
如何優(yōu)雅地實現(xiàn)多頭自注意力
本文使用 einsum 和 einops 來實現(xiàn)自注意力 self-attention 及其多頭版本。
1為什么用它們?
首先,einsum 和 einops 代碼干凈優(yōu)雅。
讓我們看一個例子:比如你想合并一個 4D 張量的 2 個維度,第一個和最后一個。
x?=?x.permute(0,?3,?1,?2)
N,?W,?C,?H?=?x.shape
x?=?x.contiguous().view(N?*?W,?C,?-1)
x?=?einops.rearrange(x,?'b?c?h?w?->?(b?w)?c?h')
其次,如果你要實現(xiàn)具有多維張量的自定義層,那么 einsum 絕對應(yīng)該在你的工具庫中!
再者,將代碼從 PyTorch 轉(zhuǎn)化成 TensorFlow 或 NumPy 將變得非常便捷。
當(dāng)然,你需要一定時間來適應(yīng)它的使用套路。結(jié)合實例來學(xué)習(xí)將更加高效,本文將實用它來實現(xiàn)一些自注意力機(jī)制。
.Einsum .
所謂愛因斯坦求和約定,簡而言之,就是使用如下結(jié)構(gòu) einsum 命令:
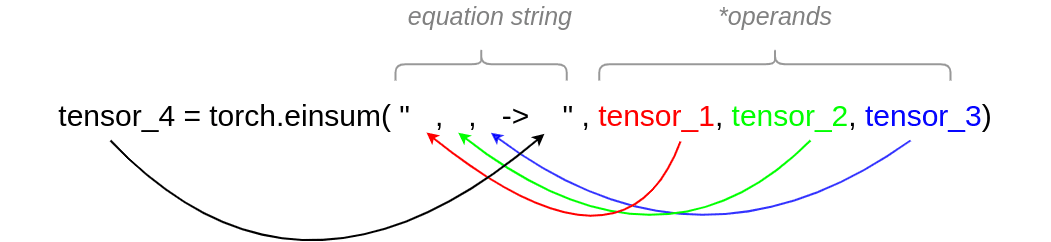
我們可以將 einsum 的參數(shù)分成兩部分:
等式字符串(Equation string):這是所有索引所在的位置。每個索引將指示張量的維度。為此,我們使用小寫字母。對于將在多個張量的等維軸上執(zhí)行的操作,我們必須使用相同的符號。
->左側(cè)的逗號個數(shù)要與使用的張量一樣多,彩色箭頭指明了對應(yīng)關(guān)系。在->的右側(cè)是操作的輸出索引,需要與輸出維度一樣多的索引。我們在輸出中使用的字母(索引)必須存在于等式字符串的右側(cè)。操作數(shù)(Operands):我們可以提供任意數(shù)量的張量。顯然,張量的數(shù)量必須與
->方程的左邊部分完全相同。
.示例:批量矩陣乘法 .
假設(shè)我們有 2 個具有以下形狀的張量,我們想在 Pytorch 中執(zhí)行批量矩陣乘法:
A?=?torch.randn(10,?20,?30)?#?b?->?10,?i?->?20,?k?->?30
C?=?torch.randn(10,?50,?30)?#?b?->?10,?j?->?50,?k?->?30
使用 einsum,可以用一個優(yōu)雅的命令清楚地說明它:
y1?=?torch.einsum('b?i?k,?b?j?k?->?b?i?j',?A,?C)?#?shape?[10,?20,?50]
這個命令對應(yīng)如下公式,
如果沒有 einsum,我們將不得不置換 C 的軸,還必須記住 Pytorch 的批量矩陣乘法命令。
y2?=?torch.bmm(A,?C.permute(0,?2,?1))
因為 torch.bmm 有它自己的章法,我們必須按照它的要求來。
torch.bmm(input, mat2, deterministic=False, out=None) → Tensor
執(zhí)行輸入和 mat2 中存儲的矩陣的批量矩陣矩陣乘積。
input 和 mat2 必須是 3-D 張量,每個張量都包含相同數(shù)量的矩陣。
例如,input 是一個 (b×n×m) 張量,mat2 是一個 (b×m×p) 張量,輸出將是一個 (b×n×p) 張量。
.Einops .
盡管 einops 是一個通用庫,但在這里主要使用 einops.rearrange。
在 einops 中,方程字符串完全相同,但參數(shù)順序與 einsum 顛倒了。你首先指定張量或張量列表。

從下劃線的數(shù)量可以理解,這個操作會將維度中的一些合并到一起(組合)。在箭頭字符串的左側(cè),我們有 4 個輸入維度,而在右側(cè),僅剩下三個。
雖然運算表達(dá)式在形式上與 einsum 有些類似,但意義不同,在 einsum 那里能意味著沿若干個軸求和(sum)。
einops 還能靈活地分解軸!下面是一個例子:
#?隨機(jī)生成一個張量,僅用于演示
qkv?=?torch.rand(2,128,3*512)?
#?分解成?n=3?個張量?q,?v,?k
#?rearrange?張量為?[3,?batch,?tokens,?dim]?
q,?k,?v?=?tuple(rearrange(?qkv?,?'b?t?(d?n)?->?n?b?t?d?',?n=3))
我們將軸分解成 3 個相等的部分!請注意,為了分解軸,你需要指定分解的具體形式,比如上面的 (d 3),但要注意它與 (3 d) 的區(qū)別。tuple 命令將使用第一個張量的維度,它將創(chuàng)建一個包含 n=3 個張量的元組。
約定:在本文中,我在對單個張量進(jìn)行操作時使用
einops.rearrange,在對多個張量進(jìn)行求和操作時使用torch.einsum。
.軸索引規(guī)則 .
與 einops 的區(qū)別在于,你可以使用多個小寫字母來索引維度。例如,你可以這樣子來展平一個 2D 張量:abc, defg -> (abc defg)。為方便起見,我們在 torch.einsum 操作中使用單個字母進(jìn)行索引。
我們將根據(jù)算法中涉及的數(shù)學(xué)公式來將自注意力模塊分解成若干個步驟。
2Scaled 點積自注意力
第 1 步:創(chuàng)建線性投影。
給定輸入
為了更輕松理解各個步驟,不妨對公式給些圖示。如下圖,我們假設(shè)
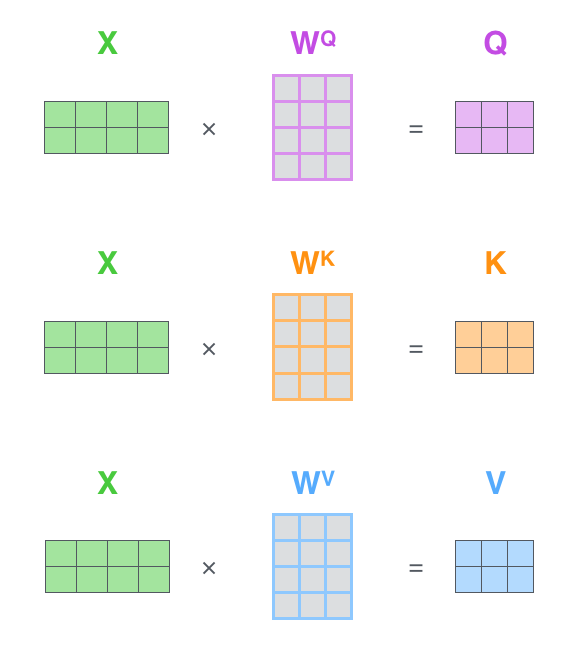
#?初始化
to_qvk?=?nn.Linear(dim,?dim?*?3,?bias=False)?
#?步驟?1
qkv?=?to_qvk(x)??#?[batch,?tokens,?dim*3?]
#?分解為?q,v,k
q,?k,?v?=?tuple(rearrange(qkv,?'b?t?(d?k)?->?k?b?t?d?',?k=3))
第?2 步: 計算 scaled 點積,應(yīng)用 mask(如果需要的話),最后計算
#?輸出張量的?shape:?[batch,?tokens,?tokens]
scaled_dot_prod?=?torch.einsum('b?i?d?,?b?j?d?->?b?i?j',?q,?k)?*?self.scale_factor
if?mask?is?not?None:
????assert?mask.shape?==?scaled_dot_prod.shape[1:]
????scaled_dot_prod?=?scaled_dot_prod.masked_fill(mask,?-np.inf)
attention?=?torch.softmax(scaled_dot_prod,?dim=-1)
第 3 步:將分?jǐn)?shù)與
torch.einsum('b?i?j?,?b?j?d?->?b?i?d',?attention,?v)
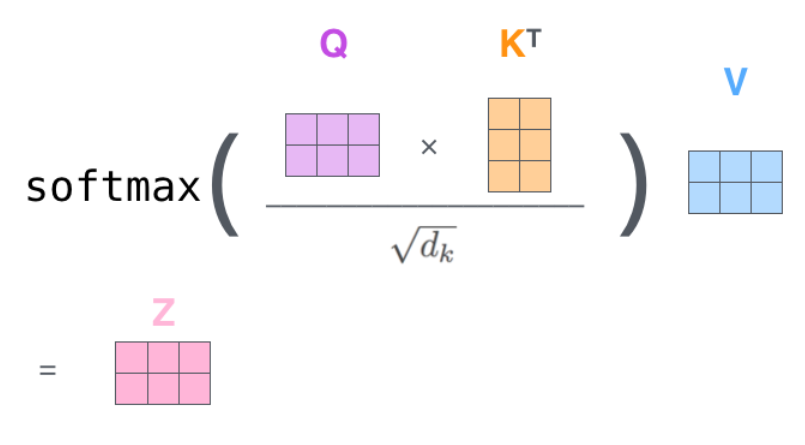
看另一個較完整的圖,這里
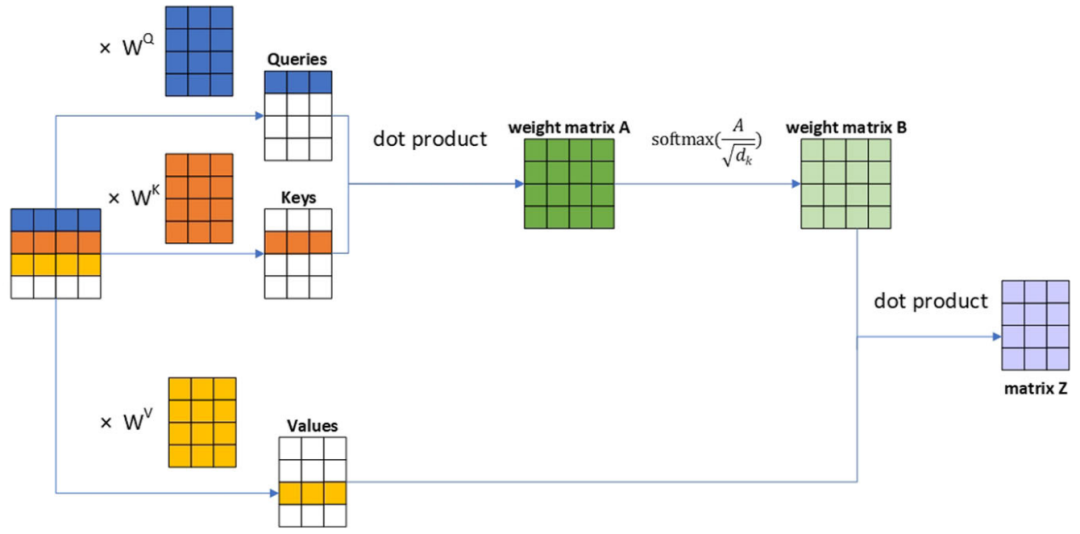
.自注意力完整實現(xiàn) .
import?numpy?as?np
import?torch
from?einops?import?rearrange
from?torch?import?nn
class?SelfAttentionAISummer(nn.Module):
????"""
????Implementation?of?plain?self?attention?mechanism?with?einsum?operations
????Paper:?https://arxiv.org/abs/1706.03762
????Blog:?https://theaisummer.com/transformer/
????"""
????def?__init__(self,?dim):
????????"""
????????Args:
????????????dim:?for?NLP?it?is?the?dimension?of?the?embedding?vector
????????????the?last?dimension?size?that?will?be?provided?in?forward(x),
????????????where?x?is?a?3D?tensor
????????"""
????????super().__init__()
????????#?for?Step?1
????????self.to_qvk?=?nn.Linear(dim,?dim?*?3,?bias=False)
????????#?for?Step?2
????????self.scale_factor?=?dim?**?-0.5??#?1/np.sqrt(dim)
????def?forward(self,?x,?mask=None):
????????assert?x.dim()?==?3,?'3D?tensor?must?be?provided'
????????#?Step?1
????????qkv?=?self.to_qvk(x)??#?[batch,?tokens,?dim*3?]
????????#?decomposition?to?q,v,k
????????#?rearrange?tensor?to?[3,?batch,?tokens,?dim]?and?cast?to?tuple
????????q,?k,?v?=?tuple(rearrange(qkv,?'b?t?(d?k)?->?k?b?t?d?',?k=3))
????????#?Step?2
????????#?Resulting?shape:?[batch,?tokens,?tokens]
????????scaled_dot_prod?=?torch.einsum('b?i?d?,?b?j?d?->?b?i?j',?q,?k)?*?self.scale_factor
????????if?mask?is?not?None:
????????????assert?mask.shape?==?scaled_dot_prod.shape[1:]
????????????scaled_dot_prod?=?scaled_dot_prod.masked_fill(mask,?-np.inf)
????????attention?=?torch.softmax(scaled_dot_prod,?dim=-1)
????????#?Step?3
????????return?torch.einsum('b?i?j?,?b?j?d?->?b?i?d',?attention,?v)
注意 softmax 沿哪個軸操作很重要,這里我們使用了最后一個軸。
另外,我們?yōu)榫€性投影使用了單個線性層,這沒問題,因為它應(yīng)用了 3 次相同操作。最后我們將其分解為
3多頭自注意力
讓我們看看如何在計算中引入多個頭,而這種類型的注意力被稱為多頭自注意力(MHSA)。
直觀地看,我們將在低維空間(代碼中的 dim_head)中執(zhí)行多次計算,多次計算是完全獨立的。它在概念上類似于 batch size,你可以把它看成是一批低維的 self-attention。這也是 einsum 表現(xiàn)驚人的地方。

單個頭,
多個頭拼接,
上式右端對應(yīng)下圖,

完整的多頭圖示,
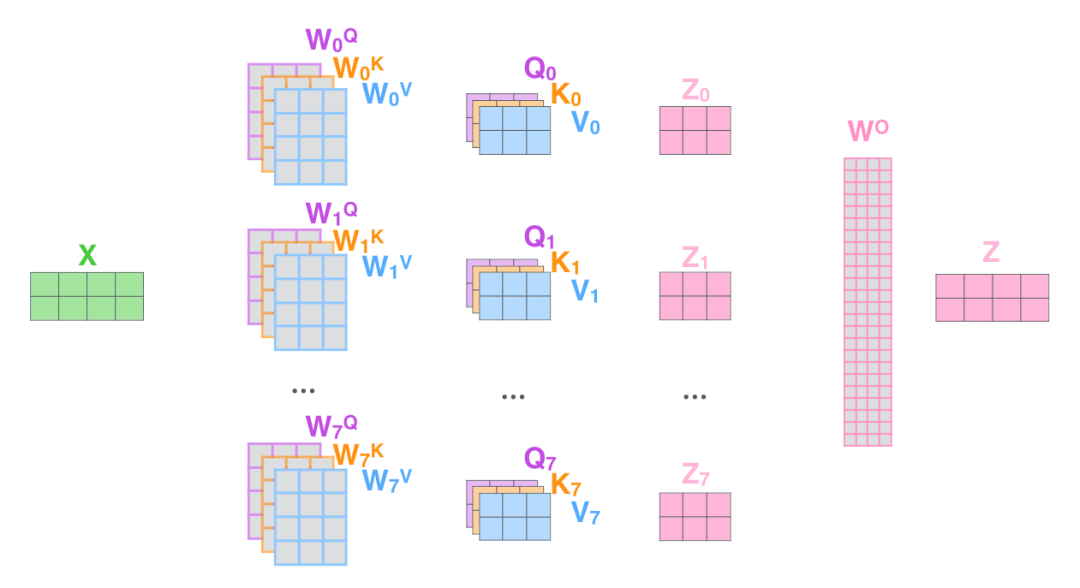
.MHSA 的實現(xiàn) .
import?numpy?as?np
import?torch
from?einops?import?rearrange
from?torch?import?nn
class?MultiHeadSelfAttentionAISummer(nn.Module):
????def?__init__(self,?dim,?heads=8,?dim_head=None):
????????"""
????????Implementation?of?multi-head?attention?layer?of?the?original?transformer?model.
????????einsum?and?einops.rearrange?is?used?whenever?possible
????????Args:
????????????dim:?token's?dimension,?i.e.?word?embedding?vector?size
????????????heads:?the?number?of?distinct?representations?to?learn
????????????dim_head:?the?dim?of?the?head.?In?general?dim_head????????????However,?it?may?not?necessary?be?(dim/heads)
????????"""
????????super().__init__()
????????self.dim_head?=?(int(dim?/?heads))?if?dim_head?is?None?else?dim_head
????????_dim?=?self.dim_head?*?heads
????????self.heads?=?heads
????????self.to_qvk?=?nn.Linear(dim,?_dim?*?3,?bias=False)
????????self.W_0?=?nn.Linear(?_dim,?dim,?bias=False)
????????self.scale_factor?=?self.dim_head?**?-0.5
????def?forward(self,?x,?mask=None):
????????assert?x.dim()?==?3
????????#?Step?1
????????qkv?=?self.to_qvk(x)??#?[batch,?tokens,?dim3heads?]
????????#?Step?2
????????#?decomposition?to?q,v,k?and?cast?to?tuple
????????#?the?resulted?shape?before?casting?to?tuple?will?be:
????????#?[3,?batch,?heads,?tokens,?dim_head]
????????q,?k,?v?=?tuple(rearrange(qkv,?'b?t?(d?k?h)?->?k?b?h?t?d?',?k=3,?h=self.heads))
????????#?Step?3
????????#?resulted?shape?will?be:?[batch,?heads,?tokens,?tokens]
????????scaled_dot_prod?=?torch.einsum('b?h?i?d?,?b?h?j?d?->?b?h?i?j',?q,?k)?*?self.scale_factor
????????if?mask?is?not?None:
????????????assert?mask.shape?==?scaled_dot_prod.shape[2:]
????????????scaled_dot_prod?=?scaled_dot_prod.masked_fill(mask,?-np.inf)
????????attention?=?torch.softmax(scaled_dot_prod,?dim=-1)
????????#?Step?4.?Calc?result?per?batch?and?per?head?h
????????out?=?torch.einsum('b?h?i?j?,?b?h?j?d?->?b?h?i?d',?attention,?v)
????????#?Step?5.?Re-compose:?merge?heads?with?dim_head?d
????????out?=?rearrange(out,?"b?h?t?d?->?b?t?(h?d)")
????????#?Step?6.?Apply?final?linear?transformation?layer
????????return?self.W_0(out)
參考資料
https://theaisummer.com/einsum-attention/
[2]https://jalammar.github.io/illustrated-transformer/