
【分享送書(shū)】暢快!5000字通俗講透決策樹(shù)基本原理
導(dǎo)讀
在當(dāng)今這個(gè)人工智能時(shí)代,似乎人人都或多或少聽(tīng)過(guò)機(jī)器學(xué)習(xí)算法;而在眾多機(jī)器學(xué)習(xí)算法中,決策樹(shù)則無(wú)疑是最重要的經(jīng)典算法之一。這里,稱(chēng)其最重要的經(jīng)典算法是因?yàn)橐源藶榛A(chǔ),誕生了一大批集成算法,包括Random Forest、Adaboost、GBDT、xgboost,lightgbm,其中xgboost和lightgbm更是當(dāng)先炙手可熱的大賽算法;而又稱(chēng)其為之一,則是出于嚴(yán)謹(jǐn)和低調(diào)。實(shí)際上,決策樹(shù)算法也是個(gè)人最喜愛(ài)的算法之一(另一個(gè)是Naive Bayes),不僅出于其算法思想直觀(guān)易懂(相較于SVM而言,簡(jiǎn)直好太多),更在于其較好的效果和巧妙的設(shè)計(jì)。似乎每個(gè)算法從業(yè)人員都會(huì)開(kāi)一講決策樹(shù)專(zhuān)題,那么今天本文也來(lái)達(dá)成這一目標(biāo)。

本文著眼講述經(jīng)典的3類(lèi)決策樹(shù)算法原理,行文框架如下:
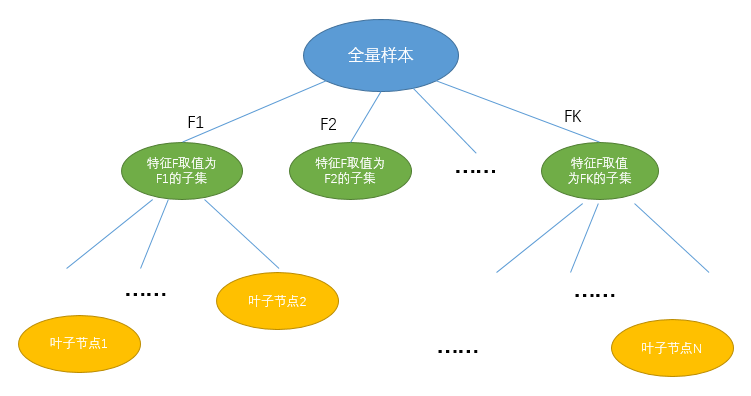
決策樹(shù)分類(lèi)的基本思想:switch-case
從ID3到C4.5,如何作出最優(yōu)的決策?
信息熵增益
信息熵增益比
CART樹(shù),既可分類(lèi)又能回歸
從信息熵到gini指數(shù)
從多叉樹(shù)到二叉樹(shù)
從分類(lèi)樹(shù)到回歸樹(shù)
決策樹(shù)算法是機(jī)器學(xué)習(xí)中的一種經(jīng)典算法,更是很多集成算法的基礎(chǔ)。雖說(shuō)是機(jī)器學(xué)習(xí),但決策樹(shù)的基本思想非常符合程序員思維:if-else或者switch-case,即如果滿(mǎn)足什么條件則怎么怎么樣,否則就另外怎么樣。所以,決策樹(shù)學(xué)習(xí)的過(guò)程就是逐步?jīng)Q策的過(guò)程,而決策過(guò)程本身則可以繪制成一棵樹(shù),當(dāng)然這里的樹(shù)是指數(shù)據(jù)結(jié)構(gòu)與算法中的樹(shù)。
決策樹(shù)的基本思想很簡(jiǎn)單,那么執(zhí)行決策樹(shù)的訓(xùn)練過(guò)程其實(shí)無(wú)非就是以下幾步:
拿什么做決策——最優(yōu)決策特征選取
什么時(shí)候停止——決策樹(shù)分裂的終止條件
決策結(jié)果如何——最終葉子節(jié)點(diǎn)的取值
本文圍繞決策樹(shù)的這3個(gè)關(guān)鍵環(huán)節(jié)展開(kāi)介紹。
首先進(jìn)入大眾視野的決策樹(shù)是ID3(Iterative Dichotomiser 3,即第三代迭代二叉樹(shù)),這里稱(chēng)之為第三代,但似乎不存在所謂的第一代或第二代的前置版本;另外,雖然叫二叉樹(shù),但I(xiàn)D3算法生成的決策樹(shù)確是一個(gè)十足的多叉樹(shù)。那么,ID3算法是基本原理是怎樣的呢?
如前所述,構(gòu)建一顆決策樹(shù)首先要明確如何做出最優(yōu)決策,具體到機(jī)器學(xué)習(xí)場(chǎng)景,那么就是從眾多潛在的特征中選擇一個(gè)最優(yōu)的特征進(jìn)行分裂。所以,這里的問(wèn)題進(jìn)一步等價(jià)于如何定義“最優(yōu)”的特征。
在ID3算法中,引入了信息熵原理來(lái)反映特征重要性。這里,信息熵既是一個(gè)通信學(xué)上的概念,而其中的熵則要追溯到物理學(xué)。來(lái)源于何處并不重要,關(guān)鍵的是信息熵可以用于表征一個(gè)事件的不確定程度。這里不確定程度用通信學(xué)的角度講,就是蘊(yùn)含的信息量。當(dāng)然,為了使得機(jī)器學(xué)習(xí)的結(jié)果盡可能準(zhǔn)確,我們當(dāng)然是希望能盡可能的通過(guò)一個(gè)個(gè)的特征消除這種不確定性,或者說(shuō)不希望它有太多的信息量。
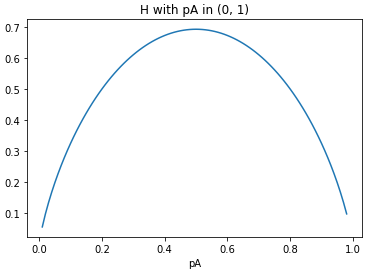
將上述過(guò)程進(jìn)行數(shù)學(xué)描述,即為:設(shè)選取特征F具有K個(gè)取值(特征F為離散型特征),則選取特征F參與決策樹(shù)訓(xùn)練意味著將原來(lái)的樣本集分裂為K個(gè)子集,在每個(gè)子集內(nèi)部獨(dú)立計(jì)算信息熵,進(jìn)而以特征F分裂后的條件信息熵為:
其中||Fi||為特征F第i個(gè)取值的個(gè)數(shù),而||F||則為特征F的總數(shù)(即樣本集總數(shù))。進(jìn)而,選取特征F訓(xùn)練帶來(lái)的信息熵增益(即,帶來(lái)的不確定性降低)可計(jì)算為:
所有特征全部用完;
分裂后的樣本子集是純的,即相應(yīng)分支上的信息熵為0;
達(dá)到預(yù)定的決策樹(shù)分裂深度,即最大深度;
分裂后的樣本子集數(shù)量少于預(yù)定葉子節(jié)點(diǎn)樣本數(shù)時(shí);
分裂帶來(lái)的信息熵增益小于指定增益閾值時(shí)
僅支持離散特征,如果是特征連續(xù)則首先需要離散化處理;
采用信息熵增益選擇最優(yōu)特征參與訓(xùn)練,在同等條件下,取值種類(lèi)多的特征比取值種類(lèi)少的特征更占優(yōu)勢(shì)。
針對(duì)第二個(gè)缺陷,C4.5決策算法給出了解決方案。
2)C4.5決策樹(shù)算法基本原理
其中,分母部分即為選取特征F自身的信息熵。雖然僅此一處細(xì)節(jié)改動(dòng),但卻有效抑制了分裂過(guò)程中對(duì)取值數(shù)目較多特征的偏好,一定程度上保證了決策樹(shù)訓(xùn)練過(guò)程的高效。
另外,C4.5決策樹(shù)還有其他比較重要的優(yōu)化設(shè)計(jì),例如支持特征缺失值的處理以及增加了剪枝策略等,此處不做展開(kāi)。
通過(guò)以上,我們介紹了決策樹(shù)的兩個(gè)經(jīng)典版本:ID3和C4.5,其中前者作為決策樹(shù)首個(gè)進(jìn)入大眾視野的版本,引入了信息熵原理參與特征的選擇和分裂,明確了決策樹(shù)終止分裂的條件;而C4.5則在ID3的基礎(chǔ)上,優(yōu)化了信息熵增益分裂準(zhǔn)則偏好選擇取值較多特征的弊端,改用信息熵增益比的準(zhǔn)則進(jìn)行分裂。但同時(shí),C4.5版本決策樹(shù)仍然存在以下弊端:
仍然僅支持離散特征的訓(xùn)練
生成的決策樹(shù)是一個(gè)多叉樹(shù),從計(jì)算機(jī)的視角來(lái)看不如二叉樹(shù)簡(jiǎn)單;
無(wú)論是信息熵增益還是增益比,都涉及大量的對(duì)數(shù)計(jì)算,計(jì)算效率低下;
仍然僅可用于分類(lèi)任務(wù),對(duì)于回歸預(yù)測(cè)無(wú)能為力。
對(duì)此,一個(gè)更高級(jí)版本的決策樹(shù)算法應(yīng)運(yùn)而生,CART樹(shù),也是當(dāng)前工業(yè)界一直沿用的決策樹(shù)算法。
特征選取準(zhǔn)則由信息熵改用gini指數(shù),并由多叉改為二叉,同時(shí)避免了對(duì)數(shù)運(yùn)算;
增加MSE準(zhǔn)則,用于回歸訓(xùn)練任務(wù)
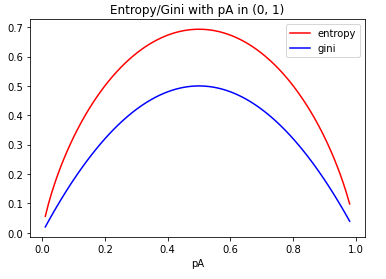
可見(jiàn),從信息熵演變?yōu)間ini指數(shù)是一個(gè)自然的迭代思路,但計(jì)算效率將會(huì)大大提升。這里,補(bǔ)充信息熵與gini指數(shù)取值的可視化對(duì)比曲線(xiàn),仍以前述的球賽結(jié)果概率為例:
決策樹(shù)是機(jī)器學(xué)習(xí)中的一個(gè)經(jīng)典算法,主要?dú)v經(jīng)了ID3、C4.5和CART樹(shù)三大版本,算法原理較為直觀(guān)易懂,改進(jìn)迭代的過(guò)程也容易理解,尤其是以決策樹(shù)算法為基礎(chǔ)更衍生了眾多的集成學(xué)習(xí)算法。除了本文講述的基本原理外,決策樹(shù)的另一大核心就是剪枝策略,這將在后續(xù)篇幅中予以闡釋。
最后,感謝清華大學(xué)出版社為本公眾號(hào)讀者贊助《數(shù)據(jù)科學(xué)實(shí)戰(zhàn)入門(mén) 使用Python和R》一本,截止下周二(3月30日)早9點(diǎn),公眾號(hào)后臺(tái)查看分享最多的前3名讀者隨機(jī)指定一人,中獎(jiǎng)讀者將在周四或周五推文中公布。
推薦語(yǔ):本書(shū)為沒(méi)有數(shù)據(jù)分析和編程經(jīng)驗(yàn)的讀者編寫(xiě),主題涵蓋數(shù)據(jù)準(zhǔn)備、探索性數(shù)據(jù)分析、準(zhǔn)備建模數(shù)據(jù)、決策樹(shù)、模型評(píng)估、錯(cuò)誤分類(lèi)代價(jià)、樸素貝葉斯分類(lèi)、神經(jīng)網(wǎng)絡(luò)、聚類(lèi)、回歸建模、降維和關(guān)聯(lián)規(guī)則挖掘。在首先講解Pyhton和R入門(mén)知識(shí)的基礎(chǔ)上,此后每一章都提供了使用Python和R解決數(shù)據(jù)科學(xué)問(wèn)題的分步說(shuō)明和實(shí)踐演練,讀者將一站式學(xué)習(xí)如何使用Python和R進(jìn)行數(shù)據(jù)科學(xué)實(shí)踐。
相關(guān)閱讀: