
3月31日美團(tuán)春招推薦算法崗面試題分享!
公眾號福利
??回復(fù)【100題】領(lǐng)取《名企AI面試100題》PDF
??回復(fù)【干貨資料】領(lǐng)取NLP、CV、ML等AI方向干貨資料
??回復(fù)【往期招聘】查看往期內(nèi)推招聘

拉至文末,找小助手進(jìn)群看公開課~


問題1:為什么分類問題損失不使用MSE而使用交叉熵
1、均方誤差作為損失函數(shù),這時(shí)所構(gòu)造出來的損失函數(shù)是非凸的,不容易求解,容易得到其局部最優(yōu)解;而交叉熵的損失函數(shù)是凸函數(shù);
2、均方誤差作為損失函數(shù),求導(dǎo)后,梯度與sigmoid的導(dǎo)數(shù)有關(guān),會導(dǎo)致訓(xùn)練慢;而交叉熵的損失函數(shù)求導(dǎo)后,梯度就是一個差值,誤差大的話更新的就快,誤差小的話就更新的慢點(diǎn)。

?
問題2:BN的作用,除了防止梯度消失這個作用外
(1)加快收斂速度:在深度神經(jīng)網(wǎng)絡(luò)中中,如果每層的數(shù)據(jù)分布都不一樣的話,將會導(dǎo)致網(wǎng)絡(luò)非常難收斂和訓(xùn)練,而如果把 每層的數(shù)據(jù)都在轉(zhuǎn)換在均值為零,方差為1 的狀態(tài)下,這樣每層數(shù)據(jù)的分布都是一樣的訓(xùn)練會比較容易收斂。
(2)控制梯度爆炸防止梯度消失:以sigmoid函數(shù)為例,sigmoid函數(shù)使得輸出在[0,1]之間,實(shí)際上當(dāng)x道了一定的大小,經(jīng)過sigmoid函數(shù)后輸出范圍就會變得很小。
(3)BN算法防止過擬合:在網(wǎng)絡(luò)的訓(xùn)練中,BN的使用使得一個minibatch中所有樣本都被關(guān)聯(lián)在了一起,因此網(wǎng)絡(luò)不會從某一個訓(xùn)練樣本中生成確定的結(jié)果,即同樣一個樣本的輸出不再僅僅取決于樣本的本身,也取決于跟這個樣本同屬一個batch的其他樣本,而每次網(wǎng)絡(luò)都是隨機(jī)取batch,這樣就會使得整個網(wǎng)絡(luò)不會朝這一個方向使勁學(xué)習(xí)。一定程度上避免了過擬合。
?
問題3:訓(xùn)練時(shí)出現(xiàn)不收斂的情況怎么辦,為什么會出現(xiàn)不收斂
從數(shù)據(jù)角度:
是否對數(shù)據(jù)進(jìn)行了預(yù)處理,包括分類標(biāo)注是否正確,數(shù)據(jù)是否干凈
是否對數(shù)據(jù)進(jìn)行了歸一化
考慮樣本的信息量是否太大,而網(wǎng)絡(luò)結(jié)構(gòu)是否太簡單
考慮標(biāo)簽是否設(shè)置正確
從模型角度:
嘗試加深網(wǎng)絡(luò)結(jié)構(gòu)
Learning rate是否合適(太大,會造成不收斂,太小,會造成收斂速度非常慢)
錯誤初始化網(wǎng)絡(luò)參數(shù)
train loss 不斷下降,test loss不斷下降,說明網(wǎng)絡(luò)仍在學(xué)習(xí);
train loss 不斷下降,test loss趨于不變,說明網(wǎng)絡(luò)過擬合;
train loss 趨于不變,test loss不斷下降,說明數(shù)據(jù)集100%有問題;
train loss 趨于不變,test loss趨于不變,說明學(xué)習(xí)遇到瓶頸,需要減小學(xué)習(xí)率或批量數(shù)目;
train loss 不斷上升,test loss不斷上升,說明網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)不當(dāng),訓(xùn)練超參數(shù)設(shè)置不當(dāng),數(shù)據(jù)集經(jīng)過清洗等問題。
問題4:LR與決策樹的區(qū)別
1、邏輯回歸通常用于分類問題,決策樹可回歸、可分類。
2、邏輯回歸是線性函數(shù),決策樹是非線性函數(shù)。
3、邏輯回歸的表達(dá)式很簡單,回歸系數(shù)就確定了模型。決策樹的形式就復(fù)雜了,葉子節(jié)點(diǎn)的范圍+取值。兩個模型在使用中都有很強(qiáng)的解釋性,銀行較喜歡。
4、邏輯回歸可用于高維稀疏數(shù)據(jù)場景,比如ctr預(yù)估;決策樹變量連續(xù)最好,類別變量的話,稀疏性不能太高。
5、邏輯回歸的核心是sigmoid函數(shù),具有無限可導(dǎo)的優(yōu)點(diǎn),常作為神經(jīng)網(wǎng)絡(luò)的激活函數(shù)。
6、在集成模型中,隨機(jī)森林、GBDT以決策樹為基模型,Boosting算法也可以用邏輯回歸作為基模型。
?
問題5:有哪些決策樹算法
ID3、C4.5、CART樹的算法思想
ID3算法的核心是在決策樹的每個節(jié)點(diǎn)上應(yīng)用信息增益準(zhǔn)則選擇特征,遞歸地構(gòu)架決策樹。
C4.5算法的核心是在生成過程中用信息增益比來選擇特征。
CART樹算法的核心是在生成過程用基尼指數(shù)來選擇特征。
基于決策樹的算法有隨機(jī)森林、GBDT、Xgboost等。
?
問題6:了解哪些行為序列建模方式
參考:https://zhuanlan.zhihu.com/p/138136777
?
問題7:Leetcode_91題:解碼方法
思路:動態(tài)規(guī)劃
class Solution:
def numDecodings(self, s: str) -> int:
n = len(s)
f = [1] + [0] * n
for i in range(1, n + 1):
if s[i - 1] != \'0\':
f[i] += f[i - 1]
if i > 1 and s[i - 2] != \'0\' and int(s[i-2:i]) <= 26:
f[i] += f[i - 2]
return f[n]
?
問題8:智力題:紅藍(lán)顏料比例問題
題目描述:兩個桶分別裝了一樣多的紅色和藍(lán)色的顏料。先從藍(lán)色桶里舀一杯倒入紅色中,攪拌不均勻。再從有藍(lán)色的紅色桶中舀一杯倒入藍(lán)色桶里,問兩個桶中藍(lán):紅與紅:藍(lán)的大小關(guān)系?
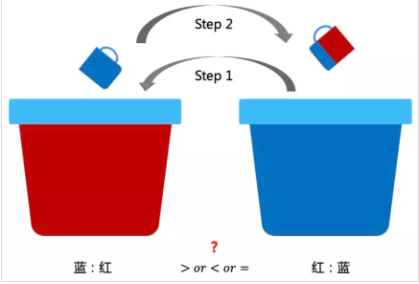
第二步舀的時(shí)候,因?yàn)椴痪鶆颍詿o法知道具體有多少比例的紅色和藍(lán)色,可以換一個角度來考慮。因?yàn)槭怯玫南嗤笮〉谋樱詢纱尾僮骱螅瑑蛇叺耐袄锏目傮w顏色是一樣多的。假設(shè)紅色里面混了一部分藍(lán)色的顏料體積為X升,那么就有X升的紅色顏料到了藍(lán)色的桶里,所以兩邊的比例是一樣的。
9、智力題:兩個人數(shù)數(shù),誰先數(shù)到20算誰贏。
要求:每次只能數(shù)1或者2個數(shù),采取什么策略可以保證必勝,先手和后手都可以選擇。
要想獲勝的規(guī)律就是要搶到19這個數(shù)
因?yàn)槭莾蓚€人參與,所以關(guān)鍵數(shù)是19,當(dāng)數(shù)到19時(shí),對方就只能數(shù)20了,所以可以反推一下,要想獲勝的話,在二十個數(shù)里,要想方設(shè)法地?fù)尩?9,16,13,10,7,4,1這幾個公差為3的整數(shù),也就是說在這個游戲里,要想獲勝的話,就要搶到1這個數(shù),即誰先數(shù)誰就獲勝。

私我回復(fù)"414"進(jìn)直播群
