
【機器學(xué)習(xí)】機器學(xué)習(xí)必知概念
公眾號:尤而小屋
作者:Peter
編輯:Peter
本文主要是介紹機器學(xué)習(xí)的一些基本內(nèi)容,包含:
除了分類和回歸之外的其他機器學(xué)習(xí)形式 評估機器學(xué)習(xí)模型的規(guī)范流程 為深度學(xué)習(xí)準備數(shù)據(jù) 特征工程 解決過擬合 處理機器學(xué)習(xí)問題的通用流程

機器學(xué)習(xí)4個分支
監(jiān)督學(xué)習(xí)supervised learning
最常見的機器學(xué)習(xí)類型。給定一組樣本(通常是人工標(biāo)準),它可以學(xué)會將數(shù)據(jù)映射到已知目標(biāo)(也叫標(biāo)注)。監(jiān)督學(xué)習(xí)廣泛應(yīng)用到光學(xué)字符識別、語音識別、圖像分類和語言翻譯。
監(jiān)督學(xué)習(xí)除了回歸和分類,還有其他變體:
序列生成 語法樹預(yù)測 目標(biāo)檢測 圖像分割
無監(jiān)督學(xué)習(xí)
無監(jiān)督學(xué)習(xí)是指在沒有目標(biāo)的情況下尋找輸入數(shù)據(jù)的有趣變換,目的是在于數(shù)據(jù)可視化、數(shù)據(jù)壓縮、數(shù)據(jù)去噪或者更好地理解數(shù)據(jù)中的相關(guān)性。
主要是降維和聚類
自監(jiān)督學(xué)習(xí)是監(jiān)督學(xué)習(xí)的特例。自監(jiān)督學(xué)習(xí)可以看做是沒有人工標(biāo)注的標(biāo)簽的監(jiān)督學(xué)習(xí)。
標(biāo)簽是仍然存在的,但是他們是從輸入數(shù)據(jù)中生成的,通常是使用啟發(fā)式算法生成的。
一個常見的例子就是:自編碼器autoencoder,其目標(biāo)就是未經(jīng)修改的輸入。
給定視頻中過去的幀來預(yù)測下一幀,或者給定文本中前面的詞語來預(yù)測下一個詞語,都是屬于自監(jiān)督學(xué)習(xí)的例子(這兩個例子是時序監(jiān)督學(xué)習(xí)的例子)
強化學(xué)習(xí)
強化學(xué)習(xí)是因為谷歌的DeepMind公司將其成功應(yīng)用于學(xué)習(xí)完Atari游戲(還有圍棋阿爾法狗)中,才開始被廣泛關(guān)注。
在強化學(xué)習(xí)中,智能體agent接收有關(guān)其環(huán)境的信息,并學(xué)會選擇使其某種獎勵最大化的行動。
分類和回歸術(shù)語
總結(jié)一下回歸和分類中常出現(xiàn)的術(shù)語:
樣本、輸入:進入模型的數(shù)據(jù)點 預(yù)測、輸出:從模型出來的結(jié)果 目標(biāo):真實值。對于外部數(shù)據(jù)源,理想狀態(tài)下,模型能夠預(yù)測出真實值 預(yù)測誤差、損失值:預(yù)測值和真實值之間的距離 類別:分類問題中供選擇的一組標(biāo)簽。比如對貓狗圖像進行分類時,貓和狗就是標(biāo)簽 標(biāo)簽:分類問題中類別標(biāo)注的具體例子。比如1234號圖像被標(biāo)注為包含類別狗,那么“狗”就是1234號圖像的標(biāo)簽 真實值和標(biāo)注:數(shù)據(jù)集的所有目標(biāo)。通常是人工收集 二分類:一種分類任務(wù),每個輸入樣本應(yīng)該被劃分到兩個互斥的類別中 多分類:一種分類任務(wù),每個輸入樣本應(yīng)該被劃分到多個不同的類別中,比如手寫數(shù)字分類 多標(biāo)簽分類:一種分類任務(wù),每個輸入樣本都可以分配多個標(biāo)簽。比如一幅圖像中既有貓又有狗,那么應(yīng)該同時標(biāo)注貓標(biāo)簽和狗標(biāo)簽。每幅圖像的標(biāo)簽個數(shù)通常是可變的。 標(biāo)量回歸:目標(biāo)是連續(xù)標(biāo)量值的任務(wù)。比如預(yù)測房價 向量回歸:目標(biāo)是一組連續(xù)值(比如一個連續(xù)變量)的任務(wù)。如果對多個值進行回歸,就是向量回歸 小批量或批量:模型同時處理的一小部分樣本,通常是8-128.樣本數(shù)通常是2的冪,方便CPU上的內(nèi)存分配。訓(xùn)練時,小批量用來為模型權(quán)重計算一次梯度下降更新。
評估機器學(xué)習(xí)的模型
機器學(xué)習(xí)的目的是得到可以泛化的模型:在前所未見的數(shù)據(jù)集上也能夠表現(xiàn)的很好,而過擬合則是核心難點。
3大數(shù)據(jù)集
評估模型的重點是將數(shù)據(jù)劃分為:訓(xùn)練集、驗證集和測試集
訓(xùn)練集:訓(xùn)練模型 驗證集:評估模型 測試集:最后一次的測試
模型一定不能讀取與測試集任何相關(guān)的信息,即使是間接讀取也不行。3大經(jīng)典評估方法:
簡單的留出驗證 K折驗證 帶有打亂數(shù)據(jù)的重復(fù)K折驗證
3大評估方法
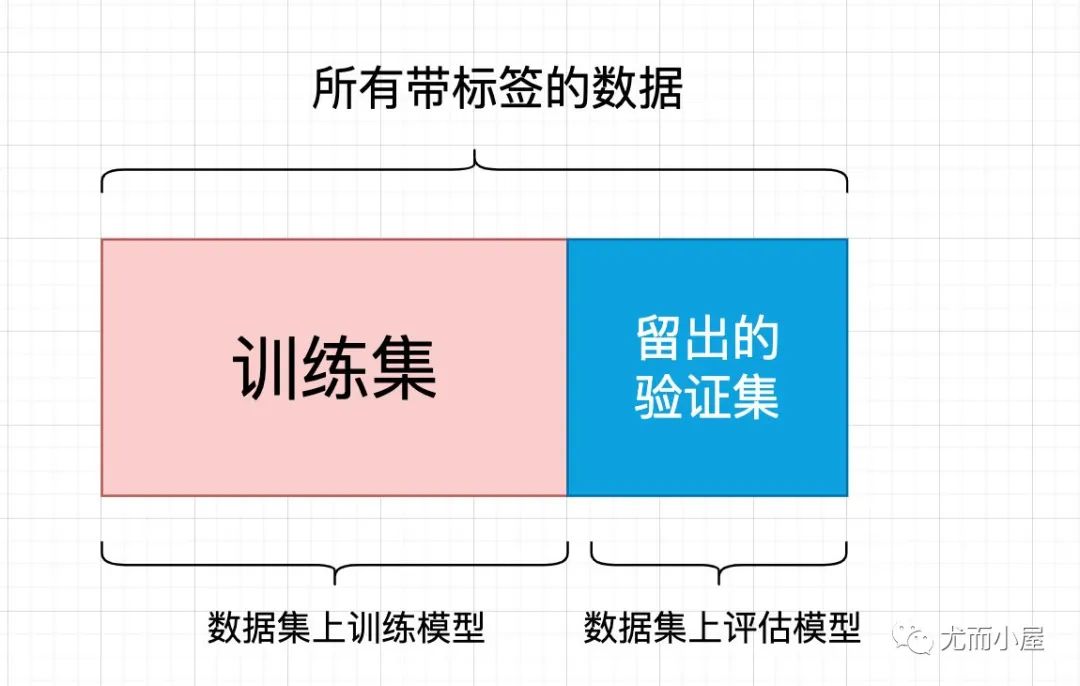
簡單的留出驗證(hold-out validation)
留出一定的比例的數(shù)據(jù)作為測試集,在剩余的數(shù)據(jù)集上訓(xùn)練數(shù)據(jù),然后在測試集上評估模型。
為了防止信息泄露,我們不能基于測試集來調(diào)節(jié)模型,必須保留一個驗證集。
#?代碼實現(xiàn)
num_validation_samples?=?10000
#?打亂數(shù)據(jù)
np.random.shuffle(data)
validation_data?=?data[:num_validation_samples]??#?驗證集
data?=?data[num_validation_samples:]??
train_data?=?data???#?訓(xùn)練集
model?=?get_model()
model.train(train_data)??#?訓(xùn)練集訓(xùn)練模型
validation_score?=?model.evaluate(validation_data)??#?驗證集上評估模型
#?調(diào)節(jié)模型、重新訓(xùn)練、評估,然后再次調(diào)節(jié),最后在測試集上評估
model?=?get_model()
#?將訓(xùn)練集和驗證合并起來進行重新訓(xùn)練
model.train(np.concatenate([train_data,validation_data]))
#?測試集上進行評估
test_score?=?model.evaluate(test_data)
一個缺點:如果可用的數(shù)據(jù)很少,可能驗證集和測試集包含的樣本很少,從而無法從統(tǒng)計學(xué)上代表數(shù)據(jù)。
因此就有了K折驗證和重復(fù)的K折驗證來解決這個問題。
K折驗證
使用K折交叉驗證的基本原理:
將數(shù)據(jù)劃分為K個分區(qū),通常是4或者5 實例化K個模型,將模型在K-1個分區(qū)上訓(xùn)練,剩下的一個區(qū)上進行評估 模型的驗證分數(shù)等于K個驗證分數(shù)的均值。
如何K折交叉驗證:以3折交叉驗證為例

#?代碼實現(xiàn)
k?=?4
num_validation_samples?=?len(data)?//?k
#?隨機打亂數(shù)據(jù)
np.random.shuffle(data)
validation_scores?=?[]
for?fold?in?range(k):
????#?驗證集
????validation_data?=?data[fold?*?num_validation_samples:?(fold?+?1)?*?num_validation_samples]
????#?訓(xùn)練集
????train_data?=?data[:?fold?*?num_validation_samples]?+?data[(fold?+?1)?*?num_validation_samples:]
????model?=?get_model()
????model.train(train_data)
????validation_score?=?model.evaluate(validation_data)??#?每個驗證集上的得分
????validation_scores.append(validation_score)??#?放到列表中
validation_score?=?np.average(validation_scores)??#?K折驗證的均值
model?=?get_model()
model.train(data)??#?data?=?train_data?+?validation_data??所有非測試集上進行訓(xùn)練
test_score?=?model.evaluate(test_data)??#??測試集上進行評估
帶有打亂數(shù)據(jù)的K折驗證
如果數(shù)據(jù)很少,又想精確地評估模型,可以使用打亂數(shù)據(jù)的K折交叉驗證:iterated K-fold validation with shuffling。
具體做法:在每次將數(shù)據(jù)劃分為k個分區(qū)之前,先將數(shù)據(jù)打亂,最終分數(shù)是每個K折驗證分數(shù)的均值
注意:這個做法一共要訓(xùn)練和評估P*K個模型,P是重復(fù)次數(shù),計算代價很大。
評估模型的注意事項
數(shù)據(jù)代表性:隨機打亂數(shù)據(jù) 時間箭頭:如果想根據(jù)過去預(yù)測未來,即針對所謂的時間序列的數(shù)據(jù),則不應(yīng)該隨機打亂數(shù)據(jù),這樣會造成時間泄露 數(shù)據(jù)冗余:確保訓(xùn)練集和驗證集之間沒有交集
數(shù)據(jù)預(yù)處理、特征工程和特征學(xué)習(xí)
預(yù)處理
預(yù)處理的主要步驟:
向量化 標(biāo)準化 處理缺失值 特征提取
向量化
神經(jīng)網(wǎng)絡(luò)的所有輸入和輸出都必須是浮點張量。都必須轉(zhuǎn)成張量,這一步叫做向量化data vectorization
值標(biāo)準化
數(shù)據(jù)輸入網(wǎng)絡(luò)前,對每個特征分別做標(biāo)準化,使其均值為0,標(biāo)準差為1。
輸入神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)應(yīng)該具有以下特征:
取值較小:大部分取值在0-1范圍內(nèi) 同質(zhì)性(homogenous):所有特征的取值范圍都在大致相同的范圍內(nèi)
Numpy實現(xiàn)的標(biāo)準化過程:
X?-=?X.mean(axis=0)??#?假定X是個二維矩陣
X?-=?X.std(axis=0)
缺失值處理
在神經(jīng)網(wǎng)絡(luò)中,一般將缺失值用0填充。
特征工程
根據(jù)已有的知識對數(shù)據(jù)進行編碼的轉(zhuǎn)換,以改善模型的效果。
特征工程的本質(zhì):用更簡單的方式表述問題,從而使得問題變得更容易。
現(xiàn)在大部分的深度學(xué)習(xí)是不需要特征工程的,因為神經(jīng)網(wǎng)絡(luò)能夠從原始數(shù)據(jù)中自動提取有用的特征。

解決過擬合
什么是過擬合和欠擬合
機器學(xué)習(xí)的根本問題是優(yōu)化和泛化的對立。
優(yōu)化:調(diào)節(jié)模型以在訓(xùn)練集上得到最佳性能;泛化:訓(xùn)練好的模型在未知數(shù)據(jù)上的性能好壞。
過擬合overfit:模型在訓(xùn)練集上表現(xiàn)良好,但是在測試集上表現(xiàn)不好。過擬合存在所有的機器學(xué)習(xí)問題中。 欠擬合underfit:訓(xùn)練數(shù)據(jù)上的損失越小,測試數(shù)據(jù)上的數(shù)據(jù)損失也越小。
過擬合和欠擬合的產(chǎn)生
1、欠擬合問題,根本的原因是特征維度過少,導(dǎo)致擬合的函數(shù)無法滿足訓(xùn)練集,誤差較大。
解決方法:欠擬合問題可以通過增加特征維度來解決。
2、過擬合問題,根本的原因則是特征維度過多,導(dǎo)致擬合的函數(shù)完美的經(jīng)過訓(xùn)練集,但是對新數(shù)據(jù)的預(yù)測結(jié)果則較差。解決過擬合問題,則有2個途徑:
減少特征維度;可以人工選擇保留的特征,或者模型選擇算法 正則化;保留所有的特征,通過降低參數(shù)θ的值,來影響模型
3招解決過擬合
減小網(wǎng)絡(luò)大小
防止過擬合最簡單的方案:減小模型大小,即減少模型中學(xué)習(xí)參數(shù)的個數(shù)(層數(shù)和每層的單元個數(shù)決定)。
容量:在深度學(xué)習(xí)中,模型中可學(xué)習(xí)參數(shù)的個數(shù)稱之為容量。
使用的模型必須具有足夠多的參數(shù),以防止過擬合,即模型應(yīng)該避免記憶資源不足。
#?電影評論分類的原網(wǎng)絡(luò)
import?tensorflow?as?tf??#?add
import?keras?as?models
import?keras?as?layers
model?=?models.Sequential()
model.add(tf.keras.Dense(16,?activation="relu",input_shape=(10000,?)))
model.add(tf.keras.Dense(16,?activation="relu"))
model.add(tf.keras.Dense(1,?activation="sigmoid"))
用一個更小的網(wǎng)絡(luò)來替代:
model?=?models.Sequential()
model.add(tf.keras.Dense(4,?activation="relu",input_shape=(10000,?)))
model.add(tf.keras.Dense(4,?activation="relu"))
model.add(tf.keras.Dense(1,?activation="sigmoid"))
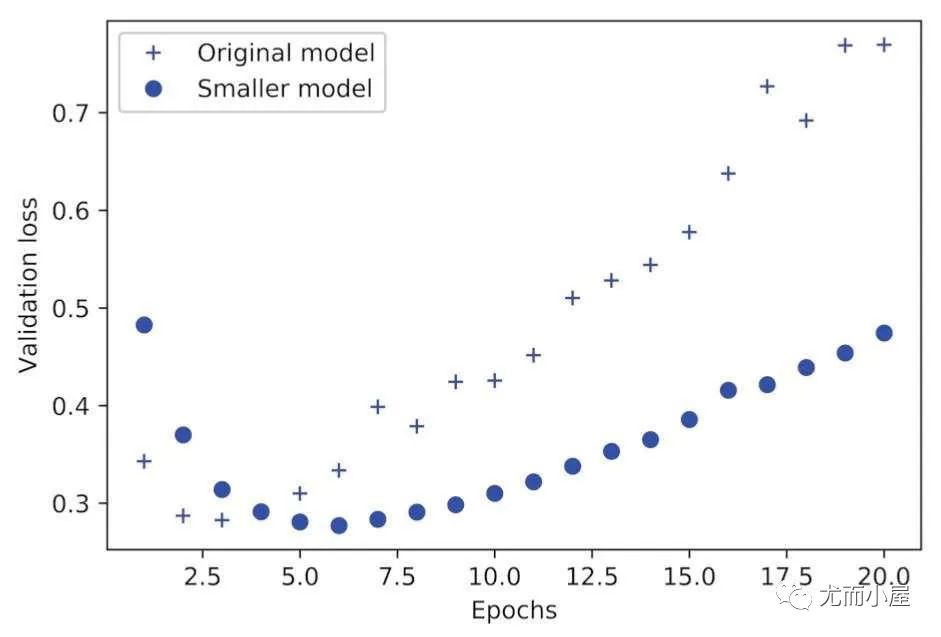
我們發(fā)現(xiàn):更小的網(wǎng)絡(luò)開始過擬合的時間要晚于之前的網(wǎng)絡(luò);而且小網(wǎng)絡(luò)的性能變差的速度也更慢。
換成更大的模型:
model?=?models.Sequential()
model.add(tf.keras.Dense(512,?activation="relu",input_shape=(10000,?)))
model.add(tf.keras.Dense(512,?activation="relu"))
model.add(tf.keras.Dense(1,?activation="sigmoid"))
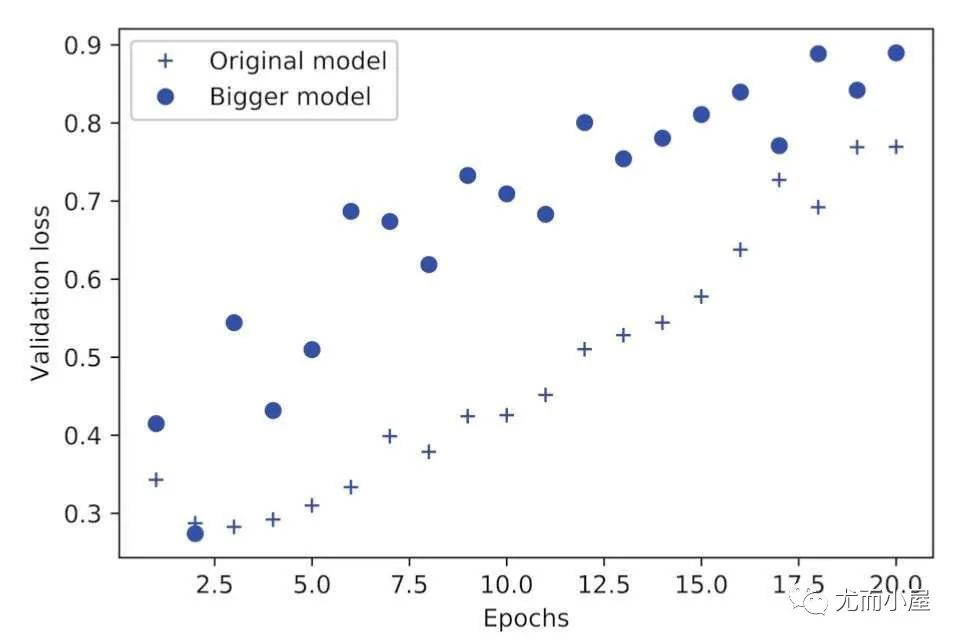
網(wǎng)絡(luò)的容量越大,擬合訓(xùn)練數(shù)據(jù)的速度也越快,更容易過擬合。
添加權(quán)重正則化(最佳)
奧卡姆剃刀(Occams razor) 原理:如果一件事有兩種解釋,那么最可能正確的就是最簡單的那個,即假設(shè)更少的那個。
權(quán)重正則化:強制讓模型權(quán)重只能取較小的值,從而限制模型的復(fù)雜度,使得權(quán)重的分布更加規(guī)則regular。其實現(xiàn)方法:向網(wǎng)絡(luò)損失函數(shù)中添加與較大權(quán)重值相關(guān)的成本。
具體兩種方式:
L1正則化:權(quán)重系數(shù)的絕對值;L1范數(shù) L2正則化:權(quán)重系數(shù)的平方;L2范數(shù)
神經(jīng)網(wǎng)絡(luò)中的L2正則化也叫做權(quán)重衰減weight decay。
Keras中添加權(quán)重正則化的方法是向?qū)觽鬟f:權(quán)重正則化實例 作為關(guān)鍵字參數(shù),以添加L2權(quán)重正則化為例:
from?keras?import?regularizers
model?=?models.Sequential()
model.add(tf.keras.layers.Dense(16,kernel_regularizer=regularizers.l2(0.001),
???????????????????????????????activation="relu",
???????????????????????????????input_shape=(10000,)))
model.add(tf.keras.layers.Dense(16,kernel_regularizer=regularizers.l2(0.001),
???????????????????????????????activation="relu"))
model.add(tf.keras.layers.Dense(1,activation="sigmoid"))
l2(0.001)的意思是該層權(quán)重矩陣的每個系數(shù)都會使網(wǎng)絡(luò)總損失增加0.001*weight_coeffient_value
由于這個懲罰項只在訓(xùn)練時添加,所以網(wǎng)絡(luò)的訓(xùn)練損失會比測試損失大的多
添加L2正則項前后對比:

其他權(quán)重正則化的添加方式:
from?keras?import?regularizers
regularizers.l1(0.001)??#?l1正則化
regularizers.l1_l2(l1=0.001,?l2=0.001)??#?同時添加
添加dropout正則化
dropout是神經(jīng)網(wǎng)絡(luò)中最有效也是最常用的正則化方式之一,做法:在訓(xùn)練過程中隨機將該層的一些輸入特征舍棄(設(shè)置為0)
dropout的比例就是被設(shè)置為0的特征所占的比例,通常在0.2-0.5之間。添加dropout的具體過程:
model.add(tf.keras.layers.Dropout(0.5))
要應(yīng)用在前面一層的輸出
model?=?models.Sequential()
model.add(tf.keras.layers.Dense(16,activation="relu",input_shape=(10000,)))
model.add(tf.keras.layers.Dropout(0.5))??#?添加
model.add(tf.keras.layers.Dense(16,activation="relu"))
model.add(tf.keras.layers.Dropout(0.5))??#?添加
model.add(tf.keras.layers.Dense(1,activation="sigmoid"))
總結(jié)
防止神經(jīng)網(wǎng)絡(luò)過擬合的方法:
獲取更多的訓(xùn)練數(shù)據(jù) 減小網(wǎng)絡(luò)容量 添加權(quán)重正則化 添加dropout
機器學(xué)習(xí)的通用工作流程
問題定義、收集數(shù)據(jù) 選擇衡量成功的標(biāo)準 平衡分類問題:精度和接受者操作特征曲線下面積-ROC/AUC 分類不平衡問題:準確率和召回率 確定評估方法 留出驗證集 K折交叉驗證 重復(fù)的K折交叉驗證 準備數(shù)據(jù) 數(shù)據(jù)轉(zhuǎn)成張量 取值縮放到0-1之間 數(shù)據(jù)標(biāo)準化 特征工程 開發(fā)比基準更好的模型

擴發(fā)模型規(guī)模:開發(fā)過擬合的模型
機器學(xué)習(xí)中無處不在的對立是優(yōu)化和泛化的對立,理想的模型是剛好在欠擬合和過擬合的邊界上,在容量不足和容量過大的邊界上。
為了弄清楚我們需要多大的模型,就必須開發(fā)一個過擬合的模型:
添加更多的層 讓每一層變的更大 訓(xùn)練更多的輪次
在訓(xùn)練的過程中始終監(jiān)控訓(xùn)練損失和驗證損失,以及我們關(guān)心的指標(biāo)。
模型正則化和調(diào)節(jié)參數(shù)
添加dropout 嘗試增加或者減少層數(shù) 添加L1或者L2正則化項 嘗試不同的超參數(shù) 反復(fù)做特征工程
往期精彩回顧