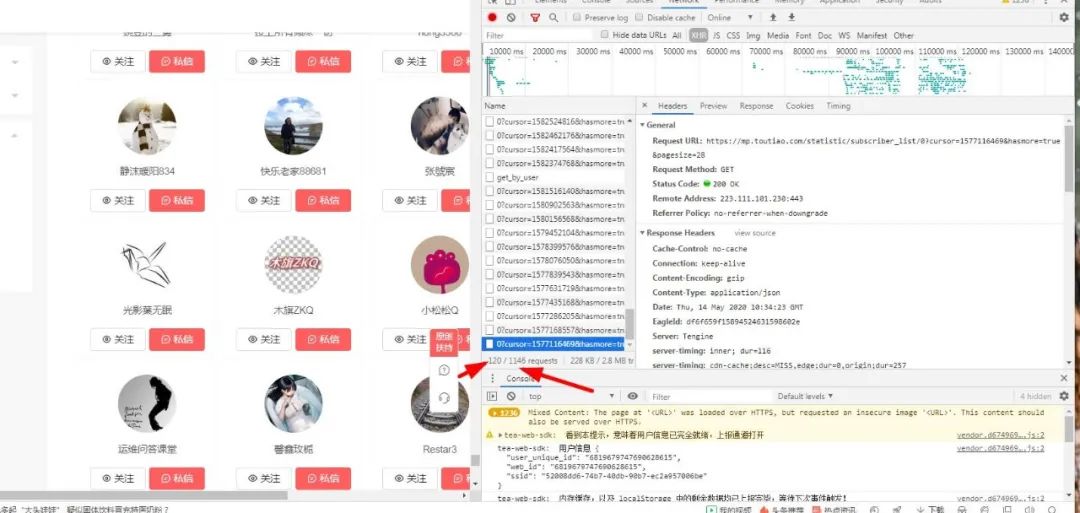
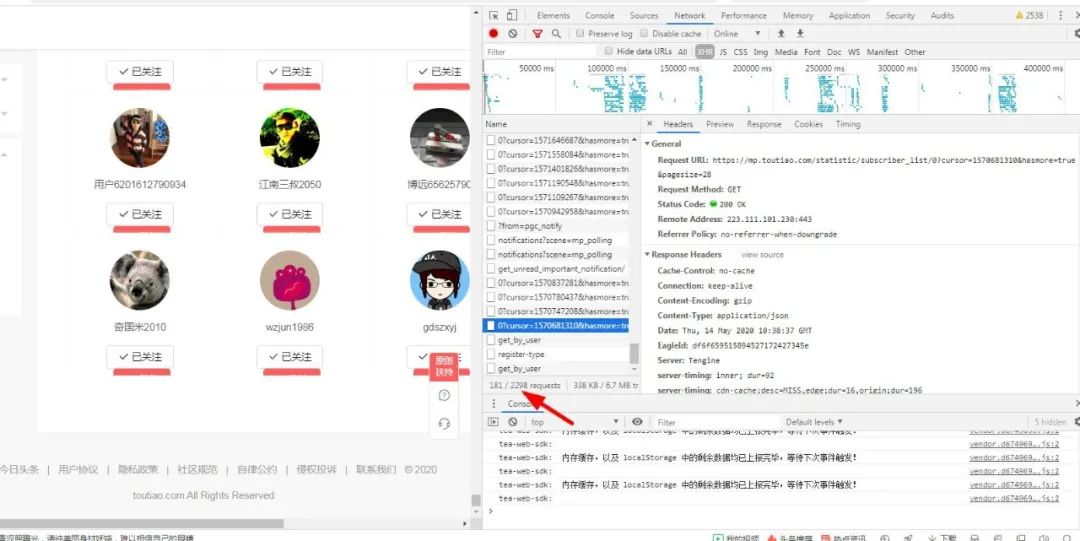
發(fā)現(xiàn)還是不行啊,跟我們想的背道而馳,在試試,發(fā)現(xiàn)最多只有200才行的通:
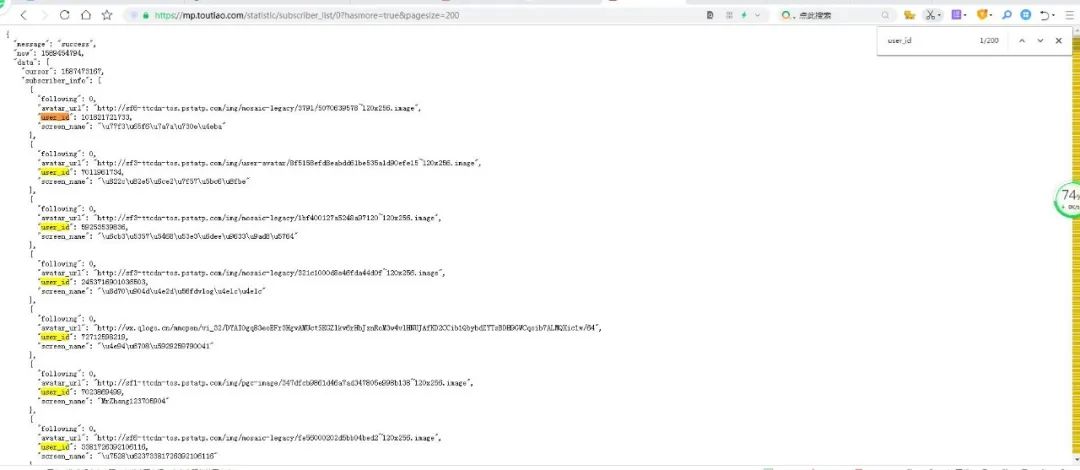
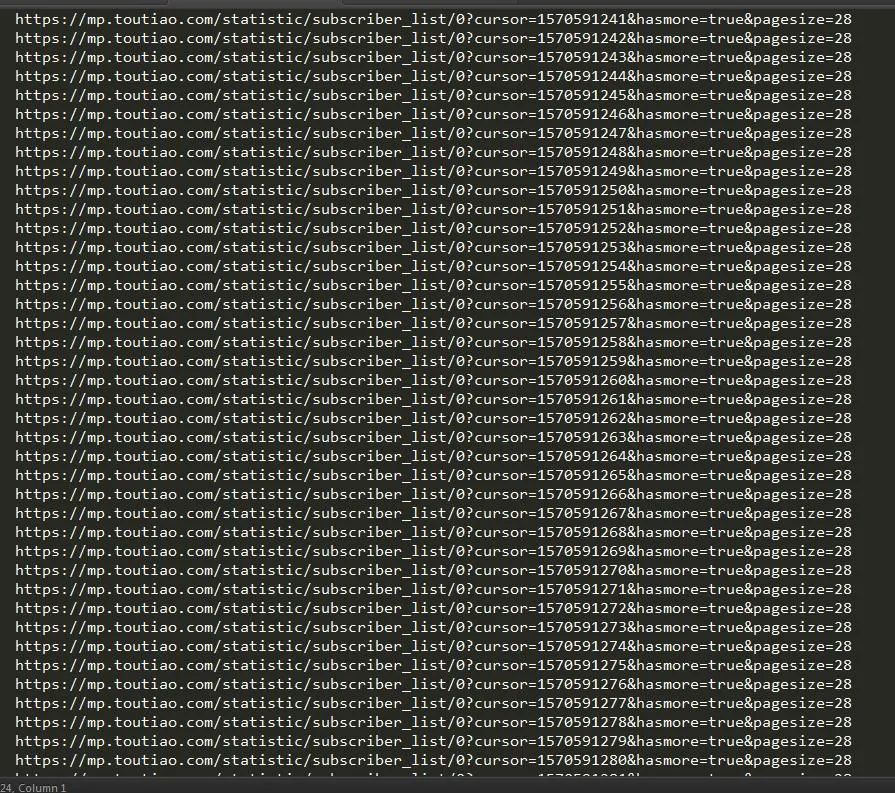
其實(shí)這個(gè)情況下,已經(jīng)捕捉到所有請(qǐng)求了,只是那些粉絲每28個(gè)粉絲分為一個(gè)請(qǐng)求,而且每個(gè)請(qǐng)求的時(shí)間戳不一,其實(shí)我們可以用三方軟件來捕獲這些請(qǐng)求響應(yīng)然后將他們加入到程序中,我們好對(duì)他們進(jìn)行一個(gè)請(qǐng)求分析,最后將他們保存為json格式的文件,然后我們獲取到他們對(duì)應(yīng)的值。
7.打印粉絲名稱和響應(yīng)正常的網(wǎng)址
我們還可以將所有請(qǐng)求中cursor最小的值和最大值拿出來分析,通過查找我找到,
cursor取值:1570591241~1589072863
這個(gè)信息很重要,接下來我們就可以依次對(duì)這些cursor構(gòu)建請(qǐng)求了:
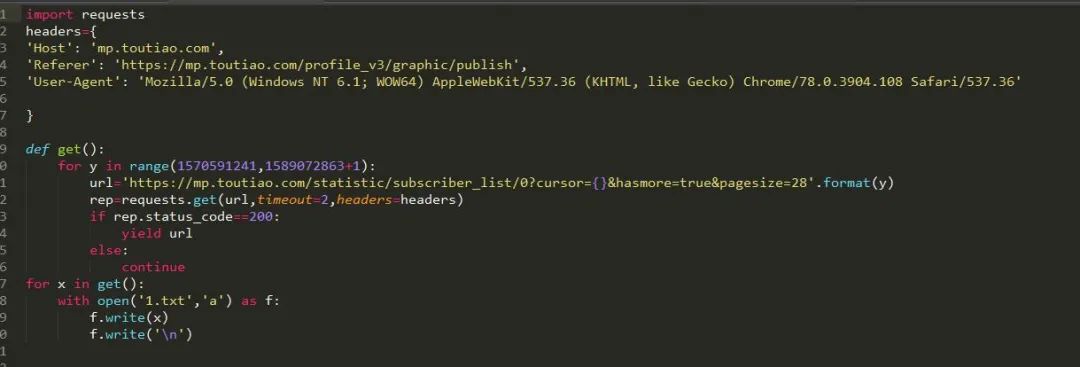
我們將所有能成功請(qǐng)求的頁面信息輸入到1.txt 文件中去,然后我們?cè)趯?duì)1.txt中的網(wǎng)頁內(nèi)容逐個(gè)讀取。然后我們獲取他們的json文件保存下來,最后直接把他讀取出來就ok啦。由于時(shí)間的關(guān)系,在此我只演示上圖中出現(xiàn)的兩百條信息,我們把它保存為json文件然后用json 模塊進(jìn)行讀取:
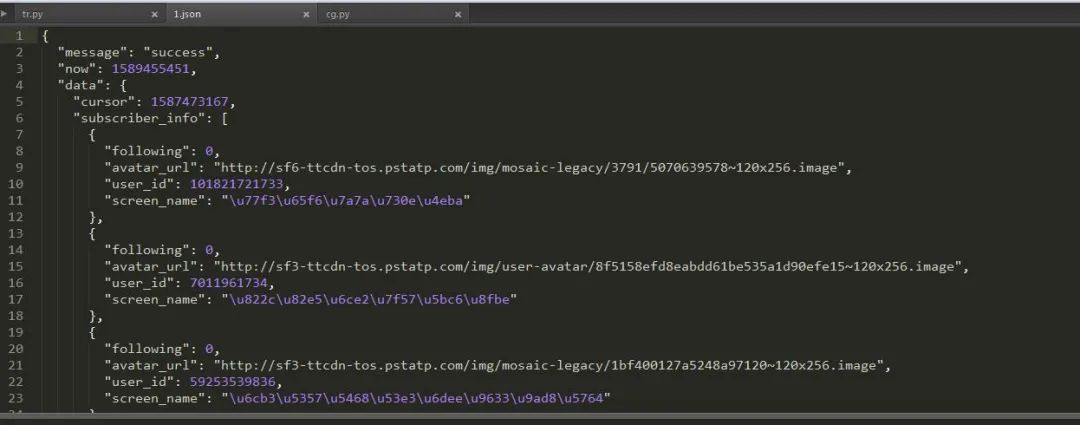
json是系統(tǒng)自帶的模塊,所以直接導(dǎo)入json模塊并讀取文件:
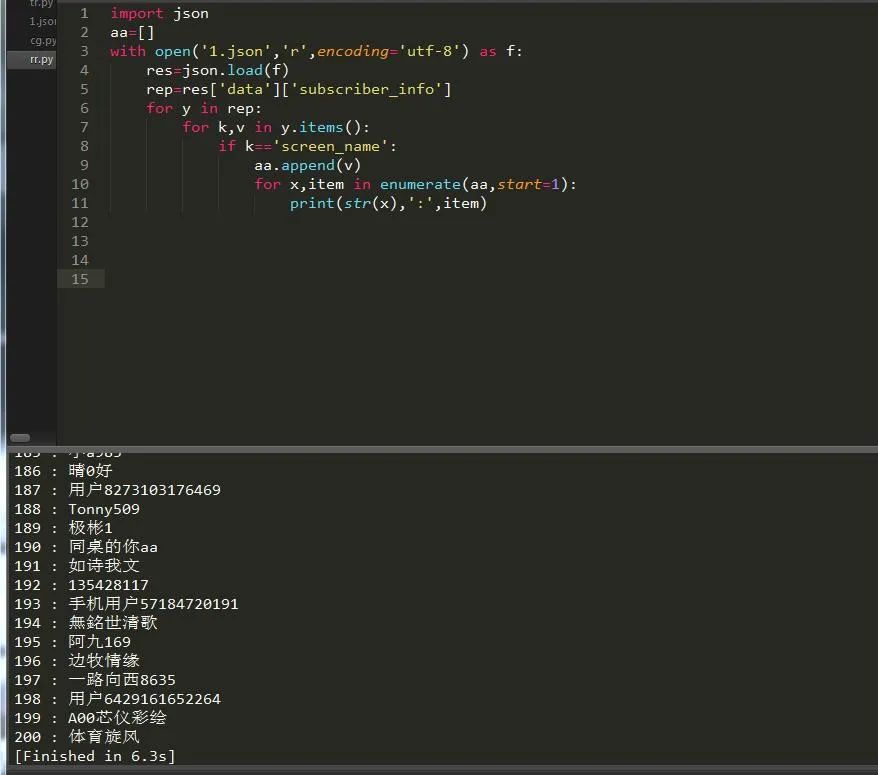
終于全部打印出來啦,哈哈哈,然后我們就可以去獲取我們自己關(guān)注了哪些人,如果有人把我們?nèi)∠P(guān)注了,那么我們也相應(yīng)取消對(duì)他們的關(guān)注。通過一段時(shí)間的爬取,終于爬的差不多了,不過我想應(yīng)該沒有爬完,因?yàn)榫W(wǎng)站有反爬:
項(xiàng)目總結(jié)
通過對(duì)今日頭條ajax和一些加密數(shù)據(jù)的一些情況使我認(rèn)識(shí)到爬蟲這條路真的很遠(yuǎn),不學(xué)js逆向是不可能的。希望大家多多學(xué)習(xí),學(xué)無止境的。
------------------- End -------------------
往期精彩文章推薦:
手把手教你用Scrapy爬蟲框架爬取食品論壇數(shù)據(jù)并存入數(shù)據(jù)庫
一篇文章淺析Python自帶的線程池和進(jìn)程池
手把手教你在Windows下設(shè)置分布式隊(duì)列Celery的心跳輪詢

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說一兩句吧~