
YOLOv5理論詳解+Pytorch源碼解析
文章目錄
先放官網(wǎng)大圖 (在這里我有個(gè)疑問哈,這張大圖來源于github源碼,但是圖片顯示的是yolov4(放大這張圖),不知道是不是一個(gè)彩蛋呢哈哈~) ios可以下載APP-iDetection,可以玩起來,但是里面也顯示的是yolov4(手動(dòng)狗頭)  YOLOv5官方Pytorch實(shí)現(xiàn):再放干貨:YOLOv5的所有權(quán)重:鏈接:提取碼:w8jq 先放張網(wǎng)絡(luò)結(jié)構(gòu)圖吧,不得不說總結(jié)的非常好(與代碼的網(wǎng)絡(luò)結(jié)構(gòu)基本一樣,只有一些細(xì)節(jié)需要自己發(fā)現(xiàn),但無(wú)傷大雅)~圖來自知乎大神江大白——鏈接:?
YOLOv5官方Pytorch實(shí)現(xiàn):再放干貨:YOLOv5的所有權(quán)重:鏈接:提取碼:w8jq 先放張網(wǎng)絡(luò)結(jié)構(gòu)圖吧,不得不說總結(jié)的非常好(與代碼的網(wǎng)絡(luò)結(jié)構(gòu)基本一樣,只有一些細(xì)節(jié)需要自己發(fā)現(xiàn),但無(wú)傷大雅)~圖來自知乎大神江大白——鏈接:?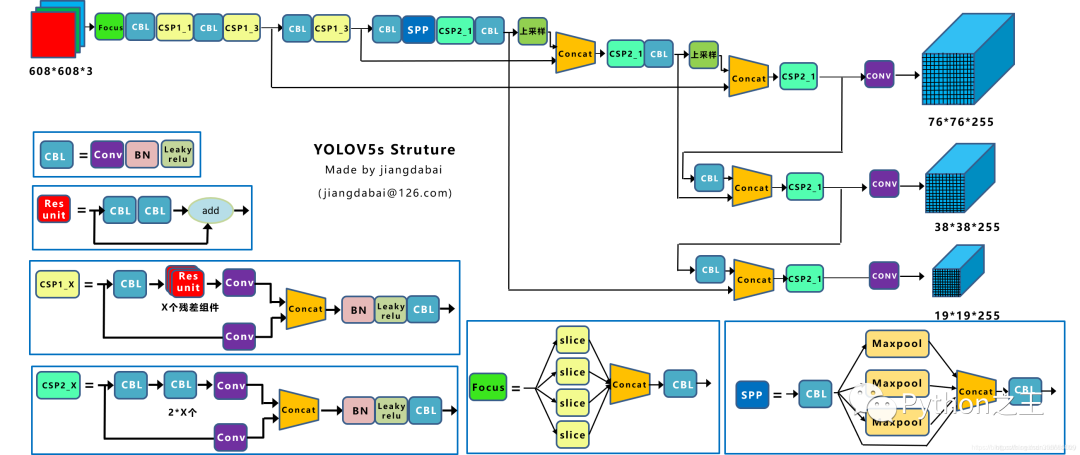
一、前言——從YOLOv3到Y(jié)OLOv5
YOLOv3 YOLO原項(xiàng)目darknet(官方)截止2020年5月31日,并沒有更新添加這個(gè)"YOLOv5"的鏈接。最新的一次update還是上個(gè)月YOLOv4重磅出爐的那次,官方正式添加了YOLOv4項(xiàng)目鏈接。
"YOLOv5"的項(xiàng)目團(tuán)隊(duì)是Ultralytics LLC 公司,很多人應(yīng)該沒有聽過這家公司。但提到他們公司的一個(gè)項(xiàng)目,很多人應(yīng)該就知道了,因?yàn)椴簧偻瑢W(xué)用過。那就是基于PyTorch復(fù)現(xiàn)的YOLOv3,按目前github上star數(shù)來看,應(yīng)該是基于PyTorch復(fù)現(xiàn)YOLOv3中的排名第一。Amusi 之前還分享過此項(xiàng)目。
附上Pytorch版的YOLOv3:
他們復(fù)現(xiàn)的YOLOv3版而且還有APP版本 YOLOv3 in PyTorch > ONNX > CoreML > iOS  其實(shí)這個(gè)公司團(tuán)隊(duì)在YOLOv3上花的功夫蠻多的,不僅有APP版,還對(duì)YOLOv3進(jìn)行了改進(jìn),官方介紹的性能效果可以說相當(dāng)炸裂!另外項(xiàng)目維護(hù)的也很牛逼,star數(shù)已達(dá)4.7 k,commits 都快逼近2500次!
其實(shí)這個(gè)公司團(tuán)隊(duì)在YOLOv3上花的功夫蠻多的,不僅有APP版,還對(duì)YOLOv3進(jìn)行了改進(jìn),官方介紹的性能效果可以說相當(dāng)炸裂!另外項(xiàng)目維護(hù)的也很牛逼,star數(shù)已達(dá)4.7 k,commits 都快逼近2500次!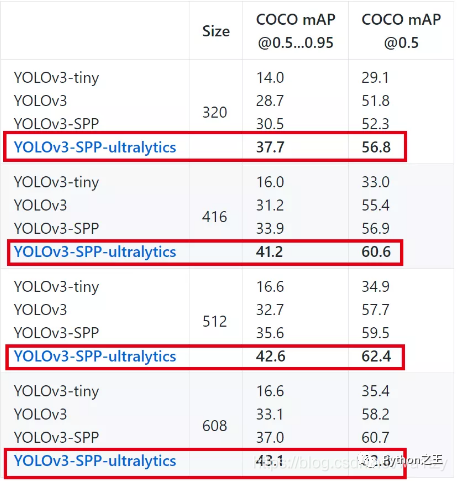 可見Ultralytics LLC 公司在YOLO社區(qū)上的貢獻(xiàn)還是有一定影響力的,這也是為什么他們剛推出"YOLOv5",就得到不少人的關(guān)注。
可見Ultralytics LLC 公司在YOLO社區(qū)上的貢獻(xiàn)還是有一定影響力的,這也是為什么他們剛推出"YOLOv5",就得到不少人的關(guān)注。
YOLOv5 據(jù)官方稱:“YOLOv5” 實(shí)際上還處于開發(fā)的階段,預(yù)計(jì)2020年第2季度/第3季度將全部開發(fā)完成。目前放出來的版本,是集成了YOLOv3-SPP和YOLOv4部分特性。
那么"YOLOv5"的性能有多強(qiáng)呢,Ultralytics LLC給出的數(shù)據(jù)如下:這里說一下,YOLOv5-x的性能已經(jīng)達(dá)到:47.2 AP / 63 FPS,但項(xiàng)目是在 image size = 736的情況下測(cè)得。但Ultralytics LLC并沒有給出"YOLOv5"的算法介紹(論文、博客其實(shí)都沒有看到),所以我們只能通過代碼查看"YOLOv5"的特性。只能說現(xiàn)在版本的"YOLOv5"集成了YOLOv3-SPP和YOLOv4的部分特性等。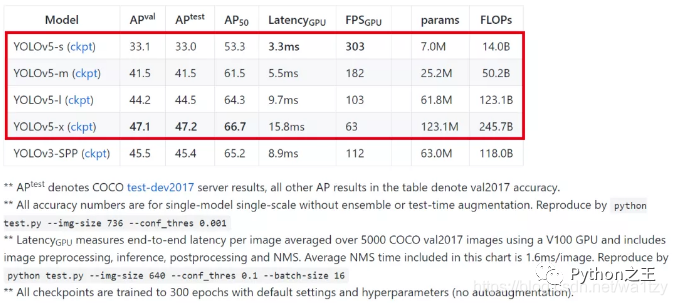
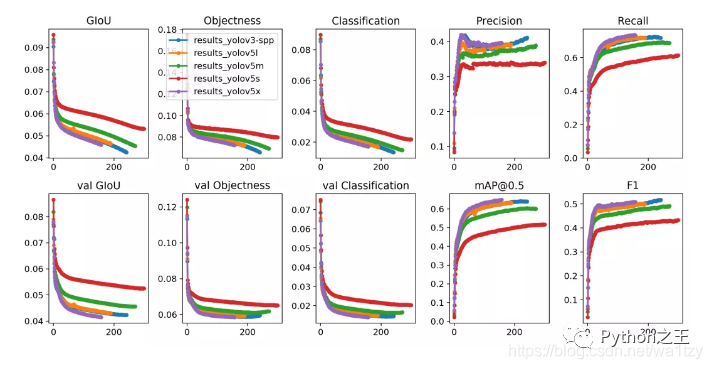
二、代碼解析
代碼目錄
2.1 運(yùn)行起來項(xiàng)目 detect.py
代碼目錄: 1)拿到y(tǒng)olov5的代碼,我們首先要把項(xiàng)目運(yùn)行起來。在這里我們需要下載得到權(quán)重,在這里我下載了yolov5s.pt文件,把其放到weights文件夾下;然后找到detect.py運(yùn)行,inference文件下推理得到output文件夾:
1)拿到y(tǒng)olov5的代碼,我們首先要把項(xiàng)目運(yùn)行起來。在這里我們需要下載得到權(quán)重,在這里我下載了yolov5s.pt文件,把其放到weights文件夾下;然后找到detect.py運(yùn)行,inference文件下推理得到output文件夾: 這樣我們的第一步項(xiàng)目就跑通了,這是我們拿到源碼首先要完成的任務(wù)。
這樣我們的第一步項(xiàng)目就跑通了,這是我們拿到源碼首先要完成的任務(wù)。
2.2 網(wǎng)絡(luò)結(jié)構(gòu) models/yolo.py
根據(jù)配置文件,models文件夾下選擇yolov5s.yaml(根據(jù)選擇的權(quán)重觀察),在yolo.py文件里運(yùn)行下面代碼,使用netron可視化網(wǎng)絡(luò)結(jié)構(gòu)。(關(guān)于netron模型可視化,我們只需要在命令行安裝pip install netron即可,然后進(jìn)入netron,復(fù)制地址進(jìn)入,打包我們需要的模型,即可使用可視化。這個(gè)工具有助于我們分析網(wǎng)絡(luò)的整體架構(gòu))
model?=?Model(opt.cfg).to(device)
torch.save(model,"m.pt")
 這個(gè)結(jié)構(gòu)看起來比較簡(jiǎn)單,我們用torch.jit導(dǎo)出jit格式來看模型詳細(xì)架構(gòu),運(yùn)行以下代碼:
這個(gè)結(jié)構(gòu)看起來比較簡(jiǎn)單,我們用torch.jit導(dǎo)出jit格式來看模型詳細(xì)架構(gòu),運(yùn)行以下代碼:
?#?Create?model
????model?=?Model(opt.cfg).to(device)
????x?=?torch.randn(1,3,384,640)
????script_models?=?torch.jit.trace(model,x)
????script_models.save("m.jit")
導(dǎo)出m.jit格式后,將其重命名為m1.pt,再進(jìn)行netron可視化分析,這里由于圖片較長(zhǎng),我就展示一部分了。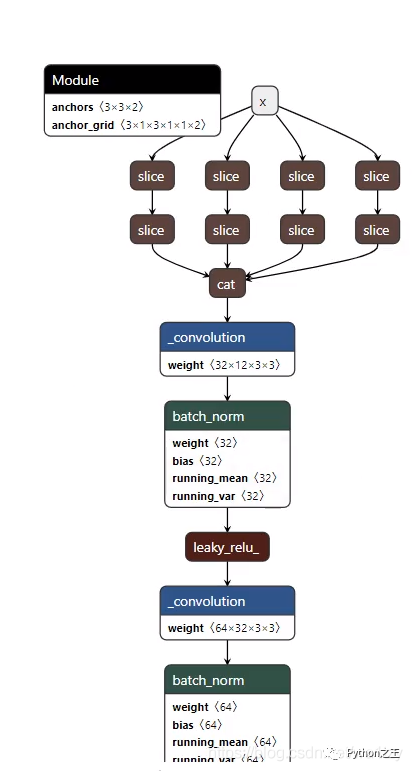
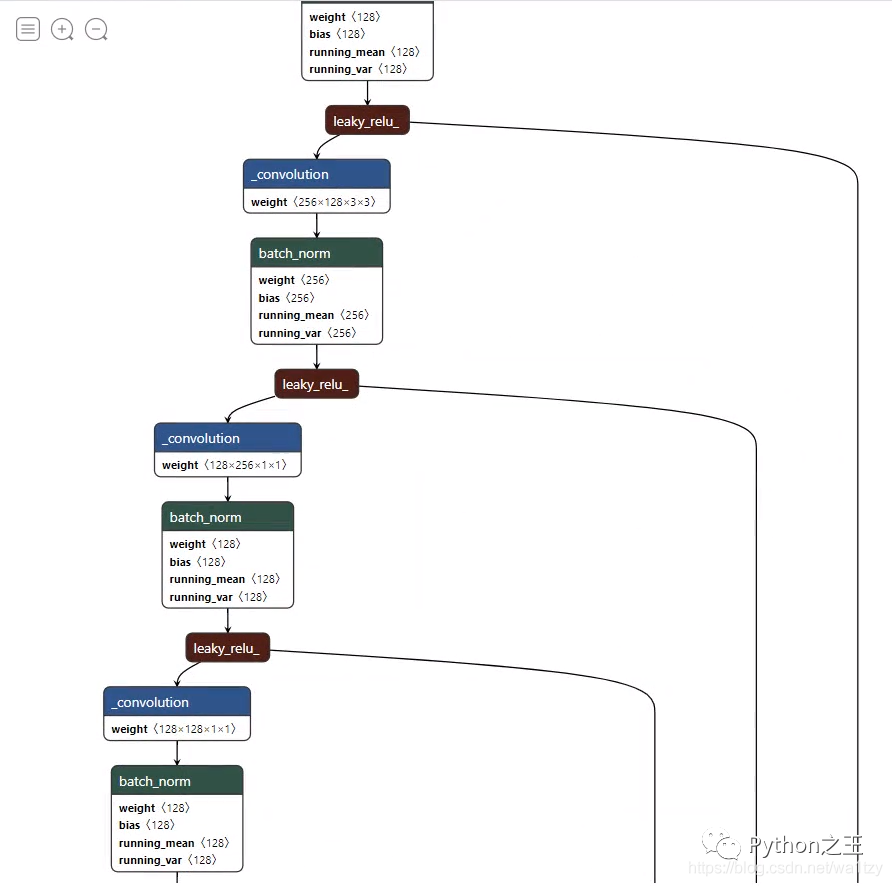
2.3 配置文件 yolov5s.yaml
#?parameters
nc:?80??#?number?of?classes
depth_multiple:?0.33??#?model?depth?multiple
width_multiple:?0.50??#?layer?channel?multiple
#?anchors
anchors:
??-?[116,90,?156,198,?373,326]??#?P5/32
??-?[30,61,?62,45,?59,119]??#?P4/16
??-?[10,13,?16,30,?33,23]??#?P3/8
#?YOLOv5?backbone
backbone:
??#?[from,?number,?module,?args]
??[[-1,?1,?Focus,?[64,?3]],??#?0-P1/2
???[-1,?1,?Conv,?[128,?3,?2]],??#?1-P2/4
???[-1,?3,?BottleneckCSP,?[128]],
???[-1,?1,?Conv,?[256,?3,?2]],??#?3-P3/8
???[-1,?9,?BottleneckCSP,?[256]],
???[-1,?1,?Conv,?[512,?3,?2]],??#?5-P4/16
???[-1,?9,?BottleneckCSP,?[512]],
???[-1,?1,?Conv,?[1024,?3,?2]],?#?7-P5/32
???[-1,?1,?SPP,?[1024,?[5,?9,?13]]],
??]
#?YOLOv5?head
head:
??[[-1,?3,?BottleneckCSP,?[1024,?False]],??#?9
???[-1,?1,?Conv,?[512,?1,?1]],
???[-1,?1,?nn.Upsample,?[None,?2,?'nearest']],
???[[-1,?6],?1,?Concat,?[1]],??#?cat?backbone?P4
???[-1,?3,?BottleneckCSP,?[512,?False]],??#?13
???[-1,?1,?Conv,?[256,?1,?1]],
???[-1,?1,?nn.Upsample,?[None,?2,?'nearest']],
???[[-1,?4],?1,?Concat,?[1]],??#?cat?backbone?P3
???[-1,?3,?BottleneckCSP,?[256,?False]],
???[-1,?1,?nn.Conv2d,?[na?*?(nc?+?5),?1,?1]],??#?18?(P3/8-small)
???[-2,?1,?Conv,?[256,?3,?2]],
???[[-1,?14],?1,?Concat,?[1]],??#?cat?head?P4
???[-1,?3,?BottleneckCSP,?[512,?False]],
???[-1,?1,?nn.Conv2d,?[na?*?(nc?+?5),?1,?1]],??#?22?(P4/16-medium)
???[-2,?1,?Conv,?[512,?3,?2]],
???[[-1,?10],?1,?Concat,?[1]],??#?cat?head?P5
???[-1,?3,?BottleneckCSP,?[1024,?False]],
???[-1,?1,?nn.Conv2d,?[na?*?(nc?+?5),?1,?1]],??#?26?(P5/32-large)
???[[],?1,?Detect,?[nc,?anchors]],??#?Detect(P5,?P4,?P3)
??]
解析:[-1, 1, Focus, [64, 3]] , [[-1, 6], 1, Concat, [1]]
① -1代表動(dòng)態(tài)計(jì)算上一層的通道數(shù)(-2代表計(jì)算上兩層的通道數(shù)),設(shè)計(jì)的原因是一層一層下來的,但存在殘差路由結(jié)構(gòu);[-1,6]代表把上一層與第六層cat起來。
② [64,3]:網(wǎng)絡(luò)第一層輸出是32個(gè)通道(把模型打印出來可以看到),但這里是64,這就與采樣率有關(guān):64乘以width_multiple=32,與網(wǎng)絡(luò)第一層輸出一致。3代表這一層復(fù)制3次,3乘以depth_multiple等于1,即1層。最少也要有1層。
width_multiple: 0.50這個(gè)參數(shù)與網(wǎng)絡(luò)設(shè)計(jì)有關(guān),現(xiàn)在設(shè)計(jì)網(wǎng)絡(luò)一般都不設(shè)計(jì)一個(gè)網(wǎng)絡(luò),如yolov3-tiny,yolov3-darknet53,yolov3-spp,但都是單獨(dú)設(shè)計(jì),不太好;如果我們?cè)O(shè)計(jì)幾種網(wǎng)絡(luò),一般設(shè)計(jì)常規(guī)網(wǎng)絡(luò)(不大不小),進(jìn)行訓(xùn)練,效果不錯(cuò)我們?cè)龠M(jìn)行縮放,包含深度縮放depth_multiple和寬度縮放width_multiple(通道數(shù)),這樣的網(wǎng)絡(luò)被證明效果是不錯(cuò)的,所以可以得到n個(gè)網(wǎng)絡(luò),減輕了設(shè)計(jì)負(fù)擔(dān)。
縮放規(guī)則:r^2βw<2,r(分辨率)β(深度即層數(shù))w(通道數(shù)),希望網(wǎng)絡(luò)的這些參數(shù)變大1倍,但計(jì)算量小于2。
2.4 網(wǎng)絡(luò)子結(jié)構(gòu) models/common.py
這部分我們需要根據(jù) yolov5s.yaml 配置文件查看主干網(wǎng)backbone和偵測(cè)網(wǎng)head查看不同的子結(jié)構(gòu)。
2.4.1 Conv與Focus
class?Conv(nn.Module):#?自定義卷積塊:卷積_BN_激活。類比yolov4里的CBL結(jié)構(gòu)
????#?Standard?convolution
????def?__init__(self,?c1,?c2,?k=1,?s=1,?g=1,?act=True):??#?ch_in,?ch_out,?kernel,?stride,?groups
????????super(Conv,?self).__init__()
????????p?=?k?//?2?if?isinstance(k,?int)?else?[x?//?2?for?x?in?k]??#?padding
????????self.conv?=?nn.Conv2d(c1,?c2,?k,?s,?p,?groups=g,?bias=False)
????????self.bn?=?nn.BatchNorm2d(c2)
????????self.act?=?nn.LeakyReLU(0.1,?inplace=True)?if?act?else?nn.Identity()
????????
??def?forward(self,?x):
????????return?self.act(self.bn(self.conv(x)))
????def?fuseforward(self,?x):
????????return?self.act(self.conv(x))
????????
class?Focus(nn.Module):# Focus模塊:將W、H信息集中到通道空間
????#?Focus?wh?information?into?c-space
????def?__init__(self,?c1,?c2,?k=1):
????????super(Focus,?self).__init__()
????????self.conv?=?Conv(c1?*?4,?c2,?k,?1)
????def?forward(self,?x):??#?x(b,c,w,h)?->?y(b,4c,w/2,h/2)
????????return?self.conv(torch.cat([x[...,?::2,?::2],?x[...,?1::2,?::2],?x[...,?::2,?1::2],?x[...,?1::2,?1::2]],?1))
Focus模塊,輸入通道擴(kuò)充了4倍,作用是可以使信息不丟失的情況下提高計(jì)算力。具體操作為把一張圖片每隔一個(gè)像素拿到一個(gè)值,類似于鄰近下采樣,這樣我們就拿到了4張圖,4張圖片互補(bǔ),長(zhǎng)的差不多,但信息沒有丟失,拼接起來相當(dāng)于RGB模式下變?yōu)?2個(gè)通道,通道多少對(duì)計(jì)算量影響不大,但圖像縮小,大大減少了計(jì)算量。可以當(dāng)成下圖理解:
2.4.2 Bottleneck與BottleneckCSP
class?BottleneckCSP(nn.Module):
????#?CSP?Bottleneck?https://github.com/WongKinYiu/CrossStagePartialNetworks
????def?__init__(self,?c1,?c2,?n=1,?shortcut=True,?g=1,?e=0.5):??#?ch_in,?ch_out,?number,?shortcut,?groups,?expansion
????????super(BottleneckCSP,?self).__init__()
????????c_?=?int(c2?*?e)??#?hidden?channels
????????self.cv1?=?Conv(c1,?c_,?1,?1)
????????self.cv2?=?nn.Conv2d(c1,?c_,?1,?1,?bias=False)
????????self.cv3?=?nn.Conv2d(c_,?c_,?1,?1,?bias=False)
????????self.cv4?=?Conv(c2,?c2,?1,?1)
????????self.bn?=?nn.BatchNorm2d(2?*?c_)??#?applied?to?cat(cv2,?cv3)
????????self.act?=?nn.LeakyReLU(0.1,?inplace=True)
????????self.m?=?nn.Sequential(*[Bottleneck(c_,?c_,?shortcut,?g,?e=1.0)?for?_?in?range(n)])
????def?forward(self,?x):
????????y1?=?self.cv3(self.m(self.cv1(x)))
????????y2?=?self.cv2(x)
????????return?self.cv4(self.act(self.bn(torch.cat((y1,?y2),?dim=1))))
在這里我們可以畫出其網(wǎng)絡(luò)結(jié)構(gòu)圖如下圖所示,其實(shí)我們還可以類比YOLOv4的子結(jié)構(gòu),我們發(fā)現(xiàn)其實(shí)他們大概類似,只不過YOLOv4第一個(gè)是CBM結(jié)構(gòu),其他的CBM結(jié)構(gòu)換成了卷積,這也解釋了我在前一篇博文提到的CBM結(jié)構(gòu)換卷積會(huì)有更好的效果,有興趣可以跳到這篇博文。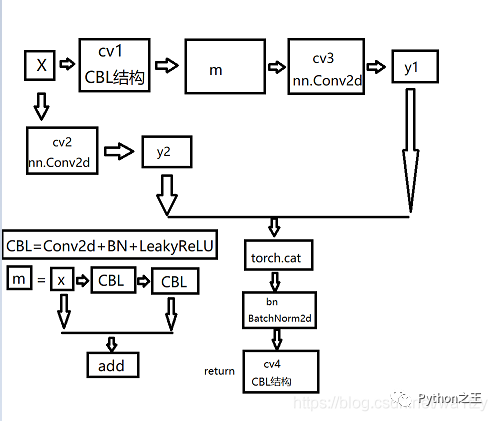 下圖為YOLOv4這部分的子結(jié)構(gòu)圖:
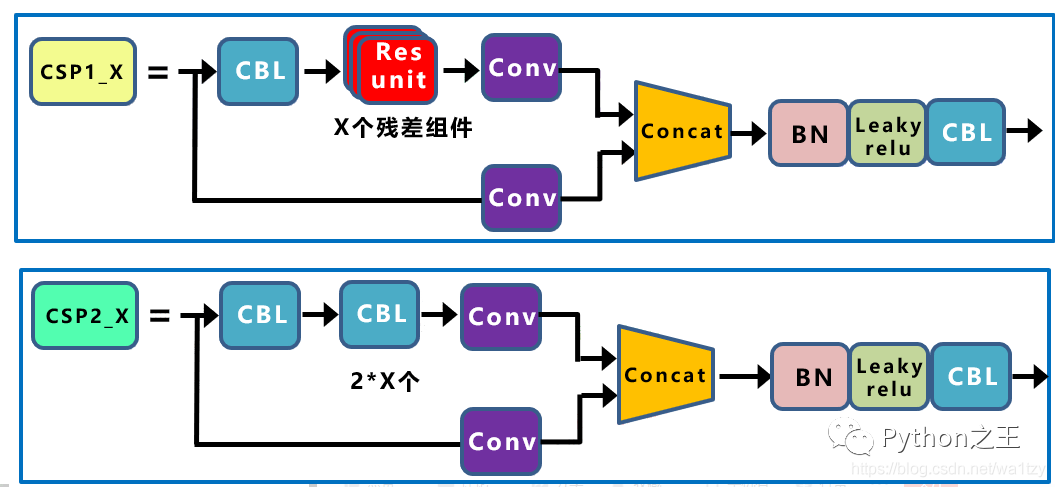
下圖為YOLOv4這部分的子結(jié)構(gòu)圖: 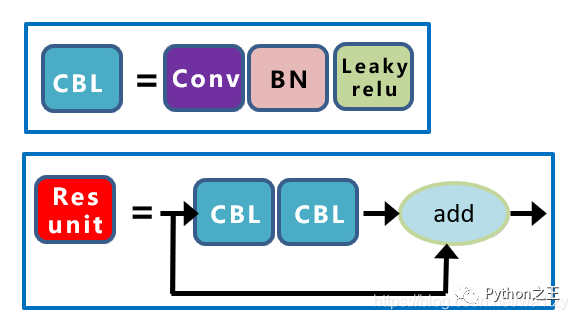
2.5 訓(xùn)練 train.py
模型下載的是模型和權(quán)重都在一起的,我們想把里面的模型單獨(dú)提出來不方便,yolov5提供另外一種方式:當(dāng)有hubconf.py這個(gè)文件,我們就可以用pytorch默認(rèn)的模型,通過這個(gè)方式去加載一些默認(rèn)模型,如果有這個(gè)文件,說明已經(jīng)上傳到pytorch上去了,形成了pytorch默認(rèn)的一個(gè)模型。新建test01.py,將以下代碼復(fù)制進(jìn)去:
import?torch
model?=?torch.hub.load('ultralytics/yolov5',?'yolov5s',?pretrained=True,?channels=3,?classes=80)
這樣就去github上下載了,yolov5完整代碼下載位置在:C盤\用戶\admin.cache\torch\hub\ultralytics_yolov5_master。運(yùn)行后會(huì)報(bào)錯(cuò),因?yàn)槲覀內(nèi)鄙贆?quán)重文件(注意這里的權(quán)重文件名也是yolov5s.pt,但與我們剛才拿到的不一樣,這個(gè)只包含權(quán)重,剛才的是模型和權(quán)重都在一塊),因?yàn)槠胀ㄓ脩魺o(wú)法使用google(原鏈接)  ,我把權(quán)重放出來供大家下載,鏈接:提取碼:0f7v
,我把權(quán)重放出來供大家下載,鏈接:提取碼:0f7v
下載后把權(quán)重yolov5s.pt放到根目錄(與test01.py在同一級(jí)目錄即可),再運(yùn)行一下就不報(bào)錯(cuò)了。
但不方便用,下載后我們可以導(dǎo)出模型裝載到我們自己的模型上去:
from?models?import??yolo
import?torch
model?=?torch.hub.load('ultralytics/yolov5',?'yolov5s',?pretrained=True,?channels=3,?classes=80)
model1?=?yolo.Model("models/yolov5s.yaml")
model1.load_state_dict(model.state_dict())
torch.save(model1.state_dict(),"my_yolov5s.pt")
這樣根目錄下就有我們自己的權(quán)重“my_yolov5s.pt”,接下來就是使用了:
model?=?yolo.Model("models/yolov5s.yaml")
model.load_state_dict(torch.load("my_yolov5s.pt"))
model.eval()
from?PIL?import?Image,ImageDraw
from?torchvision?import?transforms
from?utils?import?utils
import?numpy?as?np
img?=?Image.open(r"inference/images/zidane.jpg")
w,h?=?img.size
print(w,h)
tf?=?transforms.Compose([
????transforms.Resize((512,640)),
????transforms.ToTensor()
])
img_tensor?=?tf(img)
pred?=?model(img_tensor[None])[0]
det?=?utils.non_max_suppression(pred,?0.5,0.5)
img?=?img.resize((640,512))
Imgdraw?=?ImageDraw.Draw(img)
for?box?in?det[0]:
????b?=?box.cpu().detach().long().numpy()
????print(b)
????Imgdraw.rectangle((b[0],b[1],b[2],b[3]))
img.show()
顯示后的圖片如下(我做了縮放):
2.6 打包成jit
打包成jit
from?models?import??yolo
import?torch
from?PIL?import?Image,ImageDraw
from?torchvision?import?transforms
from?utils?import?utils
import?torch.jit
model?=?yolo.Model("models/yolov5s.yaml")
model.load_state_dict(torch.load("my_yolov5s.pt"))
model.eval()
img?=?Image.open(r"inference/images/zidane.jpg")
tf?=?transforms.Compose([
????transforms.Resize((512,640)),
????transforms.ToTensor()
])
img_tensor?=?tf(img)
pred?=?model(img_tensor[None])[0]
script_model?=?torch.jit.trace(model,img_tensor[None])
script_model.save("my_yolov5s.jit")
使用:
model?=?torch.jit.load("my_yolov5s.jit")
img?=?Image.open(r"inference/images/zidane.jpg")
tf?=?transforms.Compose([
????transforms.Resize((512,640)),
????transforms.ToTensor()
])
img_tensor?=?tf(img)
pred?=?model(img_tensor[None])[0]
det?=?utils.non_max_suppression(pred,?0.5,0.5)
img?=?img.resize((640,512))
Imgdraw?=?ImageDraw.Draw(img)
for?box?in?det[0]:
????b?=?box.cpu().detach().long().numpy()
????print(b)
????Imgdraw.rectangle((b[0],b[1],b[2],b[3]))
img.show()
2.7 打包成onnx
可以查閱官網(wǎng),看他怎么打包:進(jìn)入pytorch官網(wǎng):,點(diǎn)擊Tutorials,點(diǎn)擊下圖紅色鏈接:找到相關(guān)打包代碼  打包成onnx:
打包成onnx:
from?models?import??yolo
import?torch
from?PIL?import?Image,ImageDraw
from?torchvision?import?transforms
from?utils?import?utils
model?=?yolo.Model("models/yolov5s.yaml")
model.load_state_dict(torch.load("my_yolov5s.pt"))
model.eval()
img?=?Image.open(r"inference/images/zidane.jpg")
tf?=?transforms.Compose([
????transforms.Resize((512,640)),
????transforms.ToTensor()
])
img_tensor?=?tf(img)
pred?=?model(img_tensor[None])[0]
model.model[-1].export?=?True
torch.onnx.export(model,?img_tensor[None],?"my_yolov5s.onnx",?verbose=True,?opset_version=11,?input_names=['images'],
??????????????????????output_names=['output1','output2','output3'])??#?output_names=['classes',?'boxes']
同樣我們可以使用netron可視化分析網(wǎng)絡(luò)結(jié)構(gòu)(安裝使用在上面有介紹),這里圖示過大,我就不展示了。
使用onnx: 先安裝onnxruntime:打開控制臺(tái):pip install onnxruntime
import?onnxruntime
ort_session?=?onnxruntime.InferenceSession("my_yolov5s.onnx")
print("Exported?model?has?been?tested?with?ONNXRuntime,?and?the?result?looks?good!")
img?=?Image.open(r"inference/images/zidane.jpg")
tf?=?transforms.Compose([
????transforms.Resize((512,640)),
????transforms.ToTensor()
])
img_tensor?=?tf(img)
ort_inputs?=?{ort_session.get_inputs()[0].name:?img_tensor[None].numpy()}
pred?=?torch.tensor(ort_session.run(None,?ort_inputs)[0])
det?=?utils.non_max_suppression(pred,?0.5,0.5)
img?=?img.resize((640,512))
Imgdraw?=?ImageDraw.Draw(img)
for?box?in?det[0]:
????b?=?box.cpu().detach().long().numpy()
????print(b)
????Imgdraw.rectangle((b[0],b[1],b[2],b[3]))
img.show()

感分割線")
Python“寶藏級(jí)”公眾號(hào)【Python之王】專注于Python領(lǐng)域,會(huì)爬蟲,數(shù)分,C++,tensorflow和Pytorch等等。
近 2年共原創(chuàng) 100+ 篇技術(shù)文章。創(chuàng)作的精品文章系列有:
日常收集整理了一批不錯(cuò)的?Python?學(xué)習(xí)資料,有需要的小伙可以自行免費(fèi)領(lǐng)取。
獲取方式如下:公眾號(hào)回復(fù)資料。領(lǐng)取Python等系列筆記,項(xiàng)目,書籍,直接套上模板就可以用了。資料包含算法、python、算法小抄、力扣刷題手冊(cè)和 C++ 等學(xué)習(xí)資料!