
一些目標(biāo)檢測(cè)技巧
點(diǎn)擊上方“機(jī)器學(xué)習(xí)與生成對(duì)抗網(wǎng)絡(luò)”,關(guān)注星標(biāo)
獲取有趣、好玩的前沿干貨!
本文轉(zhuǎn)自:視學(xué)算法
源碼在mmdet/datasets/extra_aug.py里面,包括RandomCrop、brightness、contrast、saturation、ExtraAugmentation等等圖像增強(qiáng)方法。
添加位置是train_pipeline或test_pipeline這個(gè)地方(一般train進(jìn)行增強(qiáng)而test不需要),例如數(shù)據(jù)增強(qiáng)RandomFlip,flip_ratio代表隨機(jī)翻轉(zhuǎn)的概率:
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),dict(type='RandomFlip', flip_ratio=0.5),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='DefaultFormatBundle'),dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='MultiScaleFlipAug',img_scale=(1333, 800),flip=False,transforms=[dict(type='Resize', keep_ratio=True),dict(type='RandomFlip'),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']),])]
源碼在mmdet/datasets/custom.py里面,增強(qiáng)源碼為:
def pre_pipeline(self, results): results['img_prefix'] = self.img_prefix results['seg_prefix'] = self.seg_prefix results['proposal_file'] = self.proposal_file results['bbox_fields'] = [] results['mask_fields'] = []
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations', with_bbox=True),dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), #這里可以更換多尺度[(),()]dict(type='RandomFlip', flip_ratio=0.5),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='DefaultFormatBundle'),dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [dict(type='LoadImageFromFile'),dict(type='MultiScaleFlipAug',img_scale=(1333, 800),flip=False,transforms=[dict(type='Resize', keep_ratio=True),dict(type='RandomFlip'),dict(type='Normalize', **img_norm_cfg),dict(type='Pad', size_divisor=32),dict(type='ImageToTensor', keys=['img']),dict(type='Collect', keys=['img']),])]
box voting 的閾值,
不同的輸入中這個(gè)框至少出現(xiàn)了幾次來(lái)允許它輸出,
得分的閾值,一個(gè)目標(biāo)框的得分低于這個(gè)閾值的時(shí)候,就刪掉這個(gè)目標(biāo)框。
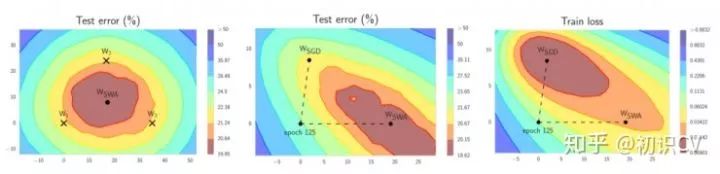
第一個(gè)模型保存模型權(quán)值的平均值(WSWA)。在訓(xùn)練結(jié)束后,它將是用于預(yù)測(cè)的最終模型。
第二個(gè)模型(W)將穿過(guò)權(quán)值空間,基于周期性學(xué)習(xí)率規(guī)劃探索權(quán)重空間。
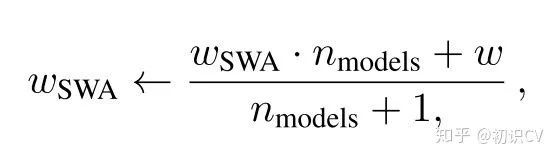
rcnn=[ dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.4, # 更換 neg_iou_thr=0.4, min_pos_iou=0.4, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.5, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', # 解決難易樣本,也解決了正負(fù)樣本比例問(wèn)題。num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.6, neg_iou_thr=0.6, min_pos_iou=0.6, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False) ], stage_loss_weights=[1, 0.5, 0.25])

 即為軟化函數(shù),通常取線性或高斯函數(shù),后者效果稍好一些。當(dāng)然,在享受這一增益的同時(shí),Soft-NMS也引入了一些超參,對(duì)不同的數(shù)據(jù)集需要試探以確定最佳配置。
即為軟化函數(shù),通常取線性或高斯函數(shù),后者效果稍好一些。當(dāng)然,在享受這一增益的同時(shí),Soft-NMS也引入了一些超參,對(duì)不同的數(shù)據(jù)集需要試探以確定最佳配置。test_cfg = dict( rpn=dict( nms_across_levels=False, nms_pre=1000, nms_post=1000, max_num=1000, nms_thr=0.7, min_bbox_size=0), rcnn=dict( score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=20)) # 這里可以換為sof_tnms更好的先驗(yàn)(YOLOv2):使用聚類(lèi)方法統(tǒng)計(jì)數(shù)據(jù)中box標(biāo)注的大小和長(zhǎng)寬比,以更好的設(shè)置anchor box的生成配置
更好的pre-train模型:檢測(cè)模型的基礎(chǔ)網(wǎng)絡(luò)通常使用ImageNet(通常是ImageNet-1k)上訓(xùn)練好的模型進(jìn)行初始化,使用更大的數(shù)據(jù)集(ImageNet-5k)預(yù)訓(xùn)練基礎(chǔ)網(wǎng)絡(luò)對(duì)精度的提升亦有幫助
超參數(shù)的調(diào)整:部分工作也發(fā)現(xiàn)如NMS中IoU閾值的調(diào)整(從0.3到0.5)也有利于精度的提升,但這一方面尚無(wú)最佳配置參照
1.各部分代碼解析
1.1 faster_rcnn_r50_fpn_1x.py:
# model settingsmodel = dict(type='FasterRCNN', # model類(lèi)型pretrained='modelzoo://resnet50', # 預(yù)訓(xùn)練模型:imagenet-resnet50backbone=dict(type='ResNet', # backbone類(lèi)型depth=50, # 網(wǎng)絡(luò)層數(shù)num_stages=4, # resnet的stage數(shù)量out_indices=(0, 1, 2, 3), # 輸出的stage的序號(hào)frozen_stages=1, # 凍結(jié)的stage數(shù)量,即該stage不更新參數(shù),-1表示所有的stage都更新參數(shù)style='pytorch'), # 網(wǎng)絡(luò)風(fēng)格:如果設(shè)置pytorch,則stride為2的層是conv3x3的卷積層;如果設(shè)置caffe,則stride為2的層是第一個(gè)conv1x1的卷積層neck=dict(type='FPN', # neck類(lèi)型in_channels=[256, 512, 1024, 2048], # 輸入的各個(gè)stage的通道數(shù)out_channels=256, # 輸出的特征層的通道數(shù)num_outs=5), # 輸出的特征層的數(shù)量rpn_head=dict(type='RPNHead', # RPN網(wǎng)絡(luò)類(lèi)型in_channels=256, # RPN網(wǎng)絡(luò)的輸入通道數(shù)feat_channels=256, # 特征層的通道數(shù)anchor_scales=[8], # 生成的anchor的baselen,baselen = sqrt(w*h),w和h為anchor的寬和高anchor_ratios=[0.5, 1.0, 2.0], # anchor的寬高比anchor_strides=[4, 8, 16, 32, 64], # 在每個(gè)特征層上的anchor的步長(zhǎng)(對(duì)應(yīng)于原圖)target_means=[.0, .0, .0, .0], # 均值target_stds=[1.0, 1.0, 1.0, 1.0], # 方差use_sigmoid_cls=True), # 是否使用sigmoid來(lái)進(jìn)行分類(lèi),如果False則使用softmax來(lái)分類(lèi)bbox_roi_extractor=dict(type='SingleRoIExtractor', # RoIExtractor類(lèi)型roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), # ROI具體參數(shù):ROI類(lèi)型為ROIalign,輸出尺寸為7,sample數(shù)為2out_channels=256, # 輸出通道數(shù)featmap_strides=[4, 8, 16, 32]), # 特征圖的步長(zhǎng)bbox_head=dict(type='SharedFCBBoxHead', # 全連接層類(lèi)型num_fcs=2, # 全連接層數(shù)量in_channels=256, # 輸入通道數(shù)fc_out_channels=1024, # 輸出通道數(shù)roi_feat_size=7, # ROI特征層尺寸num_classes=81, # 分類(lèi)器的類(lèi)別數(shù)量+1,+1是因?yàn)槎嗔艘粋€(gè)背景的類(lèi)別target_means=[0., 0., 0., 0.], # 均值target_stds=[0.1, 0.1, 0.2, 0.2], # 方差reg_class_agnostic=False)) # 是否采用class_agnostic的方式來(lái)預(yù)測(cè),class_agnostic表示輸出bbox時(shí)只考慮其是否為前景,后續(xù)分類(lèi)的時(shí)候再根據(jù)該bbox在網(wǎng)絡(luò)中的類(lèi)別得分來(lái)分類(lèi),也就是說(shuō)一個(gè)框可以對(duì)應(yīng)多個(gè)類(lèi)別# model training and testing settingstrain_cfg = dict(rpn=dict(assigner=dict(type='MaxIoUAssigner', # RPN網(wǎng)絡(luò)的正負(fù)樣本劃分pos_iou_thr=0.7, # 正樣本的iou閾值neg_iou_thr=0.3, # 負(fù)樣本的iou閾值min_pos_iou=0.3, # 正樣本的iou最小值。如果assign給ground truth的anchors中最大的IOU低于0.3,則忽略所有的anchors,否則保留最大IOU的anchorignore_iof_thr=-1), # 忽略bbox的閾值,當(dāng)ground truth中包含需要忽略的bbox時(shí)使用,-1表示不忽略sampler=dict(type='RandomSampler', # 正負(fù)樣本提取器類(lèi)型num=256, # 需提取的正負(fù)樣本數(shù)量pos_fraction=0.5, # 正樣本比例neg_pos_ub=-1, # 最大負(fù)樣本比例,大于該比例的負(fù)樣本忽略,-1表示不忽略add_gt_as_proposals=False), # 把ground truth加入proposal作為正樣本allowed_border=0, # 允許在bbox周?chē)鈹U(kuò)一定的像素pos_weight=-1, # 正樣本權(quán)重,-1表示不改變?cè)嫉臋?quán)重smoothl1_beta=1 / 9.0, # 平滑L1系數(shù)debug=False), # debug模式rcnn=dict(assigner=dict(type='MaxIoUAssigner', # RCNN網(wǎng)絡(luò)正負(fù)樣本劃分pos_iou_thr=0.5, # 正樣本的iou閾值neg_iou_thr=0.5, # 負(fù)樣本的iou閾值min_pos_iou=0.5, # 正樣本的iou最小值。如果assign給ground truth的anchors中最大的IOU低于0.3,則忽略所有的anchors,否則保留最大IOU的anchorignore_iof_thr=-1), # 忽略bbox的閾值,當(dāng)ground truth中包含需要忽略的bbox時(shí)使用,-1表示不忽略sampler=dict(type='RandomSampler', # 正負(fù)樣本提取器類(lèi)型num=512, # 需提取的正負(fù)樣本數(shù)量pos_fraction=0.25, # 正樣本比例neg_pos_ub=-1, # 最大負(fù)樣本比例,大于該比例的負(fù)樣本忽略,-1表示不忽略add_gt_as_proposals=True), # 把ground truth加入proposal作為正樣本pos_weight=-1, # 正樣本權(quán)重,-1表示不改變?cè)嫉臋?quán)重debug=False)) # debug模式test_cfg = dict(rpn=dict( # 推斷時(shí)的RPN參數(shù)nms_across_levels=False, # 在所有的fpn層內(nèi)做nmsnms_pre=2000, # 在nms之前保留的的得分最高的proposal數(shù)量nms_post=2000, # 在nms之后保留的的得分最高的proposal數(shù)量max_num=2000, # 在后處理完成之后保留的proposal數(shù)量nms_thr=0.7, # nms閾值min_bbox_size=0), # 最小bbox尺寸rcnn=dict(score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100) # max_per_img表示最終輸出的det bbox數(shù)量# soft-nms is also supported for rcnn testing# e.g., nms=dict(type='soft_nms', iou_thr=0.5, min_score=0.05) # soft_nms參數(shù))# dataset settingsdataset_type = 'CocoDataset' # 數(shù)據(jù)集類(lèi)型data_root = 'data/coco/' # 數(shù)據(jù)集根目錄img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True) # 輸入圖像初始化,減去均值mean并處以方差std,to_rgb表示將bgr轉(zhuǎn)為rgbdata = dict(imgs_per_gpu=2, # 每個(gè)gpu計(jì)算的圖像數(shù)量workers_per_gpu=2, # 每個(gè)gpu分配的線程數(shù)train=dict(type=dataset_type, # 數(shù)據(jù)集類(lèi)型ann_file=data_root + 'annotations/instances_train2017.json', # 數(shù)據(jù)集annotation路徑img_prefix=data_root + 'train2017/', # 數(shù)據(jù)集的圖片路徑img_scale=(1333, 800), # 輸入圖像尺寸,最大邊1333,最小邊800img_norm_cfg=img_norm_cfg, # 圖像初始化參數(shù)size_divisor=32, # 對(duì)圖像進(jìn)行resize時(shí)的最小單位,32表示所有的圖像都會(huì)被resize成32的倍數(shù)flip_ratio=0.5, # 圖像的隨機(jī)左右翻轉(zhuǎn)的概率with_mask=False, # 訓(xùn)練時(shí)附帶maskwith_crowd=True, # 訓(xùn)練時(shí)附帶difficult的樣本with_label=True), # 訓(xùn)練時(shí)附帶labelval=dict(type=dataset_type, # 同上ann_file=data_root + 'annotations/instances_val2017.json', # 同上img_prefix=data_root + 'val2017/', # 同上img_scale=(1333, 800), # 同上img_norm_cfg=img_norm_cfg, # 同上size_divisor=32, # 同上flip_ratio=0, # 同上with_mask=False, # 同上with_crowd=True, # 同上with_label=True), # 同上test=dict(type=dataset_type, # 同上ann_file=data_root + 'annotations/instances_val2017.json', # 同上img_prefix=data_root + 'val2017/', # 同上img_scale=(1333, 800), # 同上img_norm_cfg=img_norm_cfg, # 同上size_divisor=32, # 同上flip_ratio=0, # 同上with_mask=False, # 同上with_label=False, # 同上test_mode=True)) # 同上# optimizeroptimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001) # 優(yōu)化參數(shù),lr為學(xué)習(xí)率,momentum為動(dòng)量因子,weight_decay為權(quán)重衰減因子optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2)) # 梯度均衡參數(shù)# learning policylr_config = dict(policy='step', # 優(yōu)化策略warmup='linear', # 初始的學(xué)習(xí)率增加的策略,linear為線性增加warmup_iters=500, # 在初始的500次迭代中學(xué)習(xí)率逐漸增加warmup_ratio=1.0 / 3, # 起始的學(xué)習(xí)率step=[8, 11]) # 在第8和11個(gè)epoch時(shí)降低學(xué)習(xí)率checkpoint_config = dict(interval=1) # 每1個(gè)epoch存儲(chǔ)一次模型# yapf:disablelog_config = dict(interval=50, # 每50個(gè)batch輸出一次信息hooks=[dict(type='TextLoggerHook'), # 控制臺(tái)輸出信息的風(fēng)格# dict(type='TensorboardLoggerHook')])# yapf:enable# runtime settingstotal_epochs = 12 # 最大epoch數(shù)dist_params = dict(backend='nccl') # 分布式參數(shù)log_level = 'INFO' # 輸出信息的完整度級(jí)別work_dir = './work_dirs/faster_rcnn_r50_fpn_1x' # log文件和模型文件存儲(chǔ)路徑load_from = None # 加載模型的路徑,None表示從預(yù)訓(xùn)練模型加載resume_from = None # 恢復(fù)訓(xùn)練模型的路徑workflow = [('train', 1)] # 當(dāng)前工作區(qū)名稱(chēng)
1.2 cascade_rcnn_r50_fpn_1x.py
# model settingsmodel = dict(type='CascadeRCNN',num_stages=3, # RCNN網(wǎng)絡(luò)的stage數(shù)量,在faster-RCNN中為1pretrained='modelzoo://resnet50',backbone=dict(type='ResNet',depth=50,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,style='pytorch'),neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,num_outs=5),rpn_head=dict(type='RPNHead',in_channels=256,feat_channels=256,anchor_scales=[8],anchor_ratios=[0.5, 1.0, 2.0],anchor_strides=[4, 8, 16, 32, 64],target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0],use_sigmoid_cls=True),bbox_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2),out_channels=256,featmap_strides=[4, 8, 16, 32]),bbox_head=[dict(type='SharedFCBBoxHead',num_fcs=2,in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=81,target_means=[0., 0., 0., 0.],target_stds=[0.1, 0.1, 0.2, 0.2],reg_class_agnostic=True),dict(type='SharedFCBBoxHead',num_fcs=2,in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=81,target_means=[0., 0., 0., 0.],target_stds=[0.05, 0.05, 0.1, 0.1],reg_class_agnostic=True),dict(type='SharedFCBBoxHead',num_fcs=2,in_channels=256,fc_out_channels=1024,roi_feat_size=7,num_classes=81,target_means=[0., 0., 0., 0.],target_stds=[0.033, 0.033, 0.067, 0.067],reg_class_agnostic=True)])# model training and testing settingstrain_cfg = dict(rpn=dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.7,neg_iou_thr=0.3,min_pos_iou=0.3,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=256,pos_fraction=0.5,neg_pos_ub=-1,add_gt_as_proposals=False),allowed_border=0,pos_weight=-1,smoothl1_beta=1 / 9.0,debug=False),rcnn=[ # 注意,這里有3個(gè)RCNN的模塊,對(duì)應(yīng)開(kāi)頭的那個(gè)RCNN的stage數(shù)量dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.5,neg_iou_thr=0.5,min_pos_iou=0.5,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),pos_weight=-1,debug=False),dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.6,neg_iou_thr=0.6,min_pos_iou=0.6,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),pos_weight=-1,debug=False),dict(assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.7,neg_iou_thr=0.7,min_pos_iou=0.7,ignore_iof_thr=-1),sampler=dict(type='RandomSampler',num=512,pos_fraction=0.25,neg_pos_ub=-1,add_gt_as_proposals=True),pos_weight=-1,debug=False)],stage_loss_weights=[1, 0.5, 0.25]) # 3個(gè)RCNN的stage的loss權(quán)重test_cfg = dict(rpn=dict(nms_across_levels=False,nms_pre=2000,nms_post=2000,max_num=2000,nms_thr=0.7,min_bbox_size=0),rcnn=dict(score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=100),keep_all_stages=False) # 是否保留所有stage的結(jié)果# dataset settingsdataset_type = 'CocoDataset'data_root = 'data/coco/'img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)data = dict(imgs_per_gpu=2,workers_per_gpu=2,train=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_train2017.json',img_prefix=data_root + 'train2017/',img_scale=(1333, 800),img_norm_cfg=img_norm_cfg,size_divisor=32,flip_ratio=0.5,with_mask=False,with_crowd=True,with_label=True),val=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_val2017.json',img_prefix=data_root + 'val2017/',img_scale=(1333, 800),img_norm_cfg=img_norm_cfg,size_divisor=32,flip_ratio=0,with_mask=False,with_crowd=True,with_label=True),test=dict(type=dataset_type,ann_file=data_root + 'annotations/instances_val2017.json',img_prefix=data_root + 'val2017/',img_scale=(1333, 800),img_norm_cfg=img_norm_cfg,size_divisor=32,flip_ratio=0,with_mask=False,with_label=False,test_mode=True))# optimizeroptimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict(policy='step',warmup='linear',warmup_iters=500,warmup_ratio=1.0 / 3,step=[8, 11])checkpoint_config = dict(interval=1)# yapf:disablelog_config = dict(interval=50,hooks=[dict(type='TextLoggerHook'),# dict(type='TensorboardLoggerHook')])# yapf:enable# runtime settingstotal_epochs = 12dist_params = dict(backend='nccl')log_level = 'INFO'work_dir = './work_dirs/cascade_rcnn_r50_fpn_1x'load_from = Noneresume_from = Noneworkflow = [('train', 1)]
2.trick部分代碼,cascade_rcnn_r50_fpn_1x.py:
# fp16 settingsfp16 = dict(loss_scale=512.)# model settingsmodel = dict( type='CascadeRCNN', num_stages=3, pretrained='torchvision://resnet50', backbone=dict( type='ResNet', depth=50, num_stages=4, out_indices=(0, 1, 2, 3), frozen_stages=1, style='pytorch', #dcn=dict( #在最后三個(gè)block加入可變形卷積 # modulated=False, deformable_groups=1, fallback_on_stride=False), # stage_with_dcn=(False, True, True, True) ), neck=dict( type='FPN', in_channels=[256, 512, 1024, 2048], out_channels=256, num_outs=5), rpn_head=dict( type='RPNHead', in_channels=256, feat_channels=256, anchor_scales=[8], anchor_ratios=[0.2, 0.5, 1.0, 2.0, 5.0], # 添加了0.2,5,過(guò)兩天發(fā)圖 anchor_strides=[4, 8, 16, 32, 64], target_means=[.0, .0, .0, .0], target_stds=[1.0, 1.0, 1.0, 1.0], loss_cls=dict( type='FocalLoss', use_sigmoid=True, loss_weight=1.0), # 修改了loss,為了調(diào)控難易樣本與正負(fù)樣本比例 loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)), bbox_roi_extractor=dict( type='SingleRoIExtractor', roi_layer=dict(type='RoIAlign', out_size=7, sample_num=2), out_channels=256, featmap_strides=[4, 8, 16, 32]), bbox_head=[ dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=11, target_means=[0., 0., 0., 0.], target_stds=[0.1, 0.1, 0.2, 0.2], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=11, target_means=[0., 0., 0., 0.], target_stds=[0.05, 0.05, 0.1, 0.1], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)), dict( type='SharedFCBBoxHead', num_fcs=2, in_channels=256, fc_out_channels=1024, roi_feat_size=7, num_classes=11, target_means=[0., 0., 0., 0.], target_stds=[0.033, 0.033, 0.067, 0.067], reg_class_agnostic=True, loss_cls=dict( type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0), loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)) ])# model training and testing settingstrain_cfg = dict( rpn=dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.7, neg_iou_thr=0.3, min_pos_iou=0.3, ignore_iof_thr=-1), sampler=dict( type='RandomSampler', num=256, pos_fraction=0.5, neg_pos_ub=-1, add_gt_as_proposals=False), allowed_border=0, pos_weight=-1, debug=False), rpn_proposal=dict( nms_across_levels=False, nms_pre=2000, nms_post=2000, max_num=2000, nms_thr=0.7, min_bbox_size=0), rcnn=[ dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.4, # 更換 neg_iou_thr=0.4, min_pos_iou=0.4, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.5, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', # 解決難易樣本,也解決了正負(fù)樣本比例問(wèn)題。num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False), dict( assigner=dict( type='MaxIoUAssigner', pos_iou_thr=0.6, neg_iou_thr=0.6, min_pos_iou=0.6, ignore_iof_thr=-1), sampler=dict( type='OHEMSampler', num=512, pos_fraction=0.25, neg_pos_ub=-1, add_gt_as_proposals=True), pos_weight=-1, debug=False) ], stage_loss_weights=[1, 0.5, 0.25])test_cfg = dict( rpn=dict( nms_across_levels=False, nms_pre=1000, nms_post=1000, max_num=1000, nms_thr=0.7, min_bbox_size=0), rcnn=dict( score_thr=0.05, nms=dict(type='nms', iou_thr=0.5), max_per_img=20)) # 這里可以換為sof_tnms# dataset settingsdataset_type = 'CocoDataset'data_root = '../../data/chongqing1_round1_train1_20191223/'img_norm_cfg = dict( mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)train_pipeline = [ dict(type='LoadImageFromFile'), dict(type='LoadAnnotations', with_bbox=True), dict(type='Resize', img_scale=(492,658), keep_ratio=True), #這里可以更換多尺度[(),()] dict(type='RandomFlip', flip_ratio=0.5), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),]test_pipeline = [ dict(type='LoadImageFromFile'), dict( type='MultiScaleFlipAug', img_scale=(492,658), flip=False, transforms=[ dict(type='Resize', keep_ratio=True), dict(type='RandomFlip'), dict(type='Normalize', **img_norm_cfg), dict(type='Pad', size_divisor=32), dict(type='ImageToTensor', keys=['img']), dict(type='Collect', keys=['img']), ])]data = dict( imgs_per_gpu=8, # 有的同學(xué)不知道batchsize在哪修改,其實(shí)就是修改這里,每個(gè)gpu同時(shí)處理的images數(shù)目。workers_per_gpu=2, train=dict( type=dataset_type, ann_file=data_root + 'fixed_annotations.json', # 更換自己的json文件 img_prefix=data_root + 'images/', # images目錄 pipeline=train_pipeline), val=dict( type=dataset_type, ann_file=data_root + 'fixed_annotations.json', img_prefix=data_root + 'images/', pipeline=test_pipeline), test=dict( type=dataset_type, ann_file=data_root + 'fixed_annotations.json', img_prefix=data_root + 'images/', pipeline=test_pipeline))# optimizeroptimizer = dict(type='SGD', lr=0.001, momentum=0.9, weight_decay=0.0001) # lr = 0.00125*batch_size,不能過(guò)大,否則梯度爆炸。optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))# learning policylr_config = dict( policy='step', warmup='linear', warmup_iters=500, warmup_ratio=1.0 / 3, step=[6, 12, 19])checkpoint_config = dict(interval=1)# yapf:disablelog_config = dict( interval=64, hooks=[ dict(type='TextLoggerHook'), # 控制臺(tái)輸出信息的風(fēng)格 # dict(type='TensorboardLoggerHook') # 需要安裝tensorflow and tensorboard才可以使用 ])# yapf:enable# runtime settingstotal_epochs = 20dist_params = dict(backend='nccl')log_level = 'INFO'work_dir = '../work_dirs/cascade_rcnn_r50_fpn_1x' # 日志目錄load_from = '../work_dirs/cascade_rcnn_r50_fpn_1x/latest.pth' # 模型加載目錄文件#load_from = '../work_dirs/cascade_rcnn_r50_fpn_1x/cascade_rcnn_r50_coco_pretrained_weights_classes_11.pth'resume_from = Noneworkflow = [('train', 1)]
猜您喜歡:
附下載 | 《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實(shí)戰(zhàn)》
附下載 |《計(jì)算機(jī)視覺(jué)中的數(shù)學(xué)方法》分享
《基于深度學(xué)習(xí)的表面缺陷檢測(cè)方法綜述》
《基于深度神經(jīng)網(wǎng)絡(luò)的少樣本學(xué)習(xí)綜述》