
自監(jiān)督學(xué)習(xí)BYOL中的魔鬼BN

極市導(dǎo)讀
?在復(fù)現(xiàn)BYOL的過程中,研究者發(fā)現(xiàn)batch normalization在其中起到了關(guān)鍵作用。這強(qiáng)調(diào)了正例與負(fù)例之間對比的重要性,并有助于理解自監(jiān)督學(xué)習(xí)的原理。
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
論文鏈接:https://arxiv.org/abs/2006.07733
1、Summary
與SimCLR和MoCo等先前的研究不同,這篇來自DeepMind的論文Bootstrap Your Own Lentent(BYOL)展示了一種最先進(jìn)的方法,可以在沒有明顯對比損失函數(shù)的情況下,對圖像表示進(jìn)行self-supervised(自監(jiān)督學(xué)習(xí)),其通過消除損失函數(shù)中的負(fù)示例來簡化訓(xùn)練。我們在復(fù)現(xiàn)BYOL的工作中有兩個令人驚訝的發(fā)現(xiàn):
1) 當(dāng)batch normalization被刪除時,BYOL的性能通常不比random好;
2)batch normalization的存在隱含地導(dǎo)致了一種形式的contrastive learning(對比學(xué)習(xí))。
這些發(fā)現(xiàn)強(qiáng)調(diào)了學(xué)習(xí)表征時,正例和負(fù)例之間的對比的重要性,并幫助我們更好地理解自監(jiān)督學(xué)習(xí)是如何工作以及為什么工作。
Code:https://github.com/untitled-ai/self_supervised
2、Why does self-supervised learning matter?
機(jī)器學(xué)習(xí)通常是在監(jiān)督下完成的:我們使用由“輸入”和“標(biāo)簽”組成的數(shù)據(jù)集來尋找從輸入數(shù)據(jù)映射到正確答案的最佳函數(shù)。相比之下,在自監(jiān)督學(xué)習(xí)中,數(shù)據(jù)集中沒有給出“標(biāo)簽”。相反,我們學(xué)習(xí)一個將輸入數(shù)據(jù)映射到自身的函數(shù),例如:使用圖像的右半部分來預(yù)測圖像的左半部分。
從語言到圖像和音頻,這種方法已經(jīng)被證明是成功的。事實(shí)上,最新的語言模型,從word2vec到BERT和GPT-3,都是自監(jiān)督方法的例子。最近,這種方法在音頻和圖像方面也取得了一些令人難以置信的結(jié)果,一些人認(rèn)為它可能是人智能的重要組成部分。這篇文章主要討論圖像表示的自監(jiān)督學(xué)習(xí)。
3、State of the art in self-supervised learning
3.1、Contrastive learning
直到幾個月前BYOL發(fā)布,性能最好的算法是MoCo和SimCLR。MoCo和SimCLR都是對比學(xué)習(xí)的例子。
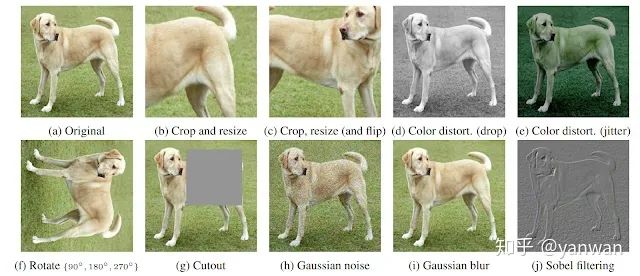
Contrastive learning是訓(xùn)練一個分類器來區(qū)分“相似”和“不同”輸入數(shù)據(jù)的過程。特別是對于MoCo和SimCLR,分類器的正面示例是同一圖像的修改版本,而反面示例是同一數(shù)據(jù)集中的其他圖像。例如,假設(shè)有一張狗的照片。在這種情況下,正面示例可以是該圖像的不同作物(見下圖),而反面示例可以是來自完全不同圖像的作物。
3.2、BYOL: self-supervised learning without contrastive learning? Not exactly.
MoCo和SimCLR在其損失函數(shù)中使用了正反兩個例子之間的對比學(xué)習(xí),而BYOL在損失函數(shù)中只使用了正例子。乍一看,在自學(xué)習(xí)的過程中,他們看起來完全不同。然而,BYOL有效的主要原因似乎是它在進(jìn)行一種形式的對比學(xué)習(xí)——只是通過一種間接的機(jī)制。
為了更深入地理解BYOL中的這種間接對比學(xué)習(xí),我們應(yīng)該首先回顧一下這些算法是如何工作的。
3.3、SimCLR
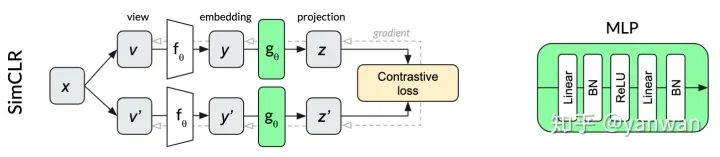
SimCLR是一種特別優(yōu)雅的自監(jiān)督算法,它設(shè)法簡化了以前的方法,使其基本核心得到簡化,并提高了它們的性能。同一圖像x的兩個變換v和v'通過同一個網(wǎng)絡(luò)來產(chǎn)生兩個投影z和z'。對比損失的目的是最大化來自同一輸入x的兩個投影的相似性,同時最小化與同一小批量內(nèi)其他圖像投影的相似性。繼續(xù)我們的dog示例,同一個dog圖像的不同作物的投影有望比同一批中其他隨機(jī)圖像中的作物更相似。
SimCLR中用于投影的多層感知器(MLP)在每個線性層之后使用batch normalization。
3.4、MoCo
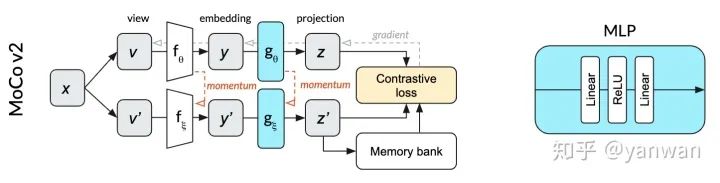
相對于SimCLR,MoCo v2成功地減少了批處理大小(從4096減少到256)和提高性能。與SimCLR不同,圖中的頂行和底行表示相同的網(wǎng)絡(luò)(由θ參數(shù)化),MoCo將單個網(wǎng)絡(luò)拆分為θ參數(shù)化的在線網(wǎng)絡(luò)(頂行)和ξ參數(shù)化的動量網(wǎng)絡(luò)(下排)。在線網(wǎng)絡(luò)采用隨機(jī)梯度下降法進(jìn)行更新,動量網(wǎng)絡(luò)則基于在線網(wǎng)絡(luò)權(quán)值的指數(shù)移動平均值進(jìn)行更新。動量網(wǎng)絡(luò)允許MoCo有效地利用過去預(yù)測的記憶庫作為對比損失的反面例子。這個內(nèi)存庫使批處理的規(guī)模小得多。在我們的狗圖像插圖中,正面的例子是相同圖像的狗的作物。反面例子是在過去的小批量中使用的完全不同的圖像,它們的投影存儲在內(nèi)存庫中。
MoCo v2中用于投影的MLP不使用batch normalization。
3.5、BYOL
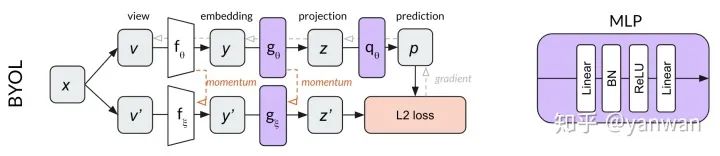
BYOL建立在MoCo動量網(wǎng)絡(luò)概念的基礎(chǔ)上,添加了一個MLP來從z預(yù)測p’,而不是使用對比損失,BYOL使用歸一化預(yù)測p’和目標(biāo)z’之間的L2 loss。繼續(xù)使用我們的dog image示例,BYOL嘗試將dog圖像的兩個裁剪轉(zhuǎn)換為相同的表示向量(使p和z’相等)。因?yàn)檫@個損失函數(shù)不需要負(fù)示例,所以在BYOL中沒有內(nèi)存庫的用處。
BYOL中的兩個MLP僅在第一個線性層之后使用批處理標(biāo)準(zhǔn)化。
通過上面的描述,通過以上描述,無需在多個不同圖像之間進(jìn)行顯式對比的情況,似乎BYOL仍然可以學(xué)習(xí)。然而,令人驚訝的是,我們發(fā)現(xiàn)BYOL不僅在做對比學(xué)習(xí),而且對比學(xué)習(xí)對其成功至關(guān)重要。
4、Our surprising results
我們最初使用為MoCo編寫的代碼在PyTorch中實(shí)現(xiàn)了BYOL。當(dāng)我們開始訓(xùn)練我們的網(wǎng)絡(luò)時,我們發(fā)現(xiàn)我們的網(wǎng)絡(luò)表現(xiàn)并不比隨機(jī)網(wǎng)絡(luò)好。將我們的代碼與另一個可用的實(shí)現(xiàn)進(jìn)行比較時,我們發(fā)現(xiàn)MLP中缺少批次標(biāo)準(zhǔn)化。我們非常驚訝批處理規(guī)范化對于訓(xùn)練BYOL是至關(guān)重要的,而mocov2根本不需要它。
在我們的初始測試中,我們在STL-10無監(jiān)督數(shù)據(jù)集上訓(xùn)練了ResNet-18和BYOL,使用的是具有動量的SGD,batch size=2563。有關(guān)數(shù)據(jù)擴(kuò)充的詳細(xì)信息,請參見附錄B。以下是在MLPs中對同一個BYOL算法進(jìn)行批量標(biāo)準(zhǔn)化和不進(jìn)行批量標(biāo)準(zhǔn)化的前十個階段的訓(xùn)練。
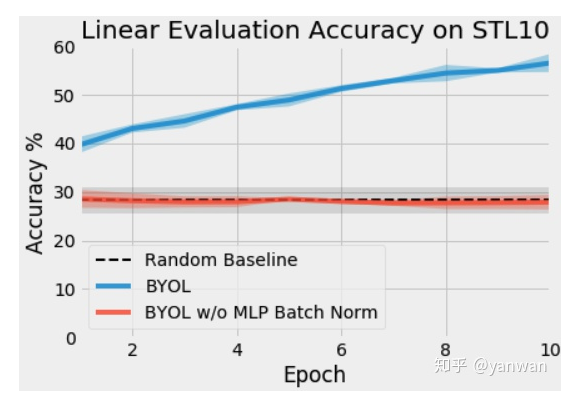
4.1、Why did this happen?
為了研究這種戲劇性的性能變化的原因,我們進(jìn)行了一些額外的實(shí)驗(yàn)。
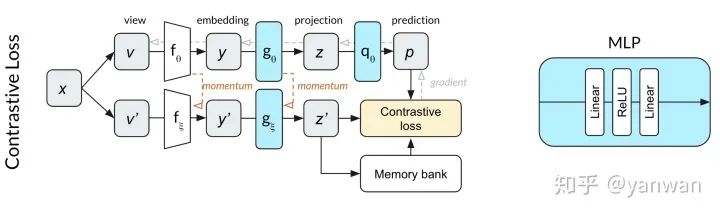
由于預(yù)測MLP q與MoCo相比改變了網(wǎng)絡(luò)深度,我們想知道是否需要批量規(guī)范化來規(guī)范化該網(wǎng)絡(luò)。也就是說,雖然MoCo不需要批處理標(biāo)準(zhǔn)化,但是在與額外的預(yù)測MLP配對時,MoCo可能確實(shí)需要批處理規(guī)范化。為了測試這一點(diǎn),我們開始使用對比損失函數(shù)訓(xùn)練上面顯示的網(wǎng)絡(luò)。我們發(fā)現(xiàn),在10個epochs內(nèi),網(wǎng)絡(luò)的性能明顯優(yōu)于隨機(jī)網(wǎng)絡(luò)。這一結(jié)果使我們懷疑不使用對比損失函數(shù)會導(dǎo)致訓(xùn)練依賴于批標(biāo)準(zhǔn)化。
然后我們想知道另一種類型的正常化是否會產(chǎn)生同樣的效果。我們將Layer Normalization應(yīng)用于MLPs,而不是batch normalization,并用BYOL訓(xùn)練網(wǎng)絡(luò)。在MLPs沒有normalization的實(shí)驗(yàn)中,性能并不比隨機(jī)性好。這個結(jié)果告訴我們,在同一小批量中激活其他輸入對于幫助BYOL查找有用的表示形式至關(guān)重要。
接下來,我們想知道在預(yù)測MLP g和預(yù)測MLP q中是否需要batch normalization,或者兩者都需要。我們的實(shí)驗(yàn)表明,batch normalization在MLP中是最有用的,但是在任何一個MLP中,網(wǎng)絡(luò)就可以學(xué)習(xí)到有用的表示,也就是說:一個mlp中的一個batch normalization足以讓網(wǎng)絡(luò)學(xué)習(xí)。
4.2、Performance for each variation
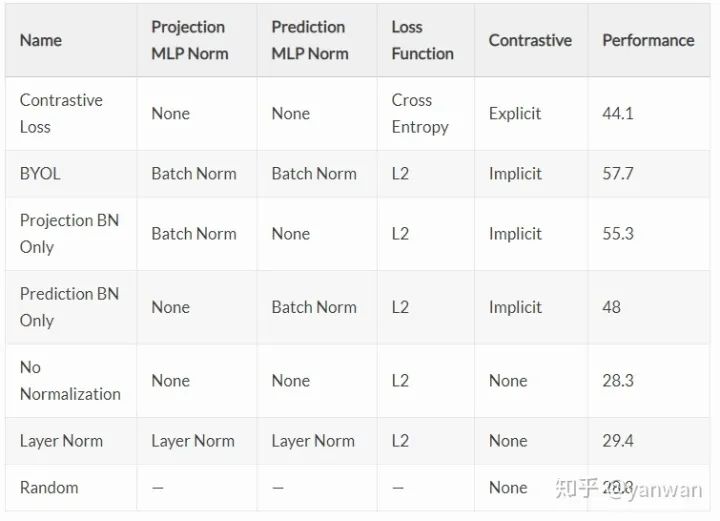
總結(jié)目前的研究結(jié)果:在沒有對比損失函數(shù)的情況下,BYOL的訓(xùn)練取決于一個與小批量中其他輸入激活相關(guān)的batch normalization。
4.3、Why batch normalization is critical in BYOL: mode collapse
對比損失函數(shù)中否定例子的一個目的是防止模式崩潰。模式崩潰的一個例子是始終輸出[1,0,0,0,…]作為其投影向量z的網(wǎng)絡(luò)。如果所有投影向量z都相同,則該網(wǎng)絡(luò)只需學(xué)習(xí)的單位函數(shù)就可以達(dá)到完美的預(yù)測精度!
在這種情況下,batch normalization的重要性變得更加明顯。如果在投影層中使用batch normalization,則投影輸出向量z不能塌陷為任何奇異值,如[1,0,0,0,…],因?yàn)檫@正是batch normalization所阻止的。不管輸入是怎樣,輸出都將根據(jù)學(xué)習(xí)到的平均值和標(biāo)準(zhǔn)差重新分配。模式崩潰的預(yù)防正是因?yàn)樵赽atch normalization之后,小批次中的所有樣本都不能采用相同的值。
Batch normalization在預(yù)測MLP中也會產(chǎn)生類似的效果。如果小批量輸入非常相似,函數(shù)將無法學(xué)習(xí)身份函數(shù):batch normalization將通過向量空間重新分配激活,因此最終層預(yù)測都是非常不同的。此函數(shù)僅在預(yù)測投影向量z'時成功,前提是這些向量z'在表示空間中足夠好地分離(即:沒有折疊),因?yàn)轭A(yù)測p被約束為在小批量中很好地分離。
4.4、Why batch normalization is implicit contrastive learning: all examples are compared to the mode
我們的研究結(jié)果似乎與一個簡單的結(jié)論相一致:防止模式崩潰的一個方法是區(qū)分例子之間的共同模式。Batch normalization在小批量實(shí)例之間標(biāo)識這種公共模式,并通過使用小批次中的其他表示作為隱式否定示例來刪除它。因此,我們可以將Batch normalization看作是在embedded representations上實(shí)現(xiàn)對比學(xué)習(xí)的一種新方法。
從另一個角度來說,通過批量標(biāo)準(zhǔn)化,BYOL通過詢問“這個圖像與普通圖像有何不同?”。SimCLR和MoCo使用的明確對比方法是通過詢問“這兩個特定圖像之間的區(qū)別是什么?”。這兩種方法似乎是等價的,因?yàn)閷⒁环鶊D像與許多其他圖像進(jìn)行比較具有與其他圖像的平均值相同的效果。例如,原型對比學(xué)習(xí)就利用了這種等價性。
4.5、Confirming our suspicions
假設(shè)上述情況屬實(shí)(刪除batch normalization會導(dǎo)致BYOL模式崩潰)。在這種情況下,我們應(yīng)該看到所有的表示和投影(z、z'和向量p)都是相等的——這正是我們所看到的。
在訓(xùn)練了上述每個變量后,我們測量了第一輸入投影向量z和第二輸入投影向量z'的余弦相似性。在訓(xùn)練的第十個epoch后,我們測量了每個小樣本的正樣本(藍(lán)色)投影之間的平均余弦相似性,以及同一小批次(紅色)的陰性樣本投影之間的相似性。
在g或q中沒有批處理標(biāo)準(zhǔn)化,投影與正示例和負(fù)示例(0.9999)高度一致,這表明表示向公共向量塌陷。因?yàn)閘ayer normalization不引入對比學(xué)習(xí),所以它也會導(dǎo)致正、負(fù)表示對齊。對于標(biāo)準(zhǔn)的BYOL訓(xùn)練(即使用batch normalization),我們得到了不同的向量,正如預(yù)期的那樣。正例(0.88)比負(fù)例(0.27)之間的投影更相似。
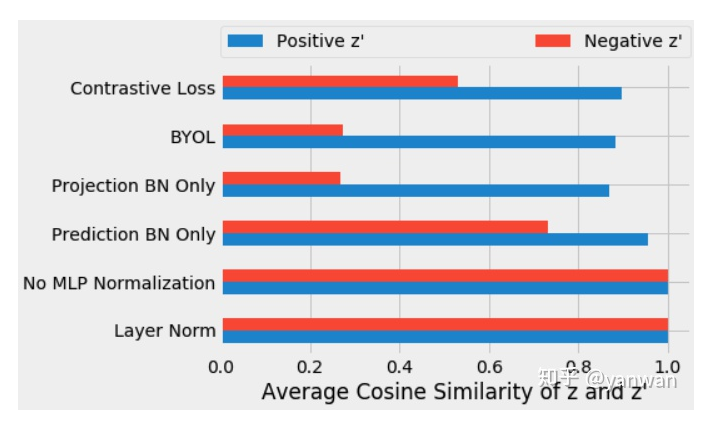
這些結(jié)果支持了我們對batch normalization的理解,即隱含地引入了使用小批量統(tǒng)計的對比學(xué)習(xí)。
5、Additional experiments
5.1、Earlier batch normalization layers have the same effect (eventually)
到目前為止,我們只看到了前10個時期的訓(xùn)練。當(dāng)我們訓(xùn)練更長時間時,我們發(fā)現(xiàn)ResNet編碼器中的batch normalization與MLPs中的batch normalization具有相似的效果。在編碼器中(而不是在MLPs中)進(jìn)行batch normalization后,網(wǎng)絡(luò)首先學(xué)習(xí)具有折疊表示的函數(shù),然后逐漸開始從正示例中分離負(fù)示例。
5.2、Removing all batch normalization completely prevents learning — unless at least one technique is used to prevent mode collapse.
當(dāng)我們從ResNet編碼器中刪除batch normalization并使用SGD訓(xùn)練網(wǎng)絡(luò)時,它無法學(xué)習(xí)任何東西(正是由于我們上面描述的原因)。
然而,當(dāng)我們聯(lián)系到作者時,他們善意地指出:在原來的BYOL論文,并沒有使用完全相同的設(shè)置。通過從SGD切換到分層學(xué)習(xí)速率自適應(yīng)(LARS)或增加權(quán)值衰減,我們的網(wǎng)絡(luò)能夠再次學(xué)習(xí)(盡管性能顯著下降)。
我們研究了每一種技術(shù),發(fā)現(xiàn)它們只是防止模式崩潰的替代方法。此外,它們自身的魯棒性明顯降低——它們依賴于仔細(xì)的超參數(shù)調(diào)整,而沒有這種調(diào)整,它們很容易出現(xiàn)模式崩潰,相應(yīng)地,它們的性能也很糟糕。因此,我們得出結(jié)論,batch normalization似乎是防止BYOL模式崩潰的最健壯的技術(shù)。
6、Conclusions
我們發(fā)現(xiàn)非常有趣的是,即使在損失函數(shù)中沒有負(fù)樣本,batch normalization也隱含地引入了BYOL中的對比學(xué)習(xí)。這一發(fā)現(xiàn)在事后看來是有意義的——當(dāng)模式崩潰時沒有學(xué)習(xí),而batch normalization使模式崩潰變得不可能!無論是將不同的圖像相互對比,還是將每個圖像與所有圖像的平均值進(jìn)行對比,學(xué)習(xí)的一個主要部分是了解事物之間的差異。
除了闡明了batch normalization在對比學(xué)習(xí)中的工作原理外,本文還可以作為一堂關(guān)于batch normalization如何產(chǎn)生意想不到的副作用的一課。通過batch normalization,網(wǎng)絡(luò)輸出不再是學(xué)習(xí)相應(yīng)輸入的純函數(shù)。由于這個和其他原因,在訓(xùn)練中避免batch normalization可能是值得的。我們建議其他實(shí)踐者也許應(yīng)該默認(rèn)使用layer normalization或者weight standardization with group normalization。
相反,這也是未來工作的一個有趣的途徑。與其因?yàn)檫@種隱式對比效應(yīng)而避免batch normalization,不如直接利用它,允許隱式對比學(xué)習(xí)在最后一層以外的層進(jìn)行。一個有趣的開放性問題是,batch normalization在訓(xùn)練神經(jīng)網(wǎng)絡(luò)方面的成功有多大程度上是由這種內(nèi)部表示的分離直接引起的。
最后,我們發(fā)現(xiàn)有趣的是,即使在沒有顯式對比損失或隱式對比機(jī)制的情況下,BYOL(使用正確的超參數(shù))也可以通過batch normalization學(xué)習(xí)一些東西。雖然我們不建議任何實(shí)踐者在實(shí)踐中使用這些網(wǎng)絡(luò),但我們認(rèn)為它們是對該領(lǐng)域的一個新穎而有趣的貢獻(xiàn),并且他們的行為潛在地提供了一個價值點(diǎn),為什么這些技術(shù)(重量衰減、重量標(biāo)準(zhǔn)化和LAR)如此有效。
參考資料
[1]https://untitled-ai.github.io/understanding-self-supervised-contrastive-learning.html#fn:ssup
[2]Prototypical Contrastive Learning
推薦閱讀
