
基于 Habana Gaudi 的 Transformers 入門
?? 寶子們可以戳 閱讀原文 查看文中所有的外部鏈接喲!
幾周前,我們很高興地 宣布 Habana Labs 和 Hugging Face 將開展加速 transformer 模型的訓練方面的合作。
與最新的基于 GPU 的 Amazon Web Services (AWS) EC2 實例相比,Habana Gaudi 加速卡在訓練機器學習模型方面的性價比提高了 40%。我們非常高興將這種性價比優(yōu)勢引入 Transformers ??。
本文,我將手把手向你展示如何在 AWS 上快速設置 Habana Gaudi 實例,并用其微調一個用于文本分類的 BERT 模型。與往常一樣,我們提供了所有代碼,以便你可以在自己的項目中重用它們。
我們開始吧!
在 AWS 上設置 Habana Gaudi 實例
使用 Habana Gaudi 加速卡的最簡單方法是啟動一個 AWS EC2 DL1 實例。該實例配備 8 張 Habana Gaudi 加速卡,借助 Habana 深度學習鏡像 (Amazon Machine Image,AMI) ,我們可以輕松把它用起來。該 AMI 預裝了 Habana SynapseAI? SDK 以及運行 Gaudi 加速的 Docker 容器所需的工具。如果你想使用其他 AMI 或容器,請參閱 Habana 文檔 中的說明。
我首先登陸 us-east-1 區(qū)域的 EC2 控制臺,然后單擊 啟動實例 并給實例起個名字 (我用的是 “habana-demo-julsimon”)。
然后,我在 Amazon Marketplace 中搜索 Habana AMI。
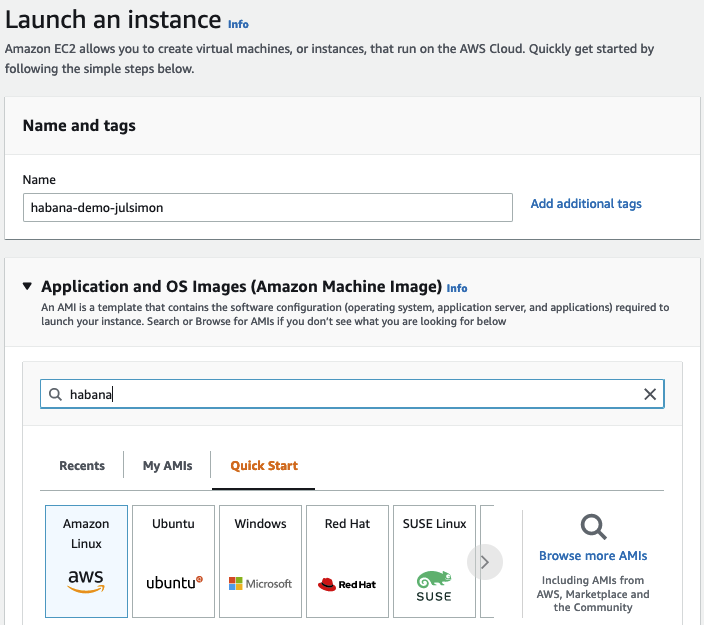
這里,我選擇了 Habana Deep Learning Base AMI (Ubuntu 20.04)。
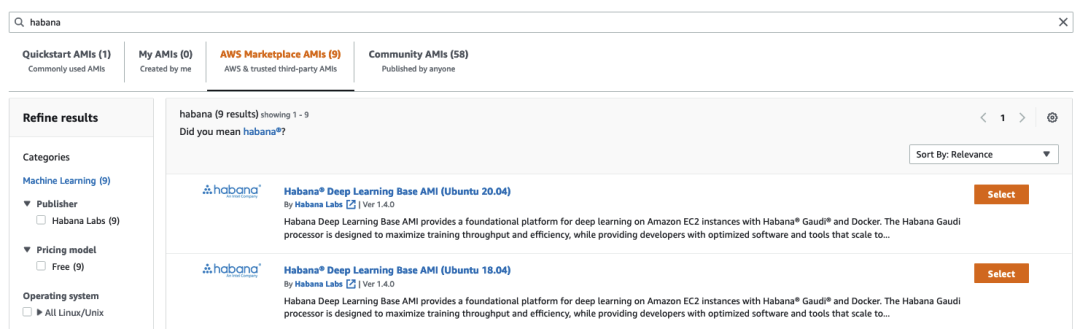
接著,我選擇了 dl1.24xlarge 實例 (實際上這是唯一可選的實例)。
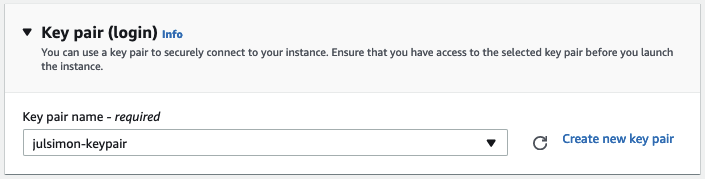
接著是選擇 ssh 密鑰對。如果你沒有密鑰對,可以就地創(chuàng)建一個。
下一步,要確保該實例允許接受 ssh 傳輸。為簡單起見,我并未限制源地址,但你絕對應該在你的帳戶中設置一下,以防止被惡意攻擊。

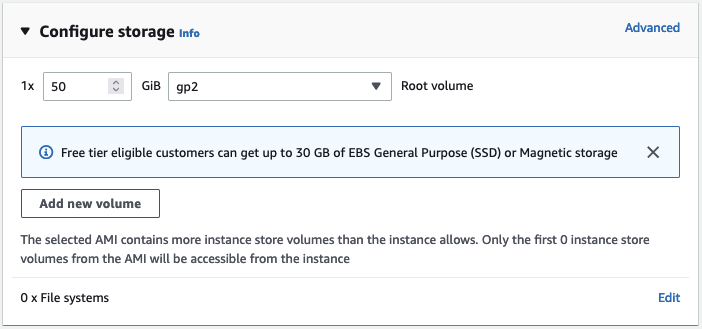
默認情況下,該 AMI 將啟動一個具有 8GB Amazon EBS 存儲的實例。但這對我來說可能不夠,因此我將存儲空間增加到 50GB。
接下來,我需要為該實例分配一個 Amazon IAM 角色。在實際項目中,此角色應具有運行訓練所需的最低權限組合,例如從 Amazon S3 存儲桶中讀取數(shù)據(jù)的權限。但在本例中,我們不需要這個角色,因為數(shù)據(jù)集是從 Hugging Face Hub 上下載的。如果您不熟悉 IAM,強烈建議閱讀這個 入門 文檔。
然后,我要求 EC2 將我的實例配置為 Spot 實例,這可以幫我降低每小時使用成本 (非 Spot 實例每小時要 13.11 美元)。
最后,啟動實例。幾分鐘后,實例已準備就緒,我可以使用 ssh 連上它了。Windows 用戶可以按照 文檔 使用 PuTTY 來連接。
ssh -i ~/.ssh/julsimon-keypair.pem [email protected]
在實例中,最后一步是拉取一個 Habana PyTorch 容器,我后面會用 PyTorch 來微調模型。你可以在 Habana 文檔 中找到有關其他預構建容器以及如何構建自己的容器的信息。
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
將 docker 鏡像拉到實例后,我就可以用交互模式運行它。
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
至此,我就準備好可以微調模型了。
在 Habana Gaudi 上微調文本分類模型
首先,在剛剛啟動的容器內拉取 Optimum Habana 存儲庫。
git clone https://github.com/huggingface/optimum-habana.git
然后,從源代碼安裝 Optimum Habana 軟件包。
cd optimum-habana
pip install .
接著,切到包含文本分類示例的子目錄并安裝所需的 Python 包。
cd examples/text-classification
pip install -r requirements.txt
現(xiàn)在可以啟動訓練了,訓練腳本首先從 Hugging Face Hub 下載 bert-large-uncased-whole-word-masking 模型,然后在 GLUE 基準的 MRPC 任務上對其進行微調。
請注意,我用于訓練的 BERT 配置是從 Hugging Face Hub 獲取的,你也可以使用自己的配置。此外,Gaudi1 還支持其他流行的模型,你可以在 Habana 的網(wǎng)頁上 中找到它們的配置文件。
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
2 分 12 秒后,訓練完成,并獲得了 0.9181 的 F1 分數(shù),相當不錯。你還可以增加 epoch 數(shù),F(xiàn)1 分數(shù)肯定會隨之繼續(xù)提高。
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
最后一步但也是相當重要的一步,用完后別忘了終止 EC2 實例以避免不必要的費用。查看 EC2 控制臺中的 Saving Summary,我發(fā)現(xiàn)由于使用 Spot 實例,我節(jié)省了 70% 的成本,每小時支付的錢從原先的 13.11 美元降到了 3.93 美元。
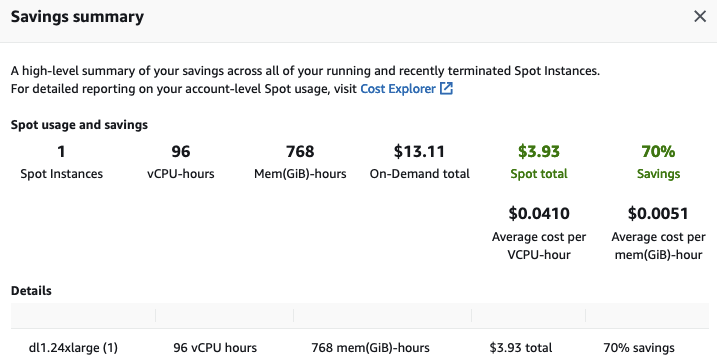
如你所見,Transformers、Habana Gaudi 和 AWS 實例的組合功能強大、簡單且經(jīng)濟高效。歡迎大家嘗試,如果有任何想法,歡迎大家在 Hugging Face 論壇 上提出問題和反饋。
如果你想了解更多有關在 Gaudi 上訓練 Hugging Face 模型的信息,請 聯(lián)系 Habana。
?? 寶子們可以戳 閱讀原文 查看文中所有的外部鏈接喲!
英文原文: https://hf.co/blog/getting-started-habana
原文作者: Julien Simon
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態(tài)數(shù)據(jù)上的應用及大規(guī)模模型的訓練推理。
審校/排版: zhongdongy (阿東)