
論文翻譯 | Mask-SLAM:基于語義分割掩模的魯棒特征單目SLAM
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

本文提出了一種將單目視覺SLAM與基于深度學(xué)習(xí)的語義分割相結(jié)合的新方法.為了穩(wěn)定運(yùn)行,vSLAM需要靜態(tài)對象上的特征點.在傳統(tǒng)的vSLAM中,隨機(jī)樣本一致性(RANSAC) 用于選擇那些特征點.然而,如果視圖的主要部分被移動的對象占據(jù),許多特征點變得不合適,并且RANSAC不能很好地執(zhí)行.根據(jù)我們的經(jīng)驗研究,天空和汽車上的特征點通常會導(dǎo)致vSLAM中的錯誤.我們提出了一個新的框架,使用語義分割產(chǎn)生的掩碼來排除特征點.排除掩蔽區(qū)域中的特征點使vSLAM能夠穩(wěn)定地估計攝像機(jī)運(yùn)動.我們在框架中應(yīng)用ORBSLAM ,這是單目vSLAM的最新實現(xiàn).在我們的實驗中,我們使用CARLA?simulator [3],在各種條件下創(chuàng)建了vSLAM評估數(shù)據(jù)集.與最先進(jìn)的方法相比,我們的方法可以獲得明顯更高的精度.
為了使機(jī)器能夠識別真實世界,攝像機(jī)姿態(tài)估計是一項關(guān)鍵的任務(wù),它可以準(zhǔn)確地估計機(jī)器在真實世界中的位置.視覺同時定位和建圖(vSLAM)是最有前途的定位方法之一.它很簡單,只需要一臺攝像機(jī)來捕捉圖像序列.利用一系列圖像,VSLAM不僅能夠估計攝像機(jī)的位置和姿態(tài),還能重建三維場景.與激光雷達(dá)等其他傳感器相比,成本要低得多,并且可以獲得更多關(guān)于周圍環(huán)境的數(shù)據(jù).然而,vSLAM并不是特別魯棒.
在本文中,我們將重點放在基于特征的vSLAM上,使用ORB-SLAM在單目vSLAM實現(xiàn)運(yùn)行相對穩(wěn)定.基于特征的vSLAM首先從圖像中提取許多特征點,然后比較序列中圖像之間每個點的描述符以搜索對應(yīng)關(guān)系,最后根據(jù)這些對應(yīng)關(guān)系估計攝像機(jī)姿態(tài).基于特征的方法可以抵抗圖像失真,并且可以為多種設(shè)備執(zhí)行高精度的姿態(tài)估計.然而,這些方法僅利用作為特征點提取的局部信息,并且不能區(qū)分世界坐標(biāo)系中靜止區(qū)域的特征點.如果特征點位于移動區(qū)域,vSLAM會產(chǎn)生估計誤差.為了從靜態(tài)區(qū)域中選擇特征點,隨機(jī)樣本一致性(RANSAC) [5]通常用于基于特征的vSLAM.
RANSAC用于從許多假設(shè)中選擇最可靠的值.假設(shè)是從大量對應(yīng)對的隨機(jī)樣本中計算出來的.vSLAM應(yīng)排除移動區(qū)域中的特征點,這些特征點可能不正確,并可能導(dǎo)致錯誤.然而考慮一個大多數(shù)對應(yīng)對不正確的情況.RANSAC無法專門選擇正確的點對,vSLAM無法正確解決問題.為了處理這些不適合RANSAC的情況,我們使用了通過基于深度神經(jīng)網(wǎng)絡(luò)的語義分割獲得的掩碼語義分割考慮了圖像中的全局信息,是對基于特征的vSLAM的補(bǔ)充,后者僅利用圖像中的局部信息.
該方法不僅考慮了圖像的局部特征,還考慮了圖像的全局特征,有利于靈活且高精度的圖像識別.僅使用圖像中的基于特征的vSLAM的環(huán)境局部信息的,這強(qiáng)烈依賴于環(huán)境.然而,使用語義分割這一深度學(xué)習(xí)中最活躍的研究課題之一,可以彌補(bǔ)基于特征的vSLAM中的不足.這是通過使用語義分割產(chǎn)生的掩碼來移除不適當(dāng)區(qū)域中的特征點來實現(xiàn)的.mask確保假設(shè)不會集中在不適當(dāng)?shù)膮^(qū)域,例如移動的對象.
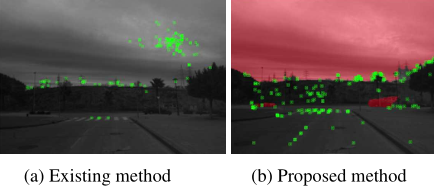
圖1:現(xiàn)有方法和建議方法在特征點提取方面的差異.通過掩蔽特征點的區(qū)域,特征點在圖像中變得均勻分布,而不集中在不適合vSLAM的區(qū)域.
在我們的實驗中,我們主要關(guān)注從移動的車輛上拍攝的視頻.在我們的初步實驗中,特征點不正確的區(qū)域通常包括行人、車輛和天空.在最著名的基準(zhǔn)數(shù)據(jù)集KITTI中,條件過于優(yōu)化,不合適的區(qū)域非常少.在現(xiàn)實世界中,天氣、移動物體(汽車)、行人等都有極端的多樣性.因此,我們決定使用CARLA?simulator[3]生成的模擬環(huán)境來評估我們.有了CARLA模擬器,人們可以自由移動汽車和改變天氣,并且可以根據(jù)需要創(chuàng)建盡可能多的數(shù)據(jù).我們使用在盡可能接近真實世界的模擬環(huán)境中獲得的大量數(shù)據(jù)集來評估所提出的方法的有效性.
本文的主要貢獻(xiàn)如下:
我們提出了一種通過引入基于深度學(xué)習(xí)的語義分割來提高單目vSLAM性能的方法.vSLAM局部信息的不足可以通過引入語義分割的全局信息來解決 所提出的方法獲得的性能幾乎與傳統(tǒng)vSLAM理想運(yùn)行時獲得的性能相同 我們利用駕駛模擬器來產(chǎn)生許多現(xiàn)有數(shù)據(jù)集中沒有的環(huán)境.基于模擬視頻的實驗表明,該方法的性能明顯優(yōu)于現(xiàn)有方法
已經(jīng)有一些嘗試來解決將深度學(xué)習(xí)與虛擬空間學(xué)習(xí)相結(jié)合的問題,或者利用深度學(xué)習(xí)來實現(xiàn)傳統(tǒng)空間學(xué)習(xí)的功能.最著名的方法之一是CNN-SLAM,它使用深度學(xué)習(xí)推斷的深度值作為SLAM估計的初始解.最近,已經(jīng)提出了無監(jiān)督的方法來估計深度[6]和自我運(yùn)動[19],并執(zhí)行3D重建[18].這些方法只能從無標(biāo)簽(原始)movie中學(xué)習(xí),與現(xiàn)有的vSLAM方法相比,它們的準(zhǔn)確性很差.我們認(rèn)為這些方法的一部分可以幫助改進(jìn)現(xiàn)有的vSLAM方法.特別是[19]的作者介紹了一種“可解釋mask”,這是一種不適合主流運(yùn)動估計技術(shù)的圖像區(qū)域mask.然而,他們的方法無法排除占據(jù)視圖的移動對象區(qū)域,因為他們的訓(xùn)練數(shù)據(jù)不包含這樣的圖像.有必要初步了解圖像中的哪些部分傾向于移動,哪些部分是靜止的.
在我們的系統(tǒng)中,我們使用語義分割來改進(jìn)vSLAM.語義分割是一種將圖像分成語義類別區(qū)域的方法,如人、車、天空等.將vSLAM和語義分割相結(jié)合是合理的,因為前者依賴于局部信息,而后者產(chǎn)生局部信息隊形.這兩種類型的信息是互補(bǔ)的,它們的適當(dāng)組合可以提高vSLAM的準(zhǔn)確性.
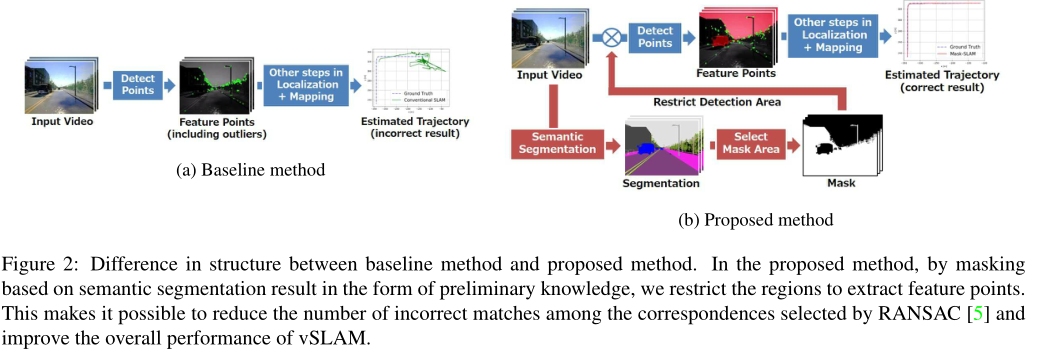
Mask-SLAM本節(jié)描述了Mask-SLAM方法.我們的模型包括使用語義分割從圖像中構(gòu)建一個掩碼,并將該信息合并到現(xiàn)有的vSLAM系統(tǒng)中.如圖2所示.
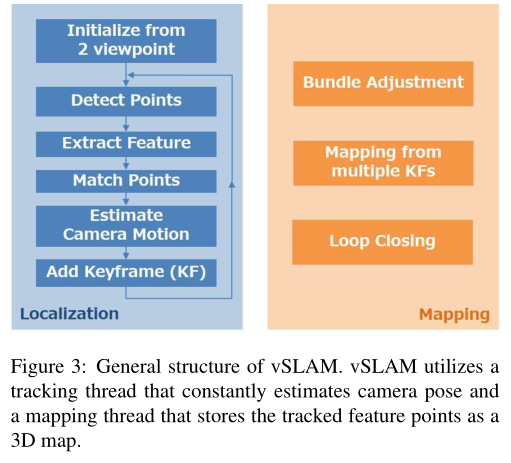
基于特征的vSLAM通常包括“定位,即跟蹤相機(jī)姿態(tài)估計”和“建圖以重建周圍的3D環(huán)境”,這兩個過程同時執(zhí)行.圖3給出了詳細(xì)的算法.vSLAM從圖像中提取特征點,通過比較每個點的描述符獲得對應(yīng)的對,并根據(jù)對應(yīng)關(guān)系估計攝像機(jī)運(yùn)動.ORB-SLAM是vSLAM的最先進(jìn)的實現(xiàn),它使用可以高速提取的ORB特征點,并比較這些ORB特征以獲得對應(yīng)點.ORB-SLAM利用獲取大量對應(yīng)對并從中選擇可靠對的策略.RANSAC 是用于選擇最可靠對應(yīng)關(guān)系的算法.
RANSAC算法的操作如下:
從數(shù)據(jù)中隨機(jī)抽取足夠數(shù)量的樣本 估計一組參數(shù)來擬合這些樣本,這組參數(shù)稱為假設(shè). 將獲得的假設(shè)應(yīng)用于除提取樣本之外的所有數(shù)據(jù),并計算每個數(shù)據(jù)樣本的估計參數(shù)之間的距離 將距離較小的樣本視為內(nèi)聯(lián)樣本,讓內(nèi)聯(lián)樣本的數(shù)量代表一個假設(shè)的正確性 以上操作執(zhí)行多次,采用內(nèi)聯(lián)數(shù)最大的假設(shè),剔除離群數(shù)據(jù)
通過實現(xiàn)上述方法,可以獲得不受異常值影響的正確估計結(jié)果.一般來說,在vSLAM中,RANSAC可以從大量對應(yīng)關(guān)系中找到最正確的一對,并可以推導(dǎo)出準(zhǔn)確的相機(jī)姿態(tài).然而,這種方法的用處是有限的.vSLAM需要靜止物體的特征,以便RANSAC能夠選擇可靠的對應(yīng)關(guān)系.當(dāng)整個視圖被移動的物體占據(jù)時,RANSAC不能選擇可靠的對應(yīng)關(guān)系.在vSLAM中,對輸入視頻的每一幀執(zhí)行RANSAC,以估計攝像機(jī)姿態(tài).如果一個不適合估計相機(jī)姿態(tài)的區(qū)域出現(xiàn)了很長一段時間,那么連續(xù)檢測不適合的對應(yīng)點作為內(nèi)聯(lián)點的概率就會大大增加.這種情況經(jīng)常發(fā)生在使用SLAM?out-doors時.
因此,我們提出使用語義分割來彌補(bǔ)RANSAC的不足.語義分割用于產(chǎn)生一個掩碼,以排除不可能找到正確對應(yīng)的區(qū)域.具體而言,在一般的vSLAM系統(tǒng)中,在檢測特征點的階段,添加了“不檢測掩蔽區(qū)域中的特征點”的操作.通過簡單地增加這個操作,可以排除大部分獲得的不準(zhǔn)確的對應(yīng)關(guān)系,這顯著地減少了RANSAC誤差.
語義分割是給每個像素分配一個對象類的問題.VOC2012和MSCOCO是語義分割的代表性數(shù)據(jù)集.我們定義要屏蔽的對象如下:
汽車:不適合特征點的運(yùn)動物體 天空:這個物體離相機(jī)視圖太遠(yuǎn).這意味著很難估計這個物體的精確3D位置
掩模中排除了應(yīng)該從圖像中檢測特征點的區(qū)域.在這項研究中,我們使用了DeepLab v2 ,它可以執(zhí)行高精度的語義分割. DeepLab v2利用具有以下結(jié)構(gòu)的網(wǎng)絡(luò):
對于輸入圖像,深度卷積神經(jīng)網(wǎng)絡(luò)輸出對象存在概率heat map.
對概率heat map.進(jìn)行雙線性插值
最終的區(qū)域分割結(jié)果基于使用條件隨機(jī)場的邊界細(xì)化而輸出[11].
DeepLab v2實現(xiàn)了一個atrous卷積,可以降低計算成本,在不降低分辨率的情況下進(jìn)行卷積運(yùn)算.通過在卷積濾波器像素之間的間隙中插入零并放大它,輸出結(jié)果保持高分辨率.此外為了獲得關(guān)于圖像中各種大小的對象的信息,可以通過組合空間金字塔匯集來提高性能,該空間金字塔匯集在多個尺度上并行執(zhí)行卷積,具有atrous卷積(atrous空間金字塔匯集(ASPP)).在Deeplab v2中,通過將ASPP合并到現(xiàn)有網(wǎng)絡(luò)(VGGNet或ResNet)中,創(chuàng)建者能夠?qū)С龈叨葴?zhǔn)確的概率heat map
在我們的實驗中,我們使用CARLA駕駛模擬器CARLA [3]創(chuàng)建的30000幅圖像(800 × 600像素)從頭開始訓(xùn)練了一個基于ResNet-101的DeepLab v2.我們使用了一個特斯拉K80 GPU來訓(xùn)練網(wǎng)絡(luò).我們基于前文的實驗設(shè)置構(gòu)建了訓(xùn)練數(shù)據(jù).
數(shù)據(jù)集由從移動的汽車捕獲的圖像和語義分割基本事實結(jié)果(13種標(biāo)簽).語義分段GT數(shù)據(jù)最初有12種類型的標(biāo)簽(無、建筑物、柵欄、其他、行人、電線桿、道路、人行道、車輛、墻壁和交通燈),但我們添加了“天空”標(biāo)簽.
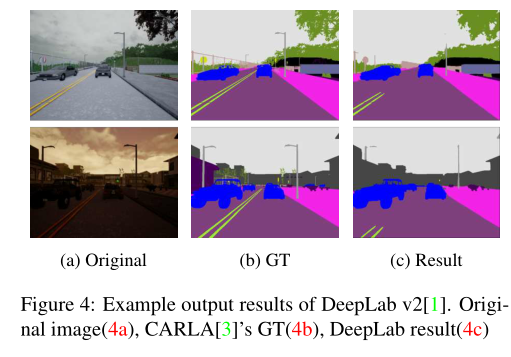
我們創(chuàng)建了“天空”標(biāo)簽,如下所示.對于深度值最深(1000[m])的語義分割GT中標(biāo)記為“無”的像素,我們將“無”的標(biāo)簽更改為“天空”.圖4顯示了DeepLab v2的結(jié)果
“汽車”(移動物體)和“天空”(遠(yuǎn)處區(qū)域)是我們憑經(jīng)驗發(fā)現(xiàn)會干擾vSLAM運(yùn)行的物體.我們輸出這兩個標(biāo)簽區(qū)域作為mask,并實現(xiàn)了一個過程,在這個過程中,不會從這些被遮罩的區(qū)域檢測到特征點.
為了證明所提出方法的有效性,我們使用了CARLA駕駛模擬器[3],它可以模擬各種環(huán)境.現(xiàn)有的基準(zhǔn),如KITTI,只考慮RANSAC不太可能失敗的有限情況.然而由于現(xiàn)實世界中出現(xiàn)了各種各樣的環(huán)境,僅使用KITTI基準(zhǔn)來評估模型是不夠的.在本實驗中,我們使用CARLA模擬了各種天氣條件和移動物體環(huán)境,以確定所提出的方法在各種條件下是否有效.CARLA可以靈活地改變天氣條件,并可以自動移動汽車.
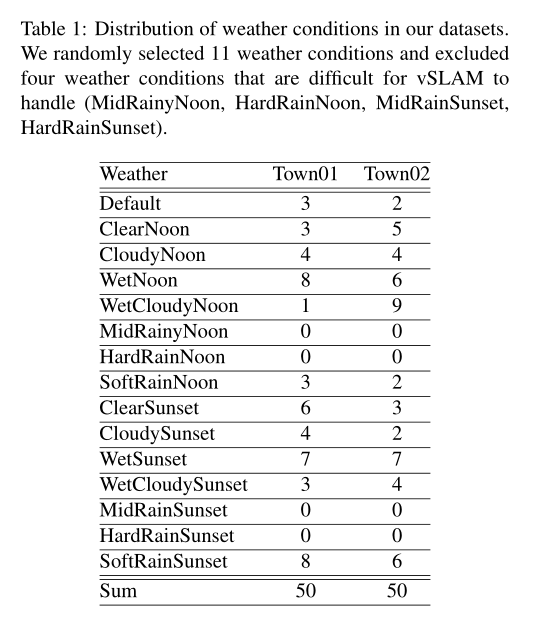
CARLA是由Desovitskiy等人開發(fā)的用于自動操作的駕駛模擬器.我們從兩個城鎮(zhèn)(Town01,Town02)在15種天氣條件下移動的汽車上獲取圖像(CloudySunset、SoftRain、Clearnoon等).
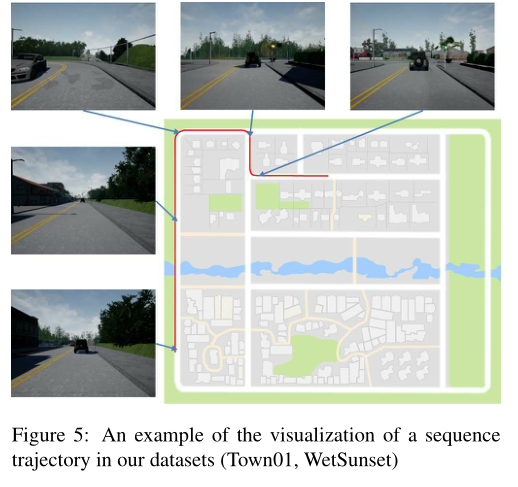
此外我們獲取了全球定位系統(tǒng)、激光雷達(dá)、語義和分割等傳感器數(shù)據(jù),這些數(shù)據(jù)在現(xiàn)實世界中是不可用的.在這個實驗中,我們從兩個城鎮(zhèn)的50次運(yùn)行中創(chuàng)建了數(shù)據(jù)集(總共100次運(yùn)行)。每次運(yùn)行包含1000幅圖像(800 × 600像素),以15幀/秒的速度拍攝.我們將運(yùn)行中獲得的圖像(視頻)稱為序列.汽車使用自動駕駛模式自動駕駛,每次行駛距離為100-500米.我們還從11個選項中隨機(jī)選擇了天氣條件.我們排除了ORBSLAM 無法運(yùn)行的四種天氣條件.表1列出了數(shù)據(jù)分布.此外,序列軌跡可視化的例子在圖5中給出.
在這一部分,我們描述我們的評估指標(biāo).我們對每種基線方法[15]和我們的每種序列方法估計了50次軌跡.我們定義了兩個評估指標(biāo)來計算每個指標(biāo)的平均值數(shù)據(jù)類型.
“序列”的評估值被定義為“通過重復(fù)推導(dǎo)一個序列的50個軌跡的估計值而獲得的平均值” “整個序列”的評估值定義為“每個序列的評估值的平均值”
在這個實驗中,我們關(guān)注的是vSLAM的整體改進(jìn).我們將改進(jìn)定義為當(dāng)原始vSLAM失去位置并停止運(yùn)行時,我們的vSLAM運(yùn)行沒有問題.我們觀察了幾個案例,在這些案例中,由于汽車或天空造成的錯誤,原始的vSLAM在完成之前就停止了.
考慮到這些想法,我們使用了以下兩種評估指標(biāo):
平均跟蹤速率(MTR):該指標(biāo)指示vSLAM是否在每個序列的基礎(chǔ)上跟蹤而不丟失其位置或停止操作.如果跟蹤成功,vSLAM輸出估計值每幀中攝像機(jī)運(yùn)動的結(jié)果.我們將“失敗跟蹤”定義為在一個序列的1000個幀中,超過80 [%]的幀未能獲得估計結(jié)果.我們將單個序列超過50次試驗的成功率輸出為“跟蹤率[%]”相反,我們將“成功跟蹤”定義為在1000幀中成功跟蹤超過80 [%]的幀.如果觀察到評估值有所改善,則表明vSLAM的性能有所改善.具體來說,我們?yōu)樗性囼炛贫恕捌骄櫬蔥%]”

平均軌跡誤差(MTE):一般變速直線加速器的目標(biāo)是“估計接近GT的攝像機(jī)的軌跡”作為接近度的評估,我們將每個時間步長的距離誤差和序列的平均值輸出為“軌跡誤差[m]”.因為我們在實現(xiàn)中使用了單目vSLAM,所以我們根據(jù)Horn的方法計算了將比例調(diào)整到GT后的誤差[9].但是需要注意的是,我們計算的誤差只針對“成功追蹤”(“追蹤率”超過80 [%]).這是因為如果“跟蹤率”低,可以在根據(jù)霍恩的方法調(diào)整比例時將誤差設(shè)置為零.但是這不是一個恰當(dāng)?shù)脑u價.我們?yōu)樗性囼炛贫恕捌骄壽E誤差(MTE) [m]”,順序如下:

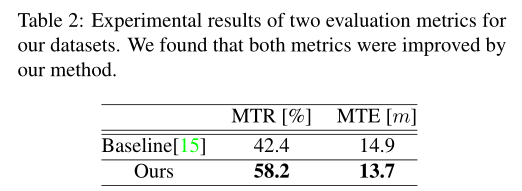
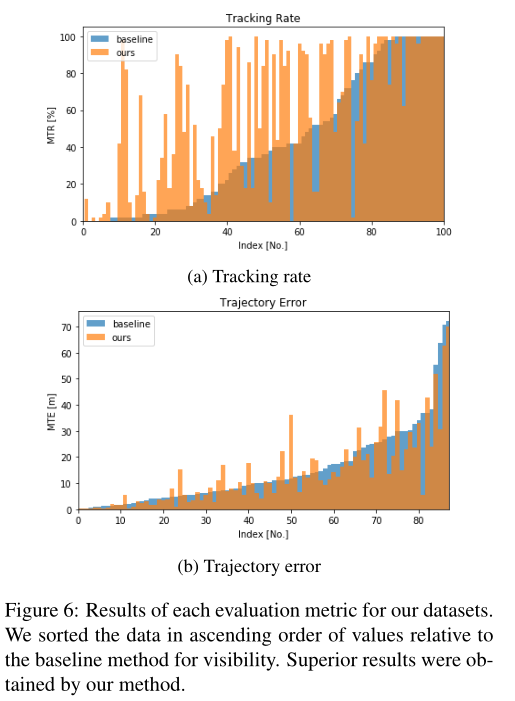
表2列出了所有數(shù)據(jù)集的評估結(jié)果(“平均跟蹤率”和“平均軌跡誤差”).可以看到,當(dāng)使用我們的方法時,在這兩個指標(biāo)上都觀察到了改進(jìn).
此外,為了詳細(xì)顯示結(jié)果,我們在圖6中說明了每個序列的結(jié)果.我們確定,當(dāng)“跟蹤速率”值增加或“軌跡誤差”值減少時,vSLAM的性能有所提高.從圖6中可以看出,當(dāng)使用所提出的方法時,我們發(fā)現(xiàn)對于所有序列,兩種評估度量都有所改進(jìn).“平均軌跡誤差(MTE)”的改善程度在表2中可能顯得很小.然而如前文所述,我們僅使用來自“成功跟蹤”試驗(其“跟蹤率”為80[%]或更高)的數(shù)據(jù)來計算“平均軌跡誤差(MTE)”由于基線“跟蹤率”較低,我們使用少量數(shù)據(jù)樣本(試驗)計算了“軌跡誤差”.相比之下,因為我們的方法的“跟蹤率”很高,所以我們使用大量的試驗來計算我們的方法的“軌跡誤差”.基線和我們的方法之間的誤差差異很小,因為試驗是閾值化的,并且只考慮成功的試驗.
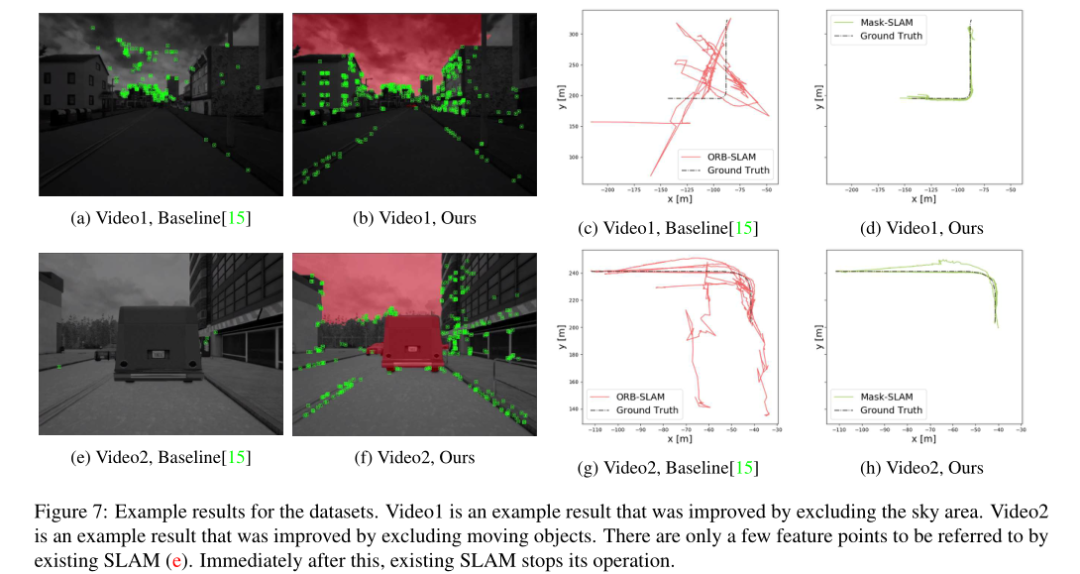
另外我們關(guān)注100個序列中的兩個結(jié)果,包括-ing數(shù)據(jù)集.結(jié)果如圖7和表3所示.圖7展示出了通過每種方法對一幀的特征提取以及每個序列的估計軌跡
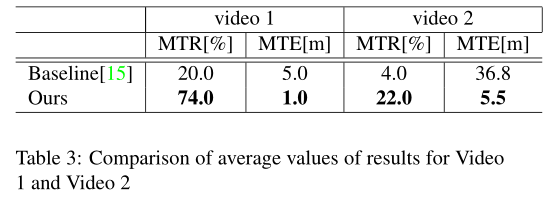
結(jié)果表明,與基線方法相比,我們的方法提高了結(jié)果.關(guān)于視頻1,通過使用掩模限制特征點檢測區(qū)域來抑制天空區(qū)域上的集中.結(jié)果,從整個視圖中提取特征點,并且估計結(jié)果變得穩(wěn)定.關(guān)于視頻2,基線vSLAM停止并失去了它的位置,因為汽車覆蓋了整個視圖.然而在所提出的方法中,通過使用掩模成功地排除了在汽車區(qū)域中特征點的檢測,在不停止我們的方法的操作的情況下,特征點的跟蹤成功.當(dāng)比較每個視頻中軌跡的結(jié)果時,基線方法輸出偏離GT的軌跡,但是所提出的方法輸出與GT重疊的相對精確的軌跡.結(jié)果,“跟蹤率”和“軌跡誤差”都得到了改善.
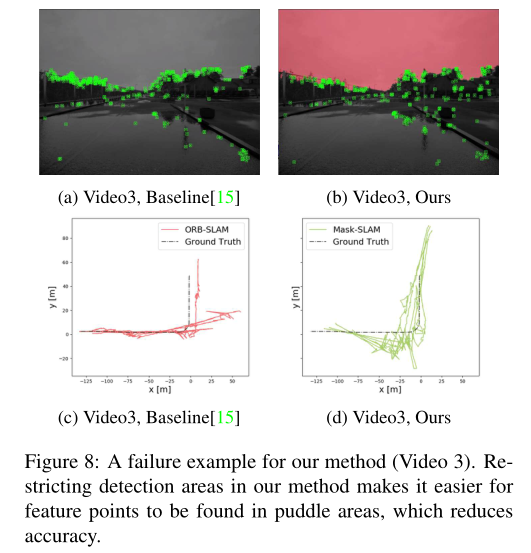


當(dāng)使用所有數(shù)據(jù)時,所提出的方法并不總是產(chǎn)生好的結(jié)果.視頻3就是一個失敗的例子.這在圖8和表4中清楚地顯示出來.視頻3中的天氣是潮濕的多云的日落,路上有水坑.跟蹤反映在水坑表面上的建筑物輪廓的特征點導(dǎo)致vSLAM的估計精度下降.在我們的方法中,通過使用遮罩排除汽車和天空,與基線方法相比,特征點更有可能在水坑區(qū)域被檢測到.結(jié)果是“跟蹤速率”和“軌跡誤差”都降低了.
提出了一種新的基于特征的向量空間模型和語義分割相結(jié)合的方法.語義分割輸出了將對象分類到圖像中的語義區(qū)域的結(jié)果,我們從不適合vSLAM的語義區(qū)域生成了一個掩碼.我們的vSLAM方法只從掩模排除的區(qū)域提取特征點,并且只能選擇可靠的特征點.這使得vSLAM能夠準(zhǔn)確穩(wěn)定地工作,而不會丟失其位置。