
自監(jiān)督學(xué)習(xí)的一些思考
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

作者:Xiaohang Zhan
來(lái)源:知乎
鏈接:https://zhuanlan.zhihu.com/p/150224914
注:本文已獲作者授權(quán)轉(zhuǎn)載,未經(jīng)作者同意禁止二次轉(zhuǎn)載
自監(jiān)督學(xué)習(xí)的流行是勢(shì)在必然的。在各種主流有監(jiān)督學(xué)習(xí)任務(wù)都做到很成熟之后,數(shù)據(jù)成了最重要的瓶頸。從無(wú)標(biāo)注數(shù)據(jù)中學(xué)習(xí)有效信息一直是一個(gè)很重要的研究課題,其中自監(jiān)督學(xué)習(xí)提供了非常豐富的想象空間。
如何定義自監(jiān)督學(xué)習(xí)?
自監(jiān)督學(xué)習(xí)是指用于機(jī)器學(xué)習(xí)的標(biāo)注(ground truth)源于數(shù)據(jù)本身,而非來(lái)自人工標(biāo)注。如下圖,自監(jiān)督學(xué)習(xí)首先屬于無(wú)監(jiān)督學(xué)習(xí),因此其學(xué)習(xí)的目標(biāo)無(wú)需人工標(biāo)注。其次,目前的自監(jiān)督學(xué)習(xí)領(lǐng)域可大致分為兩個(gè)分支。第一個(gè)是用于解決特定任務(wù)的自監(jiān)督學(xué)習(xí),例如上次討論的場(chǎng)景去遮擋,以及自監(jiān)督的深度估計(jì)、光流估計(jì)、圖像關(guān)聯(lián)點(diǎn)匹配等。另一個(gè)分支則用于表征學(xué)習(xí)。有監(jiān)督的表征學(xué)習(xí),一個(gè)典型的例子是ImageNet分類。而無(wú)監(jiān)督的表征學(xué)習(xí)中,最主要的方法則是自監(jiān)督學(xué)習(xí)。典型的方法包括:解決Jigsaw Puzzles、運(yùn)動(dòng)傳播、旋轉(zhuǎn)預(yù)測(cè),以及最近很火的MoCo等等。當(dāng)然還有其他分類方法,比如根據(jù)數(shù)據(jù)也可以分為video / image / language的自監(jiān)督學(xué)習(xí)。本文主要討論image上的自監(jiān)督學(xué)習(xí)。
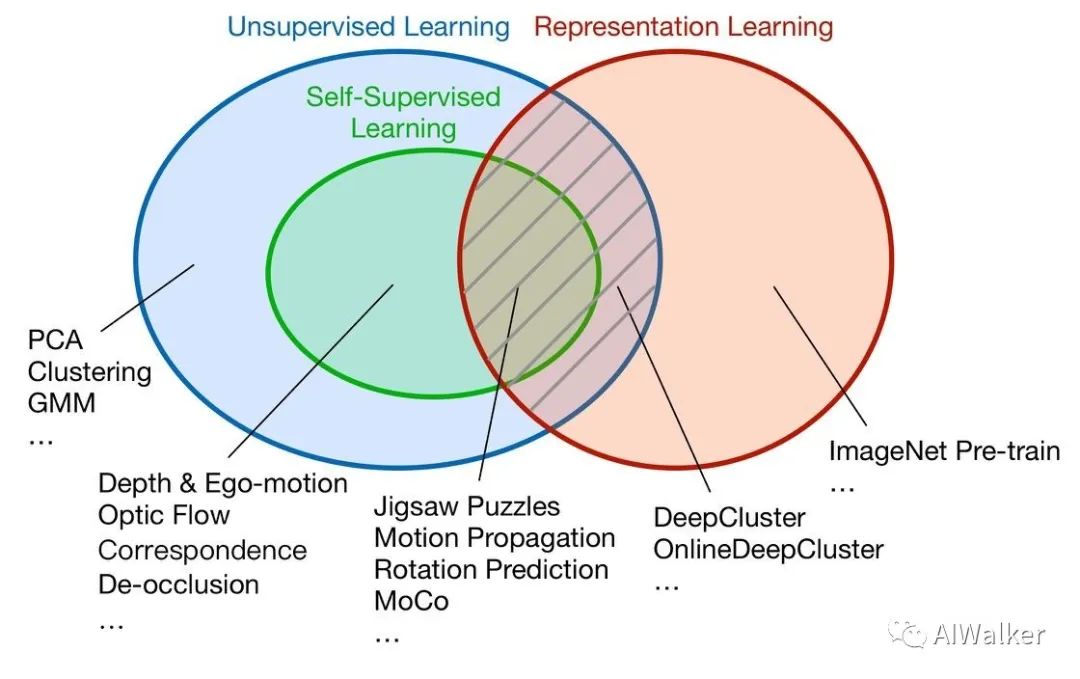
判斷一個(gè)工作是否屬于自監(jiān)督學(xué)習(xí),除了無(wú)需人工標(biāo)注這個(gè)標(biāo)準(zhǔn)之外,還有一個(gè)重要標(biāo)準(zhǔn),就是是否學(xué)到了新的知識(shí)。舉個(gè)簡(jiǎn)單的例子,例如image inpainting是否屬于自監(jiān)督學(xué)習(xí)?如果一篇image inpainting的論文,其主要目的是提升inpainting的效果,那么它就不屬于自監(jiān)督學(xué)習(xí),雖然它無(wú)需額外標(biāo)注。但是如果它的目的是借助inpainting這個(gè)任務(wù)來(lái)學(xué)習(xí)圖像的特征表達(dá),那么它就是自監(jiān)督學(xué)習(xí)(參考論文:Context Encoders [1])。如下圖,以自監(jiān)督表征學(xué)習(xí)為例,我們通常需要設(shè)計(jì)一個(gè)自監(jiān)督的proxy task,我們期望在解決這個(gè)proxy task的過(guò)程中,CNN能學(xué)到一些圖像高級(jí)的語(yǔ)義信息。然后我們將訓(xùn)練好的CNN遷移到其他目標(biāo)任務(wù),例如圖像語(yǔ)義分割、物體檢測(cè)等等。
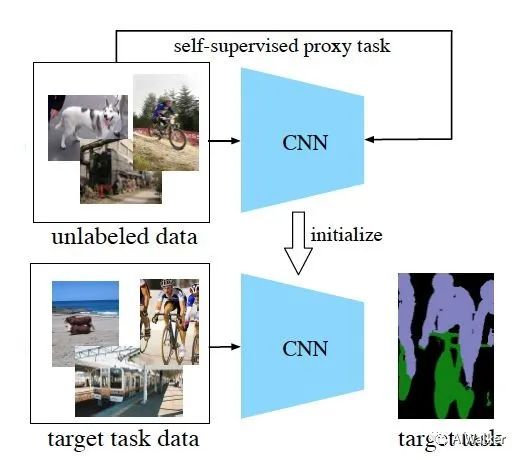
那么,自監(jiān)督的proxy task有哪些呢?如下圖舉了一些有代表性的例子,第一行中的思路是將圖像以某種方式破壞,然后用神經(jīng)網(wǎng)絡(luò)來(lái)學(xué)習(xí)恢復(fù)原圖的過(guò)程,期望在此過(guò)程中能學(xué)到一些圖像語(yǔ)義信息。然而,將圖像破壞,可能帶來(lái)預(yù)訓(xùn)練的domain和目標(biāo)任務(wù)domain不一致的問(wèn)題。第二行中的proxy tasks則代表了無(wú)需破壞原圖的自監(jiān)督任務(wù)。第三行中的方法是利用運(yùn)動(dòng)信息等多模態(tài)信息來(lái)學(xué)習(xí)圖像特征。當(dāng)然除了圖中這些例子之外,還有各種各樣其他有趣的自監(jiān)督任務(wù)。

為什么自監(jiān)督學(xué)習(xí)能學(xué)到新信息 ?
1. 先驗(yàn)
我們的世界是在嚴(yán)格的物理、生物規(guī)則下運(yùn)行的,那么對(duì)這個(gè)世界的觀測(cè)結(jié)果(圖像)也必然存在一些先驗(yàn)規(guī)律。例如圖像上色任務(wù),就是利用了物體類別和物體顏色分布之間的關(guān)聯(lián);image inpainting,則是利用了物體類別和形狀紋理之間的關(guān)聯(lián);旋轉(zhuǎn)預(yù)測(cè)任務(wù),利用了物體類別和其朝向之間的關(guān)聯(lián)。通過(guò)挖掘更多的先驗(yàn),我們也能設(shè)計(jì)自己的自監(jiān)督學(xué)習(xí)任務(wù)。
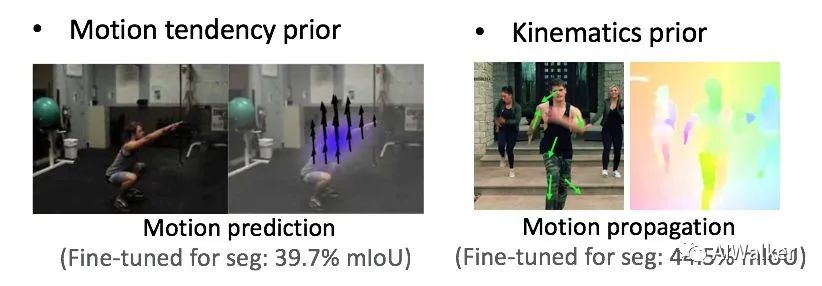
那么什么樣的先驗(yàn)更有效呢?結(jié)論是,低熵的先驗(yàn)。如下圖,左邊的運(yùn)動(dòng)預(yù)測(cè)任務(wù)(ICCV 2015: Dense Optical Flow Prediction From a Static Image [2]) ,是從單張圖片中直接預(yù)測(cè)運(yùn)動(dòng)場(chǎng),其利用的先驗(yàn)是物體的運(yùn)動(dòng)傾向性。而運(yùn)動(dòng)傾向性是比較歧義的,例如人在半蹲狀態(tài),難以預(yù)測(cè)下一時(shí)刻會(huì)站起來(lái)還是繼續(xù)下蹲。因而,運(yùn)動(dòng)傾向性是一個(gè)高熵的先驗(yàn)。而右圖的運(yùn)動(dòng)傳播任務(wù)(CVPR 2019: Self-Supervised Learning via Conditional Motion Propagation [3]),從給定的稀疏運(yùn)動(dòng)來(lái)恢復(fù)完整運(yùn)動(dòng)場(chǎng),利用的則是物體的運(yùn)動(dòng)學(xué)屬性先驗(yàn)。運(yùn)動(dòng)學(xué)屬性,例如頭部是剛體,四肢是鉸接體等,是較為確定的先驗(yàn),那么這就是一個(gè)低熵的先驗(yàn)。從實(shí)驗(yàn)結(jié)果也可以發(fā)現(xiàn),在transfer到分割任務(wù)上,運(yùn)動(dòng)傳播比運(yùn)動(dòng)預(yù)測(cè)更好。
2. 連貫性
圖片具有空間連貫性,視頻具有時(shí)空連貫性。那么就可以利用這些特點(diǎn)來(lái)設(shè)計(jì)自監(jiān)督任務(wù)。如下圖,Solving Jigsaw Puzzles [4] 利用圖片中物體空間上的語(yǔ)義連貫性,Temporal order verification [5]任務(wù)利用了視頻中物體運(yùn)動(dòng)的時(shí)間連貫性。

3. 數(shù)據(jù)內(nèi)部結(jié)構(gòu)
目前很火的基于contrastive learning的方法,包括NPID, MoCo, SimCLR等,我們可以將它們統(tǒng)一為instance discrimination [6]任務(wù)。如下圖,這類任務(wù)通常對(duì)圖片做各種變換,然后優(yōu)化目標(biāo)是同一張圖片的不同變換在特征空間中盡量接近,不同圖片在特征空間中盡量遠(yuǎn)離。
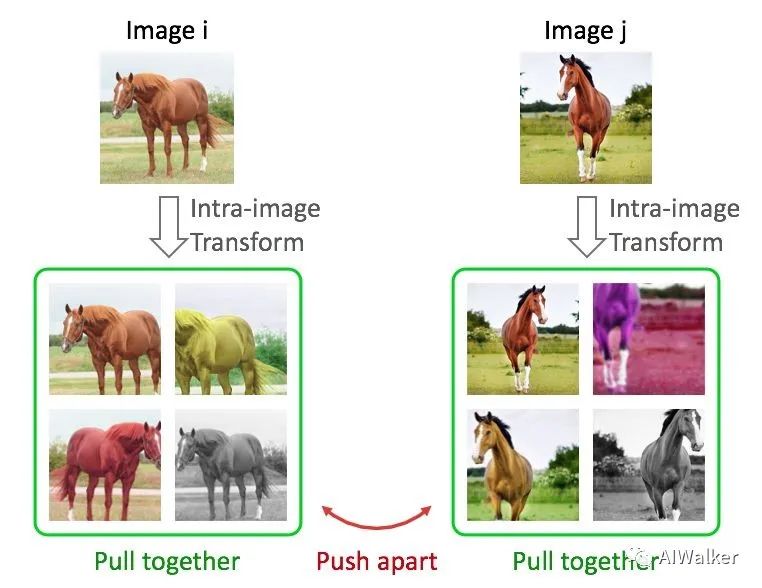
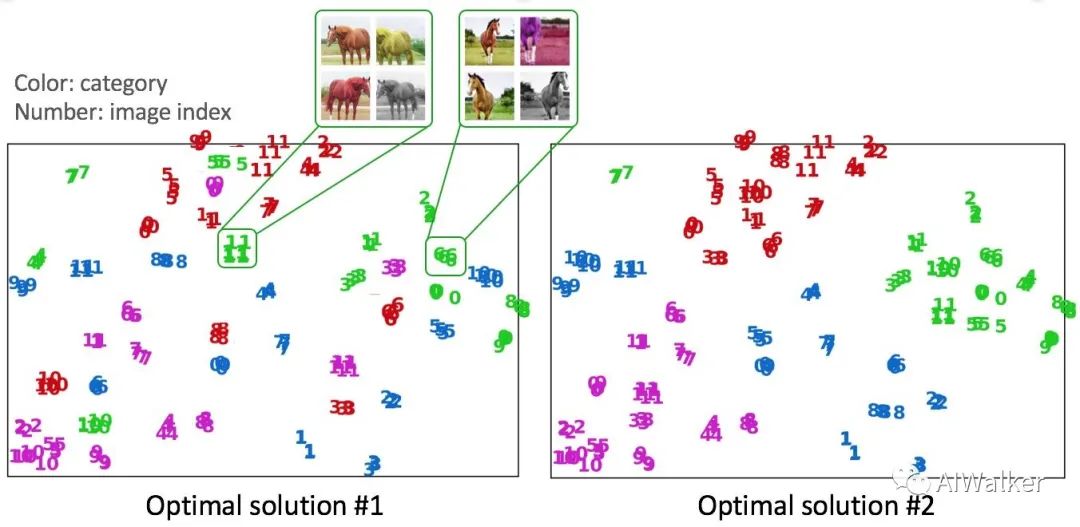
對(duì)于這類任務(wù),下圖假設(shè)了兩種可能的優(yōu)化后的特征空間。這兩種結(jié)果都是符合instance discrimination優(yōu)化目標(biāo)的,即同一張圖片的不同變換在特征空間中盡量接近,不同圖片在特征空間中盡量遠(yuǎn)離。然而,我們發(fā)現(xiàn),實(shí)際的優(yōu)化結(jié)果更偏向于第二種而非第一種,也就是說(shuō),雖然我們?cè)诮鉀Qinstance discrimination的過(guò)程中并沒(méi)有用的物體的類別標(biāo)簽,但是在優(yōu)化后的特征空間中,同類的物體還是相對(duì)能夠靠攏。這就證明了,數(shù)據(jù)之間是具有結(jié)構(gòu)性和關(guān)聯(lián)性的。Instance discrimination則是巧妙地利用了這種結(jié)構(gòu)性和關(guān)聯(lián)性。類似地,最近的BYOL [7]也可能是利用了數(shù)據(jù)在特征空間中的分布結(jié)構(gòu)特點(diǎn)來(lái)拋棄負(fù)樣本對(duì)(個(gè)人理解)。
設(shè)計(jì)一個(gè)自監(jiān)督學(xué)習(xí)任務(wù)還需要考慮什么?
捷徑(shortcuts)
以jigsaw puzzles為例,如下圖,如果我們讓劃分的patch之間緊密挨著,那么神經(jīng)網(wǎng)絡(luò)只需要判斷patch的邊緣是否具有連續(xù)性,就可以判斷patch的相對(duì)位置,而不需要學(xué)到高級(jí)的物體語(yǔ)義信息。這就是一種捷徑,我們?cè)谠O(shè)計(jì)任務(wù)的過(guò)程中需要避免這樣的捷徑。

對(duì)于這種捷徑,處理的方式也很簡(jiǎn)單,我們只需要讓patch之間產(chǎn)生一些隨機(jī)的間隔就行,如下圖。

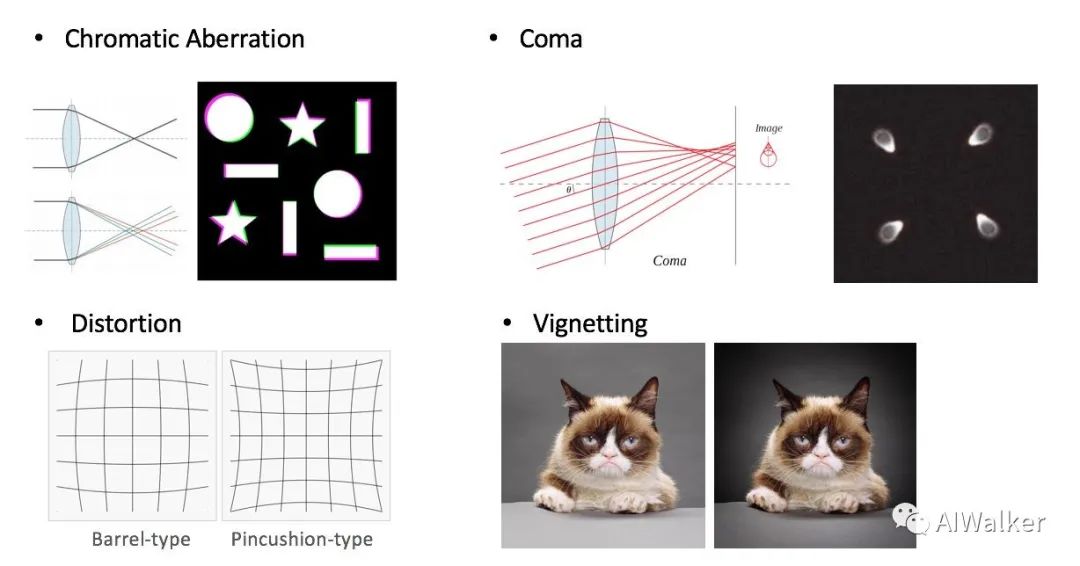
Solving jigsaw puzzles的其他捷徑還包括色差、彗差、畸變、暗角等可以指示patch在圖像中的相對(duì)位置的信息。解決方案除了想辦法消除這些畸變外,還可以讓patch盡量靠近圖像中心。
2. 歧義性(Ambiguity)
大多數(shù)利用先驗(yàn)來(lái)設(shè)計(jì)的自監(jiān)督任務(wù)都會(huì)面臨歧義性問(wèn)題。例如colorization中,一種物體的顏色可能是多種多樣的,那么從灰度圖恢復(fù)顏色這個(gè)過(guò)程就具有ambiguity;再例如在rotation prediction中,有的物體并沒(méi)有一個(gè)通常的朝向(例如俯拍放在桌上的圓盤子)。有不少已有工作在專門解決特定任務(wù)的歧義性問(wèn)題,例如CVPR 2019的Self-Supervised Representation Learning by Rotation Feature Decoupling。另外就是設(shè)計(jì)低熵的先驗(yàn),因?yàn)榈挽氐南闰?yàn)也具有較低的歧義性。
3. 任務(wù)難度
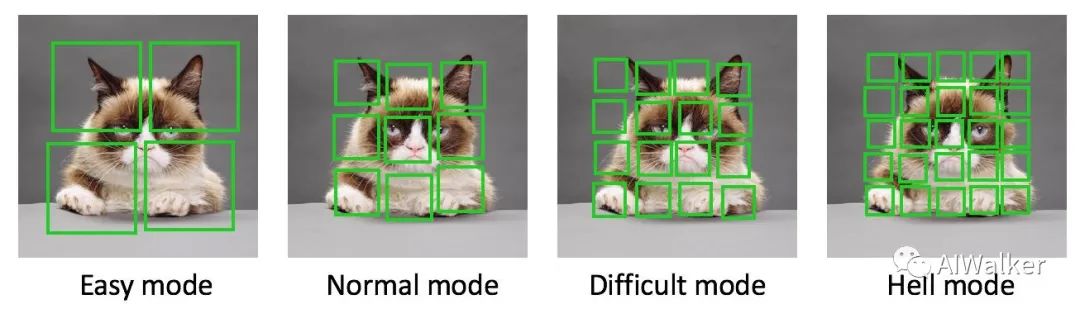
神經(jīng)網(wǎng)絡(luò)就像一個(gè)小孩,如果給他太簡(jiǎn)單的任務(wù),他學(xué)不到有用的知識(shí),如果給他太難的任務(wù),他可能直接就放棄了。設(shè)計(jì)合理的難度也是一個(gè)需要考慮的方面。
展望
我們的世界是在嚴(yán)格的物理學(xué)、化學(xué)、生物學(xué)規(guī)則下運(yùn)行的,視覺(jué)信號(hào)是這些內(nèi)在規(guī)則的外在反映,而深度學(xué)習(xí),正好非常擅長(zhǎng)處理高維的視覺(jué)信號(hào)。所以,無(wú)監(jiān)督、自監(jiān)督學(xué)習(xí)的存在和發(fā)展是必然的,因?yàn)槭澜绫旧砭褪怯行虻摹⒌挽氐模@使得數(shù)據(jù)本身就已經(jīng)包含了豐富的信息。自監(jiān)督學(xué)習(xí)看似神奇,但理解了其本質(zhì)之后,也就會(huì)覺(jué)得是情理之中了。當(dāng)然,目前學(xué)術(shù)界對(duì)自監(jiān)督學(xué)習(xí)的理解程度,可能也只是九牛一毛而已。未來(lái)會(huì)走向什么方向,誰(shuí)也說(shuō)不準(zhǔn)。目前是基于數(shù)據(jù)之間的結(jié)構(gòu)的instance discrimination處于state-of-the-art,未來(lái),基于priors的方法更勝一籌也是有可能的。所以,千萬(wàn)不要受限于一類方法,不要讓自監(jiān)督學(xué)習(xí)變成了調(diào)參游戲,自監(jiān)督領(lǐng)域的想象力空間其實(shí)非常大。
最后,這個(gè)總結(jié)主要基于自己的思考,也許不一定非常到位,權(quán)當(dāng)拋磚引玉。希望大家都能夠設(shè)計(jì)出有趣又有用的自監(jiān)督學(xué)習(xí)任務(wù),為這個(gè)領(lǐng)域添磚加瓦。
References:
1. Pathak, Deepak, et al. "Context encoders: Feature learning by inpainting."Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
2. Walker, Jacob, Abhinav Gupta, and Martial Hebert. "Dense optical flow prediction from a static image."Proceedings of the IEEE International Conference on Computer Vision. 2015.
3. Zhan, Xiaohang, et al. "Self-supervised learning via conditional motion propagation."?Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
4. Noroozi, Mehdi, and Paolo Favaro. "Unsupervised learning of visual representations by solving jigsaw puzzles."European Conference on Computer Vision. Springer, Cham, 2016.
5. Misra, Ishan, C. Lawrence Zitnick, and Martial Hebert. "Shuffle and learn: unsupervised learning using temporal order verification."European Conference on Computer Vision. Springer, Cham, 2016.
6. Wu, Zhirong, et al. "Unsupervised feature learning via non-parametric instance discrimination."Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
7. Grill, Jean-Bastien, et al. "Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning."arXiv preprint arXiv:2006.07733(2020).
小白團(tuán)隊(duì)出品:零基礎(chǔ)精通語(yǔ)義分割↓↓↓

交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~