
自監(jiān)督學(xué)習(xí):人工智能中的暗物質(zhì),來自Facebook AI Yann LeCun
作者:Yann LeCun,Ishan Misra
編譯:ronghuaiyang
Yann LeCun和Ishan Misra對于自監(jiān)督學(xué)習(xí)的現(xiàn)狀的分析和展望。
近年來,人工智能領(lǐng)域在開發(fā)能夠從大量精心標(biāo)記的數(shù)據(jù)中學(xué)習(xí)的人工智能系統(tǒng)方面取得了巨大進(jìn)展。這種監(jiān)督學(xué)習(xí)的模式在訓(xùn)練專家模型時(shí)有著良好的記錄,這些模型在訓(xùn)練任務(wù)中表現(xiàn)得非常好。不幸的是,人工智能領(lǐng)域僅靠監(jiān)督學(xué)習(xí)的發(fā)展是有限的。
監(jiān)督學(xué)習(xí)是構(gòu)建更智能的多面手模型的瓶頸,這種模型可以在不需要大量標(biāo)記數(shù)據(jù)的情況下完成多個(gè)任務(wù)并獲得新技能。實(shí)際上,不可能給世界上所有的東西都貼上標(biāo)簽。還有一些任務(wù)根本沒有足夠的標(biāo)記數(shù)據(jù),比如為低資源語言訓(xùn)練翻譯系統(tǒng)。如果人工智能系統(tǒng)能夠收集到比訓(xùn)練數(shù)據(jù)集更深入、更細(xì)致的現(xiàn)實(shí)理解,它們將更有用,并最終讓人工智能更接近人類的智能水平。
在嬰兒時(shí)期,我們主要通過觀察來了解世界是如何運(yùn)轉(zhuǎn)的。我們通過學(xué)習(xí)物體持久性和重力等概念來形成關(guān)于世界上物體的廣義預(yù)測模型。在生活的后期,我們觀察世界,采取行動(dòng),再觀察,并建立假設(shè)來解釋我們的行為如何通過試錯(cuò)改變我們的環(huán)境。
一個(gè)可行的假說是,關(guān)于世界的廣義知識(shí),或常識(shí),構(gòu)成了人類和動(dòng)物的大部分生物智能。這種常識(shí)能力在人類和動(dòng)物身上被認(rèn)為是理所當(dāng)然的,但自人工智能研究一開始就一直是一個(gè)公開的挑戰(zhàn)。在某種程度上,常識(shí)是人工智能的暗物質(zhì)。
常識(shí)幫助人們學(xué)習(xí)新技能,而不需要對每一項(xiàng)任務(wù)進(jìn)行大量的教學(xué)。例如,如果我們給小孩子看幾幅牛的畫,他們最終就能認(rèn)出任何他們看到的牛。相比之下,經(jīng)過監(jiān)督學(xué)習(xí)訓(xùn)練的人工智能系統(tǒng)需要很多牛的圖像,而且在不尋常的情況下,比如躺在海灘上,可能仍然不能對牛進(jìn)行分類。人類是如何在幾乎沒有監(jiān)督的情況下,在大約20個(gè)小時(shí)的練習(xí)中學(xué)會(huì)駕駛汽車的,而完全自動(dòng)駕駛?cè)匀粺o法實(shí)現(xiàn)我們最好的人工智能系統(tǒng),這些人工智能系統(tǒng)接受了來自人類駕駛員數(shù)千小時(shí)的數(shù)據(jù)訓(xùn)練。簡而言之,人類依賴于他們先前獲得的關(guān)于世界如何運(yùn)轉(zhuǎn)的背景知識(shí)。
我們?nèi)绾巫寵C(jī)器做同樣的事情?

我們認(rèn)為,自監(jiān)督學(xué)習(xí)(SSL)是在人工智能系統(tǒng)中構(gòu)建這種背景知識(shí)和近似常識(shí)形式的最有前途的方法之一。
自監(jiān)督學(xué)習(xí)使人工智能系統(tǒng)能夠從更大數(shù)量級(jí)的數(shù)據(jù)中學(xué)習(xí),這對于識(shí)別和理解更微妙、更不常見的世界表示模式很重要。長期以來,自監(jiān)督學(xué)習(xí)在推動(dòng)自然語言處理(NLP)領(lǐng)域取得了巨大成功,包括Collobert-Weston 2008 model, Word2Vec, GloVE, fastText等。系統(tǒng)以這種方式進(jìn)行預(yù)訓(xùn)練產(chǎn)生的性能要比僅以監(jiān)督方式進(jìn)行訓(xùn)練時(shí)高得多。
我們最新的研究項(xiàng)目SEER利用SwAV和其他方法對10億張隨機(jī)無標(biāo)記圖像進(jìn)行預(yù)處理,從而在各種視覺任務(wù)中獲得最高的精度。這一進(jìn)展表明自監(jiān)督學(xué)習(xí)可以在復(fù)雜的CV任務(wù)中勝出,在真實(shí)生活環(huán)境中也是一樣。
今天,我們將分享為什么自監(jiān)督學(xué)習(xí)可能有助于解開智能的暗物質(zhì) —— 以及人工智能的下一個(gè)前沿。我們還強(qiáng)調(diào)了我們認(rèn)為在不確定性存在的情況下,基于能量的預(yù)測模型、聯(lián)合嵌入方法和用于人工智能系統(tǒng)中自監(jiān)督學(xué)習(xí)和推理的潛在變量架構(gòu)的一些最有前途的新方向。
自監(jiān)督學(xué)習(xí)是一種預(yù)測性學(xué)習(xí)
自監(jiān)督學(xué)習(xí)從數(shù)據(jù)本身獲得監(jiān)督信號(hào),通常利用數(shù)據(jù)中的底層結(jié)構(gòu)。自監(jiān)督學(xué)習(xí)的一般技術(shù)是預(yù)測任何未觀察到的或隱藏的輸入部分(或?qū)傩?從任何觀察到的或未隱藏的輸入部分。例如,正如自然語言處理中常見的那樣,我們可以隱藏一個(gè)句子的一部分,并從剩余的單詞中預(yù)測隱藏的單詞。我們還可以預(yù)測視頻中過去或未來的幀(隱藏?cái)?shù)據(jù))和當(dāng)前的幀(觀察數(shù)據(jù))。由于自監(jiān)督學(xué)習(xí)使用的是數(shù)據(jù)本身的結(jié)構(gòu),所以它可以跨同時(shí)發(fā)生的模式(例如,視頻和音頻)和跨大型數(shù)據(jù)集利用各種監(jiān)督信號(hào) —— 所有這些都不依賴于標(biāo)簽。
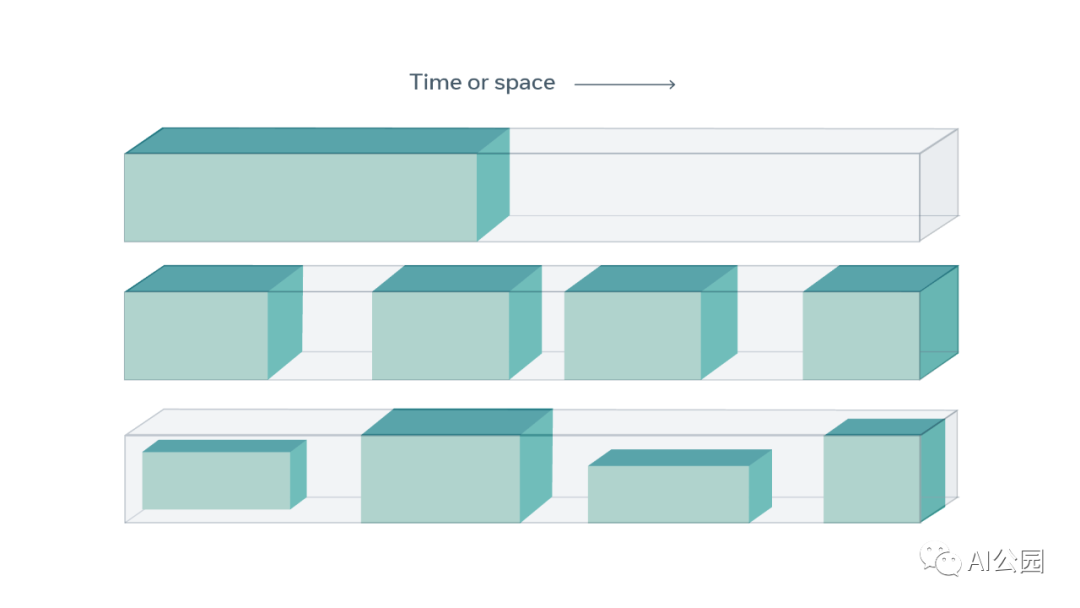
由于監(jiān)督信號(hào)告知自監(jiān)督學(xué)習(xí),術(shù)語“自監(jiān)督學(xué)習(xí)”比之前使用的術(shù)語“無監(jiān)督學(xué)習(xí)”更被接受。無監(jiān)督學(xué)習(xí)是一個(gè)定義不明確且具有誤導(dǎo)性的術(shù)語,它表明學(xué)習(xí)完全不使用監(jiān)督。事實(shí)上,自監(jiān)督學(xué)習(xí)并不是沒有監(jiān)督,因?yàn)樗葮?biāo)準(zhǔn)監(jiān)督和強(qiáng)化學(xué)習(xí)方法使用更多的反饋信號(hào)。
語言與視覺的自監(jiān)督學(xué)習(xí)
自監(jiān)督學(xué)習(xí)對自然語言處理產(chǎn)生了特別深遠(yuǎn)的影響,它允許我們在大型未標(biāo)記文本數(shù)據(jù)集上訓(xùn)練BERT、RoBERTa、XLM-R等模型,然后將這些模型用于下游任務(wù)。這些模型在自監(jiān)督階段進(jìn)行預(yù)訓(xùn)練,然后針對特定任務(wù)進(jìn)行微調(diào),比如對文本的主題進(jìn)行分類。在自監(jiān)督的預(yù)訓(xùn)練階段,向系統(tǒng)展示一段簡短的文本(通常是1000個(gè)單詞),其中一些單詞被屏蔽或替換了。該系統(tǒng)被訓(xùn)練來預(yù)測被屏蔽或替換的單詞。在這樣做的過程中,系統(tǒng)學(xué)會(huì)了表示文本的意思,這樣它就能很好地填寫“正確”的單詞,或者那些在上下文中有意義的單詞。
預(yù)測輸入中缺失的部分是SSL預(yù)訓(xùn)練中比較標(biāo)準(zhǔn)的任務(wù)之一。為了完成像“The (blank) chases the (blank) in the savanna”這樣的句子,系統(tǒng)必須知道獅子或獵豹可以追趕羚羊或角馬,但是貓可以在廚房里追趕老鼠,而不是稀樹大草原。作為訓(xùn)練的結(jié)果,系統(tǒng)學(xué)習(xí)表示單詞的意思,單詞的句法角色,以及整個(gè)文本的意思。
然而,這些技術(shù)不能輕易地推廣到新領(lǐng)域,比如CV。盡管早期的結(jié)果很有希望,但SSL還沒有在計(jì)算機(jī)視覺方面帶來我們在NLP中看到的同樣的改進(jìn)(盡管這將會(huì)改變)。
主要原因是,在預(yù)測圖像時(shí),表示圖像的不確定性比描述文字要困難得多。當(dāng)無法準(zhǔn)確預(yù)測缺失的單詞時(shí)(是“l(fā)ion”還是“cheetah”?),系統(tǒng)可以將分?jǐn)?shù)或概率與詞匯表中所有可能的單詞關(guān)聯(lián)起來:“l(fā)ion”、“cheetah”和一些其他捕食者得分高,詞匯表中所有其他單詞得分低。
這種規(guī)模的訓(xùn)練模型還需要一個(gè)模型架構(gòu),該架構(gòu)在運(yùn)行時(shí)和內(nèi)存方面都是高效的,而不影響準(zhǔn)確性。幸運(yùn)的是,F(xiàn)AIR最近設(shè)計(jì)了一種新的模式稱為RegNets,完美滿足了這些需求。RegNet模型是能夠擴(kuò)展到數(shù)十億甚至數(shù)萬億個(gè)參數(shù)的ConvNets,并且可以進(jìn)行優(yōu)化以適應(yīng)不同的運(yùn)行時(shí)和內(nèi)存限制。
但是我們不知道如何有效地表示不確定性,當(dāng)我們預(yù)測視頻中缺失的幀或圖像中缺失的補(bǔ)丁。我們不能列出所有可能的視頻幀并將其與每個(gè)幀關(guān)聯(lián)起來,因?yàn)樗鼈兊臄?shù)量是無限的。雖然這個(gè)問題限制了SSL在視覺任務(wù)中的性能改進(jìn),但諸如SwAV等新技術(shù)SSL技術(shù)開始在視覺任務(wù)中打破精度記錄。SEER系統(tǒng)最好地證明了這一點(diǎn),該系統(tǒng)使用了一個(gè)由數(shù)十億個(gè)樣本訓(xùn)練的大型卷積網(wǎng)絡(luò)。
預(yù)測中的不確定性建模
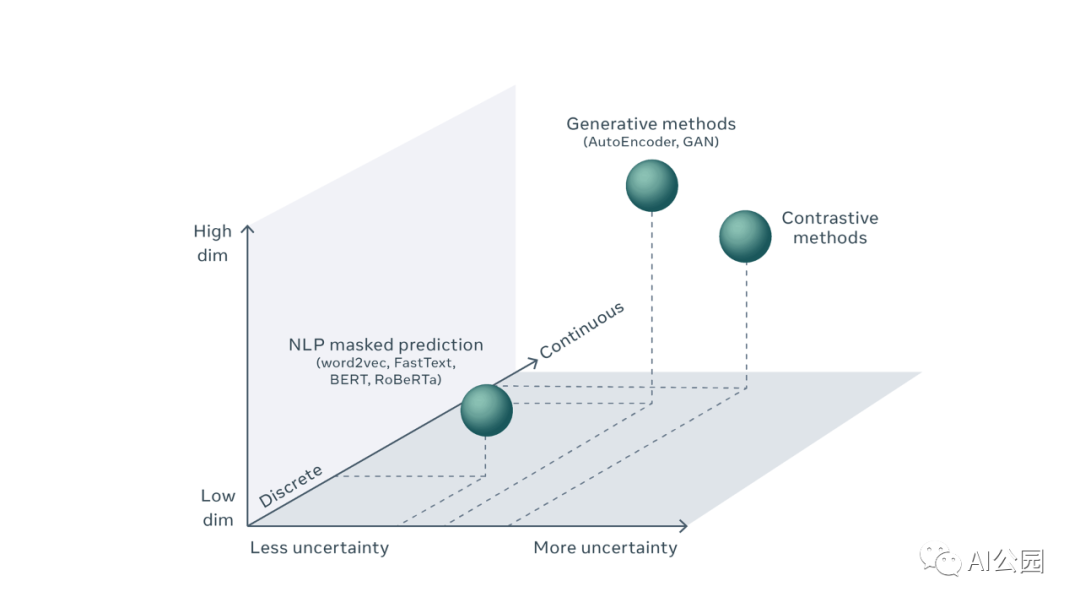
為了更好地理解這個(gè)挑戰(zhàn),我們首先需要理解預(yù)測的不確定性,以及它在NLP和CV中建模的方式。在自然語言處理中,預(yù)測缺失的單詞包括為每個(gè)可能的單詞計(jì)算預(yù)測得分。雖然詞匯量本身很大,而且預(yù)測一個(gè)遺漏的單詞包含一些不確定性,但我們還是有可能生成一個(gè)詞匯中所有可能出現(xiàn)的單詞的列表,并估算出這些單詞在該位置出現(xiàn)的概率。典型的機(jī)器學(xué)習(xí)系統(tǒng)是這樣做的:將預(yù)測問題視為分類問題,并使用一個(gè)巨大的所謂的softmax層計(jì)算每個(gè)結(jié)果的分?jǐn)?shù),該層將原始分?jǐn)?shù)轉(zhuǎn)換為單詞的概率分布。使用這種技術(shù),預(yù)測的不確定性用所有可能結(jié)果的概率分布來表示,前提是可能的結(jié)果的數(shù)量是有限的。
另一方面,在CV中,類似的預(yù)測視頻中“缺失”的幀、圖像中缺失的補(bǔ)丁或語音信號(hào)中缺失的片段的任務(wù)涉及到對高維連續(xù)對象的預(yù)測,而不是離散結(jié)果。有無限個(gè)可能的視頻幀可以合理地跟隨一個(gè)給定的視頻剪輯。不可能顯式地表示所有可能的視頻幀并將預(yù)測分?jǐn)?shù)與它們關(guān)聯(lián)起來。事實(shí)上,我們可能永遠(yuǎn)不會(huì)有技術(shù)來表示高維連續(xù)空間上合適的概率分布,比如所有可能的視頻幀的集合。
這似乎是一個(gè)棘手的問題。
對自監(jiān)督方法的統(tǒng)一看法
有一種方法可以在基于能量的模型(EBM)的統(tǒng)一框架中考慮SSL。EBM是一個(gè)可訓(xùn)練的系統(tǒng),給定兩個(gè)輸入,x和y,告訴我們它們彼此是多么不相同。例如,x可以是一個(gè)短視頻剪輯,而y可以是另一個(gè)視頻剪輯。機(jī)器會(huì)告訴我們y在多大程度上是x的良好延續(xù)。為了表示x和y之間的不相容性,機(jī)器產(chǎn)生一個(gè)單獨(dú)的數(shù)字,稱為能量。如果能量低,x和y被認(rèn)為是相容的;如果是高的,則被認(rèn)為是不相容的。
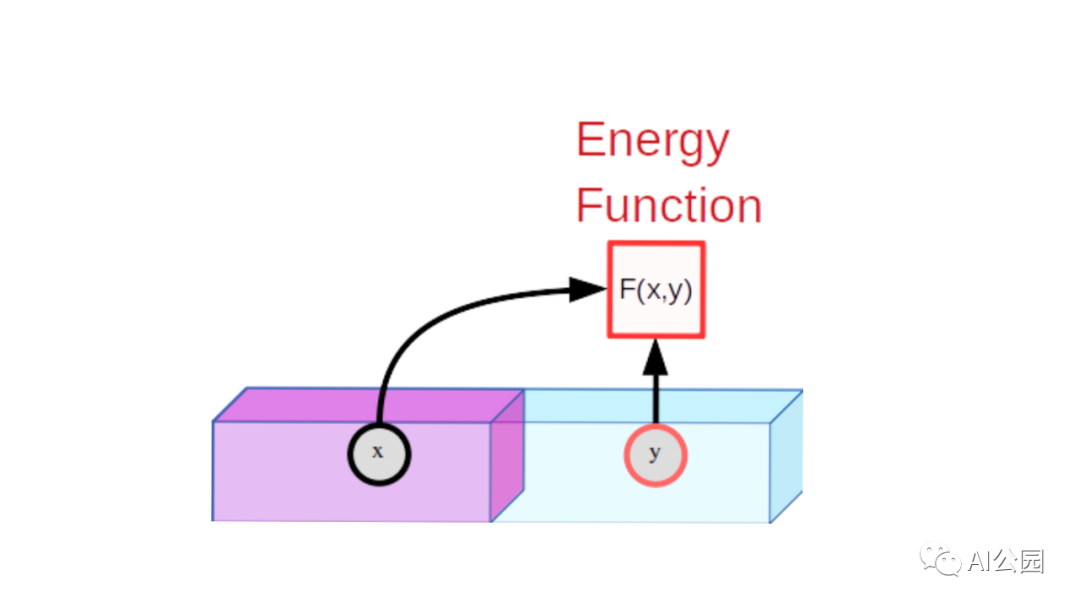
EBM訓(xùn)練包括兩部分:(1)展示它的x和y的樣本是相容的并訓(xùn)練它產(chǎn)生低能量,(2)找到一個(gè)方法來確保特定x, y值不相容,x產(chǎn)生能量高于y值相容的x。第一部分很簡單,但是第二部分是困難所在。
對于圖像識(shí)別,我們的模型將兩幅圖像x和y作為輸入。如果x和y是同一幅圖像的輕微扭曲版本,模型將被訓(xùn)練為輸出低能量。例如,x可能是一輛車的照片,y是同一輛車從一個(gè)稍微不同的位置在一天中的不同時(shí)間拍攝的,那么,y相對于x是經(jīng)過了平移,旋轉(zhuǎn),變大變小,顏色和陰影稍有不同的汽車。
聯(lián)合嵌入,孿生網(wǎng)絡(luò)
一個(gè)特別適合的深度學(xué)習(xí)體系結(jié)構(gòu)是所謂的孿生網(wǎng)絡(luò)或聯(lián)合嵌入體系結(jié)構(gòu)。這個(gè)想法可以追溯從Geoff Hinton的實(shí)驗(yàn)室和Yann LeCun組在1990年代早期的論文。長期以來,它相對被忽視,但自2019年末以來開始復(fù)蘇。聯(lián)合嵌入體系結(jié)構(gòu)由同一個(gè)網(wǎng)絡(luò)的兩個(gè)完全相同(或幾乎完全相同)的副本組成。一個(gè)網(wǎng)絡(luò)輸入x,另一個(gè)輸入y。網(wǎng)絡(luò)產(chǎn)生的輸出向量稱為嵌入向量,表示x和y。第三個(gè)模塊在頭部連接兩個(gè)網(wǎng)絡(luò),計(jì)算兩個(gè)嵌入向量之間的距離作為能量。當(dāng)模型顯示同一幅圖像的扭曲版本時(shí),網(wǎng)絡(luò)的參數(shù)可以很容易地進(jìn)行調(diào)整,使它們的輸出更接近。這將確保網(wǎng)絡(luò)將產(chǎn)生幾乎相同的對象表示(或嵌入),而不管該對象的特定視圖。
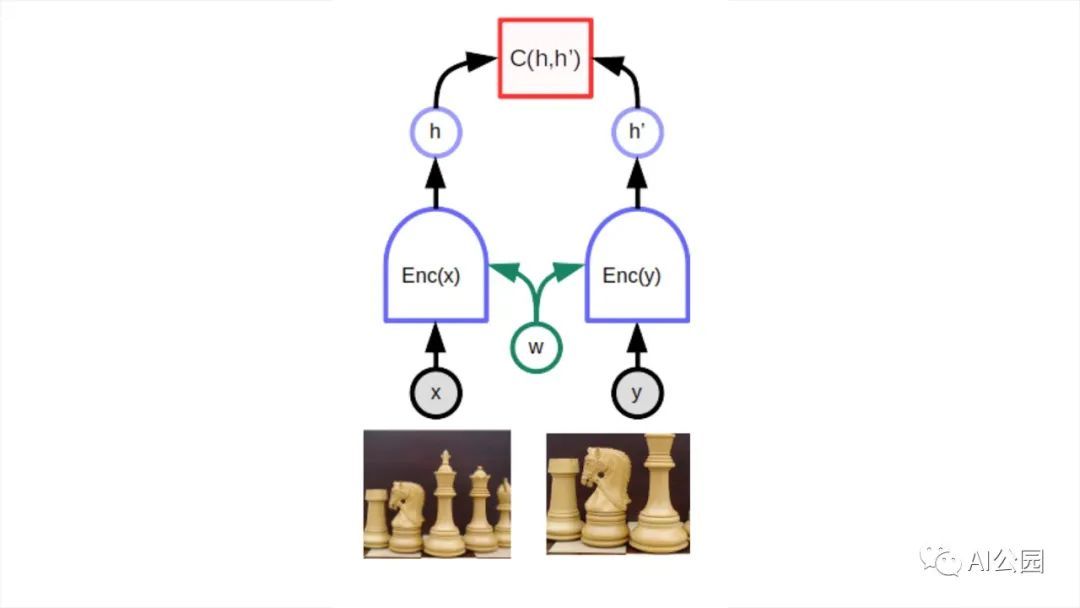
頂部的C函數(shù)產(chǎn)生一個(gè)標(biāo)量能量表示向量之間的距離(嵌入)由兩個(gè)孿生(w)網(wǎng)絡(luò)共享同一參數(shù)。當(dāng)x和y是略有不同的版本的相同的圖像,系統(tǒng)訓(xùn)練產(chǎn)生一個(gè)低能量, 這迫使模型為兩幅圖像產(chǎn)生相似的嵌入向量。困難的部分是訓(xùn)練模型,使其對不同的圖像產(chǎn)生高能量(即不同的嵌入)。
難點(diǎn)在于當(dāng)x和y是不同的圖像時(shí),要保證網(wǎng)絡(luò)產(chǎn)生高能,即不同的嵌入向量。如果沒有特定的方法,這兩個(gè)網(wǎng)絡(luò)可以愉快地忽略它們的輸入,總是產(chǎn)生相同的輸出嵌入。這種現(xiàn)象被稱為坍縮。當(dāng)發(fā)生坍縮時(shí),不匹配的x和y的能量并不比匹配的x和y的能量高。
有兩類技術(shù)避免坍縮:對比方法和正則化方法。
基于能量的對比SSL
對比方法基于構(gòu)造不兼容的x和y對的簡單思想,并調(diào)整模型的參數(shù),使相應(yīng)的輸出能量較大。

通過屏蔽或替換輸入詞來訓(xùn)練自然語言處理系統(tǒng)的方法屬于對比方法的范疇。但他們不使用聯(lián)合嵌入結(jié)構(gòu)。相反,他們使用了一種預(yù)測架構(gòu),在這種架構(gòu)中,模型直接產(chǎn)生對y的預(yù)測。一個(gè)人從一個(gè)完整的文本片段y開始,然后破壞它,例如,通過屏蔽一些單詞產(chǎn)生觀察x。將損壞輸入喂給神經(jīng)網(wǎng)絡(luò)訓(xùn)練重現(xiàn)原文y。一個(gè)未坍縮的文本將重建本身(低重建誤差),而一個(gè)損壞的文本將重建一個(gè)未坍縮的版本的本身(大的重建錯(cuò)誤)。如果將重構(gòu)錯(cuò)誤解釋為一種能量,它將具有所需的特性:“干凈”文本的能量較低,“損壞”文本的能量較高。
訓(xùn)練模型來恢復(fù)輸入的損壞版本的一般技術(shù)稱為去噪自編碼器。
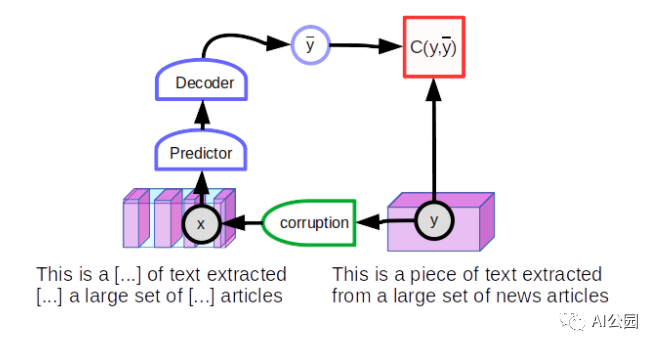
正如我們前面指出的,這種類型的預(yù)測體系結(jié)構(gòu)只能為給定的輸入產(chǎn)生一個(gè)預(yù)測。由于該模型必須能夠預(yù)測多種可能的結(jié)果,因此預(yù)測不是單一的單詞集,而是針對每個(gè)缺失單詞位置的詞匯中的每個(gè)單詞的一系列分?jǐn)?shù)。
但是我們不能將此技巧用于圖像,因?yàn)槲覀儾荒苊杜e所有可能的圖像。這個(gè)問題有解決辦法嗎?回答是否定的。在這個(gè)方向上有一些有趣的想法,但是它們還沒有產(chǎn)生像聯(lián)合嵌入架構(gòu)那樣好的結(jié)果。一個(gè)有趣的途徑是潛在變量預(yù)測架構(gòu)。
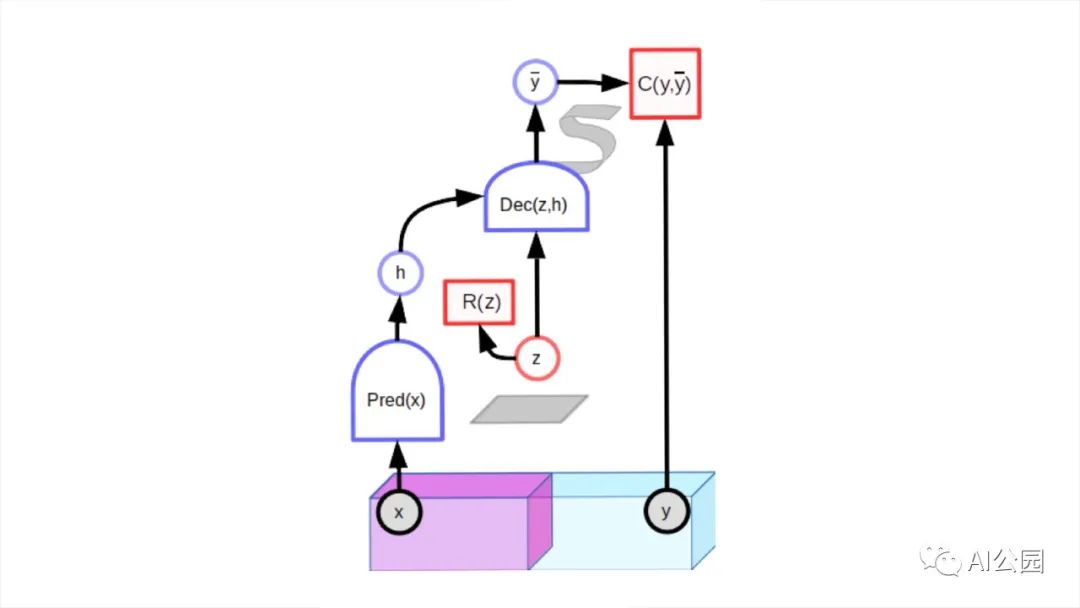
潛在變量預(yù)測模型包含一個(gè)額外的輸入變量(z)。之所以稱其為潛在變量是因?yàn)樗闹祻奈幢挥^察到。對于適當(dāng)訓(xùn)練的模型,當(dāng)潛在變量在給定集合上變化時(shí),輸出預(yù)測在與輸入x相兼容的可信預(yù)測集合上變化。
潛在變量模型可以用對比的方法進(jìn)行訓(xùn)練。生成對抗網(wǎng)絡(luò)(GAN)就是一個(gè)很好的例子。判別器可以被看作是計(jì)算一個(gè)能量,該能量指示輸入y是否看起來不錯(cuò)。對生成器網(wǎng)絡(luò)進(jìn)行訓(xùn)練,以產(chǎn)生對比樣本,對這些樣本進(jìn)行訓(xùn)練,使判別器產(chǎn)生到高能量。
但是對比的方法有一個(gè)主要問題:訓(xùn)練效率非常低。在像圖像這樣的高維空間中,一幅圖像與另一幅圖像有很多不同之處。找到一組對比圖像,涵蓋它們與給定圖像的所有不同之處,幾乎是一項(xiàng)不可能完成的任務(wù)。套用列夫·托爾斯泰的《安娜·卡列尼娜》:“幸福的家庭都是相似的,不幸的家庭各有各的不幸。”這似乎適用于任何一種高維物體。
如果有可能確保不相容對的能量高于相容對的能量而不明確地推高許多不相容對的能量會(huì)怎樣?
基于能量的非對比SSL
應(yīng)用于聯(lián)合嵌入架構(gòu)的非對比性方法可能是目前視覺SSL中最熱門的話題。這一領(lǐng)域仍大部分未被探索,但似乎很有前途。
非對比性的聯(lián)合嵌入方法包括:DeeperCluster, ClusterFit, MoCo-v2, SwAV, SimSiam, Barlow Twins, BYOL,來自DeepMind以及其他一些公司。他們使用各種技巧,如計(jì)算虛擬目標(biāo)嵌入相似的圖像組(DeeperCluster, SwAV, SimSiam)或通過架構(gòu)或參數(shù)向量(BYOL, MoCo)使兩種聯(lián)合嵌入架構(gòu)略有不同。Barlow Twins試圖最小化嵌入向量的單個(gè)組件之間的冗余。
也許從長遠(yuǎn)來看,一個(gè)更好的選擇將是設(shè)計(jì)具有潛在變量預(yù)測模型的非對比性方法。主要的障礙是它們需要一種方法來最小化潛在變量的容量。潛在變量可以改變的集合的體積限制了低能量輸出的體積。通過將體積最小化,能量就會(huì)以正確的方式自動(dòng)形成。
一個(gè)成功的方法是變分Auto-Encoder,使?jié)撟兞俊澳:保拗屏藵撟兞康娜萘俊5玍AE尚未顯示對下游視覺任務(wù)產(chǎn)生良好的表征。另一個(gè)成功的例子是稀疏的建模,但它的使用一直局限于簡單的架構(gòu)。似乎沒有什么完美的方法可以限制潛在變量的能力。
未來幾年的挑戰(zhàn)可能是為基于潛在變量能量的模型設(shè)計(jì)非對比方法,成功地生成圖像、視頻、語音和其他信號(hào)的良好表示,并在不需要大量標(biāo)記數(shù)據(jù)的情況下在下游監(jiān)督任務(wù)中獲得最佳表現(xiàn)。
英文原文:https://ai.facebook.com/blog/self-supervised-learning-the-dark-matter-of-intelligence/
 End
End
聲明:部分內(nèi)容來源于網(wǎng)絡(luò),僅供讀者學(xué)術(shù)交流之目的。文章版權(quán)歸原作者所有。如有不妥,請聯(lián)系刪除。