
150億參數(shù),谷歌開源了史上最大視覺模型V-MoE的全部代碼

極市導讀
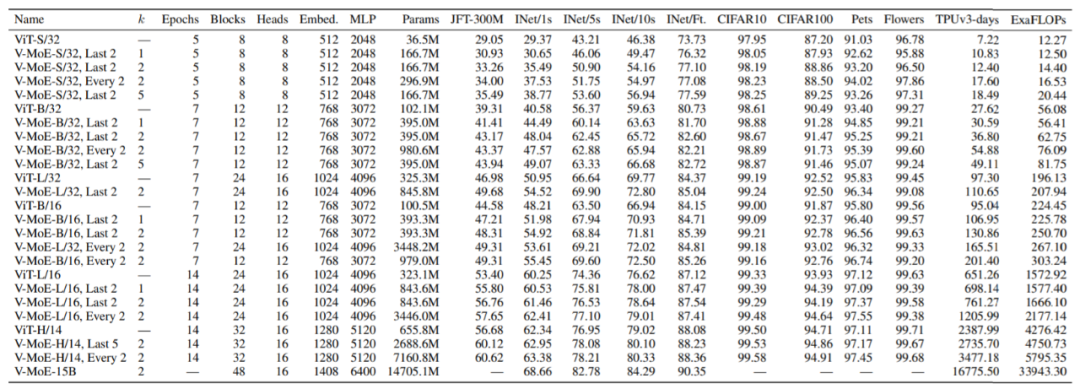
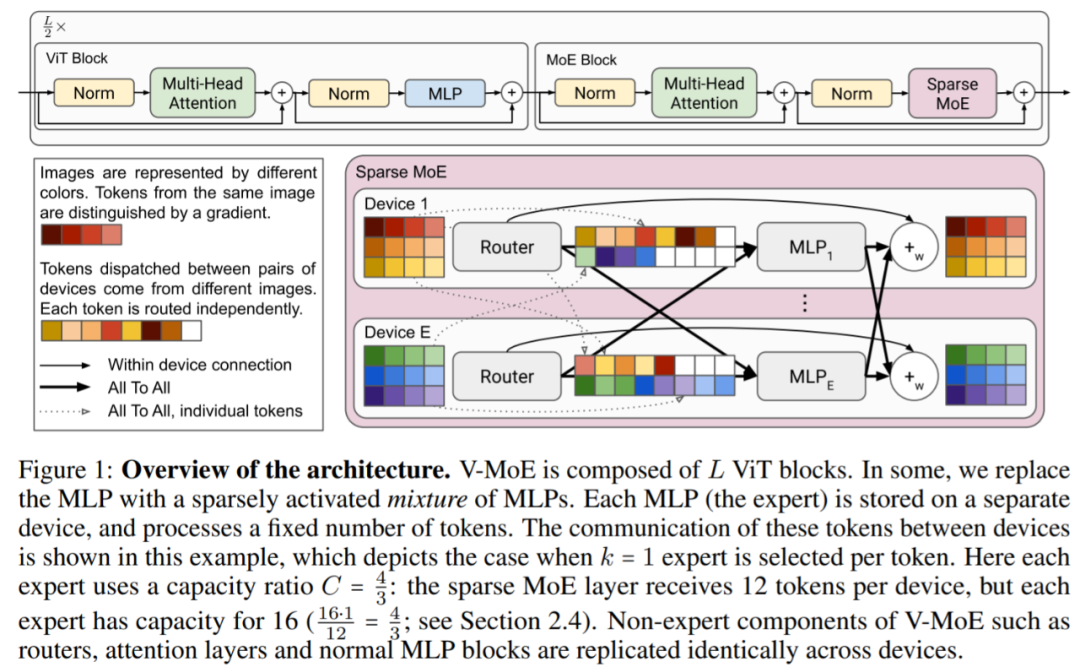
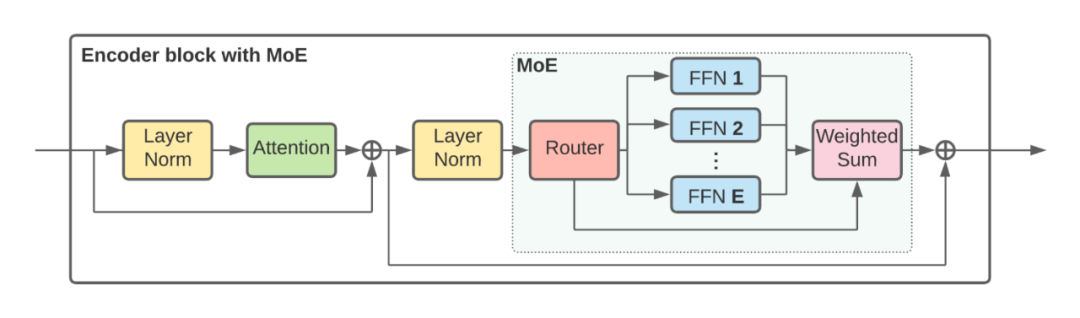
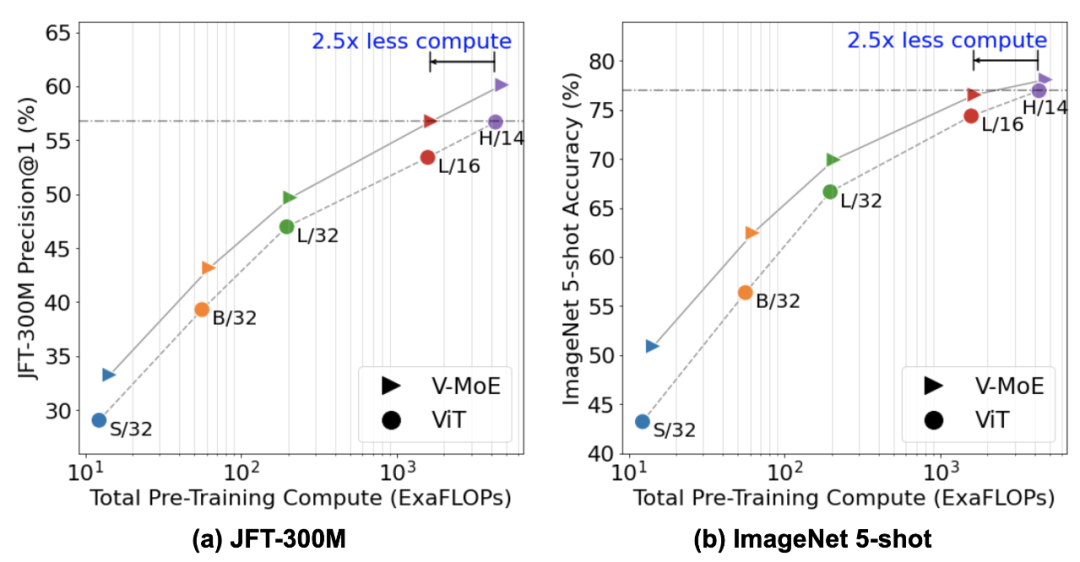
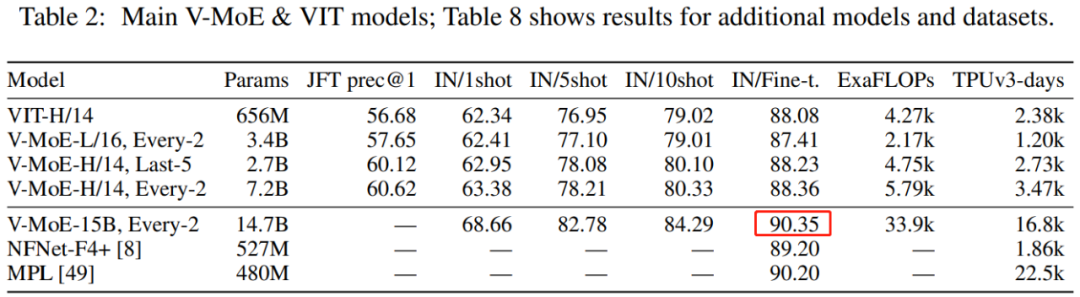
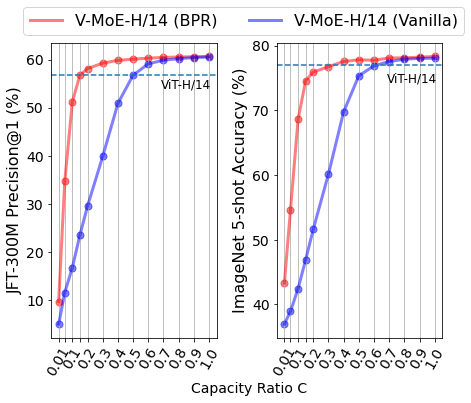
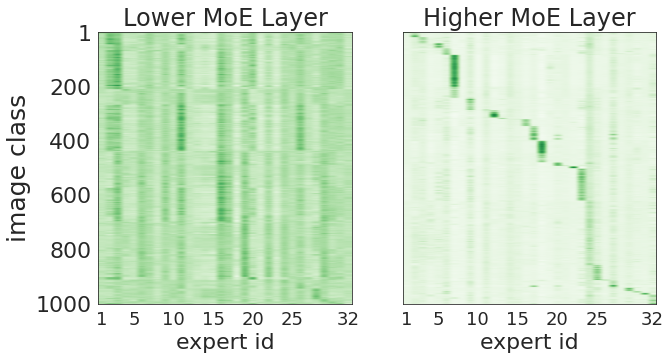
?還記得谷歌大腦團隊去年 6 月份發(fā)布的 43 頁論文《Scaling Vision with Sparse Mixture of Experts》嗎?他們推出了史上最大規(guī)模的視覺模型 V-MoE,實現(xiàn)了接近 SOTA 的 Top-1 準確率。如今,谷歌大腦開源了訓練和微調(diào)模型的全部代碼。?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿


如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復“transformer”獲取最新Transformer綜述論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~

評論
圖片
表情