
基于深度學習的單目深度估計綜述(數(shù)據(jù)集、單/雙目視覺等)
點擊下方卡片,關注“新機器視覺”公眾號
重磅干貨,第一時間送達
作者 | 黃飄 編輯 | 汽車人
原文鏈接:https://zhuanlan.zhihu.com/p/111759578
前言
前段時間有思考過結合3D信息來輔助多目標跟蹤任務,不過效果沒有達到我的預期。一方面是多目標跟蹤相關數(shù)據(jù)集除了KITTI之外缺乏多任務標注信息,另一方面單目深度估計對于密集擁擠人群的效果很差。所以我覺得對于稀疏場景、車輛跟蹤或者提供真實3D信息和相機信息的場景任務更有意義。下面的總結主要是我2019年初整理的文獻,時效性可能還沒跟上。很多圖都是我從我之前整理的word里面復制出來的,所以有些模糊,想看的話可以自行搜索相關論文。
1 任務介紹
深度估計是計算機視覺領域的一個基礎性問題,其可以應用在機器人導航、增強現(xiàn)實、三維重建、自動駕駛等領域。而目前大部分深度估計都是基于二維RGB圖像到RBG-D圖像的轉化估計,主要包括從圖像明暗、不同視角、光度、紋理信息等獲取場景深度形狀的Shape from X方法,還有結合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式預測相機位姿的算法。其中雖然有很多設備可以直接獲取深度,但是設備造價昂貴。也可以利用雙目進行深度估計,但是由于雙目圖像需要利用立體匹配進行像素點對應和視差計算,所以計算復雜度也較高,尤其是對于低紋理場景的匹配效果不好。而單目深度估計則相對成本更低,更容易普及。
那么對于單目深度估計,顧名思義,就是利用一張或者唯一視角下的RGB圖像,估計圖像中每個像素相對拍攝源的距離。對于人眼來說,由于存在大量的先驗知識,所以可以從一只眼睛所獲取的圖像信息中提取出大量深度信息。那么單目深度估計不僅需要從二維圖像中學會客觀的深度信息,而且需要提取一些經驗信息,后者則對于數(shù)據(jù)集中相機和場景會比較敏感。
通過閱讀文獻,可以將基于深度學習的單目深度估計算法大致分為以下幾類:
監(jiān)督算法 顧名思義,直接以2維圖像作為輸入,以深度圖為輸出進行訓練:


上面給的例子是KITTI數(shù)據(jù)集中的一組例子,不過深度圖可能看的不是很明顯,我重新將深度圖涂色之后:

無監(jiān)督算法
由于深度數(shù)據(jù)的獲取難度較高,所以目前有大量算法都是基于無監(jiān)督模型的。即僅僅使用兩個攝像機采集的雙目圖像數(shù)據(jù)進行聯(lián)合訓練。其中雙目數(shù)據(jù)可彼此預測對方,從而獲得相應的視差數(shù)據(jù),再根據(jù)視差與深度的關系進行演化。亦或是將雙目圖像中各個像素點的對應問題看作是立體匹配問題進行訓練。左視圖-右視圖示例:


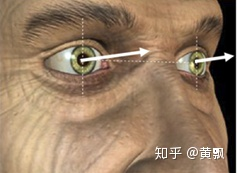
視差,以我們人眼為例,兩只眼睛看到的圖像分別位于不同的坐標系。將手指從較遠地方慢慢移動到眼前,會發(fā)現(xiàn),手指在左眼的坐標系中越來越靠右,而在右眼坐標系中越來越靠左,這種差異性就是視差。與此同時,可以說明,視差與深度成反比。除此之外,由于攝像機參數(shù)也比較容易獲取,所以也可以以相機位姿作為標簽進行訓練。
Structure from motion/基于視頻的深度估計
這一部分中既包含了單幀視頻的單目深度估計,也包含了多幀間視頻幀的像素的立體匹配,從而近似獲取多視角圖像,對相機位姿進行估計。
2 數(shù)據(jù)集介紹
2.1 KITTI
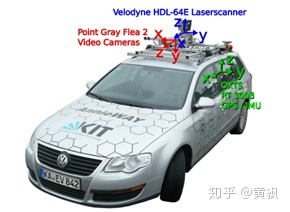
KITTI是一個多任務屬性的數(shù)據(jù)集,其中原始數(shù)據(jù)采集平臺裝配有2個灰度攝像機,2個彩色攝像機,一個Velodyne 64線3D激光雷達,4個光學鏡頭,以及1個GPS導航系統(tǒng)。
其中包含有200+G的原始數(shù)據(jù),而有關戶外場景的有175G數(shù)據(jù)。對于這些數(shù)據(jù),所標注的任務包含:立體圖像匹配、光流、場景流、深度估計(單目或者基于3D點云/激光數(shù)據(jù)的深度估計)、視覺測距、目標檢測(2D/3D物體檢測、俯視圖物體檢測)、目標跟蹤、道路/車道線檢測、目標分割等。
鏈接:http://www.cvlibs.net/datasets/kitti/eval_object.php
2.2 vKITTI
從名字可以看出這個數(shù)據(jù)集跟KITTI有關聯(lián),其對應KITTI的原始數(shù)據(jù)和各類任務,創(chuàng)建了全新的虛擬圖像,當然,并不是所有原始數(shù)據(jù)都能對應得上。這里的“虛擬”指的是:左右攝像頭15°和30°偏轉畫面、清晨、晴天、多云、霧天、下雨等基于原圖的渲染圖像。共計14G原始RGB圖像,對應的目標檢測、目標跟蹤、目標分割標注都存在。這一數(shù)據(jù)集的意義在于可以緩解深度信息對于光線的敏感問題。

鏈接:http://www.europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds
2.3 Cityscapes
Cityscapes的數(shù)據(jù)取自德國的50多個城市的戶外場景,其中數(shù)據(jù)包含有左右視角圖像、視差深度圖、相機校準、車輛測距、行人標定、目標分割等,同時也包含有類似于vKITTI的虛擬渲染場景圖像。其中簡單的左視角圖像、相機標定、目標分割等數(shù)據(jù)需要利用學生賬號注冊獲取,其他數(shù)據(jù)需要聯(lián)系管理員獲取。

鏈接:https://www.cityscapes-dataset.com/downloads/
2.4 NYU Depth V2
NYU Depth V2數(shù)據(jù)集中包含有428G室內場景數(shù)據(jù),同時包含有目標分割標注、深度標注。

鏈接:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
2.5 ScanNet
ScanNet中包含有約1500個視頻序列的RGB-D數(shù)據(jù),主要用于三維重建。

鏈接:http://www.scan-net.org/#code-and-data
2.6 Make3D
Make3d數(shù)據(jù)集包含約1000張室外場景圖片,50張室內場景,7000張合成物體。其中包含有激光-2D圖像,立體圖像、深度數(shù)據(jù)等。

3 數(shù)據(jù)處理
3.1 數(shù)據(jù)組成
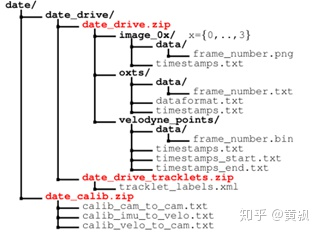
以KITTI數(shù)據(jù)集為例,它沒有給出深度相關的標注信息。其數(shù)據(jù)組成包括多個場景下的原始圖像數(shù)據(jù)(gray、color),實例分割、目標跟蹤、2d/3d目標檢測等任務信息。為了方便我后續(xù)使用,我將數(shù)據(jù)結構解析如下,由于知乎不支持表格,所以我就直接截圖了:



這一部分內容中,對于一個點云數(shù)據(jù)P:[X,Y,Z,1]^T,其中Z就是深度信息,將其轉化為相機左視圖的像素點坐標Q:[u,v,1]^T:
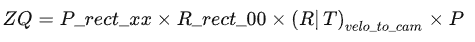
對于GPS/imu中的點G:[X,Y,Z]^T,將其轉化為相機左視圖的像素點坐標Q:
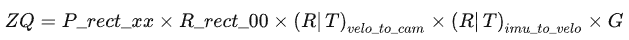
其中最需要注意的是第一個公式,用于深度的信息的提取,以及P_rect_xx,其前三列數(shù)據(jù)為修正后的相機內參。
3.2 數(shù)據(jù)處理
有關相機/像素/世界坐標系的知識我就不介紹了,對于相對位姿,如果將每個視頻場景的第一幀的位姿視為初始位姿,那么每一幀的相對位姿計算如下:

由于深度信息的轉換需要用到相機內參,所以對于圖像的縮放需要先處理,假如圖像大小的放縮尺度為[zoom_x,zoom_y],那么相機內參的變化如下:
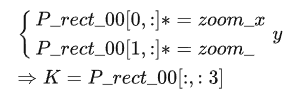
根據(jù)世界坐標系的轉換:
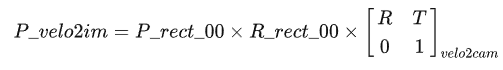
由于要求點云數(shù)據(jù)的反射強度為1,所以需要先將點云數(shù)據(jù)的反射強度置為1:
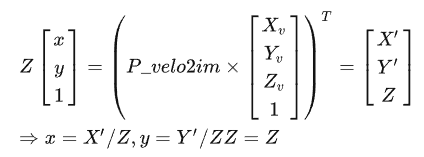
最后我們只需要保留滿足圖像邊界約束的點的深度信息,如果映射得到的點坐標相同,則只保留深度更小的。
那么對于網(wǎng)絡訓練過程中的數(shù)據(jù)增強,則可以進行多種變換,下面列出幾種基礎的:
隨機水平翻轉,所以需要改變相機內參的水平平移量cx=w-cx; 隨機尺度變換并剪切至固定大小:
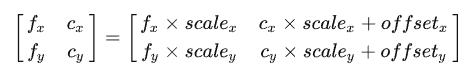
3.3 評價指標
KITTI數(shù)據(jù)集在考慮深度估計信息誤差時,所以判定的時候只取0.40810811H ~ 0.99189189H,0.03594771W ~ 0.9640522229W部分圖像區(qū)域,當然也經常會只取50m或者80m范圍內的深度信息。為了讓預測深度和真實深度的數(shù)量級范圍一致,一般會用二者深度的中位數(shù)作為尺度,對預測深度信息進行尺度放縮。
4 相關工作
4.1 基于單目視覺的深度估計
傳統(tǒng)編解碼結構
深度估計任務是從二維圖像到二維深度圖像的預測,因此整個過程是一個自編碼過程,包含編碼和解碼,通俗點就是下采樣和上采樣。這類結構主要有FCN框架和U-net框架,二者的下采樣過程都是利用了卷積和池化,而上采樣利用了逆卷積/轉置卷積(Deconvolution)和upsample。
深度回歸網(wǎng)絡
早期的單目深度估計網(wǎng)絡框架基本上都是直接利用了上面所提到的兩個基礎框架進行了預測,為了讓這類框架更好的應用于深度估計問題,一般都從以下幾個方面著手:更好的backbone模型、多尺度、更深的網(wǎng)絡。
以3DV 2016中《Deeper Depth Prediction with Fully Convolutional Residual Networks》一文為例,其提出了FCRN網(wǎng)絡框架:
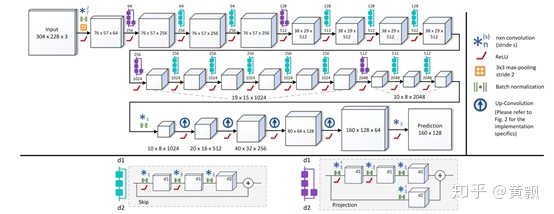
其網(wǎng)絡框架主體是基于Resnet-50,在上采樣過程中采用了獨特的方式,將逆卷積用up-pooing+conv的方式替代了,將Resnet中的project模塊進行了一定的改進。
其中上采樣過程中將特征圖利用0元素進行填充,然后利用一類特殊的卷積核進行特征提取,這一過程可以先卷積,然后錯位相連得到,原理如下:
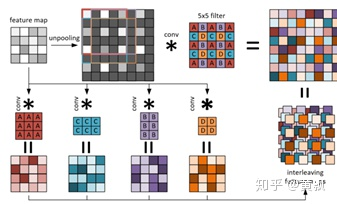
其中可以發(fā)現(xiàn)卷積核并非是正方形,而是矩形,不過過程其實是一樣的。而projection部分,即resnet中原圖先經過1×1卷積再與特征圖相連的部分,變?yōu)椋?/p>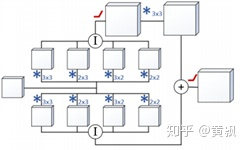
具體細節(jié)我就不在多講了,其效果如下:
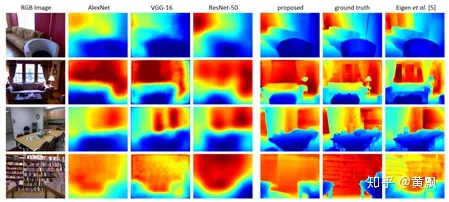
其代碼鏈接為:https://github.com/iro-cp/FCRN-DepthPrediction,基于Tensorflow和matconvnet。
深度分類網(wǎng)絡
將深度估計問題變?yōu)榛貧w問題的缺點在于,太依賴于數(shù)據(jù)集的場景,并且由于圖像中深度往往是分層的,類似于等高線之類的,所以也有學者將深度估計變?yōu)橐粋€分類問題,而類別數(shù)就是將最遠實際距離劃分為多份而制作的。
以此為代表的是CVPR2018中《Deep Ordinal Regression Network for Monocular Depth Estimation》所提出的DORN框架:
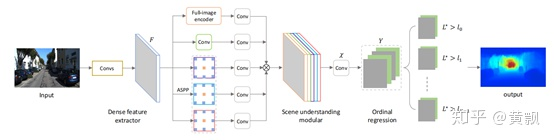
該框架2018年在多個數(shù)據(jù)集上取得了第一的名次,不過現(xiàn)在有個別算法超越了。可以看到,原圖在經過密集特征提取之后,增加了一個場景理解模塊,這一模塊包含5個部分。其中full-image encoder部分與傳統(tǒng)的自編碼器不同:
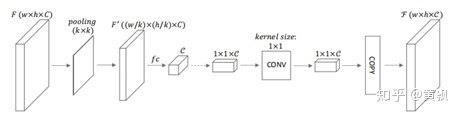
可以看到其先是利用池化進行下采樣,將其拉伸為向量之后,利用全連接層進行編解碼,然后還原為原圖大小。而ASPP模塊是利用了膨脹卷積(dilated convolution)進行特征提取,膨脹倍數(shù)分別為6,12,18。五個部分concat得到最終的特征圖。再進入有序回歸模塊,實質上是多分類器。其將深度范圍劃分為多個區(qū)間:

最后輸出W×H×2K的結果,K代表深度區(qū)間,2K是因為每兩個相鄰的通道值2n表示深度小于n的概率,2n+1表示深度大于n的概率,二者利用softmax歸一化。其效果如下:

可以看到,DORN對于深度的細節(jié)把握得非常好,其速度約為2fps,代碼基于caffe平臺,鏈接為:https://github.com/hufu6371/DORN
無論是回歸還是分類,都是以深度信息作為標簽的監(jiān)督算法,因此其受限于訓練集場景,僅限于刷榜。
4.2 結合雙目視覺的單目深度估計
既然監(jiān)督算法受限于場景,那么近兩年則出現(xiàn)了很多無監(jiān)督算法,其中就包含有利用雙目數(shù)據(jù)進行訓練的算法,下面我用幾個例子進行說明。
首先以CVPR2017中《Unsupervised Monocular Depth Estimation with Left-Right Consistency》一文所提出的Monodepth算法為例。這篇論文算是這類算法的一個開端吧,效果并沒有非常優(yōu)異,但是引出這樣一條思路。其網(wǎng)絡框架如下:
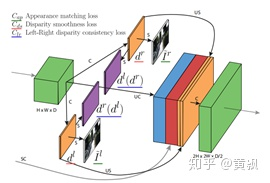
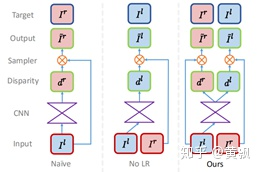
該算法將深度估計問題變成了左右視圖立體匹配問題,都是先從原始圖預測另外一個視圖的視差,然后結合輸出另外一個視圖。整體框架依賴DispNet,而DispNet又是在FlowNet基礎上進行的改變,主要改變是在多尺度銜接出增加卷積層,以保證圖像盡可能平滑。
經過自編碼器之后,分別利用逆卷積、預測的右視圖相對左視圖的視差+upsample/雙線性插值、預測的左視圖相對右視圖的視差+upsample/雙線性插值、原圖。有了這些之后,損失函數(shù)部分則同時包含有:
外觀匹配損失,即預測的視圖和實際視圖的區(qū)別:
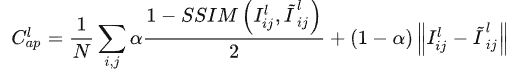
其中SSIM指的是結構相似性。
視差平滑性約束:
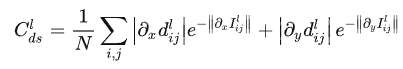
左右視差一致性損失:
由于其主要在KITTI_outdoor和Cityscapes上訓練的,所以對于室外場景效果會略好,又因為其算法框架比較簡單,所以深度信息中的細節(jié)比較模糊,尤其是存在遮擋或者物體相連的情況時。測試效果如下:

通過其原理和論文中的測試效果來看,其對于室外場景下的深度估計效果還行,不過對于邊緣部分的把握不是很好。再加上大多是街景數(shù)據(jù),所以對于室內場景的視角具有很大的不適應性。另外,由于立體匹配對于大面積的純色或者顏色相近的圖像塊效果很差,所以Monodepth不適用于紋理不清晰的場景,容易將大片顏色類似的圖像塊視為一個整體。
代碼是基于tensorflow進行開發(fā)的:https://github.com/mrharicot/monodepth,也有pytorch0.4.1的復現(xiàn)版本:https://github.com/ClubAI/MonoDepth-PyTorch。
與此同時,在CVPR2018中,由商湯團隊在《Single View Stereo Matching》一文中提出了類似的SVS算法,其相對于Monodepth,在細節(jié)和場景適應性方面有了很大的提升。
SVS網(wǎng)絡框架如下:
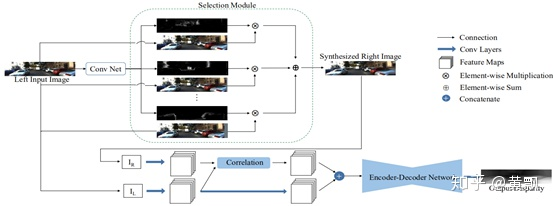
從圖中不難看出,得到預測的右視圖之后,兩個視角的圖像進行類似于DispNet的立體匹配,從而獲得左視圖的視差。而關鍵在于怎么從左視圖預測右視圖。可以發(fā)現(xiàn),SVS在利用卷積層對左視圖進行特征提取之后,分別將每一通道的特征圖和原圖進行元素乘法,然后再相加。這一部分實際上是借鑒了Deep3D的框架。Deep3D模型是用來將2D圖像轉化為3D圖像對的,其框架為:
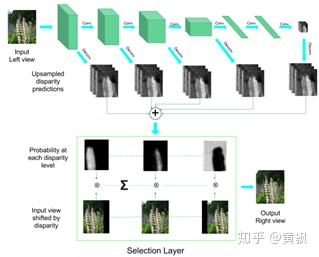
假設每個通道分別代表著在左視圖中每個像素點相對右視圖中的視差偏移量的概率分布。綜上,SVS實質上就是Deep3D+Dispnet的合體版,其效果圖如下:
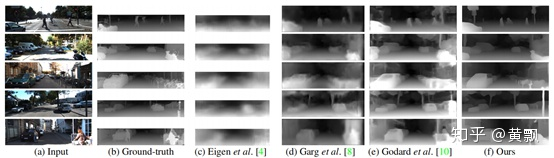
同時可以看看基于KITTI數(shù)據(jù)集訓練的SVS模型在其他數(shù)據(jù)集上的測試效果:

代碼是基于caffe開發(fā)的:https://github.com/lawy623/SVS
4.3 基于視頻的相機位姿估計和視覺測距
基于視頻的單目深度估計大多都是面向相機位姿估計和視覺測距的,其核心就是利用相鄰視頻幀所產生的運動,近似多視角圖像,并對相機位姿進行估計,從而可以估計出相機的移動路線,進一步完成SLAM工作。
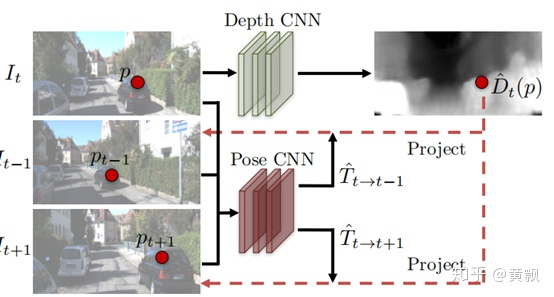
那么在CVPR2017的一篇《Unsupervised Learning of Depth and Ego-Motion from Video》中則是提出了SFM算法,這篇文章中對于深度估計的求解較為簡單,所以效果不是很好,但是提出了基于視頻幀序列的相機位姿估計算法。
其論文中使用了相鄰3幀的信息,不過代碼卻是用的相鄰5幀的信息,整體框架比較簡單:
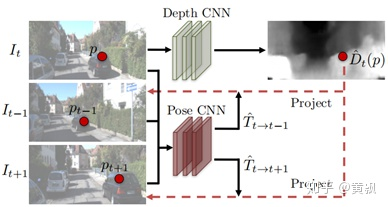
可以看到,單目深度估計部分僅僅是針對一幀的,直接采用了Dispnet的網(wǎng)絡框架,不過我發(fā)現(xiàn)實際上是U-net,而相機位姿估計則是將相鄰幀的相對相機位姿變化看作一個含有6個元素的向量(可以理解為x,y,z方向的平移量和旋轉量)進行預測。有意思的是,SFM并沒有使用深度信息作為標簽,而是將深度信息作為一個過程變量,將前后幀圖像聯(lián)系起來,從而做到無監(jiān)督學習,不過相機位姿的訓練還是有監(jiān)督的:
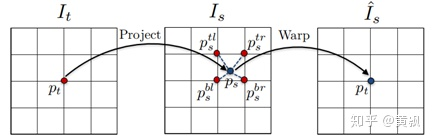
利用預測的相機位姿和深度信息,可估計出目標視圖相對原視圖的像素點位置,由于預測的像素點位置可能不是整數(shù),為了保證其為整數(shù),將采用雙線性插值,其中K是相機參數(shù)矩陣:
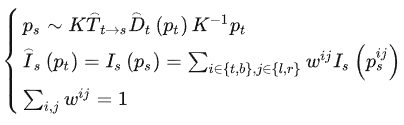
可以看到這里的插值方式是對估計像素點位置處的相鄰4個位置的像素進行加權平均,然后作為目標像素點位置處的像素值,新合成的視圖和目標視圖進行一致性約束。
不過上述這種做法受限于靜態(tài)場景,且無遮擋情況,為了緩解這種問題,作者又加入了一個可解釋性網(wǎng)絡:
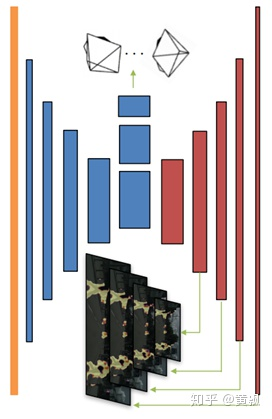
該網(wǎng)絡的編碼部分輸出的是相機位姿,解碼部分輸出的是多個尺度的解釋性眼膜,其意義是合成視圖中的每個像素點能夠被成功建模的概率。而這一部分是沒有標簽的,所以作者通過設計損失函數(shù)將其進行了約束:
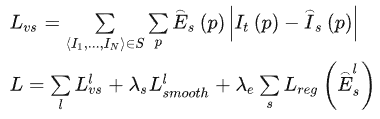
l指的是尺度,s指的是圖片,其中的平滑性約束跟上一節(jié)所講的Monodepth一樣,由于解釋性掩膜無標簽,如果不加約束的話會自動為0,所以利用交叉熵損失函數(shù)對其進行了約束,默認為全1矩陣。其效果如下:

可以看到,深度估計的效果并不是很好,不過整體的設計思路很新穎,也可以看看其對于解釋性掩膜的預測效果:

可以發(fā)現(xiàn),對于發(fā)生變化的部分,即前景部分,其不可解釋性很高,其實這個也能用來估計光流。
代碼是基于tensorflow的:https://github.com/tinghuiz/SfMLearner,
不過有pytorch的復現(xiàn)版本:https://github.com/ClementPinard/SfmLearner-Pytorch
果不其然,在CVPR2018中商湯又提出了GeoNet,該網(wǎng)絡在SFM的基礎上增加了光流監(jiān)督信息:
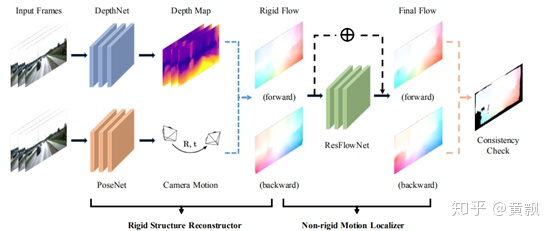
可以看到,前半部分的深度估計和相機位姿估計都跟SFM一樣,只是在后面增加了光流的輸出,先利用前半部分得到剛性結構的光流,后半部分增加一個非剛性光流預測環(huán)節(jié),二者之和就是最終的光流。效果:
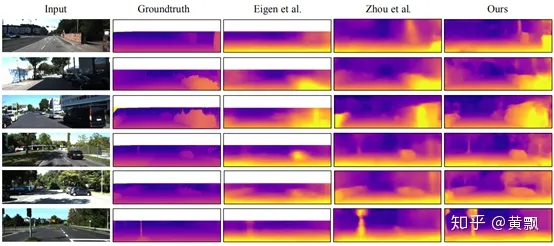
可以看到,GeoNet的深度估計效果并沒有特別突出,代碼是基于Tensorflow的:https://github.com/yzcjtr/GeoNet
同樣的還有CVPR2018的《Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction》一文中提到的Depth-VO-Feat:
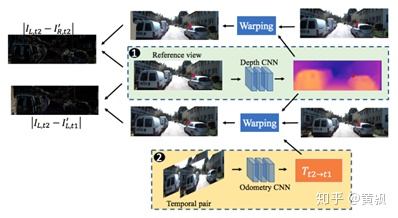
直接從這個網(wǎng)絡架構可以看到包含了兩個部分的圖像重構,一個是左視圖和右視圖的重構,一個是前后兩幀間的重構,重構的意義在于找到對應像素點的聯(lián)系,并非直接利用左右視圖進行誤差計算,可以看到圖中對于右視圖的邊緣填充。由于該框架假設場景是Lambertian的,即無論從哪個角度觀察,其光照強度是一致的,那么這對于圖像的重構就很敏感,因此,作者又添加了特征的重構,框架一致。
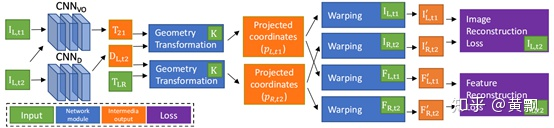
對于訓練細節(jié),除了圖像和特征的L1重構誤差之外,也加入了邊緣平滑性約束,骨干網(wǎng)絡是Resnet50的變種。對于深度估計,其預測的是深度信息的倒數(shù)。效果如下:

可以看到,深度估計的效果還是中規(guī)中矩,不過其可以用來做視頻中相機的移動軌跡預測,這一點在多目標跟蹤(MOT)中對于手持相機的場景有所幫助。代碼是基于caffe的:https://github.com/Huangying-Zhan/Depth-VO-Feat
相應的,近幾年關于無監(jiān)督單目深度估計的研究越來越多,我抽空了看了下,比如有Google出品的vid2depth和struct2depth算法,二者的代碼鏈接如下:
vid2depth:https://github.com/tensorflow/models/tree/master/research/vid2depth
struct2depth: https://github.com/tensorflow/models/tree/master/research/struct2depth。
其他的也挺多的,后面章節(jié)我會再補充一點,不過肯定不全。
4.4 基于圖像風格遷移的單目深度估計
實質上,深度圖像也是一種圖像風格,如果我們要將生成學習引入深度估計的話,就需要注意兩個地方,一個是原始圖像到深度圖像的風格轉變,這一點可以獲取類似于分割的map,另一點就是對像素點的深度進行回歸。這里的方式與第一節(jié)講的深度回歸模型不一樣,因為第一步的風格轉變,已經對于場景和相機位姿有了很好的適應性。
ECCV2018中《T2Net: Synthetic-to-Realistic Translation for Solving Single-Image Depth Estimation Tasks》所提出的T2Net嘗試性地將圖像風格遷移引入單目深度估計領域,雖然效果只是2016年的水平,不過也算是一次很好的嘗試了。下面介紹下T2Net的思路,首先給出其網(wǎng)絡框架:
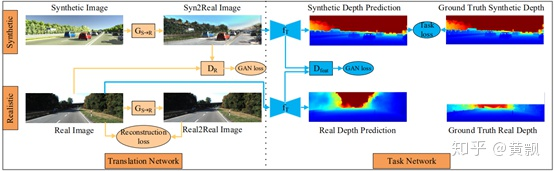
框架很明顯,對于室外場景,其訓練集用到了KITTI和VKITTI中的sunset場景,對于室內場景,則使用了NYU Depth v2和SUNCG,沒仔細看怎么下載,相關工具在https://github.com/shurans/SUNCGtoolbox。
從圖中可以看到,作者做了兩個模塊,一個是圖像風格遷移模塊,一個是單目深度估計模塊。其中圖像風格遷移模塊中包含有合成圖像到真實圖像的遷移,真實圖像到真實圖像的遷移,二者共用一個GAN。其中的Loss包含有:
由合成圖像風格遷移生成的圖像與原始圖像的GAN Loss,即利用判別器進行判定的誤差; 由真實圖像風格遷移生成的圖像預原始圖像的重構誤差,這一部分計算L1 Loss; 由合成圖像風格遷移生成的圖像與原始圖像的編碼特征的GAN Loss。
然后僅對合成圖像分支進行深度估計,同樣地,也加入了深度圖的平滑性約束。從不匹配的圖像對可以看出,其基礎框架為CycleGAN。
可以看到風格遷移的效果和深度估計的效果如下:

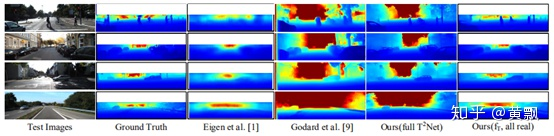
從結果中我們發(fā)現(xiàn)有一個版本的實現(xiàn)效果超過了完整框架,通過查閱發(fā)現(xiàn),是只利用真實數(shù)據(jù)進行深度估計的效果,也就是說效果比加入圖像遷移的效果更好,打自己臉。。。實際上他是在跟只用合成圖像進行深度估計訓練的效果作比較,確實好了些。
代碼鏈接:https://github.com/lyndonzheng/Synthetic2Realistic
除此之外,在CVPR2018也有一篇類似的算法《Real-Time Monocular Depth Estimation using Synthetic Data with Domain Adaptation via Image Style Transfer》,其效果則是達到了state-of-art,我們暫且稱其為MDEDA,網(wǎng)絡框架如下:
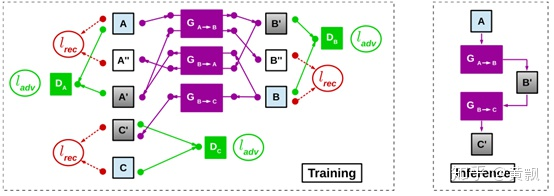
熟悉CycleGAN框架的話,應該很容易看懂其中的關系,其中存在三種圖像序列,一種是原始圖像,一種是合成的圖像,一種是深度圖像,不同的是三種圖像內容是一致的,而非CycleGAN那樣不匹配的。其中原始圖像和合成圖像之間進行圖像風格的循環(huán)遷移和重構,合成圖像與深度圖像進行單向的風格遷移。
效果如下:

左側的是直接對原圖進行深度估計的效果,中間是其他圖像遷移算法的效果,右側是采用本文算法后的合成以及深度估計效果,速度大概為44fps。合成圖像對于深度估計的效果提升也反映了一個問題,即圖像光暗條件對于深度估計有很大影響,所以對于一些出現(xiàn)了陰影,如影子等的場景,深度估計會出現(xiàn)偏差,如:

代碼只提供了測試模型:https://github.com/atapour/monocularDepth-Inference
4.5 多任務深度估計
在ICRA2019中《Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations》中基于圖像分割算法RefineNet設計了一個多任務框架。其中RefineNets是CVPR2017中提出的算法,其全局框架是基于Resnet的U-net網(wǎng)絡框架,可以輸出多尺度的分割圖:
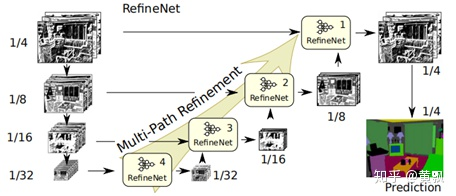
可以看到的是,RefineNet在每一個尺度的上采樣部分都增加了一個局部提升的網(wǎng)絡,用于多尺度輸出的融合:
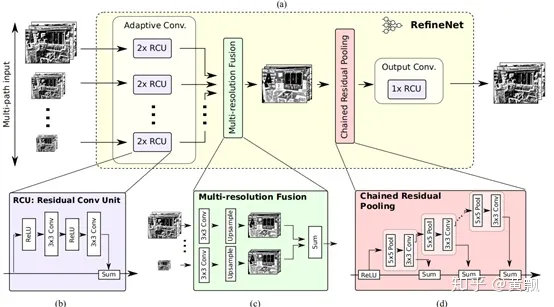
所以其主要創(chuàng)新在于采用skip-connection和 Resnet Block的方式不斷融合各種分辨率的特征,用于增加更多的細粒度特征,從而方便生成更高分辨率的預測:

那么在BMVC2018中則是提出了一種Light-weighted RefineNet算法,顧名思義,就是RefineNet的輕量級網(wǎng)絡,其對于512×512大小的圖像,速度從RefineNet的20FPS提升到了55FPS(1080Ti),效果略微下降。代碼基于Pytorch: https://github.com/DrSleep/light-weight-refinenet
那么回到正題,我們提到的這個同時進行深度估計和目標分割的網(wǎng)絡框架,對于1200×350大小的輸入,其速度為60FPS。網(wǎng)絡框架如下:
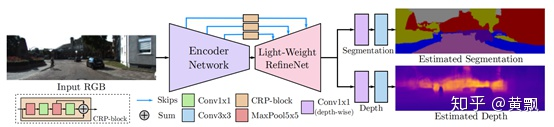
以上的結構通過之前我介紹的深度估計框架以及Light-Weighted RefineNet框架很容易能看懂,之所以比原本的Light-Weighted RefineNet還要快,是因為將其中的部分1×1卷積替換成了MobileNetV2中采用的depthwise卷積方式。
對于分割和深度估計任務的結合,從網(wǎng)絡框架和損失函數(shù)的設計來看可以發(fā)現(xiàn),其除了特征是共享的之外,預測任務是獨立的。效果如下:

代碼僅提供了測試用例:https://github.com/drsleep/multi-task-refinenet
ECCV2018中《DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency》一文提出了單目深度估計和光流預測的聯(lián)合任務框架。不同于單獨訓練兩個任務的方式,作者將二者的一致性進行了考慮,從而做到二者的相互促進,可以看到對比效果:

其主要思路是利用無監(jiān)督的方式從視頻中預測深度信息和相機位姿變化,這一部分對于剛性流場景比較適用,即靜態(tài)背景。通過幾何一致性的約束監(jiān)督,可以將3D的場景流映射到2D光流上,由此與光流預測模型的結果進行一致性約束。具體框架如下:
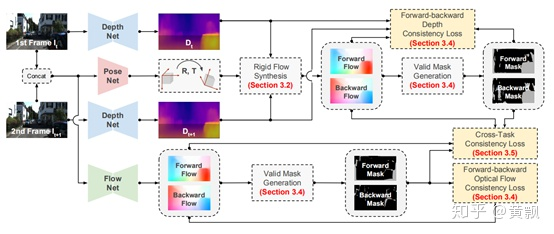
乍一看可以發(fā)現(xiàn)網(wǎng)絡框架的前半部分很眼熟,圖中展示的是分別對前后幀做單目深度估計,然后利用前后幀做相機位姿變化預測和光流預測,結合SFM網(wǎng)絡中像素點轉移的計算公式,可以利用深度信息和相機位姿變化關系求得在t+1時刻對應像素點位置,由此可以計算剛性流場景下的光流。
對于剛性流場景下的合成光流信息和直接預測到的光流信息,二者都反映了相鄰兩幀的像素點的對應關系,因此作者對此引入了光照約束(利用對比映射和插值,計算每個像素點的像素值差異)和深度的平滑性約束。
再來看Forward-Backward模塊,由于我們在上面提到了光照一致性約束,但實際上對于重疊區(qū)域并不適用,因此加入了前后向一致性的約束。即圖中的Valid Mask部分,利用剛性流信息可以檢測出一些無效的像素區(qū)域,如運動物體、畫面邊緣等,因為這些都不符合剛性這一條件,那么再在有效區(qū)域使用光照一致性假設:

感覺這個跟SFM中的Explain Mask一樣,然后前后的一致性約束,則是分光流和深度估計兩部分,其中深度的一致性跟光照一致性的計算方式一樣,而光流的一致性則是真的計算了前向和反向的光流一致性。最后對于深度和光流的共同有效區(qū)域,保證二者預測的光流盡可能一致。為了保證更好的訓練效果,作者先在SYNTHIA數(shù)據(jù)集上預訓練光流預測,采用的是UnFlownet-C網(wǎng)絡,在KITTI和Cityscapes上預訓練深度估計和相機位姿預測,采用的是SFM框架,然后進行聯(lián)合訓練。代碼基于Tensorflow: https://github.com/vt-vl-lab/DF-Net
我前段時間還發(fā)現(xiàn)一個多任務的集成框架CVPR2019的CCN算法《Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation》,效果目前好像還是SOTA,其融合了單目深度估計、相機位姿估計、光流估計和運動分割多個任務,代碼:https://github.com/anuragranj/cc
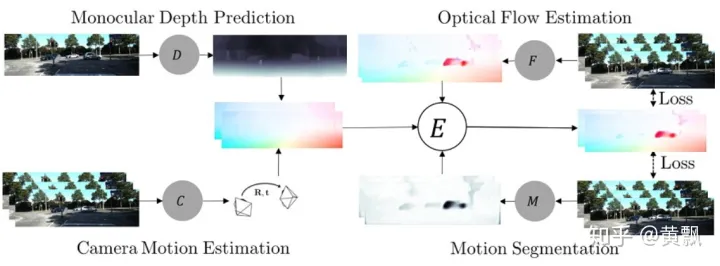
本小節(jié)的內容都是基于無監(jiān)督的單目深度估計算法。
5 總結
對于單目深度估計模型,目前主要分為基于回歸/分類的監(jiān)督模型,基于雙目訓練/視頻序列的無監(jiān)督模型,以及基于生成學習的圖像風格遷移模型。大概從2017年起,即CVPR2018開始,單目深度估計的效果就已經達到了雙目深度估計的效果,主要是監(jiān)督模型。但是由于現(xiàn)有的數(shù)據(jù)集主要為KITTI、Cityscapes、NYU DepthV2等,其場景和相機都是固定的,從而導致監(jiān)督學習下的模型無法適用于其他場景,尤其是多目標跟蹤這類細節(jié)豐富的場景,可以從論文中看到,基本上每個數(shù)據(jù)集都會有一個單獨的預訓練模型。
對于GAN,其對于圖像風格的遷移本身是一個很好的泛化點,既可以用于將場景變?yōu)榍缣臁㈧F天等情況,也可以用于圖像分割場景。但是深度估計問題中,像素點存在相對大小,因此必定涉及到回歸,因此其必定是監(jiān)督學習模型,所以泛化性能也不好,以CVPR2018的那篇GAN模型為例可以對比:

左邊是KITTI的測試效果,右邊是MOT的測試效果,從上到下依次是原圖、合成圖,以及深度圖。可以看到,其泛化性能特別差。而對于無監(jiān)督模型,從理論上來講,其泛化性能更好。那么對于無監(jiān)督模型,我們分兩部分進行討論,第一部分是利用雙目視差進行訓練的無監(jiān)督模型,這里的無監(jiān)督模型中包含有左右視圖預測的監(jiān)督信息,所以存在一定程度的局限性。以Monodepth為例:

對于無監(jiān)督的算法,可能場景適應性會更好,但依舊不適用于對行人深度的估計。
6 參考文獻
本文僅做學術分享,如有侵權,請聯(lián)系刪文。