
2021年春招Elasticsearch面試題

1、Elasticsearch是如何實(shí)現(xiàn)master選舉的?
1、對(duì)所有可以成為master的節(jié)點(diǎn)根據(jù)nodeId排序,每次選舉每個(gè)節(jié)點(diǎn)都把自己所知道節(jié)點(diǎn)排一次序,然后選出第一個(gè)(第0位)節(jié)點(diǎn),暫且認(rèn)為它是master節(jié)點(diǎn)。
2、如果對(duì)某個(gè)節(jié)點(diǎn)的投票數(shù)達(dá)到一定的值(可以成為master節(jié)點(diǎn)數(shù)n/2+1)并且該節(jié)點(diǎn)自己也選舉自己,那這個(gè)節(jié)點(diǎn)就是master。否則重新選舉。
3、對(duì)于brain split問題,需要把候選master節(jié)點(diǎn)最小值設(shè)置為可以成為master節(jié)點(diǎn)數(shù)n/2+1(quorum )2、詳細(xì)描述一下 Elasticsearch 索引文檔的過程。
1、當(dāng)分片所在的節(jié)點(diǎn)接收到來(lái)自協(xié)調(diào)節(jié)點(diǎn)的請(qǐng)求后,會(huì)將請(qǐng)求寫入到 MemoryBuffer,然后定時(shí)(默認(rèn)是每隔 1 秒)寫入到 Filesystem Cache,這個(gè)從 MomeryBuffer 到 Filesystem Cache 的過程就叫做 refresh;
2、當(dāng)然在某些情況下,存在 Momery Buffer 和 Filesystem Cache 的數(shù)據(jù)可能會(huì)丟失,ES 是通過 translog 的機(jī)制來(lái)保證數(shù)據(jù)的可靠性的。其實(shí)現(xiàn)機(jī)制是接收到請(qǐng)求后,同時(shí)也會(huì)寫入到 translog 中,當(dāng) Filesystem cache 中的數(shù)據(jù)寫入到磁盤中時(shí),才會(huì)清除掉,這個(gè)過程叫做 flush;
3、在 flush 過程中,內(nèi)存中的緩沖將被清除,內(nèi)容被寫入一個(gè)新段,段的 fsync將創(chuàng)建一個(gè)新的提交點(diǎn),并將內(nèi)容刷新到磁盤,舊的 translog 將被刪除并開始一個(gè)新的 translog。
4、flush 觸發(fā)的時(shí)機(jī)是定時(shí)觸發(fā)(默認(rèn) 30 分鐘)或者 translog 變得太大(默認(rèn)為 512M)時(shí);3、詳細(xì)描述一下 Elasticsearch 更新和刪除文檔的過程。
1、刪除和更新也都是寫操作,但是 Elasticsearch 中的文檔是不可變的,因此不能被刪除或者改動(dòng)以展示其變更。
2、磁盤上的每個(gè)段都有一個(gè)相應(yīng)的.del 文件。當(dāng)刪除請(qǐng)求發(fā)送后,文檔并沒有真的被刪除,而是在.del 文件中被標(biāo)記為刪除。該文檔依然能匹配查詢,但是會(huì)在結(jié)果中被過濾掉。當(dāng)段合并時(shí),在.del 文件中被標(biāo)記為刪除的文檔將不會(huì)被寫入新段。
3、在新的文檔被創(chuàng)建時(shí),Elasticsearch 會(huì)為該文檔指定一個(gè)版本號(hào),當(dāng)執(zhí)行更新時(shí),舊版本的文檔在.del 文件中被標(biāo)記為刪除,新版本的文檔被索引到一個(gè)新段。舊版本的文檔依然能匹配查詢,但是會(huì)在結(jié)果中被過濾掉。4、詳細(xì)描述一下 Elasticsearch 搜索的過程?
1、搜索被執(zhí)行成一個(gè)兩階段過程,我們稱之為 Query Then Fetch;
2、在初始查詢階段時(shí),查詢會(huì)廣播到索引中每一個(gè)分片拷貝(主分片或者副本分片)。每個(gè)分片在本地執(zhí)行搜索并構(gòu)建一個(gè)匹配文檔的大小為 from + size 的優(yōu)先隊(duì)列。
備注:在搜索的時(shí)候是會(huì)查詢 Filesystem Cache 的,但是有部分?jǐn)?shù)據(jù)還在 MemoryBuffer,所以搜索是近實(shí)時(shí)的。
3、每個(gè)分片返回各自優(yōu)先隊(duì)列中 所有文檔的 ID 和排序值 給協(xié)調(diào)節(jié)點(diǎn),它合并這些值到自己的優(yōu)先隊(duì)列中來(lái)產(chǎn)生一個(gè)全局排序后的結(jié)果列表。
4、接下來(lái)就是 取回階段,協(xié)調(diào)節(jié)點(diǎn)辨別出哪些文檔需要被取回并向相關(guān)的分片提交多個(gè) GET 請(qǐng)求。每個(gè)分片加載并 豐富 文檔,如果有需要的話,接著返回文檔給協(xié)調(diào)節(jié)點(diǎn)。一旦所有的文檔都被取回了,協(xié)調(diào)節(jié)點(diǎn)返回結(jié)果給客戶端。
5、補(bǔ)充:Query Then Fetch 的搜索類型在文檔相關(guān)性打分的時(shí)候參考的是本分片的數(shù)據(jù),這樣在文檔數(shù)量較少的時(shí)候可能不夠準(zhǔn)確,DFS Query Then Fetch 增加了一個(gè)預(yù)查詢的處理,詢問 Term 和 Document frequency,這個(gè)評(píng)分更準(zhǔn)確,但是性能會(huì)變差。5、Elasticsearch 對(duì)于大數(shù)據(jù)量(上億量級(jí))的聚合如何實(shí)現(xiàn)?
Elasticsearch 提供的首個(gè)近似聚合是 cardinality 度量。它提供一個(gè)字段的基數(shù),即該字段的 distinct 或者unique 值的數(shù)目。它是基于 HLL 算法的。HLL 會(huì)先對(duì)我們的輸入作哈希運(yùn)算,然后根據(jù)哈希運(yùn)算的結(jié)果中的 bits 做概率估算從而得到基數(shù)。其特點(diǎn)是:可配置的精度,用來(lái)控制內(nèi)存的使用(更精確 = 更多內(nèi)存);小的數(shù)據(jù)集精度是非常高的;我們可以通過配置參數(shù),來(lái)設(shè)置去重需要的固定內(nèi)存使用量。無(wú)論數(shù)千還是數(shù)十億的唯一值,內(nèi)存使用量只與你配置的精確度相關(guān)。6、在并發(fā)情況下,Elasticsearch 如果保證讀寫一致?
1、可以通過版本號(hào)使用樂觀并發(fā)控制,以確保新版本不會(huì)被舊版本覆蓋,由應(yīng)用層來(lái)處理具體的沖突;
2、另外對(duì)于寫操作,一致性級(jí)別支持 quorum/one/all,默認(rèn)為 quorum,即只有當(dāng)大多數(shù)分片可用時(shí)才允許寫操作。但即使大多數(shù)可用,也可能存在因?yàn)榫W(wǎng)絡(luò)等原因?qū)е聦懭敫北臼。@樣該副本被認(rèn)為故障,分片將會(huì)在一個(gè)不同的節(jié)點(diǎn)上重建。
3、對(duì)于讀操作,可以設(shè)置 replication 為 sync(默認(rèn)),這使得操作在主分片和副本分片都完成后才會(huì)返回;如果設(shè)置 replication 為 async 時(shí),也可以通過設(shè)置搜索請(qǐng)求參數(shù)_preference 為 primary 來(lái)查詢主分片,確保文檔是最新版本。7、ElasticSearch中的集群、節(jié)點(diǎn)、索引、文檔、類型是什么?
群集:一個(gè)或多個(gè)節(jié)點(diǎn)(服務(wù)器)的集合,它們共同保存您的整個(gè)數(shù)據(jù),并提供跨所有節(jié)點(diǎn)的聯(lián)合索引和搜索功能。群集由唯一名稱標(biāo)識(shí),默認(rèn)情況下為“elasticsearch”。此名稱很重要,因?yàn)槿绻?jié)點(diǎn)設(shè)置為按名稱加入群集,則該節(jié)點(diǎn)只能是群集的一部分。
節(jié)點(diǎn):屬于集群一部分的單個(gè)服務(wù)器。它存儲(chǔ)數(shù)據(jù)并參與群集索引和搜索功能。
索引:就像關(guān)系數(shù)據(jù)庫(kù)中的“數(shù)據(jù)庫(kù)”。它有一個(gè)定義多種類型的映射。索引是邏輯名稱空間,映射到一個(gè)或多個(gè)主分片,并且可以有零個(gè)或多個(gè)副本分片。
eg: MySQL =>數(shù)據(jù)庫(kù) ElasticSearch =>索引
文檔:類似于關(guān)系數(shù)據(jù)庫(kù)中的一行。不同之處在于索引中的每個(gè)文檔可以具有不同的結(jié)構(gòu)(字段),但是對(duì)于通用字段應(yīng)該具有相同的數(shù)據(jù)類型。
MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有屬性的文檔
類型:是索引的邏輯類別/分區(qū),其語(yǔ)義完全取決于用戶。8、Elasticsearch的倒排索引是什么?
1、倒排索引是搜索引擎的核心。搜索引擎的主要目標(biāo)是在查找發(fā)生搜索條件的文檔時(shí)提供快速搜索。倒排索引是一種像數(shù)據(jù)結(jié)構(gòu)一樣的散列圖,可將用戶從單詞導(dǎo)向文檔或網(wǎng)頁(yè)。它是搜索引擎的核心。其主要目標(biāo)是快速搜索從數(shù)百萬(wàn)文件中查找數(shù)據(jù)。
2、傳統(tǒng)的我們的檢索是通過文章,逐個(gè)遍歷找到對(duì)應(yīng)關(guān)鍵詞的位置。而倒排索引,是通過分詞策略,形成了詞和文章的映射關(guān)系表,這種詞典+映射表即為倒排索引。有了倒排索引,就能實(shí)現(xiàn)o(1)時(shí)間復(fù)雜度的效率檢索文章了,極大的提高了檢索效率。
學(xué)術(shù)的解答方式:
倒排索引,相反于一篇文章包含了哪些詞,它從詞出發(fā),記載了這個(gè)詞在哪些文檔中出現(xiàn)過,由兩部分組成——詞典和倒排表。
加分項(xiàng):倒排索引的底層實(shí)現(xiàn)是基于:FST(Finite State Transducer)數(shù)據(jù)結(jié)構(gòu)。
lucene從4+版本后開始大量使用的數(shù)據(jù)結(jié)構(gòu)是FST。FST有兩個(gè)優(yōu)點(diǎn):
1)空間占用小。通過對(duì)詞典中單詞前綴和后綴的重復(fù)利用,壓縮了存儲(chǔ)空間;
2)查詢速度快。O(len(str))的查詢時(shí)間復(fù)雜度。9、ElasticSearch中的分析器是什么?
1、在ElasticSearch中索引數(shù)據(jù)時(shí),數(shù)據(jù)由為索引定義的Analyzer在內(nèi)部進(jìn)行轉(zhuǎn)換。分析器由一個(gè)Tokenizer和零個(gè)或多個(gè)TokenFilter組成。編譯器可以在一個(gè)或多個(gè)CharFilter之前。分析模塊允許您在邏輯名稱下注冊(cè)分析器,然后可以在映射定義或某些API中引用它們。
2、Elasticsearch附帶了許多可以隨時(shí)使用的預(yù)建分析器。或者,您可以組合內(nèi)置的字符過濾器,編譯器和過濾器器來(lái)創(chuàng)建自定義分析器。10、啟用屬性,索引和存儲(chǔ)的用途是什么?
1、Enabled屬性適用于各類ElasticSearch特定/創(chuàng)建領(lǐng)域,如index和size。用戶提供的字段沒有“已啟用”屬性。存儲(chǔ)意味著數(shù)據(jù)由Lucene存儲(chǔ),如果詢問,將返回這些數(shù)據(jù)。
2、存儲(chǔ)字段不一定是可搜索的。默認(rèn)情況下,字段不存儲(chǔ),但源文件是完整的。因?yàn)槟M褂媚J(rèn)值(這是有意義的),所以不要設(shè)置store屬性 該指數(shù)屬性用于搜索。
3、索引屬性只能用于搜索。只有索引域可以進(jìn)行搜索。差異的原因是在分析期間對(duì)索引字段進(jìn)行了轉(zhuǎn)換,因此如果需要的話,您不能檢索原始數(shù)據(jù)。11、Elasticsearch了解多少,說說你們公司es的集群架構(gòu),索引數(shù)據(jù)大小,分片有多少,以及一些調(diào)優(yōu)手段 。
比如:ES集群架構(gòu)13個(gè)節(jié)點(diǎn),索引根據(jù)通道不同共20+索引,根據(jù)日期,每日遞增20+,索引:10分片,每日遞增1億+數(shù)據(jù),每個(gè)通道每天索引大小控制:150GB之內(nèi)。
僅索引層面調(diào)優(yōu)手段:
1.1、設(shè)計(jì)階段調(diào)優(yōu)
1)根據(jù)業(yè)務(wù)增量需求,采取基于日期模板創(chuàng)建索引,通過roll over API滾動(dòng)索引;
2)使用別名進(jìn)行索引管理;
3)每天凌晨定時(shí)對(duì)索引做force_merge操作,以釋放空間;
4)采取冷熱分離機(jī)制,熱數(shù)據(jù)存儲(chǔ)到SSD,提高檢索效率;冷數(shù)據(jù)定期進(jìn)行shrink操作,以縮減存儲(chǔ);
5)采取curator進(jìn)行索引的生命周期管理;
6)僅針對(duì)需要分詞的字段,合理的設(shè)置分詞器;
7)Mapping階段充分結(jié)合各個(gè)字段的屬性,是否需要檢索、是否需要存儲(chǔ)等。…
1.2、寫入調(diào)優(yōu)
1)寫入前副本數(shù)設(shè)置為0;
2)寫入前關(guān)閉refresh_interval設(shè)置為-1,禁用刷新機(jī)制;
3)寫入過程中:采取bulk批量寫入;
4)寫入后恢復(fù)副本數(shù)和刷新間隔;
5)盡量使用自動(dòng)生成的id。
1.3、查詢調(diào)優(yōu)
1)禁用wildcard;
2)禁用批量terms(成百上千的場(chǎng)景);
3)充分利用倒排索引機(jī)制,能keyword類型盡量keyword;
4)數(shù)據(jù)量大時(shí)候,可以先基于時(shí)間敲定索引再檢索;
5)設(shè)置合理的路由機(jī)制。
1.4、其他調(diào)優(yōu)部署調(diào)優(yōu),業(yè)務(wù)調(diào)優(yōu)等。12、Elasticsearch 索引數(shù)據(jù)多了怎么辦,如何調(diào)優(yōu),部署?
1 動(dòng)態(tài)索引層面
基于模板+時(shí)間+rollover api滾動(dòng)創(chuàng)建索引,舉例:設(shè)計(jì)階段定義:blog索引的模板格式為:blog_index_時(shí)間戳的形式,每天遞增數(shù)據(jù)。這樣做的好處:不至于數(shù)據(jù)量激增導(dǎo)致單個(gè)索引數(shù)據(jù)量非常大,接近于上線2的32次冪-1,索引存儲(chǔ)達(dá)到了TB+甚至更大。一旦單個(gè)索引很大,存儲(chǔ)等各種風(fēng)險(xiǎn)也隨之而來(lái),所以要提前考慮+及早避免。
2 存儲(chǔ)層面
冷熱數(shù)據(jù)分離存儲(chǔ),熱數(shù)據(jù)(比如最近3天或者一周的數(shù)據(jù)),其余為冷數(shù)據(jù)。對(duì)于冷數(shù)據(jù)不會(huì)再寫入新數(shù)據(jù),可以考慮定期force_merge加shrink壓縮操作,節(jié)省存儲(chǔ)空間和檢索效率。
3 部署層面
一旦之前沒有規(guī)劃,這里就屬于應(yīng)急策略。結(jié)合ES自身的支持動(dòng)態(tài)擴(kuò)展的特點(diǎn),動(dòng)態(tài)新增機(jī)器的方式可以緩解集群壓力,注意:如果之前主節(jié)點(diǎn)等規(guī)劃合理,不需要重啟集群也能完成動(dòng)態(tài)新增的。13、在使用 Elasticsearch 時(shí)要注意什么?
由于ES使用的Java寫的,所有注意的是GC方面的問題
1、倒排詞典的索引需要常駐內(nèi)存,無(wú)法 GC,需要監(jiān)控 data node 上 segmentmemory 增長(zhǎng)趨勢(shì)。
2、各類緩存,field cache, filter cache, indexing cache, bulk queue 等等,要設(shè)置合理的大小,并且要應(yīng)該根據(jù)最壞的情況來(lái)看 heap 是否夠用,也就是各類緩存全部占滿的時(shí)候,還有 heap 空間可以分配給其他任務(wù)嗎?避免采用 clear cache等“自欺欺人”的方式來(lái)釋放內(nèi)存。
3、避免返回大量結(jié)果集的搜索與聚合。確實(shí)需要大量拉取數(shù)據(jù)的場(chǎng)景,可以采用scan & scroll api 來(lái)實(shí)現(xiàn)。
4、cluster stats 駐留內(nèi)存并無(wú)法水平擴(kuò)展,超大規(guī)模集群可以考慮分拆成多個(gè)集群通過 tribe node 連接
5、想知道 heap 夠不夠,必須結(jié)合實(shí)際應(yīng)用場(chǎng)景,并對(duì)集群的 heap 使用情況做持續(xù)的監(jiān)控。14、Elasticsearch 支持哪些類型的查詢?
查詢主要分為兩種類型:精確匹配、全文檢索匹配。
精確匹配,例如 term、exists、term set、 range、prefix、 ids、 wildcard、regexp、 fuzzy等。
全文檢索,例如match、match_phrase、multi_match、match_phrase_prefix、query_string 等15、你能否列出與 Elasticsearch 有關(guān)的主要可用字段數(shù)據(jù)類型?
1、字符串?dāng)?shù)據(jù)類型,包括支持全文檢索的 text 類型 和 精準(zhǔn)匹配的 keyword 類型。
2、數(shù)值數(shù)據(jù)類型,例如字節(jié),短整數(shù),長(zhǎng)整數(shù),浮點(diǎn)數(shù),雙精度數(shù),half_float,scaled_float。
3、日期類型,日期納秒Date nanoseconds,布爾值,二進(jìn)制(Base64編碼的字符串)等。
4、范圍(整數(shù)范圍 integer_range,長(zhǎng)范圍 long_range,雙精度范圍 double_range,浮動(dòng)范圍 float_range,日期范圍 date_range)。
5、包含對(duì)象的復(fù)雜數(shù)據(jù)類型,nested 、Object。
6、GEO 地理位置相關(guān)類型。
7、特定類型如:數(shù)組(數(shù)組中的值應(yīng)具有相同的數(shù)據(jù)類型)16、如何監(jiān)控 Elasticsearch 集群狀態(tài)?
Marvel 讓你可以很簡(jiǎn)單的通過 Kibana 監(jiān)控 Elasticsearch。你可以實(shí)時(shí)查看你的集群健康狀態(tài)和性能,也可以分析過去的集群、索引和節(jié)點(diǎn)指標(biāo)。17、有了解過Elasticsearch的性化搜索方案嗎?
基于word2vec和Elasticsearch實(shí)現(xiàn)個(gè)性化搜索
(1)基于word2vec、Elasticsearch和自定義的腳本插件,我們就實(shí)現(xiàn)了一個(gè)個(gè)性化的搜索服務(wù),相對(duì)于原有的實(shí)現(xiàn),新版的點(diǎn)擊率和轉(zhuǎn)化率都有大幅的提升;
(2)基于word2vec的商品向量還有一個(gè)可用之處,就是可以用來(lái)實(shí)現(xiàn)相似商品的推薦;
(3)使用word2vec來(lái)實(shí)現(xiàn)個(gè)性化搜索或個(gè)性化推薦是有一定局限性的,因?yàn)樗荒芴幚碛脩酎c(diǎn)擊歷史這樣的時(shí)序數(shù)據(jù),而無(wú)法全面的去考慮用戶偏好,這個(gè)還是有很大的改進(jìn)和提升的空間;18、是否了解字典樹?
| 數(shù)據(jù)結(jié)構(gòu) | 優(yōu)缺點(diǎn) |
|---|---|
| Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,內(nèi)存消耗大,幾乎是原始數(shù)據(jù)的三倍 |
| Skip List | 跳躍表,可快速查找詞語(yǔ),在lucene,redis,HBase中有實(shí)現(xiàn) |
| Trie | 適合英文詞典,如果系統(tǒng)中存在大量字符串且這些字符串基本沒有公共前綴 |
| Double Array Trie | 適合做中文詞典,內(nèi)存占用小,很多分詞工具軍采用此種算法 |
| Ternary Search Tree | 一種有狀態(tài)的轉(zhuǎn)移機(jī),Lucene 4有開源實(shí)現(xiàn),并大量使用 |
Trie 的核心思想是空間換時(shí)間,利用字符串的公共前綴來(lái)降低查詢時(shí)間的開銷以
達(dá)到提高效率的目的。它有 3 個(gè)基本性質(zhì):
1、根節(jié)點(diǎn)不包含字符,除根節(jié)點(diǎn)外每一個(gè)節(jié)點(diǎn)都只包含一個(gè)字符。
2、從根節(jié)點(diǎn)到某一節(jié)點(diǎn),路徑上經(jīng)過的字符連接起來(lái),為該節(jié)點(diǎn)對(duì)應(yīng)的字符串。
3、每個(gè)節(jié)點(diǎn)的所有子節(jié)點(diǎn)包含的字符都不相同。
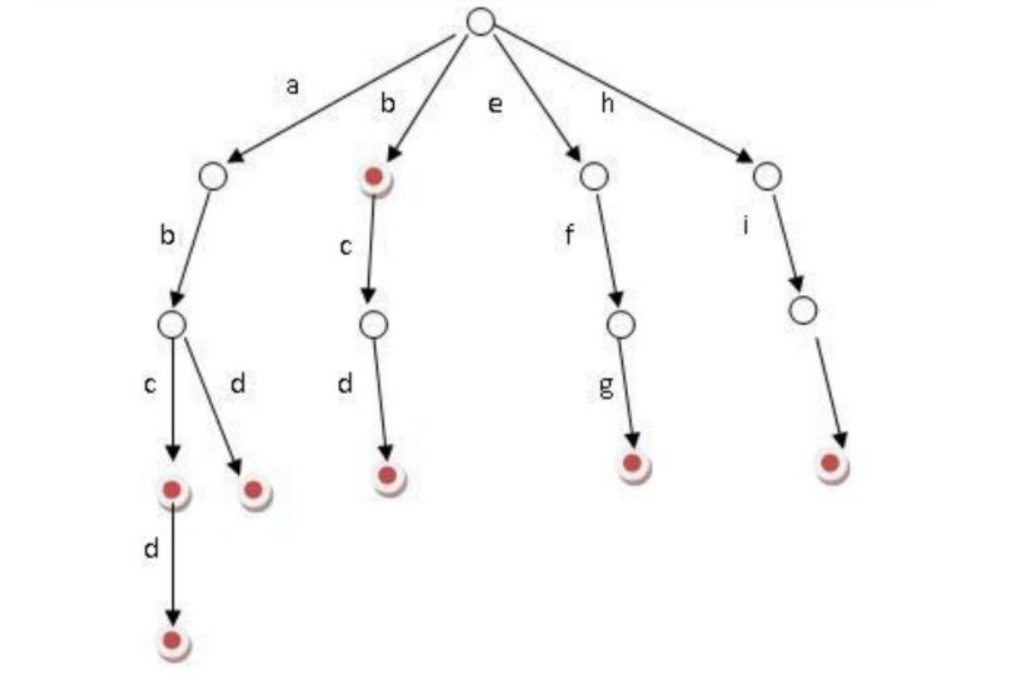
1、可以看到,trie 樹每一層的節(jié)點(diǎn)數(shù)是 26^i 級(jí)別的。所以為了節(jié)省空間,我們還可以用動(dòng)態(tài)鏈表,或者用數(shù)組來(lái)模擬動(dòng)態(tài)。而空間的花費(fèi),不會(huì)超過單詞數(shù)×單詞長(zhǎng)度。2、實(shí)現(xiàn):對(duì)每個(gè)結(jié)點(diǎn)開一個(gè)字母集大小的數(shù)組,每個(gè)結(jié)點(diǎn)掛一個(gè)鏈表,使用左兒子右兄弟表示法記錄這棵樹;3、對(duì)于中文的字典樹,每個(gè)節(jié)點(diǎn)的子節(jié)點(diǎn)用一個(gè)哈希表存儲(chǔ),這樣就不用浪費(fèi)太大的空間,而且查詢速度上可以保留哈希的復(fù)雜度 O(1)。
19、ElasticSearch是否有架構(gòu)?
1、ElasticSearch可以有一個(gè)架構(gòu)。架構(gòu)是描述文檔類型以及如何處理文檔的不同字段的一個(gè)或多個(gè)字段的描述。Elasticsearch中的架構(gòu)是一種映射,它描述了JSON文檔中的字段及其數(shù)據(jù)類型,以及它們應(yīng)該如何在Lucene索引中進(jìn)行索引。因此,在Elasticsearch術(shù)語(yǔ)中,我們通常將此模式稱為“映射”。
2、Elasticsearch具有架構(gòu)靈活的能力,這意味著可以在不明確提供架構(gòu)的情況下索引文檔。如果未指定映射,則默認(rèn)情況下,Elasticsearch會(huì)在索引期間檢測(cè)文檔中的新字段時(shí)動(dòng)態(tài)生成一個(gè)映射。20、為什么要使用Elasticsearch?
因?yàn)樵谖覀兩坛侵械臄?shù)據(jù),將來(lái)會(huì)非常多,所以采用以往的模糊查詢,模糊查詢前置配置,會(huì)放棄索引,導(dǎo)致商品查詢是全表掃面,在百萬(wàn)級(jí)別的數(shù)據(jù)庫(kù)中,效率非常低下,而我們使用ES做一個(gè)全文索引,我們將經(jīng)常查詢的商品的某些字段,比如說商品名,描述、價(jià)格還有id這些字段我們放入我們索引庫(kù)里,可以提高查詢速度【推薦】.NET Core開發(fā)實(shí)戰(zhàn)視頻課程 ★★★
.NET Core實(shí)戰(zhàn)項(xiàng)目之CMS 第一章 入門篇-開篇及總體規(guī)劃
【.NET Core微服務(wù)實(shí)戰(zhàn)-統(tǒng)一身份認(rèn)證】開篇及目錄索引
Redis基本使用及百億數(shù)據(jù)量中的使用技巧分享(附視頻地址及觀看指南)
.NET Core中的一個(gè)接口多種實(shí)現(xiàn)的依賴注入與動(dòng)態(tài)選擇看這篇就夠了
10個(gè)小技巧助您寫出高性能的ASP.NET Core代碼
用abp vNext快速開發(fā)Quartz.NET定時(shí)任務(wù)管理界面
在ASP.NET Core中創(chuàng)建基于Quartz.NET托管服務(wù)輕松實(shí)現(xiàn)作業(yè)調(diào)度
現(xiàn)身說法:實(shí)際業(yè)務(wù)出發(fā)分析百億數(shù)據(jù)量下的多表查詢優(yōu)化