
手把手教你用Python網(wǎng)絡(luò)爬蟲(chóng)獲取壁紙圖片
回復(fù)“書(shū)籍”即可獲贈(zèng)Python從入門到進(jìn)階共10本電子書(shū)
/1 前言/
????想要電腦換個(gè)壁紙時(shí)都特別苦惱,因?yàn)榘俣人训侥切┍诩堃簿褪欠直媛蔬_(dá)到了壁紙的水準(zhǔn)。可是里面圖片的質(zhì)量嘛,實(shí)在是不忍直視…。而有些4K高清的壁紙大多是有版權(quán)的 ,這就使我們想要獲取高清的圖片,變得非常的困難。
??? wallhaven 網(wǎng)站是無(wú)版權(quán)的4K壁紙 ,而且主題豐富(創(chuàng)意、攝影、人物、動(dòng)漫、繪畫(huà)、視覺(jué)),今天教大家如何去批量的去下載wallhaven4K原圖。

/2 項(xiàng)目目標(biāo)/
????獲取對(duì)應(yīng)的4K壁紙,并批量下載保存在文件夾。
/3 涉及的庫(kù)和網(wǎng)站/
????軟件:PyCharm
????需要用到的庫(kù):requests、lxml、fake_useragent、time
????先列出網(wǎng)址,如下所示:
https://wallhaven.cc/search?q=id%3A65348&page={}????網(wǎng)址city=%E5%B9%BF%E5%B7%9E指的是廣州這個(gè)城市、pn指的是頁(yè)數(shù)。
/4?項(xiàng)目分析/
????滑動(dòng)鼠標(biāo)觀察下一頁(yè)的網(wǎng)址的變化:
https://wallhaven.cc/search?q=id%3A65348&page=1https://wallhaven.cc/search?q=id%3A65348&page=2https://wallhaven.cc/search?q=id%3A65348&page=3
????滑動(dòng)下一頁(yè)時(shí),每增加一頁(yè)page自增加1,用{}代替變換的變量,再用for循環(huán)遍歷這網(wǎng)址,實(shí)現(xiàn)多個(gè)網(wǎng)址請(qǐng)求。
/5?具體實(shí)現(xiàn)/
1、定義一個(gè)class類繼承object,定義init方法繼承self,主函數(shù)main繼承self。導(dǎo)入需要的庫(kù)和網(wǎng)址。
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport timeclass wallhaven(object):def __init__(self):self.url = "https://wallhaven.cc/search?q=id%3A65348&page={}"def main(self):passif __name__ == '__main__':imageSpider = wallhaven()imageSpider.main()
2、fake_useragent模塊實(shí)現(xiàn)隨機(jī)產(chǎn)生UserAgent。
ua = UserAgent(verify_ssl=False)for i in range(1, 50):self.headers = {'User-Agent': ua.random,}
3、for循環(huán)實(shí)現(xiàn)多網(wǎng)址訪問(wèn)。
startPage = int(input("起始頁(yè):"))endPage = int(input("終止頁(yè):"))for page in range(startPage, endPage + 1):url?=?self.url.format(page)
4、發(fā)送請(qǐng)求 ?獲取響應(yīng)。
'''發(fā)送請(qǐng)求 獲取響應(yīng)'''def get_page(self, url):res = requests.get(url=url, headers=self.headers)html = res.content.decode("utf-8")return html
5、解析一級(jí)頁(yè)面,得到二級(jí)頁(yè)面的 href 地址。
def parse_page(self, html):????parse_html?=?etree.HTML(html)image_src_list = parse_html.xpath('//figure//a/@href')
6、遍歷二級(jí)頁(yè)面網(wǎng)址,發(fā)生請(qǐng)求、解析數(shù)據(jù)。找到相對(duì)于的圖片地址。
html1 = self.get_page(i) # 二級(jí)頁(yè)面發(fā)生請(qǐng)求parse_html1 = etree.HTML(html1)# print(parse_html1)filename = parse_html1.xpath('//div[@class="scrollbox"]//img/@src')# print(filename)
7、獲取到的圖片地址,發(fā)生請(qǐng)求,保存。
# 圖片地址發(fā)生請(qǐng)求for img in filename:dirname = "./圖/" + img[32:] '''可修改圖片保存的地址'''print(dirname)html2 = requests.get(url=img, headers=self.headers).contentwith open(dirname, 'wb') as f:f.write(html2)print("%s下載成功" % filename)
8、調(diào)用方法,實(shí)現(xiàn)功能。
html = self.get_page(url)self.parse_page(html)
優(yōu)化:設(shè)置延時(shí)。(防止ip被封)。
time.sleep(1.4) """時(shí)間延時(shí)"""/6 效果展示/
1、點(diǎn)擊綠色按鈕運(yùn)行,將結(jié)果顯示在控制臺(tái),如下圖所示。輸起始頁(yè)和終止頁(yè),回車。

2、圖片下載成功控制臺(tái)輸出。
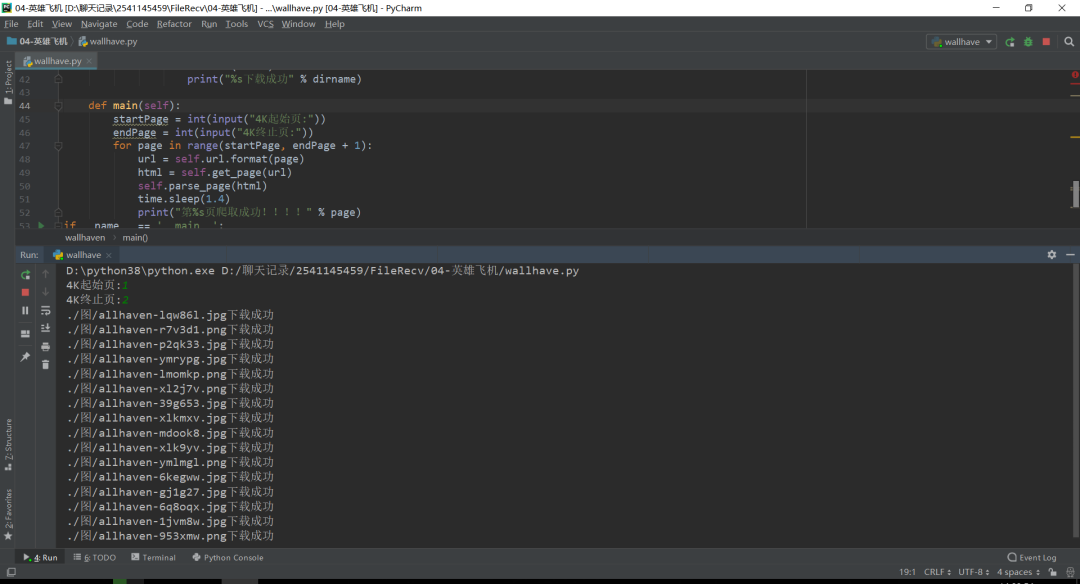
3、批量保存。

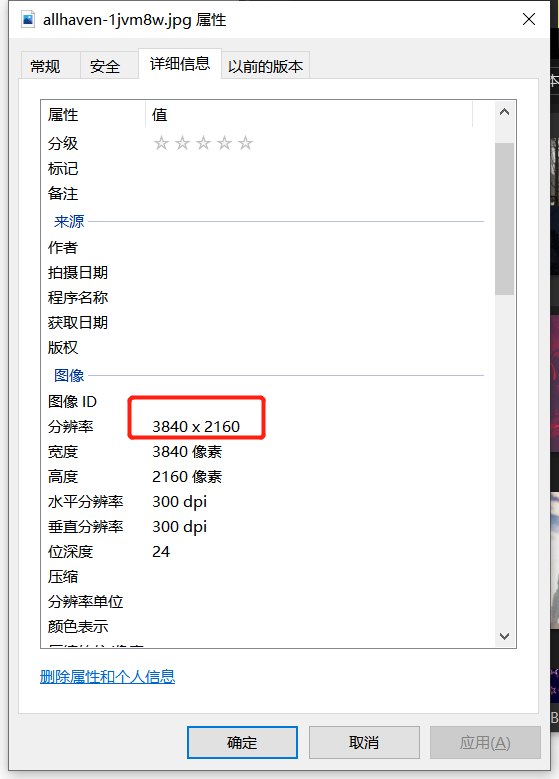
4、驗(yàn)證4K。(點(diǎn)擊圖片打開(kāi)屬性)
/7 小結(jié)/
1、不建議抓取太多數(shù)據(jù),容易對(duì)服務(wù)器造成負(fù)載,淺嘗輒止即可。
2、本文基于Python網(wǎng)絡(luò)爬蟲(chóng),利用爬蟲(chóng)庫(kù),獲取wallhaven4K壁紙。
3、4K的壁紙下載時(shí)可能會(huì)有點(diǎn)緩慢,請(qǐng)大家耐心的等待。如果圖片的地址不一樣,需要自己修改一下圖片的保存的地址。
4、大家也可以在wallhaven網(wǎng)址上,尋找自己喜歡圖片,按照操作步驟,自己嘗試去做。自己實(shí)現(xiàn)的時(shí)候,總會(huì)有各種各樣的問(wèn)題,切勿眼高手低,勤動(dòng)手,才可以理解的更加深刻。
5、如果本文源碼的小伙伴,請(qǐng)?jiān)诤笈_(tái)回復(fù)“4K壁紙”四個(gè)字進(jìn)行獲取,覺(jué)得不錯(cuò),記得給個(gè)Star噢~
-------------------?End?-------------------
往期精彩文章推薦:
手把手用Python教你如何發(fā)現(xiàn)隱藏wifi
手把手教你用Python做個(gè)可視化的“剪刀石頭布”小游戲
手把手用Python網(wǎng)絡(luò)爬蟲(chóng)帶你爬取全國(guó)著名高校附近酒店評(píng)論

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請(qǐng)?jiān)诤笈_(tái)回復(fù)【入群】
萬(wàn)水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說(shuō)一兩句吧~~